继CIFAR-10图像分类:【Res残差连接学习】结合CIFAR-10任务学习-CSDN博客 再优化
本次训练结果在测试集上的准确率表现可达到90%以上
1.训练模型(MyModel.py)
python
import torch
import torch.nn as nn
class SENet(nn.Module): # SE-Net模块
def __init__(self, channel, reduction=16): # 默认r为16
super(SENet, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1) # 平均池化层,输出大小1*1
self.fc = nn.Sequential(
nn.Linear(channel * 2, channel // reduction), # 输入通道数加倍
nn.ReLU(),
nn.Linear(channel // reduction, channel),
nn.Sigmoid(), # 将通道权重输出为0-1
)
def forward(self, x, previous_features=None):
b, c, _, _ = x.size()
y_current = self.avg_pool(x).view(b, c) # 当前层的全局平均池化
# 将当前特征向量与之前特征向量拼接
if previous_features is not None:
y_previous = self.avg_pool(previous_features).view(b, c) # 之前特征的全局平均池化
y = torch.cat([y_current, y_previous], dim=1) # 拼接
else:
y = y_current # 如果没有之前的特征,只使用当前特征
y = self.fc(y).view(b, c, 1, 1) # 计算通道权重
return x * y.expand_as(x) # 对应元素进行逐一相乘
class BasicRes(nn.Module):
def __init__(self, in_cha, out_cha, stride=1, res=True):
super(BasicRes, self).__init__()
self.conv01 = nn.Sequential(
nn.Conv2d(in_channels=in_cha, out_channels=out_cha, kernel_size=3, stride=stride, padding=1),
nn.BatchNorm2d(out_cha),
nn.ReLU(),
)
self.conv02 = nn.Sequential(
nn.Conv2d(in_channels=out_cha, out_channels=out_cha, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(out_cha),
)
self.se = SENet(out_cha)
if res:
self.res = res
if in_cha != out_cha or stride != 1: # 若x和f(x)维度不匹配:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels=in_cha, out_channels=out_cha, kernel_size=1, stride=stride),
nn.BatchNorm2d(out_cha),
)
else:
self.shortcut = nn.Sequential()
def forward(self, x):
residual = x
x = self.conv01(x)
features = x
x = self.conv02(x)
x = self.se(x=x, previous_features=features) # 传递前层的特征图
if self.res:
x += self.shortcut(residual)
return x
# 2.训练模型
class cifar10(nn.Module):
def __init__(self):
super(cifar10, self).__init__()
# 初始维度3*32*32
self.Stem = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(64),
nn.ReLU(),
)
self.layer01 = BasicRes(in_cha=64, out_cha=64)
self.layer02 = BasicRes(in_cha=64, out_cha=64)
self.layer11 = BasicRes(in_cha=64, out_cha=128)
