基于 PyTorch 2.7
文章目录
- [基准测试工具 - torch.utils.benchmark](#基准测试工具 - torch.utils.benchmark)
- torch.utils.bottleneck
- torch.utils.checkpoint
- torch.utils.cpp_extension
- torch.utils.data
-
- 数据集类型
- 数据加载顺序与采样器
- 加载批处理与非批处理数据
-
- 自动批处理(默认情况)
- 禁用自动批处理
- [使用 `collate_fn`](#使用
collate_fn)
- 单进程与多进程数据加载
- 内存固定
- torch.utils.deterministic
- torch.utils.dlpack
- torch.utils.mobile_optimizer
- torch.utils.model_zoo
- torch.utils.tensorboard
- torch.utils.module_tracker
- 类型信息
- 命名张量
- 命名张量操作覆盖范围
- torch.config
- torch.future
- torch._logging
- [Torch 环境变量](#Torch 环境变量)
基准测试工具 - torch.utils.benchmark
python
class torch.utils.benchmark.Timer(stmt='pass', setup='pass', global_setup='', timer=<built-in function perf_counter>, globals=None, label=None, sub_label=None, description=None, env=None, num_threads=1, language=Language.PYTHON)用于测量PyTorch语句执行时间的辅助类。
完整使用教程请参阅:
https://pytorch.org/tutorials/recipes/recipes/benchmark.html
PyTorch计时器基于timeit.Timer(内部实际使用timeit.Timer实现),但具有几个关键差异:
1、运行时感知:计时器会执行预热(这对PyTorch某些延迟初始化的组件很重要),设置线程池大小以确保比较条件一致,并在必要时同步异步CUDA函数。
2、聚焦重复测量:在测量代码(特别是复杂内核/模型)时,运行间的差异是重要干扰因素。所有测量都应包含重复次数以量化噪声并支持中位数计算(比平均值更鲁棒)。为此,本类在概念上合并了timeit.Timer.repeat和timeit.Timer.autorange方法(具体算法见方法文档字符串)。保留timeit方法用于不需要自适应策略的场景。
3、可选元数据:定义计时器时可选指定label、sub_label、description和env等字段(后文定义)。这些字段会包含在结果对象的表示中,并被Compare类用于分组和显示对比结果。
4、指令计数:除挂钟时间外,计时器可通过Callgrind运行语句并报告执行指令数。
直接对应timeit.Timer构造参数: stmt, setup, timer, globals
PyTorch计时器特有构造参数:label, sub_label, description, env, num_threads
参数说明
stmt (str)-- 在循环中运行并计时的代码片段setup (str)-- 可选设置代码,用于定义stmt中使用的变量global_setup (str)-- (仅C++)置于文件顶层的代码,如#include语句timer (Callable[[], float])-- 返回当前时间的可调用对象。如果PyTorch未启用CUDA或没有GPU,默认使用timeit.default_timer;否则会在测量时间前同步CUDAglobals (Optional[dict[str, Any]])-- 执行stmt时的全局变量字典,这是提供stmt所需变量的另一种方式label (Optional[str])-- 概括stmt的字符串。例如stmt为torch.nn.functional.relu(torch.add(x, 1, out=out))时,可设为"ReLU(x + 1)"提高可读性sub_label (Optional[str])-- 提供补充信息以区分相同stmt或label的测量。例如上例中可设为"float"或"int",便于在打印Measurements或用Compare汇总时区分:ReLU(x + 1): (float)和ReLU(x + 1): (int)description (Optional[str])-- 区分相同label和sub_label测量的字符串。主要用途是通过Compare标识数据列。例如可根据输入尺寸创建如下表格:
python
| n=1 | n=4 | ...
------------- ...
ReLU(x + 1): (float) | ... | ... | ...
ReLU(x + 1): (int) | ... | ... | ...使用 Compare 时,该标签也会在打印 Measurement 时包含。
env (Optional[str])-- 此标签表示其他条件相同的任务在不同环境中运行,因此不等价。例如在进行内核变更的 A/B 测试时,Compare 在合并重复运行结果时会将具有不同 env 指定的 Measurement 视为不同实体。num_threads ( int )-- 执行 stmt 时 PyTorch 线程池的大小。单线程性能既是一个关键推理工作负载指标,也是内在算法效率的重要体现,因此默认值设为 1。这与默认 PyTorch 线程池大小(会尝试利用所有核心)形成对比。
python
adaptive_autorange(threshold=0.1, *, min_run_time=0.01, max_run_time=10.0, callback=None)类似于blocked_autorange,但还会检查测量值的变异性,并重复执行直到iqr/median小于阈值或达到max_run_time。
从高层次来看,adaptive_autorange执行以下伪代码:
setup
python
times = []
while times.sum < max_run_time
start = timer()
for _ in range(block_size):
`stmt`
times.append(timer() - start)
enough_data = len(times)>3 and times.sum min_run_time
small_iqr=times.iqr/times.mean<threshold
if enough_data and small_iqr:
break参数
threshold (float)-- 用于停止的iqr/median阈值min_run_time (float)-- 检查阈值前所需的总运行时间max_run_time (float)-- 不考虑阈值情况下所有测量的总运行时间
返回值:一个包含测量运行时间和重复次数的Measurement对象,可用于计算统计量(如平均值、中位数等)。
返回类型:Measurement
python
blocked_autorange(callback=None, min_run_time=0.2)在保持计时器开销最小化的同时测量多个重复样本。
从高层次来看,blocked_autorange 执行以下伪代码:
python
`setup`
total_time = 0
while total_time < min_run_time
start = timer()
for _ in range(block_size):
`stmt`
total_time += (timer() - start)请注意内层循环中的变量block_size。选择适当的块大小对测量质量至关重要,需要平衡两个相互制约的目标:
1、较小的块大小会产生更多重复样本,通常能获得更好的统计结果。
2、较大的块大小能更好地分摊计时器调用的开销,从而减少测量偏差。这一点尤为重要,因为CUDA同步时间不可忽视(通常在个位数到低两位数微秒量级),否则会影响测量准确性。
blocked_autorange通过运行预热阶段来设置block_size,它会逐步增加块大小,直到计时器开销低于总计算时间的0.1%。这个最终确定的块大小值将用于主测量循环。
返回值:返回一个Measurement对象,其中包含测量的运行时间和重复次数,可用于计算统计量(如平均值、中位数等)。
返回类型:Measurement
python
collect_callgrind(number: int , *, repeats: None , collect_baseline: bool , retain_out_file: bool ) → CallgrindStats
python
collect_callgrind(number: int , *, repeats: int , collect_baseline: bool , retain_out_file: bool ) → tuple [torch.utils.benchmark.utils.valgrind_wrapper.timer_interface.CallgrindStats ,
...]使用 Callgrind 收集指令计数。
与挂钟时间不同,指令计数具有确定性(程序本身的非确定性和 Python 解释器产生的少量抖动除外)。这使其成为详细性能分析的理想选择。该方法在独立进程中运行 stmt 语句,以便 Valgrind 能够对程序进行插桩。虽然插桩会显著降低性能,但由于通常只需少量迭代即可获得良好测量结果,这一缺点得到了缓解。
使用此方法需要安装 valgrind、callgrind_control 和 callgrind_annotate。
由于调用者(当前进程)与 stmt 执行之间存在进程边界,全局变量不能包含任意内存数据结构(与计时方法不同)。作为替代,全局变量仅限于内置类型、nn.Modules 和 TorchScripted 函数/模块,以减少序列化与反序列化带来的意外因素。GlobalsBridge 类提供了关于此主题的更多细节。特别注意 nn.Modules:它们依赖 pickle,可能需要添加导入设置才能正确传输。
默认情况下,系统会收集并缓存空语句的分析文件,用于指示驱动 stmt 的 Python 循环产生的指令数量。
返回值:返回一个 CallgrindStats 对象,该对象提供指令计数及用于分析和处理结果的基本功能。
python
timeit(number=1000000)实现了与 timeit.Timer.timeit() 相同的语义功能。
将主语句(stmt)执行指定次数(number)。
https://docs.python.org/3/library/timeit.html#timeit.Timer.timeit
返回类型:Measurement
python
class torch.utils.benchmark.Measurement(number_per_run, raw_times, task_spec, metadata=None)计时器测量结果。
该类存储给定语句的一次或多次测量数据。它具有可序列化特性,并为下游使用者提供了多个便捷方法(包括详细的__repr__实现)。
python
static merge(measurements)合并重复样本的便捷方法。
该方法会将时间数据外推至 number_per_run=1 且不会转移任何元数据(因为不同重复样本间可能存在差异)。
返回类型:list Measurement
python
property significant_figures: int 近似有效数字估计。
该属性旨在提供一种便捷方式来评估测量精度。它仅使用四分位距区域来估算统计量,以减轻尾部偏斜的影响,并采用静态z值1.645(因为预期不会用于小样本量n的情况,此时z可近似替代t)。
有效数字估计需与trim_sigfig方法配合使用,以提供更符合人类直觉的数据摘要。注意__repr__方法不会使用此功能,而是直接显示原始值。有效数字估计功能主要为Compare模块设计。
python
class torch.utils.benchmark.CallgrindStats(task_spec, number_per_run, built_with_debug_symbols, baseline_inclusive_stats, baseline_exclusive_stats, stmt_inclusive_stats, stmt_exclusive_stats, stmt_callgrind_out)Timer收集的Callgrind结果顶级容器。
通常通过FunctionCounts类进行操作,该类可通过调用CallgrindStats.stats(...)获取。同时还提供了多个便捷方法,其中最重要的是CallgrindStats.as_standardized()。
python
as_standardized()从函数字符串中去除库名称和某些前缀。
在比较两组不同的指令计数时,路径前缀可能成为绊脚石。Callgrind 在报告函数时会包含完整文件路径(这是合理的做法)。然而,这在进行性能分析对比时可能引发问题。例如,如果关键组件(如 Python 或 PyTorch)在两个分析文件中分别构建于不同位置,可能会导致类似以下情况:
python
23234231 /tmp/first_build_dir/thing.c:foo(...)
9823794 /tmp/first_build_dir/thing.c:bar(...)
...
53453 .../aten/src/Aten/...:function_that_actually_changed(...)
...
-9823794 /tmp/second_build_dir/thing.c:bar(...)
-23234231 /tmp/second_build_dir/thing.c:foo(...)通过去除前缀可以改善这一问题,它能规范化字符串并在差异比较时实现更好的等效调用点消除效果。
返回类型:CallgrindStats
python
counts(*, denoise=False)返回已执行指令的总数。
关于去噪参数的解释,请参阅 FunctionCounts.denoise()。
返回类型:int
python
delta(other, inclusive=False)对比两组计数数据。
收集指令计数的一个常见原因是为了确定特定变更对执行某项工作单元所需指令数量的影响。如果变更导致指令数增加,接下来自然要问"为什么"。这通常需要查看代码中哪部分的指令计数有所增加。此函数自动化了这一过程,使用户能够轻松地进行包含性和排他性的计数差异分析。
返回类型:FunctionCounts
python
stats(inclusive=False)返回详细的函数调用计数。
从概念上讲,返回的FunctionCounts可以视为由(计数, 路径及函数名)元组组成的元组。
参数inclusive的语义与callgrind一致。若设为True,计数将包含子函数执行的指令。inclusive=True适用于识别代码热点;inclusive=False则有助于在比较两次运行的计数差异时减少干扰(更多细节请参阅CallgrindStats.delta(...))。
返回类型:FunctionCounts
python
class torch.utils.benchmark.FunctionCounts(_data, inclusive, truncate_rows=True, _linewidth=None)用于操作 Callgrind 结果的容器。
支持功能包括:
1、通过加减运算合并或对比结果
2、类元组索引访问
3、降噪功能,可去除已知非确定性且噪声较大的 CPython 调用
4、提供两种高阶方法(filter 和 transform)用于自定义操作处理
python
denoise()移除已知的噪声指令。
CPython解释器中有几个指令会产生较多噪声。这些指令涉及Unicode到字典的查找操作,Python用这种方式来映射变量名。FunctionCounts通常是一个与内容无关的容器,但对于获取可靠结果而言,这个处理非常重要,因此需要作为例外情况处理。
返回类型:FunctionCounts
python
filter(filter_fn)仅保留函数名经 filter_fn 处理后返回 True 的元素。
返回类型:FunctionCounts
python
transform(map_fn)对所有函数名称应用map_fn映射。
该功能可用于:
- 规范化函数名称(例如去除文件路径中的无关部分)
- 通过将多个函数映射到相同名称来合并条目(此时计数会累加)
返回类型:
FunctionCounts
python
class torch.utils.benchmark.Compare(results)用于以格式化表格形式展示多项测量结果的辅助类。
该表格格式基于 torch.utils.benchmark.Timer 提供的信息字段(description、label、sub_label、num_threads 等)。
可通过 print() 直接打印表格,或转换为字符串。
完整使用教程请参阅:
https://pytorch.org/tutorials/recipes/recipes/benchmark.html
参数
results (list[torch.utils.benchmark.utils.common.Measurement])-- 待展示的 Measurement 对象列表
python
colorize(rowwise=False)为格式化表格添加颜色。
默认按列着色。
python
extend_results(results)将结果追加到已存储的数据中。
所有添加的结果必须是 Measurement 的实例。
python
highlight_warnings()启用格式化表格构建时的警告高亮功能。
python
print()打印格式化表格
python
trim_significant_figures()在构建格式化表格时启用有效数字的截断功能。
torch.utils.bottleneck
torch.utils.bottleneck 是一个工具,可作为程序性能瓶颈调试的初步步骤。它会结合 Python 分析器和 PyTorch 的自动梯度分析器来汇总脚本的运行情况。
在命令行中通过以下方式运行:
shell
python -m torch.utils.bottleneck /path/to/source/script.py [args]其中args是传递给script.py的任意数量参数,或运行python -m torch.utils.bottleneck -h获取更多使用说明。
警告:由于脚本将被性能分析,请确保它能在有限时间内退出。
警告:由于CUDA内核的异步特性,在分析CUDA代码时,cProfile输出和CPU模式的自动梯度分析器可能无法显示正确的时间:报告的CPU时间仅包含内核启动耗时,除非操作执行了同步,否则不会包含内核在GPU上的实际执行时间。
在常规CPU模式分析器下,执行同步的操作会显得极其耗时。
当出现计时不准确的情况时,CUDA模式的自动梯度分析器可能会有所帮助。
注意:要决定查看哪种(仅CPU模式或CUDA模式)自动梯度分析器输出,首先应检查脚本是否受CPU限制("CPU总时间远大于CUDA总时间")。
如果是CPU受限,查看CPU模式分析器的结果将有所帮助。反之,如果脚本大部分时间在GPU上执行,则应开始查看CUDA模式分析器输出中相关的CUDA算子。
当然实际情况更为复杂,根据模型评估部分的不同,脚本可能不处于这两种极端情况。如果分析器输出没有帮助,可以尝试结合nvprof查看torch.autograd.profiler.emit_nvtx()的结果。
但请注意NVTX的开销非常高,通常会导致时间线严重失真。类似地,Intel® VTune™ Profiler可通过torch.autograd.profiler.emit_itt()进一步分析Intel平台的性能。
警告:如果分析CUDA代码,bottleneck运行的第一个分析器(cProfile)会在时间报告中包含CUDA启动时间(CUDA缓冲区分配成本)。当瓶颈导致的代码延迟远大于CUDA启动时间时,这通常不会产生影响。
关于分析器更复杂的用法(如多GPU场景),请参阅https://docs.python.org/3/library/profile.html或torch.autograd.profiler.profile()获取更多信息。
torch.utils.checkpoint
注意:检查点机制通过在反向传播期间重新运行每个检查点段的前向传播段来实现。这可能导致持久状态(如RNG随机数生成器状态)比不使用检查点时更超前。默认情况下,检查点包含处理RNG状态的逻辑,使得使用RNG的检查点传递(例如通过dropout)与非检查点传递相比具有确定性输出。根据检查点操作的运行时情况,保存和恢复RNG状态的逻辑可能会带来中等性能损耗。如果不需要与非检查点传递相比的确定性输出,可以向checkpoint或checkpoint_sequential传入preserve_rng_state=False来省略每次检查点时对RNG状态的保存和恢复。
该保存逻辑会为CPU和另一种设备类型(通过_infer_device_type从非CPU张量参数推断设备类型)向run_fn保存并恢复RNG状态。如果存在多个设备,仅会保存单一设备类型的设备状态,其余设备将被忽略。因此,如果任何检查点函数涉及随机性,这可能导致梯度计算错误。(注意:如果检测到CUDA设备,将优先处理;否则会选择遇到的第一个设备。)如果没有CPU张量,将保存和恢复默认设备类型状态(默认值为cuda,可通过DefaultDeviceType设置为其他设备)。
但该逻辑无法预知用户是否会在run_fn内部将张量移动到新设备。因此,如果在run_fn内将张量移动到新设备("新"指不属于当前设备+张量参数设备集合),与非检查点传递相比的确定性输出将永远无法得到保证。
python
torch.utils.checkpoint.checkpoint(function, *args, use_reentrant=None, context_fn=<function noop_context_fn>, determinism_check='default', debug=False, **kwargs)对模型或部分模型进行检查点保存。
激活检查点是一种用计算资源换取内存空间的技术。在检查点区域的前向计算中,不会保存用于反向传播的张量,而是在反向传播时重新计算这些张量,而不是将它们一直保留到梯度计算时才使用。激活检查点可以应用于模型的任何部分。
目前有两种检查点实现方式,由use_reentrant参数决定。建议使用use_reentrant=False。关于两者差异的讨论,请参考下文说明。
警告 :如果在反向传播过程中function的调用与前向传播不同(例如由于全局变量导致),检查点版本可能不等价,可能会引发错误或导致梯度计算静默错误。
警告 :必须显式传递use_reentrant参数。在2.4版本中,如果未传递该参数将会抛出异常。如果使用use_reentrant=True变体,请参考下文说明了解重要注意事项和潜在限制。
说明 :可重入检查点(use_reentrant=True)与非可重入检查点(use_reentrant=False)存在以下差异:
-
非可重入检查点会在所有需要的中间激活值重新计算完成后立即停止。此功能默认启用,但可通过
set_checkpoint_early_stop()禁用。 -
可重入检查点在反向传播时会完整地重新计算整个
function。 -
可重入变体在前向传播时不记录autograd计算图,因为它在前向传播时运行在
torch.no_grad()模式下。非可重入版本会记录autograd计算图,允许在检查点区域内对计算图执行反向传播。 -
可重入检查点仅支持不带输入参数的
torch.autograd.backward()API进行反向传播,而非可重入版本支持所有反向传播方式。 -
可重入变体要求至少有一个输入和输出具有
requires_grad=True。如果不满足此条件,模型的检查点部分将没有梯度。非可重入版本没有此要求。 -
可重入版本不认为嵌套结构中的张量(如自定义对象、列表、字典等)参与autograd计算,而非可重入版本则认为参与。
-
可重入检查点不支持计算图中分离张量的检查点区域,而非可重入版本支持。对于可重入变体,如果检查点段包含使用
detach()或torch.no_grad()分离的张量,反向传播将引发错误。这是因为checkpoint会使所有输出都需要梯度,当模型中定义不需要梯度的张量时会导致问题。为避免此问题,应在checkpoint函数外部分离张量。
参数说明
function- 描述模型或部分模型在前向传播中运行的内容。它还应知道如何处理作为元组传递的输入。例如在LSTM中,如果用户传递(activation, hidden),function应正确使用第一个输入作为activation,第二个输入作为hiddenpreserve_rng_state ([bool], 可选)- 是否在每个检查点期间省略保存和恢复RNG状态。注意在torch.compile下,此标志不生效,我们始终保留RNG状态。默认值:Trueuse_reentrant ([bool])- 指定是否使用需要可重入autograd的激活检查点变体。必须显式传递此参数。在2.5版本中,如果未传递该参数将会抛出异常。如果use_reentrant=False,checkpoint将使用不需要可重入autograd的实现,从而支持更多功能,如与torch.autograd.grad正常配合工作,并支持向检查点函数输入关键字参数。context_fn (Callable, 可选)- 返回两个上下文管理器元组的可调用对象。函数及其重新计算将分别在第一个和第二个上下文管理器下运行。仅当use_reentrant=False时支持此参数。determinism_check (str, 可选)- 指定确定性检查的字符串。默认为"default",会比较重新计算张量与保存张量的形状、数据类型和设备。要关闭此检查,请指定"none"。目前仅支持这两个值。如需更多确定性检查,请提交issue。仅当use_reentrant=False时支持此参数,若use_reentrant=True则始终禁用确定性检查。debug ([bool], 可选)- 如果为True,错误信息还将包含原始前向计算和重新计算期间运行的操作符追踪。仅当use_reentrant=False时支持此参数。args- 包含function输入参数的元组
返回值
运行function在*args上的输出结果
python
torch.utils.checkpoint.checkpoint_sequential(functions, segments, input, use_reentrant=None, **kwargs)对顺序模型进行检查点保存以节省内存。
顺序模型会按顺序执行一系列模块/函数(即顺序执行)。因此,我们可以将这类模型划分为多个片段,并对每个片段设置检查点。除最后一段外,其他片段都不会存储中间激活值。每个检查点片段的输入会被保存,以便在反向传播时重新运行该片段。
警告:必须显式传递 use_reentrant 参数。在 2.4 版本中,如果没有传递该参数,我们将抛出异常。
如果使用 use_reentrant=True 的变体,请参阅 :func:~torch.utils.checkpoint.checkpoint 了解该变体的重要注意事项和限制。建议使用 use_reentrant=False。
参数
functions-- 一个torch.nn.Sequential或组成模型的模块/函数列表,将按顺序执行。segments-- 在模型中创建的块数input-- 输入到functions的张量preserve_rng_state ([bool], 可选)-- 是否在每个检查点期间跳过保存和恢复 RNG 状态。默认值:Trueuse_reentrant ([bool])-- 指定是否使用需要可重入自动求导的激活检查点变体。必须显式传递此参数。在 2.5 版本中,如果没有传递该参数,我们将抛出异常。如果use_reentrant=False,checkpoint将使用不需要可重入自动求导的实现。这使得checkpoint能够支持更多功能,例如与torch.autograd.grad正常配合工作,并支持向检查点函数传入关键字参数。
返回值:在 *inputs 上顺序执行 functions 的输出
示例
python
>>> model = nn.Sequential(...)
