【本文为我在去年完成的综述,因某些原因未能及时投稿,但本文仍能为想要全面了解文本到图像的生成和编辑的学习者提供可靠的参考。目前本文已投稿 ACM Computing Surveys。

完整内容可在如下链接获取,或在 Q 群群文件获取。 中文版为论文初稿,英文版有适量改动。
链接: https://pan.baidu.com/s/19FSRXH4TxlqgE3rgjuXDDg?pwd=y3gj 提取码: y3gj
论文地址:https://arxiv.org/abs/2505.02527
进 Q 学术交流群:922230617 或加 CV_EDPJ 进 W 交流群
】
Text to Image Generation and Editing: A Survey

目录
[0. 摘要](#0. 摘要)
[1. 简介](#1. 简介)
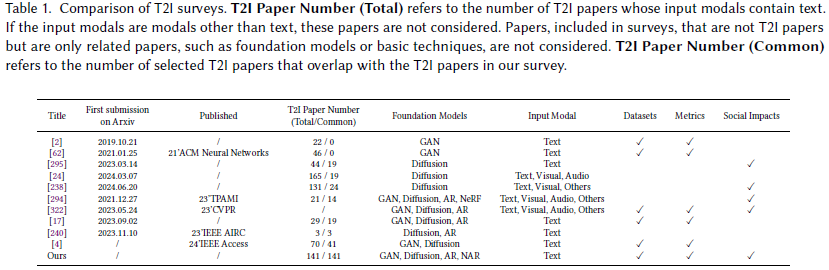
[1.1 综述对比(表)](#1.1 综述对比(表))
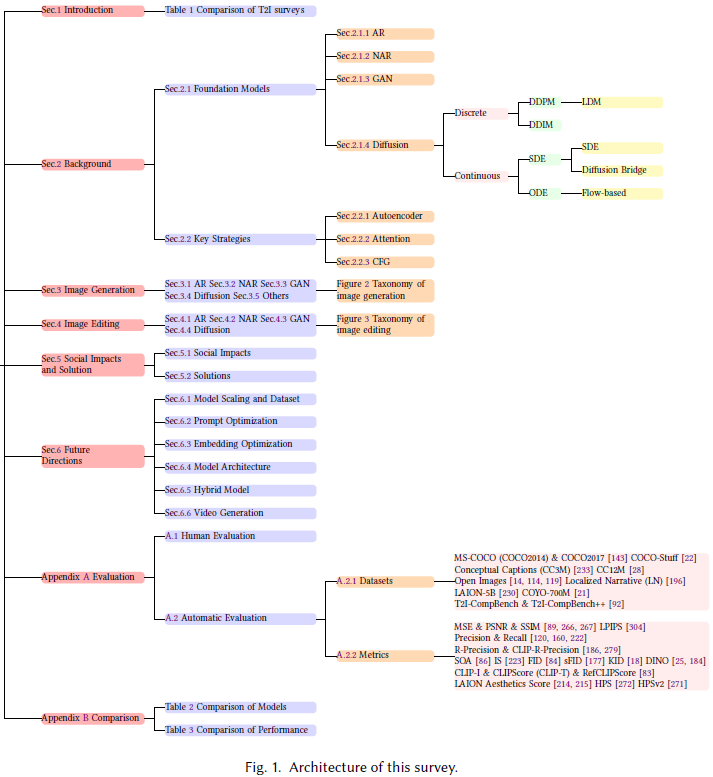
[1.2 本文框架 (图)](#1.2 本文框架 (图))
[1.3 文本到图像生成 (图)](#1.3 文本到图像生成 (图))
[1.4 文本到图像编辑 (图)](#1.4 文本到图像编辑 (图))
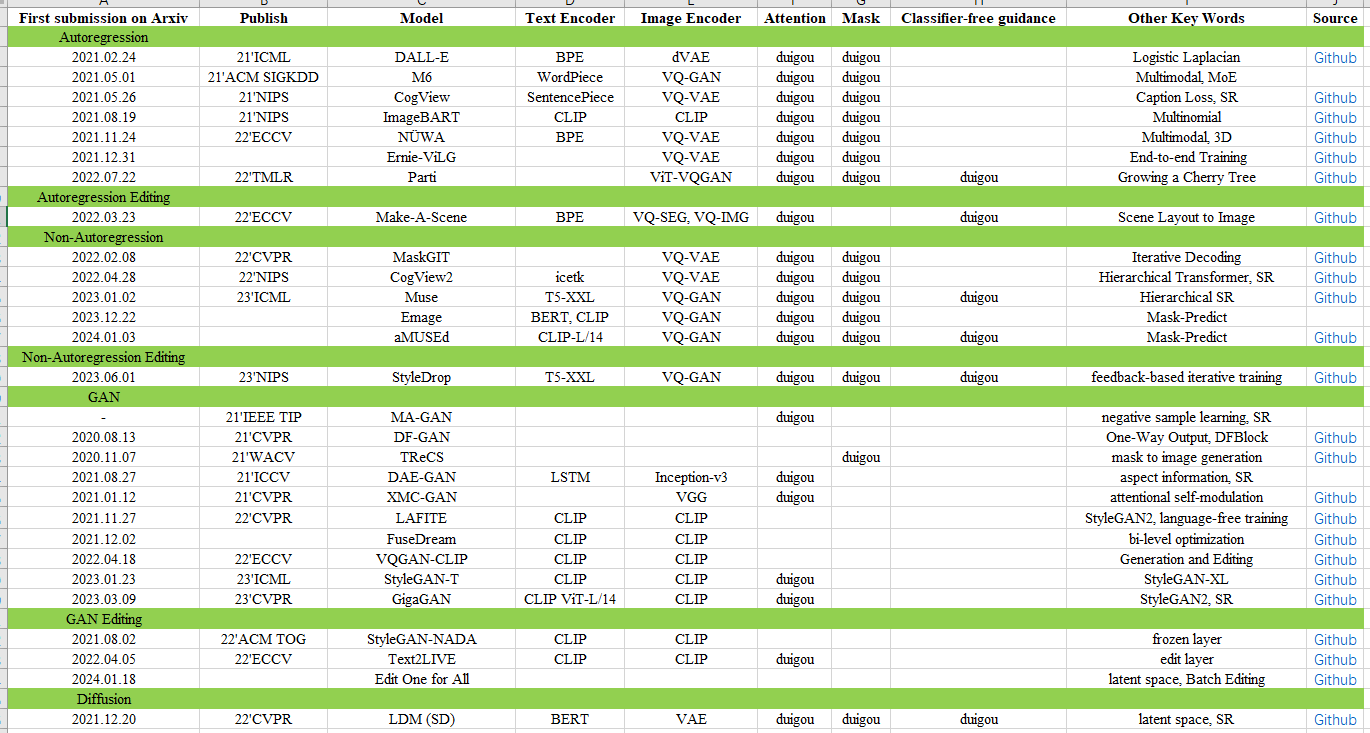
[1.5 模型对比 (表)](#1.5 模型对比 (表))
