文章目录
- Redis最新入门教程
-
- 1.安装Redis
- 2.连接Redis
- 3.Redis环境变量配置
- 4.入门Redis
-
- [4.1 Redis的数据结构](#4.1 Redis的数据结构)
- [4.2 Redis的Key](#4.2 Redis的Key)
- [4.3 Redis-String](#4.3 Redis-String)
- [4.4 Redis-Hash](#4.4 Redis-Hash)
- [4.5 Redis-List](#4.5 Redis-List)
- [4.6 Redis-Set](#4.6 Redis-Set)
- [4.7 Redis-Zset](#4.7 Redis-Zset)
- 5.在Java中使用Redis
- 6.缓存雪崩、击穿、穿透
-
- [6.1 缓存雪崩](#6.1 缓存雪崩)
- [6.2 缓冲击穿](#6.2 缓冲击穿)
- [6.3 缓冲穿透](#6.3 缓冲穿透)
- [6.4 业务可靠性处理](#6.4 业务可靠性处理)
- 参考
Redis最新入门教程
Redis 是互联网技术领域中使用最广泛的存储中间件,它是 Re mote Di ctionary S ervice 三个单词中加粗字母的组合。它是一个存储在磁盘上的内存数据库。数据模型是键-值对,但支持许多不同类型的值:Strings, Lists, Sets, Sorted Sets, Hashes。
1.安装Redis
Redis 官方不建议在 windows 下使用 Redis,所以官网没有 Windows 版本可以下载。但是官方给出了一个在 Windows 下使用Redis的方法:Install Redis on Windows,具体操作就是安装 WSL,然后在电脑上运行 Ubuntu,大家也可以尝试。
对于我们本地开发与学习,下载非官方的 Windows 版本就可以。这里推荐两个 Windows 版本的 Redis 仓库:
- 微软的开源 Windows版本 --> 这个项目已经不再被维护了,最高版本为 3.2.100。
- redis-windows 项目 --> 借助 GitHub Actions 强大的自动化构建能力,实时编译最新版本的 Redis for Windows 系统。版本和官方保持一致,推荐👍
note:建议使用 Windows 版本进行本地开发,并按照 Redis 官方指导将其部署在 Linux 上用于生产环境。
安装流程:
-
-
解压,直接运行项目中的
start.bat脚本,一键启动。或者使用命令行启动redis-server.exe redis.conf。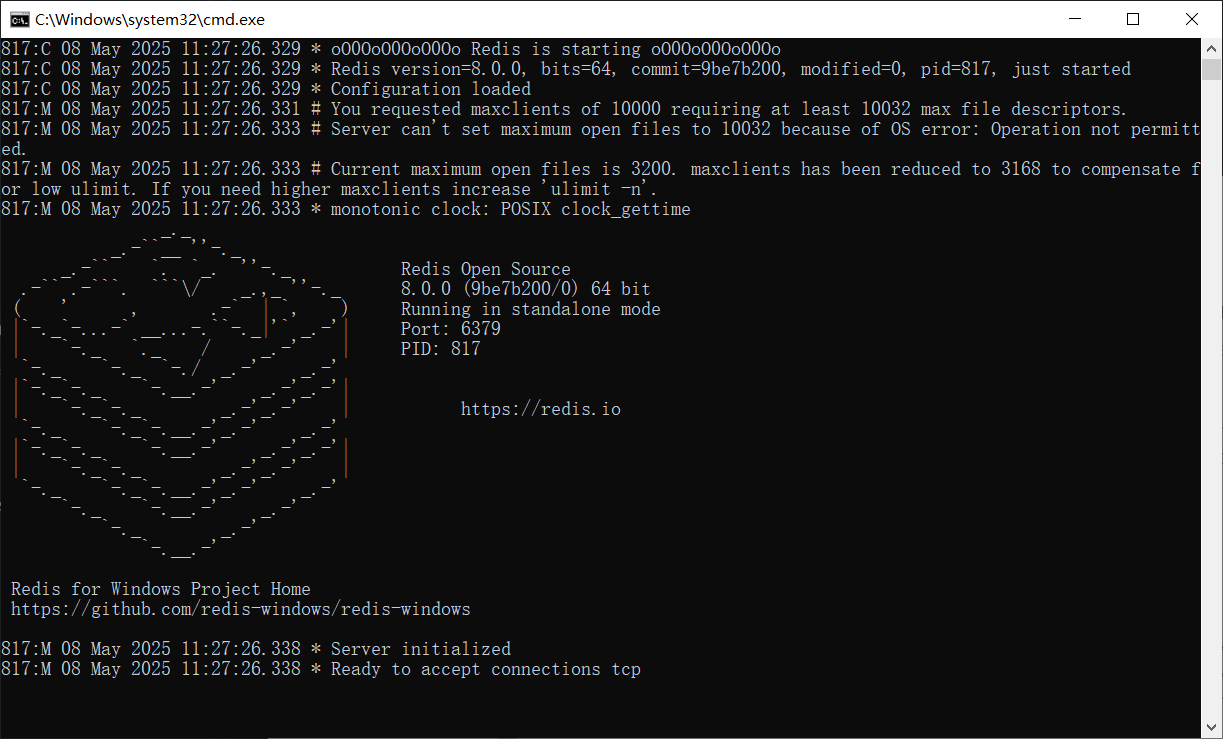
note:使用 Redis 时,这个窗口不可以关闭。若想要停止 Redis 服务,直接关闭窗口。
2.连接Redis
Redis 本身就自带了一个命令行客户端,可以直接通过 redis-cli 命令来连接 Redis 服务。如下所示,表明连接成功:

这里推荐两款好用的 Redis 图形化客户端,大家可以根据自己喜好下载:
- AnotherRedisDesktopManager,github 已经有 32k+ 的 star 了。
- Redis Insight,官方 Redis 数据库工具。
由于我个人喜欢使用官方版本,所以接下来介绍一下 Redis Insight 的安装:进入官网 Redis Insight 下载安装包,然后一直下一步即可安装成功。第一次打开勾选上 I have read and understood the Terms 点击 Submit 就好,其他选项(主要是隐私设置以及通知设置)不用勾选。这样就可以开始使用 Redis Insight了。
3.Redis环境变量配置
每次连接 Redis 都必须到解压后的目录,才可以输入启动命令。所以通过配置环境变量,解决这一问题。