>>> input_var = checkpoint_sequential(model, chunks, input_var)
python
torch.utils.checkpoint.set_checkpoint_debug_enabled(enabled)上下文管理器 ,用于设置运行检查点时是否应打印额外的调试信息。有关详细信息,请参阅 checkpoint() 的 debug 参数。请注意,当启用时,此上下文管理器会覆盖传递给检查点的 debug 值。若要遵循局部设置,请向此上下文传递 None。
参数
enabled ([bool])-- 控制检查点是否打印调试信息。
默认值为None。
python
class torch.utils.checkpoint.CheckpointPolicy(value)用于指定反向传播期间检查点策略的枚举类型。
支持以下策略:
{MUST,PREFER}_SAVE:在正向传播期间保存操作输出,反向传播时不会重新计算{MUST,PREFER}_RECOMPUTE:在正向传播期间不保存操作输出,反向传播时会重新计算
优先使用MUST_*而非PREFER_*,以表明该策略不应被其他子系统(如torch.compile)覆盖。
注意:始终返回PREFER_RECOMPUTE的策略函数等效于原始检查点机制。
而每个操作都返回PREFER_SAVE的策略函数并不等同于不使用检查点机制。使用此类策略会保存额外的张量,这些张量不仅限于梯度计算实际需要的部分。
python
class torch.utils.checkpoint.SelectiveCheckpointContext(*, is_recompute)在选择性检查点过程中传递给策略函数的上下文。
此类用于在选择性检查点过程中向策略函数传递相关元数据。元数据包括当前策略函数调用是否发生在重新计算期间。
示例
python
>>> >
>>> def policy_fn(ctx, op, args, *kwargs):
>>> print(ctx.is_recompute)
>>> >
>>> context_fn = functools.partial(create_selective_checkpoint_contexts, policy_fn)
>>> >
>>> out = torch.utils.checkpoint.checkpoint(
>>> fn, x, y, >> use_reentrant=False, >> context_fn=context_fn, >>)
python
torch.utils.checkpoint.create_selective_checkpoint_contexts(policy_fn_or_list, allow_cache_entry_mutation=False)用于避免在激活检查点期间重新计算某些操作的辅助工具。
与 torch.utils.checkpoint.checkpoint 配合使用,可控制在反向传播过程中需要重新计算哪些操作。
参数
-
policy_fn_or_list (Callable* 或 *List)---
如果提供策略函数,该函数应接受一个
SelectiveCheckpointContext上下文、OpOverload操作、该操作的参数及关键字参数,并返回一个CheckpointPolicy枚举值,指示是否应重新计算该操作的执行。 -
如果提供操作列表,则等效于一个策略:对指定操作返回
CheckpointPolicy.MUST_SAVE,对其他所有操作返回CheckpointPolicy.PREFER_RECOMPUTE。
-
-
allow_cache_entry_mutation ([bool], 可选)-- 默认情况下,如果选择性激活检查点缓存的任何张量发生变更,会触发错误以确保正确性。若设为 True,则禁用此检查。
返回
包含两个上下文管理器的元组。
示例:
python
>>> import functools
>>> >
>>> x = torch.rand(10, 10, requires_grad=True)
>>> y = torch.rand(10, 10, requires_grad=True)
>>> >
>>> ops_to_save = [
>>> torch.ops.aten.mm.default, >>]
>>> >
>>> def policy_fn(ctx, op, args, *kwargs):
>>> if op in ops_to_save:
>>> return CheckpointPolicy.MUST_SAVE
>>> else:
>>> return CheckpointPolicy.PREFER_RECOMPUTE
>>> >
>>> context_fn = functools.partial(create_selective_checkpoint_contexts, policy_fn)
>>> >
>>> # or equivalently
>>> context_fn = functools.partial(create_selective_checkpoint_contexts, ops_to_save)
>>> >
>>> def fn(x, y):
>>> return torch.sigmoid(torch.matmul(torch.matmul(x, y), y)) * y
>>> >
>>> out = torch.utils.checkpoint.checkpoint(
>>> fn, x, y, >> use_reentrant=False, >> context_fn=context_fn, >>)torch.utils.cpp_extension
(注:根据核心翻译原则,标题中的代码部分torch.utils.cpp_extension保持原样未翻译,仅添加了中文括号说明翻译行为)
python
torch.utils.cpp_extension.CppExtension(name, sources, *args, **kwargs)为C++创建setuptools.Extension。
这是一个便捷方法,用于创建带有构建C++扩展所需最基本(但通常足够)参数的setuptools.Extension。
所有参数都会转发给setuptools.Extension的构造函数。完整参数列表可查阅https://setuptools.pypa.io/en/latest/userguide/ext_modules.html#extension-api-reference
警告:PyTorch的Python API(由libtorch_python提供)不能使用py_limited_api=True标志进行构建。当传递此标志时,用户需确保其库中不使用来自libtorch_python的API(特别是pytorch/python绑定),而仅使用来自libtorch的API(aten对象、运算符和调度器)。例如,要从Python访问自定义操作,库应通过调度器注册这些操作。
与CPython的setuptools不同(当在setup中为"bdist_wheel"命令指定py_limited_api选项时,它不会定义-DPy_LIMITED_API作为编译标志),PyTorch会这样做!我们将指定-DPy_LIMITED_API=min_supported_cpython以最佳方式强制实现一致性、安全性和合理性,从而鼓励最佳实践。要针对不同版本,请将min_supported_cpython设置为所选CPython版本的十六进制代码。
示例
python
>>> from setuptools import setup
>>> from torch.utils.cpp_extension import BuildExtension, CppExtension
>>> setup(
... name='extension',
... ext_modules=[
... CppExtension(
... name='extension',
... sources=['extension.cpp'],
... extra_compile_args=['-g'],
... extra_link_args=['-Wl,--no-as-needed', '-lm'])
... ],
... cmdclass={
... 'build_ext': BuildExtension
... })
python
torch.utils.cpp_extension.CUDAExtension(name, sources, *args, **kwargs)为CUDA/C++创建setuptools.Extension。
这是一个便捷方法,用于创建带有构建CUDA/C++扩展所需最基本(但通常足够)参数的setuptools.Extension。这些参数包括CUDA包含路径、库路径和运行时库。
所有参数都会转发给setuptools.Extension构造函数。完整参数列表可查阅https://setuptools.pypa.io/en/latest/userguide/ext_modules.html#extension-api-reference
警告:PyTorch的Python API(由libtorch_python提供)不能使用py_limited_api=True标志进行构建。当传递此标志时,用户需确保其库中不使用来自libtorch_python的API(特别是pytorch/python绑定),而仅使用来自libtorch的API(aten对象、运算符和调度器)。例如,要从Python访问自定义操作,库应通过调度器注册这些操作。
与CPython的setuptools不同(当在setup中将py_limited_api指定为"bdist_wheel"命令选项时,CPython不会定义-DPy_LIMITED_API作为编译标志),PyTorch会这样做!我们将指定-DPy_LIMITED_API=min_supported_cpython以最佳方式强制执行一致性、安全性和合理性,从而鼓励最佳实践。要针对不同版本,请将min_supported_cpython设置为所选CPython版本的十六进制代码。
示例
python
>>> from setuptools import setup
>>> from torch.utils.cpp_extension import BuildExtension, CUDAExtension
>>> setup(
... name='cuda_extension',
... ext_modules=[
... CUDAExtension(
... name='cuda_extension',
... sources=['extension.cpp', 'extension_kernel.cu'],
... extra_compile_args={'cxx': ['-g'],
... 'nvcc': ['-O2']},
... extra_link_args=['-Wl,--no-as-needed', '-lcuda'])
... ],
... cmdclass={
... 'build_ext': BuildExtension
... })计算能力:
默认情况下,扩展会被编译为支持构建过程中可见显卡的所有架构版本,外加PTX。如果后续安装了新显卡,可能需要重新编译扩展。如果可见显卡的计算能力(CC)版本高于当前nvcc能完全编译二进制文件的最新支持版本,PyTorch会让nvcc回退到使用当前nvcc支持的最新PTX版本来构建内核(PTX详情见下文)。
您可以通过TORCH_CUDA_ARCH_LIST覆盖默认行为,显式指定扩展需要支持的CC版本:
TORCH_CUDA_ARCH_LIST="6.1 8.6" python build_my_extension.py
TORCH_CUDA_ARCH_LIST="5.2 6.0 6.1 7.0 7.5 8.0 8.6+PTX" python build_my_extension.py
+PTX选项会使扩展内核二进制文件包含指定CC版本的PTX指令。PTX是一种中间表示形式,允许内核在运行时针对任何大于等于指定CC版本的显卡进行编译(例如8.6+PTX生成的PTX可以针对CC≥8.6的GPU进行运行时编译)。这会增强二进制文件的向前兼容性。但依赖旧版PTX通过运行时编译支持新版CC,可能会轻微影响新版CC上的性能表现。如果明确知道目标GPU的具体CC版本,单独指定这些版本总是更好的选择。例如,若需要扩展支持8.0和8.6版本,"8.0+PTX"在功能上可行(因其包含可针对8.6运行时编译的PTX),但"8.0 8.6"才是更优方案。
请注意:虽然可以包含所有支持的架构版本,但包含的版本越多,构建过程就越慢,因为每个架构版本都需要构建独立的内核映像。
注意:Windows平台上,CUDA-11.5的nvcc在解析torch/extension.h时会出现内部编译器错误。解决方法是将Python绑定逻辑移至纯C++文件。
使用示例:
#include <ATen/ATen.h> at::Tensor SigmoidAlphaBlendForwardCuda(....)替代方案:
#include <torch/extension.h> torch::Tensor SigmoidAlphaBlendForwardCuda(...)当前关于 nvcc 错误的未解决问题:https://github.com/pytorch/pytorch/issues/69460
完整解决方案代码示例:https://github.com/facebookresearch/pytorch3d/commit/cb170ac024a949f1f9614ffe6af1c38d972f7d48
可重定位设备代码链接说明:
若需要在编译单元之间(跨目标文件)引用设备符号,则必须使用可重定位设备代码选项(-rdc=true 或 -dc)来构建目标文件。
此规则的一个例外是"动态并行"(嵌套内核启动),该特性目前已较少使用。
由于可重定位设备代码优化程度较低,应仅对确实需要的目标文件使用该选项。
在设备代码编译阶段和 dlink 阶段使用 -dlto(设备链接时优化)有助于减轻 -rdc 可能带来的性能损耗。
注意:必须在这两个阶段同时使用该选项才能生效。
若存在 rdc 编译的目标文件,则需在 CPU 符号链接步骤前增加额外的 -dlink(设备链接)步骤。
还存在一种无需 -rdc 但需使用 -dlink 的情况:当扩展模块链接到包含 rdc 编译对象的静态库时,
例如 NVSHMEM 库。
注意:使用 RDC 链接构建 CUDA 扩展时必须使用 Ninja 编译系统。
示例
python
>>> CUDAExtension(
... name='cuda_extension',
... sources=['extension.cpp', 'extension_kernel.cu'],
... dlink=True,
... dlink_libraries=["dlink_lib"],
... extra_compile_args={'cxx': ['-g'],
... 'nvcc': ['-O2', '-rdc=true']})
python
torch.utils.cpp_extension.SyclExtension(name, sources, *args, **kwargs)为SYCL/C++创建setuptools.Extension的便捷方法。
该方法会创建一个带有最基本(但通常足够)参数的setuptools.Extension,用于构建SYCL/C++扩展模块。所有参数都会被转发给setuptools.Extension的构造函数。
警告 :PyTorch的Python API(由libtorch_python提供)不能使用py_limited_api=True标志进行构建。当传递此标志时,用户需确保其库中不使用来自libtorch_python的API(特别是pytorch/python绑定),而仅使用来自libtorch的API(aten对象、运算符和调度器)。例如,若要从Python访问自定义操作,库应通过调度器注册这些操作。
与CPython的setuptools不同(当在setup中将py_limited_api指定为"bdist_wheel"命令选项时,CPython不会定义-DPy_LIMITED_API编译标志),PyTorch会这样做!我们将指定-DPy_LIMITED_API=min_supported_cpython以最大程度地确保一致性、安全性和合理性,从而鼓励最佳实践。若要针对不同版本,请将min_supported_cpython设置为所选CPython版本的十六进制代码。
示例:
python
>>> from torch.utils.cpp_extension import BuildExtension, SyclExtension
>>> setup(
... name='xpu_extension',
... ext_modules=[
... SyclExtension(
... name='xpu_extension',
... sources=['extension.cpp', 'extension_kernel.cpp'],
... extra_compile_args={'cxx': ['-g', '-std=c++20', '-fPIC']})
... ],
... cmdclass={
... 'build_ext': BuildExtension
... })默认情况下,该扩展会被编译为支持构建过程中可见显卡的所有架构。如果后续安装了新显卡,可能需要重新编译扩展。您可以通过 TORCH_XPU_ARCH_LIST 覆盖默认行为,显式指定扩展需要支持的设备架构:
TORCH_XPU_ARCH_LIST="pvc,xe-lpg" python build_my_extension.py
请注意,虽然可以包含所有支持的架构,但包含的架构越多,构建过程会越慢,因为需要为每个架构单独构建内核镜像。
注意:构建 SyclExtension 需要 Ninja。
python
torch.utils.cpp_extension.BuildExtension(*args, **kwargs)一个自定义的 setuptools 构建扩展。
这个 setuptools.build_ext 子类负责传递最低要求的编译器标志(例如 -std=c++17),以及处理混合的 C++/CUDA/SYCL 编译(并支持一般的 CUDA/SYCL 文件)。
使用 BuildExtension 时,可以为 extra_compile_args 提供一个字典(而非通常的列表),该字典将语言/编译器(仅支持 cxx、nvcc 或 sycl)映射到要传递给编译器的额外标志列表。
这使得在混合编译期间能够为 C++、CUDA 和 SYCL 编译器提供不同的标志。
use_ninja (布尔值):如果 use_ninja 为 True(默认值),则尝试使用 Ninja 后端进行构建。与标准的 setuptools.build_ext 相比,Ninja 能显著加快编译速度。
如果 Ninja 不可用,则回退到标准的 distutils 后端。
注意:默认情况下,Ninja 后端使用 #CPUS + 2 个工作线程来构建扩展。在某些系统上,这可能会占用过多资源。可以通过将 MAX_JOBS 环境变量设置为非负数来控制工作线程的数量。
python
torch.utils.cpp_extension.load(name, sources, extra_cflags=None, extra_cuda_cflags=None, extra_sycl_cflags=None, extra_ldflags=None, extra_include_paths=None, build_directory=None, verbose=False, with_cuda=None, with_sycl=None, is_python_module=True, is_standalone=False, keep_intermediates=True)即时加载 PyTorch C++ 扩展(JIT)。
要加载扩展,系统会生成一个 Ninja 构建文件,用于将给定的源代码编译成动态库。随后该库会作为模块加载到当前 Python 进程中,并由此函数返回以供使用。
默认情况下,构建文件的输出目录和生成的库文件路径为 <tmp>/torch_extensions/<name>,其中 <tmp> 是当前平台的临时文件夹,<name> 是扩展的名称。可通过两种方式覆盖此路径:
1、若设置了 TORCH_EXTENSIONS_DIR 环境变量,它将替换 <tmp>/torch_extensions,所有扩展都将编译到该目录的子文件夹中。
2、若提供了本函数的 build_directory 参数,它将完全覆盖默认路径,即库会直接编译到指定文件夹。
编译源代码时默认使用系统编译器 (c++),可通过设置 CXX 环境变量覆盖。要向编译过程传递额外参数,可提供 extra_cflags 或 extra_ldflags。例如,要启用优化编译扩展,可传递 extra_cflags=['-O3']。也可通过 extra_cflags 传递额外的包含目录。
支持混合编译 CUDA 代码。只需将 CUDA 源文件(.cu 或 .cuh)与其他源文件一起传递,这些文件会被检测并使用 nvcc 而非 C++ 编译器编译。系统会自动添加 CUDA lib64 目录作为库目录并链接 cudart。可通过 extra_cuda_cflags 向 nvcc 传递额外标志,类似于 C++ 的 extra_cflags。系统采用多种启发式方法查找 CUDA 安装目录,通常效果良好。若失败,设置 CUDA_HOME 环境变量是最稳妥的方案。
支持混合编译 SYCL 代码。只需将 SYCL 源文件(.sycl)与其他源文件一起传递,这些文件会被检测并使用 SYCL 编译器(如 Intel DPC++ 编译器)而非 C++ 编译器编译。可通过 extra_sycl_cflags 向 SYCL 编译器传递额外标志,类似于 C++ 的 extra_cflags。SYCL 编译器应通过系统 PATH 环境变量查找。
参数
name-- 要构建的扩展名,必须与 pybind11 模块名相同sources (Union[str, list[str]])-- C++ 源文件的相对或绝对路径列表extra_cflags-- 可选,传递给构建的编译器标志列表extra_cuda_cflags-- 可选,构建 CUDA 源时传递给 nvcc 的编译器标志列表extra_sycl_cflags-- 可选,构建 SYCL 源时传递给 SYCL 编译器的标志列表extra_ldflags-- 可选,传递给构建的链接器标志列表extra_include_paths-- 可选,传递给构建的包含目录列表build_directory-- 可选,用作构建工作区的路径verbose-- 为True时启用加载步骤的详细日志with_cuda (Optional[bool])-- 决定是否在构建中添加 CUDA 头文件和库。默认为None,此时根据sources中是否存在.cu或.cuh自动判断。设为True强制包含with_sycl (Optional[bool])-- 决定是否在构建中添加 SYCL 头文件和库。默认为None,此时根据sources中是否存在.sycl自动判断。设为True强制包含is_python_module-- 为True(默认)时将生成的共享库作为 Python 模块导入。为False时行为取决于is_standaloneis_standalone-- 为False(默认)时将构建的扩展作为普通动态库加载到进程中。为True时构建独立可执行文件