[1.6 性能对比(表)](#1.6 性能对比(表))
0. 摘要
文本到图像生成(T2I)指的是模型在文本提示的引导下,生成符合文本描述的高质量图像。在过去的几年,T2I 引起了人们的广泛关注,涌现了无数的作品。在本综述中,我们综合性的回顾了从 2021 到 2024 进行的 141 项研究。
- 首先,我们介绍了 T2I 的四个基础模型架构(Autoregression,Non-autoregression,GAN 和Diffusion)以及常用的关键技术(Autoencoder,Attention 和无分类器引导 )。
- 其次,我们就 T2I 生成和 T2I 编辑两个方向系统地对比了这些研究的方法,包括它们使用的编码器以及关键技术。
- 此外,我们还并排对比了这些研究的性能,从数据集,评估指标、训练资源以及推断速度等方面。
- 除了四个基础模型,我们还调查了T2I的其他研究,例如基于能量的模型以及近期的 Mamba 和多模态。我们还调查了 T2I 可能的社会影响并给出了相应的解决措施。
- 最后,我们提出了提高T2I模型能力以及未来可能发展方向的独特见解。
总之,我们的综述是第一篇系统且全面的T2I的综合性概述,旨在为未来的研究人员提供了一个有价值的指南,并激励这一领域的持续进步。
1. 简介
随着生成式模型的发展,文本到图像生成(T2I)也得到了极大的发展,涌现了无数的工作。我们的综述为研究人员提供了一个整体的视角,包括对社区已有的重要工作的对比以及一些新兴的研究方向,以此来帮助研究人员了解T2I领域的发展。