-
复制 Redis 的地址。
Example: D:\Redis\Redis-8.0.0-Windows-x64-cygwin
-
「环境变量」->「系统变量」->「path」->「编辑」->「新建」,粘贴 Redis 路径。
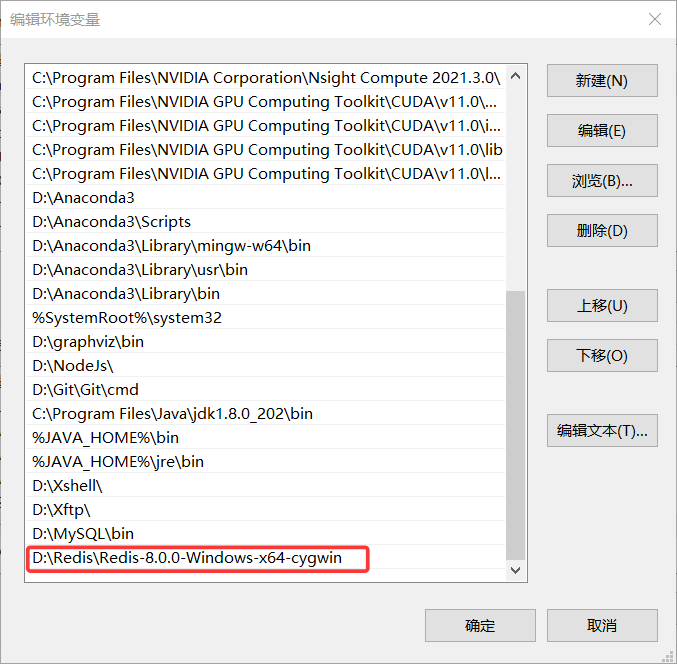
这样在任何位置,打开 cmd 就可以输入 Redis 的命令了。
-
启动 Redis:
shellredis-server -
连接 Redis:
shellredis-cli
4.入门Redis
4.1 Redis的数据结构
Redis 有 5 种基础数据结构,String、Hash、List、Set、SortedSet。除此之外,还有 HyperLogLog、Geo、Pub/Sub 等高级数据结构。
- string(字符串): 基本的数据存储单元,可以存储字符串、整数或者浮点数。
- hash(哈希):一个键值对集合,可以存储多个字段。
- list(列表):一个简单的列表,可以存储一系列的字符串元素。
- set(集合):一个无序集合,可以存储不重复的字符串元素。
- zset(sorted set:有序集合): 类似于集合,但是每个元素都有一个分数(score)与之关联。
- 位图(Bitmaps):位数组,可以对字符串进行位操作。常用于实现布隆过滤器等位操作。
- 超日志(HyperLogLogs):用于基数统计,可以估算集合中的唯一元素数量。
- 地理空间(Geospatial):用于存储地理位置信息,支持地理空间索引和半径查询。
- 发布/订阅(Pub/Sub):一种消息通信模式,允许客户端订阅消息通道,并接收发布到该通道的消息。
- 流(Streams):用于消息队列和日志存储,支持消息的持久化和时间排序。
- 模块(Modules):Redis 支持动态加载模块,可以扩展 Redis 的功能。
4.2 Redis的Key
Redis 键命令用于管理 redis 的键。Redis 键命令的基本语法如下:
shell
COMMAND KEY_NAME
shell
127.0.0.1:6379> set name redis
OK
127.0.0.1:6379> del name
(integer) 1
- del 命令用来删除一个键值对,
(integer) 1表示执行成功,(integer) 0表示执行失败。- exists 命令用来测试一个键值对是否存在,
(integer) 1表示存在,(integer) 0表示不存在。
4.3 Redis-String
String 类型是 Redis 最基本的数据类型,string 类型的值最大能存储 512MB。
常用命令:
SET key value:设置键的值。GET key:获取键的值。INCR key:将键的值加 1。DECR key:将键的值减 1。APPEND key value:将值追加到键的值之后。
shell
127.0.0.1:6379> set name1 xiaoming
OK
127.0.0.1:6379> get name1
"xiaoming"4.4 Redis-Hash
Hash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象。每个 hash 最多可以存储 2 32 − 1 2^{32}-1 232−1 个键值对。
常用命令:
HSET key field value:设置哈希表中字段的值。HGET key field:获取哈希表中字段的值。HGETALL key:获取哈希表中所有字段和值。HDEL key field:删除哈希表中的一个或多个字段。
shell
127.0.0.1:6379> hset student id 1 name "zhangsan" gender "男"