self.layer12 = BasicRes(in_cha=128, out_cha=128)
self.layer21 = BasicRes(in_cha=128, out_cha=256)
self.layer22 = BasicRes(in_cha=256, out_cha=256)
self.layer31 = BasicRes(in_cha=256, out_cha=512)
self.layer32 = BasicRes(in_cha=512, out_cha=512)
self.pool_max = nn.MaxPool2d(2)
self.pool_avg = nn.AdaptiveAvgPool2d((1, 1)) # b*c*1*1
self.fc = nn.Sequential(
nn.Dropout(0.4),
nn.Linear(512, 128),
nn.ReLU(),
nn.Linear(128, 10),
)
def forward(self, x):
x = self.Stem(x)
x = self.layer01(x)
x = self.layer02(x)
x = self.pool_max(x)
x = self.layer11(x)
x = self.layer12(x)
x = self.pool_max(x)
x = self.layer21(x)
x = self.layer22(x)
x = self.pool_max(x)
x = self.layer31(x)
x = self.layer32(x)
x = self.pool_max(x)
x = self.pool_avg(x).view(x.size()[0], -1)
x = self.fc(x)
return x本训练模型结合了 SE 模块和残差学习思想,并且适当修改了SE模块的输入层以更好地捕捉图像中重要的特征。
SENet类:Squeeze-and-Excitation(SE)模块,通过全局平均池化来获取特征图的全局信息,然后通过一系列全连接层生成一个通道权重向量,这部分适当修改了SE模块的输入层可做参考;
BasicRes类:基本残差块实现了一个带有 SE 模块的残差连接,使用两个卷积层用于提取特征,第二个卷积层的输出与第一层特征的输出都传入 SE 模块,用于计算通道权重,从而增强网络对特征的选择性;
cifar10类 (主网络结构):
-
Stem(干茎部分):由卷积层、批归一化层和 ReLU 激活组成,负责特征的初步提取,输入是大小为 3x32x32 的图像,输出是 64 个通道。
-
多个 BasicRes 块:这些块逐层堆叠形成一个深度网络,具体分为三组:第一组:两个BasicRes块(64 通道),后接最大池化层;第二组:两个 BasicRes 块(128 通道),后接最大池化层;第三组:两个 BasicRes 块(256 通道),后接最大池化层;第四组:两个 BasicRes 块(512 通道),后接最大池化层。
-
全局平均池化和全连接层:最后的特征图经过 Adaptive Avg Pooling 调整为 1x1 的大小,然后展平为一维向量,送入全连接层进行最终分类。
2.训练函数
python
import torch
import torchvision.datasets as dataset
import torchvision.transforms as transforms
import torch.nn as nn
from torch.utils.data import DataLoader, random_split
import matplotlib.pyplot as plt
import time
from MyModel import cifar10
def train_val(train_loader, val_loader, device, model, loss, optimizer, epochs, save_path, scheduler): # 正式训练函数
model = model.to(device)
plt_train_loss = [] # 训练过程loss值,存储每轮训练的均值
plt_train_acc = [] # 训练过程acc值
plt_val_loss = [] # 验证过程
plt_val_acc = []
max_acc = 0 # 以最大准确率来确定训练过程的最优模型
for epoch in range(epochs): # 开始训练
train_loss = 0.0
train_acc = 0.0
val_acc = 0.0
val_loss = 0.0
start_time = time.time()
model.train()
for index, (images, labels) in enumerate(train_loader):
