仓库已满:https://gitee.com/mrxiao_com/2d_game_6
新仓库:https://gitee.com/mrxiao_com/2d_game_7
回顾并为今天的内容定下基调
我们今天的主要目标是对游戏的调试"Top List"进行改进,也就是用来显示游戏中耗时最多的函数或模块的性能分析列表。昨天我们已经实现了基础版本,但它还缺乏一些关键功能,因此今天专门来完善它。
一开始提到,我们曾讨论过允许可执行文件在运行时自我修补的做法。但这不是我们想要支持的功能,所以我们决定删除这部分逻辑,以免在项目中引起不必要的问题。
接下来转向调试代码的优化:
-
当前的 Top List 在运行时确实能列出执行时间,但有几个问题:
- 输出文本的排版很乱,比如
sprintf的格式并未遵循宽度设置,打印出来的内容不整齐。我们打算手动把数据按列排好。 - 绘制结果没有被限制在一个窗口区域内,导致超出了界限也仍会显示。这违反了应有的 UI 显示规范,后续我们需要加上裁剪逻辑,限制绘制区域。
- 输出文本的排版很乱,比如
最重要的改进需求是"排除子函数耗时"的统计方式:
- 当前展示的函数执行时间包括了子函数的耗时。例如
GameUpdateAndRender显示耗时 2300 万周期,但它内部还调用了许多函数,而这些子函数的执行时间也被包含进来了。 - 这并不能真正帮助我们优化,因为我们无法知道耗时具体发生在哪一段子逻辑中。比如
GameUpdate本身可能只是一个简单的函数,真正耗时的是它调用的下一级代码。
我们希望能:
- 增加"排除子函数"的独占时间(Exclusive Time)统计功能。
- 这样在展示的时候可以明确哪些函数自身真正耗时多,而不是只是因为它们调用了许多其他函数。
- 比如如果函数 A 总耗时 2300 万周期,但其中 2200 万都在子函数中完成的,那么我们希望只显示它自身耗时为 100 万周期。
为实现上述功能,我们计划在调试信息收集阶段(collation phase)中计算每个函数的"独占时间":
- 当前的框架其实已经处在一个合适的位置去做这件事,只是我们还没有实现。
- 所以我们只需要为每个分析节点增加一个额外的 64 位计数器(其实用 32 位也够了,因为没有函数单次会耗时超过 40 亿周期),用于记录独占耗时。
我们后续还想到了一些附加的优化想法,会在完成核心逻辑后进行尝试,这些想法可能会让工具变得更强大。现在的第一步是为每个调试节点增加统计独占时间的能力,从而实现更有效的性能分析。
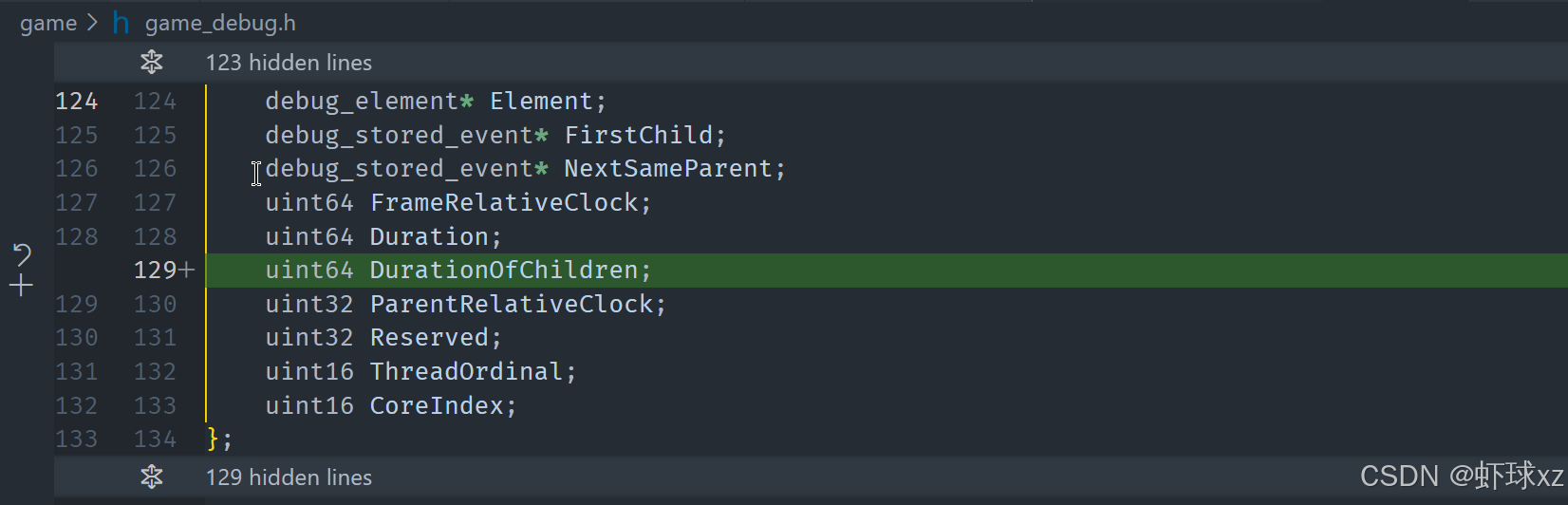
game_debug.h:给 debug_profile_node 添加 Duration 和 DurationOfChildren 字段,用于分离计时信息
为了实现更精准的性能分析,我们决定在创建性能分析节点(profile node)时,增加两个时间统计字段:一个是总耗时(Duration),另一个是子节点总耗时(DurationOfChildren)。这样我们就可以分别统计当前函数本身执行耗时以及其所有子函数的耗时。
具体做法如下:
-
在构建每个性能分析节点时,记录两个数值:
Duration:当前节点的总耗时,包含了自身执行时间和所有子节点的耗时。DurationOfChildren:该节点中所有子节点加起来的耗时。
-
如果需要获取当前函数本身的独占耗时(不包括子函数),只需要用
Duration减去DurationOfChildren即可。这种方式可以非常方便地计算出哪些函数自身最耗时,而不被它调用的函数影响。 -
现在要做的就是在构建每个分析节点时,同时收集
Duration和DurationOfChildren的值,并在后续使用时进行减法得到独占耗时。
当前代码中查看的位置不是我们希望添加逻辑的正确函数,因此需要跳转到负责实际创建性能分析节点的部分,去实现这两个时间字段的计算和记录。
这一改动的最终目标是增强性能分析工具的实用性,让我们能够准确定位代码中真正消耗 CPU 时间的具体函数,而不是被一些高层次的逻辑误导。
game_debug.cpp:计算 DurationOfChildren,让 TopClocksList 排除子节点的时间
为了更精确地分析性能开销,我们在调试分析中对每个 profile 节点(性能分析节点)引入了"子节点耗时"的统计,并对数据的整理流程进行了相应改进。
具体实现细节如下:
-
在初始化每个 profile 节点时 ,除了设置
Duration(总耗时)为 0 之外,我们也将DurationOfChildren(子节点总耗时)初始化为 0。这样我们可以在后续构建数据时,随时往其中累加子节点的耗时。 -
在"闭合"某个代码块时(即从代码块栈中弹出节点) ,我们就知道当前节点执行所耗费的总时间了,这时我们就可以将这个节点的耗时加入它父节点的
DurationOfChildren中。-
具体做法是:
- 找到当前节点的父节点(也就是当前线程的"第一个打开的代码块"的上一个 block)。
- 如果存在父节点,直接将当前节点的
Duration加到父节点的DurationOfChildren中。
-
-
这样做的好处是:
- 在整个整理(Collation)过程中,我们只需在一次遍历中就能构建每个节点的"子节点总耗时"字段。
- 避免后续在生成"Top List"时还要反复遍历子节点进行累加,提高效率,逻辑也更加集中清晰。
-
有了
Duration和DurationOfChildren,我们就可以随时计算"排除子函数的独占耗时":- 即
ExclusiveDuration = Duration - DurationOfChildren。 - 在生成 Top List 时直接使用这个值,可以准确地反映"每个函数自身"的耗时,而不是包含其调用的所有子函数。
- 即
-
最后提到了一点开发上的体验问题,比如自动缩进的体验还不够好(比如删除缩进时不智能),并且对即将到来的暑期编程时间表示期待,希望能集中时间继续优化和改进相关工具与功能。
这一系列改动使得性能分析工具更贴合实际开发需要,能真正帮助我们发现性能瓶颈,定位到具体的耗时函数,而不会被表面的高层函数误导。
「无子节点的计时器」
我们引入了"去除子节点后的时钟耗时(clocks without children)"的概念,这是对性能分析展示方式的重要改进,目的是让我们更清晰地看到每个代码块自身所消耗的时间,而不是包括它所调用的所有子函数。
具体逻辑如下:
-
原先我们展示的时钟耗时(clocks with children),是包括所有子函数在内的总耗时。这对于定位性能瓶颈帮助有限,因为大部分时间可能是其他子调用造成的。
-
为了解决这个问题,我们现在通过如下方式计算"独立耗时":
- 从每个节点的总耗时中,减去它子节点的总耗时(即
Duration - DurationOfChildren),得到该节点自身的耗时。
- 从每个节点的总耗时中,减去它子节点的总耗时(即
-
这样,我们就能准确知道每个代码块本身占用了多少时间,不再被嵌套调用误导。
-
在切换展示方式时,我们可以选择:
- 显示"含子节点"的耗时(clocks with children),用于查看整个调用树结构。
- 或者显示"去除子节点"的独占耗时(clocks without children),用于精准定位哪一段代码最耗费性能。
-
实际效果是,修改计算逻辑后,性能分析界面会立即反映出每个代码块真实的独立性能开销,使我们能立刻看出最该优化的地方。
通过这种方式,我们极大提升了性能分析工具的实用性,使其更符合我们实际的调试和优化需求。
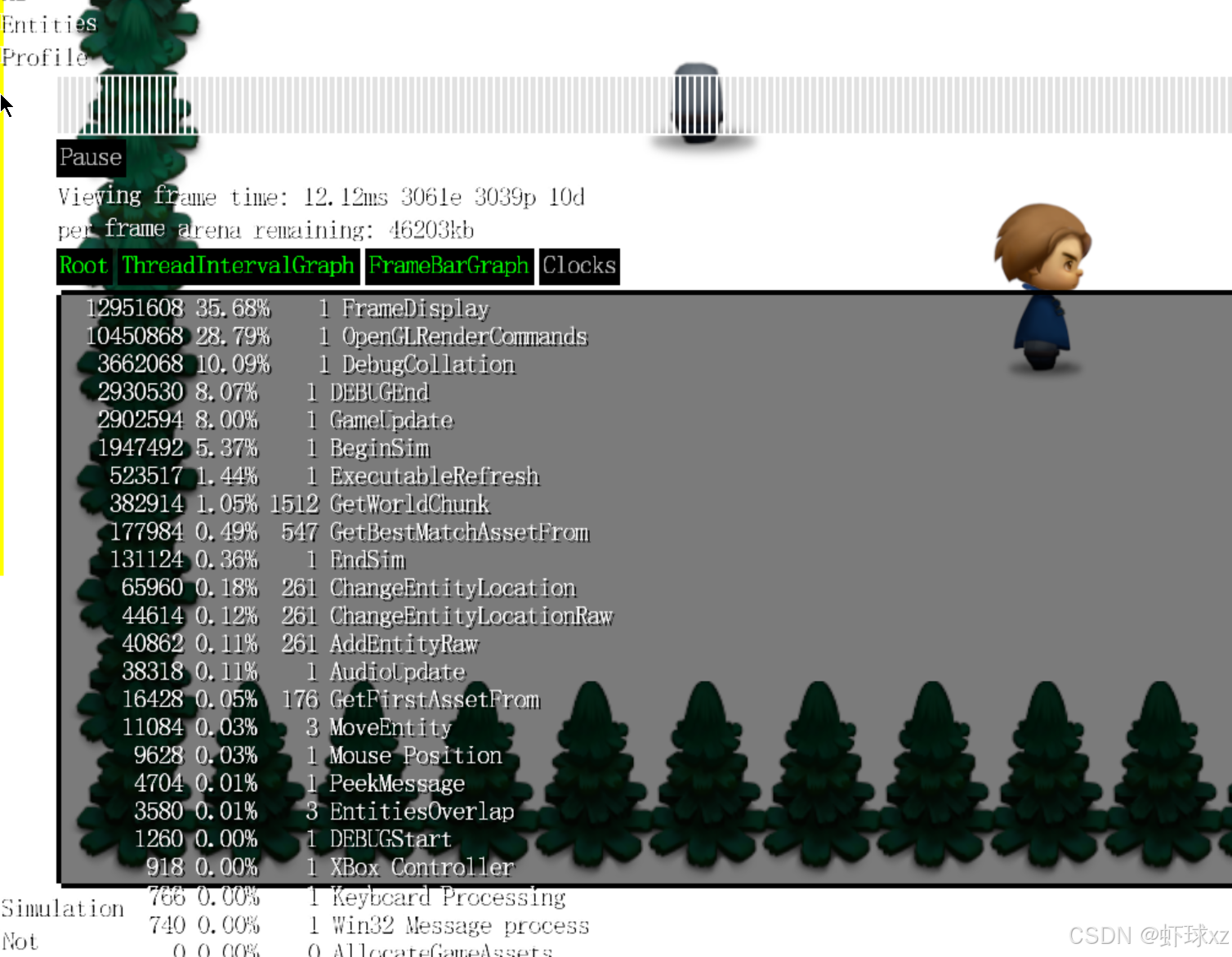
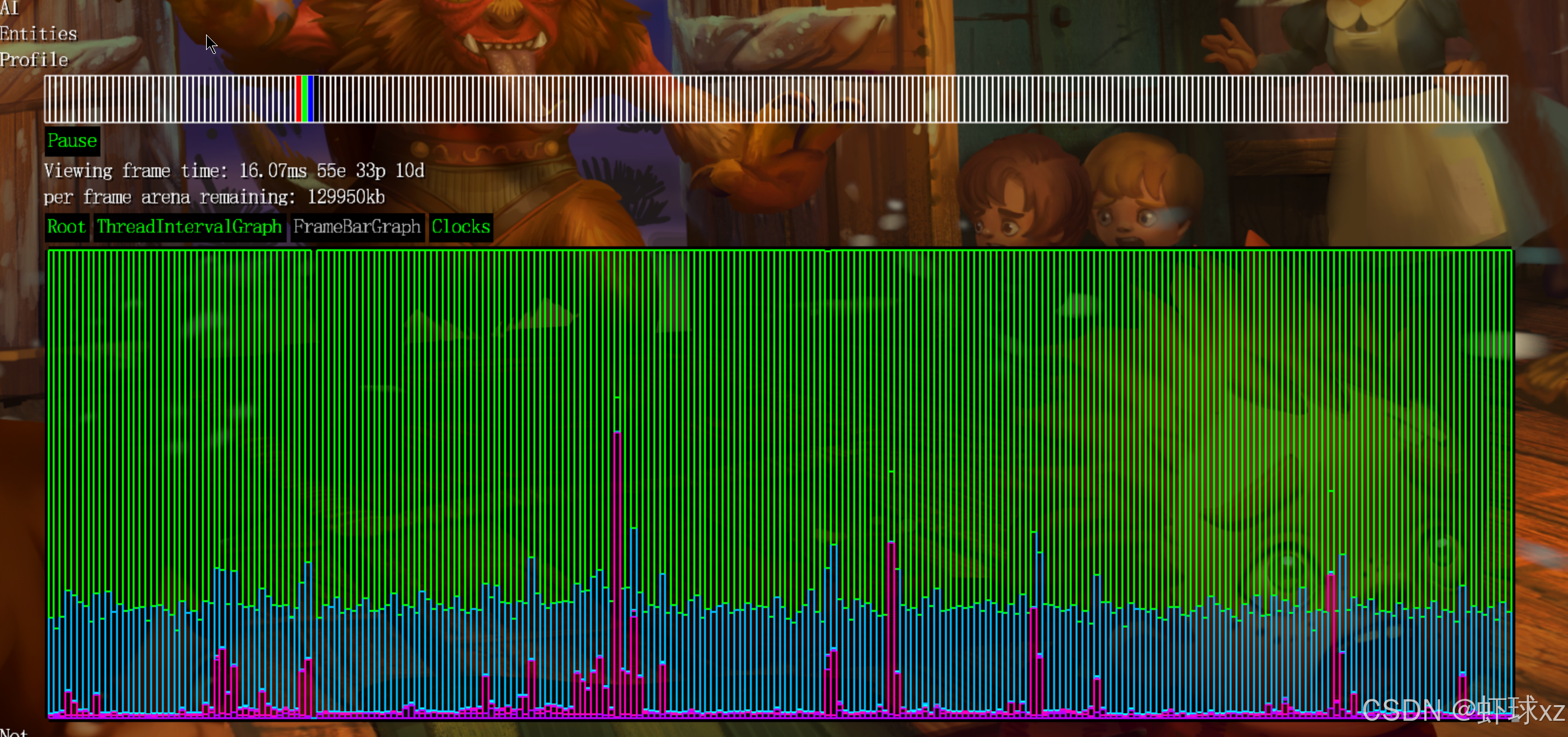
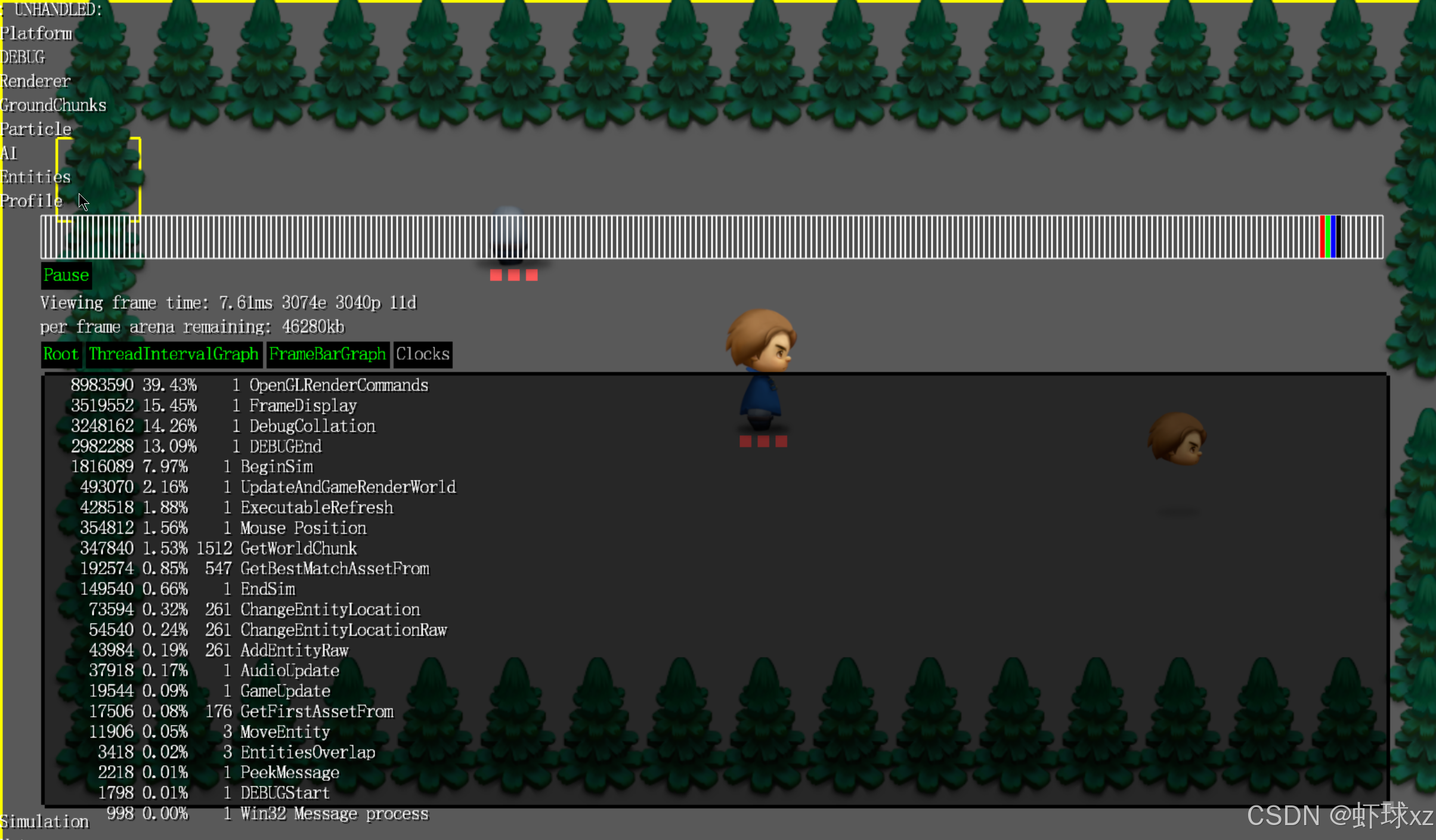
运行游戏,更清楚地看到时间消耗的位置
我们现在通过排除子节点耗时的方式,对程序中各个部分的性能开销有了更加清晰、准确的认识。
过去的分析方式存在明显的问题:多个嵌套代码块在统计时会重复计算子节点的耗时,导致百分比被双重、三重甚至更多次叠加,最终无法真正看清哪个部分独立消耗了多少时间。
改进之后,百分比只表示每个代码块自身独立消耗的时间,从而大幅提高了分析的准确性。现在我们能一目了然地看到:
- 当程序处于过场动画阶段时,几乎所有的时间都花在了调试系统(debug system)和图形渲染(GPU)上,因为这时程序本身没有做什么,只是把画面输出给图形卡,然后等待垂直同步(VBlank)或者继续渲染其他内容。
- 此时绝大多数时间花在渲染调试界面、准备绘图指令等任务上,实际的游戏逻辑消耗可以忽略不计。
而当切换到正常的游戏状态后:
- 分析数据变得更加平衡。
- 游戏逻辑更新(GameUpdate)和渲染(Render)部分开始占据显著的时间比例,比如更新和渲染可能占用20%左右。
- 同时可以观察到仍然有一部分时间由调试系统消耗,这也符合预期,因为调试工具在运行时仍会渲染界面、采集数据等。
改进的效果非常直观,比如:
- 原本在顶部显示为主要耗时的
GameUpdate块,现在变成了"几乎不耗时",因为它本身只是一个调用其他函数的外壳,它的时间此前是由内部函数撑起来的。 - 真正花时间的代码块现在被正确地识别并显示出来了,比如某些图形处理、系统调用或者是某些具体的渲染函数。
通过这种方式,我们可以准确找到瓶颈所在,更合理地进行优化,而不是被重复统计的数据误导。调试和分析体验显著提升,结果也更加贴近程序的真实运行情况。
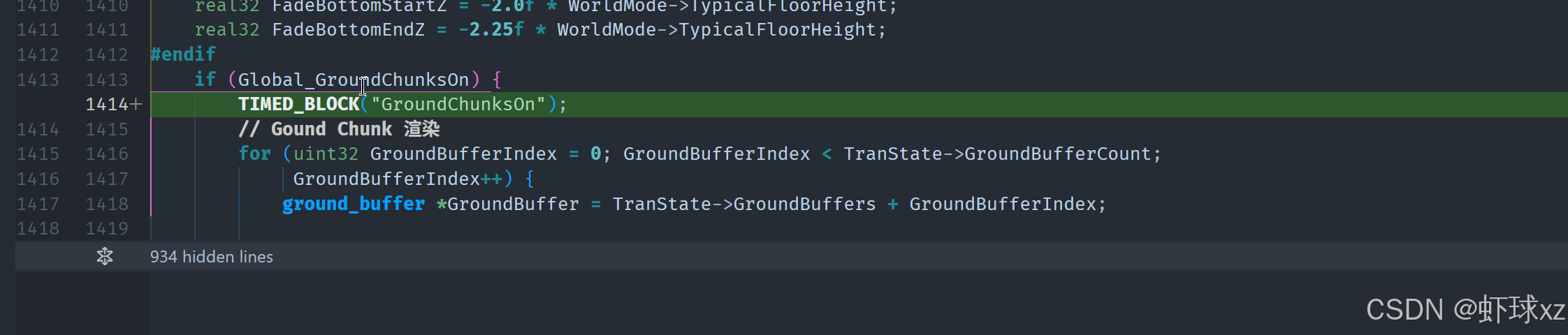
game_world_mode.cpp:将 UpdateAndRenderWorld 设为 TIMED_FUNCTION
我们现在可以开始深入分析为什么 GameUpdateAndRender 会占用如此多的时间。这是一个很合理的问题,而我们也可以立刻着手去确认问题所在。
首先我们定位到了 GameUpdateAndRender 的代码位置,并查看了它的计时调用。可以看到其中包含了一些初始化代码,还有一系列其他的操作,但我们推测,真正耗时的部分应该是 TitleScreen、Cosine、或是 WorldRender 这几个子过程。为了验证这一点,我们决定进一步细化分析。
接下来我们进入 world_mode.cpp 文件,找到 UpdateAndRenderWorld 函数,尝试把这个函数也包裹成一个计时代码块,以便更精确地观测其性能表现,从而验证我们关于它耗时较多的猜测是否属实。
在添加这个计时器的过程中,我们回顾了现有的性能分析系统,确认我们不需要为这些计时代码块指定名称,系统会自动根据代码位置生成对应的标识。因此我们可以非常方便地将 UpdateAndRenderWorld 包裹进性能分析流程,从而对其进行独立的时间记录。
