Hadoop 实战拾遗:作业历史追踪、数据安全阀与 MapReduce 巧算 π
一、追溯作业足迹:JobHistory Server 的配置与使用
Hadoop 集群高效运行的背后,离不开对已完成作业的细致分析。JobHistory Server (JHS) 就像是作业的"黑匣子",为我们保存了宝贵的历史记录。
-
为何需要 JHS?
当 YARN 中的Application 结束后,其运行时上下文随之消失。JHS 的存在就是为了持久化这些作业日志和统计信息,方便日后回溯。
-
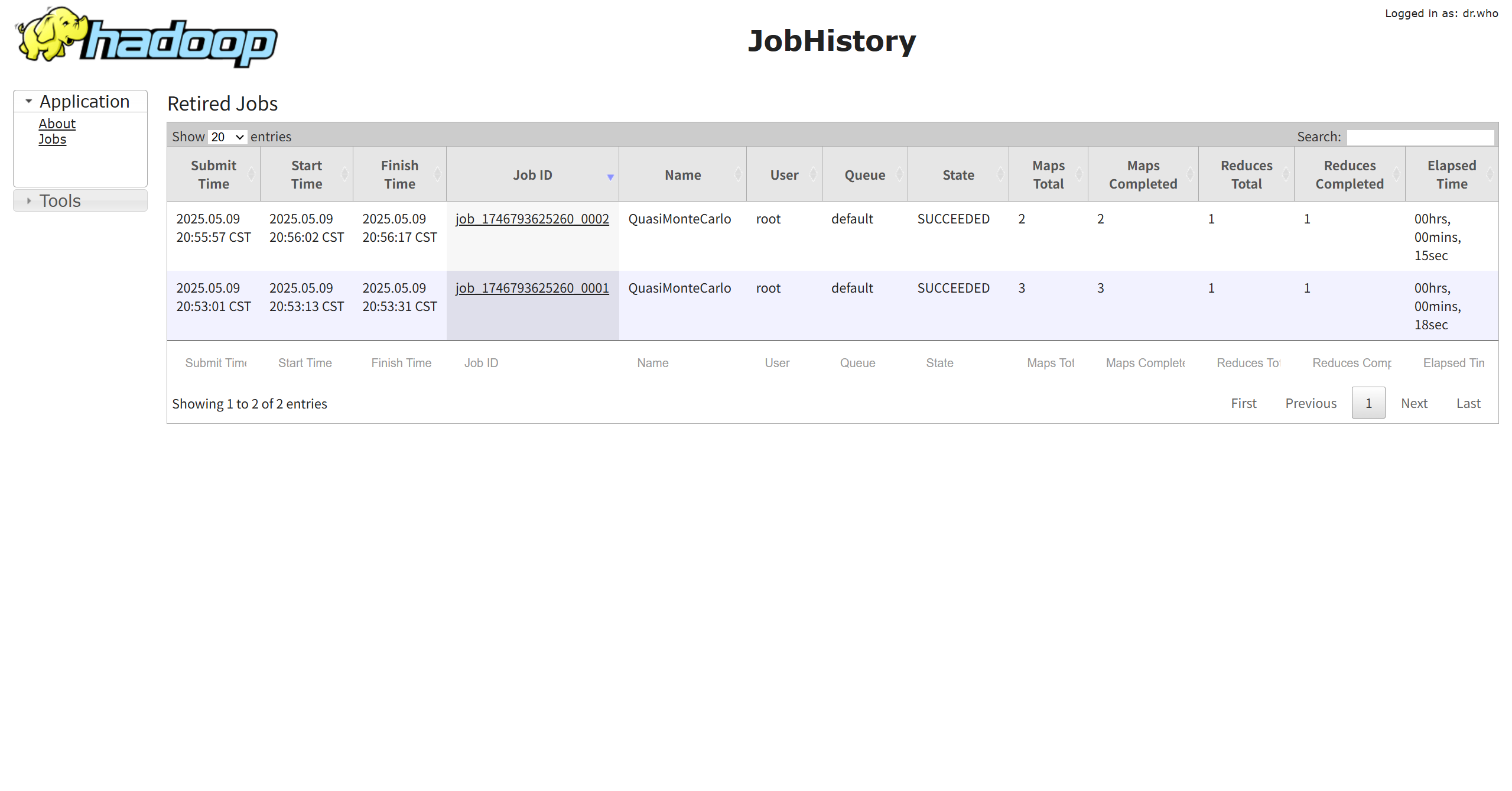
JHS 的工作核心:
JHS 默默收集 MapReduce (或其他兼容框架如 Spark on YARN) 作业在运行时产生的各类事件和配置,将其写入 HDFS 的指定目录。随后,它解析这些文件,并通过Web UI (通常是19888端口) 提供查询服务。