返回
- 当
is_python_module为True时:返回加载的 PyTorch 扩展作为 Python 模块 - 当
is_python_module为False且is_standalone为False时:无返回值(共享库作为副作用加载到进程中) - 当
is_standalone为True时:返回可执行文件路径(Windows 上会作为副作用将 TORCH_LIB_PATH 添加到 PATH 环境变量)
返回类型
取决于 is_python_module 的设置
示例:
python
>>> from torch.utils.cpp_extension import load
>>> module = load(
... name='extension',
... sources=['extension.cpp', 'extension_kernel.cu'],
... extra_cflags=['-O2'],
... verbose=True)
python
torch.utils.cpp_extension.load_inline(name, cpp_sources, cuda_sources=None, sycl_sources=None, functions=None, extra_cflags=None, extra_cuda_cflags=None, extra_sycl_cflags=None, extra_ldflags=None, extra_include_paths=None, build_directory=None, verbose=False, with_cuda=None, with_sycl=None, is_python_module=True, with_pytorch_error_handling=True, keep_intermediates=True, use_pch=False)从字符串源码即时(JIT)加载PyTorch C++扩展。
该函数的行为与load()完全相同,但接收字符串形式的源码而非文件名。这些字符串会被存入构建目录的文件中,之后load_inline()的行为就与load()完全一致。
查看测试用例可以找到使用此函数的优秀示例。
源码可以省略典型非内联C++扩展的两个必需部分:必要的头文件包含和(pybind11)绑定代码。具体来说,传递给cpp_sources的字符串会先被拼接成单个.cpp文件,然后在该文件开头自动添加#include <torch/extension.h>。
此外,如果提供了functions参数,将为每个指定函数自动生成绑定。functions可以是函数名列表,也可以是函数名到文档字符串的映射字典。如果传入列表,则使用各函数名作为其文档字符串。
cuda_sources中的源码会被拼接成单独的.cu文件,并自动添加torch/types.h、cuda.h和cuda_runtime.h头文件。.cpp和.cu文件会分开编译,但最终链接为单个库。注意不会为cuda_sources中的函数本身生成绑定。要绑定CUDA内核,必须创建调用它的C++函数,并在某个cpp_sources中声明或定义该函数(并将其名称包含在functions中)。
sycl_sources中的源码会被拼接成单独的.sycl文件,并自动添加torch/types.h和sycl/sycl.hpp头文件。.cpp和.sycl文件会分开编译,但最终链接为单个库。注意不会为sycl_sources中的函数本身生成绑定。要绑定SYCL内核,必须创建调用它的C++函数,并在某个cpp_sources中声明或定义该函数(并将其名称包含在functions中)。
关于省略参数的描述,请参见load()。
参数
cpp_sources- 包含C++源码的字符串或字符串列表cuda_sources- 包含CUDA源码的字符串或字符串列表sycl_sources- 包含SYCL源码的字符串或字符串列表functions- 需要生成函数绑定的函数名列表。如果传入字典,应映射函数名到文档字符串(否则默认使用函数名作为文档字符串)with_cuda- 决定是否在构建中添加CUDA头文件和库。设为None(默认值)时,会根据是否提供cuda_sources自动判断。设为True可强制包含CUDA头文件和库with_sycl- 决定是否在构建中添加SYCL头文件和库。设为None(默认值)时,会根据是否提供sycl_sources自动判断。设为True可强制包含SYCL头文件和库with_pytorch_error_handling- 决定是否由pytorch而非pybind处理错误和警告宏。为此,每个函数foo会通过中间函数_safe_foo调用。这种重定向在某些复杂cpp场景可能导致问题。当重定向引发问题时,应将此标志设为False
示例
python
>>> from torch.utils.cpp_extension import load_inline
>>> source = """
at::Tensor sin_add(at::Tensor x, at::Tensor y) {
return x.sin() + y.sin();
}
"""
>>> module = load_inline(name='inline_extension',
... cpp_sources=[source],
... functions=['sin_add'])注意:由于 load_inline 会即时编译源代码,请确保运行时环境中已安装正确的工具链。例如,加载 C++ 代码时需确保存在 C++ 编译器;若加载 CUDA 扩展,则需额外安装对应的 CUDA 工具包(包括 nvcc 及代码所需的其他依赖项)。安装 PyTorch 时不会自动包含编译工具链,必须另行安装。
编译过程中,默认情况下 Ninja 后端会使用 #CPUS + 2 个工作线程来构建扩展。在某些系统上这可能占用过多资源。可通过设置 MAX_JOBS 环境变量为非负数值来控制工作线程数量。
python
torch.utils.cpp_extension.include_paths(device_type='cpu')获取构建 C++、CUDA 或 SYCL 扩展所需的包含路径。
参数
device_type (str)-- 默认为 "cpu"。
返回值:包含路径字符串的列表。
返回类型:list str
python
torch.utils.cpp_extension.get_compiler_abi_compatibility_and_version(compiler)判断给定的编译器及其版本是否与 PyTorch 保持 ABI 兼容。
参数
compiler (str)-- 待检查的编译器可执行文件名(例如g++)。必须能在 shell 进程中执行。
返回值:返回一个元组,其中包含一个布尔值(表示该编译器是否可能与 PyTorch 存在 ABI 不兼容)和一个 TorchVersion 字符串(以点号分隔的编译器版本号)。
返回类型:tuple bool , torch.torch_version.TorchVersion
python
torch.utils.cpp_extension.verify_ninja_availability()如果系统中没有可用的 ninja 构建系统,则抛出 RuntimeError 异常;否则不执行任何操作。
python
torch.utils.cpp_extension.is_ninja_available()如果系统上存在 ninja 构建系统则返回 True,否则返回 False。
torch.utils.data
PyTorch数据加载工具的核心是torch.utils.data.DataLoader类。它代表了一个可迭代的数据集Python对象,支持以下功能:
这些选项通过DataLoader的构造函数参数进行配置,其函数签名为:
python
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None, *, prefetch_factor=2,
persistent_workers=False)以下章节详细描述了这些选项的作用和用法。
数据集类型
DataLoader 构造函数最重要的参数是 dataset,它指定了用于加载数据的数据集对象。PyTorch 支持两种不同类型的数据集:
映射式数据集
映射式数据集是指实现了 __getitem__() 和 __len__() 协议的数据集类型,它表示从(可能非整型的)索引/键到数据样本的映射关系。
例如,当通过 dataset[idx] 访问此类数据集时,它可以从磁盘上的文件夹中读取第 idx 张图像及其对应的标签。
更多细节请参阅 Dataset 文档。
可迭代式数据集
可迭代式数据集是 IterableDataset 子类的实例,它实现了 __iter__() 协议,表示一个可遍历的数据样本序列。这种类型的数据集特别适用于随机读取成本高昂甚至不可行,以及批量大小取决于所获取数据的场景。
例如,当调用 iter(dataset) 时,此类数据集可以返回从数据库、远程服务器读取的数据流,甚至是实时生成的日志。
更多详情请参阅 IterableDataset 文档。
注意:当将 IterableDataset 与多进程数据加载结合使用时,相同的数据集对象会在每个工作进程上复制,因此必须对副本进行不同的配置以避免数据重复。具体实现方法请参考 IterableDataset 文档。
数据加载顺序与采样器
对于可迭代式数据集,数据加载顺序完全由用户自定义的迭代逻辑控制。这种方式更易于实现分块读取和动态批量大小(例如每次生成一个批处理样本)。
本节其余内容针对映射式数据集的情况。torch.utils.data.Sampler类用于指定数据加载过程中使用的索引/键序列。这些采样器是对数据集索引的可迭代对象。例如在随机梯度下降(SGD)的常见场景中,采样器可以随机打乱索引列表并逐个生成,或者为小批量SGD生成少量索引。
系统会根据DataLoader的shuffle参数自动构建顺序采样器或随机采样器。用户也可以通过sampler参数指定自定义采样器对象,该对象每次生成下一个待获取的索引/键。
若需每次生成批量索引列表,可将自定义采样器通过batch_sampler参数传入。也可以通过batch_size和drop_last参数启用自动批处理功能。更多细节请参阅下一章节。
注意:sampler和batch_sampler参数均不适用于可迭代式数据集,因为此类数据集没有键或索引的概念。
加载批处理与非批处理数据
DataLoader 支持通过参数 batch_size、drop_last、batch_sampler 和 collate_fn(具有默认函数)自动将单独获取的数据样本整理成批次。
自动批处理(默认情况)
这是最常见的情况,对应的是获取一个小批次数据并将其整理为批处理样本,即包含一个维度为批次维度(通常是第一个维度)的张量。
当 batch_size(默认为 1)不为 None 时,数据加载器会生成批处理样本而非单个样本。batch_size 和 drop_last 参数用于指定数据加载器如何获取数据集键的批次。对于映射式数据集,用户也可以选择指定 batch_sampler,它每次生成一个键列表。
注意:batch_size 和 drop_last 参数本质上用于从 sampler 构造一个 batch_sampler。对于映射式数据集,sampler 由用户提供或基于 shuffle 参数构造。对于可迭代式数据集,sampler 是一个虚拟的无限采样器。更多关于采样器的详细信息,请参阅本节。
注意:当从可迭代式数据集使用多进程获取数据时,drop_last 参数会丢弃每个工作进程数据集副本的最后一个不完整批次。
使用采样器中的索引获取样本列表后,通过 collate_fn 参数传递的函数用于将样本列表整理为批次。
在这种情况下,从映射式数据集加载数据大致相当于:
python
for indices in batch_sampler:
yield collate_fn([dataset[i] for i in indices])从可迭代式数据集加载大致等同于:
python
dataset_iter = iter(dataset)for indices in batch_sampler:
yield collate_fn([next(dataset_iter) for _ in indices])可以使用自定义的 collate_fn 来定制数据整理逻辑,例如将序列数据填充至批次中的最大长度。更多关于 collate_fn 的用法,请参阅此章节。
禁用自动批处理
在某些情况下,用户可能希望在数据集代码中手动处理批处理,或仅加载单个样本。例如,直接加载批量数据可能更高效(如从数据库批量读取或读取连续的内存块),或批处理大小依赖于数据,亦或程序设计为处理单个样本。在这些场景下,最好不要使用自动批处理(即通过collate_fn合并样本),而是让数据加载器直接返回dataset对象的每个成员。
当batch_size和batch_sampler均为None时(batch_sampler的默认值本就是None),自动批处理将被禁用。此时从dataset获取的每个样本都会通过作为collate_fn参数传入的函数进行处理。
当自动批处理被禁用时 ,默认的collate_fn仅将NumPy数组转换为PyTorch张量,并保持其他所有内容不变。
这种情况下,从映射式数据集加载数据大致等同于:
python
for index in sampler:
yield collate_fn(dataset[index])从可迭代式数据集加载大致等同于:
python
for data in iter(dataset):
yield collate_fn(data)请参阅本节了解更多关于collate_fn的信息。
使用 collate_fn
collate_fn 的用法在启用或禁用自动批处理时略有不同。
当禁用自动批处理时 ,collate_fn 会针对每个单独的数据样本调用,数据加载器迭代器直接输出处理后的结果。此时,默认的 collate_fn 仅将 NumPy 数组转换为 PyTorch 张量。
当启用自动批处理时 ,collate_fn 每次会接收一个数据样本列表。它的作用是将这些输入样本整理成一个批次,供数据加载器迭代器输出。本节后续内容将描述默认 collate_fn (default_collate()) 的行为特性。
例如,若每个数据样本包含一个 3 通道图像和整型类别标签(即数据集的每个元素返回 (image, class_index) 元组),默认的 collate_fn 会将此类元组列表整理成单个元组,包含批处理后的图像张量和类别标签张量。具体而言,默认 collate_fn 具有以下特性:
- 总是添加新维度作为批次维度
- 自动将 NumPy 数组和 Python 数值转换为 PyTorch 张量
- 保持数据结构不变------若样本是字典,则输出具有相同键的字典,但值会被转换为批处理张量(若无法转换则保持列表)。对于
list、tuple、namedtuple等结构同理
用户可通过自定义 collate_fn 实现特殊批处理需求,例如:沿非第一维度整理数据、填充不同长度的序列,或增加对自定义数据类型的支持。
如果发现 DataLoader 输出的维度或类型与预期不符,建议检查 collate_fn 的实现。
单进程与多进程数据加载
默认情况下,DataLoader 使用单进程数据加载方式。
在 Python 进程中,全局解释器锁 (GIL) 会阻止 Python 代码实现真正的跨线程并行化。为了避免数据加载阻塞计算代码,PyTorch 提供了简易的多进程数据加载切换方案------只需将 num_workers 参数设置为正整数即可实现。
单进程数据加载(默认模式)
在此模式下,数据获取操作与初始化 DataLoader 的进程相同。因此,数据加载可能会阻塞计算任务。但在以下场景中推荐使用该模式:
- 跨进程共享资源(如共享内存、文件描述符)受限时
- 整个数据集较小且可完全载入内存时
此外,单进程加载模式能提供更清晰易懂的错误堆栈信息,对调试工作尤为有利。
多进程数据加载
将参数 num_workers 设置为正整数时,会启用多进程数据加载,并创建指定数量的加载器工作进程。
警告:经过多次迭代后,工作进程会消耗与父进程相同的CPU内存,用于存储父进程中所有被工作进程访问的Python对象。如果数据集包含大量数据(例如在构建Dataset时加载了一个非常大的文件名列表)和/或使用了大量工作进程(总内存占用为 工作进程数量 * 父进程大小),这可能会引发问题。最简单的解决方案是将Python对象替换为非引用计数的表示形式,例如Pandas、Numpy或PyArrow对象。更多关于此问题的原因及示例代码的解决方法,请参阅issue #13246。
在此模式下,每次创建 DataLoader 的迭代器时(例如调用 enumerate(dataloader)),会创建 num_workers 个工作进程。此时,dataset、collate_fn 和 worker_init_fn 会被传递给每个工作进程,用于初始化和获取数据。这意味着数据集访问及其内部IO、转换(包括 collate_fn)都在工作进程中运行。
torch.utils.data.get_worker_info() 在工作进程中返回各种有用信息(包括工作进程ID、数据集副本、初始种子等),在主进程中则返回 None。用户可以在数据集代码和/或 worker_init_fn 中使用此函数,单独配置每个数据集副本,并判断代码是否在工作进程中运行。例如,这对于分片数据集特别有用。
对于映射式数据集,主进程使用 sampler 生成索引并将其发送给工作进程。因此,任何随机打乱操作都在主进程中完成,通过分配索引来指导加载。
对于可迭代式数据集,由于每个工作进程获取的是 dataset 对象的副本,简单的多进程加载通常会导致数据重复。使用 torch.utils.data.get_worker_info() 和/或 worker_init_fn,用户可以独立配置每个副本。(具体实现方法请参阅 IterableDataset 文档。)出于类似原因,在多进程加载中,drop_last 参数会丢弃每个工作进程的可迭代式数据集副本的最后一个不完整批次。
工作进程会在迭代结束时或迭代器被垃圾回收时关闭。
警告:通常不建议在多进程加载中返回CUDA张量,因为在多进程中使用CUDA和共享CUDA张量存在许多复杂问题(参见多进程中的CUDA)。相反,建议使用自动内存固定(即设置 pin_memory=True),这样可以快速将数据传输到支持CUDA的GPU。
平台特定行为
由于工作进程依赖Python的multiprocessing模块,Windows和Unix系统下的工作进程启动行为存在差异:
- 在Unix系统中,默认采用
fork()作为multiprocessing的启动方式。通过fork()创建的子工作进程通常可以直接访问克隆地址空间中的dataset和Python参数函数。 - 在Windows或MacOS系统中,默认采用
spawn()作为multiprocessing启动方式。通过spawn()会启动新的解释器来运行主脚本,随后通过pickle序列化机制将dataset、collate_fn等参数传递给内部工作函数。
这种独立的序列化机制意味着,在使用多进程数据加载时需要采取以下两个步骤来确保Windows兼容性:
- 将主脚本的主要代码封装在
if __name__ == '__main__':代码块中,防止工作进程启动时重复执行(通常会导致错误)。数据集和DataLoader实例的创建逻辑可以放在此处,因为这些代码不需要在工作进程中重复执行。 - 确保所有自定义的
collate_fn、worker_init_fn或dataset代码都声明为顶层定义(位于__main__检查之外)。这样可以保证这些函数在工作进程中可用(由于函数是通过引用而非bytecode进行序列化的,因此需要这种处理方式)。
多进程数据加载中的随机性
默认情况下,每个工作进程的PyTorch种子会被设置为base_seed + worker_id,其中base_seed是由主进程使用其随机数生成器(RNG)生成的一个长整型数(因此会强制消耗一个RNG状态)或指定的generator。然而,其他库的种子在初始化工作进程时可能会被复制,导致每个工作进程返回相同的随机数。(详见FAQ中的这一节)。
在worker_init_fn中,你可以通过torch.utils.data.get_worker_info().seed或torch.initial_seed()访问为每个工作进程设置的PyTorch种子,并在数据加载之前用它来为其他库设置种子。
内存固定
当数据从固定(页锁定)内存发起时,主机到GPU的拷贝速度会快得多。关于何时以及如何使用固定内存的更多细节,请参阅使用固定内存缓冲区。
对于数据加载,向DataLoader传递pin_memory=True会自动将获取的数据张量放入固定内存,从而加快向支持CUDA的GPU传输数据的速度。
默认的内存固定逻辑仅识别张量及包含张量的映射和可迭代对象。默认情况下,如果固定逻辑遇到自定义类型的批次(例如当你的collate_fn返回自定义批次类型时),或者批次中的每个元素都是自定义类型,固定逻辑将无法识别它们,并返回未固定内存的批次(或元素)。要为自定义批次或数据类型启用内存固定,需在你的自定义类型上定义pin_memory()方法。
参见以下示例。
示例:
python
class SimpleCustomBatch:
def __init__(self, data):
transposed_data = list(zip(data))
self.inp = torch.stack(transposed_data[0], 0)
self.tgt = torch.stack(transposed_data[1], 0)
# custom memory pinning method on custom type
def pin_memory(self):
self.inp = self.inp.pin_memory()
self.tgt = self.tgt.pin_memory()
return self
def collate_wrapper(batch):
return SimpleCustomBatch(batch)
inps = torch.arange(10 * 5, dtype=torch.float32).view(10, 5)
tgts = torch.arange(10 * 5, dtype=torch.float32).view(10, 5)