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad() # 梯度置0
pred = model(images)
bat_loss = loss(pred, labels) # CrossEntropyLoss会对输入进行一次softmax
bat_loss.backward() # 回传梯度
optimizer.step() # 更新模型参数
train_loss += bat_loss.item()
# 注意此时的pred结果为64*10的张量
pred = pred.argmax(dim=1)
train_acc += (pred == labels).sum().item()
print("当前为第{}轮训练,批次为{}/{},该批次总loss:{} | 正确acc数量:{}"
.format(epoch+1, index+1, len(train_data)//config["batch_size"],
bat_loss.item(), (pred == labels).sum().item()))
# 计算当前Epoch的训练损失和准确率,并存储到对应列表中:
plt_train_loss.append(train_loss / train_loader.dataset.__len__())
plt_train_acc.append(train_acc / train_loader.dataset.__len__())
model.eval() # 模型调为验证模式
with torch.no_grad(): # 验证过程不需要梯度回传,无需追踪grad
for index, (images, labels) in enumerate(val_loader):
images, labels = images.cuda(), labels.cuda()
pred = model(images)
bat_loss = loss(pred, labels) # 算交叉熵loss
val_loss += bat_loss.item()
pred = pred.argmax(dim=1)
val_acc += (pred == labels).sum().item()
print("当前为第{}轮验证,批次为{}/{},该批次总loss:{} | 正确acc数量:{}"
.format(epoch+1, index+1, len(val_data)//config["batch_size"],
bat_loss.item(), (pred == labels).sum().item()))
val_acc = val_acc / val_loader.dataset.__len__()
if val_acc > max_acc:
max_acc = val_acc
torch.save(model, save_path)
plt_val_loss.append(val_loss / val_loader.dataset.__len__())
plt_val_acc.append(val_acc)
print('该轮训练结束,训练结果如下[%03d/%03d] %2.2fsec(s) TrainAcc:%3.6f TrainLoss:%3.6f | valAcc:%3.6f valLoss:%3.6f \n\n'
% (epoch+1, epochs, time.time()-start_time, plt_train_acc[-1], plt_train_loss[-1], plt_val_acc[-1], plt_val_loss[-1]))
scheduler.step() # 更新学习率
print(f'训练结束,最佳模型的准确率为{max_acc}')
plt.plot(plt_train_loss) # 画图
plt.plot(plt_val_loss)
plt.title('loss')
plt.legend(['train', 'val'])
plt.show()
plt.plot(plt_train_acc)
plt.plot(plt_val_acc)
plt.title('Accuracy')
plt.legend(['train', 'val'])
# plt.savefig('./acc.png')
plt.show()将真正的训练过程封装为上述函数。
训练模式中使用"训练模型"获取预估值,根据loss和梯度回传不断优化模型内参数,且保存训练过程的loss值。
验证模式无需梯度回传,设置为验证模式以保证模型验证过程的数据完整性,记录验证过程的模型loss值。
最后将整个训练过程和验证过程的loss值和acc值进行可视化展现。
3.训练过程
python
total_start = time.time()
