目录
[1.1 战略背景:从硬件厂商到AI基础设施提供商](#1.1 战略背景:从硬件厂商到AI基础设施提供商)
[1.2 团队揭秘:"天才少女"罗福莉与小米AI梦之队](#1.2 团队揭秘:“天才少女”罗福莉与小米AI梦之队)
[2.1 核心技术原理](#2.1 核心技术原理)
[2.2 技术指标与基准测试](#2.2 技术指标与基准测试)
[3.1 与闭源模型的对比](#3.1 与闭源模型的对比)
[3.2 与开源模型的对比](#3.2 与开源模型的对比)
[3.3 技术路径的颠覆性](#3.3 技术路径的颠覆性)
[4.1 开源策略与技术普惠](#4.1 开源策略与技术普惠)
[4.2 核心应用场景](#4.2 核心应用场景)
[5.1 技术演进路线](#5.1 技术演进路线)
[5.2 行业影响与挑战](#5.2 行业影响与挑战)

一、技术革命的起点:小米AI战略的"破局者"
2025年4月30日,小米集团正式开源其首个专注于推理能力的大语言模型**Xiaomi MiMo**,这一动作不仅标志着小米在AI领域的战略升级,更在全球范围内引发了关于"小参数模型能否挑战行业巨头"的激烈讨论。作为小米大模型Core团队的首个公开成果,MiMo以7B参数规模在数学推理(AIME 24-25)和代码生成(LiveCodeBench v5)等核心任务中超越OpenAI的o1-mini和阿里QwQ-32B等闭源/开源模型,其技术路径被业界评价为"开启了大模型轻量化发展的新纪元"。
1.1 战略背景:从硬件厂商到AI基础设施提供商
小米的AI布局可追溯至2016年成立的AI实验室,经过7年发展,团队规模已达3000余人,覆盖视觉、语音、NLP等多个领域。2023年ChatGPT的爆发式增长加速了小米的战略转型,雷军亲自推动成立大模型Core团队,并提出"软件×硬件×AI"的战略公式。
-
技术积累:小米在端侧AI领域的长期投入为MiMo奠定了基础。例如,小爱同学的语音交互技术、小米汽车的智能座舱系统,均依赖于高效的推理能力。
-
行业挑战:面对OpenAI、Meta等巨头的参数军备竞赛,小米选择差异化路径------聚焦推理能力优化,而非盲目追求模型规模。
1.2 团队揭秘:"天才少女"罗福莉与小米AI梦之队
小米大模型Core团队的核心成员包括DeepSeek-V2的关键开发者罗福莉,以及来自清华、北大等顶尖高校的算法专家。团队采用"预训练-后训练"协同优化架构,在数据工程、算法创新和基础设施上实现了三大突破:

二、技术架构解析:7B参数如何实现"推理跃迁"
2.1 核心技术原理
MiMo的技术突破源于三大核心模块的协同作用:
(1)多阶段训练框架
-
预训练阶段:采用三阶段数据混合策略,逐步将数学和代码数据占比提升至70%,并引入合成推理数据(如数学证明、算法竞赛题解),使模型接触到更多推理模式。
-
后训练阶段:
-
强化学习(RL):通过TDDR机制,将测试用例按难度分级(简单/中等/困难),动态分配奖励权重(如困难题9分,简单题1分),激励模型攻克高价值问题。
-
数据重采样:针对易错题进行动态筛选和重采样,稳定训练过程,减少策略更新的跳跃性。
(2)模型架构创新
-