dataset = TensorDataset(inps, tgts)
loader = DataLoader(dataset, batch_size=2, collate_fn=collate_wrapper, pin_memory=True)
for batch_ndx, sample in enumerate(loader):
print(sample.inp.is_pinned())
print(sample.tgt.is_pinned())
python
class torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=None, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None, multiprocessing_context=None, generator=None, *, prefetch_factor=None, persistent_workers=False, pin_memory_device='', in_order=True)数据加载器(DataLoader)将数据集与采样器相结合,为给定数据集提供可迭代访问接口。DataLoader 支持映射式(map-style)和可迭代式(iterable-style)数据集,具备单进程/多进程加载能力,可自定义加载顺序,并支持可选的自动批处理(整理)与内存固定功能。更多细节请参阅 torch.utils.data 文档页。
参数
dataset (Dataset)-- 数据加载的目标数据集batch_size (int, 可选)-- 每批加载的样本数(默认:1)shuffle (bool, 可选)-- 设为True时会在每个epoch重新打乱数据(默认:False)sampler (Sampler 或 Iterable, 可选)-- 定义从数据集抽取样本的策略。可以是任何实现了__len__的可迭代对象。若指定此参数,则不可指定shufflebatch_sampler (Sampler 或 Iterable, 可选)-- 类似sampler,但每次返回一批索引。与batch_size、shuffle、sampler及drop_last互斥num_workers (int, 可选)-- 数据加载的子进程数。0表示在主进程加载(默认:0)collate_fn (Callable, 可选)-- 合并样本列表形成小批量张量,用于映射式数据集的批处理加载pin_memory (bool, 可选)-- 设为True时,数据加载器会在返回前将张量复制到锁页内存。若数据元素为自定义类型或collate_fn返回自定义批次,请参考示例drop_last (bool, 可选)-- 设为True时丢弃最后不完整的批次(当数据集大小不能被批次大小整除时)。若为False且不能整除,则最后批次会较小(默认:False)timeout (数值, 可选)-- 非负值,表示从工作进程收集批次的超时秒数(默认:0)worker_init_fn (Callable, 可选)-- 若非None,会在每个工作子进程初始化后、数据加载前调用,传入工作进程ID([0, num_workers - 1]的整数)(默认:None)multiprocessing_context (str 或 multiprocessing.context.BaseContext, 可选)-- 为None时使用操作系统默认的多进程上下文(默认:None)generator (torch.Generator, 可选)-- 若非None,RandomSampler 会用它生成随机索引,多进程会用它生成工作进程的base_seed(默认:None)prefetch_factor (int, 可选, 仅关键字参数)-- 每个工作进程预加载的批次数。2表示所有工作进程共预加载 2 * num_workers 批次(默认值取决于 num_workers:num_workers=0 时为None,否则为2)persistent_workers (bool, 可选)-- 设为True时,数据集消费完后不关闭工作进程,保持工作进程的 Dataset 实例存活(默认:False)pin_memory_device (str, 可选)-- 当pin_memory=True时的目标设备。未指定时默认使用当前加速器。此参数不推荐使用,未来可能废弃in_order (bool, 可选)-- 设为False时不强制按先进先出顺序返回批次。仅当num_workers > 0时生效(默认:True)
警告
- 使用
spawn启动方法时,worker_init_fn不能是不可序列化对象(如 lambda 函数)。详见 PyTorch多进程最佳实践 len(dataloader)的启发式规则基于采样器长度。对IterableDataset则基于len(dataset)/batch_size估算(考虑drop_last的舍入),该估算可能不准确:分片可能导致多工作进程产生不完整末批次,且drop_last可能丢弃多个批次样本- 参阅可复现性、数据加载器工作进程返回相同随机数及多进程数据加载的随机性说明
- 在数据不均衡场景下,设置
in_order=False可能损害可复现性并导致训练器接收倾斜的数据分布
python
class torch.utils.data.Dataset一个抽象类,用于表示从键映射到数据样本的 Dataset。
所有表示键到数据样本映射的数据集都应继承此类。子类必须重写 __getitem__() 方法,以支持根据给定键获取数据样本。子类还可以选择性地重写 __len__() 方法------许多采样器实现和 DataLoader 的默认选项会调用该方法来获取数据集大小。此外,子类可选择实现 __getitems__() 方法以加速批量样本加载,该方法接收批处理的样本索引列表并返回样本列表。
注意:DataLoader 默认会构建一个生成整数索引的采样器。若要让其支持使用非整数索引/键的映射式数据集,必须提供自定义采样器。
python
class torch.utils.data.IterableDataset一个可迭代的数据集。
所有表示数据样本可迭代对象的数据集都应继承此类。这种形式的数据集特别适用于数据来自流式源的情况。
所有子类必须重写__iter__()方法,该方法应返回该数据集中的样本迭代器。当子类与DataLoader配合使用时,数据集中的每个条目都将通过DataLoader迭代器产生。
当num_workers > 0时,每个工作进程都会拥有数据集对象的不同副本,因此通常需要单独配置每个副本,以避免从工作进程返回重复数据。在工作进程中调用get_worker_info()可获取该工作进程的信息。此方法既可用于数据集的__iter__()方法中,也可用于DataLoader的worker_init_fn选项,以修改每个副本的行为。
示例1:在__iter__()中跨所有工作进程分配工作负载:
python
>>> class MyIterableDataset(torch.utils.data.IterableDataset):
... def __init__(self, start, end):
... super(MyIterableDataset).__init__()
... assert end start, "this example code only works with end >= start"
... self.start = start
... self.end = end
...
... def __iter__(self):
... worker_info = torch.utils.data.get_worker_info()
... if worker_info is None: # single-process data loading, return the full iterator
... iter_start = self.start
... iter_end = self.end
... else: # in a worker process
... # split workload
... per_worker = int(math.ceil((self.end - self.start) / float(worker_info.num_workers)))
... worker_id = worker_info.id
... iter_start = self.start + worker_id * per_worker
... iter_end = min(iter_start + per_worker, self.end)
... return iter(range(iter_start, iter_end))
...
>>> # should give same set of data as range(3, 7), i.e., [3, 4, 5, 6].
>>> ds = MyIterableDataset(start=3, end=7)
>>> # Single-process loading
>>> print(list(torch.utils.data.DataLoader(ds, num_workers=0)))
[tensor([3]), tensor([4]), tensor([5]), tensor([6])]
>>> # Multi-process loading with two worker processes
>>> # Worker 0 fetched [3, 4]. Worker 1 fetched [5, 6].
>>> print(list(torch.utils.data.DataLoader(ds, num_workers=2)))
[tensor([3]), tensor([5]), tensor([4]), tensor([6])]
>>> # With even more workers
>>> print(list(torch.utils.data.DataLoader(ds, num_workers=12)))
[tensor([3]), tensor([5]), tensor([4]), tensor([6])]示例 2:使用 worker_init_fn 在所有工作进程间分配工作负载
python
>>> class MyIterableDataset(torch.utils.data.IterableDataset):
... def __init__(self, start, end):
... super(MyIterableDataset).__init__()
... assert end start, "this example code only works with end >= start"
... self.start = start
... self.end = end
...
... def __iter__(self):
... return iter(range(self.start, self.end))
...
>>> # should give same set of data as range(3, 7), i.e., [3, 4, 5, 6].
>>> ds = MyIterableDataset(start=3, end=7)
>>> # Single-process loading
>>> print(list(torch.utils.data.DataLoader(ds, num_workers=0)))
[3, 4, 5, 6]
>>> >
>>> # Directly doing multi-process loading yields duplicate data
>>> print(list(torch.utils.data.DataLoader(ds, num_workers=2)))
[3, 3, 4, 4, 5, 5, 6, 6]
>>> # Define a `worker_init_fn` that configures each dataset copy differently
>>> def worker_init_fn(worker_id):
... worker_info = torch.utils.data.get_worker_info()
... dataset = worker_info.dataset # the dataset copy in this worker process
... overall_start = dataset.start
... overall_end = dataset.end
... # configure the dataset to only process the split workload
... per_worker = int(math.ceil((overall_end - overall_start) / float(worker_info.num_workers)))
... worker_id = worker_info.id
... dataset.start = overall_start + worker_id * per_worker
... dataset.end = min(dataset.start + per_worker, overall_end)
...
>>> # Mult-process loading with the custom `worker_init_fn`
>>> # Worker 0 fetched [3, 4]. Worker 1 fetched [5, 6].
>>> print(list(torch.utils.data.DataLoader(ds, num_workers=2, worker_init_fn=worker_init_fn)))
[3, 5, 4, 6]
>>> # With even more workers
>>> print(list(torch.utils.data.DataLoader(ds, num_workers=12, worker_init_fn=worker_init_fn)))
[3, 4, 5, 6]
python
class torch.utils.data.TensorDataset(*tensors)数据集封装张量。
每个样本将通过沿第一维度索引张量来获取。
参数
*tensors ( Tensor )-- 具有相同第一维大小的张量。
python
class torch.utils.data.StackDataset(*args, **kwargs)数据集作为多个数据集的堆叠。
该类可用于组装作为数据集给出的复杂输入数据的不同部分。
示例
python
>>> images = ImageDataset()
>>> texts = TextDataset()
>>> tuple_stack = StackDataset(images, texts)
>>> tuple_stack[0] == (images[0], texts[0])
>>> dict_stack = StackDataset(image=images, text=texts)
>>> dict_stack[0] == {'image': images[0], 'text': texts[0]}参数
*args (Dataset)-- 以元组形式返回用于堆叠的数据集。**kwargs (Dataset)-- 以字典形式返回用于堆叠的数据集。
python
class torch.utils.data.ConcatDataset(datasets)将多个数据集拼接而成的数据集。
这个类可用于组合不同的现有数据集。
参数
datasets (sequence)-- 要拼接的数据集列表
python
class torch.utils.data.ChainDataset(datasets)用于链式组合多个IterableDataset的数据集类。
该类可用于组装不同的现有数据集流。链式操作是实时进行的,因此用此类连接大规模数据集将非常高效。
参数
datasets (iterable* *of* [IterableDataset](https://pytorch.org/docs/stable/data.html#torch.utils.data.IterableDataset "torch.utils.data.IterableDataset"))-- 需要被链式组合的数据集集合
python
class torch.utils.data.Subset(dataset, indices)在指定索引处获取数据集的子集。
参数
dataset (Dataset)-- 完整的数据集indices (sequence)-- 用于选取子集的全局索引序列
python
torch.utils.data._utils.collate.collate(batch, *, collate_fn_map=None)通用的批处理数据整理函数,用于处理每个批次中包含集合类型元素的情况。
该函数还会打开函数注册表来处理特定类型的元素。default_collate_fn_map提供了针对张量、NumPy数组、数字和字符串的默认整理函数。
参数
batch- 待整理的单个批次数据collate_fn_map (Optional[dict[Union[type,* tuple[type, ...]],* Callable]])- 可选的字典,用于映射元素类型到对应的整理函数。如果元素类型不在该字典中,本函数会按照字典的插入顺序遍历每个键,当元素类型是键的子类时,调用对应的整理函数。
示例:
python
>>> def collate_tensor_fn(batch, *, collate_fn_map):
... # Extend this function to handle batch of tensors
... return torch.stack(batch, 0)
>>> def custom_collate(batch):
... collate_map = {torch.Tensor: collate_tensor_fn}
... return collate(batch, collate_fn_map=collate_map)
>>> # Extend `default_collate` by in-place modifying `default_collate_fn_map`
>>> default_collate_fn_map.update({torch.Tensor: collate_tensor_fn})注意:每个整理函数需要一个位置参数用于批次处理,以及一个关键字参数用于指定整理函数字典(即collate_fn_map)。
python
torch.utils.data.default_collate(batch)接收一批数据,并将该批次中的元素放入一个具有额外外部维度(批次大小)的张量中。
具体输出类型可以是 torch.Tensor、torch.Tensor 序列、torch.Tensor 集合或保持不变,这取决于输入类型。
当 DataLoader 中定义了 batch_size 或 batch_sampler 时,此函数将作为默认的批次整理函数。
以下是基于批次元素类型的通用输入到输出类型映射:
torch.Tensor-torch.Tensor(添加外部批次大小维度)- NumPy 数组 -
torch.Tensor - 浮点数 -
torch.Tensor - 整数 -
torch.Tensor - 字符串 - str(保持不变)
- 字节 - bytes(保持不变)
- MappingK, V_i - MappingK, default_collate(\[V_1, V_2, ...)]
- NamedTupleV1_i, V2_i, ... - NamedTupledefault_collate(\[V1_1, V1_2, ...), default_collate(V2_1, V2_2, ...), ...]
- SequenceV1_i, V2_i, ... - Sequencedefault_collate(\[V1_1, V1_2, ...), default_collate(V2_1, V2_2, ...), ...]
参数
batch-- 需要整理的单个批次
示例
python
>>> # Example with a batch of `int`s:
>>> default_collate([0, 1, 2, 3])
tensor([0, 1, 2, 3])
>>> # Example with a batch of `str`s:
>>> default_collate(['a', 'b', 'c'])
['a', 'b', 'c']
>>> # Example with `Map` inside the batch:
>>> default_collate([{'A': 0, 'B': 1}, {'A': 100, 'B': 100}])
{'A': tensor([0, 100]), 'B': tensor([1, 100])}
>>> # Example with `NamedTuple` inside the batch:
>>> Point = namedtuple('Point', ['x', 'y'])
>>> default_collate([Point(0, 0), Point(1, 1)])
Point(x=tensor([0, 1]), y=tensor([0, 1]))
>>> # Example with `Tuple` inside the batch:
>>> default_collate([(0, 1), (2, 3)])
[tensor([0, 2]), tensor([1, 3])]
>>> # Example with `List` inside the batch:
>>> default_collate([[0, 1], [2, 3]])
[tensor([0, 2]), tensor([1, 3])]
>>> # Two options to extend `default_collate` to handle specific type
>>> # Option 1: Write custom collate function and invoke `default_collate`
>>> def custom_collate(batch):
... elem = batch[0]
... if isinstance(elem, CustomType): # Some custom condition
... return ...
... else: # Fall back to `default_collate`
... return default_collate(batch)
>>> # Option 2: In-place modify `default_collate_fn_map`
>>> def collate_customtype_fn(batch, *, collate_fn_map=None):
... return ...