这一流程是我们整体性能调优的重要组成部分,它帮助我们从最外层函数逐层往里钻,找出真正消耗性能的具体代码位置,以便有针对性地优化而不是停留在模糊的大块调用分析上。这样可以有效避免误判和优化误区,把精力集中在实际有价值的目标上。
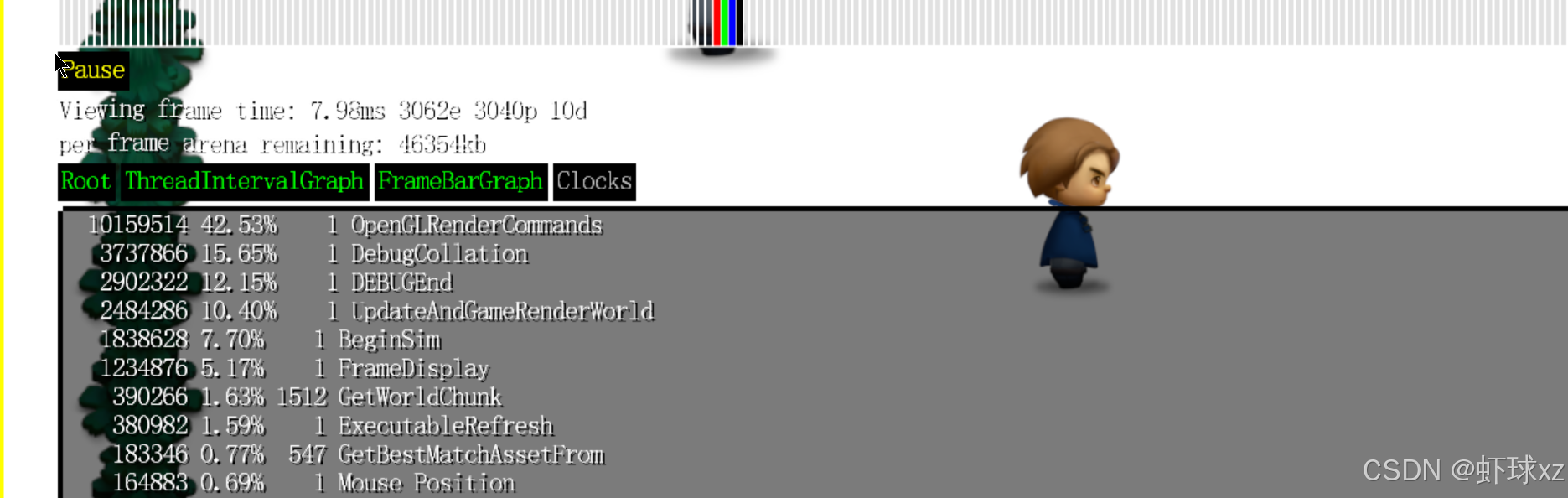
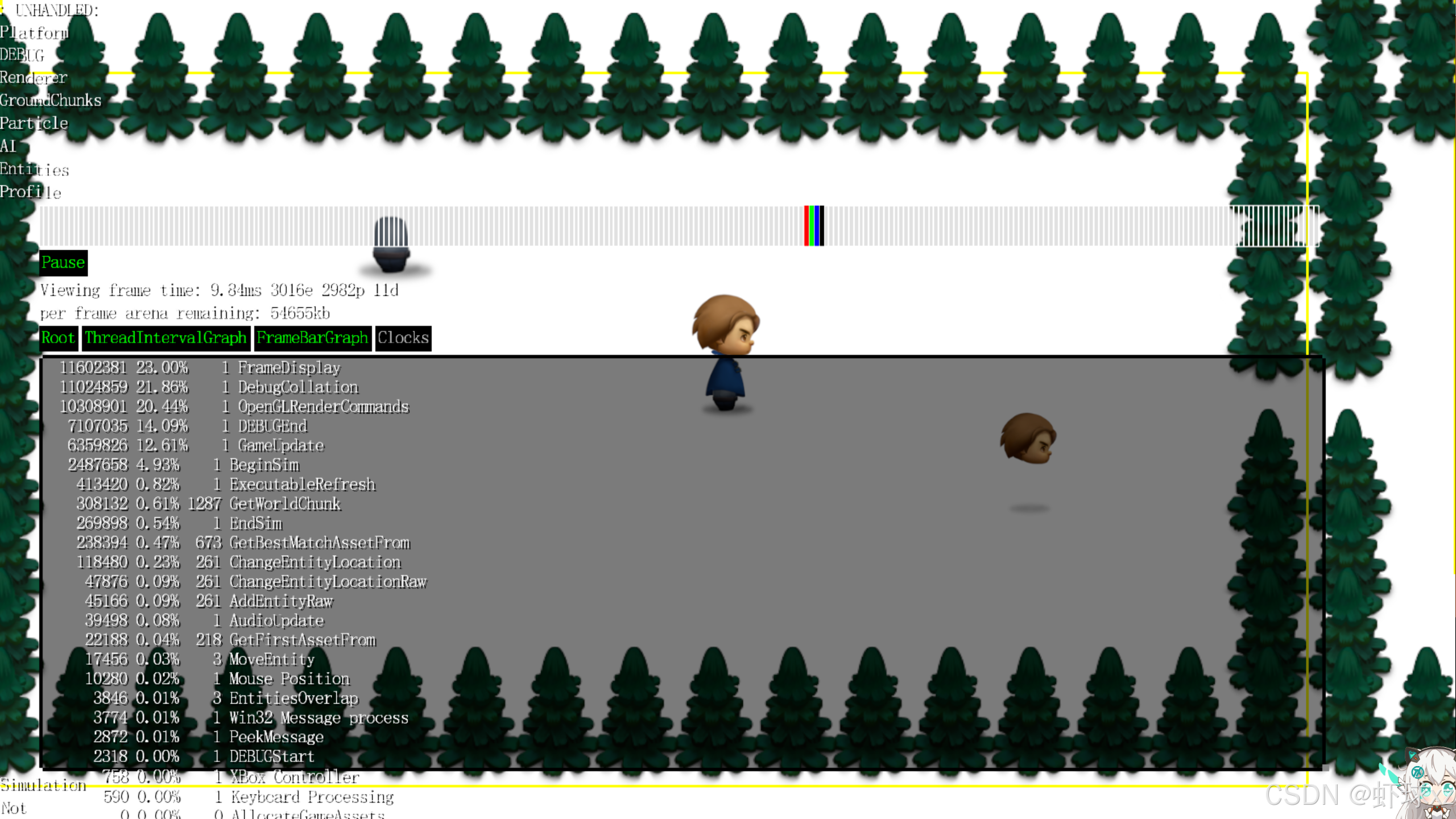
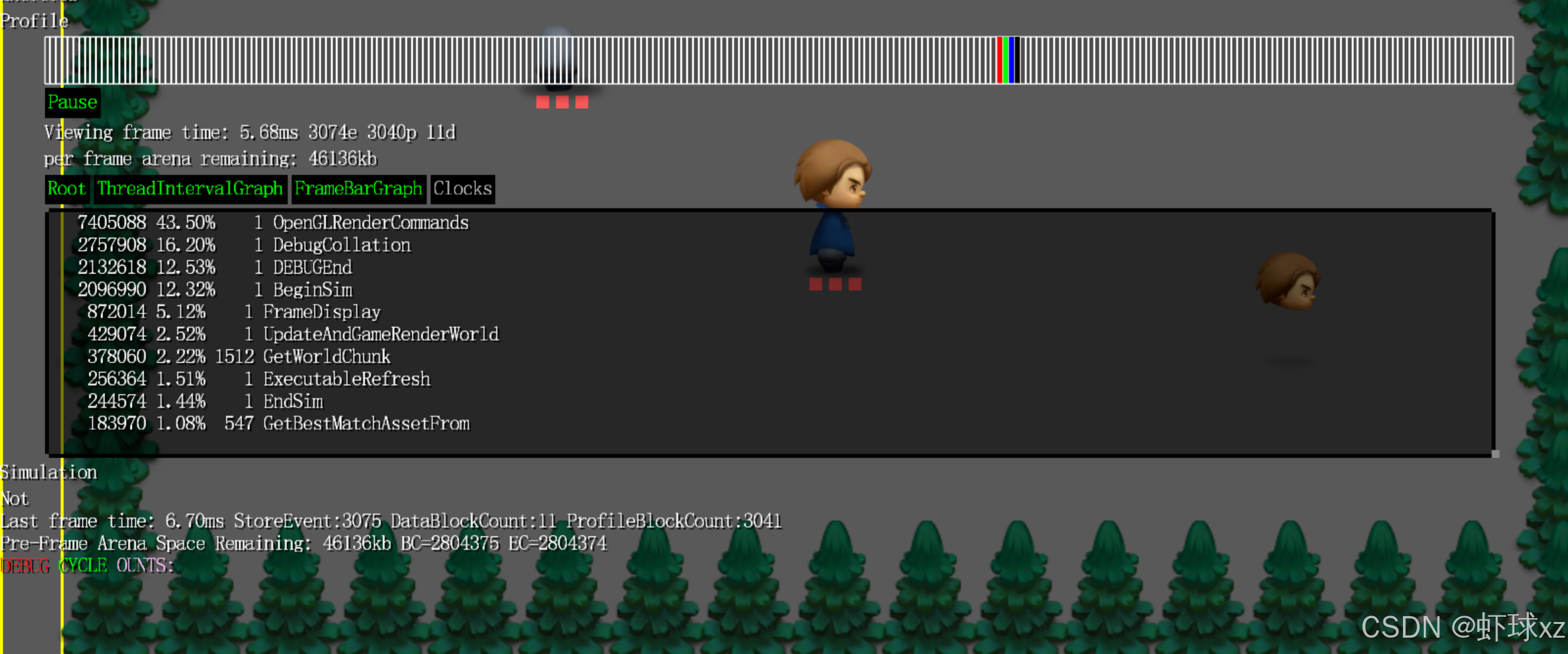
运行游戏,查看时间消耗情况
暂停执行并查看最新的分析结果后,可以看到我们之前的猜测得到了验证:UpdateAndRenderWorld 函数占用了约 13% 的总运行时间。这与我们之前认为 GameUpdateAndRender 本身占用大量时间的现象更为一致,因为之前的观察其实是它的子过程所消耗。
不过奇怪的是,现在显示 GameUpdateAndRender 占用了大约 1100 万个时钟周期,而 UpdateAndRenderWorld 却也显示为相同的周期数,但它们所占的百分比却不一样。这说明虽然它们的周期数一致,但整体帧时间发生了变化,导致百分比换算不同。这一现象令人困惑。
进一步回顾后发现,原来这个现象可能是由调试系统的绘制逻辑引起的。在我们修改了代码文件之后,由于使用guid行号作为标识的机制存在,导致同一个逻辑块会因为文件结构变化而被绘制两次。这直接增加了绘制工作量,使得整个帧时间变长,从而影响了周期百分比的换算结果。
这种设计带来的副作用看起来并不理想。一个文件内容的微小调整就可能引发整个系统重复绘制并错误累加分析数据。这种行为可能并不符合预期,也可能会误导性能分析结论。因此我们开始思考是否有必要修改guid系统的这一行为方式,也许应该优化其逻辑,避免重复绘制造成额外开销并影响性能数据的准确性。至于如何改动,还需要进一步思考和设计。
game_debug_interface.h:将 RecordDebugEvent 的参数从 DEBUG_NAME 改为 Name
目前我们已经观察到 UpdateAndRenderWorld 是主要的耗时来源,正如预期所示。在分析中也发现了一个问题:由于guid系统(guid System)在标识调试项时使用了文件名、行号和计数器等信息,导致某些调试元素在文件结构或行号发生变化后被重复绘制。这使得我们每次重建游戏时,即使逻辑未变,也可能因为文件结构的改变造成调试系统重复渲染,最终影响性能分析的准确性。
在进一步探查中,我们定位到了guid系统相关的接口定义。在当前实现中,唯一性(Unique ID)的生成依赖于调试项所在的文件、具体行号以及一个计数器。我们开始质疑这种做法的合理性。具体而言:
- 是否还需要依赖行号(line)和计数器(counter)?
- 是否仅靠调试项的名字(name)就足以唯一标识一个调试元素?
- UI 元素是否本就应该在程序重启或重载后保持唯一性,避免重复注册?
我们开始倾向于移除对行号和计数器的依赖,单独使用调试项的名字来标识调试元素。这样一来,即使源代码发生变动,只要名字不变,调试系统就不会重复生成相同内容,能避免如前述重复绘制的性能开销。
这一变更虽然还未最终定论,但我们已经明确了一点:当前方式可能并不理想,未来很可能需要将 debug_name 替换为更常规的 name 字段,以便更合理地管理 UI 元素的唯一性。
总结而言,我们识别出了调试guid系统在调试项唯一性设计上的问题,提出了优化方向,即仅使用名字来标识调试项,减少重复渲染的风险,并为后续进一步性能分析做好准备。接下来将继续深入 UpdateAndRenderWorld 函数,以拆分并进一步定位具体耗时代码。
去掉DEBUG_NAME 好像不能显示了
运行游戏,发现 GroundChunksOn 占用了大量时间
我们继续进行了性能分析后发现,目前有大约 20% 的时间被花费在地面区块(ground chunks)相关的处理上。这一结果令人惊讶,因为原本预期这部分逻辑并不会占用这么高的执行周期。
地面区块通常是用于表示和管理世界中某一片区域的地形数据或结构体。可能的耗时来源包括但不限于:
- 区块数据的动态生成或加载;
- 每帧执行的状态更新(例如物理、碰撞、可见性判断等);
- 区块缓存机制未优化,导致频繁重建或拷贝;
- 内部存在大量小型对象的动态分配或频繁的数据访问。
从这一发现中可以初步判断,这段代码可能包含了未被预料的性能问题。接下来需要深入地查看 GroundChunks 相关模块,确认是否存在重复计算、不必要的内存操作、或者可以延迟执行的逻辑。
接下来的步骤:
- 对
GroundChunks模块中各个子函数添加定点计时代码,明确到底是哪一部分最耗时; - 检查是否存在数据结构设计上的低效,例如链表遍历、哈希查找等;
- 考虑缓存策略、是否可以进行按需更新或延迟计算;
- 如果涉及渲染相关,进一步排查是否有状态切换或冗余的 GPU 提交。
这一发现提醒我们,不应该凭直觉忽略某些模块的潜在成本,实际测量是发现性能瓶颈的最有效方法。
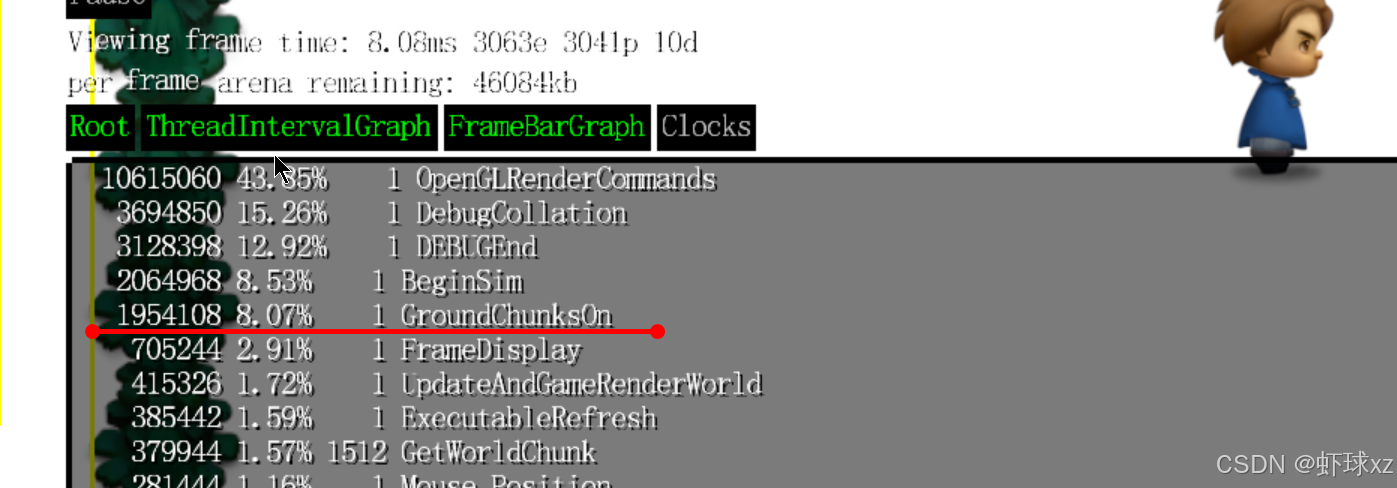
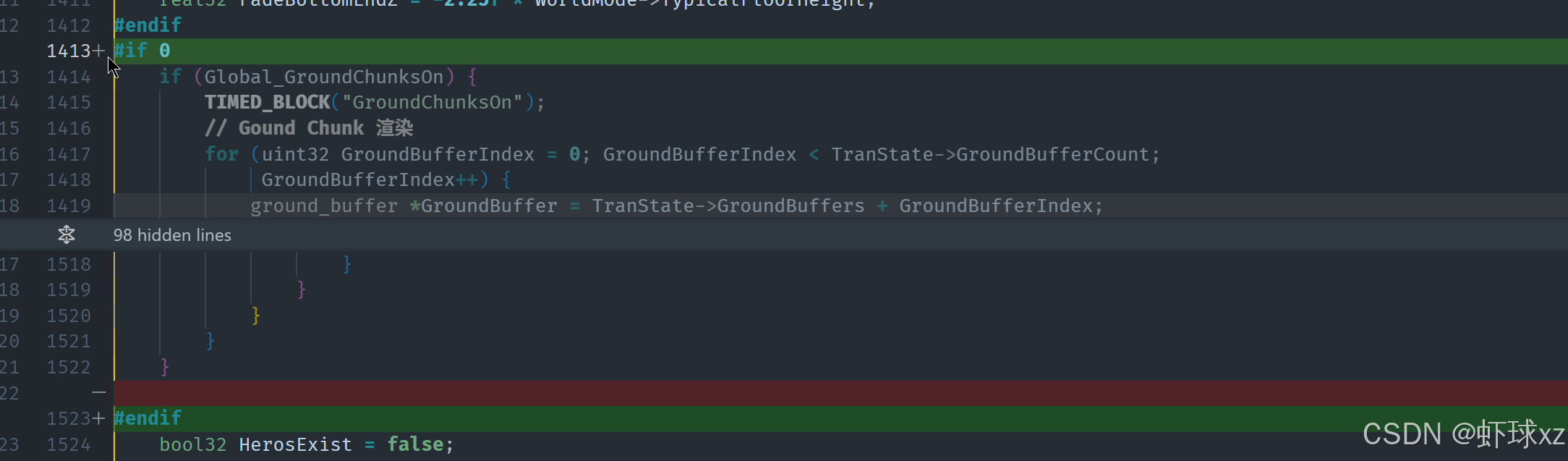
game_world_mode.cpp:移除 GroundChunksOn,再次查看分析器
我们注意到 GroundChunks 相关的逻辑基本属于遗留内容,当前游戏设计早已不再使用该机制,因此其存在已无意义。尽管这些代码还在运行,但实质上是无用的垃圾逻辑,导致我们在性能分析器中看到大量不必要的计算资源被浪费。根据推测,可能是因为分配了太多无用的地形缓冲区,导致整体性能下降。
我们决定将这部分逻辑彻底清除,正好也是我们本来就计划进行的优化。清除后,性能明显提升,BeginSim 的耗时从原本占据大量比例下降到只剩下 10%,其余主要耗时集中在调试系统中,这样的性能分布更加合理。
虽然我们当前处于调试模式(Debug Mode),但可以预见,在发布模式(Release Mode)下,性能表现将更优。这进一步证明移除无用逻辑所带来的显著收益。
继续分析性能数据时发现,现在的 GameUpdate 几乎所有耗时都集中在 GameUpdateAndRender,而其中又几乎全被 UpdateAndRenderWorld 占据。这与预期一致,表明整个逻辑链已经清晰明了,问题模块已被有效剔除。
调试系统的实时反馈效果令人惊喜,它的功能非常强大,甚至足以发展成一个独立的商业产品。只需开发一个优秀的可视化查看器,即可将该系统打造成一个通用的性能分析解决方案。目前的调试界面虽然简陋,仅凭零散的十分钟时间做了一些基础渲染调整,但如果能投入完整的一周开发时间,将能打造出非常强大且直观的调试工具。
当前我们已经能通过该工具快速定位问题,并迅速解决。例如刚才识别出一个占用大量资源的废弃模块并完成清除,性能立刻提升,这说明这套系统不仅实用而且高效。
接下来的工作将主要集中在渲染方面的清理,确保调试窗口不会越界显示,限制其内容在合理范围内。我们不会对其进行过多复杂功能扩展,仅做一次合理的整理和优化,保证清晰可用即可。
目前来看,这一部分功能已经达到理想效果,后续只需做一些简单的收尾和整理,整体框架已经具备良好可用性。
game_debug.cpp:将分析器绘图裁剪到 ProfileRect.Min.Y
我们开始尝试为当前调试窗口实现一种"简易剪裁(clip)"功能,不需要正式暴露渲染组的剪裁矩形机制。尽管系统本身支持剪裁,但实际上我们并没有开放设置剪裁区域的接口,这是一个我们早该补充的功能。暂时决定不引入这一完整机制,而是用一个临时的方式处理显示越界的问题。
目标是防止窗口绘制内容超出其边界。现有文本绘制过程是直接从顶部开始不断输出内容,完全没有边界判断,导致内容会直接越界绘制。我们希望加入一个逻辑:如果当前文本行绘制的 Y 坐标加上该字体的行高,已经超出窗口底部边界,就不再绘制。这样可以让显示内容在窗口区域内自然截断,防止溢出。
初步实现后,我们能看到绘制停止于窗口底部,但顶部仍可能有内容出现在视野之外,同时在接近底部的区域,内容会提前被清除掉。虽然这种行为并不完美,但当前这种方式已经初步实现了"窗口边界裁切"效果。
为了进一步完善效果,还需要考虑字体本身的基线位置,而不是当前 Y 坐标加行高。因为文字往下有可能会出现下部偏移,导致部分字符在理论上没越界但实际已越界。要精确判断是否应该绘制某一行,需要引用字体绘制的实际底部偏移量,这一步若要实现得更完整,最终仍需正式使用剪裁矩形机制。我们讨论是否值得引入完整剪裁支持,目前暂时搁置。
此外,还对调试窗口中的"可拖动控制区域"进行了改进,之前抓取手柄(grab handle)太小,经常点不中。定位到控制区域绘制逻辑后,将控制区域矩形的尺寸手动扩大了四个像素,显著改善交互体验。修改完成后,拖动控制变得更加顺畅,操作手感明显提升。
总结来看,目前已实现:
- 添加了简单的绘制裁切逻辑,防止绘制内容溢出窗口底部。
- 修改了拖动控制区域的尺寸,使其更容易被用户抓取。
- 初步分析了使用真正剪裁矩形的可行性和必要性,后续视情况考虑引入。
整体显示逻辑已趋于稳定,窗口绘制和交互体验也有了明显提升,剩余改动以小规模整理为主。
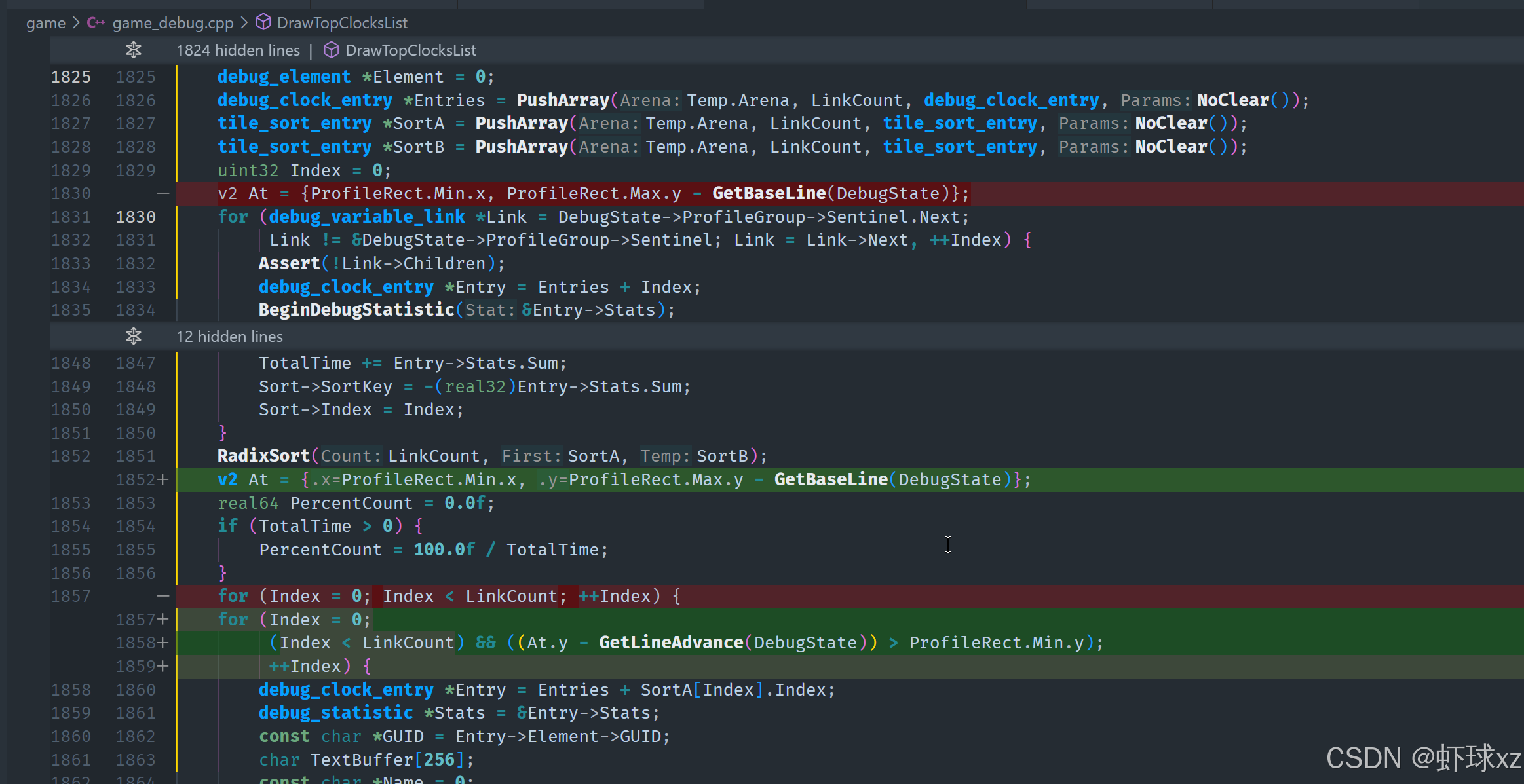
黑板:选择正确的裁剪线
我们当前的目标是确保在绘制文本时,所有内容都严格限制在一个给定的矩形区域内,不会出现超出窗口边界的绘制行为。问题在于,我们现在手头可能只有当前行的 at_y 指针,也就是当前要绘制的基线位置。然而,这个位置本身无法确定实际的字体像素是否会向上"突出",也就是说,无法确保即将绘制的文本是否会侵入上方窗口边界。
为了解决这个问题,我们采用一种更可靠的判断方式:不是单纯判断当前绘制行的位置,而是通过上一行来反推当前行的位置。如果我们知道前一行的底部仍在窗口可见范围内,那么当前行的顶部也一定不会越界。因为字体的绘制不会在基线之上无限延伸,我们可以合理地以此为界。
因此,理想的判断逻辑是:如果上一行的绘制已经在窗口外了,那么当前行就不可能全部出现在窗口内,于是可以直接跳过绘制当前行。这种方法比判断当前行是否"在范围内"更安全,因为它有效防止了字体上方像素越界的问题。
这种策略可以确保即使字体有向上或向下的突出(例如大写字母、下沉的字母等),也不会影响窗口边界之外的区域,从而实现真正意义上的剪裁行为。这是目前我们所能实现的一个更加精细且合理的绘制控制逻辑。

game_debug.cpp:让分析器多绘制一行
我们现在在处理一个关于文本绘制范围的问题,目标是在绘制前判断是否需要继续绘制,避免无意义地渲染已经超出可视区域的文本。
当前的做法是:在每次执行绘制之前,检查当前 at_y(也就是当前行的基线位置)是否已经小于用于显示的窗口矩形 profile_rect 的 min.y(也就是可见区域的上边界)。如果当前 at_y 位置已经低于这个上边界,那么可以确定即将绘制的文本已经完全不可见,无需继续渲染,因此可以直接跳出绘制循环。