(integer) 3
127.0.0.1:6379> hgetall student
1) "id"
2) "1"
3) "name"
4) "zhangsan"
5) "gender"
6) "\xe7\x94\xb7"
127.0.0.1:6379> hget student name
"zhangsan"
127.0.0.1:6379> hget student id
"1"4.5 Redis-List
List 是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。列表最多可以存储 2 32 − 1 2^{32}-1 232−1 个元素。
常用命令:
LPUSH key value:将值插入到列表头部。RPUSH key value:将值插入到列表尾部。LPOP key:移出并获取列表的第一个元素。RPOP key:移出并获取列表的最后一个元素。LRANGE key start stop:获取列表在指定范围内的元素。
shell
127.0.0.1:6379> lpush order first second
(integer) 2
127.0.0.1:6379> lrange order 0 1
1) "second"
2) "first"
127.0.0.1:6379> lpush order third
(integer) 3
127.0.0.1:6379> lrange order 0 3
1) "third"
2) "second"
3) "first"
127.0.0.1:6379> lrange order 0 2
1) "third"
2) "second"
3) "first"
127.0.0.1:6379> lrange order 0 1
1) "third"
2) "second"4.6 Redis-Set
Set 是 string 类型的无序集合。集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。集合中最大的成员数为 2 32 − 1 2^{32}-1 232−1。
常用命令:
SADD key value:向集合添加一个或多个成员。SREM key value:移除集合中的一个或多个成员。SMEMBERS key:返回集合中的所有成员。SISMEMBER key value:判断值是否是集合的成员。
shell
127.0.0.1:6379> sadd color red yellow blue
(integer) 3
127.0.0.1:6379> smembers color
1) "red"
2) "yellow"
3) "blue"
127.0.0.1:6379> srem color red
(integer) 1
127.0.0.1:6379> smembers color
1) "yellow"
2) "blue4.7 Redis-Zset
zset 和 set 一样也是 string 类型元素的集合,且不允许重复的成员。不同的是每个元素都会关联一个 double 类型的分数。redis 正是通过分数来为集合中的成员进行从小到大的排序 。zset 的成员是唯一的,但分数(score)却可以重复。
常用命令:
ZADD key score value:向有序集合添加一个或多个成员,或更新已存在成员的分数。ZRANGE key start stop [WITHSCORES]:返回指定范围内的成员。ZREM key value:移除有序集合中的一个或多个成员。ZSCORE key value:返回有序集合中,成员的分数值。
shell
127.0.0.1:6379> zadd class 100 "one" 90 "two" 100 three
(integer) 3
127.0.0.1:6379> zrange class 0 2
