文章目录
-
通过构建一个3 层的人工神经网络ANN模型对收集到的数据进行训练,得到该医疗数据的分类模型,最后利用新的医疗数据,预测其所属病理分类。
血液检测项目
- 本次血液检测项目只有链球菌 x 1 x_1 x1和葡萄球菌 x 2 x_2 x2两种,身体血液中对于不同的球菌组合会呈现不同的病原体(不同的病症)。 现在假设有两个分类,分别是病原体I和病原体 II,分别用蓝色和灰色表达: x轴表示链球菌的值, y轴表示葡萄球菌的值。
项目实现步骤
项目导包和自定义分类边界函数
python
import matplotlib.pyplot as plt
import numpy as np
from mpmath.libmp.backend import xrange
from sklearn import datasets
from sklearn import linear_model
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
def plot_decision_boundary(pred_func, data, labels):
# 绘制分类边界函数
x_min, x_max = data[:, 0].min() - 0.5, data[:, 0].max() + 0.5
y_min, y_max = data[:, 1].min() - 0.5, data[:, 1].max() + 0.5
# 生成一个点阵网格,点阵间距为h
h = 0.01 # 点阵间距
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
# 计算分类结果z
z = pred_func(np.c_[xx.ravel(), yy.ravel()])
z = z.reshape(xx.shape)
# 绘制轮廓和训练样本,轮廓颜色使用Blues透明度0.2
plt.contourf(xx, yy, z, cmap=plt.cm.Blues, alpha=0.2)
plt.scatter(data[:, 0], data[:, 1], s=40, c=labels, cmap=plt.cm.tab20c, edgecolors="Black")准备数据
- 本例中产生的医疗数据是通过skiearn 的 datasets 产生的,并不是真实的医疗数据。
python
# 医疗数据是通过sklearn的datasets产生的,并不是真实的医疗数据
np.random.seed(0)
X, y = datasets.make_moons(300, noise=0.25) # 300个数据点,噪声设定0.25
# 显示产生的医疗数据 深色 病原体Ⅰ 浅色 病原体Ⅱ
plt.scatter(X[:, 0], X[:, 1], s=50, c=y, cmap=plt.cm.tab20c, edgecolors="Black")
plt.title('Medical Data Analysis')
plt.xlabel("链球菌值")
plt.ylabel("葡萄球菌值")
plt.show()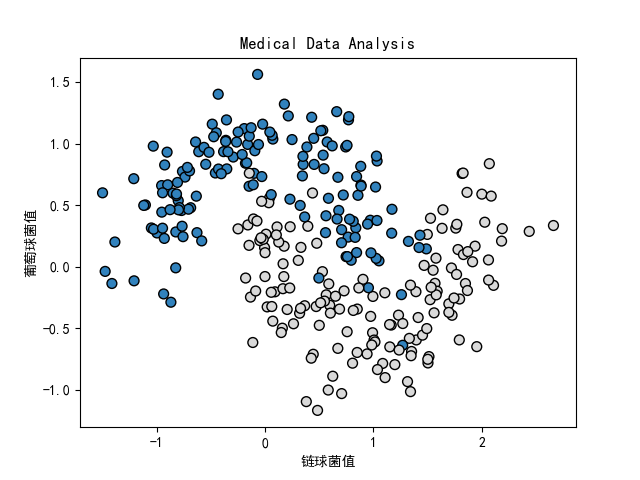
线性分类
- 对数据进行二分类最直接有效的方法就是采用线性回归分类器,下面使用 skleam的 LogisticRegressionCV 函数对数据进行二分类。
python
# 使用scikit-learn的线性回归分类器
logistic_fun = linear_model.LogisticRegressionCV()
logistic_fun.fit(X, y)
# 示线性分类结果
plot_decision_boundary(lambda x: logistic_fun.predict(x), X, y)