这种做法实际上是基于一种优化判断:提前终止那些完全位于可视区域之外的文本行的绘制。具体流程如下:
- 判断条件 :在每次绘制之前,判断当前的
at_y是否小于profile_rect.min.y。 - 提前中止:如果条件成立,说明当前行已经完全在窗口上方(即不可见区域),那么即使再执行换行或位置更新也不会使其变得可见。
- 执行跳出:因此可以直接在这一轮判断后中止后续绘制,提高效率。
- 更新方式 :这种判断可以放在绘制循环内部的前部,也可以放在处理
advance(位置推进)之后立即进行判断。
总之,这是一个通过逻辑判断避免渲染冗余内容、减少性能消耗的优化策略,确保只绘制用户真正能看到的内容,从而提升系统整体绘制性能和响应效率。
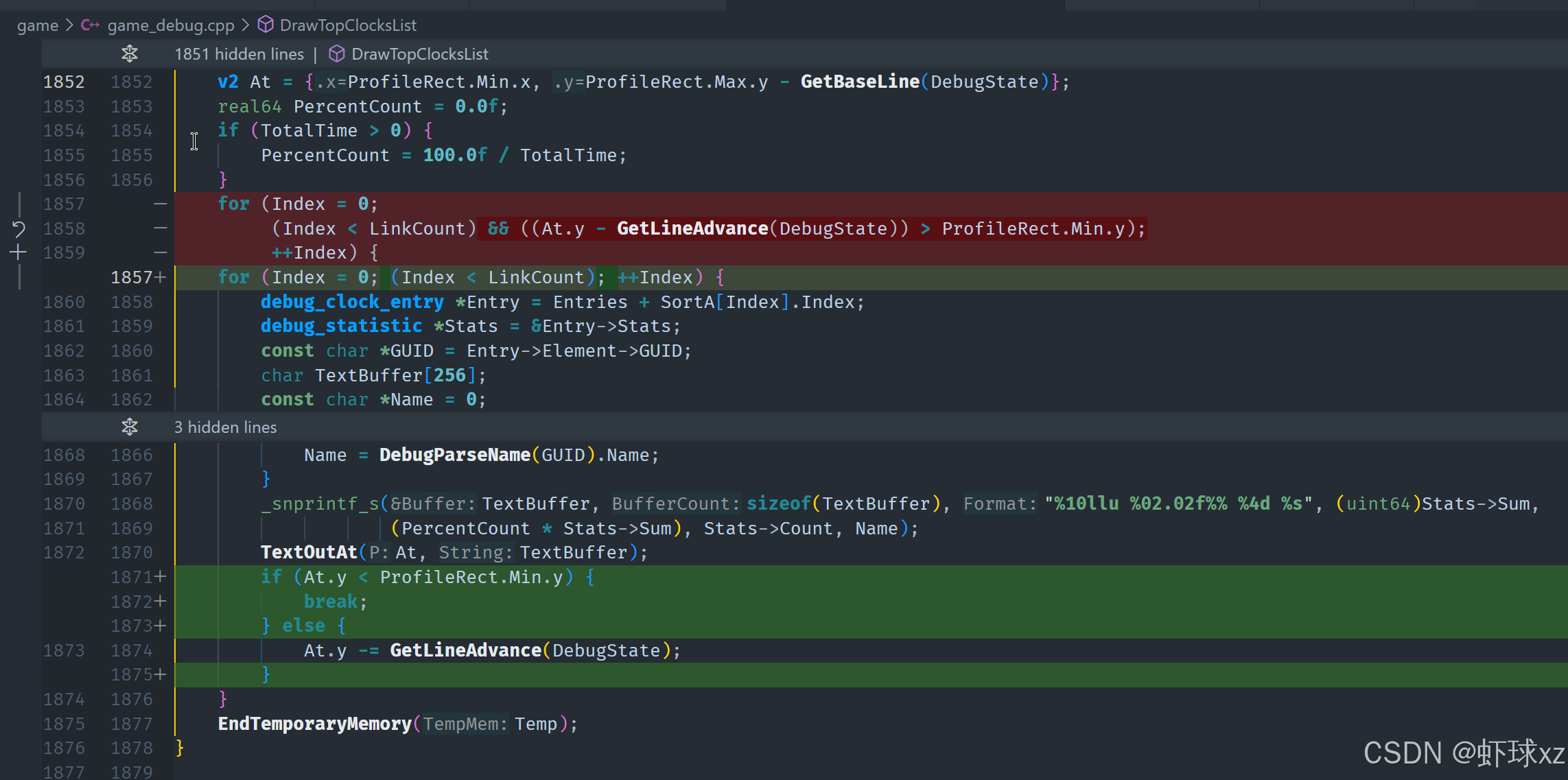
查看分析器,看到多绘制的效果
我们现在对绘制逻辑做了进一步优化,主要集中在实现裁剪(clipping)矩形的机制,并分析了其设计思路及在渲染系统中的整合方式。以下是详尽总结:
我们希望在绘制时稍微越界一点,确保即使超出边界,也会渲染出一点被裁掉的内容。这样可以避免出现空白区域,能够在实现裁剪时正确显示边缘被遮挡的部分,这是我们希望看到的效果。
接下来要引入**裁剪矩形(clipping rectangle)**的概念。虽然目前的渲染系统中已经有"相机变换(camera transform)",可以用于坐标变换,但我们可以在这个基础上扩展功能,让它也包含一个"裁剪矩形",用于限制绘制区域。
实现思路:
-
相机变换中加入裁剪矩形字段
默认情况下,这个矩形可以设为整屏大小;当需要裁剪时,我们再手动指定具体区域。
-
用户接口设计思考
考虑到使用方便性,我们可能需要提供类似
PushClipRect和pop_clip_rect的操作,允许在渲染组内部动态维护裁剪状态的堆栈。 -
裁剪矩形的记录与传递
每当执行绘制指令,比如
render_entry_bitmap或render_entry_rectangle,都必须携带裁剪矩形的相关信息:- 对于矩形来说比较简单,直接裁剪并保存裁剪后的矩形即可;
- 对于位图等复杂绘制项,需要确保能访问到正确的裁剪矩形,以便做更复杂的图形裁剪处理。
-
实现方案的对比与选择
- 一个做法是把裁剪矩形作为渲染流中的一个显式指令写入,比如"当前的裁剪区域为 X",这样会和其他绘制项一起存在于渲染流中;
- 但这样做会带来复杂性,比如需要显式解析、状态追踪等问题;
- 最终决定不采用这种方式,而是选择在渲染组内部统一维护裁剪状态,由引擎主动管理。
总结来说,我们为渲染系统增加了裁剪机制的设计,目的是提高渲染质量和灵活性。设计重点在于如何让裁剪区域自然融入已有的渲染框架,同时又不引入过多的复杂状态。当前倾向于用渲染组内部状态维护的方式进行裁剪,而不是将其作为显式的渲染命令记录在渲染流中。这种方式更简洁、控制集中,便于后续扩展和维护。
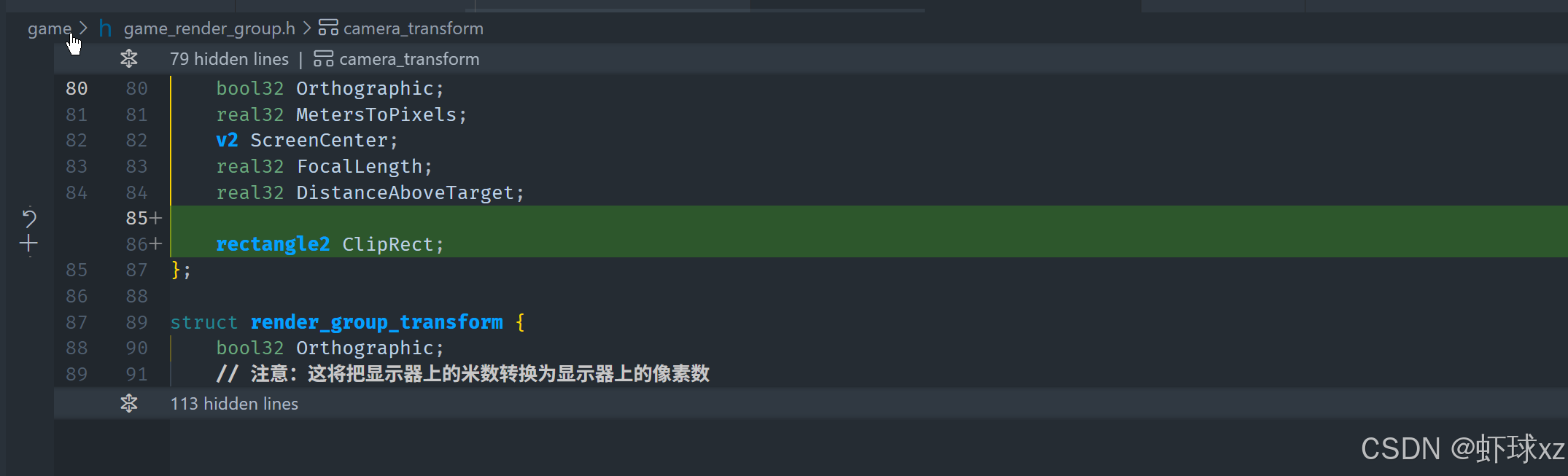
game_render_group.h/.cpp:考虑如何让位图支持裁剪
我们在这一阶段的目标是将位图(bitmap)的绘制行为正确地集成进裁剪(clipping)系统。矩形(rectangle)的裁剪较为简单,可以直接进行几何层面的剪裁处理,但位图绘制则更加复杂,因为不仅需要处理位置和尺寸的变化,还要对应地调整纹理坐标(UV),以便正确显示被裁剪后的那部分图像。
以下是我们当前的详细思考和处理流程:
位图裁剪的问题本质:
位图具有位置(p)和尺寸(size),但不像矩形那样可以直接裁剪其几何区域,因为纹理坐标(UV)会因此错位。即使我们预裁剪图像后,原来的UV坐标依然指向整张图,而不是裁剪后部分。
初步设想:通过UV偏移来处理
我们尝试了一种简化思路:记录一个 UV 偏移量(uv_offset) ,在绘制位图时将原本的最小/最大 UV 坐标偏移这个量即可。
这样可以不修改太多原有结构,仅添加一个偏移信息即可完成大部分裁剪视觉效果。
但在思考过程中我们发现这个方法存在根本性问题:
- 如果裁剪区域不对齐,只偏移 UV 是不够的;
- 无法处理从多个方向同时裁剪(如左上角同时被遮挡);
- 缺少对应的实际绘制区域数据支持。
因此,我们放弃了这种偏移方案。
改进方向:存储完整的绘制信息
我们转向更完整的方案,重新设计 bitmap 的绘制数据结构,使其足够表达完整的裁剪与变换需求。当前结构显然不够用,比如:
- 缺少旋转角度信息;
- 不能完整表达裁剪后的坐标和 UV 映射;
- 处理更高阶变换时也无法扩展。
于是我们决定重构为一种更"真实"(更完整)的数据格式,具备以下信息:
所需数据字段:
- base_p:基础绘制起点,例如左上角坐标;
- x_axis, y_axis:用于描述变换后的贴图区域方向(允许旋转等);
- bitmap_size:图像原始尺寸;
- clip_rect:当前裁剪矩形;
- uv_min / uv_max:纹理坐标范围(裁剪后重新计算);
- 颜色/透明度等其他参数。
通过这些字段,我们可以实现:
- 精确绘制裁剪后的图像;
- 正确匹配裁剪区域对应的纹理区域;
- 支持旋转、缩放等复杂绘制逻辑;
- 与现有渲染系统更好整合。
总结
我们放弃了单纯通过 UV 偏移量实现裁剪的想法,转而设计更完整的绘制数据结构。这样不仅能更准确地支持位图裁剪,还为后续支持旋转、缩放、复杂变换等功能打下基础。虽然实现上更复杂,但这才是更合理、可拓展的方向。我们会逐步将这种新结构集成到渲染系统中,替代当前简化版本的 bitmap 渲染路径。
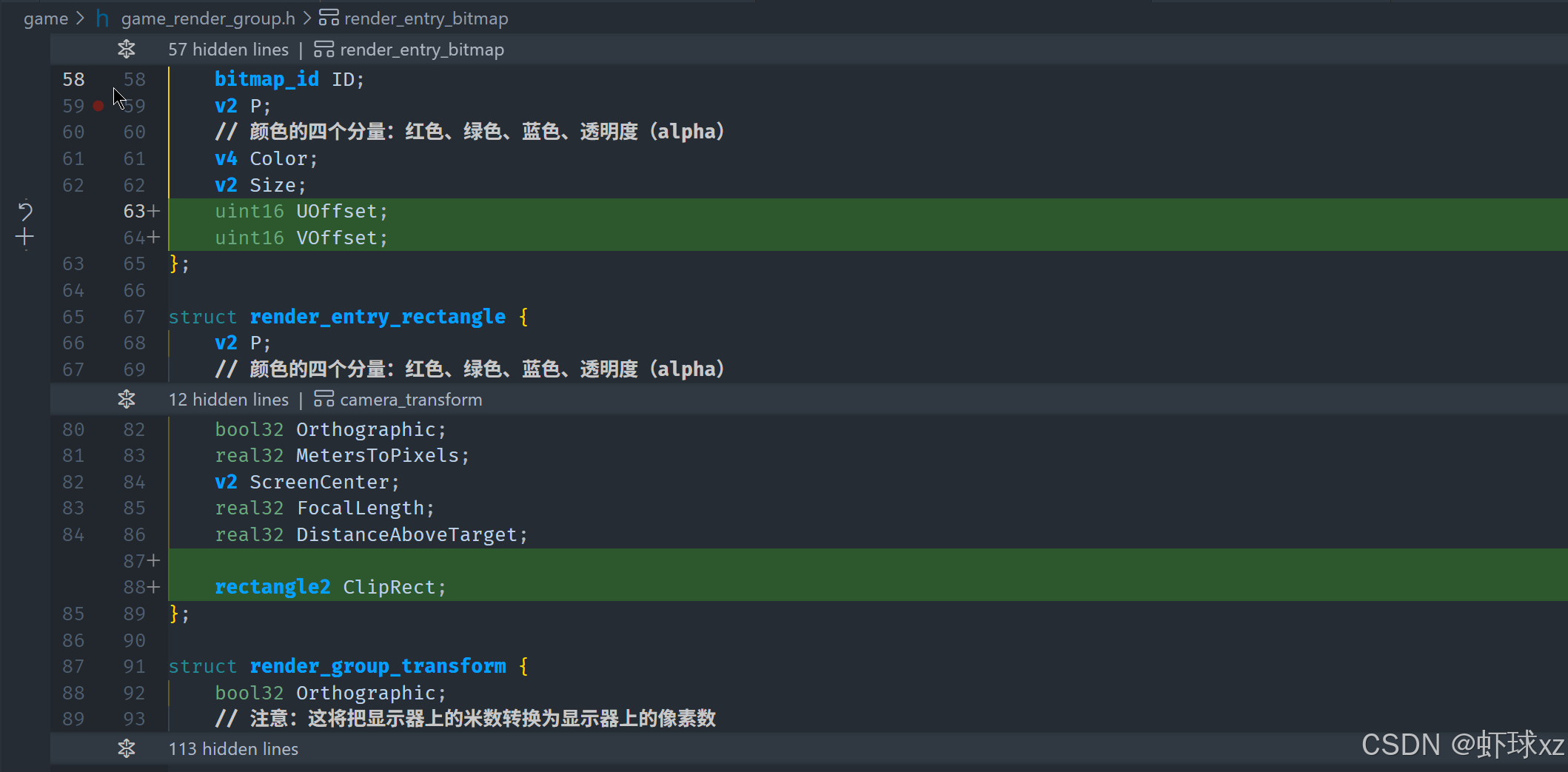
黑板:重新定义位图规格
我们在这一部分深入思考了位图渲染结构的表达方式,并探索了在支持变换(例如旋转、缩放)的同时如何处理裁剪(clipping)的问题。以下是我们逻辑推演与最终结论的详细整理:
原始绘制方式的回顾:
我们原本的绘制方式是:
- 有一个基准点(p);
- 然后通过两个向量分别描述 x 轴和 y 轴方向的延展;
- 整个绘制区域由这两个向量构成的平行四边形决定。
这种方式功能强大,理论上可以支持任意旋转、缩放甚至非矩形的位图绘制。
面临的问题:
-
过度灵活导致的问题
这种结构允许做出我们并不想支持的操作,比如非均匀拉伸(squish),会导致图像失真,纹理采样出现伪影。
-
支持旋转后无法简单裁剪
如果允许任意旋转和倾斜,渲染区域就不再是轴对齐矩形(axis-aligned rectangle),这使得我们无法轻松利用硬件或简单的代码来进行矩形裁剪。
-
裁剪数据冗余问题
如果我们把裁剪信息绑定在每一个位图渲染条目中,那会导致每个条目体积变大,浪费内存和带宽,尤其是在推送大量位图(高吞吐量)时会成为瓶颈。
思考与优化:
非矩形裁剪的放弃:
我们不打算支持自由变换之后仍进行精确裁剪(如旋转后的图像区域),因为这会要求复杂的几何运算和不易优化的逻辑。我们倾向于在不旋转的前提下执行裁剪。
限定绘制形式:
我们重新设想绘制结构,设定为:
- 一个起点
p; - 一个
x_axis(完整的方向向量); - 一个标量
y_axis_coefficient表示 y 轴方向延展倍数(其方向为与x_axis垂直);
这样:
- 我们仍可支持非均匀缩放(宽高比不同);
- 避免了任意旋转带来的裁剪困难;
- 渲染区域仍是矩形,便于进行简单裁剪处理。
将裁剪区域从绘制条目中抽离:
我们决定将裁剪矩形(clip rect)作为绘制流(stream)的一部分进行管理,即:
- 在推入若干绘制条目前,设置一个裁剪矩形;
- 之后所有条目都使用该裁剪矩形;
- 当裁剪区域改变时,更新裁剪状态或"清除"当前裁剪设置。
这样可以:
- 避免在每个绘制条目中存储重复数据;
- 降低带宽压力,提高批量渲染性能;
- 保持结构清晰、数据整洁。
最终结论:
我们放弃了原本自由向量描述图像变换的过度灵活方式,转而采用更受限、但更高效和易控的结构。通过将裁剪矩形从条目中独立出来,并作为渲染流状态进行维护,我们在保证绘制能力的同时,也能确保裁剪处理的可控性和高效性。这一设计更适合我们后续在性能和结构清晰度上的追求。
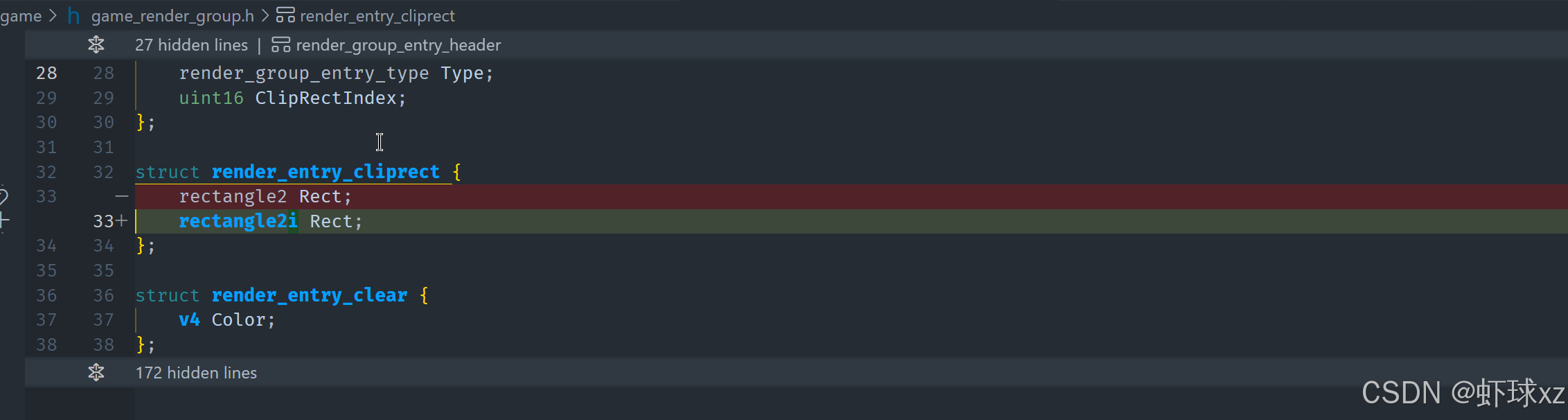
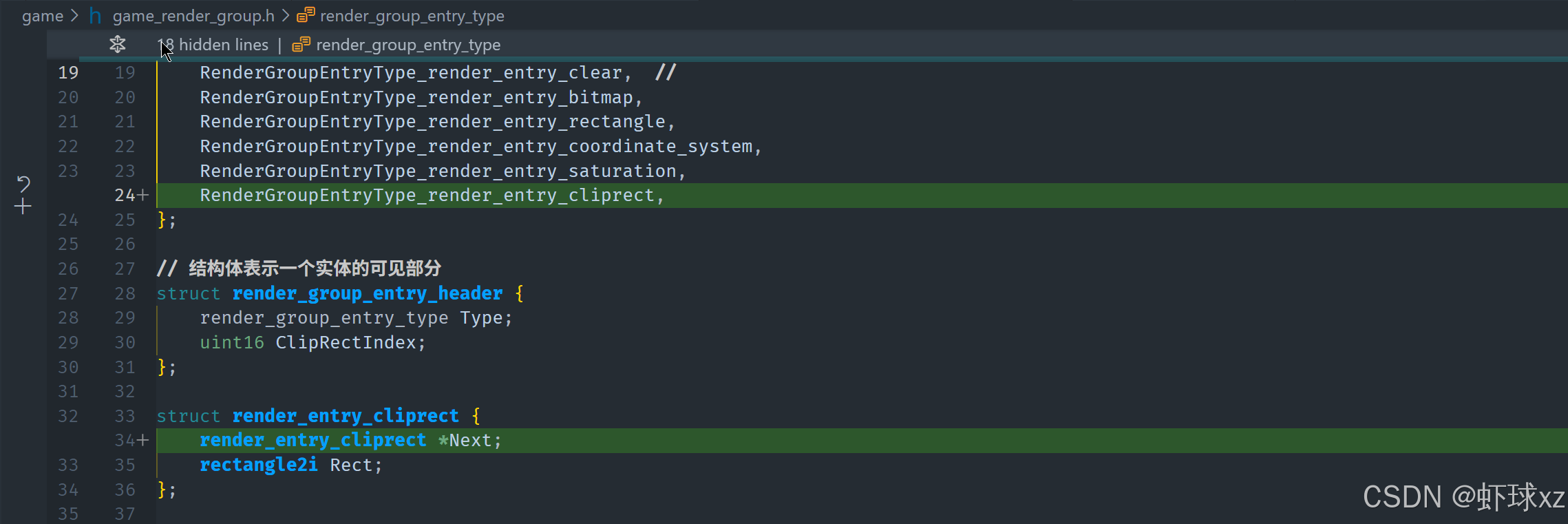
game_render_group.h:尝试引入 render_entry_cliprect,用于传递裁剪区域
在这一部分,讨论了如何设计一个新的 render entry 类型来管理裁剪区域(clip rect)。具体步骤如下:
新增 render entry clip 类型:
-
定义
render entry clip:- 该类型的主要作用是存储当前裁剪区域。
- 裁剪区域是一个矩形(
clip rect),表示我们当前允许绘制的区域。
-
存储裁剪矩形:
clip rect的内容包含矩形的最小值(min)和最大值(max),这两个值确定了当前裁剪区域的边界。- 该矩形应该以像素为单位进行存储,因为当前系统中的所有数据都使用像素为单位。
-
设置裁剪区域:
render entry clip只需要简单地存储一个矩形(clip),该矩形指定了当前的裁剪区域。这样就可以在渲染过程中使用这个裁剪区域来限制渲染输出的范围。
通过这种设计,可以很容易地在渲染流中添加裁剪区域的控制,使得绘制的内容只出现在预定的区域内,从而避免了不必要的渲染并提高了性能。这种方法简洁明了,不需要额外复杂的计算,只需在渲染过程中根据当前裁剪区域进行裁剪处理。
game_opengl.cpp:考虑排序问题
在这一部分,讨论了在渲染过程中如何处理裁剪区域(clip rect)并解决相关的复杂性。关键点如下:
-
问题:
render entry clip类型被引入用于存储裁剪矩形。然而,问题出在渲染和渲染组会进行深度排序(depth sorting)。这意味着渲染组中的项会被重新排列,因此无法简单地在渲染项之间共享裁剪区域信息。- 因为渲染项在排序后可能会改变顺序,裁剪区域必须是特定于每个渲染项的,而不是全局共享的。否则,裁剪区域就会丢失或不准确。
-
需要为每个渲染项单独设置裁剪:
- 由于排序,裁剪区域必须与每个渲染项直接相关联。不能简单地将裁剪信息存储为全局的或共享的。
- 如果要支持任意裁剪区域,可能需要更复杂的管理方式,像是为每个渲染项单独计算和保存裁剪区域。
-
性能与复杂性:
- 这种方法可能导致更大的数据流量,因为每个渲染项都需要保存和管理自己的裁剪区域。这可能会增加内存占用和处理开销。
- 尽管现代 GPU 可能不太在意这一点,软件渲染器则可能对此更为敏感,尤其是在需要进行大量渲染时。
-
可能的解决方案:
- 一个潜在的解决方案是重新设计渲染架构,以便根据需要处理裁剪区域,特别是在进行深度排序时。
- 然而,这可能会导致不必要的复杂性和性能损失,所以是否需要这么做需要仔细考虑。
