代码随想录算法训练营第九天 |【字符串】151.翻转字符串里的单词、卡码网55.右旋转字符串、28.实现strStr、459.重复的子字符串
151.翻转字符串里的单词
思路
- 我的想法是模拟,用状态机拾取单词,然后存到双重数组中,再反向读取输出
- 状态机有两个状态,IN 和 OUT 如果状态机检测到分隔符,则一定转换为状态OUT,如果未检测到分隔符,则转换为状态IN,单词计数加一切开始
看完代码随想录之后的想法
想多了,三步走法
-
移除多余空格,快慢指针,有两个版本
-
版本一分别讨论了前面、中间、尾部的空格去除,比较繁琐
//版本一
void removeExtraSpaces(string& s) {
int slowIndex = 0, fastIndex = 0; // 定义快指针,慢指针
// 去掉字符串前面的空格
while (s.size() > 0 && fastIndex < s.size() && s[fastIndex] == ' ') {
fastIndex++;
}
for (; fastIndex < s.size(); fastIndex++) {
// 去掉字符串中间部分的冗余空格
if (fastIndex - 1 > 0
&& s[fastIndex - 1] == s[fastIndex]
&& s[fastIndex] == ' ') {
continue;
} else {
s[slowIndex++] = s[fastIndex];
}
}
if (slowIndex - 1 > 0 && s[slowIndex - 1] == ' ') { // 去掉字符串末尾的空格
s.resize(slowIndex - 1);
} else {
s.resize(slowIndex); // 重新设置字符串大小
}
} -
版本二是用27.移除元素的逻辑,遇到非空格就处理,手动添加空格,最后补上该单词
// 版本二
void removeExtraSpaces(string& s) {//去除所有空格并在相邻单词之间添加空格, 快慢指针。
int slow = 0; //整体思想参考https://programmercarl.com/0027.移除元素.html
for (int i = 0; i < s.size(); ++i) { //
if (s[i] != ' ') { //遇到非空格就处理,即删除所有空格。
if (slow != 0) s[slow++] = ' '; //手动控制空格,给单词之间添加空格。slow != 0说明不是第一个单词,需要在单词前添加空格。
while (i < s.size() && s[i] != ' ') { //补上该单词,遇到空格说明单词结束。
s[slow++] = s[i++];
}
}
}
s.resize(slow); //slow的大小即为去除多余空格后的大小。
}
-
-
将整个字符串反转,见344.反转字符串 ,541.反转字符串II
swap()// 反转字符串s中左闭右闭的区间[start, end] void reverse(string& s, int start, int end) { for (int i = start, j = end; i < j; i++, j--) { swap(s[i], s[j]); } } -
将每个单词反转
string reverseWords(string s) {
removeExtraSpaces(s); //去除多余空格,保证单词之间之只有一个空格,且字符串首尾没空格。
reverse(s, 0, s.size() - 1);
int start = 0; //removeExtraSpaces后保证第一个单词的开始下标一定是0。
