最近突然看了一下pandas向excel追加数据的方法,发现有很多人出了一些馊主意;
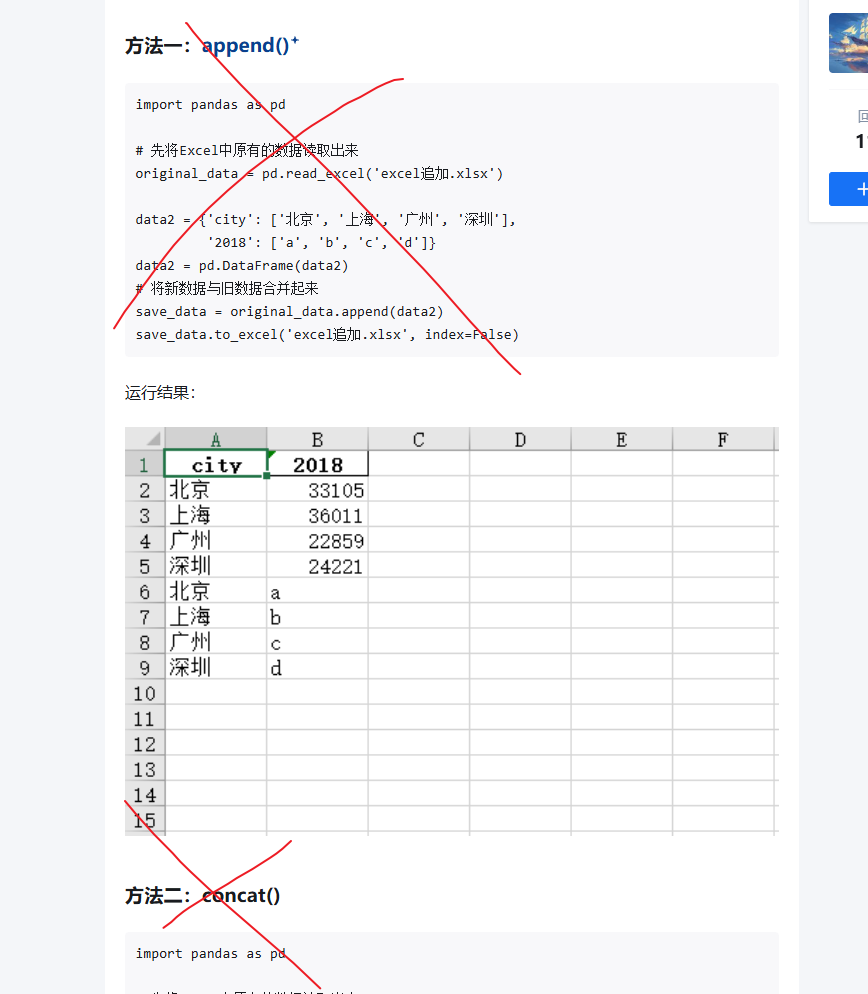
比如用concat,append等方法,这种方法的会先将旧数据df_1读取到内存,再把新数据df_2与旧的合并,形成df_new,再覆盖写入,消耗和速度极大,肯定不聪明;
如果是CSV文件,pandas的to_csv可以直接mode=a追加,毕竟就是一个纯文本型文件;
但excel不行,毕竟excel存储的原理不同,同样的数据excel要小很多,粗糙地可认为,把很多相似内容,用键值对存储,那么单元格内很多重复的东西,只需要用key值代替,体积就小,但计算开销大;
1.自己试验了一下,先说结论:
**需求:**向EXCEL某个表中,追加数据,不覆盖原数据,正确高效方法:
df_1为旧数据,存到excel之后,再用pandas read_excel后称为data_1;
新数据为df_2
import pandas as pd
path = 'd:/test_pd.xlsx'
# 正确方法
with pd.ExcelWriter(path ,mode='a',if_sheet_exists='overlay') as w:
df_2.to_excel(w,'Sheet1',index=False,header=False,startrow=df_1.shape[0]+1)注意:
①ExcelWriter的mode和if_sheet_exists这两模式要选对;