plt.title("Logistic Regression Result")
plt.xlabel("链球菌值")
plt.ylabel("葡萄球菌值")
plt.show()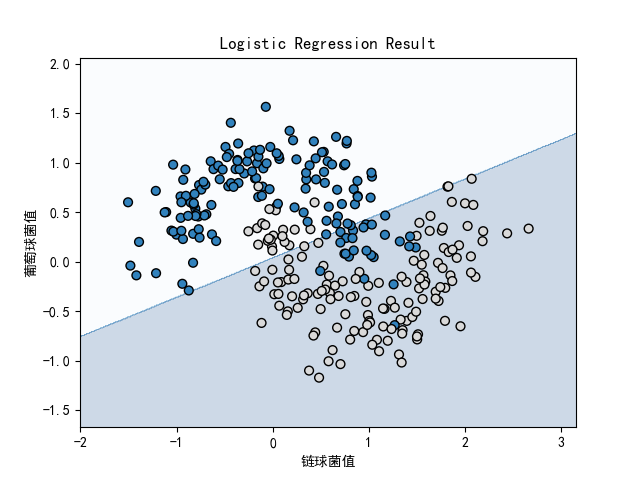
- 逻辑回归算法直接用直线将数据分隔为两类。从图中可以清晰地看到该分类结果远远不能满足真实
目的。
人工神经网络模型
- 在现实生活当中,数据大多是线性不可分的,因此我们不能简单地使用直线将数据划分为两份。为减少误差, 提升分类的结果和质量,可以采用人工神经网络对数据进行预测分类。
设计人工神经网络模型
- 建立一个3 层神经网络模型,包括输入层、隐层、输出层。
- 输入层中的神经节点数目由输入数据的维数决定,本例中有链球菌 x 1 x_1 x1和葡萄球菌 x 2 x_2 x2,因此输入数据维度是 2 2 2,输入由2个神经元节点组成。同理,输出层中的节点数目由输出的分类维度决定, 本例中为病原体 I(O)和病原体 II(1),因此输出层由 2个神经元组成。
- 人工神经网络的定义图
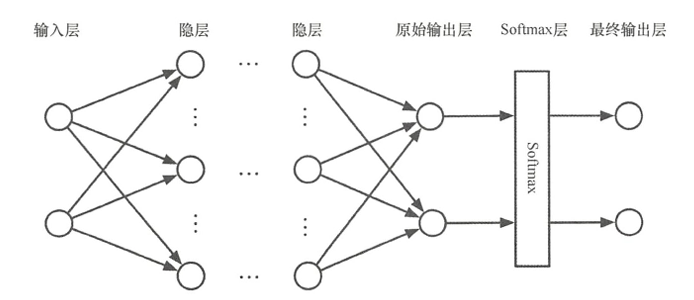
- 激活函数使用Tanh函数,输出层函数使用Softmax函数
- 在神经网络中Softmax 函数常作用于输出层,将神经网络的输出向量转换成同分布的概率分布。
- 损失函数采用交叉熵损失函数(负对数似然函数),假设 N N N个训练样本,对应C个分类,预测值 y ^ \hat y y^与真实值 y y y的损失函数为:
L ( y , y ^ ) = − 1 N ∑ n ∈ N ∑ i ∈ C y n , i l o g y ^ n , i L(y,\hat y)=- \frac{1}{N} \sum_{n \in N} \sum_{i \in C} y_{n,i}log\hat y_{n,i} L(y,y^)=−N1n∈N∑i∈C∑yn,ilogy^n,i - 梯度下降算法使用固定学习率 η \eta η的批量梯度下降算法 x ← x − η Δ x x \leftarrow x-\eta \Delta x x←x−ηΔx对本例中人工智能模型中用到的参数 W 1 , b 1 , W 2 , b 2 W_1,b_1,W_2,b_2 W1,b1,W2,b2求导,对权重和偏置参数进行求导则是利用 BP反向传播算法,可以得到网络中各个参数的偏导
δ 3 = y ^ − y δ 2 = ( 1 − tanh 2 ( z 1 ) ) × δ 3 W 2 T ∂ L ∂ W 2 = a 1 T δ 3 ∂ L ∂ b 2 = δ 3 ∂ L ∂ W 1 = x T δ 2 ∂ L ∂ b 1 = δ 2 \begin{align*} \boldsymbol{\delta}_3 &= \hat{\boldsymbol{y}} - \boldsymbol{y} \\ \boldsymbol{\delta}_2 &= \left(1 - \tanh^2(\boldsymbol{z}_1)\right) \times \boldsymbol{\delta}_3 \boldsymbol{W}_2^T \\ \frac{\partial L}{\partial \boldsymbol{W}_2} &= \boldsymbol{a}_1^T \boldsymbol{\delta}_3 \\ \frac{\partial L}{\partial \boldsymbol{b}_2} &= \boldsymbol{\delta}_3 \\ \frac{\partial L}{\partial \boldsymbol{W}_1} &= \boldsymbol{x}^T \boldsymbol{\delta}_2 \\ \frac{\partial L}{\partial \boldsymbol{b}_1} &= \boldsymbol{\delta}_2 \end{align*} δ3δ2∂W2∂L∂b2∂L∂W1∂L∂b1∂L=y^−y=(1−tanh2(z1))×δ3W2T=a1Tδ3=δ3=xTδ2=δ2
