一、进程地址空间是什么?
先看这样一个具体的例子
#include<stdlib.h>
#include <stdio.h>
#include<unistd.h>
int main()
{
int a=1;
pid_t id=fork();
while(1)
{
if(id==0)
{
printf("i am child,pid:%d,ppid:%d,a:%d ,&a:%p\n",getpid(),getppid(),a,&a);
sleep(1);
}else if(id>0)
{
printf("i am father,pid:%d,ppid:%d,a:%d,&a:%p\n",getpid(),getppid(),a,&a);
sleep(1);
a++;
}
}
return 0;
}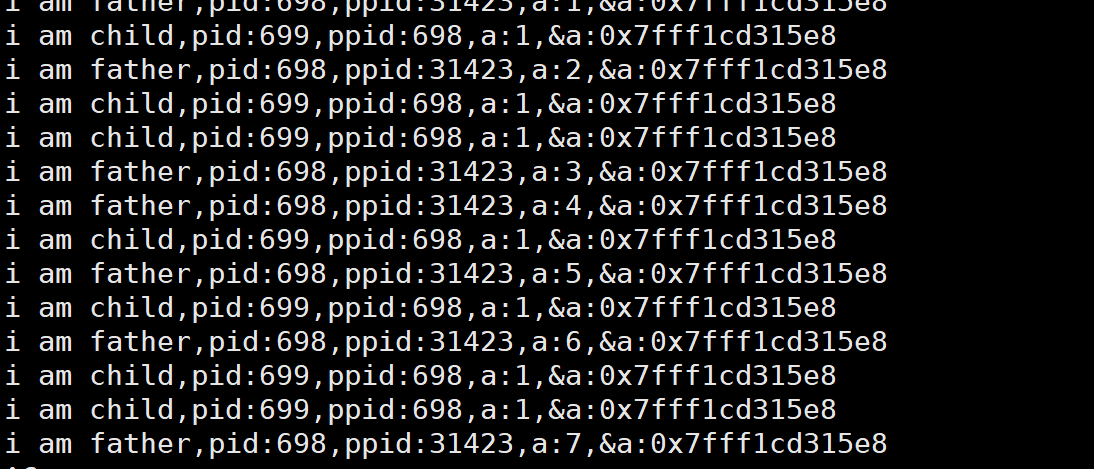
我们发现在同一个地址空间的a变量,父进程和子进程访问时获取的值却不是相同的,这是什么原因呢?
首先,我们可以理解,父子进程的值不同是因为进程间具有独立性,但是这里的i的地址居然是相同的。
因此,我们可以先排除该地址是变量i在物理磁盘上的地址的可能性(因为物理磁盘的同一个地址,只能存放唯一确定的一个值)。
因此,这个地址只能是虚拟地址(也称为线性地址)。在Linux中,有时候我们也将这种地址称为逻辑地址。
操作系统为每个进程都创建了独立的地址空间,地址空间的内容通过页表映射到物理内存中,这样每个进程都能独立的运行。
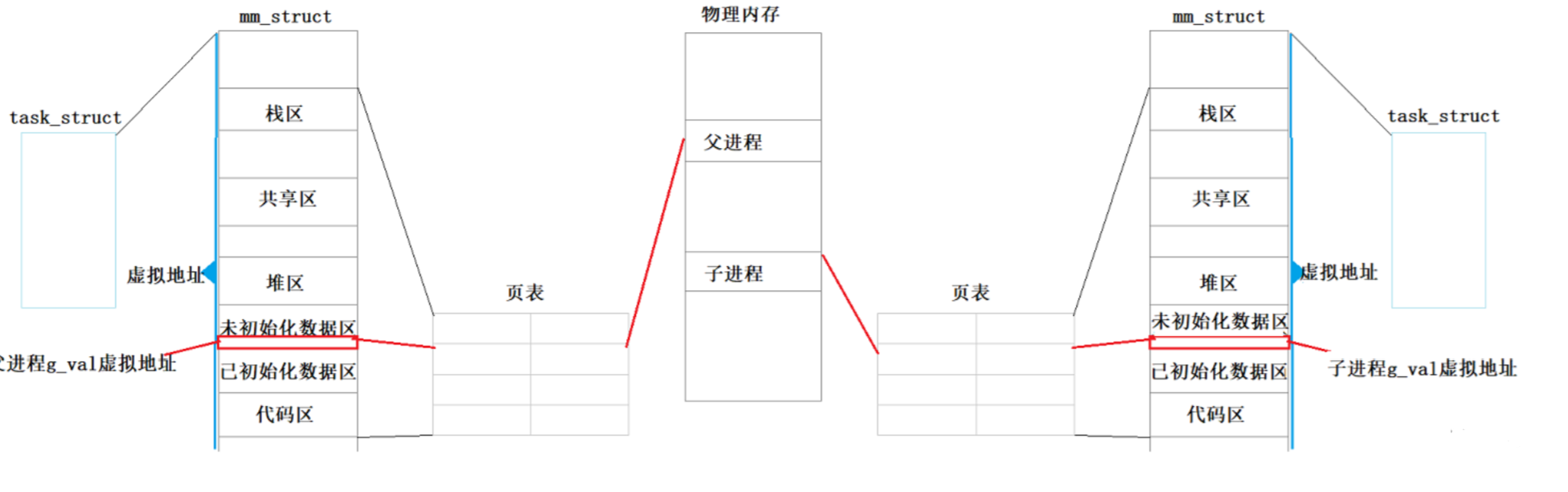
上面现象的解释:
父进程和子进程都有自己独立的进程地址空间,也有独立的页表结构。子进程由父进程创建,因此子进程的进程地址空间是拷贝父进程的进程地址空间。
一开始父子进程并未对进程地址空间做修改,因此a值在一开始是指向同一个物理内存。
后来,子进程修改了i的值,操作系统通过页表映射发现i的值是被两个进程共享的,就会发生写时拷贝,操作系统为了保持进程的独立性,当子进程或者父进程任何一方尝试对共享的数据做写入,操作系统就会在物理内存上重新开辟一块新的内存空间同时拷贝原来的数据,然后修改写入方的页表映射关系,使其指向新的物理地址,再进行写入操作。整个修改的过程中,这些工作与父子进程的虚拟地址没有关系,只有底层经过页表映射到了新的物理地址,因此我们观察到的虚拟地址是相同的,但是内容却不同。
写时拷贝:父子进程中的任意一方试图对共享数据进行写入,操作系统就会先将原数据进行拷贝,然后改变要写入一方的页表映射,使它映射到新的物理内存中,然后再让进程进行写入的技术称为写时拷贝。