>>> default_collate_fn_map.update(CustomType, collate_customtype_fn)
>>> default_collate(batch) # Handle `CustomType` automatically
python
torch.utils.data.default_convert(data)将每个NumPy数组元素转换为torch.Tensor。
如果输入是序列(Sequence)、集合(Collection)或映射(Mapping),则会尝试将其内部每个元素转换为torch.Tensor。
如果输入不是NumPy数组,则保持不变。
当DataLoader中既未定义batch_sampler也未定义batch_size时,此函数将作为默认的整理函数使用。
其输入类型到输出类型的通用映射关系与default_collate()类似。更多细节可参考该函数的描述。
参数
data------ 待转换的单个数据点
示例:
python
>>> # Example with `int`
>>> default_convert(0)
0
>>> # Example with NumPy array
>>> default_convert(np.array([0, 1]))
tensor([0, 1])
>>> # Example with NamedTuple
>>> Point = namedtuple('Point', ['x', 'y'])
>>> default_convert(Point(0, 0))
Point(x=0, y=0)
>>> default_convert(Point(np.array(0), np.array(0)))
Point(x=tensor(0), y=tensor(0))
>>> # Example with List
>>> default_convert([np.array([0, 1]), np.array([2, 3])])
[tensor([0, 1]), tensor([2, 3])]
python
torch.utils.data.get_worker_info()返回当前 DataLoader 迭代器工作进程的相关信息。
当在工作进程中调用时,该方法返回一个保证包含以下属性的对象:
id:当前工作进程的IDnum_workers:工作进程总数seed:为当前工作进程设置的随机种子。该值由主进程的随机数生成器和工作进程ID共同决定。详见DataLoader文档说明dataset:当前进程中的数据集对象副本。注意,该对象在不同进程中与主进程中的数据集对象是不同的实例
在主进程中调用时,该方法返回 None。
注意:当在传递给 DataLoader 的 worker_init_fn 中使用时,此方法可用于差异化设置每个工作进程。例如:
- 使用
worker_id配置dataset对象仅读取分片数据集中的特定部分 - 使用
seed为数据集中使用的其他库设置随机种子
返回类型:OptionalWorkerInfo
python
torch.utils.data.random_split(dataset, lengths, generator=<torch._C.Generator object>)将数据集随机分割为指定长度的非重叠新数据集。
如果提供一组总和为1的比例值,系统会自动根据公式 floor(frac * len(dataset)) 计算每个比例对应的数据长度。
计算长度后若存在余数,将采用轮询方式为各长度分配1个计数,直至余数分配完毕。
可通过固定生成器实现可复现的结果,例如:
python
>>> generator1 = torch.Generator().manual_seed(42)
>>> generator2 = torch.Generator().manual_seed(42)
>>> random_split(range(10), [3, 7], generator=generator1)
>>> random_split(range(30), [0.3, 0.3, 0.4], generator=generator2)参数
dataset (Dataset)-- 待分割的数据集lengths (sequence)-- 分割后的子集长度或比例序列generator (Generator)-- 用于随机排列的生成器
返回类型:list torch.utils.data.dataset.Subset \[\~_T]
python
class torch.utils.data.Sampler(data_source=None)所有采样器的基类。
每个 Sampler 子类都必须提供 __iter__() 方法,该方法需要支持对数据集元素的索引或索引列表(批次)进行迭代,同时可以选择提供 __len__() 方法返回迭代器的长度。
参数
data_source (Dataset)-- 该参数当前未被使用,将在 2.2.0 版本中移除。您仍可在自定义实现中使用它。
示例
python
>>> class AccedingSequenceLengthSampler(Sampler[int]):
>>> def __init__(self, data: List[str]) -None:
>>> self.data = data
>>> >
>>> def __len__(self) -int:
>>> return len(self.data)
>>> >
>>> def __iter__(self) -Iterator[int]:
>>> sizes = torch.tensor([len(x) for x in self.data])
>>> yield from torch.argsort(sizes).tolist()
>>> >
>>> class AccedingSequenceLengthBatchSampler(Sampler[List[int]]):
>>> def __init__(self, data: List[str], batch_size: int) -None:
>>> self.data = data
>>> self.batch_size = batch_size
>>> >
>>> def __len__(self) -int:
>>> return (len(self.data) + self.batch_size - 1) // self.batch_size
>>> >
>>> def __iter__(self) -Iterator[List[int]]:
>>> sizes = torch.tensor([len(x) for x in self.data])
>>> for batch in torch.chunk(torch.argsort(sizes), len(self)):
>>> yield batch.tolist()注意:DataLoader 并不严格要求实现 __len__() 方法,但在涉及计算 DataLoader 长度的场景中,通常会需要此方法。
python
class torch.utils.data.SequentialSampler(data_source)按固定顺序依次采样元素。
参数
data_source (Dataset)-- 用于采样的数据集
python
class torch.utils.data.RandomSampler(data_source, replacement=False, num_samples=None, generator=None)随机抽取样本元素。如果是不放回抽样,则从打乱的数据集中取样。
如果是有放回抽样,用户可以指定 num_samples 来抽取样本。
参数
data_source (Dataset)-- 用于抽样的数据集replacement ([bool])-- 如果为True则进行有放回抽样,默认为Falsenum_samples ( int )-- 抽取的样本数量,默认为len(dataset)generator (Generator)-- 用于抽样的生成器
python
class torch.utils.data.SubsetRandomSampler(indices, generator=None)从给定的索引列表中随机抽取元素,不重复取样。
参数
indices (sequence)-- 索引序列generator (Generator)-- 用于抽样的生成器。
python
class torch.utils.data.WeightedRandomSampler(weights, num_samples, replacement=True, generator=None)从给定的概率权重(weights)中采样元素,范围为 [0,..,len(weights)-1]。
参数
weights (sequence)-- 权重序列,不要求总和为一num_samples (int)-- 需要抽取的样本数量replacement ([bool])-- 如果为True,则采用有放回抽样。否则为无放回抽样,这意味着当某行的样本索引被抽取后,该行无法再次抽取相同的索引。generator (Generator)-- 用于抽样的生成器。
示例:
python
>>> list(WeightedRandomSampler([0.1, 0.9, 0.4, 0.7, 3.0, 0.6], 5, replacement=True))
[4, 4, 1, 4, 5]
>>> list(WeightedRandomSampler([0.9, 0.4, 0.05, 0.2, 0.3, 0.1], 5, replacement=False))
[0, 1, 4, 3, 2]
python
class torch.utils.data.BatchSampler(sampler, batch_size, drop_last)包装另一个采样器以生成小批量索引。
参数
sampler ([Sampler](https://pytorch.org/docs/stable/data.html#torch.utils.data.Sampler "torch.utils.data.Sampler") 或 *可迭代对象)- 基础采样器。可以是任何可迭代对象batch_size ( int )- 小批量的大小。drop_last ([bool])- 如果为True,采样器将丢弃最后一个小批量(如果其大小小于batch_size)
示例
python
>>> list(BatchSampler(SequentialSampler(range(10)), batch_size=3, drop_last=False))
[[0, 1, 2], [3, 4, 5], [6, 7, 8], [9]]
>>> list(BatchSampler(SequentialSampler(range(10)), batch_size=3, drop_last=True))
[[0, 1, 2], [3, 4, 5], [6, 7, 8]]
python
class torch.utils.data.distributed.DistributedSampler(dataset, num_replicas=None, rank=None, shuffle=True, seed=0, drop_last=False)一种限制数据加载到数据集子集的采样器。
它特别适合与 torch.nn.parallel.DistributedDataParallel 配合使用。在这种情况下,每个进程可以传递一个 DistributedSampler 实例作为 DataLoader 的采样器,并加载原始数据集中专属于它的子集。
注意:假设数据集的大小是恒定的,并且它的任何实例总是以相同的顺序返回相同的元素。
参数
dataset (Dataset)-- 用于采样的数据集。num_replicas (int, 可选)-- 参与分布式训练的进程数量。默认情况下,world_size从当前分布式组中获取。rank (int, 可选)-- 当前进程在num_replicas中的排名。默认情况下,rank从当前分布式组中获取。shuffle ([bool], 可选)-- 如果为True(默认值),采样器将打乱索引顺序。seed (int, 可选)-- 当shuffle=True时用于打乱采样器的随机种子。这个数字在分布式组的所有进程中应该保持一致。默认值:0。drop_last ([bool], 可选)-- 如果为True,采样器将丢弃数据的尾部,使其在副本数量之间均匀分配。如果为False,采样器将添加额外的索引以使数据在副本之间均匀分配。默认值:False。
警告:在分布式模式下,在 创建 DataLoader 迭代器之前,每个 epoch 开始时调用 set_epoch() 方法是必要的,以确保多个 epoch 之间的打乱正常工作。否则,将始终使用相同的顺序。
示例:
python
>>> sampler = DistributedSampler(dataset) if is_distributed else None
>>> loader = DataLoader(dataset, shuffle=(sampler is None),
... sampler=sampler)
>>> for epoch in range(start_epoch, n_epochs):
... if is_distributed:
... sampler.set_epoch(epoch)
... train(loader)torch.utils.deterministic
torch.utils.deterministic.fill_uninitialized_memory
一个bool值,当设置为True时,在torch.use_deterministic_algorithms()启用的情况下,会将未初始化的内存填充为已知值。浮点数和复数值会被设为NaN,整数值会被设为最大值。
默认值:True
填充未初始化内存会影响性能。因此,如果你的程序是有效的且不会将未初始化内存作为操作的输入,则可以关闭此设置以获得更好的性能,同时仍保持确定性。
当此设置启用时,以下操作会填充未初始化内存:
- 对非量化张量调用
torch.Tensor.resize_() torch.empty()torch.empty_strided()torch.empty_permuted()torch.empty_like()
torch.utils.dlpack
python
torch.utils.dlpack.from_dlpack(ext_tensor) → Tensor 将外部库中的张量转换为 torch.Tensor。
返回的 PyTorch 张量将与输入张量共享内存(输入张量可能来自其他库)。请注意,原地操作因此也会影响输入张量的数据。这可能导致意外问题(例如其他库可能设置了只读标志或使用不可变数据结构),因此用户应仅在确认无误的情况下使用此功能。
参数:
ext_tensor (具有 __dlpack__ 属性的对象,或 DLPack 胶囊)-- 待转换的张量或 DLPack 胶囊。
如果 ext_tensor 是张量(或 ndarray)对象,则必须支持 __dlpack__ 协议(即具有 ext_tensor.__dlpack__ 方法)。否则 ext_tensor 可以是 DLPack 胶囊,这是一个不透明的 PyCapsule 实例,通常由 to_dlpack 函数或方法生成。
返回类型:Tensor
示例:
python
>>> import torch.utils.dlpack
>>> t = torch.arange(4)
# Convert a tensor directly (supported in PyTorch >= 1.10)
>>> t2 = torch.from_dlpack(t)
>>> t2[:2] = -1 # show that memory is shared
>>> t2
tensor([-1, -1, 2, 3])
>>> t
tensor([-1, -1, 2, 3])
# The old-style DLPack usage, with an intermediate capsule object
>>> capsule = torch.utils.dlpack.to_dlpack(t)
>>> capsule
<capsule object "dltensor" at ...>
>>> t3 = torch.from_dlpack(capsule)
>>> t3
tensor([-1, -1, 2, 3])
>>> t3[0] = -9 # now we're sharing memory between 3 tensors
>>> t3
tensor([-9, -1, 2, 3])
>>> t2
tensor([-9, -1, 2, 3])
>>> t
tensor([-9, -1, 2, 3])
python
torch.utils.dlpack.to_dlpack(tensor) → PyCapsule 返回一个表示张量的不透明对象("DLPack胶囊")。
注意:to_dlpack 是传统的DLPack接口。它返回的胶囊在Python中除了作为from_dlpack的输入外,不能用于其他任何用途。更符合惯例的DLPack用法是直接在张量对象上调用from_dlpack------当该对象具有__dlpack__方法时(PyTorch和大多数其他库现在确实都有此方法),这种方式是可行的。
警告:对于每个通过to_dlpack生成的胶囊,仅调用一次from_dlpack。多次使用同一个胶囊的行为是未定义的。
参数
tensor-- 待导出的张量
DLPack胶囊与张量共享内存。
torch.utils.mobile_optimizer
警告:PyTorch Mobile 已不再积极维护。请关注 ExecuTorch ------ PyTorch 全新的设备端推理库。您也可以查阅 XNNPACK 和 Vulkan 代理的文档。
Torch mobile 支持通过 torch.utils.mobile_optimizer.optimize_for_mobile 工具对处于评估模式的模块运行一系列优化操作。该方法接收以下参数:一个 torch.jit.ScriptModule 对象、优化黑名单集合、需要保留的方法列表以及目标后端。
对于 CPU 后端,默认情况下如果优化黑名单为空,optimize_for_mobile 将执行以下优化:
- Conv2D + BatchNorm 融合 (黑名单选项 mobile_optimizer.MobileOptimizerType.CONV_BN_FUSION):该优化会将模块及其子模块
forward方法中的Conv2d-BatchNorm2d合并为单个Conv2d,并相应更新卷积层的权重和偏置。 - 插入并折叠预打包算子 (黑名单选项 mobile_optimizer.MobileOptimizerType.INSERT_FOLD_PREPACK_OPS):该优化会重写计算图,将 2D 卷积和线性算子替换为其预打包版本。预打包算子是状态相关算子,需要预先创建状态(如权重预打包)并在执行时使用这些状态。XNNPACK 就是提供此类预打包算子的后端,其内核针对移动平台(如 ARM CPU)进行了优化。权重预打包可实现高效内存访问,从而加速内核执行。当前优化会将
Conv2D/Linear替换为:1) 为 XNNPACK conv2d/linear 算子预打包权重的算子;2) 接收预打包权重和激活输入并生成输出的算子。由于步骤1只需执行一次,我们会折叠权重预打包操作使其仅在模型加载时执行一次。 - ReLU/Hardtanh 融合 :XNNPACK 算子支持输出激活的截断融合,即截断操作会作为内核的一部分执行(包括 2D 卷积和线性算子内核),因此截断操作实际上没有额外开销。该优化会查找跟随 XNNPACK
Conv2D/linear算子的ReLU/hardtanh算子并将其融合。 - Dropout 移除 (黑名单选项 mobile_optimizer.MobileOptimizerType.REMOVE_DROPOUT):当训练模式为 false 时,该优化会从模块中移除所有
dropout和dropout_节点。 - 卷积打包参数提升(黑名单选项 mobile_optimizer.MobileOptimizerType.HOIST_CONV_PACKED_PARAMS):该优化将卷积打包参数移动到根模块,从而可以删除卷积结构体,在不影响数值精度的前提下减小模型体积。
- Add/ReLU 融合 (黑名单选项 mobile_optimizer.MobileOptimizerType.FUSE_ADD_RELU):该优化会查找跟随
add算子的relu算子,并将其融合为单个add_relu算子。
对于 Vulkan 后端,默认情况下如果优化黑名单为空,optimize_for_mobile 将执行以下优化:
自动 GPU 传输 (黑名单选项 mobile_optimizer.MobileOptimizerType.VULKAN_AUTOMATIC_GPU_TRANSFER):该优化会重写计算图,使输入/输出数据在 GPU 间的移动成为模型的一部分。
optimize_for_mobile 还会调用 freeze_module 优化,该优化默认仅保留 forward 方法。如果您需要保留其他方法,请将其添加到保留方法列表中传入该方法。
python
torch.utils.mobile_optimizer.optimize_for_mobile(script_module, optimization_blocklist=None, preserved_methods=None, backend='CPU')优化 TorchScript 模块以适配移动端部署。
参数
script_module(ScriptModule) - 需优化的 TorchScript 模块实例,类型为 ScriptModule。optimization_blocklist(Optionalset\[torch._C._MobileOptimizerType]) - 类型为 MobileOptimizerType 的集合。未设置时,优化方法将执行所有优化流程;设置后,优化方法仅执行未包含在该集合中的优化流程。preserved_methods(Optionallist\[\~AnyStr]) - 执行 freeze_module 流程时需要保留的方法列表。backend(str) - 运行结果模型的设备类型(默认为'CPU',可选'Vulkan'或'Metal')。
返回值:优化后的新 TorchScript 模块
返回类型:RecursiveScriptModule
torch.utils.model_zoo
已迁移至 torch.hub。
python
torch.utils.model_zoo.load_url(url, model_dir=None,
map_location=None, progress=True, check_hash=False,
file_name=None, weights_only=False)从指定URL加载Torch序列化对象。
如果下载的文件是zip压缩包,将自动解压。
若对象已存在于model_dir目录中,则直接反序列化并返回。
model_dir的默认值为<hub_dir>/checkpoints,其中hub_dir是由get_dir()返回的目录路径。
参数说明
url (str)-- 待下载对象的URL地址model_dir (str, 可选)-- 保存对象的目录路径map_location (可选)-- 指定存储位置重映射的函数或字典(参见torch.load)progress ([bool], 可选)-- 是否在标准错误流显示进度条,默认为Truecheck_hash ([bool], 可选)-- 若为True,URL中的文件名部分需遵循filename-<sha256>.ext命名规范,其中<sha256>为文件内容SHA256哈希值的前8位或更多位。此哈希用于确保唯一文件名并验证文件内容完整性,默认为Falsefile_name (str, 可选)-- 下载文件的命名。未设置时使用URL中的文件名weights_only ([bool], 可选)-- 若为True,仅加载权重而不加载复杂的pickle对象。建议用于不可信数据源,详见load()说明
返回类型:dictstr, Any
示例:
python
>>> state_dict = torch.hub.load_state_dict_from_url(
... "https://s3.amazonaws.com/pytorch/models/resnet18-5c106cde.pth"
... )torch.utils.tensorboard
在深入之前,你可以在https://www.tensorflow.org/tensorboard/找到关于TensorBoard的更多详细信息。
安装TensorBoard后,这些工具允许你将PyTorch模型和指标记录到一个目录中,以便在TensorBoard界面中进行可视化。无论是PyTorch模型和张量,还是Caffe2网络和blob,都支持标量、图像、直方图、计算图和嵌入可视化。
SummaryWriter类是你记录数据以供TensorBoard使用和可视化的主要入口。例如:
python
import torch
import torchvision
from torch.utils.tensorboard import SummaryWriter
from torchvision import datasets, transforms
# Writer will output to ./runs/ directory by default
writer = SummaryWriter()
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
trainset = datasets.MNIST('mnist_train', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
model = torchvision.models.resnet50(False)
# Have ResNet model take in grayscale rather than RGB
model.conv1 = torch.nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3, bias=False)
images, labels = next(iter(trainloader))
grid = torchvision.utils.make_grid(images)
writer.add_image('images', grid, 0)
writer.add_graph(model, images)
writer.close()这可以通过 TensorBoard 进行可视化,安装和运行 TensorBoard 的命令如下:
shell
pip install tensorboard
tensorboard --logdir=runs每次实验可能会记录大量信息。为了避免界面混乱并实现更好的结果聚类,我们可以通过分层命名来对图表进行分组。
例如,"Loss/train"和"Loss/test"会被归为一组,而"Accuracy/train"和"Accuracy/test"则会在TensorBoard界面中被单独分组显示。
python
from torch.utils.tensorboard import SummaryWriter
import numpy as np
writer = SummaryWriter()
for n_iter in range(100):
writer.add_scalar('Loss/train', np.random.random(), n_iter)
writer.add_scalar('Loss/test', np.random.random(), n_iter)
writer.add_scalar('Accuracy/train', np.random.random(), n_iter)
writer.add_scalar('Accuracy/test', np.random.random(), n_iter)预期结果:
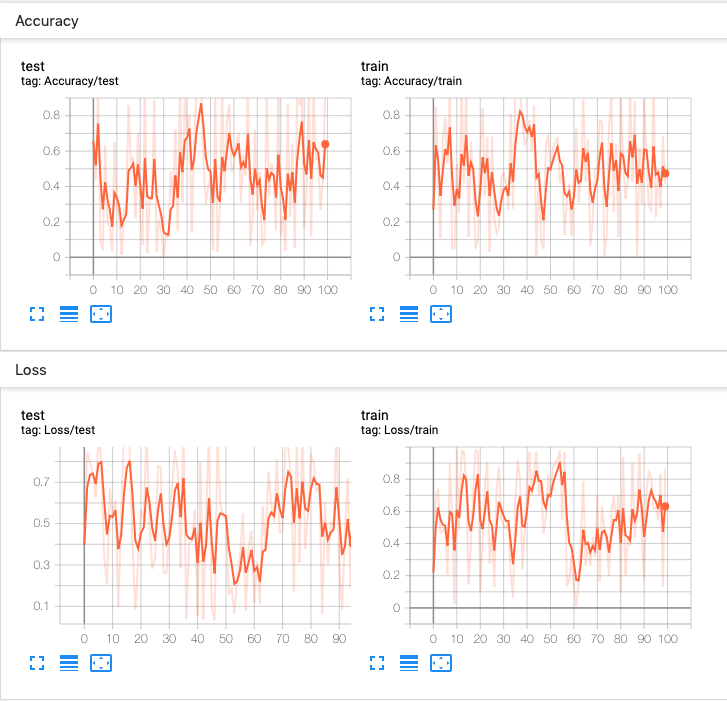
python
class torch.utils.tensorboard.writer.SummaryWriter(log_dir=None, comment='', purge_step=None, max_queue=10, flush_secs=120, filename_suffix='')将日志条目直接写入 log_dir 目录下的事件文件,供 TensorBoard 使用。
SummaryWriter 类提供了高级 API,用于在指定目录创建事件文件并添加摘要和事件。该类会异步更新文件内容,使得训练程序可以直接从训练循环中调用方法将数据添加到文件,而不会降低训练速度。
python
__init__(log_dir=None, comment='', purge_step=None, max_queue=10, flush_secs=120, filename_suffix='')创建一个用于将事件和摘要写入事件文件的 SummaryWriter。
参数
log_dir (str)-- 保存目录位置。默认值为 runs/当前日期时间_主机名,每次运行后会变化。使用层级文件夹结构便于比较不同运行结果。例如传入 'runs/exp1'、'runs/exp2' 等路径来区分不同实验。comment (str)-- 追加到默认log_dir后的注释后缀。如果已指定log_dir,则该参数无效。purge_step ( int )-- 当日志在步骤 T+X 崩溃并在步骤 T 重启时,所有 global_step 大于等于 T 的事件将被清除且不会显示在 TensorBoard 中。注意崩溃后恢复的实验应使用相同的log_dir。max_queue ( int )-- 在强制刷新到磁盘前,待处理事件和摘要的队列大小。默认为十个条目。flush_secs ( int )-- 每隔多少秒将待处理事件和摘要刷新到磁盘。默认为两分钟。filename_suffix (str)-- 添加到 log_dir 目录下所有事件文件名的后缀。更多文件名构造细节请参考 tensorboard.summary.writer.event_file_writer.EventFileWriter。
示例:
python
from torch.utils.tensorboard import SummaryWriter
# create a summary writer with automatically generated folder name.
writer = SummaryWriter()
# folder location: runs/May04_22-14-54_s-MacBook-Pro.local/
# create a summary writer using the specified folder name.
writer = SummaryWriter("my_experiment")
# folder location: my_experiment
# create a summary writer with comment appended.
writer = SummaryWriter(comment="LR_0.1_BATCH_16")
# folder location: runs/May04_22-14-54_s-MacBook-Pro.localLR_0.1_BATCH_16/
python
add_scalar(tag, scalar_value, global_step=None, walltime=None, new_style=False, double_precision=False)向摘要中添加标量数据。
参数
tag (str)-- 数据标识符scalar_value (float 或 *string/blobname)-- 要保存的值global_step ( int )-- 记录的全局步长值walltime (float)-- 可选参数,用于覆盖默认时间戳(time.time()),指定事件发生后的秒数new_style (boolean)-- 是否使用新样式(tensor字段)或旧样式(simple_value字段)。新样式可以加快数据加载速度。
示例:
python
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter()
x = range(100)for i in x:
writer.add_scalar('y=2x', i * 2, i)
writer.close()预期结果:
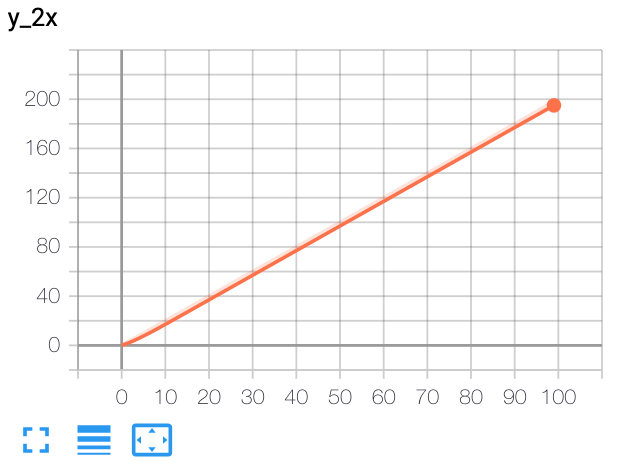
python
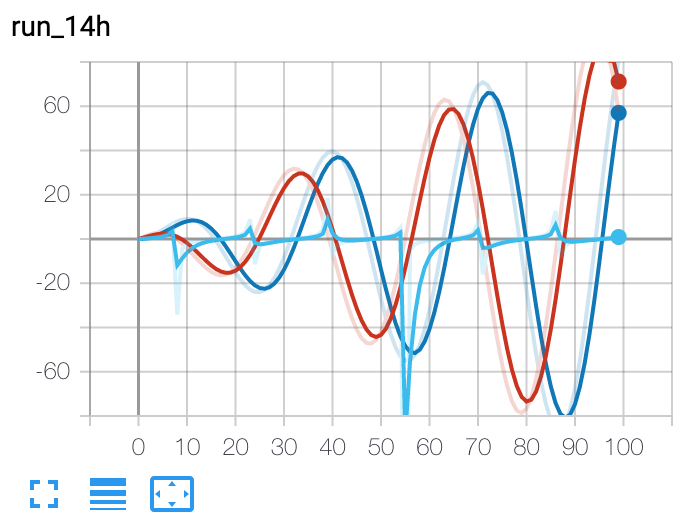
add_scalars(main_tag, tag_scalar_dict, global_step=None, walltime=None)向摘要中添加多个标量数据。
参数
main_tag (str)-- 标签的父名称tag_scalar_dict ( dict )-- 存储标签及对应值的键值对global_step ( int )-- 要记录的全局步长值walltime (float)-- 可选参数,用于覆盖默认的 walltime (time.time()),表示事件发生后的秒数
示例:
python
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter()
r = 5for i in range(100):
writer.add_scalars('run_14h', {'xsinx':i*np.sin(i/r), 'xcosx':i*np.cos(i/r), 'tanx': np.tan(i/r)}, i)
writer.close()
# This call adds three values to the same scalar plot with the tag
# 'run_14h' in TensorBoard's scalar section.预期效果:
python
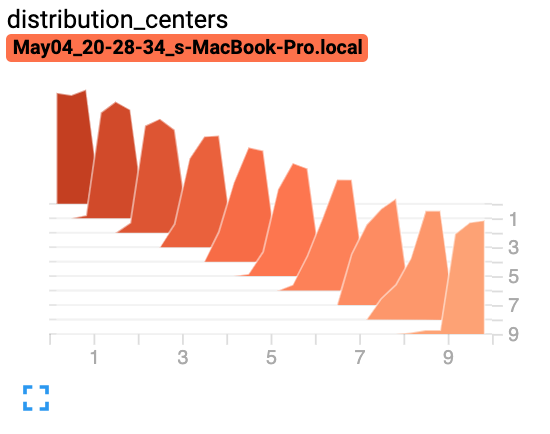
add_histogram(tag, values, global_step=None, bins='tensorflow', walltime=None, max_bins=None)向摘要中添加直方图。
参数
tag (str)-- 数据标识符values (torch.Tensor,* numpy.ndarray, 或* *string/blobname)-- 用于构建直方图的值global_step ( int )-- 记录的全局步长值bins (str)-- 可选值包括 {'tensorflow','auto', 'fd', ...}。该参数决定如何生成直方图区间。更多选项可参考:
https://docs.scipy.org/doc/numpy/reference/generated/numpy.histogram.htmlwalltime (float)-- 可选参数,用于覆盖默认的时间戳(time.time()),表示事件发生的时间(自纪元起的秒数)
示例:
python
from torch.utils.tensorboard import SummaryWriter
import numpy as np
writer = SummaryWriter()for i in range(10):
x = np.random.random(1000)
writer.add_histogram('distribution centers', x + i, i)
writer.close()预期结果:
python
add_image(tag, img_tensor, global_step=None, walltime=None, dataformats='CHW')将图像数据添加到摘要中。
注意:这需要安装 pillow 包。
参数
tag (str)-- 数据标识符img_tensor (torch.Tensor,* numpy.ndarray, 或* *string/blobname)-- 图像数据global_step ( int )-- 记录的全局步长值walltime (float)-- 可选参数,覆盖默认的 walltime (time.time())
事件发生后的秒数(从纪元开始计算)
dataformats (str)-- 图像数据格式规范,形式为
CHW, HWC, HW, WH 等。
形状:img_tensor: 默认为 (3,H,W)(3, H, W)(3,H,W)。可以使用 torchvision.utils.make_grid() 将一批张量转换为 3xHxW 格式,或者调用 add_images 让我们来完成这项工作。
只要传递了相应的 dataformats 参数,例如 CHW、HWC、HW,形状为 (1,H,W)(1, H, W)(1,H,W)、(H,W)(H, W)(H,W)、(H,W,3)(H, W, 3)(H,W,3) 的张量也是适用的。
示例:
python
from torch.utils.tensorboard import SummaryWriter
import numpy as np
img = np.zeros((3, 100, 100))
img[0] = np.arange(0, 10000).reshape(100, 100) / 10000
img[1] = 1 - np.arange(0, 10000).reshape(100, 100) / 10000
img_HWC = np.zeros((100, 100, 3))
img_HWC[:, :, 0] = np.arange(0, 10000).reshape(100, 100) / 10000
img_HWC[:, :, 1] = 1 - np.arange(0, 10000).reshape(100, 100) / 10000
writer = SummaryWriter()
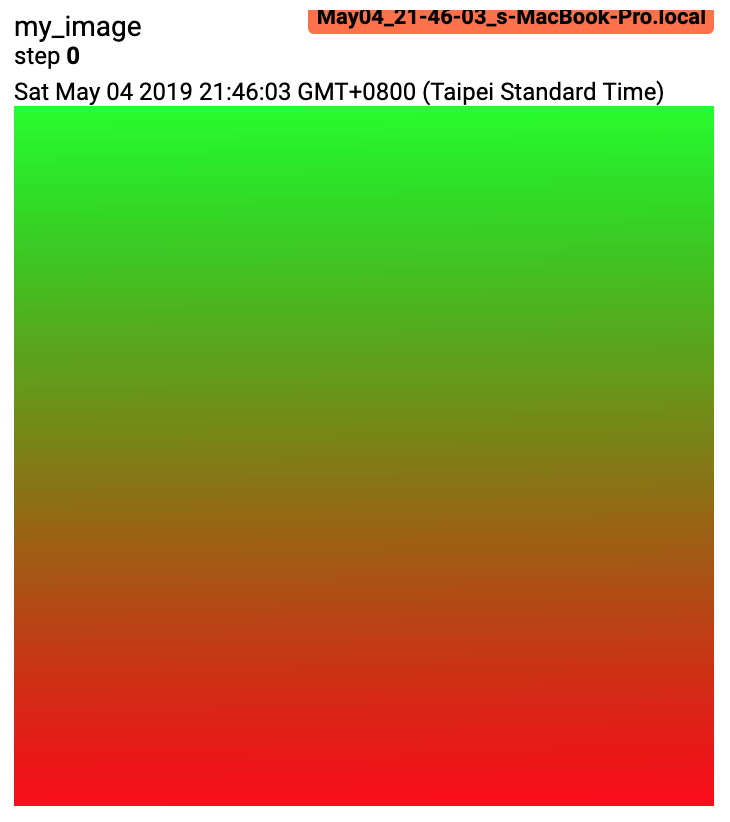
writer.add_image('my_image', img, 0)
# If you have non-default dimension setting, set the dataformats argument.
writer.add_image('my_image_HWC', img_HWC, 0, dataformats='HWC')
writer.close()预期结果:
python
add_images(tag, img_tensor, global_step=None, walltime=None, dataformats='NCHW')将批量图像数据添加到摘要中。
注意:此功能需要安装 pillow 包。
参数
tag (str)-- 数据标识符img_tensor (torch.Tensor,* numpy.ndarray, 或* *string/blobname)-- 图像数据global_step ( int )-- 要记录的全局步长值walltime (float)-- 可选参数,用于覆盖默认的时间戳(time.time())
事件发生后的秒数(从纪元开始计算)
dataformats (str)-- 图像数据格式规范,形式为
NCHW、NHWC、CHW、HWC、HW、WH 等。
形状:img_tensor: 默认为 (N,3,H,W)(N, 3, H, W)(N,3,H,W)。如果指定了 dataformats,则可以接受其他形状,例如 NCHW 或 NHWC。
示例:
python
from torch.utils.tensorboard import SummaryWriter
import numpy as np
img_batch = np.zeros((16, 3, 100, 100))for i in range(16):
img_batch[i, 0] = np.arange(0, 10000).reshape(100, 100) / 10000 / 16 * i
img_batch[i, 1] = (1 - np.arange(0, 10000).reshape(100, 100) / 10000) / 16 * i
writer = SummaryWriter()
writer.add_images('my_image_batch', img_batch, 0)
writer.close()预期结果:

python
add_figure(tag, figure, global_step=None, close=True, walltime=None)将 matplotlib 图形渲染为图像并添加到摘要中。
注意:此功能需要安装 matplotlib 包。
参数
tag (str)-- 数据标识符figure ( Union [Figure*,* list['Figure']])-- 单个图形或图形列表global_step (Optional[int])-- 记录的全局步长值close ([bool])-- 自动关闭图形的标志位walltime (Optional[float])-- 可选项,用于覆盖默认时间戳(事件发生时的纪元时间,单位为秒)
python
add_video(tag, vid_tensor, global_step=None, fps=4, walltime=None)向摘要中添加视频数据。
注意:这需要安装 moviepy 包。
参数
tag (str)-- 数据标识符vid_tensor (torch.Tensor)-- 视频数据global_step ( int )-- 要记录的全局步长值fps (float or int )-- 每秒帧数walltime (float)-- 可选项,覆盖默认的 walltime (time.time()),表示事件发生后的秒数(自纪元起)
形状:vid_tensor: (N,T,C,H,W)(N, T, C, H, W)(N,T,C,H,W)。数值范围应为 0, 255(uint8 类型)或 0, 1(float 类型)。
python
add_audio(tag, snd_tensor, global_step=None, sample_rate=44100, walltime=None)向摘要中添加音频数据。
参数
tag (str)-- 数据标识符snd_tensor (torch.Tensor)-- 音频数据global_step (int)-- 要记录的全局步长值sample_rate (int)-- 采样率(单位:Hz)walltime (float)-- 可选参数,用于覆盖默认的时间戳(time.time()),表示自纪元以来的秒数
数据形状:snd_tensor: (1,L)(1, L)(1,L)。数值范围应在-1, 1之间。
python
add_text(tag, text_string, global_step=None, walltime=None)向摘要中添加文本数据。
参数
tag (str)-- 数据标识符text_string (str)-- 要保存的字符串global_step ( int )-- 记录的全局步长值walltime (float)-- 可选参数,用于覆盖默认的时间戳(time.time()),表示事件发生后的秒数
示例:
python
writer.add_text('lstm', 'This is an lstm', 0)
writer.add_text('rnn', 'This is an rnn', 10)
python
add_graph(model, input_to_model=None, verbose=False, use_strict_trace=True)向摘要中添加图数据。
参数
model ( torch.nn.Module )-- 要绘制的模型。input_to_model (torch.Tensor 或 torch.Tensor 列表)-- 要输入的变量或变量元组。verbose ([bool])-- 是否在控制台打印图结构。use_strict_trace ([bool])-- 是否将关键字参数 strict 传递给 torch.jit.trace。当需要记录可变容器类型(如列表、字典)时,请传递 False。
python
add_embedding(mat, metadata=None, label_img=None, global_step=None, tag='default', metadata_header=None)向摘要中添加嵌入投影数据。
参数
mat (torch.Tensor 或 numpy.ndarray)- 一个矩阵,其中每行是数据点的特征向量metadata (list)- 标签列表,每个元素将被转换为字符串label_img (torch.Tensor)- 对应每个数据点的图像global_step (int)- 要记录的全局步长值tag (str)- 嵌入的名称metadata_header (list)- 多列元数据的标题列表。如果提供,每个元数据必须是一个包含与标题对应值的列表
形状:
mat: ( N , D ) (N,D) (N,D),其中N是数据数量,D是特征维度
label_img: ( N , C , H , W ) (N,C,H,W) (N,C,H,W)
示例:
python
import keyword
import torch
meta = []
while len(meta)<100:
meta = meta+keyword.kwlist # get some strings
meta = meta[:100]
for i, v in enumerate(meta):
meta[i] = v+str(i)
label_img = torch.rand(100, 3, 10, 32)for i in range(100):
label_img[i]=i/100.0
writer.add_embedding(torch.randn(100, 5), metadata=meta, label_img=label_img)
writer.add_embedding(torch.randn(100, 5), label_img=label_img)
writer.add_embedding(torch.randn(100, 5), metadata=meta)注意:如果分类(即非数值型)元数据要用于嵌入投影器的着色功能,其唯一值数量不得超过50个。
python
add_pr_curve(tag, labels, predictions, global_step=None, num_thresholds=127, weights=None, walltime=None)添加精确率-召回率曲线。
绘制精确率-召回率曲线可以帮助您理解模型在不同阈值设置下的性能表现。通过此功能,您需要为每个目标提供真实标签(真/假)和预测置信度(通常是模型的输出)。TensorBoard 界面将允许您交互式地选择阈值。
参数
tag (str)-- 数据标识符labels (torch.Tensor,* numpy.ndarray, 或* *string/blobname)-- 真实数据。每个元素的二元标签。predictions (torch.Tensor,* numpy.ndarray, 或* *string/blobname)-- 元素被分类为真的概率。
值应在 0, 1 范围内
global_step ( int )-- 记录的全局步长值num_thresholds ( int )-- 用于绘制曲线的阈值数量walltime (float)-- 可选参数,覆盖默认的事件时间戳(time.time()),表示自纪元以来的秒数
示例:
python
from torch.utils.tensorboard import SummaryWriter
import numpy as np
labels = np.random.randint(2, size=100) # binary label
predictions = np.random.rand(100)
writer = SummaryWriter()
writer.add_pr_curve('pr_curve', labels, predictions, 0)
writer.close()
python
add_custom_scalars(layout)通过在 'scalars' 中收集图表标签来创建特殊图表。
注意:每个 SummaryWriter() 对象只能调用一次此函数。
由于它仅向 tensorboard 提供元数据,因此该函数可以在训练循环之前或之后调用。
参数
layout ( dict )-- {类别名称: 图表 },其中 图表 也是一个字典
{图表名称: 属性列表 }。属性列表 中的第一个元素是图表的类型