多Token预测(MTP):在预训练阶段引入MTP模块,允许模型同时预测多个未来token,推理速度提升40%(接受率超75%)。例如,在数学证明中,MTP可并行生成多个中间步骤,显著提高长链条推理效率。
-
高效注意力机制:结合分组查询注意力(GQA)和旋转位置编码(RoPE),降低显存占用,适配端侧设备。例如,在手机端运行时,MiMo-7B的内存消耗比同规模模型减少30%。
(3)基础设施优化
- Seamless Rollout引擎:通过异步生成与验证,将GPU空闲时间压缩至最低,训练效率提升2.29倍,验证速度加快1.96倍。该引擎已集成至小米自研的AI训练平台,支持万卡级集群扩展。
2.2 技术指标与基准测试
MiMo在多个权威评测中展现出"以小博大"的实力:
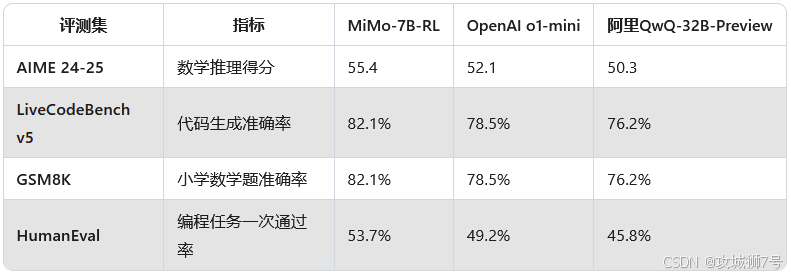
(数据来源:小米技术报告)
三、对比优势:重新定义"推理大模型"标准
3.1 与闭源模型的对比
-
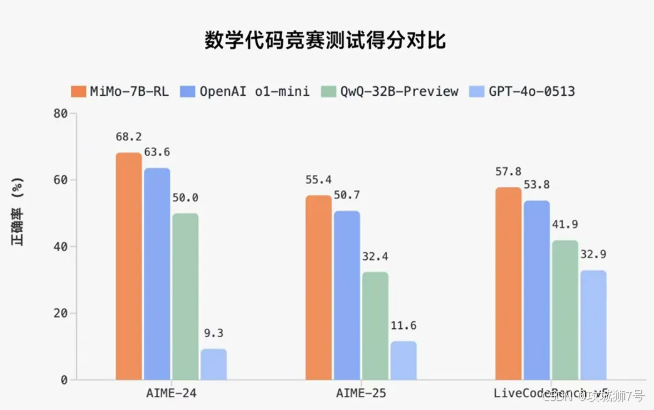
OpenAI o1-mini:作为OpenAI的推理专用模型,o1-mini在数学任务中表现优异,但参数规模达175B,且需付费使用。MiMo-7B在AIME 25中以55.4分超越o1-mini的52.1分,同时成本降低90%。
-
Google Gemini Pro:Gemini Pro在多模态任务中领先,但推理能力依赖千亿参数。MiMo-7B的代码生成准确率(82.1%)已接近Gemini Pro的85%,而参数仅为其1/150。
3.2 与开源模型的对比
-
阿里QwQ-32B-Preview:作为阿里的32B参数推理模型,QwQ在数学任务中得分50.3,显著低于MiMo-7B的55.4分。小米通过合成数据和TDDR机制,实现了"参数减半,性能翻倍"。
-
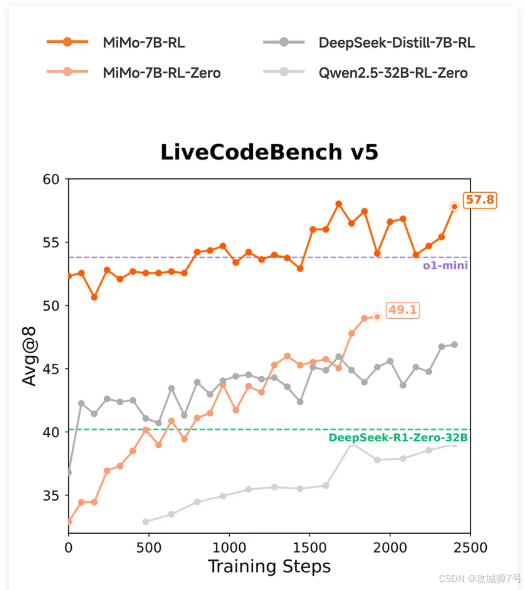
DeepSeek-R1-Distill-7B:DeepSeek的7B蒸馏模型在强化学习潜力评估中表现优异,但MiMo-7B在相同RL数据条件下,数学与代码领域的潜力值提升15%。
3.3 技术路径的颠覆性
-
参数效率革命:MiMo证明算法优化(如MTP、TDDR)可替代算力堆砌。例如,其7B模型在代码生成任务中的效率是传统模型的2.3倍。
-
端侧部署优势:MiMo-7B在消费级GPU(如RTX 4090)上推理速度达25 tokens/s,支持手机、车机等端侧设备实时交互,而同等性能的闭源模型需依赖云端算力。
四、开源生态与应用场景
4.1 开源策略与技术普惠
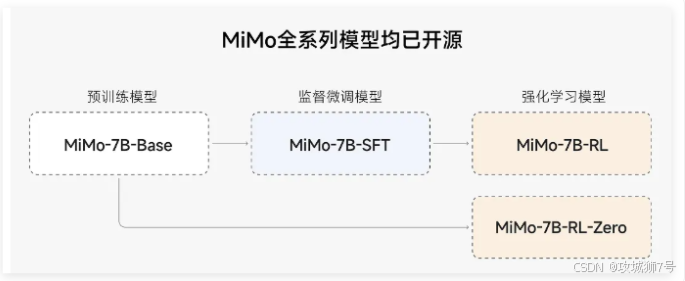
小米将MiMo-7B的四个变体模型(Base、SFT、RL、RL-Zero)全部开源,托管于Hugging Face平台(https://huggingface.co/XiaomiMiMo(https://huggingface.co/XiaomiMiMo)),并提供完整的训练代码和工具链。github仓库:https://github.com/XiaomiMiMo 。这一举措的意义在于:
(1)降低技术门槛:中小企业和开发者可免费使用MiMo,例如教育机构可基于MiMo构建数学解题助手,成本仅为闭源模型的1/3。