总结:要支持按深度排序的渲染,同时又能正确处理每个渲染项的裁剪区域,可能需要额外的工作和优化。直接将裁剪区域与每个渲染项绑定,尽管增加了复杂性,但也可以确保渲染的准确性。在此过程中,需要平衡性能和功能性。
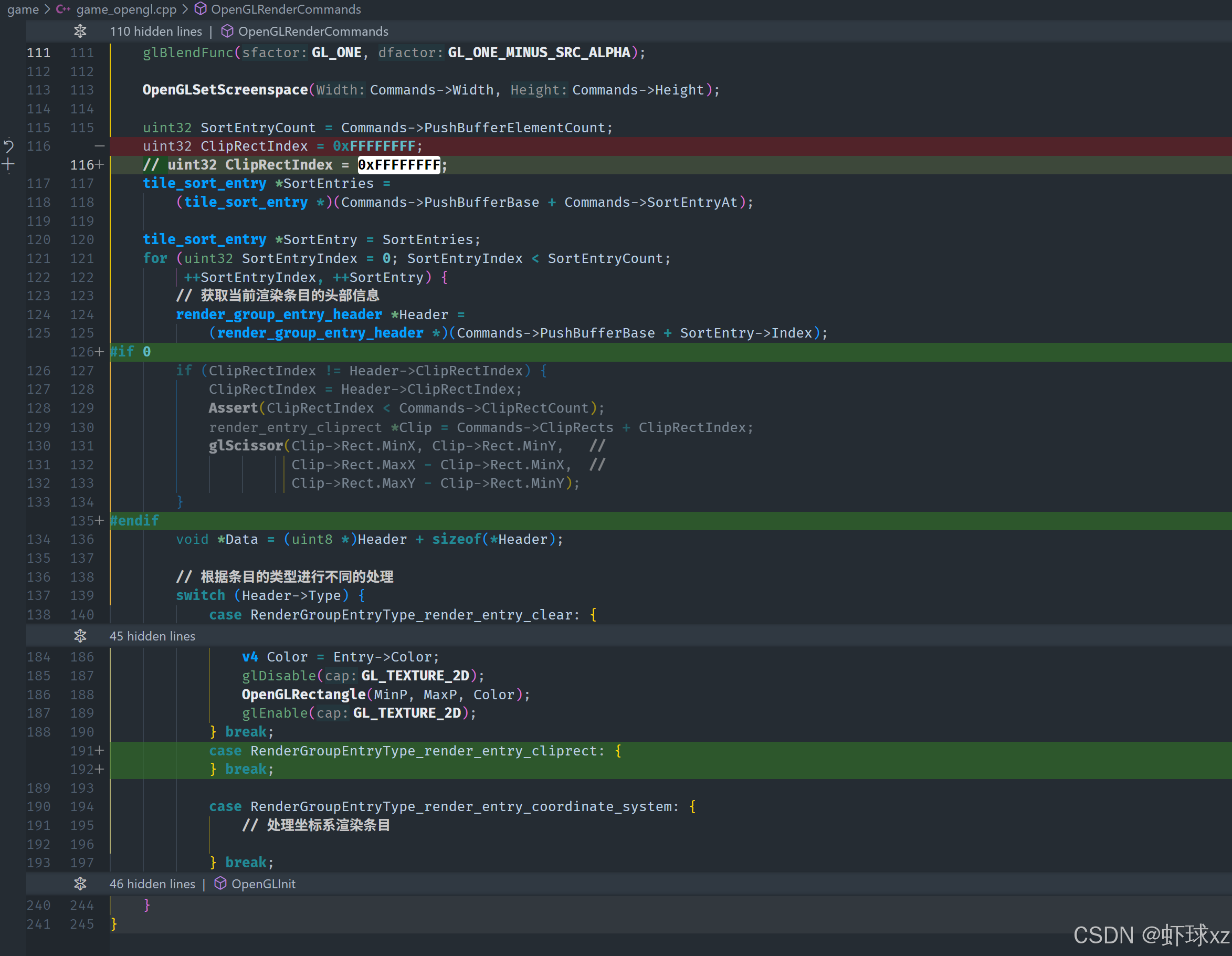
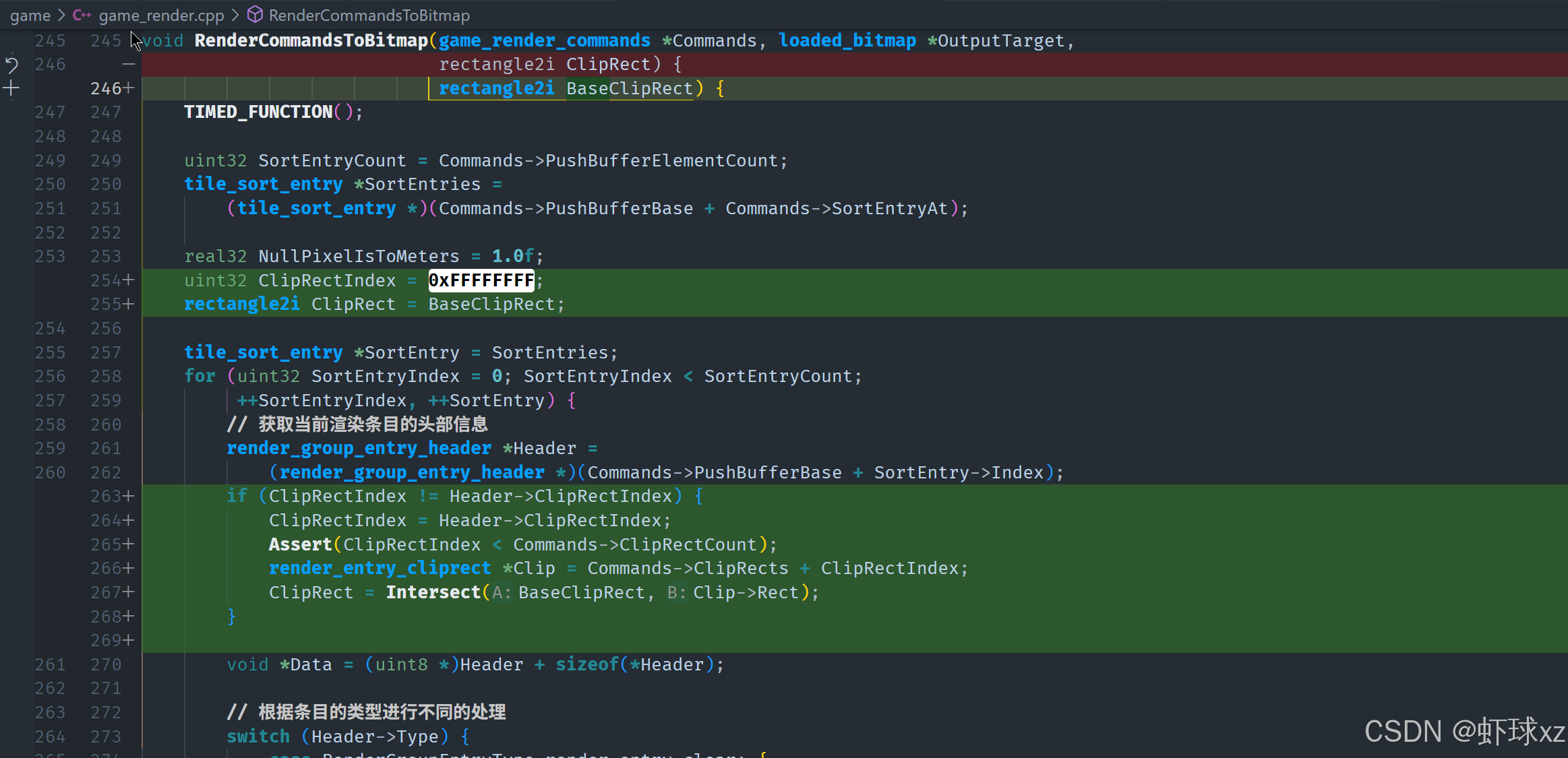
game_render_group.h:给 render_entry_bitmap 添加 ClipRect,并为 render_group_entry_header 添加 ClipRectIndex,以支持排序时的裁剪
在这一部分,讨论了如何优化渲染过程中裁剪矩形(clip rect)的管理,主要目的是减少不必要的操作和提升效率。关键点如下:
-
裁剪区域的索引化:
- 通过将裁剪矩形(clip rect)索引化,可以在每次渲染时检查当前的裁剪矩形是否发生变化,只有在变化时才更新裁剪区域。
- 具体来说,使用一个
clip wrecked index来标识当前裁剪矩形的索引。每次渲染时,先检查该索引与当前需要的裁剪矩形索引是否相同。 - 如果裁剪矩形的索引没有变化,则不需要更新裁剪区域,避免不必要的处理。只有当索引不同的时候,才会设置新的裁剪区域。
-
减少数据流量:
- 通过这种优化,可以避免每次都重新设置裁剪矩形,从而减少了不必要的操作和数据流量。
- 如果裁剪矩形没有变化,渲染过程可以继续进行而无需扩展数据流量,从而提高了性能。
-
提高效率:
- 这种方法避免了每个渲染项都重新计算裁剪区域的需要,从而减小了处理和内存占用。只有在裁剪矩形变化时,才需要进行相应的更新,降低了冗余操作。
-
如何实现:
- 每个渲染项的头部可以包含一个
clip wrecked index,初始化为零。在渲染时检查该索引是否与当前需要的裁剪矩形索引相同。 - 如果索引相同,就不做任何操作;如果不同,就更新裁剪矩形并进行相应的渲染操作。
- 每个渲染项的头部可以包含一个
总结:为了优化渲染性能,避免不必要的更新,可以通过为裁剪矩形引入索引机制,仅在必要时更新裁剪区域。这种方法通过减少冗余计算和数据流量,提高了渲染过程的效率,并避免了不必要的内存扩展。
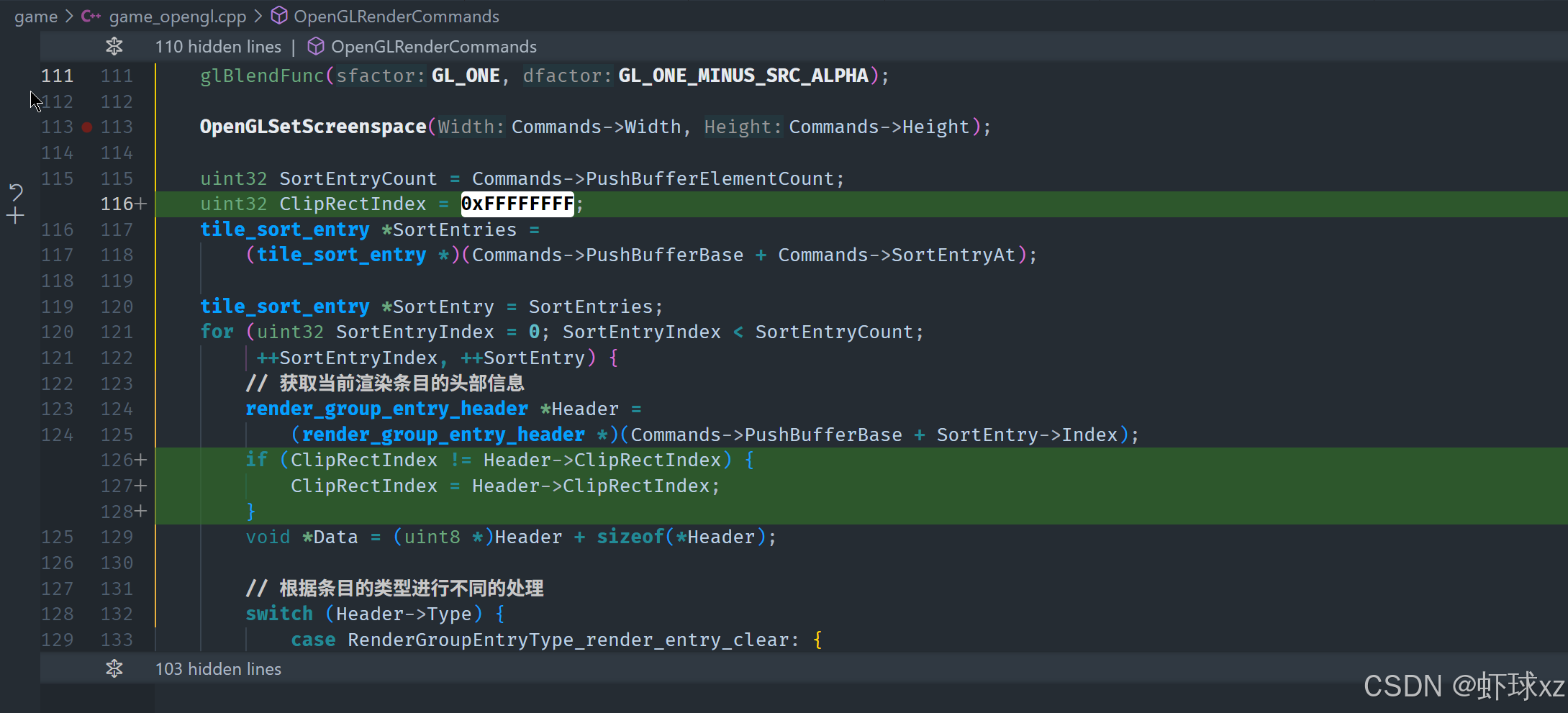
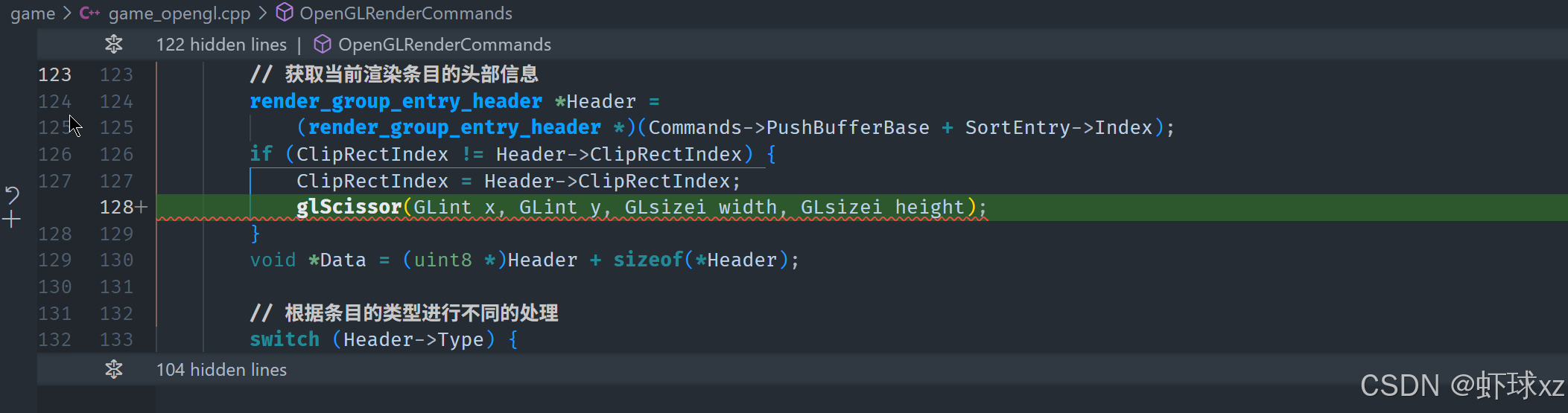
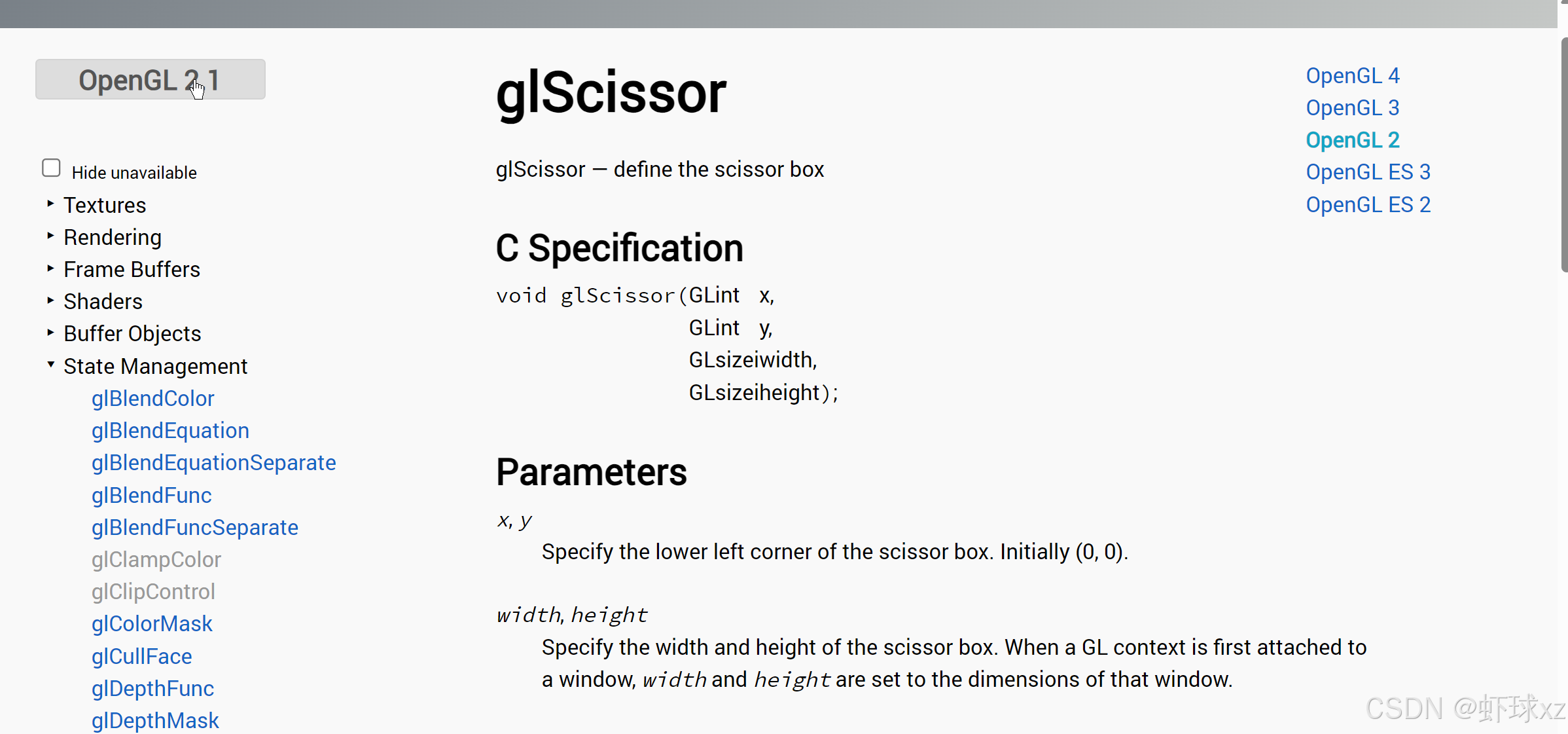
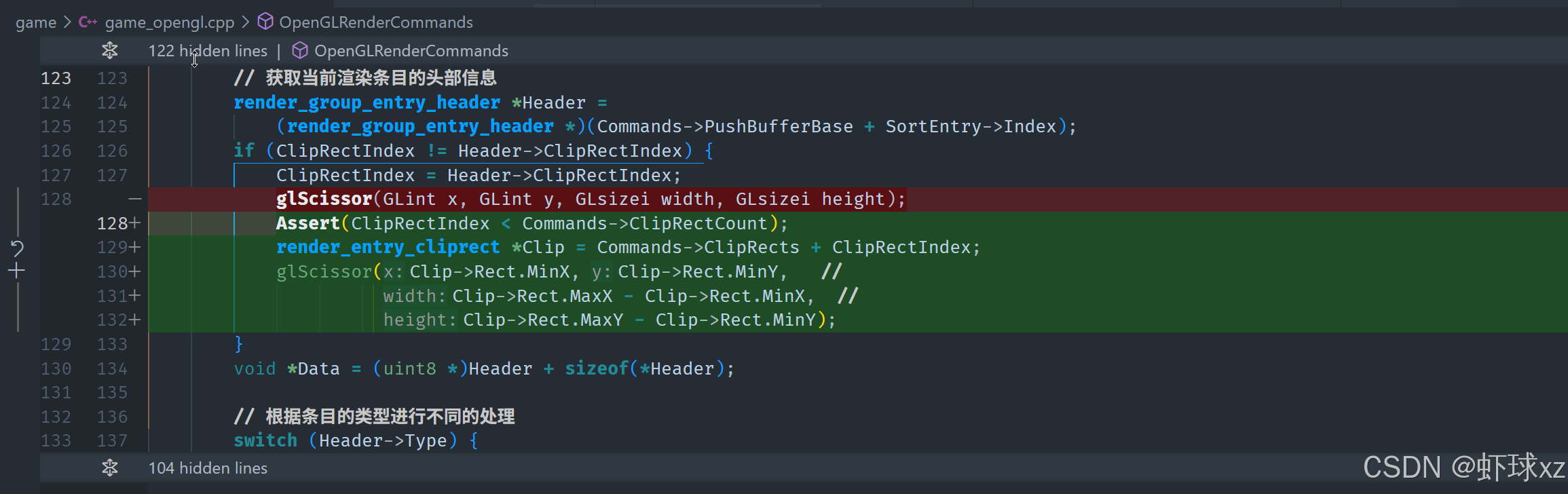
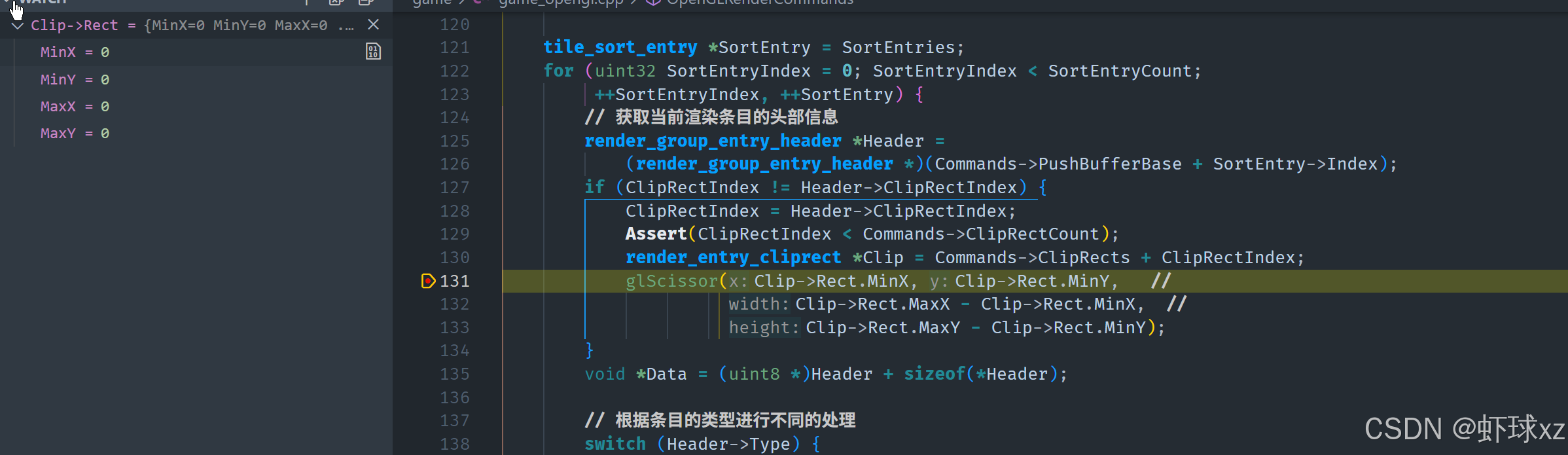
game_opengl.cpp:调用 glScissor
在这一部分,讨论了如何通过使用 OpenGL 的 glScissor 函数来限制绘制的区域。具体内容如下:
-
glScissor 的作用:
glScissor是 OpenGL 中用于设置剪裁区域的函数。通过调用它,可以定义一个矩形区域,只有这个区域内的内容才会被渲染。- 默认情况下,渲染区域是整个窗口的大小,而
glScissor允许在窗口内设置一个更小的区域,从而限制绘制的范围。
-
如何使用 glScissor:
- 在实际的渲染中,调用
glScissor可以指定一个新的矩形区域,之后的渲染操作仅会在该区域内进行。如果需要限制渲染内容的区域,glScissor就是实现这一目标的工具。 - 这个矩形区域通常会根据具体的需求来调整,例如可能需要裁剪掉多余的部分,或只渲染屏幕上的一部分。
- 在实际的渲染中,调用
-
实际应用:
- 通过设置
glScissor,可以避免在不需要渲染的区域进行无用的渲染操作,从而提高效率。 - 在绘制某些部分时,如果希望只在特定的区域内进行渲染,可以使用
glScissor来控制渲染的区域,从而实现区域限制渲染。
- 通过设置
总结:glScissor 是 OpenGL 中用于控制绘制区域的函数,能够通过设置矩形区域来限制渲染的范围。在需要对渲染区域进行裁剪或限制时,glScissor 是一个非常有效的工具。
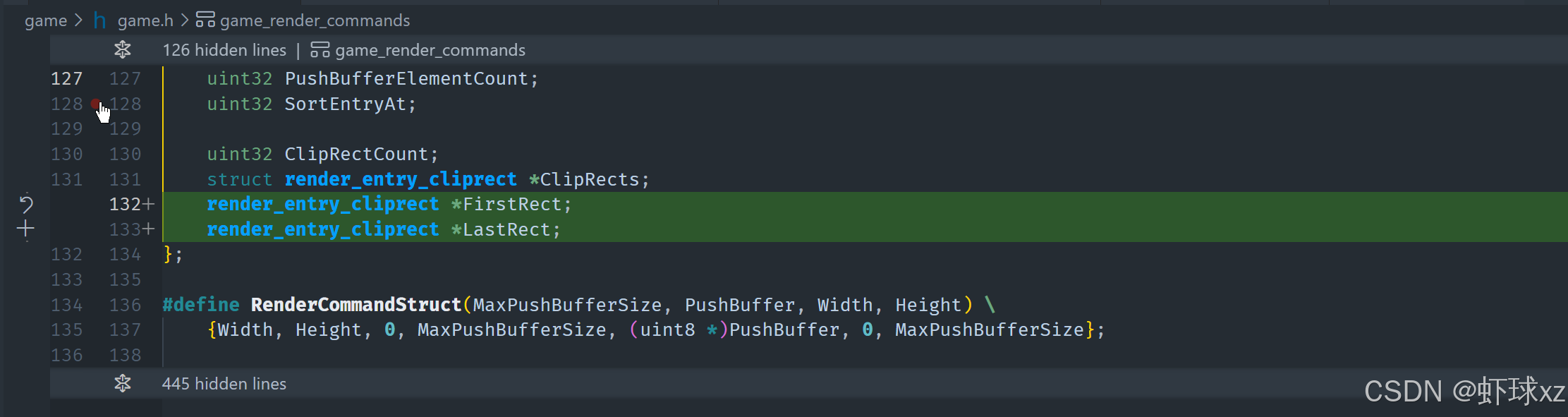
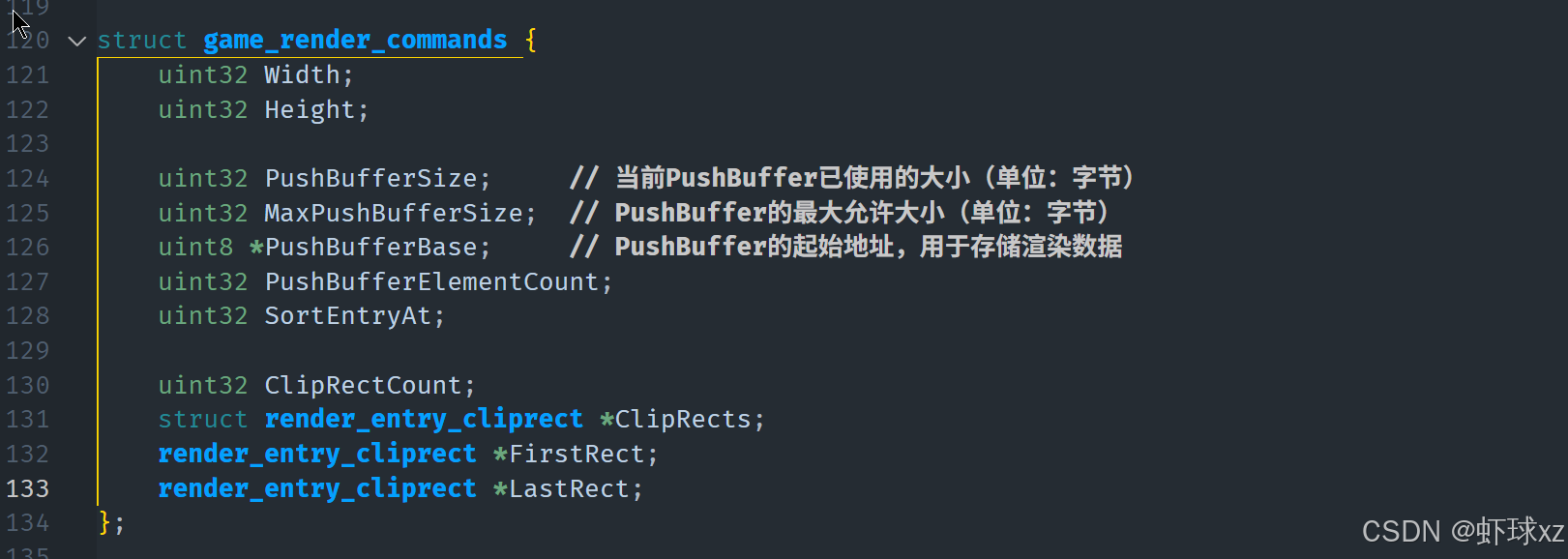
game_platform.h:为 game_render_commands 添加 ClipRectCount 和 *ClipRects
我们决定使用 glScissor 来设置剪裁区域,从而在 OpenGL 中限制绘制范围,以下是具体的设计与实现思路的详细总结:
一、核心目标
我们希望通过 glScissor 对绘制区域进行限制,这样就能在渲染过程中根据需要控制哪些区域可以被绘制,从而支持更复杂的剪裁逻辑(例如多个不同的剪裁区域)。
二、数据结构设计
1. 在 GameRenderCommands 中增加剪裁信息:
- 添加一个新的字段
clip_rect_count表示剪裁矩形的数量。 - 添加一个数组
clip_rects(类型为矩形结构,可能是Rect2i)来保存所有剪裁区域。 - 这些数据将和其他渲染命令一起被传入渲染函数,供后续逻辑使用。
c
u32 clip_rect_count;
Rect2i *clip_rects;2. 新增 RenderEntry 中的剪裁索引字段:
- 每个渲染条目(比如位图绘制命令)中都新增一个
clip_rect_index字段,类型为u16。 - 该字段表示当前绘制条目应该使用哪个剪裁矩形。
三、运行时逻辑
1. 在执行绘制前:
-
检查当前
clip_rect_index是否与之前的一致。- 如果一致,说明剪裁区域未改变,可以跳过。
- 如果不一致,则需要更新剪裁区域,调用
glScissor。
2. 设置 glScissor 的流程:
- 通过
clip_rect_index从clip_rects中取出对应矩形。 - 将该矩形转换为
glScissor所需要的参数(x, y, width, height)。 - 调用
glScissor设置新的剪裁区域。
3. 默认行为:
- 默认情况下设置
clip_rect_index为一个不可能使用的值(如0xFFFF),从而确保第一次绘制时一定会触发剪裁设置。 - 也可以指定索引 0 为"全屏剪裁区域",这样便于初始化或不需要特殊剪裁的条目使用。
4. 安全性检查:
- 每次设置剪裁区域时,先断言
clip_rect_index必须小于clip_rect_count,避免越界访问非法区域。
四、附加说明
uv_offset相关的设计已被移除,不再使用。- 后续要在
RenderGroup中真正创建并管理这些剪裁索引数据结构,确保每个绘制命令都能正确地附带所需的剪裁信息。 - 这样设计之后,在保持渲染效率的前提下实现了灵活的剪裁能力,且不增加渲染命令本身的大小负担(通过索引引用共享剪裁区域)。
总结
我们为实现灵活而高效的剪裁功能,设计了统一的剪裁区域管理方式:所有剪裁区域集中存储,并通过索引应用到具体的渲染命令上,配合 OpenGL 的 glScissor 调用完成实际限制绘制区域的工作。这种设计在保持高性能的同时提供了高度的灵活性,并避免冗余的数据复制。
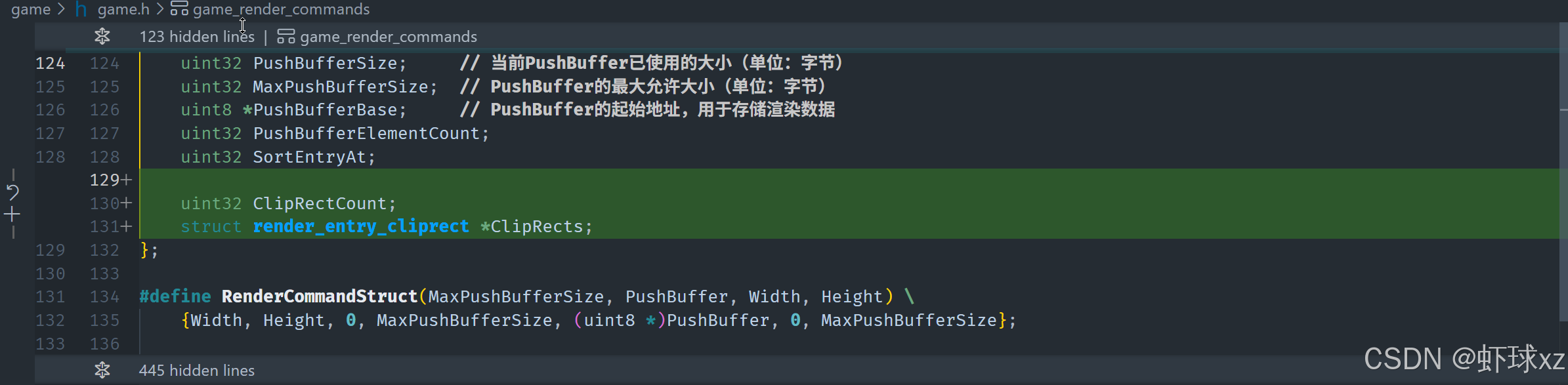
game_render_group.h:引入 game_render_cliprect
我们已经基本完成了对剪裁区域功能的底层支持,但接下来还需要清理并补全一些实现细节,以确保系统可被正常使用与扩展。以下是完整的实现补充与设计细节:
一、GameRenderCommands 中的结构初始化与管理
我们在渲染器中定义了一个结构体 GameRenderCommands,作为核心渲染命令容器。它被暴露在外部,虽然名称可能略显奇怪,但已作为接口的一部分被确定了下来。
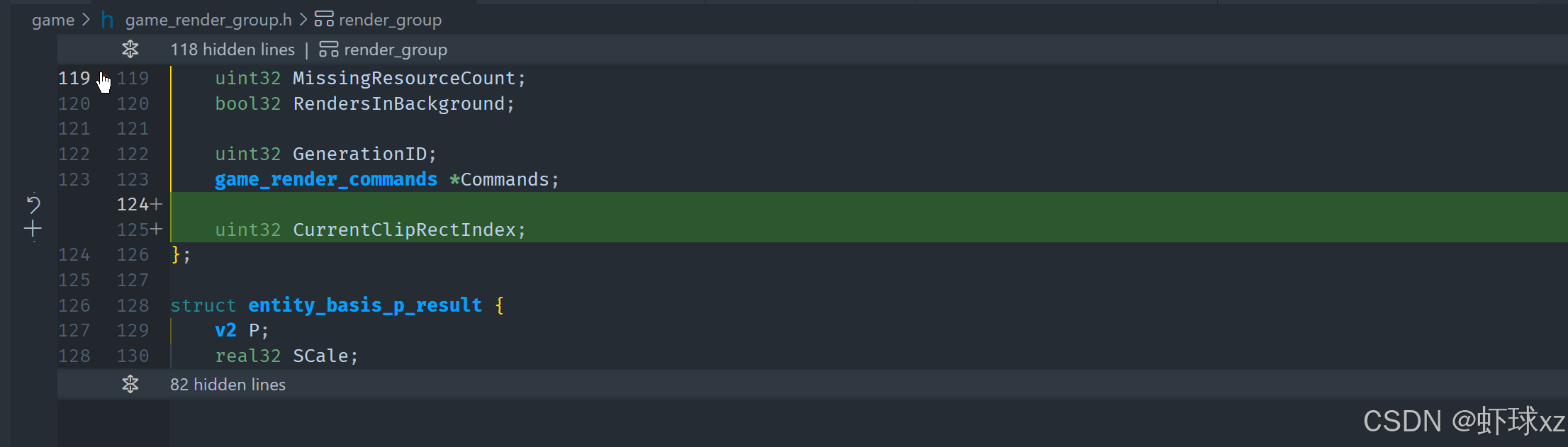
二、剪裁索引初始化与默认行为设置
- 在
RenderGroup结构体中,新增字段current_clip_rect_index,表示当前使用的剪裁区域索引。 - 在
RenderGroup初始化时,将current_clip_rect_index设为 0,表示默认使用第一个剪裁区域(一般是全屏)。
c
render_group->current_clip_rect_index = 0;三、剪裁矩形数组内存分配问题
目前 GameRenderCommands 中的数据是通过手动将结构压入 push buffer 的方式构建的:
- 并未使用内存分配器(如 arena allocator),完全是手动偏移
PushBufferBase与PushBufferSize来操作。 - 这种机制意味着没有自动内存管理,也没有动态扩展能力。
问题:
- 我们在支持多个剪裁区域时需要存储一个剪裁矩形数组
ClipRects。 - 当前系统没有专门的内存分配或扩容策略,不适合直接追加不定长的数据结构。
四、两种解决方案权衡
方案一:硬编码固定数量的剪裁区域
- 在
GameRenderCommands中预留一个固定大小的剪裁矩形数组,比如 256 个。
c
#define MAX_CLIP_RECTS 256
Rect2i ClipRects[MAX_CLIP_RECTS];- 优点:简单、直接、不会增加 push buffer 的复杂度。
- 缺点:浪费内存,不灵活,不能支持大量独立剪裁区域。
方案二:在 push buffer 前预留空间、动态分配
- 在初始化
GameRenderCommands时,使用 push buffer 分配一块内存专门用来保存剪裁矩形。 - 在后续的每次绘制调用中,通过该区域的偏移进行访问和更新。
- 优点:灵活,不受固定数组长度限制。
- 缺点:需要额外逻辑管理这块区域的大小和边界。
目前倾向于第二种方式,避免将来因剪裁区域数量限制造成问题,但这需要稍微改动 push buffer 的使用逻辑。
五、后续计划与注意事项
- 在将剪裁区域数据写入 push buffer 之前,需要提前计算并保留所需内存。
- 所有绘制条目都必须附带当前的
ClipRectIndex,用于在渲染阶段调用glScissor。 - 在渲染阶段还需添加逻辑,用于判断当前是否需要更新
glScissor状态,避免重复调用。
六、总结
我们通过添加 current_clip_rect_index 字段控制当前活跃剪裁区域,并计划以更灵活的方式在 GameRenderCommands 中管理剪裁矩形数组。由于当前系统手动管理 push buffer,我们正在考虑在 push buffer 中显式分配剪裁矩形空间,从而实现可扩展的剪裁支持。虽然内存管理略复杂,但可以实现高效灵活的渲染剪裁机制。
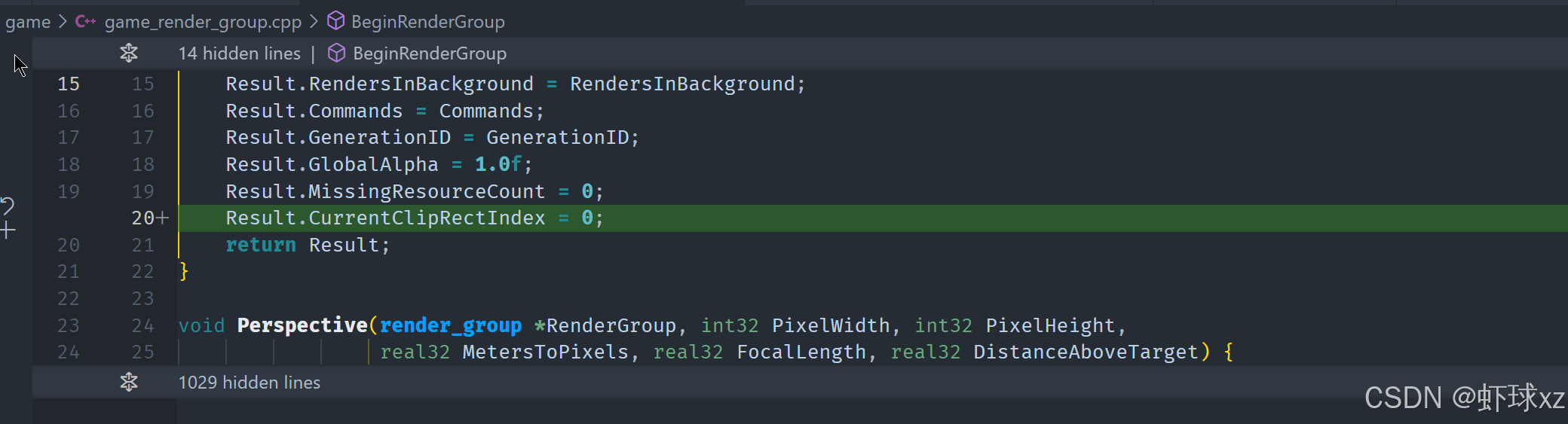
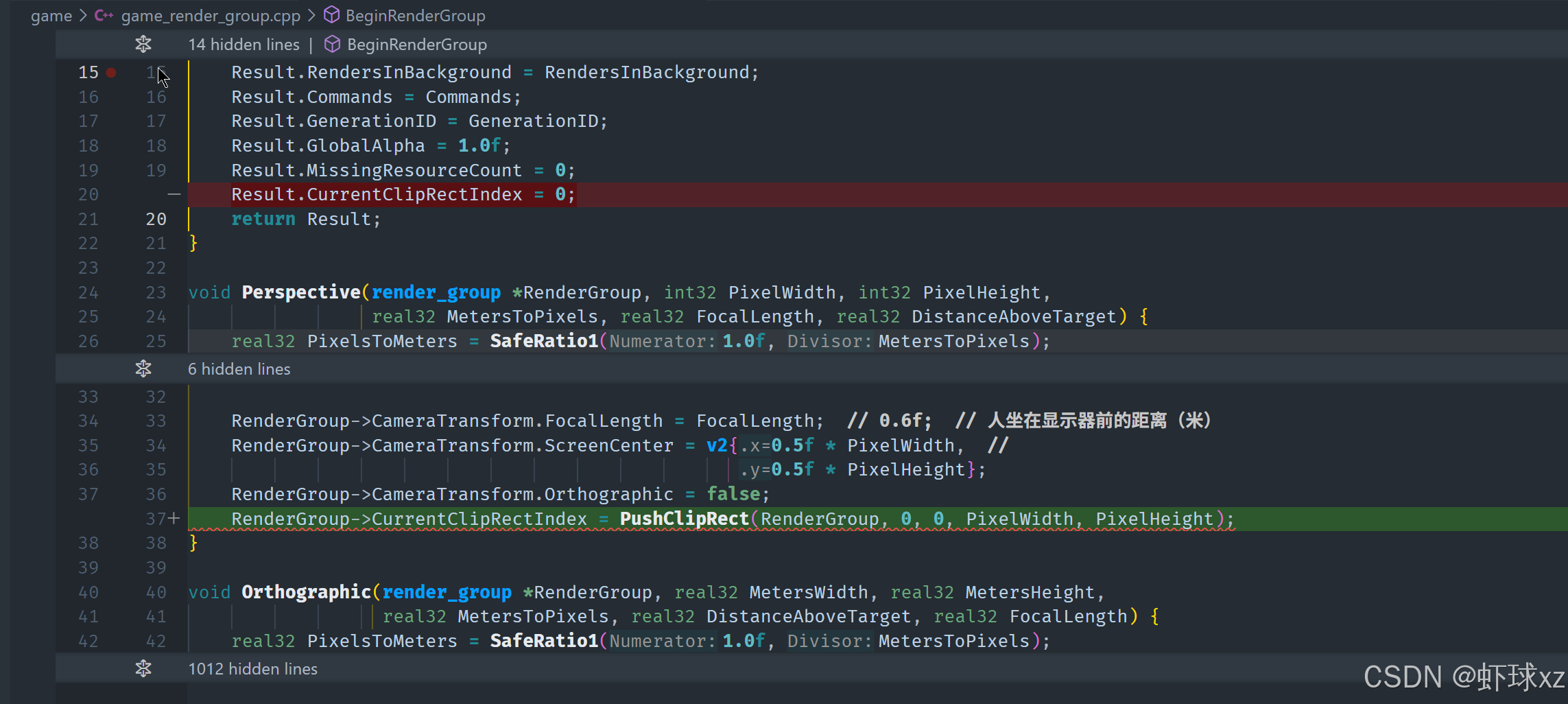
