文章目录
-
-
- [✅ 简单回顾:什么是 VAE?](#✅ 简单回顾:什么是 VAE?)
- [🔄 Stable Diffusion 和 VAE 的关系:](#🔄 Stable Diffusion 和 VAE 的关系:)
-
- [🎯 编码器:](#🎯 编码器:)
- [💥 解码器:](#💥 解码器:)
- [🤔 那 Stable Diffusion 本身是 VAE 吗?](#🤔 那 Stable Diffusion 本身是 VAE 吗?)
- [🧠 简要对比:](#🧠 简要对比:)
-
, VAE(变分自编码器) 和 Stable Diffusion 有密切关系,尤其体现在其 编码器和解码器结构 上,但它们并不完全等同。
✅ 简单回顾:什么是 VAE?
变分自编码器(VAE) 是一种生成模型,结构包含:
- 编码器(Encoder):将输入数据编码为潜在空间中的分布(而不是一个点),即输出均值和方差;
- 重参数化技巧(Reparameterization Trick):从这个分布中采样潜在变量;
- 解码器(Decoder):从潜在变量中重构出原始数据;
- KL 散度损失:用来让编码分布接近标准正态分布。
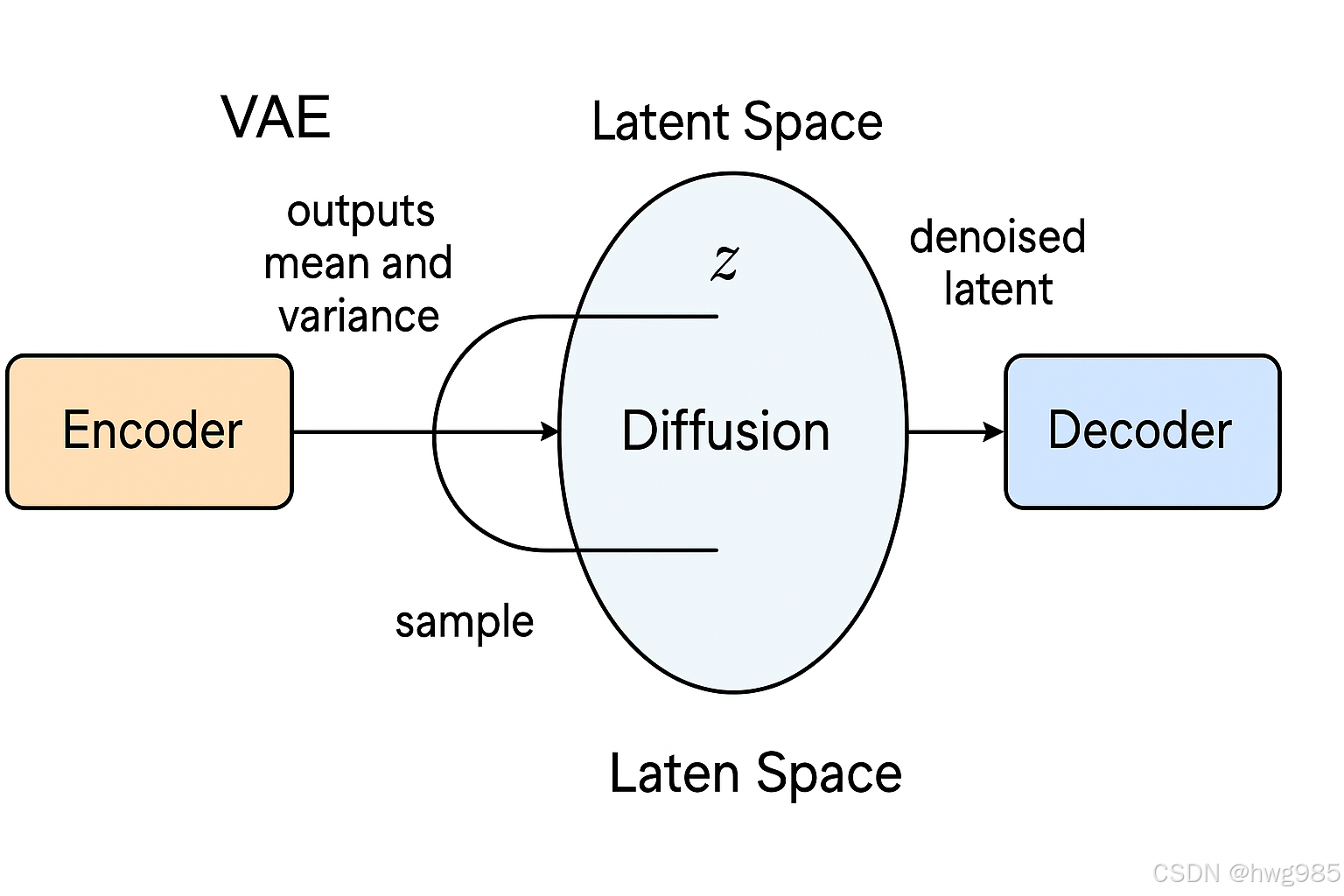
🔄 Stable Diffusion 和 VAE 的关系:
在 Stable Diffusion 中,VAE 的角色主要体现在数据预处理和还原:
🎯 编码器:
- 输入一张真实图像;
- 编码成 潜在空间中的一个"紧凑表征"(一个更小的 latent image);
- 这个 latent image 是接下来扩散过程的输入。
💥 解码器:
- 当扩散过程完成后(得到一个 denoised latent 表征);
- 用解码器将 latent image 还原为最终的图像。
这个过程就是 Stable Diffusion 中的 VAE。
🤔 那 Stable Diffusion 本身是 VAE 吗?
不是。
- Stable Diffusion 是基于 扩散模型(Diffusion Models) 的,它的核心是逐步去噪的过程;
- 它的 潜在空间编码器和解码器 是借用了 VAE 的结构思路;
- 但主要的建模能力来自 U-Net 模型 + 噪声预测(denoising),不是 VAE 的重参数化采样方式。
🧠 简要对比:
| 方面 | VAE | Stable Diffusion |
|---|---|---|
| 核心机制 | 编码-解码 + KL损失 | 噪声建模 + 去噪采样 |
| 编码器 | 输出高斯分布 | 压缩图像为 latent |
| 解码器 | 重建图像 | 从 latent 生成图像 |
| 潜变量使用 | 显式使用 ( z \sim N(\mu, \sigma^2) ) | 在 latent space 上运行扩散 |
画个结构图或者进一步讲讲 latent space 和扩散过程的交互