(Multiline 或 Margin 之一),第二个元素应包含一个列表,其中包含
你在 add_scalar 函数中使用过的标签,这些标签将被收集到新图表中。
示例:
python
layout = {'Taiwan':{'twse':['Multiline',['twse/0050', 'twse/2330']]}, 'USA':{ 'dow':['Margin', ['dow/aaa', 'dow/bbb', 'dow/ccc']], 'nasdaq':['Margin', ['nasdaq/aaa', 'nasdaq/bbb', 'nasdaq/ccc']]}}
writer.add_custom_scalars(layout)
python
add_mesh(tag, vertices, colors=None, faces=None, config_dict=None, global_step=None, walltime=None)将网格或3D点云添加到TensorBoard。
该可视化基于Three.js实现,因此用户可以与渲染对象进行交互。除了顶点、面片等基本定义外,用户还可以进一步提供相机参数、光照条件等配置。
高级用法请参考 https://threejs.org/docs/index.html#manual/en/introduction/Creating-a-scene。
参数说明
tag (str)- 数据标识符vertices (torch.Tensor)- 顶点3D坐标列表colors (torch.Tensor)- 每个顶点的颜色值faces (torch.Tensor)- 每个三角形内顶点的索引(可选)config_dict- 包含ThreeJS类名及配置的字典global_step (int)- 记录的全局步长值walltime (float)- 可选的默认时间戳覆盖值(time.time()纪元后的秒数)
形状说明:
vertices: ( B , N , 3 ) (B,N,3) (B,N,3) (批次大小, 顶点数量, 通道数)
colors: ( B , N , 3 ) (B,N,3) (B,N,3) 数值范围:uint8类型为0,255,float类型为0,1
faces: ( B , N , 3 ) (B,N,3) (B,N,3) 数值范围:uint8类型为0, 顶点数量
使用示例:
python
from torch.utils.tensorboard import SummaryWriter
vertices_tensor = torch.as_tensor([
[1, 1, 1], [-1, -1, 1], [1, -1, -1], [-1, 1, -1], ], dtype=torch.float).unsqueeze(0)
colors_tensor = torch.as_tensor([
[255, 0, 0], [0, 255, 0], [0, 0, 255], [255, 0, 255], ], dtype=torch.int).unsqueeze(0)
faces_tensor = torch.as_tensor([
[0, 2, 3], [0, 3, 1], [0, 1, 2], [1, 3, 2], ], dtype=torch.int).unsqueeze(0)
writer = SummaryWriter()
writer.add_mesh('my_mesh', vertices=vertices_tensor, colors=colors_tensor, faces=faces_tensor)
writer.close()
python
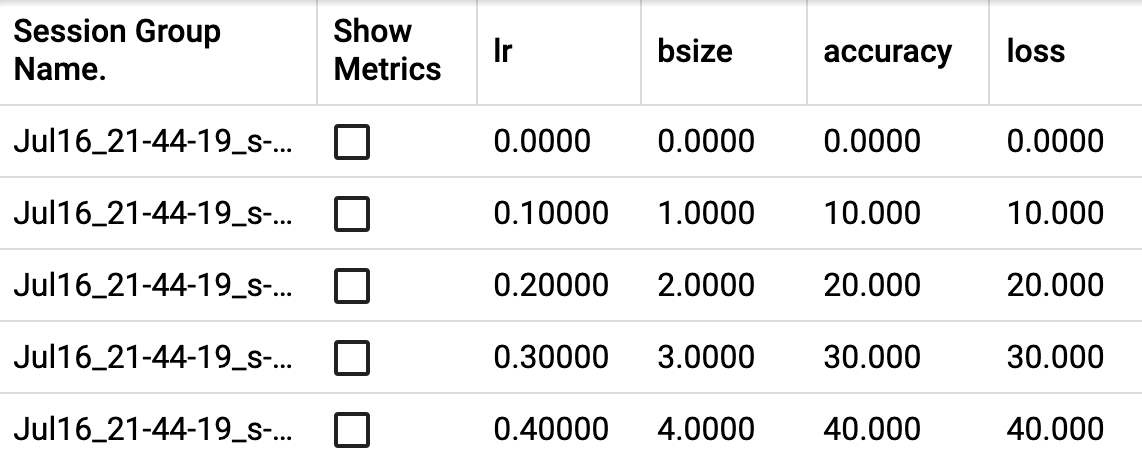
add_hparams(hparam_dict, metric_dict, hparam_domain_discrete=None, run_name=None, global_step=None)在TensorBoard中添加一组用于比较的超参数。
参数
hparam_dict ( dict )- 字典中的每个键值对表示超参数的名称及其对应值。值的类型可以是布尔值、字符串、浮点数、整数或None。metric_dict ( dict )- 字典中的每个键值对表示指标的名称及其对应值。注意,此处使用的键在TensorBoard记录中应是唯一的。否则,通过add_scalar添加的值会显示在hparam插件中,这通常不是期望的行为。hparam_domain_discrete- (OptionalDict\[str, List\[Any]]) 一个包含超参数名称及其所有可能离散值的字典run_name (str)- 运行的名称,将作为日志目录的一部分。如果未指定,将使用当前时间戳。global_step ( int )- 要记录的全局步长值
示例:
python
from torch.utils.tensorboard import SummaryWriter with SummaryWriter() as w:
for i in range(5):
w.add_hparams({'lr': 0.1*i, 'bsize': i}, {'hparam/accuracy': 10*i, 'hparam/loss': 10*i})预期结果:
flush()将事件文件刷新到磁盘。
调用此方法可确保所有待处理事件都已写入磁盘。
close()torch.utils.module_tracker
该工具用于追踪当前在torch.nn.Module层级结构中的位置。它可以与其他追踪工具配合使用,从而轻松地将测量值与用户友好的名称关联起来。目前该功能主要在FlopCounterMode中应用。
python
class torch.utils.module_tracker.ModuleTrackerModuleTracker 是一个上下文管理器,用于在执行过程中跟踪 nn.Module 的层级关系,以便其他系统能够查询当前正在执行哪个 Module(或其反向传播过程)。
您可以通过该上下文管理器的 parents 属性获取当前正在执行的所有 Module 的集合(通过它们的完全限定名 fqn 标识,该名称也用作 state_dict 中的键)。
您可以通过 is_bw 属性来判断当前是否处于反向传播阶段。
请注意,parents 永远不会为空,且始终包含 "Global" 键。is_bw 标志在前向传播结束后会保持为 True,直到另一个 Module 开始执行。如果您需要更精确的标志状态,请提交 issue 说明需求。目前尚未实现从 fqn 到模块实例的映射功能,如有需要也请提交 issue 提出请求。
示例:
python
mod = torch.nn.Linear(2, 2)
with ModuleTracker() as tracker:
# Access anything during the forward pass
def my_linear(m1, m2, bias):
print(f"Current modules: {tracker.parents}")
return torch.mm(m1, m2.t()) + bias
torch.nn.functional.linear = my_linear
mod(torch.rand(2, 2))类型信息
可以通过 torch.finfo 或 torch.iinfo 访问 torch.dtype 的数值属性。
torch.finfo
python
class torch.finfo torch.finfo 是一个表示浮点数类型数值属性的对象,适用于 torch.dtype(如 torch.float32、torch.float64、torch.float16 和 torch.bfloat16)。其功能类似于 numpy.finfo。
torch.finfo 提供以下属性:
| 名称 | 类型 | 描述 |
|---|---|---|
| bits | int | 该类型占用的比特数 |
| eps | float | 满足 1.0 + eps != 1.0 的最小可表示数 |
| max | float | 最大可表示数 |
| min | float | 最小可表示数(通常为 -max) |
| tiny | float | 最小正规格化数,等价于 smallest_normal |
| smallest_normal | float | 最小正规格化数(参见注释) |
| resolution | float | 该类型的近似十进制分辨率,即 10**-precision |
注意:torch.finfo 的构造函数可以不传参数调用,此时会为 PyTorch 默认 dtype(通过 torch.get_default_dtype() 获取)创建该类的实例。
注意:smallest_normal 返回的是最小规格化 数,但还存在更小的非规格化数。详见 https://en.wikipedia.org/wiki/Denormal_number。
torch.iinfo
python
class torch.iinfo torch.iinfo 是一个表示整数数值属性的对象,适用于 torch.dtype(如 torch.uint8、torch.int8、torch.int16、torch.int32 和 torch.int64)。其功能类似于 numpy.iinfo。
torch.iinfo 提供以下属性:
| 名称 | 类型 | 描述 |
|---|---|---|
| bits | int | 该类型占用的比特数 |
| max | int | 可表示的最大数值 |
| min | int | 可表示的最小数值 |
命名张量
命名张量允许用户为张量的维度指定显式名称。在大多数情况下,接受维度参数的操作将支持使用维度名称,从而无需通过位置来跟踪维度。此外,命名张量会利用名称在运行时自动检查API是否正确使用,提供额外的安全性保障。名称还可用于重新排列维度,例如支持"按名称广播"而非"按位置广播"。
警告:命名张量API目前是实验性功能,后续可能会发生变化。
创建命名张量
工厂函数现在新增了一个 names 参数,用于为每个维度关联名称。
python
>>> torch.zeros(2, 3, names=('N', 'C'))
tensor([[0., 0., 0.], [0., 0., 0.]], names=('N', 'C'))命名维度与常规张量维度一样是有序的。
tensor.names[i] 表示张量 tensor 第 i 维的名称。
以下工厂函数支持命名张量:
命名维度
关于张量命名的限制,请参阅 names。
使用 names 访问张量的维度名称,使用 rename() 重命名已命名的维度。
python
>>> imgs = torch.randn(1, 2, 2, 3 , names=('N', 'C', 'H', 'W'))
>>> imgs.names
('N', 'C', 'H', 'W')
>>> renamed_imgs = imgs.rename(H='height', W='width')
>>> renamed_imgs.names
('N', 'C', 'height', 'width)命名张量可以与未命名张量共存;命名张量是 torch.Tensor 的实例。未命名张量的维度名称为 None。命名张量并不要求所有维度都必须命名。
python
>>> imgs = torch.randn(1, 2, 2, 3 , names=(None, 'C', 'H', 'W'))
>>> imgs.names
(None, 'C', 'H', 'W')名称传播语义
命名张量使用名称在运行时自动检查API调用是否正确。这一过程称为名称推断。
更正式地说,名称推断包含以下两个步骤:
检查名称:运算符可以在运行时执行自动检查,验证特定维度名称必须匹配。传播名称:名称推断将名称传播到输出张量。
所有支持命名张量的操作都会传播名称。
python
>>> x = torch.randn(3, 3, names=('N', 'C'))
>>> x.abs().names
('N', 'C')匹配语义
当两个名称相等(字符串相等)或至少有一个为None时,它们被视为匹配 。None本质上是一种特殊的"通配符"名称。
unify(A, B)函数用于决定将名称A还是B传播到输出。如果两个名称匹配,则返回更具体的那个名称。如果名称不匹配,则会报错。
注意:在实际使用命名张量时,应避免存在未命名维度,因为它们的处理可能比较复杂。建议通过使用refine_names()将所有未命名维度提升为命名维度。
基本名称推断规则
让我们看看在不需要广播的情况下相加两个一维张量时,match和unify如何用于名称推断。
python
x = torch.randn(3, names=('X',))
y = torch.randn(3)
z = torch.randn(3, names=('Z',))检查名称 :确保两个张量的名称匹配。
以下示例说明:
python
>>> # x + y # match('X', None) is True
>>> # x + z # match('X', 'Z') is False
>>> # x + x # match('X', 'X') is True
>>> x + z
Error when attempting to broadcast dims ['X'] and dims ['Z']: dim 'X' and dim 'Z' are at the same position from the right but do not match.传播名称 :统一名称以选择要传播的名称。
对于 x + y 的情况,unify('X', None) = 'X' 因为 'X' 比 None 更具体。
python
>>> (x + y).names
('X',)
>>> (x + x).names
('X',)要查看完整的名称推断规则列表,请参阅命名张量操作符覆盖范围。
以下是两个值得了解的常见操作:
通过名称显式对齐
使用 align_as() 或 align_to() 方法,可以按照名称将张量维度对齐到指定的顺序。这种方法特别适用于实现"按名称广播"的操作。
python
# This function is agnostic to the dimension ordering of `input`, # as long as it has a `C` dimension somewhere.
def scale_channels(input, scale):
scale = scale.refine_names('C')
return input * scale.align_as(input)
>>> num_channels = 3
>>> scale = torch.randn(num_channels, names=('C',))
>>> imgs = torch.rand(3, 3, 3, num_channels, names=('N', 'H', 'W', 'C'))
>>> more_imgs = torch.rand(3, num_channels, 3, 3, names=('N', 'C', 'H', 'W'))
>>> videos = torch.randn(3, num_channels, 3, 3, 3, names=('N', 'C', 'H', 'W', 'D')
>>> scale_channels(imgs, scale)
>>> scale_channels(more_imgs, scale)
>>> scale_channels(videos, scale)维度操作
使用 align_to() 可以排列大量维度,而无需像 permute() 那样需要显式指定所有维度。
python
>>> tensor = torch.randn(2, 2, 2, 2, 2, 2)
>>> named_tensor = tensor.refine_names('A', 'B', 'C', 'D', 'E', 'F')
# Move the F (dim 5) and E dimension (dim 4) to the front while keeping
# the rest in the same order
>>> tensor.permute(5, 4, 0, 1, 2, 3)
>>> named_tensor.align_to('F', 'E',
...)使用 flatten() 和 unflatten() 可以分别实现维度的展平和还原。虽然这些方法比 view() 和 reshape() 更冗长,但对于阅读代码的人来说具有更明确的语义含义。
python
>>> imgs = torch.randn(32, 3, 128, 128)
>>> named_imgs = imgs.refine_names('N', 'C', 'H', 'W')
>>> flat_imgs = imgs.view(32, -1)
>>> named_flat_imgs = named_imgs.flatten(['C', 'H', 'W'], 'features')
>>> named_flat_imgs.names
('N', 'features')
>>> unflattened_named_imgs = named_flat_imgs.unflatten('features', [('C', 3), ('H', 128), ('W', 128)])
>>> unflattened_named_imgs.names
('N', 'C', 'H', 'W')自动梯度支持
当前自动梯度对命名张量的支持有限:它会忽略所有张量上的名称。梯度计算仍然正确,但我们会失去命名机制提供的安全保障。
python
>>> x = torch.randn(3, names=('D',))
>>> weight = torch.randn(3, names=('D',), requires_grad=True)
>>> loss = (x - weight).abs()
>>> grad_loss = torch.randn(3)
>>> loss.backward(grad_loss)
>>> weight.grad # Unnamed for now. Will be named in the future
tensor([-1.8107, -0.6357, 0.0783])
>>> weight.grad.zero_()
>>> grad_loss = grad_loss.refine_names('C')
>>> loss = (x - weight).abs()