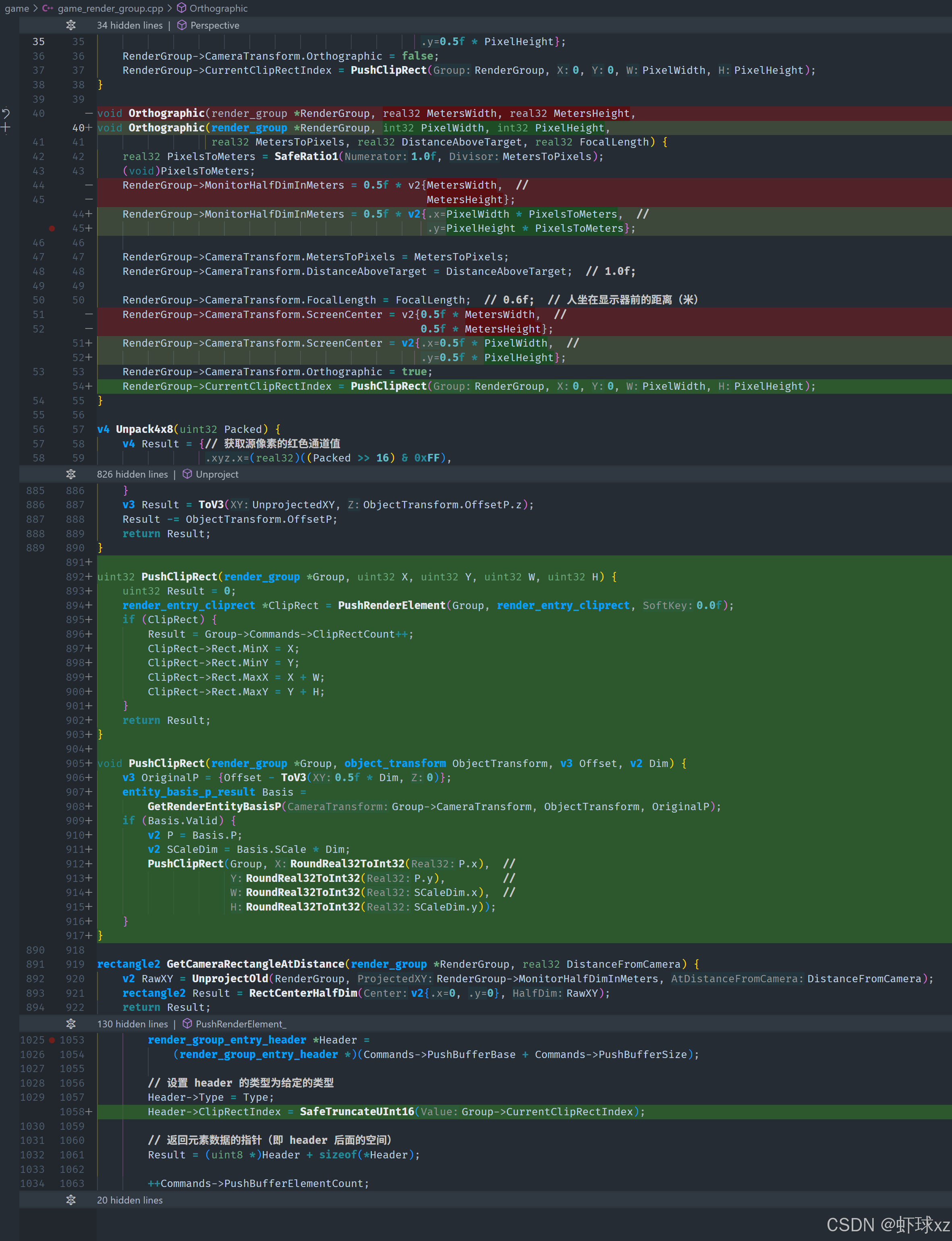
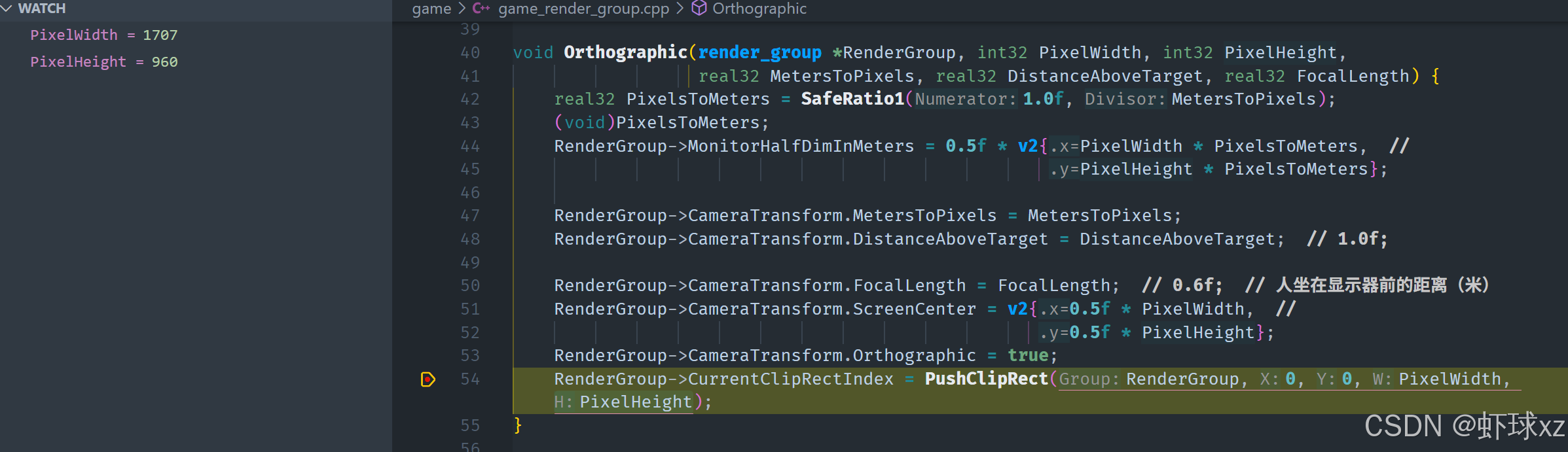
game_render_group.h:在 Perspective 中为整个窗口设置 CurrentClipRectIndex
我们决定采取一种更灵活的方式来支持任意数量的剪裁区域,只要这些区域可以在现有的 push buffer 空间中容纳得下。这种设计允许我们根据需要动态生成和存储剪裁矩形,而不会受到固定数量的限制。以下是具体的设计与实现细节:
一、目标与思路
我们的目标是支持任意数量的剪裁区域(ClipRects),只要它们能装入 push buffer 内部的空间。为此,我们设计了一种新的结构与推送机制。
二、剪裁区域的结构设计
我们设定剪裁区域的存储结构如下:
c
struct RenderEntry_ClipRect {
GameRenderClipRect ClipRect;
RenderEntryHeader Header;
};这个结构体 RenderEntry_ClipRect:
- 包含一个实际的剪裁矩形
GameRenderClipRect,用于记录区域的位置与大小。 - 包含一个
Header,用于链接到渲染命令系统中的下一条命令,实现链式结构或流水线处理。
三、剪裁区域的推送机制
我们添加一个新的推送函数 PushClipRect,该函数会:
- 在 push buffer 中分配一个新的剪裁区域 entry;
- 将对应的剪裁矩形数据写入其中;
- 将该剪裁区域的索引记录在
RenderGroup的状态中,供后续绘制条目使用。
例如:
c
uint16 NewClipRectIndex = RenderGroup->TotalClipRectCount++;
RenderEntry_ClipRect *NewClipRect = (RenderEntry_ClipRect *)PushRenderElement(RenderGroup, RenderEntryType_ClipRect, sizeof(RenderEntry_ClipRect));
NewClipRect->ClipRect = FullScreenRect;
RenderGroup->CurrentClipRectIndex = NewClipRectIndex;四、初始化默认剪裁区域
考虑到系统初始化时还不知道窗口尺寸,因此我们在推送第一个剪裁区域(默认全屏剪裁)时,要在一个能够获得窗口尺寸的位置执行。例如:
- 在第一次实际绘制开始前;
- 或在某个函数调用点,已能访问到窗口宽高。
这样可以将第一个默认剪裁矩形设为整屏大小。
五、状态管理
在 RenderGroup 结构中新增两个状态字段:
CurrentClipRectIndex:表示当前生效的剪裁区域索引;TotalClipRectCount:用于记录已分配的剪裁区域数量,确保每次推送索引唯一。
六、渲染阶段的使用
在渲染阶段,我们根据每个渲染条目附带的剪裁索引,从剪裁矩形表中获取对应的区域,然后通过 glScissor 设置 OpenGL 的裁剪区域。例如:
c
if (CurrentClipIndex != PreviousClipIndex) {
glScissor(clipRect.MinX, clipRect.MinY, Width, Height);
PreviousClipIndex = CurrentClipIndex;
}这种方式避免了重复设置相同的剪裁区域,提高了性能。
七、总结
通过动态将剪裁矩形作为一种渲染条目推入 push buffer,我们实现了对任意数量剪裁区域的支持,且不影响已有渲染管线设计。这种设计保持了灵活性与效率,并为后续的 UI 系统或复杂场景剪裁打下了良好基础。我们只需确保在初始化时插入一个默认的全屏剪裁区域即可保证系统稳定运行。
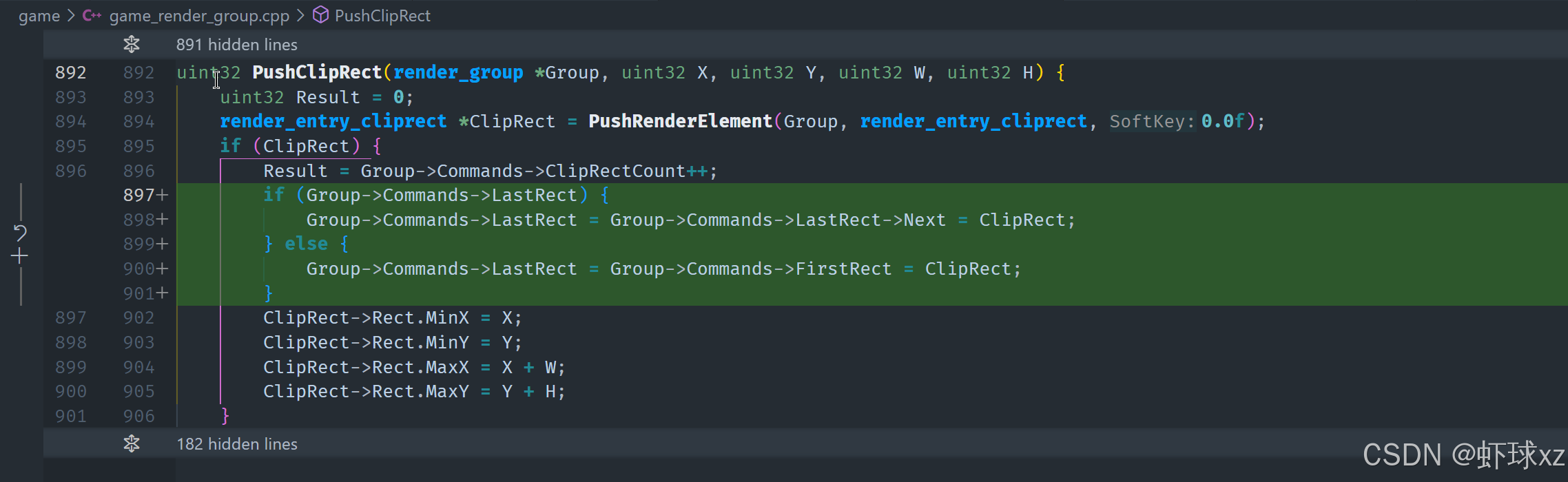
game_render_group.cpp:引入 PushClipRect
我们决定实现一种更灵活、动态的裁剪系统,使得在渲染过程中可以随时推送任意数量的裁剪区域(ClipRects),并且每一个裁剪区域都可以被后续的渲染元素引用。这一设计需要考虑裁剪矩形的存储结构、推送机制、变换应用、ID分配、以及渲染阶段的访问与排序等多个方面,以下是详细的实现与逻辑说明:
一、裁剪区域的推送策略
我们设计了两种方式来推送裁剪区域:
- PushClipRect:直接传入一个矩形区域,不经过任何变换;
- PushTransformedClipRect:传入一个带有变换(Transform)的裁剪区域,适用于需要考虑局部变换的场景。
在推送时,直接写入 push buffer,就像普通的渲染元素一样。这些裁剪区域不参与排序(SortKey 无关),仅用于记录和引用。
二、裁剪区域的结构设计
推送的裁剪矩形结构为 RenderEntry_ClipRect,它只包含一个经过变换或原始的矩形区域数据,类型定义如下:
c
struct RenderEntry_ClipRect {
GameRenderClipRect ClipRect;
};这个结构体被视为一种标准的渲染元素(RenderEntry),能够统一加入到 push buffer 队列中。
三、唯一编号与引用系统
每当推送一个新的 ClipRect:
- 会将当前的
RenderGroup->TotalClipRectCount作为该裁剪区域的唯一编号返回; - 然后裁剪计数递增,为下一个分配准备;
- 后续任何希望引用该裁剪区域的元素,只需使用这个编号即可。
这种方式允许我们动态地推送任意数量的裁剪区域,并保持对每个区域的准确引用。
四、整数截断与安全性检查
为了保证裁剪区域坐标在合理范围内,使用了 SafeTruncateUInt32ToUInt16 等安全截断机制。这样在调试过程中可捕捉非法值,同时防止渲染时发生内存越界或不可见区域绘制。
五、在渲染阶段的访问与重组
由于裁剪区域和其他渲染元素一样被插入 push buffer,它们在内存中的位置可能是离散的。而渲染系统要求裁剪信息可以被快速访问,因此需要将这些裁剪区域提取出来、重组为一个紧凑的数组:
- 在渲染流程中,我们会遍历整个 push buffer;
- 找到所有的
RenderEntry_ClipRect并提取其数据; - 将它们按编号顺序整理成一个新的数组,便于索引;
- 后续渲染元素通过索引值引用这个裁剪数组进行快速裁剪判断。
六、渲染排序与限制
虽然裁剪区域本身不参与排序,但渲染排序(SortKey)在裁剪后仍然有效。我们只需确保在裁剪区域生效之后的渲染元素才会使用它,从而保证排序与裁剪逻辑正确无误。
七、缓存友好性设计
在构建裁剪区域数组时,我们特别强调数据的缓存友好性:
- 将所有有效的裁剪区域按顺序整理成紧凑数组;
- 减少随机访问带来的缓存抖动;
- 提高 GPU 或 CPU 的裁剪运算效率。
八、最后的整合流程
在渲染流程末尾(如 EndRenderGroup 或 RenderCommandsToOutput):
- 遍历 push buffer;
- 提取所有
RenderEntry_ClipRect; - 构建编号到矩形的映射表;
- 然后开始正常渲染流程,每个元素根据其绑定的裁剪编号查表裁剪。
九、总结
这套裁剪系统实现了一个统一且高度灵活的机制:
- 任意时刻可以插入新的裁剪区域;
- 裁剪区域可绑定局部变换;
- 每个裁剪区域自动分配编号;
- 渲染时可快速访问所有区域;
- 在性能、扩展性和数据结构合理性之间达成了平衡。
整个系统的核心思想是将裁剪区域与渲染元素视为同类操作统一处理,最大限度减少特殊路径和分支逻辑,从而保持渲染代码简洁而高效。
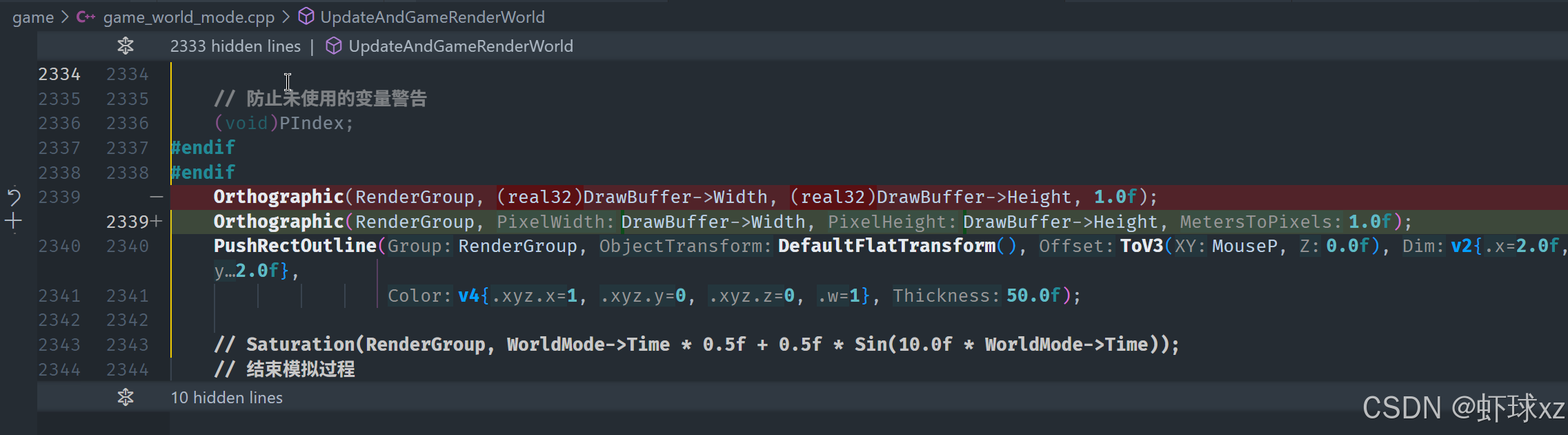
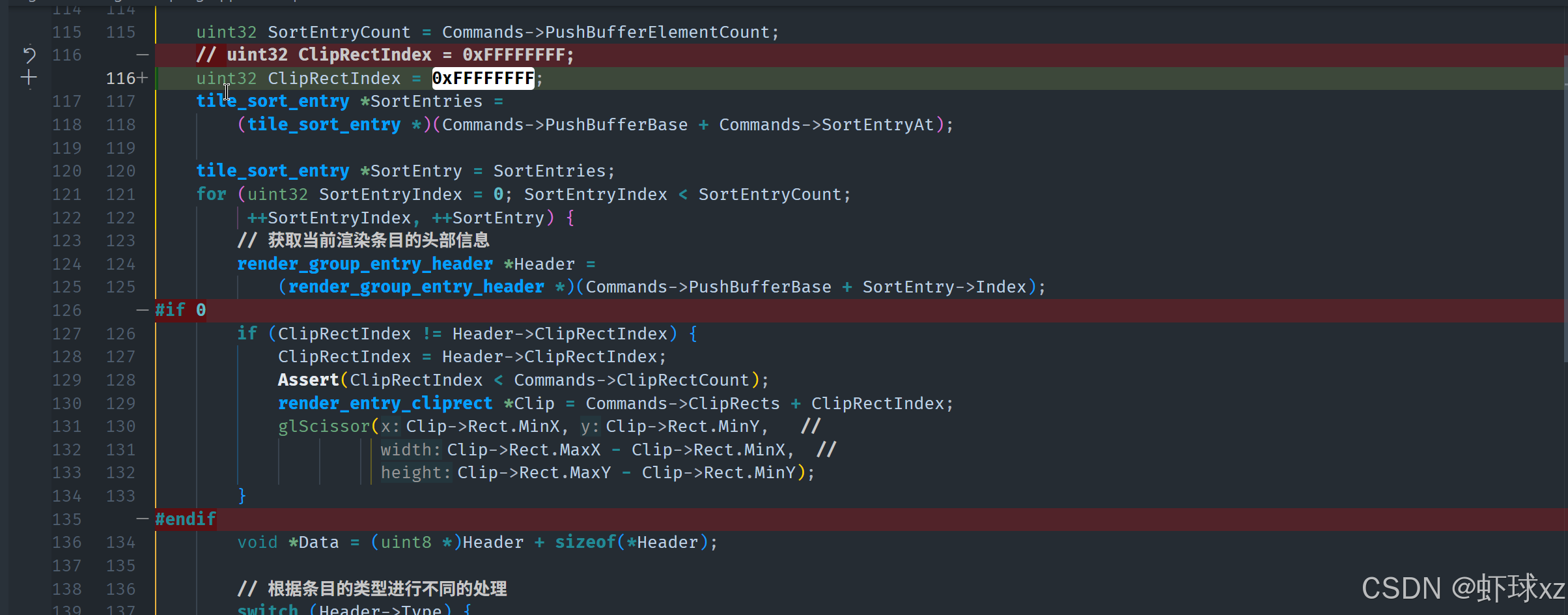
改了Orthographic 传进去的为像素先看看有没有问题
没问题再把注释掉的打开
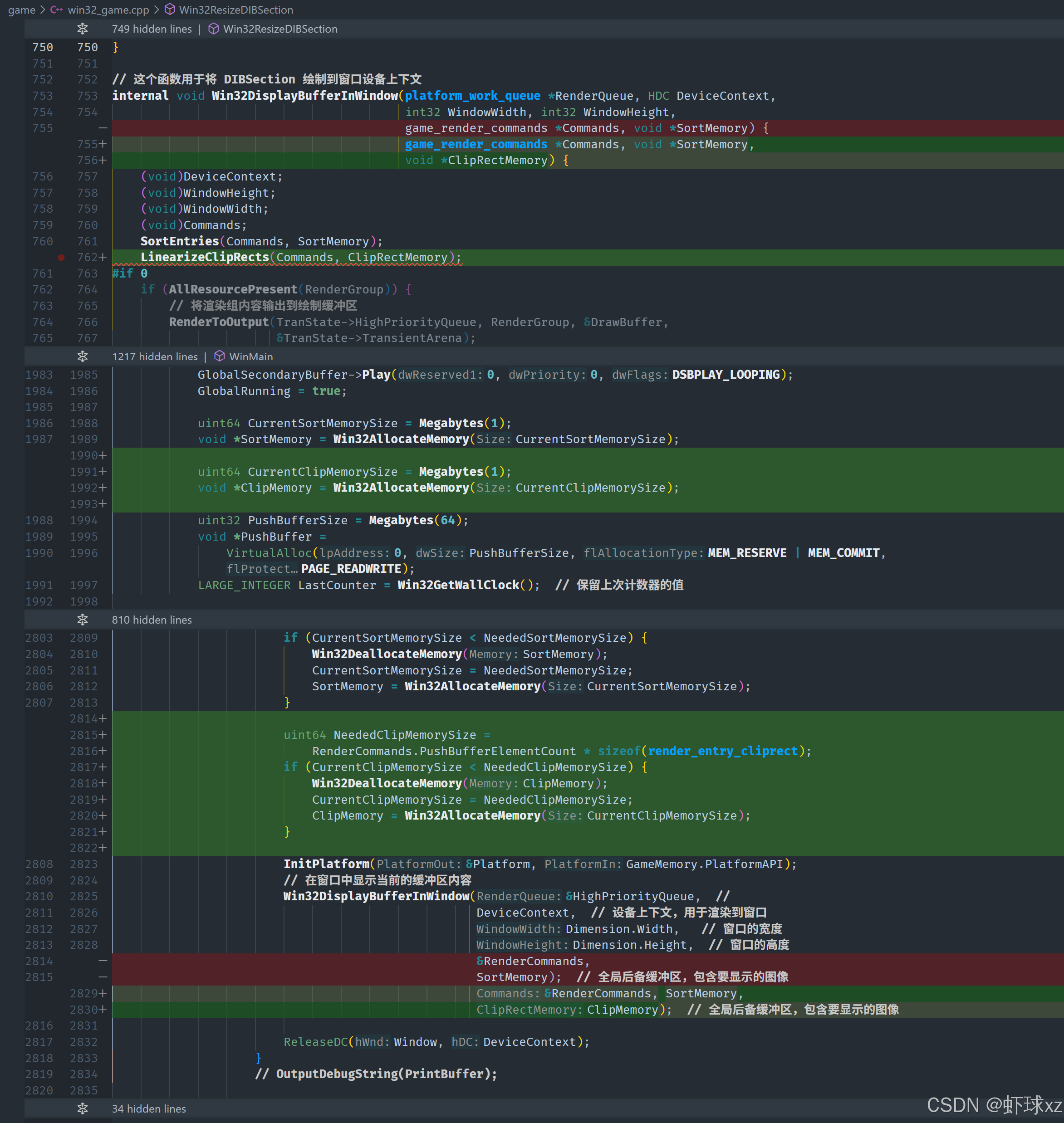
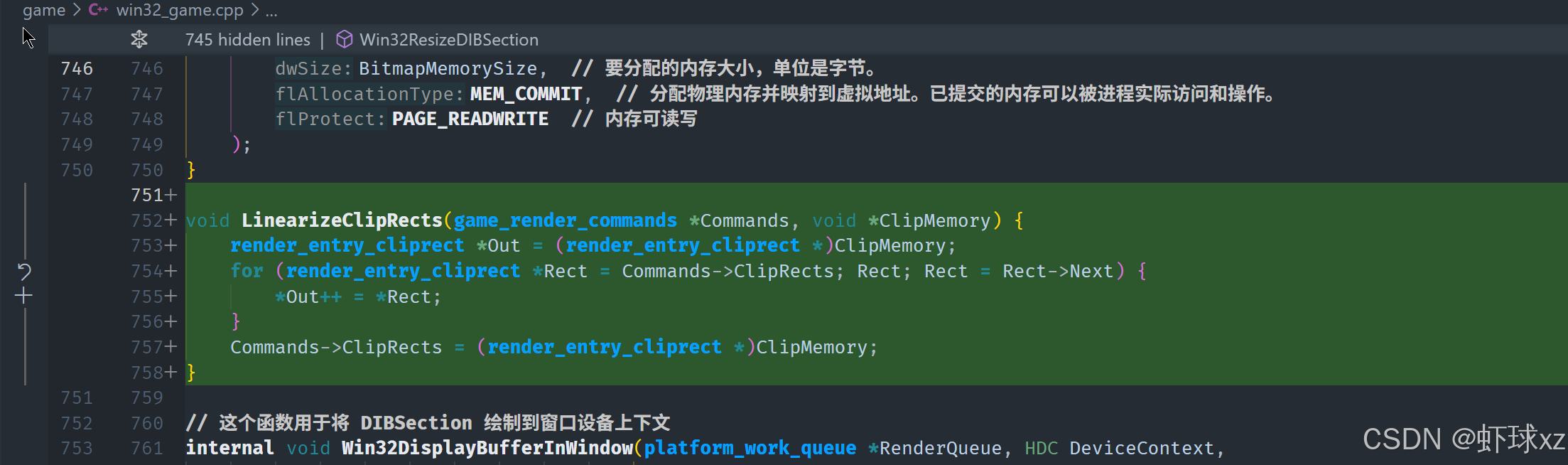
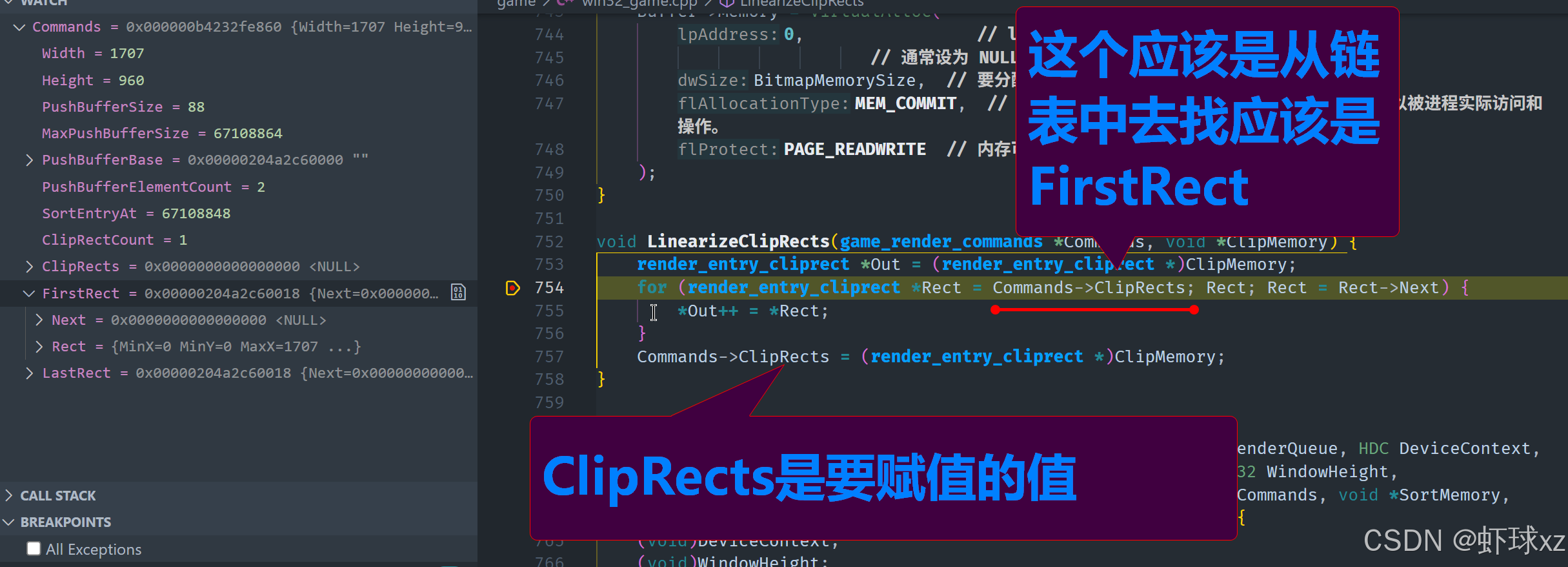
win32_game.cpp:让 Win32DisplayBufferInWindow 接受 ClipRectMemory 并调用 LinearizeClipRects
在渲染过程中,我们需要对推送的裁剪区域(ClipRects)进行排序,并将其按线性顺序存储到缓冲区中,确保它们能高效地用于后续渲染。以下是详细的流程与实现方法:
一、裁剪区域排序与存储
渲染的过程中,首先会调用 SortEntries 来对渲染元素进行排序。这一过程会影响到裁剪区域的排序,因此我们需要一个类似的机制来处理裁剪区域的排序。
- 排序:裁剪区域将按照一定的规则进行排序,并存入内存。排序的操作将确保裁剪区域以合理的顺序存放,便于高效访问。
- 线性存储 :裁剪区域的内存布局需要是线性的,这样可以确保裁剪数据能够快速地被提取和渲染。通过
CopyClipRects函数,可以将裁剪区域线性化,存储到合适的内存缓冲区中。
二、内存管理
为了处理这些裁剪区域,我们需要一块专门的内存区域来存储它们:
- 裁剪内存 :我们需要为裁剪区域分配内存,这块内存区域被称为
clip memory。它用于存储所有裁剪区域,确保在渲染时能够快速访问。 - 当前内存 :除了常规的排序内存,我们还需要一个
current clip memory变量,来动态地跟踪当前使用的裁剪区域内存位置。
三、避免额外开销的设计
在设计时,考虑到不想为每个裁剪区域的头部添加过多的额外数据(如指向裁剪区域的指针),我们选择将所有裁剪区域统一存储并通过内存管理进行访问。这样做虽然稍微复杂,但避免了不必要的数据冗余和额外开销。
四、渲染中的实际操作
在渲染时,所有的裁剪区域数据会被传递到 linear asset(线性资源)中。这是通过将裁剪区域拷贝到一个连续的内存区域(缓冲区)来实现的,从而使得渲染时能够迅速地获取这些区域的信息。
- 裁剪区域复制 :每次进行渲染时,裁剪区域会通过
linear asset进行复制,确保它们按顺序被处理。 - 使用内存:在实际使用过程中,所有的裁剪区域内存会以线性方式存储,便于快速访问。
五、总结
整体设计上,我们实现了一个高效的裁剪区域管理系统,通过排序和线性内存存储来提高渲染效率。每个裁剪区域都被存储到专门的内存中,按需排序并传递到渲染流程中。通过避免在每个裁剪区域头部添加过多的数据,我们优化了内存布局,减少了额外的开销。
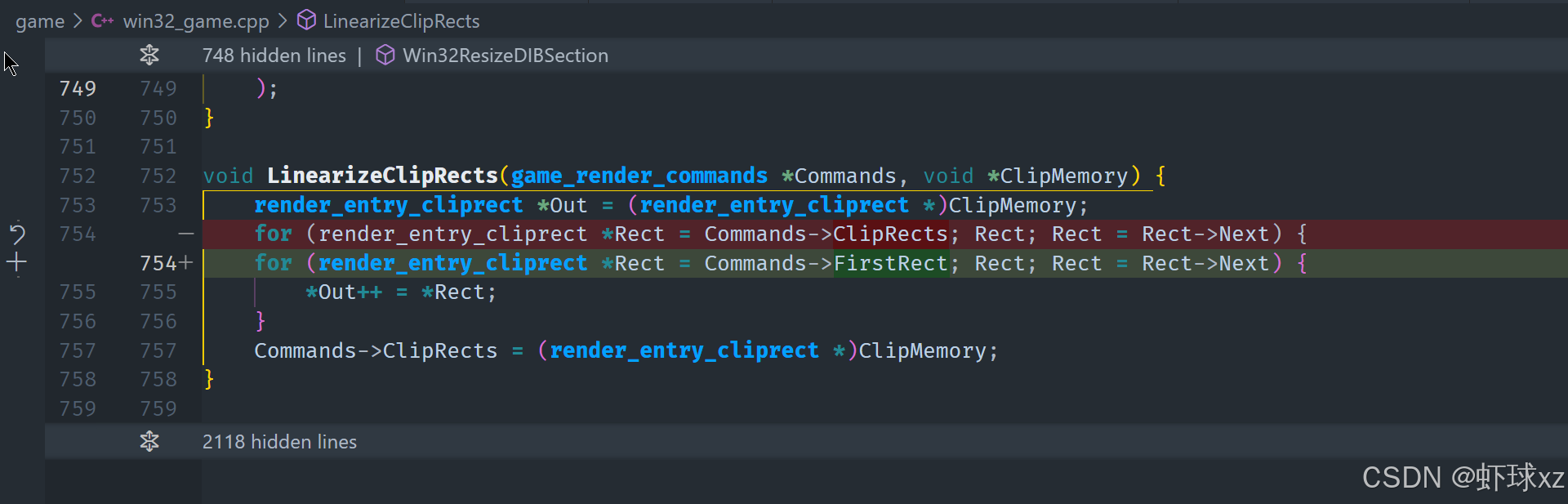
game_render.cpp:引入 LinearizeClipRects