# 1.数据预处理
transform = transforms.Compose([
transforms.RandomHorizontalFlip(), # 以 50% 的概率随机翻转输入的图像,增强模型的泛化能力
transforms.RandomCrop(size=(32, 32), padding=4), # 随机裁剪
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 对图像张量进行归一化
]) # 数据增强
ori_data = dataset.CIFAR10(
root="./Data_CIFAR10",
train=True,
transform=transform,
download=True
)
print(f"各标签的真实含义:{ori_data.class_to_idx}\n")
# print(len(ori_data))
# # 查看某一样本数据
# image, label = ori_data[0]
# print(f"Image shape: {image.shape}, Label: {label}")
# image = image.permute(1, 2, 0).numpy()
# plt.imshow(image)
# plt.title(f'Label: {label}')
# plt.show()
config = {
"train_size_perc": 0.8,
"batch_size": 64,
"learning_rate": 0.001,
"epochs": 60,
"lr_decay_step": 20,
"lr_decay_gamma": 0.2, # 衰减系数
"save_path": "model_save/NewSe60_0.2_model.pth"
}
# 设置训练集和验证集的比例
train_size = int(config["train_size_perc"] * len(ori_data)) # 80%用于训练
val_size = len(ori_data) - train_size # 20%用于验证
train_data, val_data = random_split(ori_data, [train_size, val_size])
# print(len(train_data))
# print(len(val_data))
train_loader = DataLoader(dataset=train_data, batch_size=config["batch_size"], shuffle=True)
val_loader = DataLoader(dataset=val_data, batch_size=config["batch_size"], shuffle=False)
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"{device}\n")
model = cifar10()
# model = torch.load(config["save_path"]).to(device)
print(f"我的模型框架如下:\n{model}")
loss = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = torch.optim.AdamW(model.parameters(), lr=config["learning_rate"], weight_decay=1e-3) # L2正则化
# optimizer = torch.optim.Adam(model.parameters(), lr=config["learning_rate"]) # 优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=config["lr_decay_step"], gamma=config["lr_decay_gamma"]) # 创建学习率调度器
train_val(train_loader, val_loader, device, model, loss, optimizer, config["epochs"], config["save_path"], scheduler)
print(f"\n本次训练总耗时为:{(time.time()-total_start) / 60 }min")整个训练过程如上。
数据预处理部分 :通过 随机水平翻转、随机裁剪、归一化 实现数据增强;
**学习率衰减与优化器选择:**使用(AdamW)来更新模型参数减小损失,期间引入L2正则化(weight_decay=1e-3可自行调整);使用 StepLR 学习率调度器,每过一定的训练步数(step_size=20),学习率会下降一个特定的比例(gamma=0.2),有助于动态调整学习率,以提高模型的收敛速度和性能。
4.测试文件