# Ideally we'd check that the names of loss and grad_loss match but we don't yet.
>>> loss.backward(grad_loss)
>>> weight.grad
tensor([-1.8107, -0.6357, 0.0783])当前支持的操作和子系统
运算符
完整支持的 torch 和 tensor 操作列表请参阅 Named Tensors 运算符覆盖范围。目前暂不支持以下未包含在链接中的功能:
- 索引操作、高级索引
对于 torch.nn.functional 模块的运算符,我们支持以下函数:
torch.nn.functional.relu()torch.nn.functional.softmax()torch.nn.functional.log_softmax()torch.nn.functional.tanh()torch.nn.functional.sigmoid()torch.nn.functional.dropout()
子系统支持情况
当前支持自动求导功能,详见自动求导支持。由于梯度目前未命名,优化器可能可以工作但未经测试。
神经网络模块目前不受支持。这会导致以下情况:
- 神经网络模块参数未命名,因此输出可能仅部分被命名
- 神经网络模块的前向传播代码不支持命名张量,会正确报错
以下子系统也不支持(部分功能可能开箱即用):
- 概率分布
- 序列化(
torch.load()、torch.save()) - 多进程
- JIT编译
- 分布式
- ONNX导出
如果这些功能对您的使用场景有帮助,请先搜索是否已有相关issue,若没有则新建issue。
命名张量 API 参考
本节提供命名张量专用 API 的文档说明。如需了解名称如何通过其他 PyTorch 运算符传播的完整参考,请参阅命名张量运算符覆盖范围。
python
class torch.Tensor名称
存储该张量各维度的名称。
names[idx] 对应张量第 idx 维的名称。
如果维度有名称,则名称为字符串;如果维度未命名,则为 None。
维度名称可以包含字母或下划线。此外,维度名称必须是有效的 Python 变量名(即不能以下划线开头)。
张量不能有两个同名的已命名维度。
警告:命名张量 API 处于实验阶段,可能会发生变化。
python
rename(*names, **rename_map)重命名张量self的维度名称。
主要有两种使用方式:
1、self.rename(*rename_map):返回一个张量视图,其中维度名称按照rename_map映射关系进行重命名。
2、self.rename(names):返回一个张量视图,通过names参数按位置顺序重命名所有维度。
使用self.rename(None)可以移除张量的所有维度名称。
注意:不能同时指定位置参数names和关键字参数rename_map。
示例:
python
>>> imgs = torch.rand(2, 3, 5, 7, names=('N', 'C', 'H', 'W'))
>>> renamed_imgs = imgs.rename(N='batch', C='channels')
>>> renamed_imgs.names
('batch', 'channels', 'H', 'W')
>>> renamed_imgs = imgs.rename(None)
>>> renamed_imgs.names
(None, None, None, None)
>>> renamed_imgs = imgs.rename('batch', 'channel', 'height', 'width')
>>> renamed_imgs.names
('batch', 'channel', 'height', 'width')警告:命名张量 API 目前处于实验阶段,后续可能会发生变化。
python
rename_(*names, **rename_map)原地版本的 rename() 方法。
python
refine_names(*names)根据 names 优化 self 的维度名称。
维度优化是一种特殊的重命名操作,可以将未命名的维度"提升"为命名维度。
None 维度可以被优化为任意名称;已命名的维度只能优化为相同名称。
由于命名张量可以与未命名张量共存,维度优化提供了一种优雅的方式,使得支持命名张量的代码能同时处理命名和未命名张量。
names 参数最多可包含一个省略号(...)。
省略号会进行贪婪扩展:它会就地展开,用 self.names 对应索引的名称填充 names,使其长度与 self.dim() 相同。
Python 2 不支持省略号语法,但可以使用字符串字面量替代('...')。
参数
names (iterable* *of* str)-- 输出张量期望的维度名称。最多可包含一个省略号。
示例:
python
>>> imgs = torch.randn(32, 3, 128, 128)
>>> named_imgs = imgs.refine_names('N', 'C', 'H', 'W')
>>> named_imgs.names
('N', 'C', 'H', 'W')
>>> tensor = torch.randn(2, 3, 5, 7, 11)
>>> tensor = tensor.refine_names('A',
..., 'B', 'C')
>>> tensor.names
('A', None, None, 'B', 'C')警告:命名张量 API 目前处于实验阶段,后续可能会发生变化。
python
align_as(other) → Tensor 将 self 张量的维度重新排列以匹配 other 张量的维度顺序,并为任何新名称添加大小为1的维度。
此操作适用于通过名称进行显式广播(参见示例)。
使用此方法时,self 的所有维度都必须已命名。
结果张量是原始张量的视图。
self 的所有维度名称都必须存在于 other.names 中。
other 可以包含 self.names 中不存在的命名维度;输出张量会为每个新名称添加一个大小为1的维度。
若要将张量与特定顺序对齐,请使用 align_to()。
示例:
python
# Example 1: Applying a mask
>>> mask = torch.randint(2, [127, 128], dtype=torch.bool).refine_names('W', 'H')
>>> imgs = torch.randn(32, 128, 127, 3, names=('N', 'H', 'W', 'C'))
>>> imgs.masked_fill_(mask.align_as(imgs), 0)
# Example 2: Applying a per-channel-scale
>>> def scale_channels(input, scale):
>>> scale = scale.refine_names('C')
>>> return input * scale.align_as(input)
>>> num_channels = 3
>>> scale = torch.randn(num_channels, names=('C',))
>>> imgs = torch.rand(32, 128, 128, num_channels, names=('N', 'H', 'W', 'C'))
>>> more_imgs = torch.rand(32, num_channels, 128, 128, names=('N', 'C', 'H', 'W'))
>>> videos = torch.randn(3, num_channels, 128, 128, 128, names=('N', 'C', 'H', 'W', 'D'))
# scale_channels is agnostic to the dimension order of the input
>>> scale_channels(imgs, scale)
>>> scale_channels(more_imgs, scale)
>>> scale_channels(videos, scale)警告:命名张量 API 属于实验性功能,后续可能会发生变化。
python
align_to(*names)调整self张量的维度顺序以匹配names指定的顺序,并为任何新名称添加大小为1的维度。
使用此方法时,self的所有维度必须已命名。
结果张量是原始张量的视图。
self的所有维度名称必须出现在names中。
names可以包含self.names中不存在的新名称;输出张量会为每个新名称添加一个大小为1的维度。
names最多可包含一个省略号(...)。
省略号会被展开为self中所有未在names中提及的维度名称,顺序与它们在self中出现的顺序一致。
Python 2不支持省略号,但可以使用字符串字面量替代('...')。
参数
names (iterable* *of* str)-- 输出张量期望的维度顺序。最多可包含一个省略号,该省略号会被展开为self中所有未提及的维度名称。
示例:
python
>>> tensor = torch.randn(2, 2, 2, 2, 2, 2)
>>> named_tensor = tensor.refine_names('A', 'B', 'C', 'D', 'E', 'F')
# Move the F and E dims to the front while keeping the rest in order
>>> named_tensor.align_to('F', 'E',
...)警告:命名张量 API 目前处于实验阶段,后续可能会发生变化。
python
flatten(dims, out_dim) → Tensor 将 dims 展平为名为 out_dim 的单一维度。
所有 dims 必须在 self 张量中按顺序连续排列,但在内存中不必是连续的。
示例:
python
>>> imgs = torch.randn(32, 3, 128, 128, names=('N', 'C', 'H', 'W'))
>>> flat_imgs = imgs.flatten(['C', 'H', 'W'], 'features')
>>> flat_imgs.names, flat_imgs.shape
(('N', 'features'), torch.Size([32, 49152]))警告:命名张量 API 属于实验性功能,后续可能会发生变化。
命名张量操作覆盖范围
请先阅读命名张量了解命名张量的基本概念。
本文档是关于名称推断的参考指南,该过程定义了命名张量如何:
1、使用名称提供额外的运行时正确性检查
2、将名称从输入张量传播到输出张量
以下是所有支持命名张量的操作及其相关名称推断规则的列表。
如果您需要的操作未在此列出,请先搜索是否已有相关issue,如果没有则提交新issue。
警告:命名张量API目前是实验性的,可能会发生变化。
支持的操作
保留输入名称
所有逐点一元函数均遵循此规则,部分其他一元函数也同样适用。
- 检查名称:无
- 传播名称:输入张量的名称会传播到输出。
python
>>> x = torch.randn(3, 3, names=('N', 'C'))
>>> x.abs().names
('N', 'C')移除维度
所有归约操作(如 sum())都会通过缩减指定维度来移除该维度。其他操作如 select() 和 squeeze() 也会移除维度。
任何可以传入整数维度索引的操作符,同样可以传入维度名称。接受维度索引列表的函数也可以接受维度名称列表。
- 检查名称:如果
dim或dims以名称列表形式传入,需检查这些名称是否存在于self中。 - 传播名称:如果输入张量中由
dim或dims指定的维度未出现在输出张量中,那么这些维度对应的名称也不会出现在output.names中。
python
>>> x = torch.randn(1, 3, 3, 3, names=('N', 'C', 'H', 'W'))
>>> x.squeeze('N').names
('C', 'H', 'W')
>>> x = torch.randn(3, 3, 3, 3, names=('N', 'C', 'H', 'W'))
>>> x.sum(['N', 'C']).names
('H', 'W')
# Reduction ops with keepdim=True don't actually remove dimensions.
>>> x = torch.randn(3, 3, 3, 3, names=('N', 'C', 'H', 'W'))
>>> x.sum(['N', 'C'], keepdim=True).names
('N', 'C', 'H', 'W')统一输入张量的名称
所有二元算术运算都遵循此规则。进行广播操作时,仍会从右至左按位置广播,以保持与未命名张量的兼容性。如需按名称显式广播,请使用 Tensor.align_as()。
-
名称检查 :所有名称必须从右至左按位置匹配。例如在
tensor + other运算中,对于i在区间(-min(tensor.dim(), other.dim()) + 1, -1]内的所有值,必须满足match(tensor.names[i], other.names[i])为真。 -
名称检查 :此外,所有命名维度必须从右至左对齐。在匹配过程中,如果将命名维度
A与未命名维度None进行匹配,则A不得出现在包含未命名维度的张量中。 -
名称传播:从两个张量的右侧统一名称对,以生成输出名称。
例如,
python
# tensor: Tensor[ N, None]
# other: Tensor[None, C]
>>> tensor = torch.randn(3, 3, names=('N', None))
>>> other = torch.randn(3, 3, names=(None, 'C'))
>>> (tensor + other).names
('N', 'C')检查名称:
match(tensor.names[-1], other.names[-1])结果为Truematch(tensor.names[-2], tensor.names[-2])结果为True- 由于我们在
tensor中将None与'C'进行了匹配,需确认'C'不存在于tensor中(确实不存在)。 - 需确认
'N'不存在于other中(确实不存在)。
最终,输出名称通过 [unify('N', None), unify(None, 'C')] = ['N', 'C'] 计算得出。
更多示例:
python
# Dimensions don't match from the right:
# tensor: Tensor[N, C]
# other: Tensor[ N]
>>> tensor = torch.randn(3, 3, names=('N', 'C'))
>>> other = torch.randn(3, names=('N',))
>>> (tensor + other).names
RuntimeError: Error when attempting to broadcast dims ['N', 'C'] and dims
['N']: dim 'C' and dim 'N' are at the same position from the right but do
not match.
# Dimensions aren't aligned when matching tensor.names[-1] and other.names[-1]:
# tensor: Tensor[N, None]
# other: Tensor[ N]
>>> tensor = torch.randn(3, 3, names=('N', None))
>>> other = torch.randn(3, names=('N',))
>>> (tensor + other).names
RuntimeError: Misaligned dims when attempting to broadcast dims ['N'] and dims ['N', None]: dim 'N' appears in a different position from the right
across both lists.注意:在上述最后两个示例中,可以通过名称对齐张量后再执行加法运算。使用 Tensor.align_as() 按名称对齐张量,或使用 Tensor.align_to() 将张量对齐至自定义维度顺序。
维度置换
某些操作(如 Tensor.t())会对维度顺序进行置换。维度名称与各个维度绑定,因此会随维度一同被置换。
当操作接受位置索引参数 dim 时,也可以接收维度名称作为 dim 参数:
- 名称检查 :若
dim以名称形式传入,需检查该名称是否存在于张量中 - 名称传播:维度名称的置换方式与其绑定的维度置换方式保持一致
python
>>> x = torch.randn(3, 3, names=('N', 'C'))
>>> x.transpose('N', 'C').names
('C', 'N')消除维度的合约
矩阵乘法函数遵循以下某种变体。我们先来看 torch.mm(),然后推广到批量矩阵乘法的规则。
对于 torch.mm(tensor, other):
- 名称检查:无
- 名称传播:结果名称为
(tensor.names[-2], other.names[-1])
python
>>> x = torch.randn(3, 3, names=('N', 'D'))
>>> y = torch.randn(3, 3, names=('in', 'out'))
>>> x.mm(y).names
('N', 'out')本质上,矩阵乘法会在两个维度上执行点积运算并将它们折叠。当两个张量进行矩阵乘法时,收缩的维度会消失且不会出现在输出张量中。
torch.mv() 和 torch.dot() 的工作方式类似:名称推断不会检查输入名称,并移除参与点积运算的维度:
python
>>> x = torch.randn(3, 3, names=('N', 'D'))
>>> y = torch.randn(3, names=('something',))
>>> x.mv(y).names
('N',)现在,让我们来看看 torch.matmul(tensor, other)。假设 tensor.dim() >= 2 且 other.dim() >= 2。
- 检查名称:确保输入的批次维度是对齐且可广播的。
关于输入对齐的含义,请参阅从输入统一名称。
- 传播名称:结果名称通过统一批次维度并移除收缩维度得到:
unify(tensor.names[:-2], other.names[:-2]) + (tensor.names[-2], other.names[-1])。
示例:
python
# Batch matrix multiply of matrices Tensor['C', 'D'] and Tensor['E', 'F'].
# 'A', 'B' are batch dimensions.
>>> x = torch.randn(3, 3, 3, 3, names=('A', 'B', 'C', 'D'))
>>> y = torch.randn(3, 3, 3, names=('B', 'E', 'F'))
>>> torch.matmul(x, y).names
('A', 'B', 'C', 'F')最后,许多矩阵乘法函数都有融合了add操作的版本,例如addmm()和addmv()。这些函数被视为组合了mm()的名称推断和add()的名称推断。
工厂函数
工厂函数现在新增了一个 names 参数,用于为每个维度关联名称。
python
>>> torch.zeros(2, 3, names=('N', 'C'))
tensor([[0., 0., 0.], [0., 0., 0.]], names=('N', 'C'))输出函数与原地操作变体
作为out=参数指定的张量具有以下行为:
- 如果该张量没有命名的维度,则操作计算得出的名称会传播给它。
- 如果该张量包含任何命名的维度,则操作计算得出的名称必须与现有名称完全一致,否则会报错。
所有原地操作方法都会将输入张量的名称修改为名称推断计算得出的名称。例如:
python
>>> x = torch.randn(3, 3)
>>> y = torch.randn(3, 3, names=('N', 'C'))
>>> x.names
(None, None)
>>> x += y
>>> x.names
('N', 'C')torch.config
python
torch.__config__.show()返回一个包含 PyTorch 配置描述的可读字符串。
返回类型:str
python
torch.__config__.parallel_info()返回包含并行化设置的详细字符串
返回类型:str
torch.future
python
torch.__future__.set_overwrite_module_params_on_conversion(value)设置是否在转换nn.Module时为参数分配新张量,而不是就地修改现有参数。
启用此功能后,以下方法将为模块分配新参数:
1、module.{device}()(例如nn.Module.cuda())用于在设备间移动模块
2、module.{dtype}()(例如nn.Module.float())用于将模块转换为不同的数据类型
3、nn.Module.to()
4、nn.Module.to_empty()
参数说明
value ([bool])- 是否分配新张量。
python
torch.__future__.get_overwrite_module_params_on_conversion()返回在转换torch.nn.Module时是否要为参数分配新张量,而不是就地修改现有参数。默认为False。
更多信息请参阅set_overwrite_module_params_on_conversion()。
返回类型:bool
python
torch.__future__.set_swap_module_params_on_conversion(value)设置是否使用 swap_tensors() 来原地修改现有参数,替代以下两种场景:
1、转换 nn.Module 时直接设置 .data 的方式
2、将状态字典加载到 nn.Module 时使用 param.copy_(state_dict[key]) 的方式
注意:此功能优先级高于 get_overwrite_module_params_on_conversion()
启用后,以下方法将原地交换现有参数:
1、module.{device}() 方法(如 nn.Module.cuda())用于跨设备移动模块
2、module.{dtype}() 方法(如 nn.Module.float())用于转换模块数据类型
3、nn.Module.to()
4、nn.Module.to_empty()
5、nn.Module.load_state_dict()
当启用时,load_state_dict() 的语义如下:
1、对每个参数/缓冲区,其对应的 state_dict['key'] 会通过 module_load() 进行转换(即 res = param.module_load(state_dict['key']))
2、如有必要,res 会被包装成 Parameter
3、模块中的参数/缓冲区将通过 swap_tensors() 与 res 进行交换
参数
value ([bool])-- 是否使用swap_tensors()
python
torch.__future__.get_swap_module_params_on_conversion()返回在转换 nn.Module 时是否使用 swap_tensors() 而非通过设置 .data 来原地修改现有参数。默认为 False。
更多信息请参阅 set_swap_module_params_on_conversion()。
返回类型:bool
torch._logging
PyTorch 拥有一个可配置的日志系统,可以为不同组件设置不同的日志级别。例如,可以完全禁用某个组件的日志消息,而将另一个组件的日志消息设置为最高详细程度。
警告:此功能目前处于测试阶段,未来可能会存在破坏性变更。
警告:此功能尚未扩展至控制 PyTorch 中所有组件的日志消息。
有两种方式可以配置日志系统:通过环境变量 TORCH_LOGS 或 Python API torch._logging.set_logs。
set_logs |
为各组件设置日志级别并切换特定日志输出类型。 |
|---|
环境变量 TORCH_LOGS 是以逗号分隔的 [+-]<component> 键值对列表,其中 <component> 是下文指定的组件。前缀 + 会降低组件的日志级别(显示更多日志消息),而前缀 - 会提高组件的日志级别(显示更少日志消息)。默认设置是当组件未在 TORCH_LOGS 中指定时的行为。除了组件外,还存在日志输出项(artifacts)。输出项是与组件关联的特定调试信息片段,它们要么显示要么不显示,因此对输出项添加 + 或 - 前缀不会产生效果。由于输出项与组件关联,启用组件通常也会启用其关联的输出项,除非该输出项被指定为默认关闭(off_by_default)。此选项在 _registrations.py 中为那些过于冗长、应仅在显式启用时显示的输出项指定。
以下组件和输出项可通过 TORCH_LOGS 环境变量配置(Python API 参见 torch._logging.set_logs):
组件:
all:特殊组件,配置所有组件的默认日志级别。默认值:logging.WARNdynamo:TorchDynamo 组件的日志级别。默认值:logging.WARNaot:AOTAutograd 组件的日志级别。默认值:logging.WARNinductor:TorchInductor 组件的日志级别。默认值:logging.WARNyour.custom.module:任意未注册模块的日志级别。提供完整限定名即可启用该模块。默认值:logging.WARN
输出项:
bytecode:是否输出 TorchDynamo 的原始及生成字节码。默认值:Falseaot_graphs:是否输出 AOTAutograd 生成的图。默认值:Falseaot_joint_graph:是否输出 AOTAutograd 生成的前向-反向联合图。默认值:Falsecompiled_autograd:是否输出 compiled_autograd 的日志。默认值:Falseddp_graphs:是否输出 DDPOptimizer 生成的图。默认值:Falsegraph:是否以表格形式输出 TorchDynamo 捕获的图。默认值:Falsegraph_code:是否输出 TorchDynamo 捕获图的 Python 源码。默认值:Falsegraph_breaks:是否在 TorchDynamo 追踪期间遇到唯一图中断时输出消息。默认值:Falseguards:是否为每个编译函数输出 TorchDynamo 生成的守卫(guards)。默认值:Falserecompiles:是否在 TorchDynamo 重新编译函数时输出守卫失败原因及消息。默认值:Falseoutput_code:是否输出 TorchInductor 生成的代码。默认值:Falseschedule:是否输出 TorchInductor 调度计划。默认值:False
示例:
TORCH_LOGS="+dynamo,aot":将 TorchDynamo 日志级别设为logging.DEBUG,AOT 设为logging.INFOTORCH_LOGS="-dynamo,+inductor":将 TorchDynamo 日志级别设为logging.ERROR,TorchInductor 设为logging.DEBUGTORCH_LOGS="aot_graphs":启用aot_graphs输出项TORCH_LOGS="+dynamo,schedule":将 TorchDynamo 日志级别设为logging.DEBUG并启用schedule输出项TORCH_LOGS="+some.random.module,schedule":将 some.random.module 日志级别设为logging.DEBUG并启用schedule输出项
Torch 环境变量
PyTorch 利用环境变量来调整影响其运行时行为的各种设置。这些变量可用于控制关键功能,例如在遇到错误时显示 C++ 堆栈跟踪、同步 CUDA 内核的执行、指定并行处理任务的线程数等。
此外,PyTorch 还依赖多个高性能库(如 MKL 和 cuDNN),这些库同样通过环境变量来修改其功能。这种设置的相互作用使得开发环境具有高度可定制性,可以针对效率、调试和计算资源管理进行优化。
请注意,虽然本文档涵盖了与 PyTorch 及其相关库相关的大部分环境变量,但并非详尽无遗。如果您发现文档中存在遗漏、错误或有改进空间的内容,请通过提交 issue 或创建 pull request 告知我们。
2025-05-10(六)