1) "two"
2) "one"
3) "three"
127.0.0.1:6379> zscore class two
"90"5.在Java中使用Redis
-
第一步,在项目中添加 Jedis(Java 和 Redis 的混拼)依赖:
xml<dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>8.0.0</version> </dependency> -
第二步,新建 UserInfo(用户信息)类:
javapackage org.example; public class UserInfo { private String name; private int age; public UserInfo() { } public UserInfo(String name, int age) { this.name = name; this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } @Override public String toString() { return "UserInfo{" + "name='" + name + '\'' + ", age=" + age + '}'; } } -
第三步,在项目中添加 Gson(用于序列化和反序列化用户信息)依赖:
xml<dependency> <groupId>com.google.code.gson</groupId> <artifactId>gson</artifactId> <version>2.8.6</version> <scope>compile</scope> </dependency> -
第四步,新建测试类 RedisTest:
javapublic class RedisTest { // 定义 Redis 中存储用户信息的键 private static final String REDIS_KEY = "user"; public static void main(String[] args) { // 创建 Jedis 实例,连接到本地 Redis 服务器,端口为 6379 Jedis jedis = new Jedis("localhost", 6379); // 创建 Gson 实例,用于 Java 对象和 JSON 字符串之间的转换 Gson gson = new Gson(); // 创建 UserInfo 对象,存储用户信息 UserInfo userInfo = new UserInfo("鱼儿也有烦恼", 18); // 将 UserInfo 对象转换为 JSON 字符串,并存储到 Redis 中 jedis.set(REDIS_KEY, gson.toJson(userInfo)); // 从 Redis 中获取 JSON 字符串,并转换为 UserInfo 对象 UserInfo getUserInfoFromRedis = gson.fromJson(jedis.get(REDIS_KEY), UserInfo.class); // 打印从 Redis 中获取的用户信息 System.out.println("get:" + getUserInfoFromRedis); // 打印指定键是否存在于 Redis 中 System.out.println("exists:" + jedis.exists(REDIS_KEY)); // 删除 Redis 中指定键对应的值,并打印删除的键的数量 System.out.println("del:" + jedis.del(REDIS_KEY)); // 尝试获取已删除键的值,并打印结果 System.out.println("get:" + jedis.get(REDIS_KEY)); } } -