-
关键配置与启动命令:
- 配置
mapred-site.xml:
xml
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop01:10020</value> <!-- JHS RPC 服务地址 -->
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop01:19888</value> <!-- JHS Web UI 地址 -->
</property>- 启动|停止 JobHistory Server:
bash
mr-jobhistory-daemon.sh start|stop historyserver- jobhistory不受hadoop集群的启停命令的影响,每次都需单独启动和关闭
- 历史作业的"时光机":
配置并启动 JHS 后,只需在浏览器中输入hadoop01:19888,即可进入历史作业的查询界面,轻松追溯每个作业的前世今生。
二、HDFS 的"后悔药":垃圾桶 (Trash) 机制解析
手滑误删是数据操作中的常见噩梦。HDFS 的垃圾桶机制,就如同为我们的重要数据提供了一道安全防线。
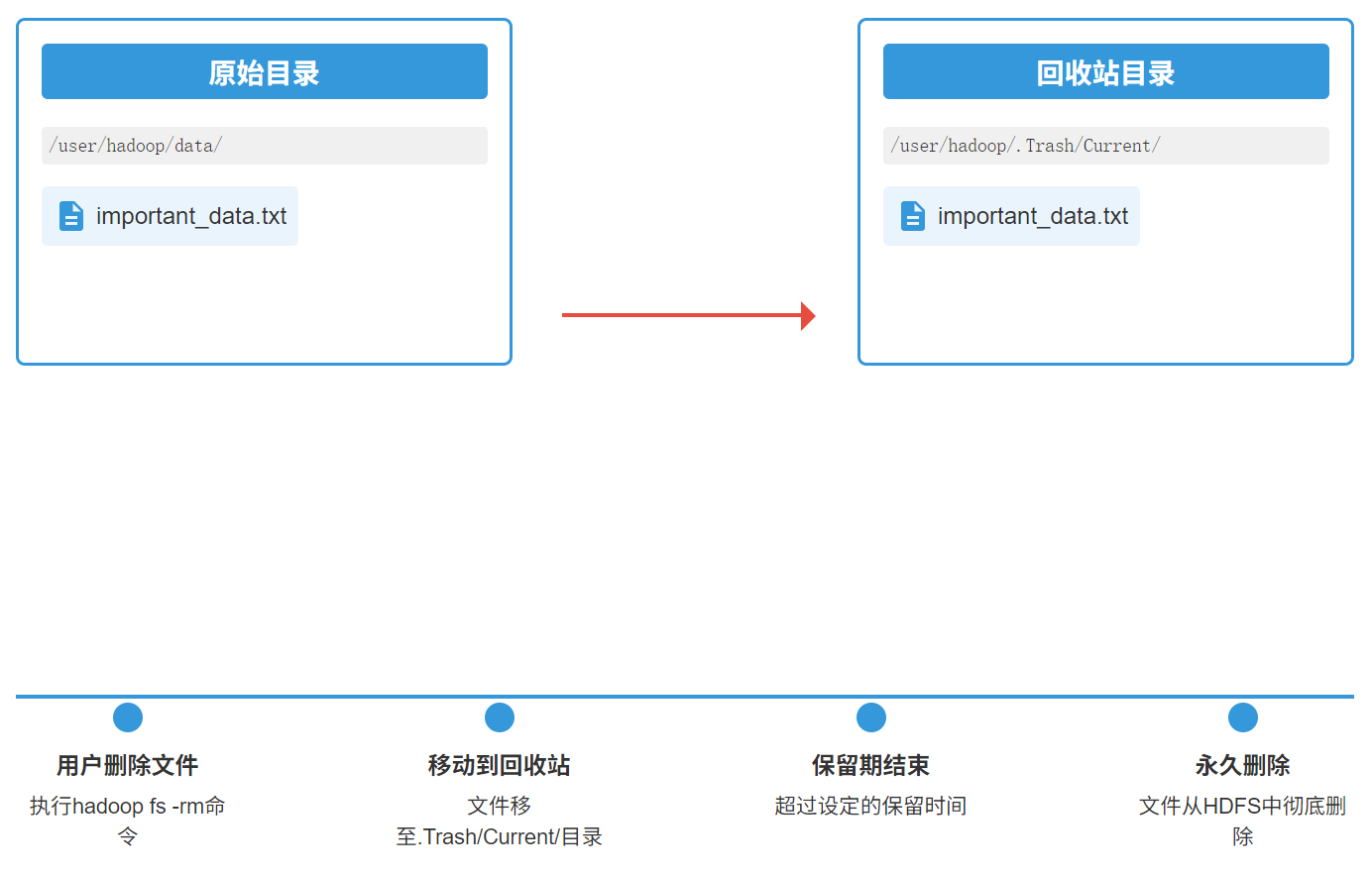
- 垃圾桶的工作逻辑:
当启用此功能后,执行hdfs dfs -rm命令删除文件或目录时,它们并不会被立刻从磁盘抹去,而是被悄悄地移动到当前用户HDFS主目录下的.Trash/Current/目录中,保留了其原始的路径结构。
- 配置与启用:
垃圾桶的核心配置在core-site.xml文件中。
- 设置保留时间:
xml