本综述所调查的 T2I 论文的选取标准为:
- 我们调查 2021~2024 年的论文;
- 我们调查社区中高度关注的T2I论文及其后续工作,例如:LDM,Imagen,DALL-E,Cogview以及 Pixart 等;
- 我们调查来自会议的顶级论文中的T2I论文;
- 我们调查根据前面的标准选取的文章中引用的(进行了对比或在相关工作中提到)T2I论文;
- 在起草本综述时,我们关注 arXiv 中最新的令人感兴趣的 T2 I论文,其中部分文章在完成本文时已被会议收录。详见表 2。
之前的 T2I 综述,通常只涉及单个基础模型的调查;如 GAN 或者 Diffusion。虽然也有一些综述也调查了多个基础模型,但与我们的综述相比,不够全面:
- 它们调查的文献数量太少,
- 它们未调查近期的一些研究,例如Mamba,
- 它们的对比不够充分,我们的调查使用的并排对比(见表2和表3)使不同模型的差异一目了然,
- 相比于这些综述,我们的综述对社会影响及解决办法做出了详尽的调查,
- 立足于已有文献,我们的综述指出了更多的未来研究方向。详细对比见表 1。
1.1 综述对比 (表)
1.2 本文框架 (图)
1.3 文本到图像生成 (图)

1.4 文本到图像编辑 (图)

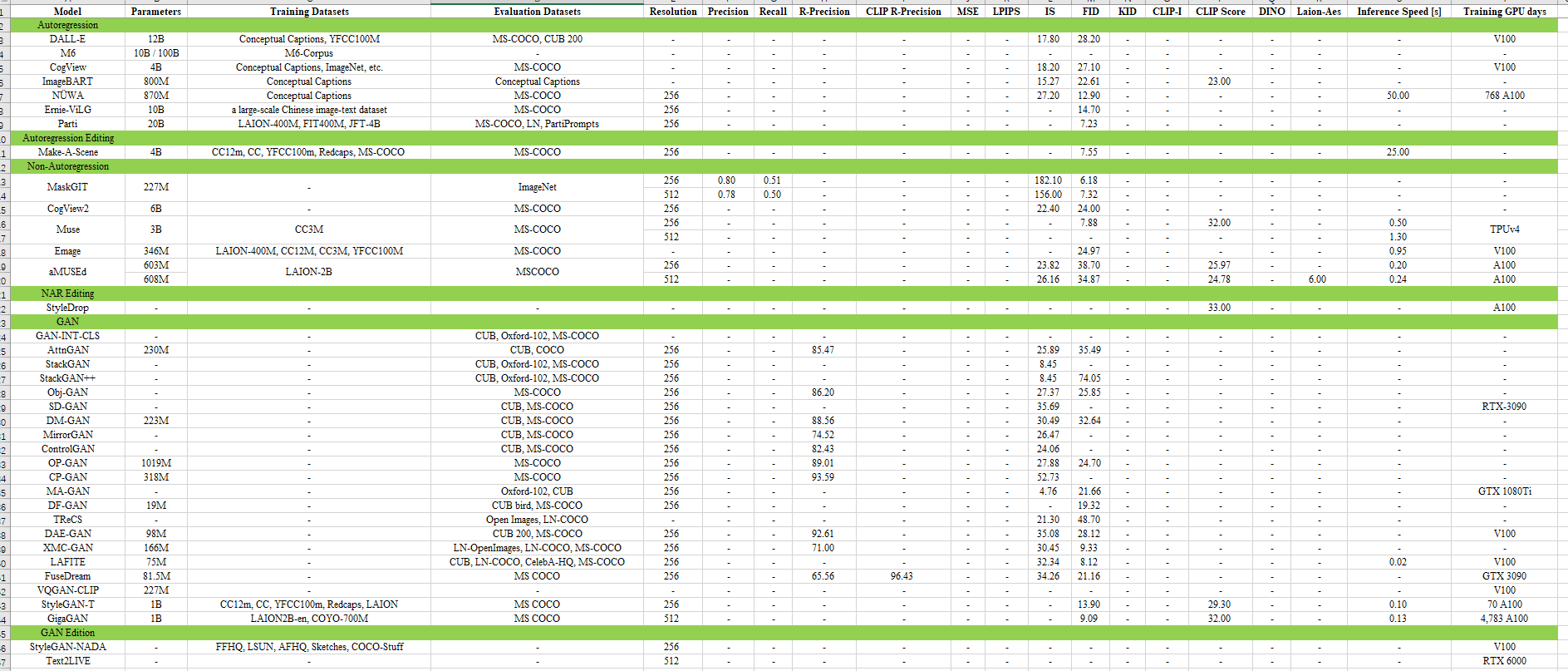
1.5 模型对比 (表)
1.6 性能对比(表)