for (int i = 0; i <= s.size(); ++i) {
if (i == s.size() || s[i] == ' ') { //到达空格或者串尾,说明一个单词结束。进行翻转。
reverse(s, start, i - 1); //翻转,注意是左闭右闭 []的翻转。
start = i + 1; //更新下一个单词的开始下标start
}
}
return s;
}
卡码网55.右旋转字符串
思路
- 用双指针法,暴力每次向右移动一个字符,然后贴到字头
看完代码随想录之后的想法
双重倒叙法
-
通过 整体倒叙,把两段子串顺序颠倒,两个段子串里的的字符在倒叙一把,负负得正,这样就不影响子串里面字符的顺序了。
include
include
using namespace std;
int main() {
int t;
string s;
cin >> t;
cin >> s;
reverse(s.begin(), s.end());
reverse(s.begin(), s.begin() + t);
reverse(s.end() - t, s.end());
return 0;
} -
当然还有第二种做法,就是先反转局部,再反转整体
#include<iostream> #include<algorithm> using namespace std; int main() { int n; string s; cin >> n; cin >> s; int len = s.size(); //获取长度 reverse(s.begin(), s.begin() + n); // 反转第一段长度为n reverse(s.begin() + n, s.end()); // 反转第二段长度为len-n reverse(s.begin(), s.end()); // 整体反转 cout << s << endl; }
28.实现strStr
思路
- 一个一个遍历,用文本串和模式串暴力匹配,没其他思路了
看完代码随想录之后的想法
KMP经典思想
-
KMP的经典思想就是:当出现字符串不匹配时,可以记录一部分之前已经匹配的文本内容,利用这些信息避免从头再去做匹配。
-
什么是KMP------因为是由这三位学者发明的:Knuth,Morris和Pratt
-
KMP有什么用------当出现字符串不匹配时,可以记录一部分之前已经匹配的文本内容,利用这些信息避免从头再去做匹配
-
什么是前缀表------next数组
- 前缀表是用来回退的,它记录了模式串与主串(文本串)不匹配的时候,模式串应该从哪里开始重新匹配。
- 举例:要在文本串:aabaabaafa 中查找是否出现过一个模式串:aabaaf
- 前缀表:记录下标i之前(包括i)的字符串中,有多大长度的相同前缀后缀。
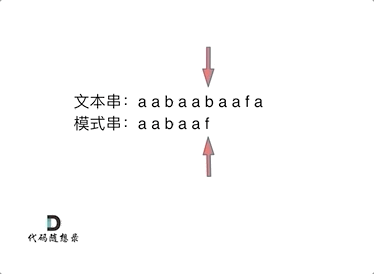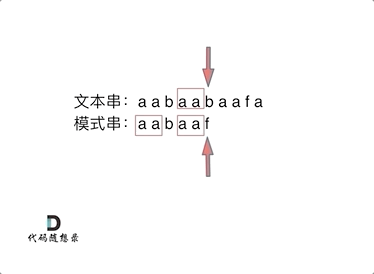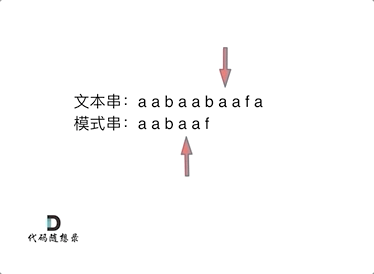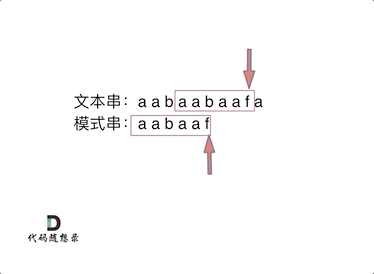
-
最长公共前后缀
- 前缀是指不包含最后一个字符的所有以第一个字符开头的连续子串。
- 后缀是指不包含第一个字符的所有以最后一个字符结尾的连续子串。
-
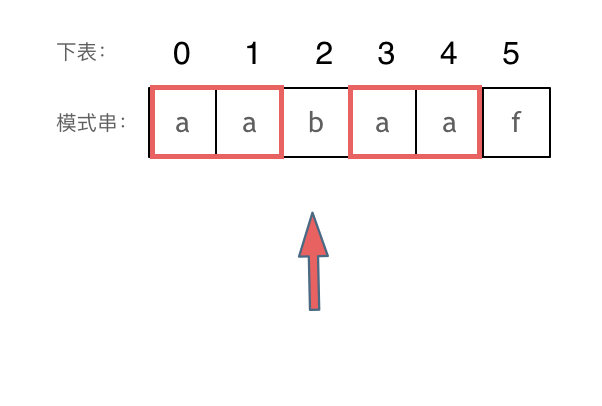
为什么一定要用前缀表
- 下标5之前这部分的字符串(也就是字符串aabaa)的最长相等的前缀 和 后缀字符串是 子字符串aa ,因为找到了最长相等的前缀和后缀,匹配失败的位置是后缀子串的后面,那么我们找到与其相同的前缀的后面重新匹配就可以了。
-
如何计算前缀表
- 下标i之前(包括i)的字符串中,有多大长度的相同前缀后缀。