<property>
<name>fs.trash.interval</name>
<value>1440</value> <!-- 文件在垃圾桶中保留的分钟数,例如 1440 分钟 = 24 小时 -->
</property>(注意:如果此值为 0,则垃圾桶功能被禁用。)
- (可选) 设置检查点间隔:
xml
<property>
<name>fs.trash.checkpoint.interval</name>
<value>60</value> <!-- 后台清理垃圾桶的检查点间隔(分钟),通常小于或等于 fs.trash.interval -->
</property>- "失而复得"的操作:
如果在保留期内意识到误删,可以找回数据。
- 查看垃圾桶内容 (示例):
bash
hdfs dfs -ls /user/your_username/.Trash/Current/path/to/your/deleted_file- 恢复文件/目录 (示例):
bash
hdfs dfs -mv /user/your_username/.Trash/Current/path/to/your/deleted_file /original/path/deleted_file- 特别提醒:
- 使用
hdfs dfs -rm -skipTrash <path>命令会直接跳过垃圾桶,永久删除。 - 垃圾桶会消耗存储空间,需合理规划保留策略。
- 使用
三、MapReduce 趣味编程:蒙特卡洛法估算 π
MapReduce 不仅能处理枯燥的数据统计,也能参与到一些有趣的数学实验中。用蒙特卡洛方法估算 π 就是一个经典案例。
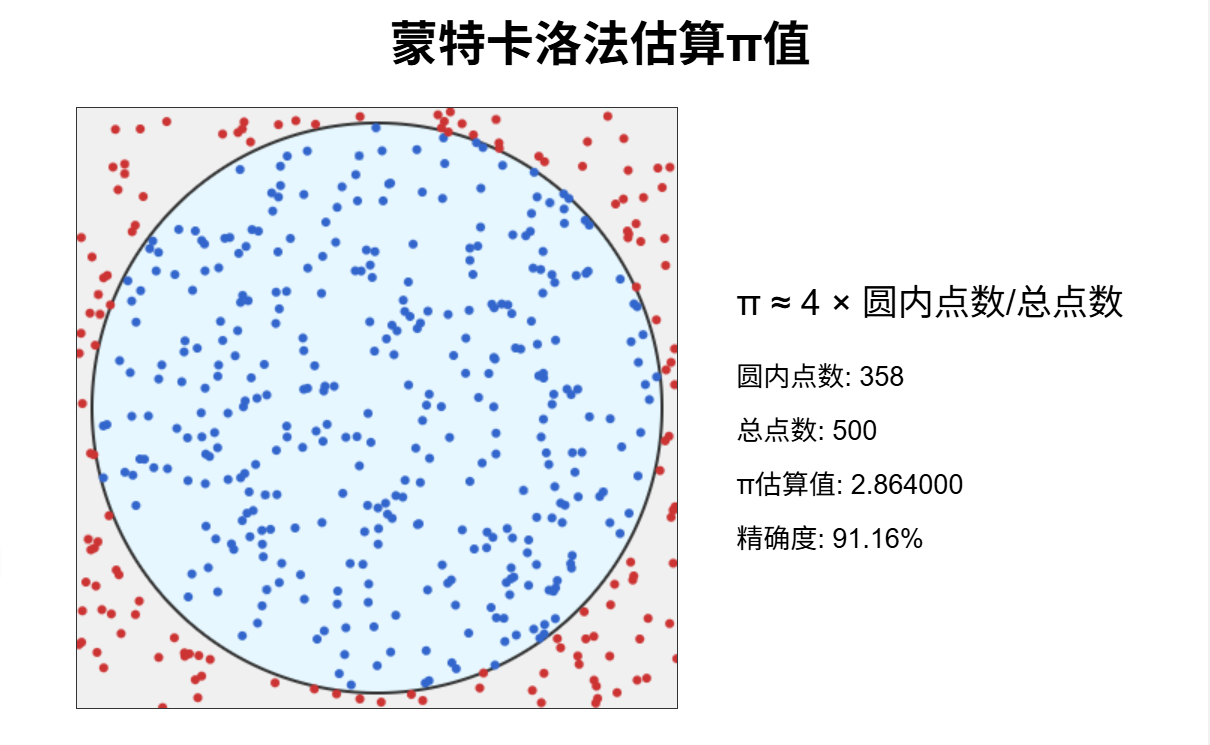