二、为什么需要存在进程地址空间
保证了数据的安全性;
如果进程出现越界非法访问、非法写入等情况时,页表会对进程进行拦截。直接对物理内存进行访问,对于账号信息等数据是不安全的(可能会出现意外损坏数据或者恶意读取用户信息等问题)。
方便进程之间数据代码的解耦,保证了进程的独立性;
一个进程对数据的修改不会对另一个进程造成影响,保证了进程的独立性。
让进程以统一的视角看待进程的代码和数据所在的各个区域,同时方便了编译器以统一视角编译代码。
可执行程序在被编译器编译的时候,其代码和数据在内存中已经有虚拟地址了(这种地址在磁盘上被称为逻辑地址),也就是说操作系统和编译器都是遵守地址空间这一理论的。
在程序被加载到内存成为进程前,每个变量/函数都具备了物理地址。因此,我们现在有两套地址,一套是用于表示物理内存中代码和数据的物理地址;另一套是用于程序内部函数之间进行跳转的虚拟地址。
加载完毕后,代码的各个区域的地址,操作系统和编译器都已经知道了。进程被调度时,CPU拿到虚拟地址,经过地址空间的页表映射,就能查到物理地址,通过物理地址访问到代码,然后执行。
CPU -> 虚拟地址 -> 页表 -> 物理地址 -> 执行。
CPU运行的整个过程中,都没有见到物理地址,只通过虚拟地址就可以运行程序。
三、进程地址空间是如何实现它所具有的功能的
操作系统要为每一个进程分配地址空间,操作系统如何管理进程的地址空间?
进程本身需要被管理的,操作系统管理它的方式是将进程的信息存入结构体PCB(即task_struct)中,再用链式结构将每一个进程的PCB对象组织起来。
而地址空间也是通过内核数据结构mm_struct进行管理的,OS会为每一个进程创建一个mm_struct(结构体)对象进行管理。该结构体对象保存在它所对应进程的PCB中。PCB中的一个属性mm_struct
四. 进程地址空间区域的划分与调整
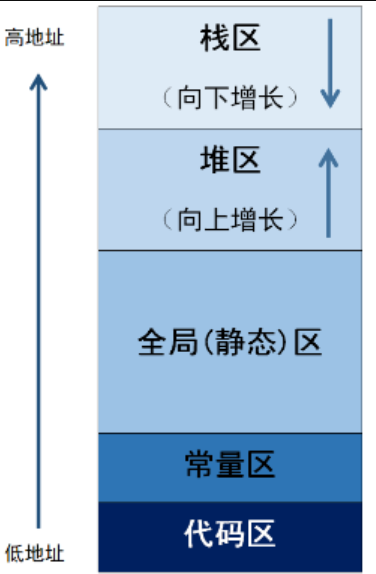
地址空间有很多区域:栈区、堆区、数据段、代码段等,那么进程地址空间是如何进行区域划分的呢?
虚拟地址空间是连续的,因此将地址空间划分为不同区域的方法与上面例子的做法类似,我们用一个区域的起始地址start和终止地址end来调整和维护这一块区域。
struct mm_struct {
uint32_t code_start,code_end;
uint32_t data_start,data_end;
uint32_t heap_start,heap_end;
uint32_t stack_start,stack_end;
}
因此: 所谓的区域调整,本质就是修改对应区域的start和end的值。