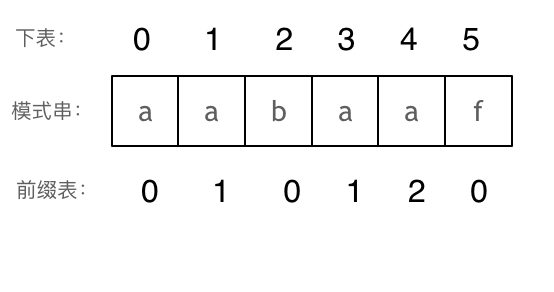
- 找到的不匹配的位置, 那么此时我们要看它的前一个字符的前缀表的数值是多少
- 前一个字符的前缀表的数值是2, 所以把下标移动到下标2的位置继续比配
-
前缀表与next数组
- next数组是新前缀表(旧前缀表统一减一了)
-
构造next数组------构造next数组其实就是计算模式串s,前缀表的过程
-
初始化:定义两个指针i和j,j指向前缀末尾位置,i指向后缀末尾位置,nexti 表示 i(包括i)之前最长相等的前后缀长度(其实就是j)
int j = -1; next[0] = j; -
处理前后缀不相同的情况:
-
因为j初始化为-1,那么i就从1开始,进行si 与 sj+1的比较。
-
如果 si 与 sj+1不相同,也就是遇到 前后缀末尾不相同的情况,就要向前回退。
-
nextj就是记录着j(包括j)之前的子串的相同前后缀的长度。
for (int i = 1; i < s.size(); i++) { // 这里不能写成if,因为这是一个连续递归回退的过程,如果不相等要继续回退 while (j >= 0 && s[i] != s[j + 1]) { // 前后缀不相同了 j = next[j]; // 向前回退 } -
-
处理前后缀相同的情况
-
如果 si 与 sj + 1 相同,那么就同时向后移动i 和j 说明找到了相同的前后缀,同时还要将j(前缀的长度)赋给nexti, 因为nexti要记录相同前后缀的长度。
if (s[i] == s[j + 1]) { // 找到相同的前后缀 j++; } next[i] = j; -
-
整体代码如下:
void getNext(int* next, const string& s){ int j = -1; next[0] = j; for(int i = 1; i < s.size(); i++) { // 注意i从1开始 while (j >= 0 && s[i] != s[j + 1]) { // 前后缀不相同了 j = next[j]; // 向前回退 } if (s[i] == s[j + 1]) { // 找到相同的前后缀 j++; } next[i] = j; // 将j(前缀的长度)赋给next[i] } } -
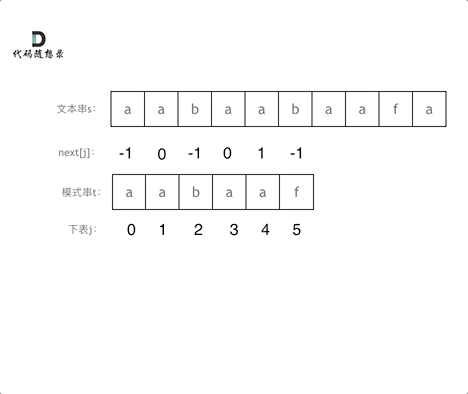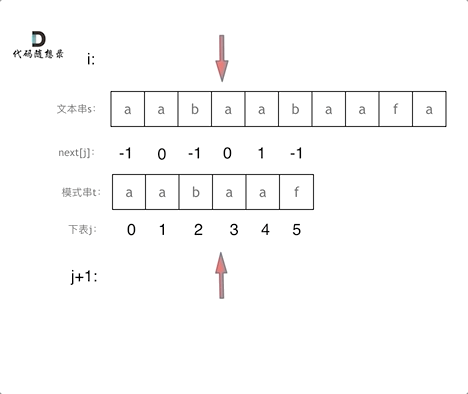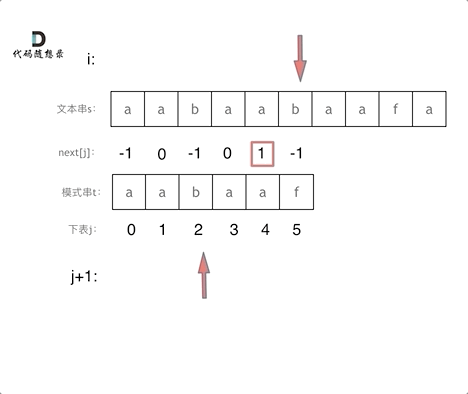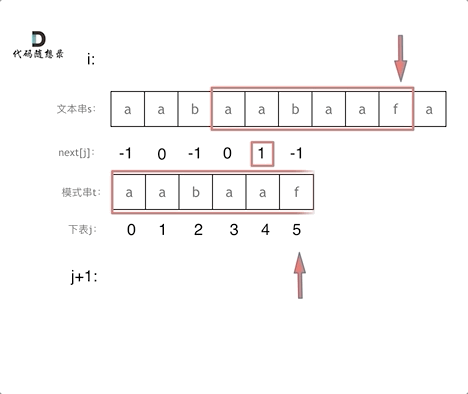
逻辑动画如下:
-
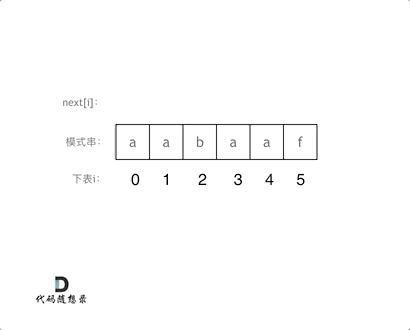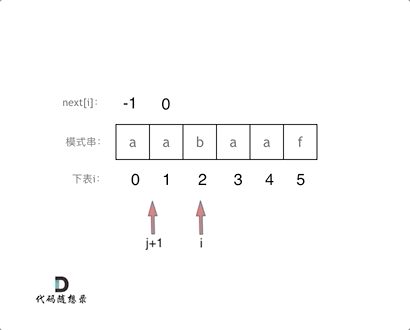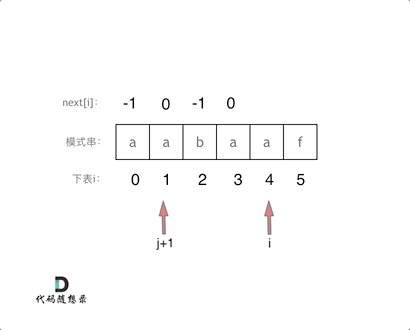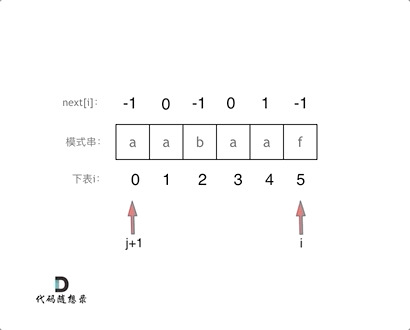
-
-
使用next数组来匹配------在文本串s里找是否出现过模式串t
-
定义两个下标j 指向模式串起始位置,i指向文本串起始位置,j初始值依然为-1,因为next数组里记录的起始位置为-1
-
接下来就是 si 与 tj + 1 (因为j从-1开始的) 进行比较。
- 如果 si 与 tj + 1 不相同,j就要从next数组里寻找下一个匹配的位置。
- 如果 si 与 tj + 1 相同,那么i 和 j 同时向后移动
- 如果j指向了模式串t的末尾,那么就说明模式串t完全匹配文本串s里的某个子串了,所以返回当前在文本串匹配模式串的位置i 减去 模式串的长度,就是文本串字符串中出现模式串的第一个位置。