- 核心思想:概率的魔法:
在一个正方形内随机投点,统计落入其内切圆的点的比例。这个比例乘以 4,就近似于 π。点投得越多,结果越准。
- 用
hadoop-examples.jar执行 π 估算:
Hadoop 通常自带一个名为hadoop-examples.jar的示例程序包,其中包含了用 MapReduce 实现的PiEstimator(或类似名称的) π 估算程序。我们可以直接通过命令行运行它。
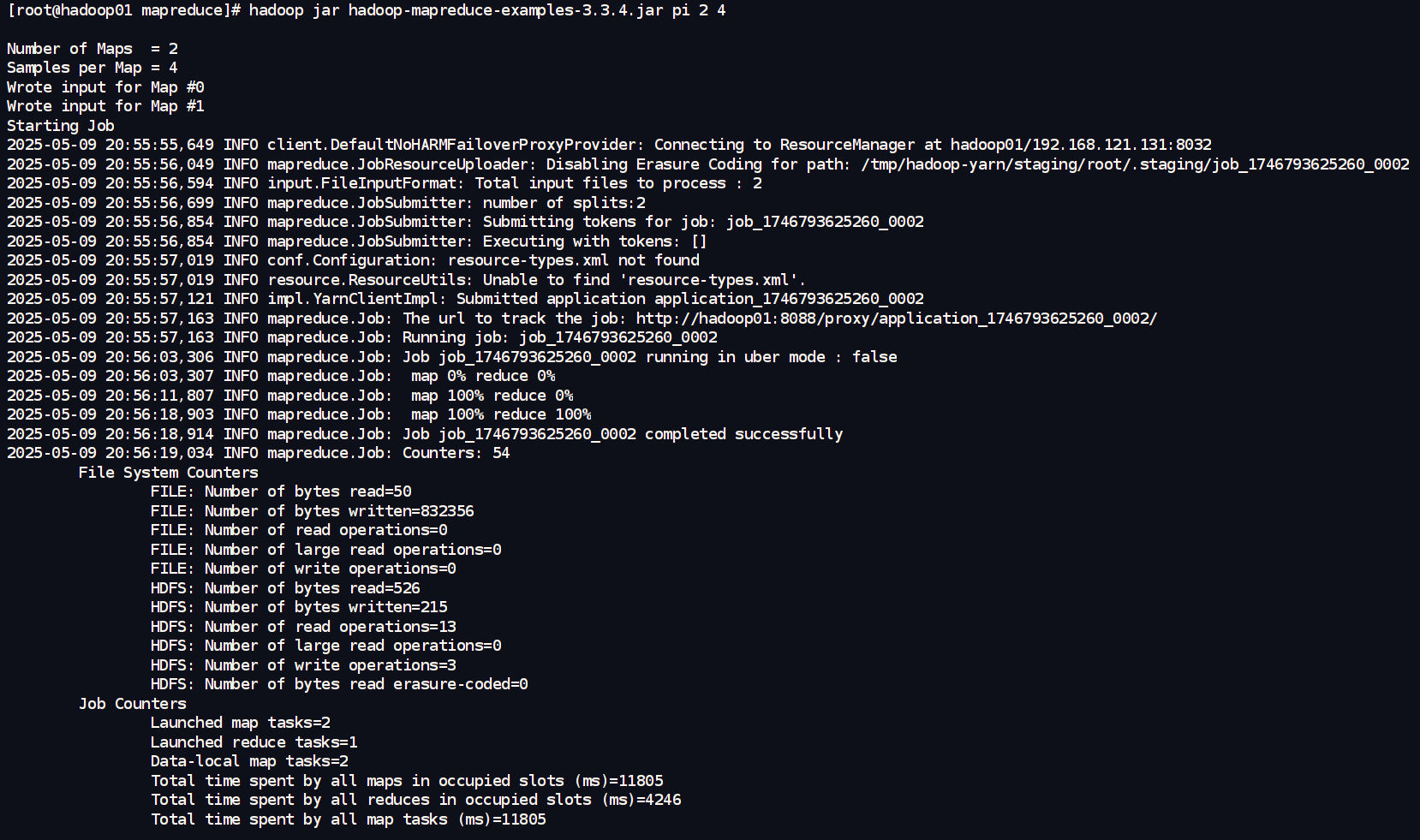
- 执行命令示例:
bash
hadoop jar hadoop-mapreduce-examples-3.3.4.jar pi 2 4pi: 指定要运行hadoop-examples.jar中的PiEstimator程序。2: 指定使用的 Map 任务数量。4: 指定每个 Map 任务投掷的点数 (samples per map)。