在渲染过程中,我们需要对裁剪区域(ClipRects)进行线性化处理,以便它们能够更高效地存储和访问。以下是处理这些裁剪区域的详细步骤:
一、线性化裁剪区域
-
初始化裁剪区域指针:首先,我们为每个裁剪区域创建一个指针,并开始遍历这些指针。这些指针会指向具体的游戏条目(Game Entry)中的裁剪区域。
-
线性化过程:接下来,遍历这些指针,将它们按照顺序线性地排列成一个扁平化的列表。这个过程会将裁剪区域从分散的推送缓冲区(Push Buffer)中提取出来,压缩成一个临时内存区域,便于后续快速查找。
-
使用临时内存:通过将裁剪区域转化为线性存储方式,我们能够将这些区域组织成一个查找表,从而在渲染过程中更加高效地访问它们。
二、管理链表和指针
为了管理这些裁剪区域,我们使用了一个链表结构,每个裁剪区域会包含一个指向下一个裁剪区域的指针(Next Pointer)。该链表会用于链接裁剪区域,以便在后续操作中能够快速地访问它们。
-
链表结构:每个裁剪区域都会有一个指针,指向下一个裁剪区域,形成一个双向链表。这样可以在渲染过程中轻松地遍历裁剪区域。
-
初始化指针:在处理裁剪区域时,首先检查链表是否为空。如果为空,则将当前裁剪区域设置为链表的头部和尾部。如果链表非空,则将当前裁剪区域附加到链表的末尾。
-
命令中的管理:这些链表指针会被保存在渲染命令中,这样多个组件可以同时读取和更新裁剪区域的信息。
三、内存管理和推送操作
在实际渲染时,裁剪区域会被存入一个共享的内存区域,这个区域将会在多个渲染命令之间进行读取和更新。每个裁剪区域会根据需要被插入到合适的位置,确保它们能够在渲染过程中按正确的顺序处理。
-
渲染命令中的处理:在渲染过程中,裁剪区域的指针会传递给渲染组(Render Group)。渲染组负责处理这些裁剪区域的内存分配、排序和链接操作。
-
处理链表:渲染组内部会根据当前状态更新链表的指针,确保裁剪区域的正确顺序。每次操作都会检查链表是否为空,并根据情况将新的裁剪区域插入到链表的末尾。
四、优化与未来改进
当前的实现已经能够通过链表和线性化存储来高效地管理裁剪区域。然而,有时可能需要进一步优化,例如减少不必要的数据冗余或改进内存管理,以确保渲染过程更加高效。
-
避免冗余指针:虽然每个裁剪区域都包含一个指向下一个区域的指针,但我们也在考虑是否可以通过其他方法减少这些指针的数量,避免额外的内存开销。
-
内存分配优化:未来可以对内存分配策略进行优化,例如更好地管理裁剪区域的内存,以减少内存碎片并提高缓存命中率。
五、总结
总的来说,通过将裁剪区域线性化存储并使用链表管理指针,我们能够在渲染过程中高效地处理裁剪区域。这种方法确保了裁剪区域能够快速访问和更新,同时保持了渲染操作的高效性。虽然当前方案已经能够满足需求,但仍然可以进一步优化内存管理和指针操作,以提高系统的整体性能。
运行游戏,遇到 InvalidDefaultCase
在处理渲染命令时,我们希望跳过某些操作,不将这些操作输入到排序流中。为了实现这一点,需要进行一些调整,确保这些命令不会被处理或参与到排序操作中。
一、跳过无关的渲染命令
我们不希望某些渲染命令进入排序流,因此在处理这些命令时,不需要调用通常的缓存条目操作。相反,我们希望直接跳过这些命令,只推送一些占位符或空白空间,这样就可以避免它们的处理。
二、调整推送渲染元素
原本在处理渲染时会调用"推送渲染元素"操作,但现在考虑到跳过某些命令,可以选择直接推送而不需要进一步处理。这样可以通过简单的操作来推送命令,而不调用复杂的渲染元素缓存和排序流程。
三、排序条目的优化
考虑到排序操作可能会涉及很多不必要的额外开销,一种优化思路是将类型字段放到排序条目的顶部4位,这样在进行排序时,不需要额外的读取和查找操作。这种优化可以减少不必要的计算,提高效率。
四、简化排序条目结构
为了进一步提高效率,可以考虑简化排序条目的结构。例如,可以考虑不再存储渲染命令的头部信息,而是将所有类型信息存储在排序索引中,这样不仅可以避免冗余的存储,还能加快排序处理的速度。
五、总体思路
通过对渲染命令和排序条目结构进行优化,能够减少不必要的计算和内存开销,从而提高渲染系统的性能。特别是在处理不需要参与排序的命令时,能够有效避免不必要的操作,使渲染过程更加高效。
game_render_group.cpp:在 PushClipRect 中加入溢出保护
在这段内容中,目标是进行一些图形渲染与管理操作,重点在于如何确保图形组件不出现溢出问题。首先,计划通过"渲染条目"和"裁剪"来处理图形元素。这里的核心思想是不涉处理,也不需要在某些图形元素中插入其他内容。
为了确保渲染过程的正常运作,主要的任务是防止溢出。具体来说,要确认在渲染区域内,图形元素的大小不超出范围,因此,必须在考虑渲染尺寸的同时,确保它能够适应容器。如果所有图形元素能适配并且没有溢出,那么渲染过程将正常工作。
在处理"剪辑破坏"的部分时,要避免将其列入不必要的列表。这意味着要进行某些转换操作,例如将一些数据从一个结构中剔除,或者按照需求进行索引管理。这样一来,可以更好地控制图形元素的更新与添加,尤其是当需要动态增加图形元素时。
另外,使用"组命令"来管理渲染流程也是一个需要注意的点。这样做可以确保渲染操作的协调性和一致性。
具体到推送的实现,如果想要通过调用一个矩形的形式进行操作,考虑到这些元素的大小和颜色问题,通常这些图形元素没有具体的"z轴"高度,且颜色也不重要。只要能够正确计算这些图形元素的尺寸并将其正确推送到渲染系统,就能确保系统正常运作,甚至可以通过调整大小或其他参数来使其符合需求。
最后,这些操作的整体目标是优化渲染的稳定性和灵活性,确保即使添加新的图形元素,系统也能正常处理并避免任何渲染溢出的问题。
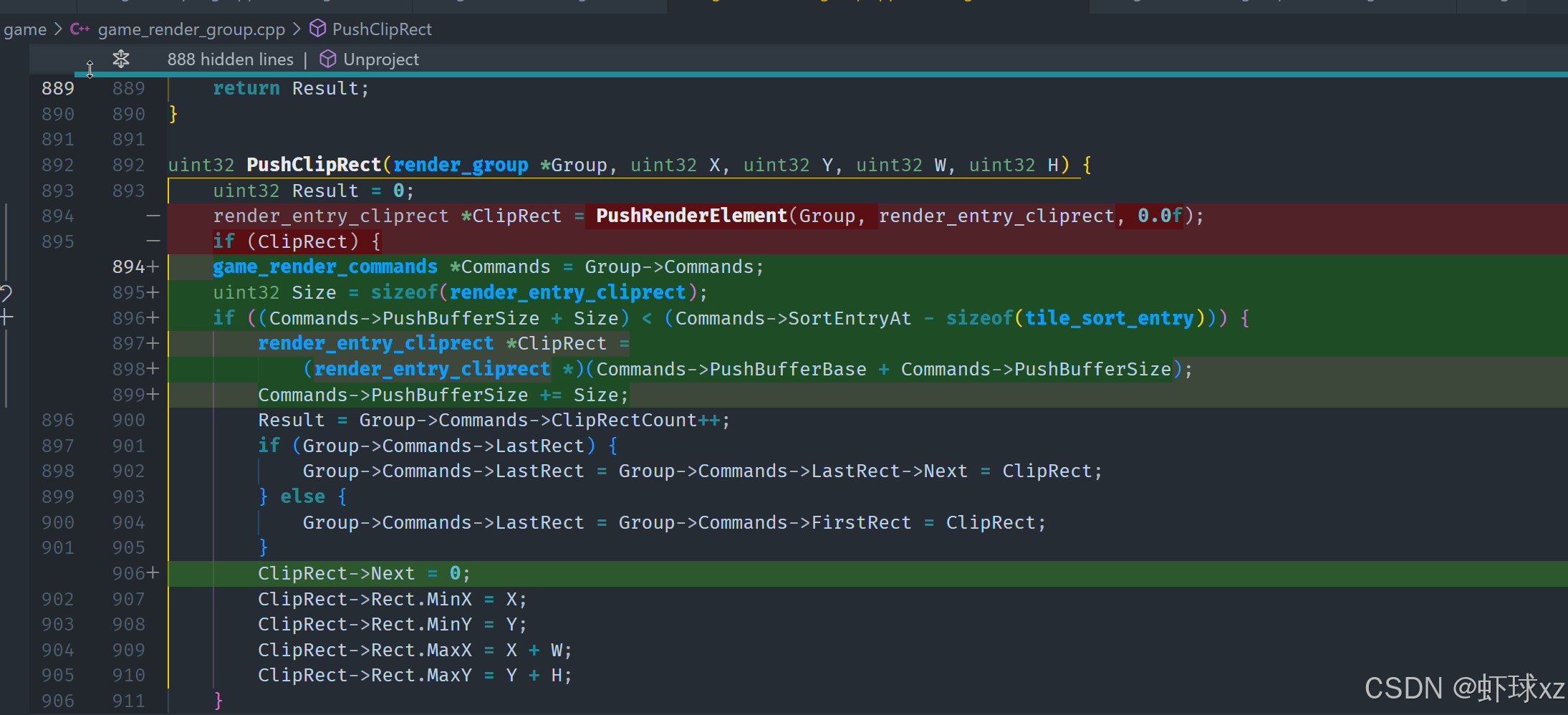
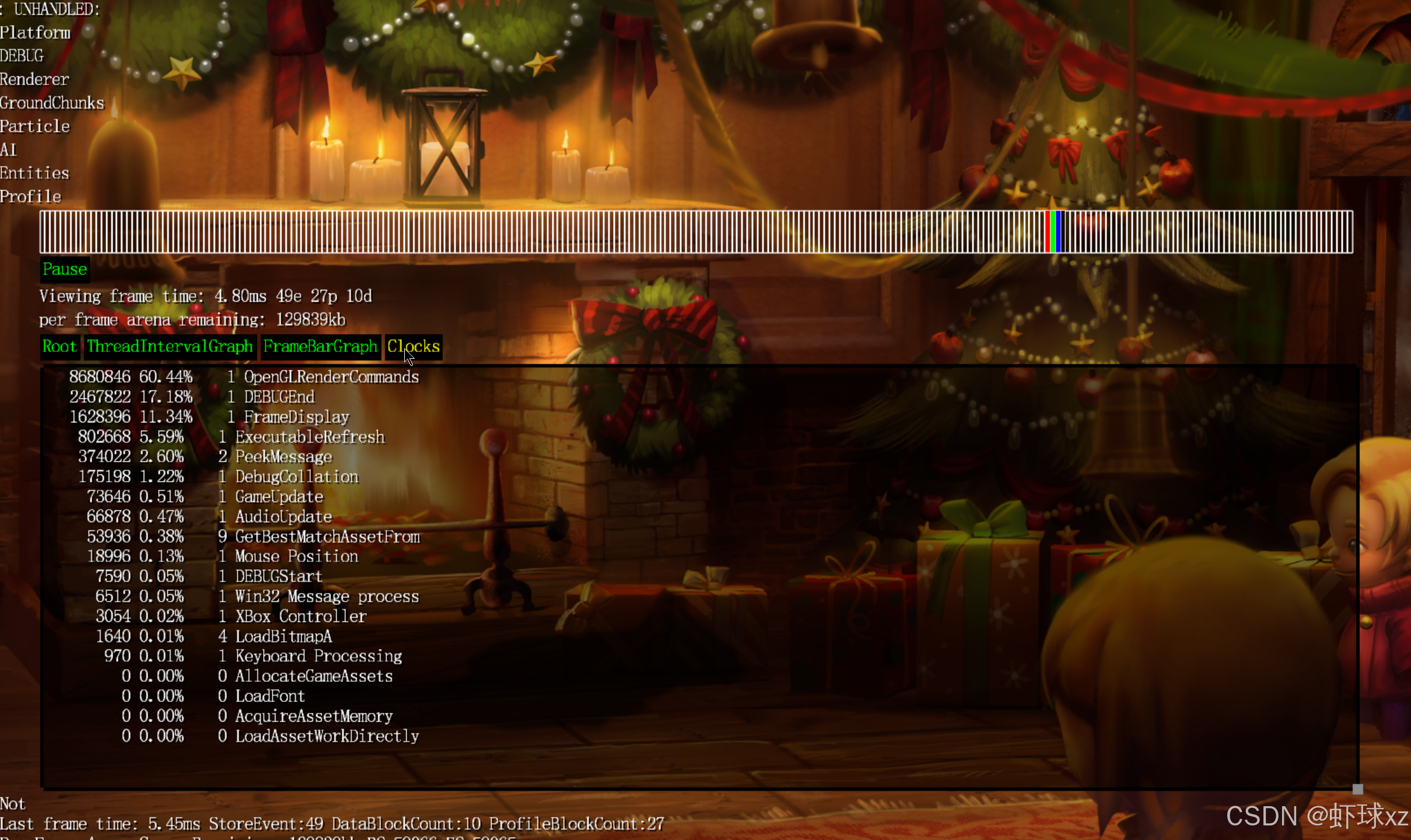

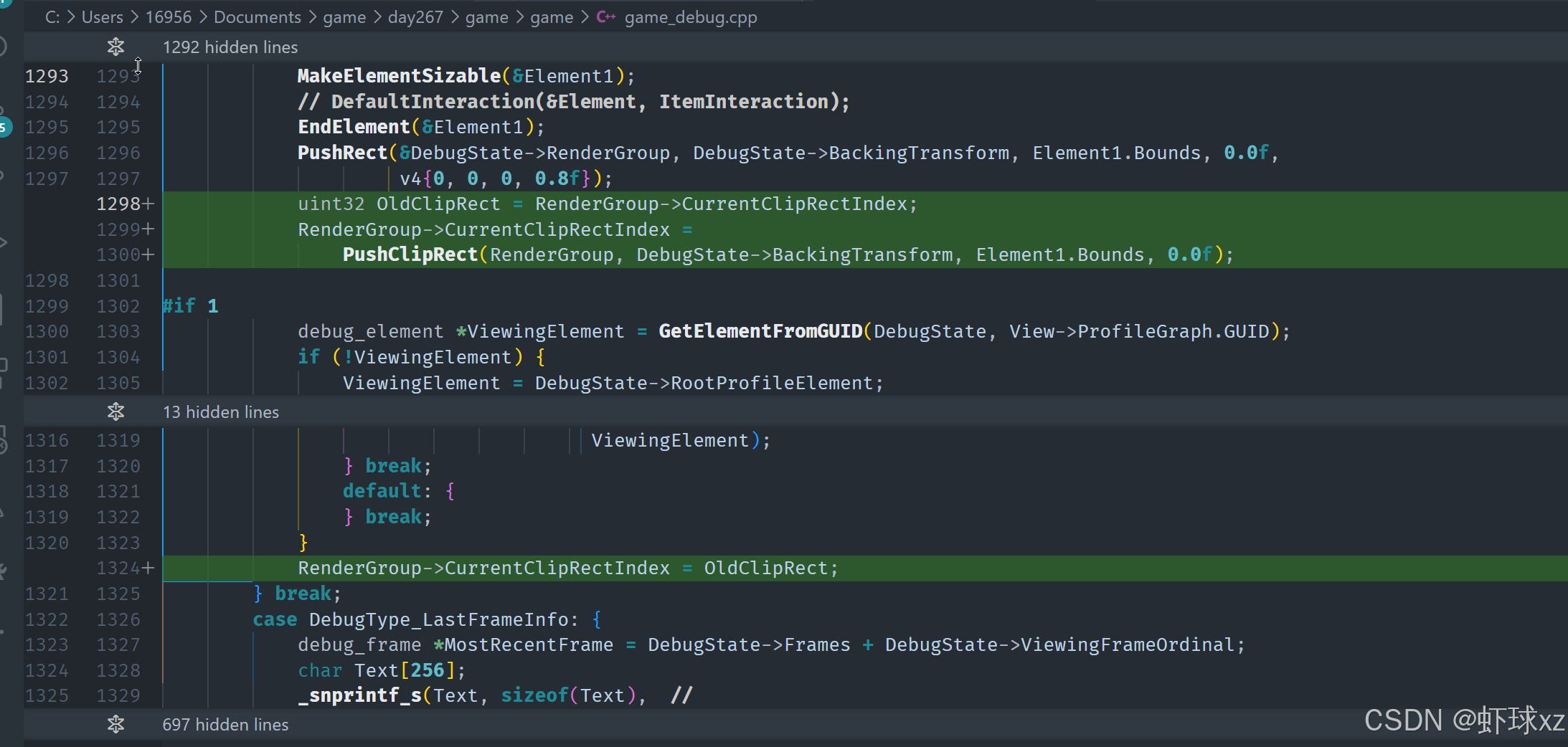
game_debug.cpp:在 DrawTopClocksList 中调用 PushClipRect
在这一段内容中,核心目标是实现对 push_rect 操作的尝试性集成,尽管当前预期它不会立即成功,需要在后续进行调试和修复。主要的思路是,当进入一个具体的流程(与 vp 和 bug 相关)并准备保存某个"DrawTopClocksList"时,尝试在创建矩形元素时,同时进行一次剪辑区域的设置操作。
流程如下:
- 在创建矩形元素时 ,会对其执行一次
push_rect操作,同时还需要为它设置一个对应的剪辑区域(clip rect)。 - 这通过调用
PushClipRect实现,初步阶段是手动实现,后续可能封装为一个小工具函数进行复用。 - 先定义一个
OldClipRect,这个变量来自当前的渲染组(render group)中的剪辑区域。 - 然后设置
RenderGroup->CurrentClipRectIndex为一个新的"剪辑区域"索引值,这个索引来源于push到当前渲染组中的操作。 - 这个新推入的剪辑区域使用的坐标和尺寸值与绘制该矩形时所使用的完全一致,实现区域的一致性。
- 此剪辑矩形不需要颜色值,只需空间坐标与范围。
- 这种做法本质上是一个"推入"和"弹出"机制,在图形堆栈中进行维护,方便后续的还原与切换。
- 同时,需要初始化一个变量,并标记其为
true,用于追踪状态或控制流程。
随后,出现了一个小问题------变量被误删,或者变量维度(dim)不匹配,导致出错。通过编译器的反馈发现原因在于使用的是不同维度的对象,进行了修正。
总结来说,这一部分重点是把剪辑区域与渲染的矩形元素绑定起来,在图形管线中同步推进,从而实现更细致的可视区域控制,并为未来的调试和功能增强打下基础。整体思路是逐步推入剪辑信息,保持图形输出的一致性和可控性。
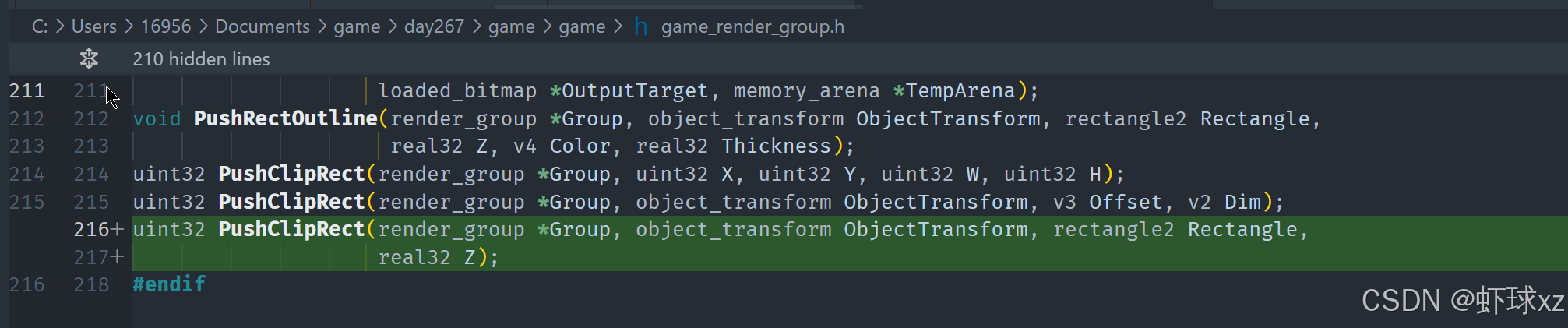
调试器:单步查看 ClipRectIndex 的值
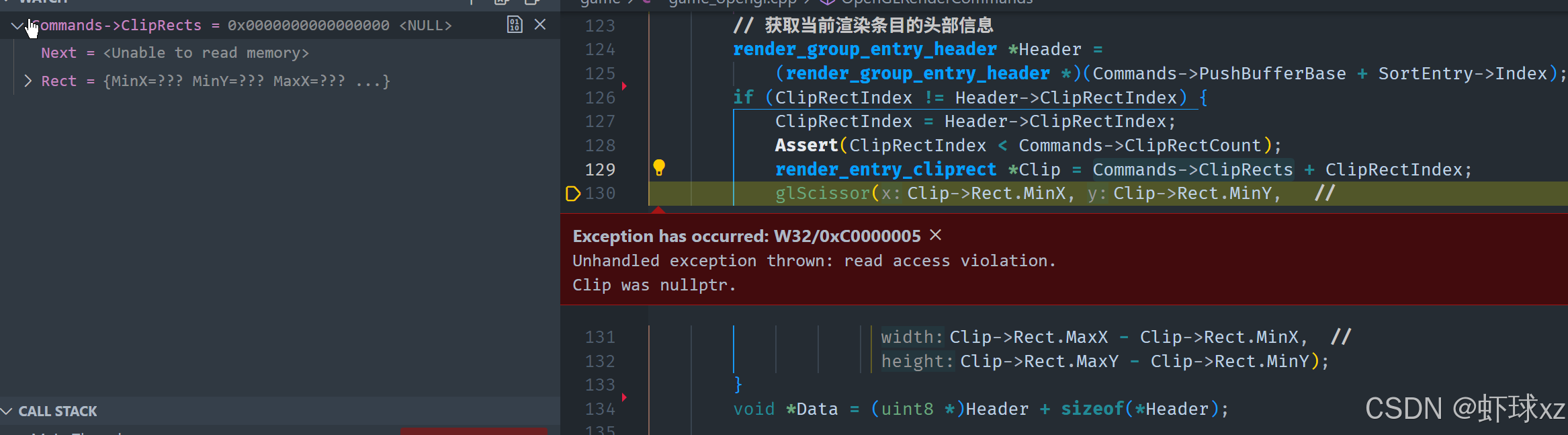
目前的状态是,渲染中的剪辑操作还没有正常工作。理论上,如果流程正常运行,那么某些区域应该已经被成功裁剪,也就是说,图像渲染结果中应该能明显看到裁剪生效的效果。然而现在并没有出现预期中的裁剪行为,说明还存在问题,需要进一步调试,这部分计划留到明天进行处理。
当前观察到的情况是,剪辑矩形(clip rect)的设置虽然已经尝试执行,但系统中所实际使用的剪辑范围仍然是全屏大小。这种情况与预期不符,因为已经设置了新的剪辑矩形索引,理应使用新的裁剪区域。当前索引值从默认的 0 切换到了 1,但实际上索引为 1 的剪辑矩形范围依然是全屏,说明新的矩形设置没有正确生效或被正确引用。
从渲染数据中可以看到,已经存在试图进行裁剪的记录,但这些记录并没有真正带来裁剪效果,问题可能出现在以下几个方面:
- 新推入的剪辑矩形没有被正确设置(即尺寸、位置不对);
- 剪辑矩形已经设置成功但没有被实际引用;
- 渲染管线中的某些步骤忽略了新设置的剪辑信息;
- 剪辑索引虽然变了,但对应的数据仍然是旧的内容或默认全屏设置。
因此,后续调试的重点是确认新设置的剪辑矩形是否被正确写入、更新和应用在渲染管线中,以及查看是否有逻辑或顺序问题导致被忽略。
另外,也计划处理一些与 Habermas 理论相关的问题,包括阅读相关材料和回答相关提问。这部分内容将和图形渲染的调试工作并行进行。整体目标是在确保渲染正确性的同时,推进理论知识的理解与讨论。
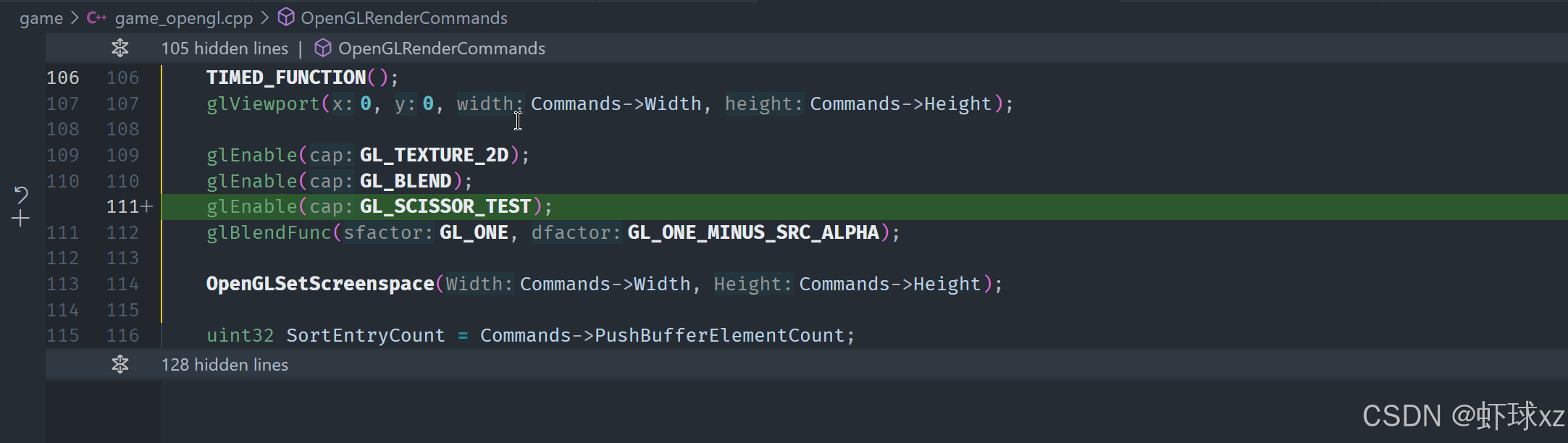
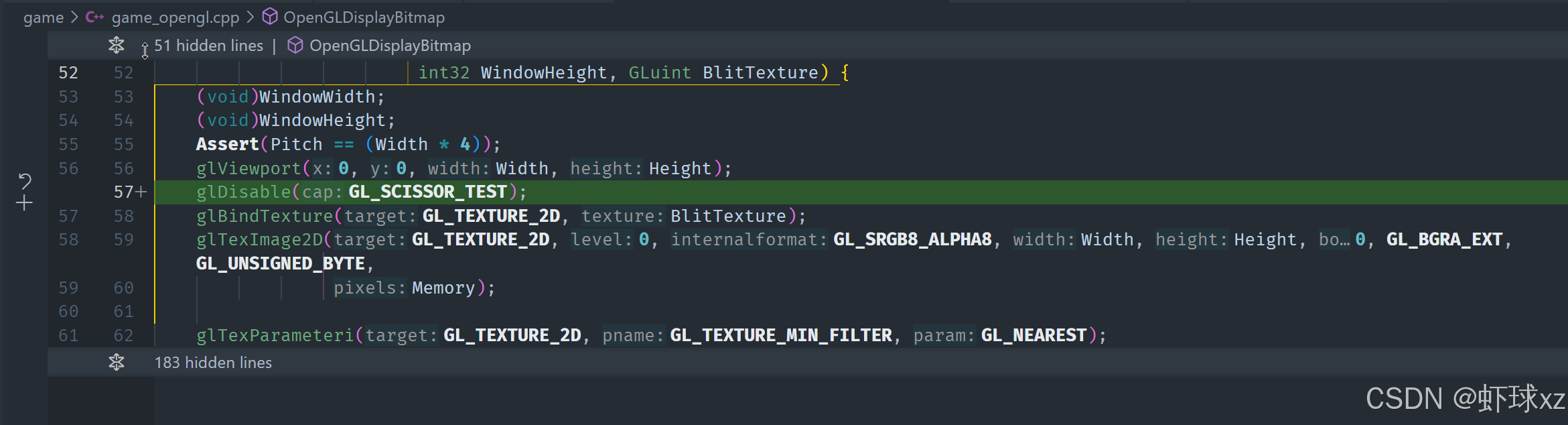
game_opengl.cpp:启用 GL_SCISSOR_TEST
当前遇到的问题核心在于"裁剪操作"(scissor test)没有生效,进一步排查后发现原因可能是从未启用 OpenGL 中的 glScissor 功能。glScissor 是一种用于设置局部渲染区域的机制,但它在默认情况下是关闭的,只有在明确调用 glEnable(GL_SCISSOR_TEST) 后才会真正起作用。
当前的渲染初始化流程中,虽然设置了剪裁矩形区域,但在初始化渲染状态(例如设置初始状态或执行渲染前的设置)时,忽略了对 GL_SCISSOR_TEST 的启用。因此,所有设置的 glScissor 区域实际上没有被 OpenGL 所采纳,导致整个屏幕仍然处于未裁剪状态。
这意味着:
- 即便调用了
glScissor并设置了区域,若没有启用GL_SCISSOR_TEST,这些设置是完全无效的; - 渲染效果仍然会覆盖整个帧缓冲(framebuffer),无法限制到所设定的局部矩形区域;
- 实际观察到的"没有裁剪生效"的现象正是由此引起;
- 需要在渲染系统初始化阶段,显式添加对
GL_SCISSOR_TEST的启用逻辑; - 可能遗漏了在启用列表中加入
glEnable(GL_SCISSOR_TEST),或者状态被中途清除导致不起效。