②startrow,必须指定起始行(默认为0),并且要+1,不然df_2的数据会覆盖df_1,跟直接df_2.to_excel()没区别;
2证明:
import pandas as pd
import random
from faker import Faker # 生成假数据的库
df_1 = pd.DataFrame(columns=['index','name','value'])
# 生成10个数据
fake_instance = Faker("zh_CN")
index_1 = [i for i in range(1,11)]
fake_names_1 = [fake_instance.name() for i in range(1,11)]
fake_values_1 = [random.randint(1,100) for i in range(1,11)]
# 写到dataframe中
temp_list = [index_1,fake_names_1,fake_values_1]
for col,v in zip(df_1.columns,temp_list):
df_1[col] = v
# 第一波数据还是把标题带上,后面就不带标题了
df_1.to_excel('d:/test_pd.xlsx',index=False,header=True)
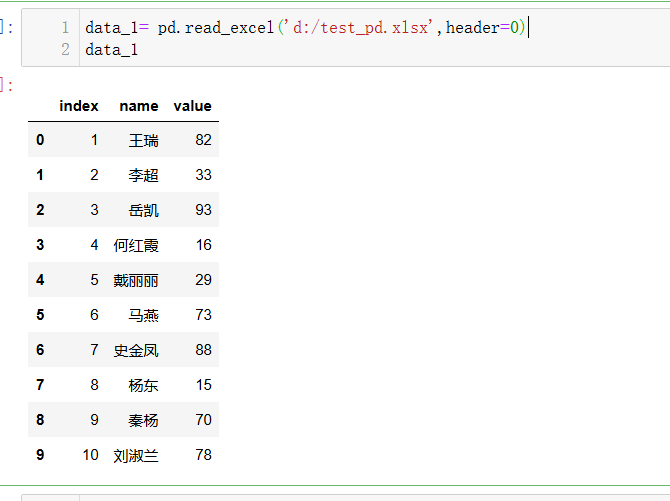
df_12.1数据如下:
2.2再来一波数据:
index_2 = [i for i in range(11,21)]
fake_names_2 = [fake_instance.name() for i in range(11,21)]
fake_values_2 = [random.randint(1,100) for i in range(11,21)]
df_2=pd.DataFrame({'index':index_2,'name':fake_names_2,'value':fake_values_2})
df_2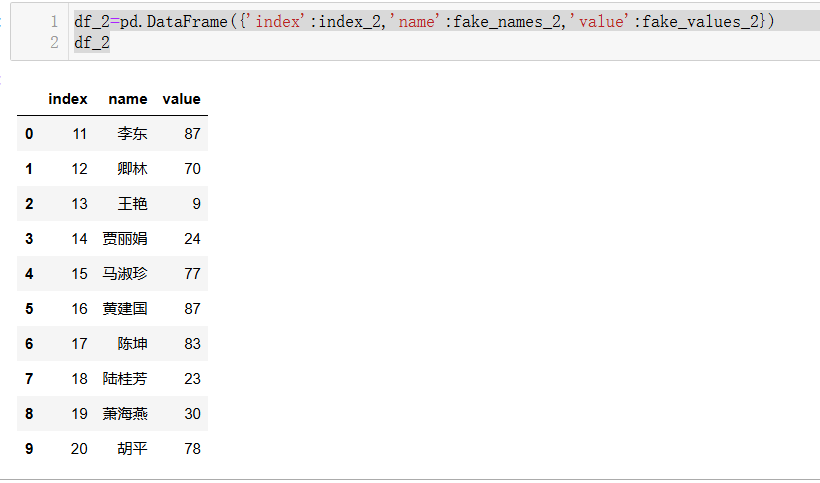
2.3使用简单而高效正确的方法追加数据:
# 正确方法
with pd.ExcelWriter(path ,mode='a',if_sheet_exists='overlay') as w:
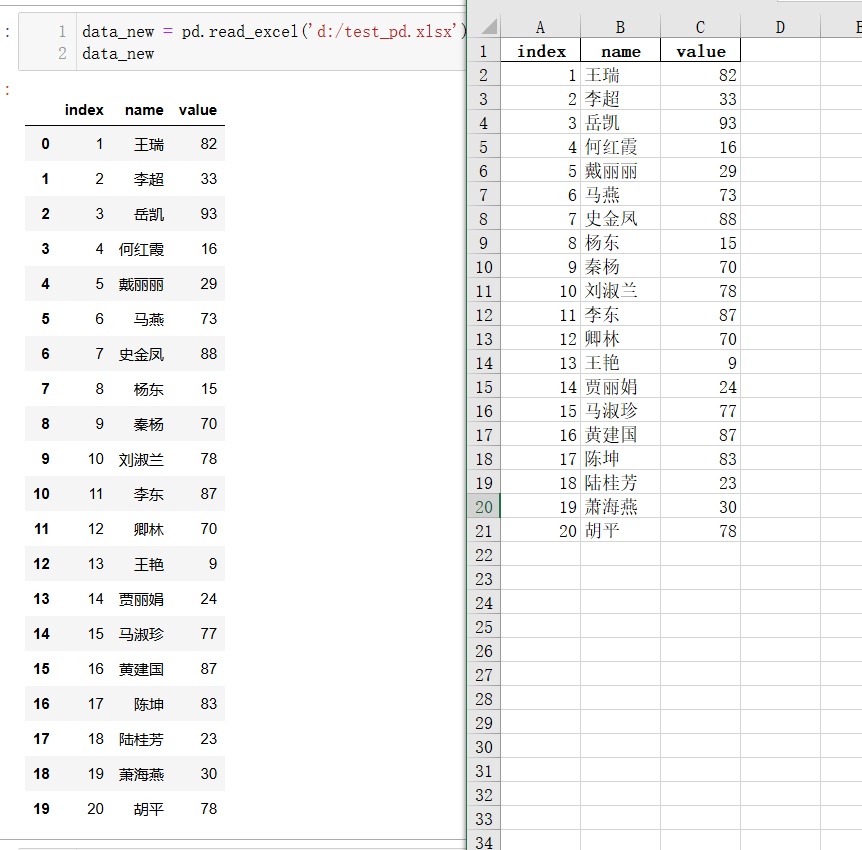
df_2.to_excel(w,'Sheet1',index=False,header=False,startrow=df_1.shape[0]+1)2.4验证本地数据:
2.5如果不指定startrow,则
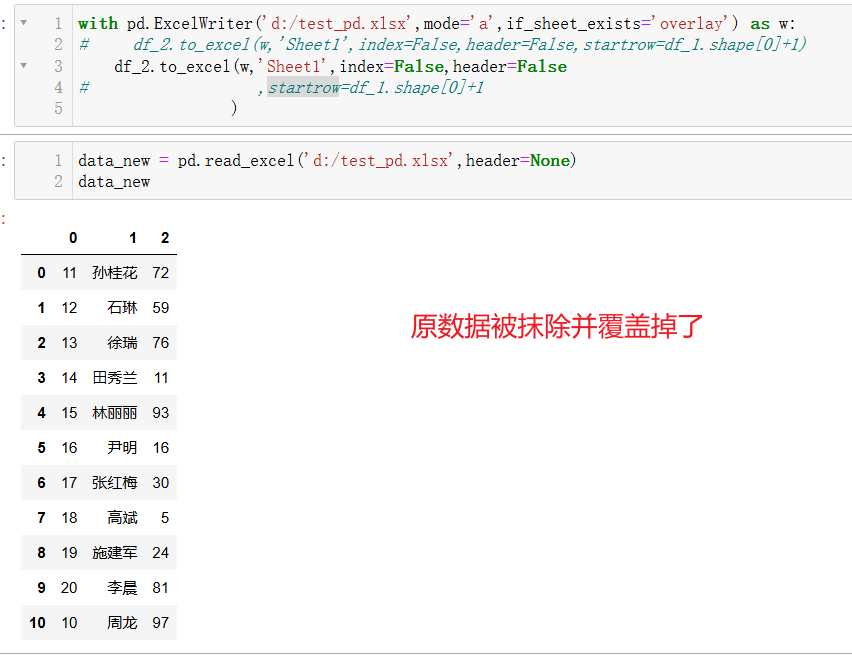
观点来自:
pandas.DataFrame.to_excel:在同一个sheet内追加数据_pandas to excel的mode设置为a,可以再同一个表追加数据么-CSDN博客