-
整体代码如下:
int j = -1; // 因为next数组里记录的起始位置为-1 for (int i = 0; i < s.size(); i++) { // 注意i就从0开始 while(j >= 0 && s[i] != t[j + 1]) { // 不匹配 j = next[j]; // j 寻找之前匹配的位置 } if (s[i] == t[j + 1]) { // 匹配,j和i同时向后移动 j++; // i的增加在for循环里 } if (j == (t.size() - 1) ) { // 文本串s里出现了模式串t return (i - t.size() + 1); } }
-
-
前缀表统一减一代码实现
c++class Solution { public: void getNext(int* next, const string& s) { int j = -1; next[0] = j; for(int i = 1; i < s.size(); i++) { // 注意i从1开始 while (j >= 0 && s[i] != s[j + 1]) { // 前后缀不相同了 j = next[j]; // 向前回退 } if (s[i] == s[j + 1]) { // 找到相同的前后缀 j++; } next[i] = j; // 将j(前缀的长度)赋给next[i] } } int strStr(string haystack, string needle) { if (needle.size() == 0) { return 0; } vector<int> next(needle.size()); getNext(&next[0], needle); int j = -1; // // 因为next数组里记录的起始位置为-1 for (int i = 0; i < haystack.size(); i++) { // 注意i就从0开始 while(j >= 0 && haystack[i] != needle[j + 1]) { // 不匹配 j = next[j]; // j 寻找之前匹配的位置 } if (haystack[i] == needle[j + 1]) { // 匹配,j和i同时向后移动 j++; // i的增加在for循环里 } if (j == (needle.size() - 1) ) { // 文本串s里出现了模式串t return (i - needle.size() + 1); } } return -1; } }; -
前缀表不减一代码实现:
// 1.next数组 // 定义j为前缀末尾,设置next第一个为0 // 循环next数组,当前后缀不相等时,j跳转到前一位的next值,连续跳转 // 当前后缀相等时,j指针向后移一位,最后next要等与j的值 // 2.判断模式串和子串 // 先判断needle的长度不能为0哦,否则返回0 // 生成next数组,和模式串一样大就行 // 循环子串,和next数组一样,当前后缀不相等时,j跳转到前一位的next值,连续跳转 // 当前后缀相等时,j指针向后移一位,最后next要等与j的值 // 如果j走到了模式数组的最后一位,返回第一位即可,否则返回1 class Solution { public: // next使用指针传递,needle使用引用传递,减少空间占用 void getNext(int* next, const string& s) { int j = 0; next[0] = 0; // 注意这里要从i=1开始循环 for(int i = 1; i < s.size(); i++) { while (j > 0 && s[i] != s[j]) { j = next[j - 1]; } if (s[i] == s[j]) { j++; } next[i] = j; } } int strStr(string haystack, string needle) { if (needle.size() == 0) { return 0; } vector<int> next(needle.size()); // 这里因为要把vector类型的next传进来,所以用&next[0],当然int数组可以直接传next getNext(&next[0], needle); int j = 0; for (int i = 0; i < haystack.size(); i++) { while(j > 0 && haystack[i] != needle[j]) { j = next[j - 1]; } if (haystack[i] == needle[j]) { j++; } if (j == needle.size() ) { return (i - needle.size() + 1); } } return -1; } };这么做有两个变化:
- nextj-1的判断变成了前一位,而且判断也有所变化。
- 从后向前填充元素,避免了从前向后填充元素时,每次添加元素都要将添加元素之后的所有元素向后移动的问题。
-
时间复杂度: O(n + m)
-
空间复杂度: O(m)
459.重复的子字符串
思路
- KMP算法,如果有重复子串,next数组中就会有大于等于2的值,计算即可
- 该想法不对,问题是判断是否完全由重复子串构成,next是计算最大前后缀的
- 暴力解法是for循环,获取子串,去和主串匹配,时间复杂度O(N2)
- 字符串结束位置,而且只到中间即可,因为子串长度不可能大于二分之一,而且子串一定是从第一个字符开始的
看完代码随想录之后的想法
移动匹配法
-
当一个字符串s:abcabc,内部由重复的子串组成,也就是由前后相同的子串组成。
-
那么既然前面有相同的子串,后面有相同的子串,用 s + s,这样组成的字符串中,后面的子串做前串,前面的子串做后串,就一定还能组成一个s,
-
在判断 s + s 拼接的字符串里是否出现一个s的的时候,要刨除 s + s 的首字符和尾字符
-
使用库函数
find,他就是用KMP算法实现的 -
判断字符串s是否由重复子串组成,只要两个s拼接在一起,里面还出现一个s的话,就说明是由重复子串组成。
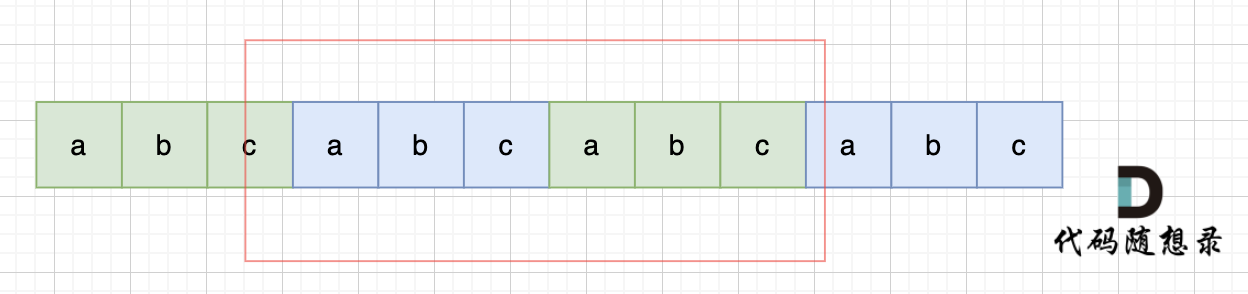
class Solution { public: bool repeatedSubstringPattern(string s) { string t = s + s; t.erase(t.begin()); t.erase(t.end() - 1); // 掐头去尾 if (t.find(s) != std::string::npos) return true; // r return false; } };
KMP算法
-
如果一个字符串s是由重复子串组成,那么 最长相等前后缀不包含的子串一定是字符串s的最小重复子串。
-
当 最长相等前后缀不包含的子串的长度 可以被 字符串s的长度整除 ,那么不包含的子串 就是s的最小重复子串。
-
如果
next[len - 1] != 0,则说明字符串有最长相同的前后缀(就是字符串里的前缀子串和后缀子串相同的最长长度) -
最长相等前后缀的长度为:
next[len - 1]。(这里的next数组是以正常的方式计算的,不需要+1 -
len - next[len - 1]是最长相等前后缀不包含的子串的长度。 -
如果
len % (len - (next[len - 1] + 1)) == 0,则说明数组的长度正好可以被 最长相等前后缀不包含的子串的长度 整除 ,说明该字符串有重复的子字符串。// 可以用移动匹配法,也可以用KMP法