此外,怀疑可能是在某个设置状态的流程中遗漏了这个步骤,比如在执行 setup 或 init_state 相关逻辑时,未包含对裁剪测试的处理。
总结而言,修复的关键在于:确保在所有使用 glScissor 的渲染上下文中,先执行一次 glEnable(GL_SCISSOR_TEST),这样后续设置的裁剪区域才会生效,从而实现局部渲染和防止图形内容越界绘制的问题。
奇怪

怎么是零呢
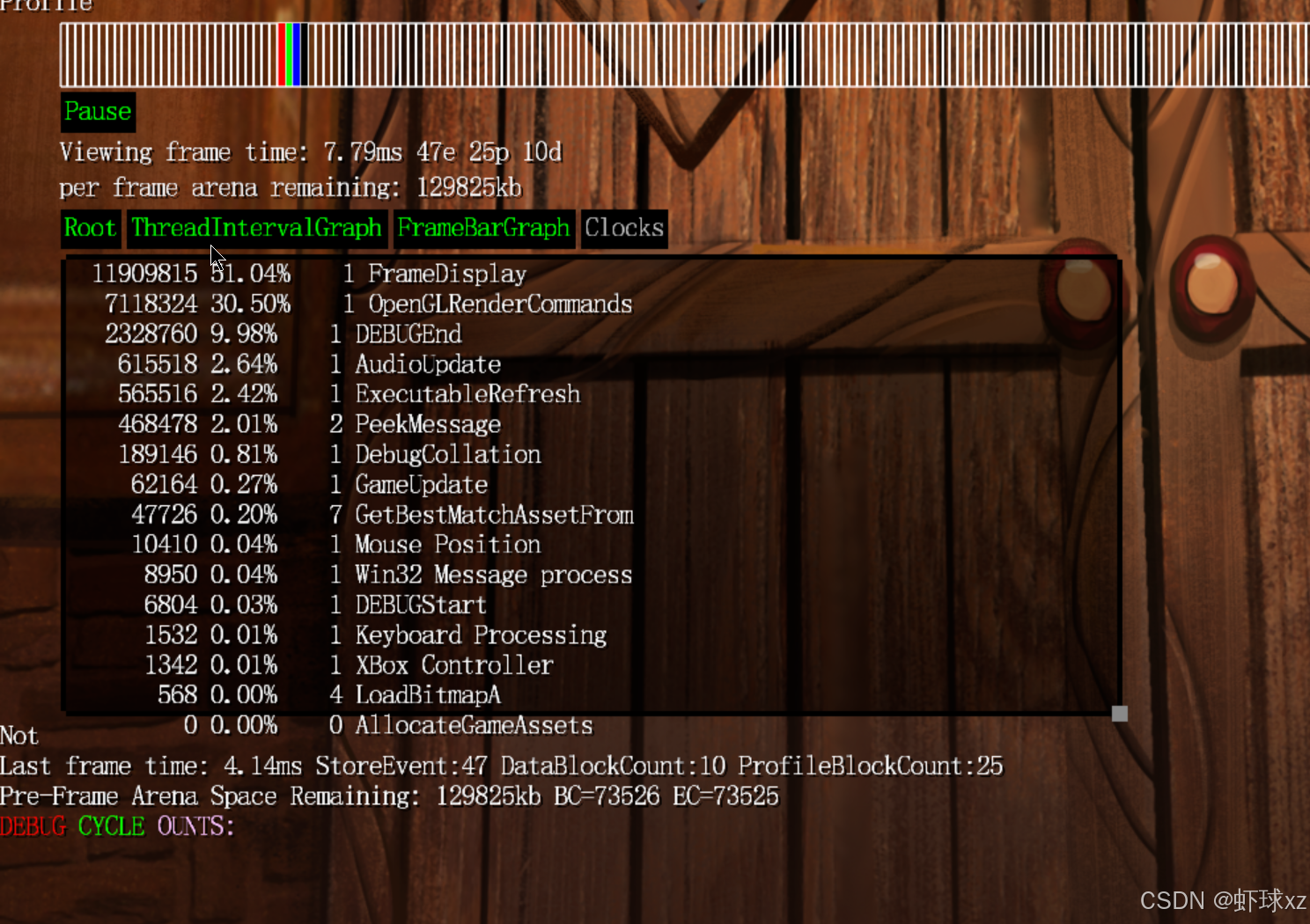
查看正确裁剪的分析器
现在的渲染系统中,裁剪功能已经正常工作,经过调试发现,第一次的设置实际上就是成功的,尽管过程看起来不太像是正确的,但结果确实是有效的。目前图形渲染已经可以实现局部裁剪区域,这标志着 glScissor 功能被正确启用并开始发挥作用。
当前还存在的唯一问题,是在使用软件渲染器(software renderer)时,裁剪功能还没有被正确支持。这意味着虽然硬件加速的渲染路径已经能够识别并执行 glScissor 设置,实现裁剪功能,但软件渲染的分支还未实现对这部分逻辑的处理,导致切换到软件渲染平台时无法生效。
具体观察到的行为是,当切换到软件渲染模式时,虽然仍然启用了 GL_SCISSOR_TEST,但实际并没有看到预期的裁剪效果。由此推测:
- 软件渲染路径中未实现与
glScissor等价的逻辑裁剪操作; - 软件渲染器仍然在处理整个帧区域的绘制,而不是参考指定的裁剪矩形;
- 当前状态下,系统仍然保留了硬件渲染路径中的状态(例如
glEnable的结果),但软件渲染部分并不会使用这些状态; - 需要手动实现一套逻辑判断,在软件渲染分支中加入类似的矩形区域检测,从而手动跳过不在裁剪范围内的像素处理。
因此,后续的改进任务包括:
- 在软件渲染器中实现对当前剪辑矩形的处理逻辑;
- 确保在切换平台时(例如从硬件到软件),状态的一致性不会被破坏;
- 修复因保留
GL_SCISSOR_TEST状态而导致的行为错误或视觉差异; - 验证平台控制逻辑,确保渲染路径之间的功能对等。
总之,目前裁剪功能在硬件渲染路径中已经正常启用并生效,接下来需要补全软件渲染部分的支持,以确保所有渲染平台在功能行为上保持一致。
game_opengl.cpp:在 OpenGLDisplayBitmap 中禁用 GL_SCISSOR_TEST
当前在使用 OpenGL 进行屏幕渲染(如 blit to screen 或类似操作)时,存在一个问题:OpenGL 的裁剪测试(GL_SCISSOR_TEST)仍然处于启用状态。然而在这种情况下,并不希望该测试生效,因此在执行这类操作前,需要显式地禁用裁剪测试,否则可能会影响最终的输出或造成视觉上的错误。
进一步观察发现,当切换渲染后端为软件渲染器时,图形不再执行区域裁剪,说明软件渲染路径没有正确处理剪辑信息。目前软件渲染器并没有被告知需要依据特定区域进行裁剪,也就是说,虽然逻辑上已经在系统中设置了裁剪矩形,但该设置并未传递给软件渲染模块,导致其依然渲染了完整区域,忽略了剪辑范围。
问题可以归纳如下:
- 在使用 OpenGL 进行屏幕绘制时 ,应确保不受
GL_SCISSOR_TEST的干扰,这意味着需要在进入该流程前调用glDisable(GL_SCISSOR_TEST); - 软件渲染路径中,尚未接收或处理任何来自系统的剪辑区域信息;
- 当前的剪辑设置逻辑只影响了 OpenGL 渲染路径,但没有同步至软件渲染器;
- 结果是:在使用软件渲染器时,裁剪无效,全部内容被渲染,缺乏与 OpenGL 渲染器的一致性;
- 为了解决这个问题,必须在软件渲染流程中加入类似 OpenGL
scissor功能的逻辑,根据设定的矩形区域裁剪绘制范围。
接下来的工作包括:
- 在
blit或其他屏幕输出前确保禁用裁剪测试,避免不必要的干扰; - 更新软件渲染器,使其支持基于设定剪辑矩形的绘制限制;
- 确保两种渲染路径(OpenGL 与软件)对相同渲染状态的响应是一致的;
- 将当前的剪辑矩形索引与实际的矩形数据传递给软件渲染模块,使其能够依据这些数据判断像素是否应被绘制。
整体目标是使系统在不同渲染后端之间切换时,仍能保持功能和渲染效果的一致性,避免出现一种路径下有裁剪而另一种路径无裁剪的现象。
软件渲染
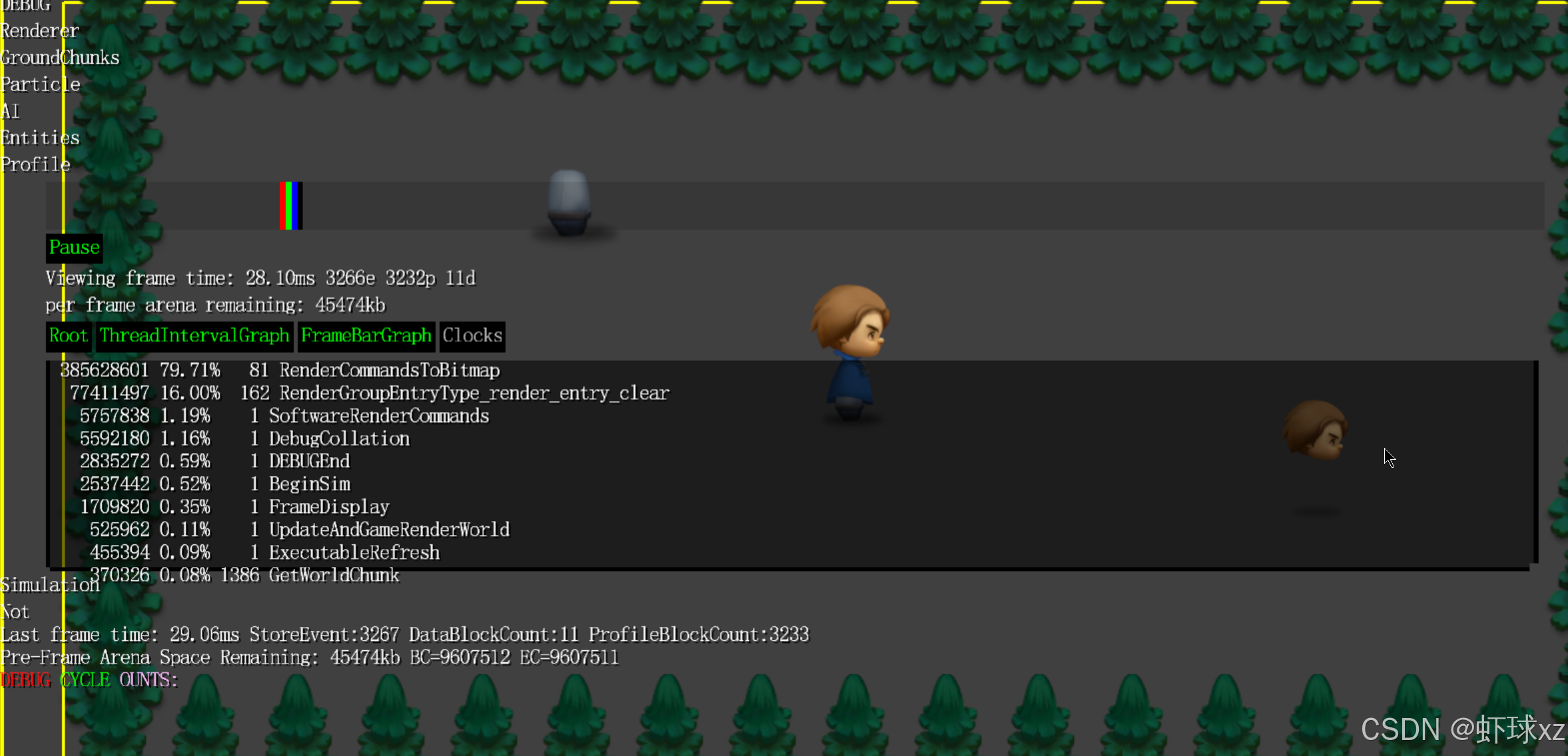
game_render.cpp:在软件渲染器中实现裁剪功能
当前正在处理的问题是软件渲染器在绘制位图(bitmap)时没有正确应用剪裁区域(clip rect)。尽管渲染指令中确实有传入 clip rect,并且函数调用中也能看到剪裁矩形被传递,但实际行为中并没有真正使用这个 clip rect,也就是说,传入只是形式上的,渲染逻辑没有依据它进行像素裁剪。
进一步观察发现,目前只有在瓦片式渲染(tiled render)流程中使用了这个剪裁矩形,而在其它路径中,特别是在常规软件渲染中,并没有更新 clip rect 的内容,仍然使用了默认或未初始化的区域。这就导致在非瓦片路径下,所有渲染操作都没有裁剪限制,像素会被绘制到整个缓冲区中。
计划的解决策略如下:
- 把当前的
clip rect视作一个"基础裁剪区域"(base clip rect); - 在渲染每一帧 bitmap 或每一组命令时,基于当前上下文的"基础裁剪区域"动态更新
clip rect; - 效果类似于 OpenGL 渲染路径中实时设置裁剪矩形(即
glScissor)的方式,只不过软件渲染器中需要手动处理这个逻辑; - 每当获取到一个 bitmap 渲染命令时,就重新设置当前
clip rect为基础区域的交集; - 不再使用单独的状态切换逻辑(如
glBlit中的裁剪重置),而是在实际绘制前就更新到正确的矩形范围。
所需的具体操作包括:
- 明确在 bitmap 渲染命令或其他 draw call 过程中,对当前
clip rect进行更新; - 将这个更新嵌入在渲染流程前端逻辑中,而不是在低层细节或平台特定的实现里处理;
- 确保与 OpenGL 渲染路径行为一致,也就是每次绘制前都根据上下文重新应用裁剪区域;
- 如果已有瓦片渲染使用了类似逻辑,可以复用或抽取公共裁剪更新函数以提升一致性和可维护性;
- 保证所有软件渲染输出在逻辑上都被限制在正确的
clip rect范围内。
最终目标是使所有软件渲染路径都能与 OpenGL 渲染路径保持一致的裁剪行为,确保图像绘制受到当前有效矩形区域的限制,防止绘制溢出或错误区域渲染。
黑板:交错的瓦片绘制问题
当前正在处理软件渲染中的裁剪问题,尤其是在采用瓦片渲染(tiled rendering)策略的情况下。整个渲染系统将屏幕划分为多个区域(tiles),由不同线程并行处理,每个线程负责各自的 tile 区域进行绘制。这种方式提高了效率,但也引入了裁剪逻辑的复杂性。
问题在于:除了 tile 自身的边界限制,还存在一个由渲染命令(如 bitmap draw call)指定的逻辑裁剪区域(clip rect)。为了确保每次绘制操作不会越界或干扰其它 tile,需要将这两个裁剪区域结合处理,也就是进行矩形的交集裁剪。
解决方案如下:
-
识别两个裁剪区域来源:
- 一个是瓦片系统提供的 tile 范围,称为"tile clip rect";
- 一个是具体渲染命令传入的裁剪区域,称为"command clip rect"。
-
执行矩形交集操作:
- 使用已有的数据结构
rectangle2i(整型二维矩形)进行操作; - 通过
Intersect函数将两者合并为一个最终有效的裁剪矩形,保证同时受到 tile 限制和命令逻辑限制。
- 使用已有的数据结构
-
更新 render group 的裁剪矩形格式:
- 原始的裁剪矩形存储方式可能是通过 min/max 坐标定义;
rectangle2i提供了更简洁的封装,直接包含 min(左上角)和 max(右下角);- 需要将旧的裁剪矩形转换为
rectangle2i类型,保持结构统一,方便后续操作和传递。
-
适配 OpenGL 的裁剪测试逻辑(如 glScissor):
- OpenGL 使用
glScissor(x, y, width, height)来设置裁剪区域; - 而
rectangle2i使用 min/max 坐标; - 因此必须从 min/max 坐标推导出 OpenGL 所需的宽高参数(width = max.x - min.x,height = max.y - min.y);
- 实现两个系统之间的坐标转换与兼容。
- OpenGL 使用
-
实际渲染前应用这个新的交集裁剪区域:
- 在每次处理渲染命令前先计算交集;
- 然后将交集区域作为当前帧或当前线程的裁剪区域传入绘制逻辑;
- 确保每个线程只绘制它负责的 tile 区域,并且只绘制需要被显示的那一部分内容。
整体来说,当前逻辑通过使用统一的数据结构(rectangle2i)和裁剪区域交集操作,有效提升了渲染系统中裁剪的准确性与一致性,既支持并行瓦片渲染,又尊重每条绘制指令的逻辑边界。此举将显著提升渲染正确性,尤其是在复杂 UI 或多层渲染场景中。
查看分析器,确认两个渲染器都支持裁剪
目前完成了对软件渲染器中裁剪逻辑的修复和完善,确保其与 OpenGL 渲染器在行为上一致。整个过程如下:
-
验证 OpenGL 渲染器未受影响:在对裁剪逻辑进行调整后,首先回到 OpenGL 渲染路径,确保其渲染输出没有出现错误或偏差,确认新的实现没有破坏已有功能。
-
切换回软件渲染路径进行测试:在完成对软件渲染路径中裁剪逻辑的更新之后,回到该路径下进行实际验证。
-
软件渲染器裁剪生效:裁剪效果如预期般正常运作,图形内容被正确限制在指定区域内,不再溢出或渲染到不该渲染的区域。此时说明两个系统(OpenGL 和软件渲染器)都已经正确应用了新的裁剪逻辑。
-
裁剪逻辑统一完成:
- 利用
rectangle2i数据结构统一表示裁剪区域; - 在绘制前对 tile 区域和命令裁剪区域进行交集运算,确保准确裁剪;
- OpenGL 使用
glScissor,软件渲染器使用相同的边界控制逻辑,达成一致; - 通过裁剪区域的格式转换,保持两端逻辑对等。
- 利用
最终结果是两个渲染路径都支持了精确裁剪功能。图形渲染更加稳定、干净,显示区域得到正确限制,系统行为一致,整体框架进一步稳定,功能完善。裁剪逻辑现已实现全面覆盖,无论使用哪种渲染器,表现均符合预期,流程完整,效果正确。
问答环节
目前我们注意到 DebugEnd 函数执行时间较长,起初以为性能瓶颈可能出现在调试信息的收集阶段(如 DebugCollation),但进一步分析后发现并非如此。
实际上,DebugEnd 本身包含了大量绘制相关的构造操作。它不仅仅是简单地结束调试流程,而是在这个阶段进行了各种调试图形的构建和渲染操作。因此,性能消耗主要集中在:
-
调试图形的绘制处理:
- 在