(总投掷点数 = Map 任务数 * 每个 Map 的点数 = 2 * 2 = 8)
运行后,该 MapReduce 作业会在集群中执行,并在控制台输出估算的 π 值以及作业的相关信息。
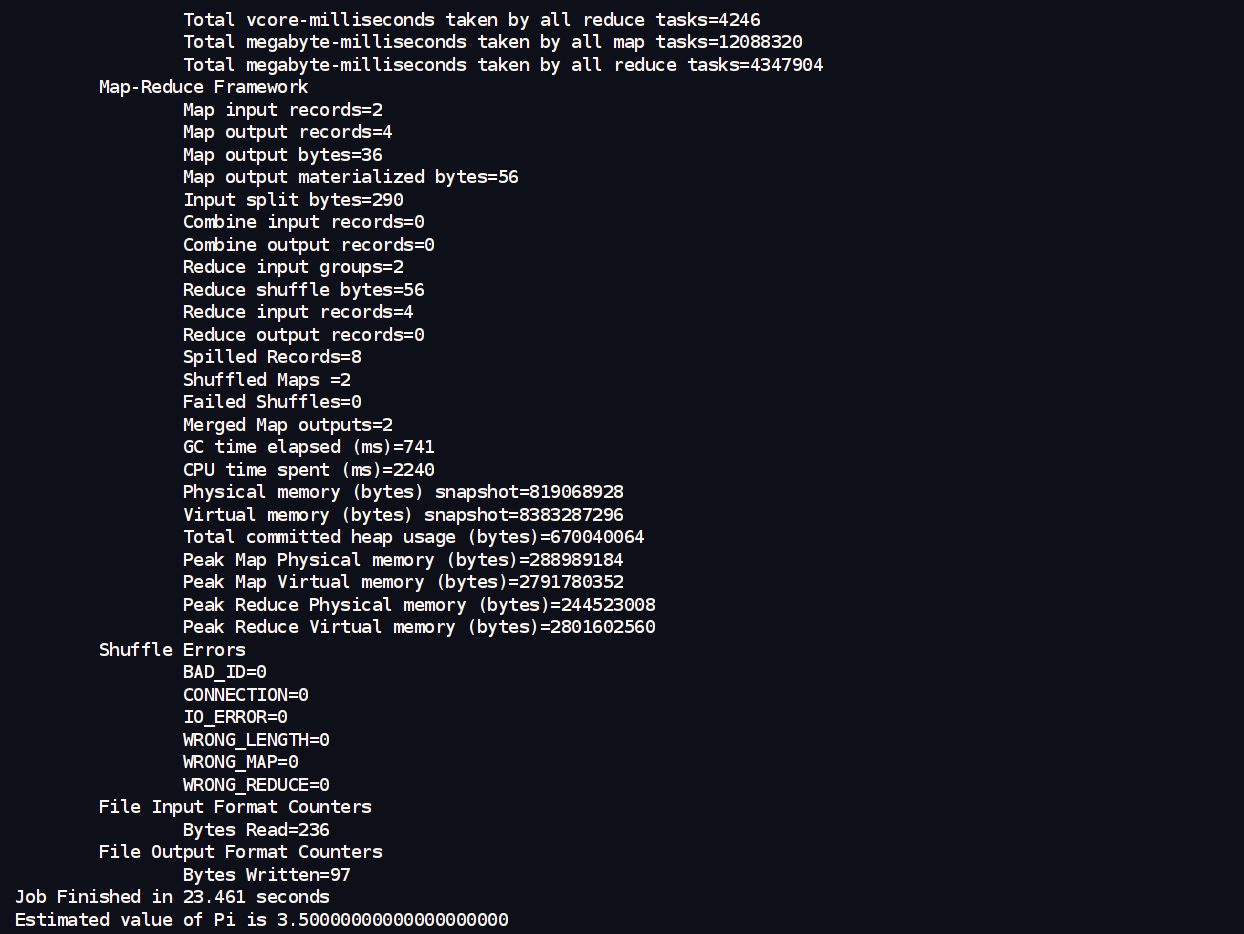
想要查看详细的信息,可以去YARN ResourceManager Web UI界面看
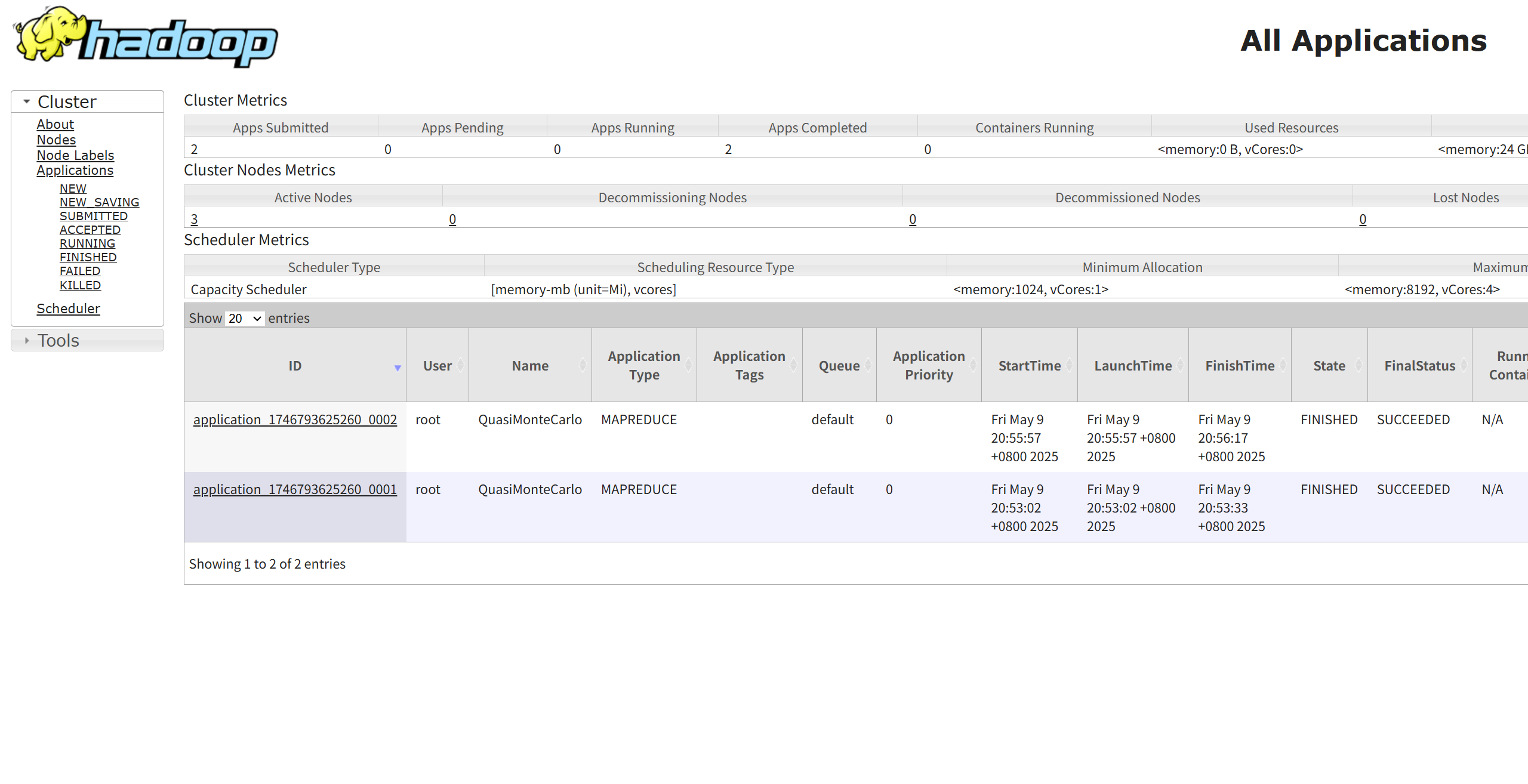
- 实验的启示:
这个命令行操作,让我们无需编写一行 Java 代码,就能体验 MapReduce 分布式计算的魅力。它背后的原理与之前讨论的Mapper/Reducer 逻辑是一致的:大量的随机投点被分配到多个 Map 任务中并行处理,最终结果被汇总得出 π 的估算值。