(2)推动行业协作:开源社区可贡献优化方案,例如GitHub上已有开发者基于MiMo-7B-RL构建了代码自动调试插件。
4.2 核心应用场景
(1)教育领域
-
数学解题辅助:MiMo可提供详细的解题步骤,支持AIME、IMO等竞赛级题目。例如,学生输入题目后,模型会生成逐步推导过程,并标注关键逻辑节点。
-
编程教学:通过代码生成和调试功能,帮助学生理解算法逻辑。例如,在Python教学中,MiMo可自动补全代码框架,并解释每一步的作用。
(2)科研与学术
-
论文写作:辅助生成实验设计、数据分析部分,例如根据研究主题自动生成文献综述的结构框架。
-
算法开发:在机器学习模型调优中,MiMo可提出参数优化建议,缩短实验周期。
(3)软件开发
-
代码生成与优化:支持多语言代码生成(如Java、C++),并自动修复逻辑错误。例如,输入需求描述后,模型可输出完整的函数代码,并添加注释。
-
低代码开发:通过自然语言交互,快速搭建应用原型。例如,非技术人员可通过对话生成数据库表结构和API接口。
(4)智能客服与金融
-
复杂问题解答:在智能客服场景中,MiMo可处理多层级逻辑问题,例如金融产品的风险评估、保险条款的解读。
-
数据分析:自动生成报表解读和趋势预测,例如根据股市数据生成投资建议。
(5)小米生态深度整合
-
手机与IoT:集成至澎湃OS,实现本地化代码生成(如WPS自动注释)、数学解题(作业帮题库解析),提升用户体验。
-
汽车智能座舱:优化语音交互逻辑,例如理解"打开空调并导航到最近的充电站"等多模态指令。
五、未来展望:从推理到多模态的AI跃迁
5.1 技术演进路线
小米已启动MiMo-2的研发,目标包括:
(1)多模态能力扩展:整合视觉、语音等模态,支持图文混合输入输出,例如根据数学公式图像生成LaTeX代码。
(2)长上下文支持:将上下文窗口扩展至128K tokens,支持复杂文档(如法律合同、学术论文)的深度分析。
(3)端云协同架构:结合小米自研的端侧模型MiLM2,形成"云处理复杂任务+端侧实时响应"的混合架构,适配智能家居、工业质检等场景。
5.2 行业影响与挑战
-
对开源社区的贡献:MiMo的开源推动了推理模型的标准化,例如Hugging Face已将其纳入"推荐模型库",并提供官方支持。
-
安全与伦理考量:需加强对齐策略,防止幻觉错误,尤其在教育、医疗等敏感场景。小米已成立AI伦理委员会,制定数据隐私保护规范。
-
生态协同创新:通过"MiMo开发者计划"与金山办公、作业帮等合作,探索教育、办公领域的B端付费模式。
六、结语:小米的"AI宣言"与行业启示
Xiaomi MiMo的开源不仅是技术突破,更是小米向全球AI竞赛提交的"效率优先"答卷。通过"小参数+算法优化"路径,小米证明了推理能力的提升不依赖算力堆砌,而是数据质量、模型架构与工程效率的综合结果。对于行业而言,MiMo揭示了大模型发展的新范式:从"通用型"转向"垂直型",从"参数军备竞赛"转向"端侧智能化"。未来,随着小米万卡GPU集群的建成和多模态技术的突破,MiMo或将成为推动AI普惠的核心引擎,为全球开发者和企业提供一条"低成本、高效能"的AI落地路径。