class Solution {
public:
// 移动匹配法
// 先拼接+,再去头尾erase,最后查找子串find std::string::npos
bool repeatedSubstringPattern2(string s) {
string t = s + s;
t.erase(t.begin());
t.erase(t.end() - 1);
if (t.find(s) != std::string::npos) return true;
return false;
}
// KMP法
// 算next数组,如果next数组最后一位不等于0,且长度能被最长相等前后缀不包含的字串的长度整除,那这就是个重复的字符串
void getNext(int* next, const string& s) {
int j = 0;
next[0] = j;
// 注意这里i初始化为1,错两次了
for (int i = 1; i < s.size(); i++) {
while (j > 0 && s[i] != s[j]) {
j = next[j - 1];
}
// 注意这里是等于
if (s[i] == s[j]) {
j++;
}
next[i] = j;
}
}
bool repeatedSubstringPattern(string s) {
if (s.size() <= 0) return false;
// 要判断s大小别是0了
vectornext(s.size());
getNext(&next[0], s);
int len = next.size();
if (next[len - 1] != 0 && (len % (len - next[len - 1])) == 0) {
return true;
}
return false;}};
字符串总结
字符串基础类
- 在C语言中,把一个字符串存入一个数组时,也把结束符 '\0'存入数组,并以此作为该字符串是否结束的标志。
- 在C++中,提供一个string类,string类会提供 size接口,可以用来判断string类字符串是否结束,就不用'\0'来判断是否结束。
- vector< char > 和 string 又有什么区别呢?
- string提供更多的字符串处理的相关接口,例如string 重载了+,而vector却没有。
- 所以想处理字符串,还是会定义一个string类型
- 打基础的时候,不要太迷恋于库函数
双指针法
- 使用双指针法实现了反转字符串的操作,双指针法在数组,链表和字符串中很常用。
- 在字符串:替换空格 (opens new window),其实很多数组填充类的问题,都可以先预先给数组扩容带填充后的大小,然后在从后向前进行操作
- 151.翻转字符串里的单词 (opens new window)中我们使用O(n)的时间复杂度,完成了删除冗余空格
- 一些同学会使用for循环里调用库函数erase来移除元素,这其实是O(n^2)的操作,因为erase就是O(n)的操作
反转系列
- 通过 先整体反转再局部反转,实现了反转字符串里的单词
- 通过先局部反转再整体反转达到了左旋的效果
KMP
-
KMP的主要思想是当出现字符串不匹配时,可以知道一部分之前已经匹配的文本内容,可以利用这些信息避免从头再去做匹配了
-
前缀表:起始位置到下标i之前(包括i)的子串中,有多大长度的相同前缀后缀
-
前缀:指不包含最后一个字符的所有以第一个字符开头的连续子串。
后缀:指不包含第一个字符的所有以最后一个字符结尾的连续子串。
-
理解j=nextx-1这一步最为关键
遇到困难
- 一些字符串操作的库函数,需要总结
今日收获
- 今日打卡终于赶上了进度,加油