输出结果:
get:UserInfo{name='鱼儿也有烦恼', age=18} exists:true del:1 get:null
6.缓存雪崩、击穿、穿透
6.1 缓存雪崩
概念:即缓存同一时间大面积的失效,这个时候来了一大波请求,都怼到数据库上,最后数据库处理不过来崩了。
业务场景举例:APP首页放着很多热门数据,大型活动期间,首页数据得按不同时间更新。就像零点要换一批新数据,旧数据刚过期,新数据还没完全加载好。偏偏零点又有个小活动启动,一下子来了好多人打开APP,服务器收到海量请求。可新数据没加载完,缓存里大多找不到对应内容,这些请求全跑到数据库那儿去了。数据库应付不过来这么多请求,最后直接瘫痪了。
解决方案:
- 给过期时间加个随机时间。需要注意的是,这里设置的随机过期时间并非短短几秒,而是可以长达数分钟。这是因为当数据量庞大时,再结合上述场景,考虑到Redis采用单线程处理数据的特性,仅仅几秒的缓冲时间,根本无法确保所有新数据都能加载完毕。 因此,在设置过期时间时,宁长勿短。毕竟无论时间长短,数据最终都会过期,从最终效果来看并无差别。而且,适当扩大过期时间范围,能让Redis的key分布得更加分散。这样一来,Redis在批量处理过期key时,阻塞时间也会相应缩短,有效提升系统运行效率。
- 加互斥锁,但这个方案会导致吞吐量明显下降。(上述例子不合适用)
- 热点数据不设置过期。不过期的话,正常业务请求自然就不会打到数据库了。
6.2 缓冲击穿
概念:缓存击穿是指一个热点 key 过期或被删除后,导致线上原本能命中该热点 key 的请求,瞬间大量地打到数据库上,最终导致数据库被击垮。
业务场景举例:出现情况一般是误操作,比如设置错了过期时间、误删除导致的。
解决方案:
- 仔细检查每一处代码细节,确保没有潜在问题。对于热点数据,要明确制定清晰的过期策略:究竟需不需要设置过期时间?如果需要,具体在何时让数据过期?这些都要有明确的规划。
- 线上误操作问题,需加强权限管理,特别是线上权限必须审核,防止误操作。
6.3 缓冲穿透
概念:客户端请求缓存和数据库中不存在的数据,导致所有的请求都打到数据库上。如果请求很多,数据库依旧会挂掉。
业务场景举例:
- 数据库主键 id 都是正数,然后客户端发起了
id = -1的查询。 - 一个查询接口,有一个状态字段 status,其实 0 表示开始、1 表示结束。结果有请求一直发
status=3的请求过来。
解决方案:
- 做好参数校验,对于不合理的参数要及时 return 结束。
- 对于查不到数据的 key,也将其短暂缓存起来。比如 30s。这样能避免大量相同请求瞬间打到数据库上,减轻压力。
- 提供一个能迅速判断请求是否有效的拦截机制,比如布隆过滤器,Redis 本身就具有这个功能。可以利用 Redis 维护所有合法的键(key),当有请求到来时,先通过布隆过滤器检查请求参数中的键是否合法。若不合法,就直接返回响应结果;若合法,再从缓存或者数据库里获取所需数据。
6.4 业务可靠性处理
-
提高 Redis 可用性。
Redis 要么用集群架构,要么用主从 + 哨兵。保证 Redis 的可用性。
光搞主从架构,没加哨兵的话,出问题根本不会自动切换。要是赶上业务高峰期或者搞活动的时候服务器挂了,等系统报警、排查问题、跟团队沟通完,再等运维来修,黄花菜都凉了!
-
减少对缓存的依赖。
对于热点数据,可以考虑加上本地缓存,比如:Guava、Ehcache,更简单点,hashMap、List 等也可以。减少 Redis 压力的同时,还能提高性能,一举两得。
-
业务降级。
从保护下游接口或者数据库的方面来想,在碰到大流量的情况时,搞个限流措施挺有必要的。就算缓存突然崩了,也不至于让下游直接全垮掉。还有,那些能降级的功能就降级。提前把降级开关和降级逻辑写好,到了关键时候,全指望着它们来稳住局面呢。
🤗🤗🤗