实现损失函数和预测函数
- model 字典中存储着网络中的权重参数和偏置参数,通过model 获取网络中的参数 w 1 , b 1 , w 2 , b 2 w_1,b_1,w_2,b_2 w1,b1,w2,b2,使用神经网络的前馈公式进行前馈计算。 前馈计算后得到预测的输出值 probs,再用 probs与真实的输出值y来计算损失值。
python
# 人工神经网络实现
# 1 定义参数 input_dim 输入维度 output_dim 输出维度
input_dim, output_dim = 2, 2
epsilon = 0.01 # 梯度下降的学习率
reg_lambda = 0.01 # 正则化强度
# 损失函数
def calculate_loss(model):
num_examples = len(X) # 训练集大小
w1, b1, w2, b2 = model['W1'], model['b1'], model['W2'], model['b2']
# 使用正向传播计算预测值
z1 = X.dot(w1) + b1
a1 = np.tanh(z1)
z2 = a1.dot(w2) + b2
exp_scores = np.exp(z2)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
# 计算损失
data_loss = np.sum(-np.log(probs[range(num_examples), y]))
# 正则化
data_loss += reg_lambda / 2 * (np.sum(np.square(w1)) + np.sum(np.square(w2)))
return 1. / num_examples * data_loss
# 预测函数
def predict(model, x):
w1, b1, w2, b2 = model['W1'], model['b1'], model['W2'], model['b2']
# 正向传播
z1 = x.dot(w1) + b1
a1 = np.tanh(z1)
z2 = a1.dot(w2) + b2
exp_scores = np.exp(z2)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
return np.argmax(probs, axis=1)人工神经网络模型整体函数
- ann_model()函数实现反向传播算法来计算梯度下降。
- 迭代次数为20000次,使用批量梯度下降算法
python
# 人工神经网络模型整体函数
def ann_model(x, y, nn_hdim):
"""
人工神经网络模型函数
:param x:
:param y:
:param nn_hdim: 隐层的神经元节点(隐层的数目)
:return:
"""
num_indim = len(x) # 输入维度
model = {} # 模型参数
# 随机初始化网络中的权重参数w1、w2和偏置b1、b2
np.random.seed(0)
w1 = np.random.randn(input_dim, nn_hdim) / np.sqrt(input_dim)
b1 = np.zeros((1, nn_hdim))
w2 = np.random.randn(nn_hdim, output_dim) / np.sqrt(nn_hdim)
