本文学习自不去幼儿园大佬的文章!加上自己的一些小见解,欢迎交流!【强化学习】近端策略优化算法(PPO)万字详解(附代码)-腾讯云开发者社区-腾讯云
过去,在强化学习中,直接优化策略会导致不稳定的训练,模型可能因为过大的参数更新而崩溃。
解决方案:PPO通过限制策略更新幅度,使得每一步训练都不会偏离当前策略太多,同时高效利用采样数据。
PPO(Proximal Policy Optimization)核心思想
PPO的目标是:
1、限制策略更新幅度,防止策略过度偏离
2、使用优势函数 ****来评价某个动作的相对好坏。
PPO目标函数如下:
其中,有一些重要参数:
:表示对时间步 t 的期望值,时间步 t 的期望值,即对
一、概率比例 它表示新策略 和旧策略在同一状态下选择动作的概率比值。
:新策略对动作
的概率。
:旧策略对动作
的概率。
这个比率表示策略变化的程度。
二、优势函数 ,或者用广义优势估计(GAE)的方法近似。
表示在状态下采取动作
相对于平均情况的优越程度。
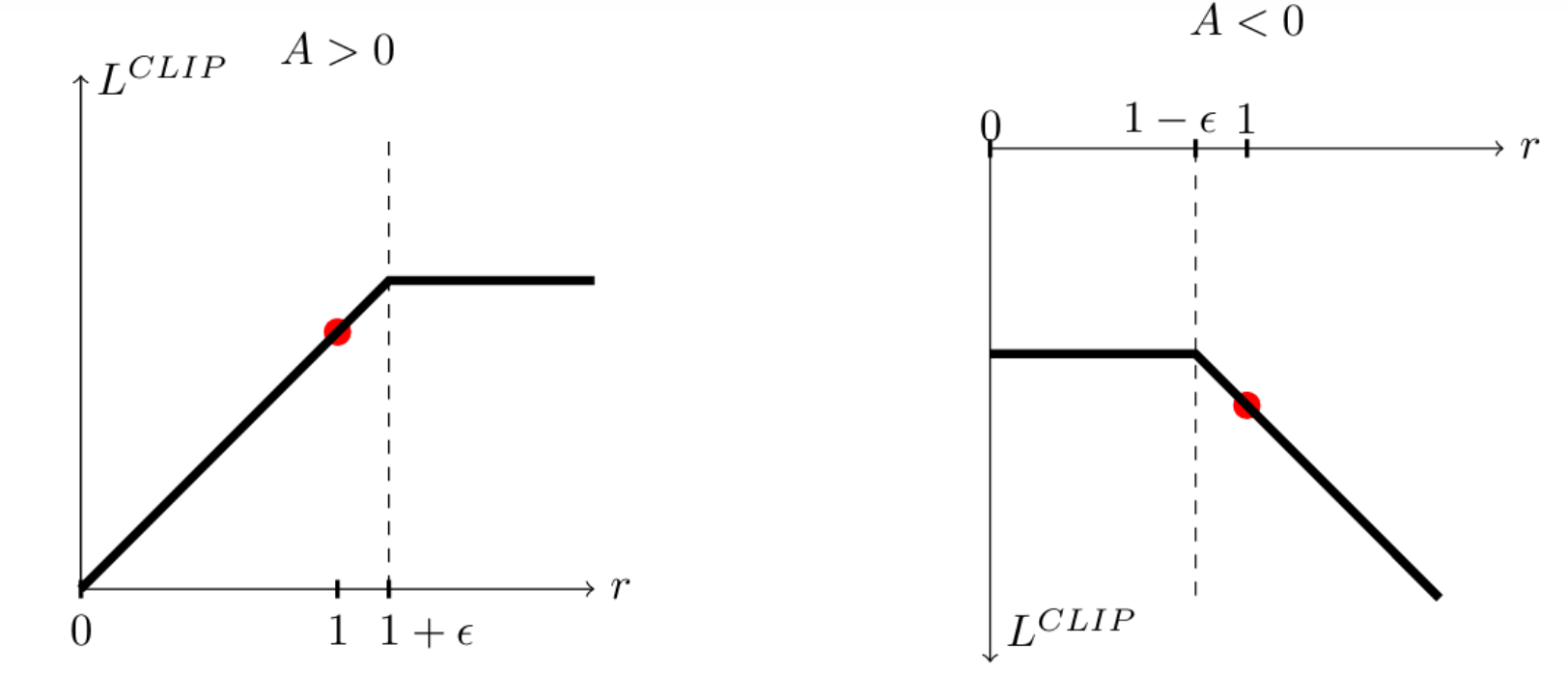
三、剪辑操作 ,它将
限制在区间
,防止策略变化过大。
为什么 PPO 很强?
- 简洁性: 比 TRPO(Trust Region Policy Optimization)更简单,无需二次优化。
- 稳定性: 使用剪辑机制防止策略更新过度。
- 高效性: 利用采样数据多次训练,提高样本利用率。
PPO的直观类比
假设你是一个篮球教练,训练球员投篮:
如果每次训练晚秋改变投篮动作,球员可能会表现失常(类似于策略更新过度)
如果每次训练动作变化太小,可能很难进步(类似于更新不足)
PPO的剪辑机制就像一个"适度改进"的规则,告诉球员在合理范围内调整投篮动作,同时评估每次投篮的表现是否优于平均水平。
强化学习的核心目标是优化策略 ,表示在给定状态下采取某个动作的概率分布
,表示在给定状态下采取某个动作的概率分布
最大化累计奖励。
策略梯度方法(如REINFORCE)直接优化策略,但更新过大可能导致不稳定。为了解决这个问题,PPO通过引入限制更新幅度的机制,保证策略的稳定性。
目标是优化以下期望:
通过梯度上升法更新策略。
值函数优化
PPO不仅优化策略,还同时更新值函数
通过最小化均方误差来更新:
:表示当前状态的值函数的预测
:累计回报。
策略熵正则化
为了鼓励策略探索 ,PPO引入了熵正则化项:
:策略的熵,表示策略分布的不正确性
增加熵可以防止策略过早收敛到局部最优。
总损失函数
PPO结合策略损失、值函数损失和熵正则化项,形成总损失函数:
和
:权重系数,用于平衡策略优化、值函数更新和熵正则化。