DebugEnd阶段会生成一批调试可视化元素,如边界框、指示线、标签、统计信息等; - 这些图形元素需要进行位置计算、顶点生成、纹理或字体处理,可能涉及缓冲区更新或GPU命令准备。
- 在
-
渲染命令的构建:
- 在该函数中,相关渲染数据需要从内存状态整理成渲染命令或对象;
- 包括调试图形的排序、分组、合并等操作。
-
状态同步和清理:
- 一些数据结构(如临时缓存、命令队列、调试数据集合)会在此阶段被清空或刷新;
- 可能会涉及锁、资源管理器更新等操作,这也会带来额外耗时。
因此,DebugEnd 之所以耗时,并非因为调试信息的"采集",而是因为其承担了图形构建、资源管理和状态提交等核心绘制职责。理解这一点有助于后续优化,如:
- 推迟部分图形构建操作;
- 改进调试图形缓存机制;
- 或者分离出绘制逻辑与其他调试状态管理逻辑。
整体来说,DebugEnd 是调试渲染流程中的重负载阶段,其性能瓶颈主要来源于可视化资源的构建和渲染准备。
FPS 降低的三个主要原因是什么?
在讨论帧率(FPS)下降的主要原因时,我们可以从游戏运行的通用层面来总结。以下是导致帧率下降最常见的三个核心原因:
-
渲染负载过高
渲染管线中可能存在大量需要实时绘制的图形内容,比如复杂的模型、过多的粒子系统、全屏后处理特效、高精度阴影或体积光照等。这些内容会直接增加 GPU 的负担,导致渲染时间延长,从而帧率下降。尤其是在视野中同时存在大量动态物体或高分辨率贴图时,这种问题尤为突出。
-
CPU瓶颈与游戏逻辑复杂度
当游戏中的逻辑处理(例如物理碰撞检测、AI决策、路径规划、动画更新等)过于复杂,或主线程负载不均衡时,CPU 无法及时提交渲染指令或完成游戏帧逻辑,导致渲染管线被阻塞,从而影响帧率。此外,脚本系统运行缓慢或数据结构管理低效(如频繁的内存分配、垃圾回收等)也会加剧这种情况。
-
资源加载或内存带宽问题
动态加载场景或纹理、读取新区域的数据时,如果未使用异步加载机制,可能会阻塞主线程导致卡顿。同时,当显存或系统内存占用过高,超过硬件带宽,或频繁触发页面调度(如VRAM频繁换入换出),也会造成帧率波动。此外,当数据未正确缓存、资源访问存在瓶颈(如纹理采样超出缓存)时,也会明显拖慢帧率。
总结来看,FPS 下降通常是 CPU、GPU 或内存系统中任一部分负载超出实时处理能力的表现,合理分配资源、优化数据结构与渲染路径是缓解此类问题的核心方向。
ClipRect 会在调试以外的场景中使用吗?会用在哪里?
我们当前的裁剪机制虽然最初是为了调试用途而构建的,但它本身已经具备了通用性,因此也完全可以在调试之外的场景中使用。具体来说,有几个实际应用的可能性:
-
游戏中区域性渲染优化
在一些复杂的场景中,比如存在多层结构或视线穿透(如地板开孔看到下层),我们可以通过裁剪区域来限制只渲染可视区域,避免对整个屏幕进行多余的绘制。这种方式可以显著减少不必要的像素填充和片段着色器运行,从而提升性能。
-
用于组合式渲染(Compositing)
如果渲染系统未来升级到更高级的形式,比如支持马赛克渲染、离屏缓冲、局部重绘等技术,那么在合成阶段限制渲染区域是十分关键的。比如一个 UI 窗口组件只更新其中一小块区域时,只裁剪并重绘该区域即可,避免整块区域重绘。
-
提高系统渲染精度与效率
就算不进行大的系统升级,当前的裁剪机制也可以用于优化局部渲染行为。比如在渲染过程中,如果知道某些区域不会被用户看到(例如在遮挡物后面),可以主动裁剪掉这些区域来节省资源。尤其是在一些静态背景或分块渲染中,效果尤为明显。
总结而言,这一裁剪功能虽然起源于调试,但完全具备推广至渲染系统其他部分的潜力,特别是在需要提升渲染效率或进行更复杂合成行为时,能够提供实用的技术支撑。
能详细说说你打算用来替换 MoveEntity 中拖拽函数的 ODE 吗?
目前我们暂时不会深入讲解打算用来替换 MoveEntity 函数的那套"odeon"方案。关于它的具体实现原理、如何推导、替换的时机以及为何要进行替换,都会留到未来确实要进行替换的时候再详细展开讲解。
这项替换的本质,是一个具有一定复杂度的话题,需要结合实际上下文进行说明和展示。它并非当前阶段的重点,也不影响现有系统的运行逻辑与功能,因此暂时搁置。但可以明确的是,这个替代方案是经过深思熟虑并具有潜在优化价值的,一旦进入替换阶段,我们会详尽地分析它的推导过程和实际好处,确保理解其技术和设计上的合理性。
既然现在能裁剪了,考虑让 top list 支持滚动吗?当分析项变多时会更易查看
由于现在已经实现了裁剪功能,在分析性能时,尤其在涉及大量采样或事件时,绘制完整的调用图(scribble)会变得非常低效甚至痛苦。作为一种提升可扩展性的练习,我们可以只绘制顶层的 scribble。
实际上我们在分析时只关注顶层的条目。这些顶层条目往往才是性能开销集中的部分。更深层次的调用在绝大多数情况下都没有太大意义------即便在理论层面上也许有价值,但在实际操作中,它们的影响通常非常微小,不足以改变判断或优化方向。
通常我们只会查看那些开销占比超过 1% 的条目。低于 1% 的部分对整体性能几乎没有影响,因此没有必要让它们参与渲染或分析流程。基于这种思路,仅保留顶层调用的可视化内容既能显著提升效率,也更符合分析需求。这样不仅简化了渲染任务,也提高了可读性和分析聚焦度。
什么时候裁剪绘制区域的成本比直接绘制还高?
裁剪操作本身并不会导致性能成本增加,反而能够带来优化。无论如何,图形都必须裁剪到屏幕区域,所以缩小裁剪范围只会节省时间,而不会增加成本。所有的图形都会被裁剪到显示区域,而裁剪的精细程度(比如仅裁剪掉不显示的部分)会使渲染过程更高效。
不过,历史上在进行几何裁剪时,特别是在处理三角形的几何裁剪时,裁剪操作确实可能增加计算量,因为每一次裁剪可能会导致三角形被多次细分,这样的情况在早期渲染中更为常见。但随着现代渲染方法的进步,今天的渲染方式更依赖于矩形区域的裁剪,三角形裁剪的情况已经不再是瓶颈。
因此,在现代渲染中,裁剪并不会引入额外的性能损耗,反而是提升效率的手段,尤其在处理2D矩形和更高效的3D渲染场景时。虽然在早期的3D渲染中,复杂的几何裁剪可能会引起性能问题,但如今已经不再是主要问题。
这不完全正确,裁剪状态的改变不是免费的,如果尺寸变化很小,可能不值得裁剪
改变裁剪矩形的操作并不是完全免费的。如果裁剪矩形的大小变化非常小,而且这种变化频繁发生时,可能会带来额外的性能开销。例如,每次更新裁剪矩形时,需要更新GPU中的几个内存条目,这虽然不是非常显著,但如果这种更新发生频繁,就可能成为一个性能瓶颈。
如果没有必要频繁改变裁剪矩形,尤其是对于没有实际意义的变化,那么每次更新这些内存条目的开销可能就不值得。此外,频繁的状态变化会导致额外的管理和更新工作,可能会影响渲染性能。
当你切换渲染器时帧时间会改变,那新裁剪框中的计时是否也受渲染器影响,比如顺序或分布不同?
在切换渲染时,视图帧时间的确会受到影响。新的裁剪框中的时钟也可能会受到不同渲染器的影响,尤其是当渲染的顺序发生变化时。这是因为渲染器的切换可能会改变帧的处理方式,进而影响到渲染时的各个参数,包括时钟。
首先,考虑到优化构建版本,通常在进行性能分析时并不会过多查看分析数据。因此,首先要做的是确保在进行性能分析时使用正确的构建版本。这可以通过对不同渲染器和裁剪框的处理进行测试,以确保数据的准确性和一致性。
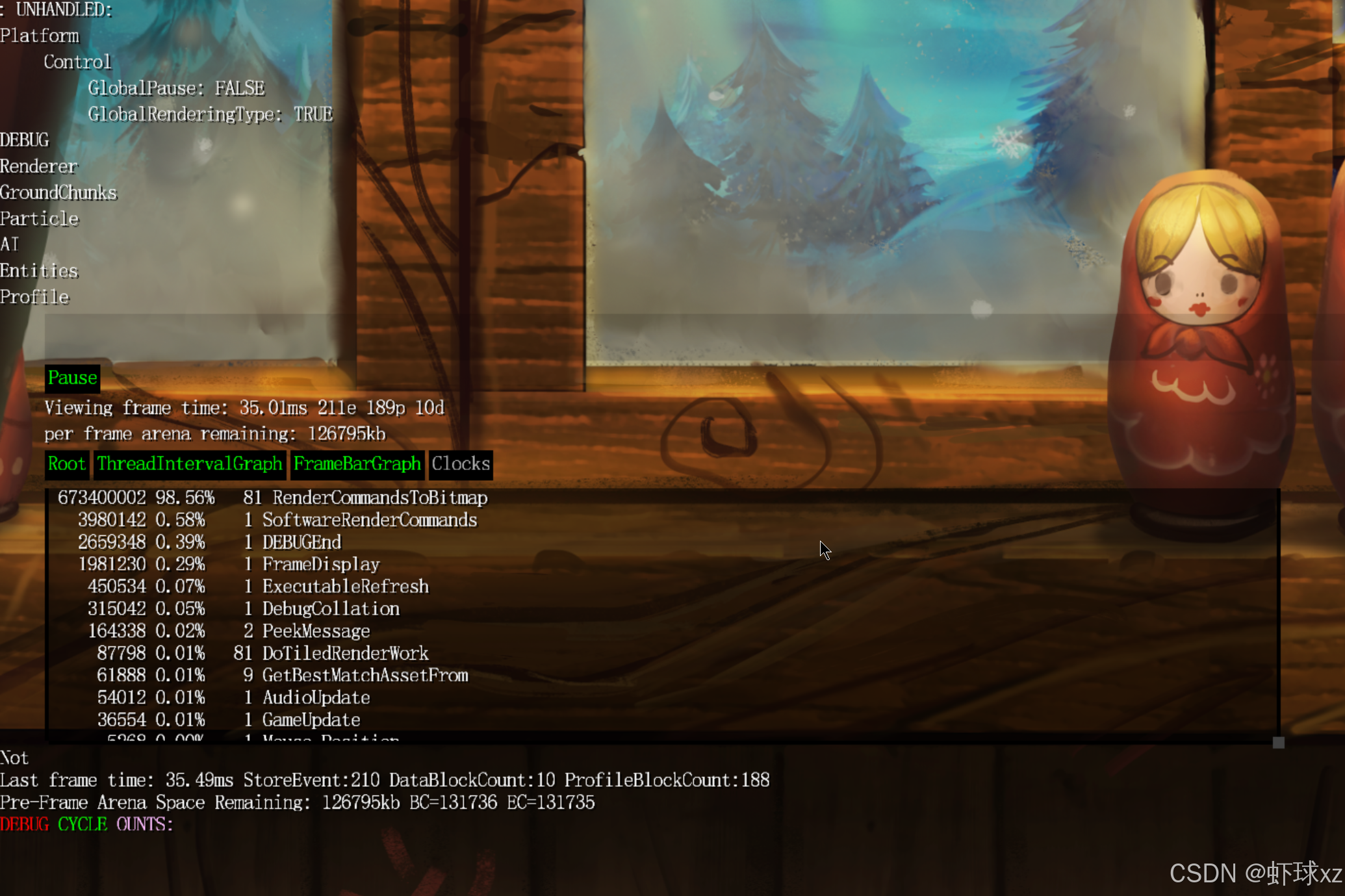
build.bat:切换到 -O2 和 查看分析器表现
打开该功能后,可以选择关闭调试并减慢速度,这样可以减少大量的代码执行,从而减少干扰。接着,我们可以查看性能分析,获得一个更现实的视图,了解实际情况的开销。在启用软件渲染后,可以看到更现实的性能数据,并且现在可以看到大约50%的时间都花费在软件渲染上,这是预期的结果。
在实际游戏中,调试聚合仍然占据了大部分时间,这很有趣,可能是因为频繁调用像素填充操作所致。考虑到这一点,可能需要移除一些不必要的生成内容,因为它们生成了大量我们不需要的东西。
game_render.cpp:忽略 IGNORED_TIMED_FUNCTION 和 IGNORED_TIMED_BLOCK
在game render中,我将会处理这些被忽略的时间函数,并且实际去忽略它们。这样做后,我们就不会在相关操作上浪费太多时间。接下来,我们可以看到硬件渲染和软件渲染的性能数据。从结果来看,几乎所有的时间都花在了细节渲染上,这是预期中的表现。尽管如此,帧率表现不佳,这部分是因为需要渲染大量不必要的内容,因此实际上这些数据并不完全公平。
为了更准确地评估性能,可以暂停渲染并滚动查看帧时间差异。在某些情况下,帧时间为24毫秒,而在某些情况下为45毫秒,差异相当明显。这些差距主要来源于渲染的小纹理填充操作。如果需要优化软件渲染,可以使用矩形块操作来提高字体渲染的速度,但我们并不关心这些细节。
在查看游戏代码时,即使做了优化,渲染时间仍然表现良好。尽管如此,实际情况有些让人疑惑,尤其是frame display部分,花费了很多时间。经过分析,发现主要原因是Windows本身的效率低下,它在处理矩形绘制时非常耗时,且每个矩形绘制的时间是分开的。而且这些矩形总数达到18000个,实在是让人怀疑是否真的需要绘制这么多矩形。
game_render.cpp:忽略 DrawRectangle 和 "Pixel Fill"
这些操作应该总是被计时的,18000个矩形的绘制次数听起来不太对劲,实在是有点奇怪。我觉得需要对这些操作进行更多的计时,并进一步分析为何会有这么多矩形被调用,确实很值得调查。
从整体来看,Windows处理这些操作的时间非常长,比预期的要慢很多,导致在完成渲染到显示到屏幕上之间花费了过多时间。这可能是由于垂直同步(V-Sync)或者其他某些问题导致的,可能是存在一帧的延迟,或者有一些不明的原因。总之,这是一个非常有趣的现象。实际上,如果没有这个问题,可能我们现在已经能够达到60Hz的刷新率了,这一点真的很酷。
启用 gl_scissor_test 时 OpenGL 会做什么?它检测什么?
OpenGL 在启用 gl_scissor_test,其实是在说,OpenGL 不会简单地将渲染区域翻转到窗口边界,而是会根据你指定的边界进行裁剪。这样做的目的是确保 OpenGL 不会将图像绘制到无效的内存区域,避免内存损坏或者覆盖不应绘制的部分。因此,OpenGL 始终会进行裁剪,以确保渲染操作不会出错。
黑板讲解:glScissor 的工作机制
在 OpenGL 中,屏幕上有一个区域和一个裁剪区域(scissor)。这个裁剪区域就是通过设置 glScissor 来指定的。当启用 glScissorTest 时,OpenGL 会使用你传递的裁剪矩形。如果没有启用裁剪测试,OpenGL 就会默认使用整个屏幕作为裁剪区域。基本上,这个操作是在控制是否启用裁剪矩形,而不是每次都强制使用整个屏幕。至于为什么要这样做,可能是因为 OpenGL 的工作方式就是提供这种启用和禁用的控制选项。也许可以说,理论上你应该始终设置裁剪区域,如果不需要裁剪,可以直接设置为整个屏幕。