python
import torch
import torchvision.datasets as dataset
import torchvision.transforms as transforms
import torch.nn as nn
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import time
from MyModel import BasicRes, cifar10
total_start = time.time()
# 测试函数
def test(save_path, test_loader, device, loss): # 测试函数
best_model = torch.load(save_path).to(device)
test_loss = 0.0
test_acc = 0.0
start_time = time.time()
with torch.no_grad():
for index, (images, labels) in enumerate(test_loader):
images, labels = images.cuda(), labels.cuda()
pred = best_model(images)
bat_loss = loss(pred, labels) # 算交叉熵loss
test_loss += bat_loss.item()
pred = pred.argmax(dim=1)
test_acc += (pred == labels).sum().item()
print("正在最终测试:批次为{}/{},该批次总loss:{} | 正确acc数量:{}"
.format(index + 1, len(test_data) // config["batch_size"],
bat_loss.item(), (pred == labels).sum().item()))
print('最终测试结束,测试结果如下:%2.2fsec(s) TestAcc:%.2f%% TestLoss:%.2f \n\n'
% (time.time() - start_time, test_acc/test_loader.dataset.__len__()*100, test_loss/test_loader.dataset.__len__()))
# 1.数据预处理
transform = transforms.Compose([
transforms.RandomHorizontalFlip(), # 以 50% 的概率随机翻转输入的图像,增强模型的泛化能力
transforms.RandomCrop(size=(32, 32), padding=4), # 随机裁剪
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 对图像张量进行归一化
]) # 数据增强
test_data = dataset.CIFAR10(
root="./Data_CIFAR10",
train=False,
transform=transform,
download=True
)
# print(len(test_data)) # torch.Size([3, 32, 32])
config = {
"batch_size": 64,
"save_path": "model_save/NewSe60_0.2_model.pth"
}
test_loader = DataLoader(dataset=test_data, batch_size=config["batch_size"], shuffle=True)
loss = nn.CrossEntropyLoss() # 交叉熵损失函数
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"{device}\n")
test(config["save_path"], test_loader, device, loss)
print(f"\n本次训练总耗时为:{time.time()-total_start}sec(s)")通过训练过程保存的最优loss结果模型,对测试数据进行检测模型表现,测试过程无需梯度回传。
5.结果展示
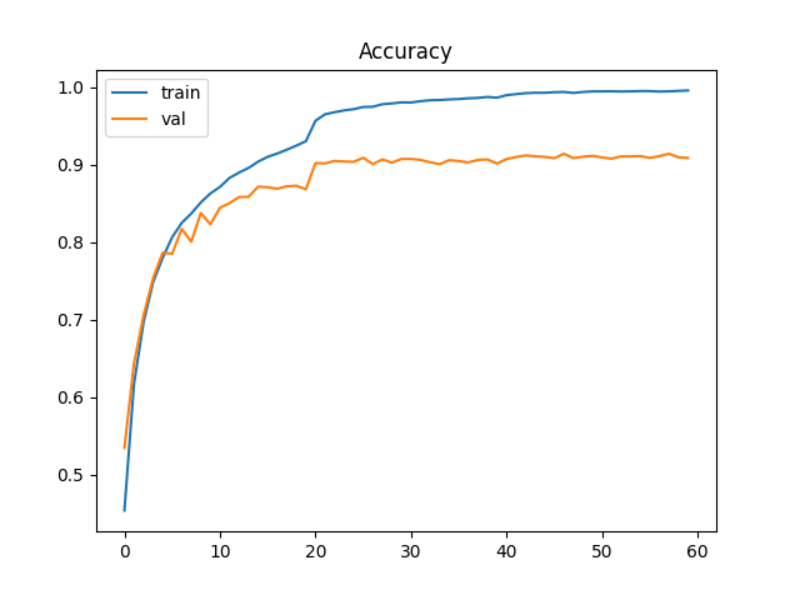
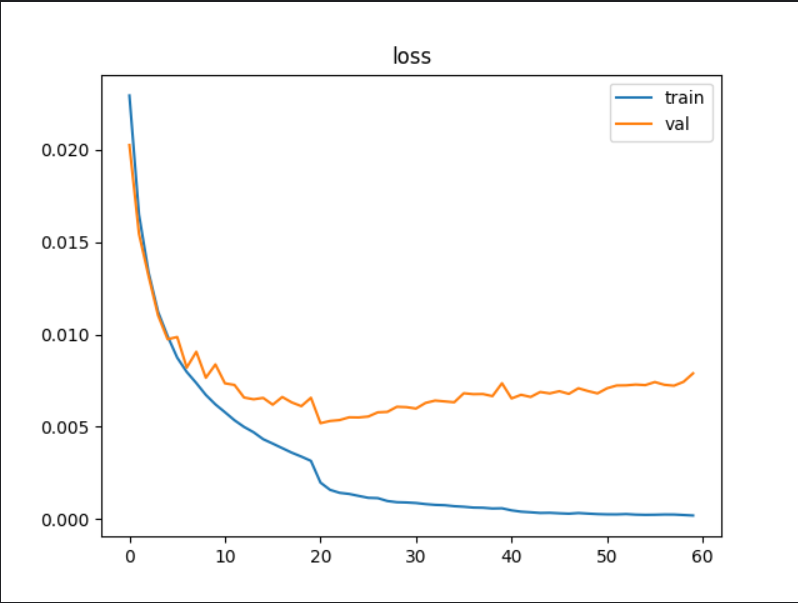
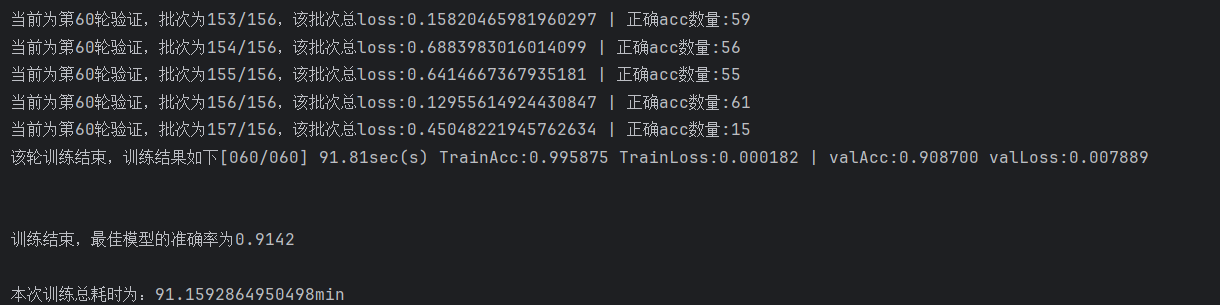
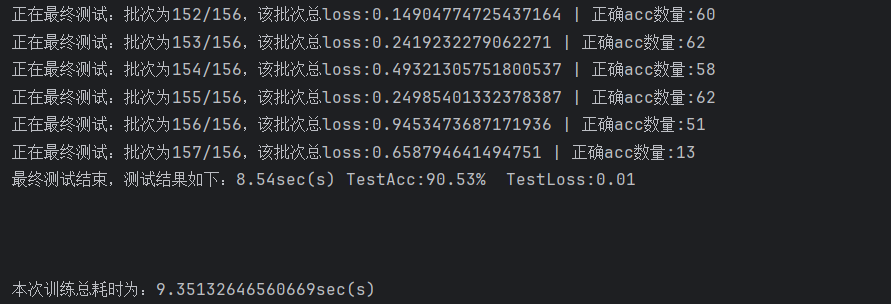
最优模型在验证集上的准确率为91.42%,在测试集上准确率表现有90.53%。