b2 = np.zeros((1, output_dim))
# 批量梯度下降算法 BSGD
num_passes = 20000 # 迭代次数
for i in xrange(0, num_passes):
z1 = x.dot(w1) + b1
a1 = np.tanh(z1)
z2 = a1.dot(w2) + b2
exp_scores = np.exp(z2)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
# 向后传播算法
delta3 = probs # 获取预测值
delta3[range(len(x)), y] -= 1 # 预测值减去真实值
delta2 = delta3.dot(w2.T) * (1 - np.power(a1, 2))
dW2 = a1.T.dot(delta3) # w2的倒数
db2 = np.sum(delta3, axis=0, keepdims=True) # b2的倒数
dW1 = np.dot(x.T, delta2) # w1的倒数
db1 = np.sum(delta2, axis=0) # b1的倒数
# 添加正则项
dW1 += reg_lambda * w1
dW2 += reg_lambda * w2
# 根据梯度下降算法更新权重
w1 += -epsilon * dW1 # epsilon
w2 += -epsilon * dW2
b1 += -epsilon * db1
b2 += -epsilon * db2
# 把新的参数写入model 字典中进行记录
model = {'W1': w1, 'b1': b1, 'W2': w2, 'b2': b2}
if i % 1000 == 0:
print("迭代次数:{},损失函数:{}".format(i, calculate_loss(model)))
return model隐层节点数效果对比
- 研究不同的隐层节点数(隐层中神经元的数量)对ANN模型的影响。使用 l i s t list list来记录被测试的不同隐层节点数,分别是 1 , 2 , 3 , 4 , 5 , 15 , 30 , 50 1, 2, 3, 4, 5, 15, 30, 50 1,2,3,4,5,15,30,50,然后使用 f o r for for来迭代 P y t h o n Python Python的 e n u m e r a t e enumerate enumerate对象
python
# 定义输出图像的大小
plt.figure(figsize=(32, 16))
# 待输入的隐层节点数list
hidden_layer_dimensions = [1, 2, 3, 4, 30, 50]
for i, nn_hdim in enumerate(hidden_layer_dimensions):
plt.subplot(2, 3, i + 1)
plt.title('Hidden Layer size %d' % nn_hdim)
model = ann_model(X, y, nn_hdim) # 建立 nn_hdim 个神经元的隐层
plot_decision_boundary(lambda x: predict(model, x), X, y) # 输出 ANN 模型分类结果
plt.show()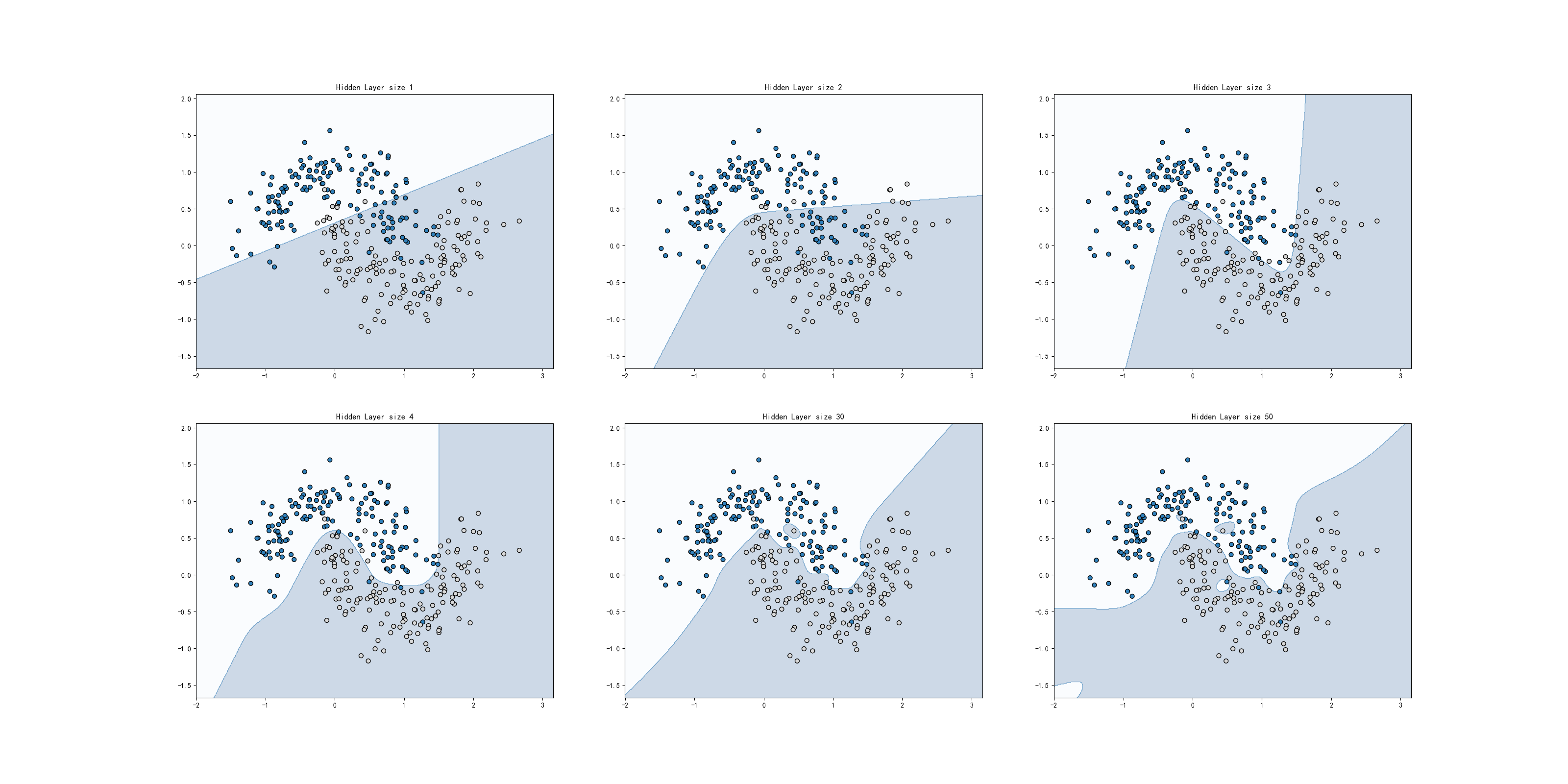
- 结果:隐层数在低维(3, 4,5)时能够很好地表达数据的分类属性。随着隐层中节点数的增加,过度拟合的可能性越高(如隐层数为 50)。
结论
- 神经网络并不非隐层数越多或者隐层节点越多效果越好。因此在实际工程中,要重视训练结果和效果可视化。