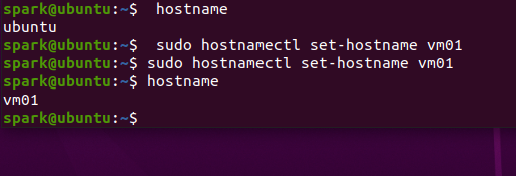
1.先查看虚拟机的默认名称,将其修改为vm01
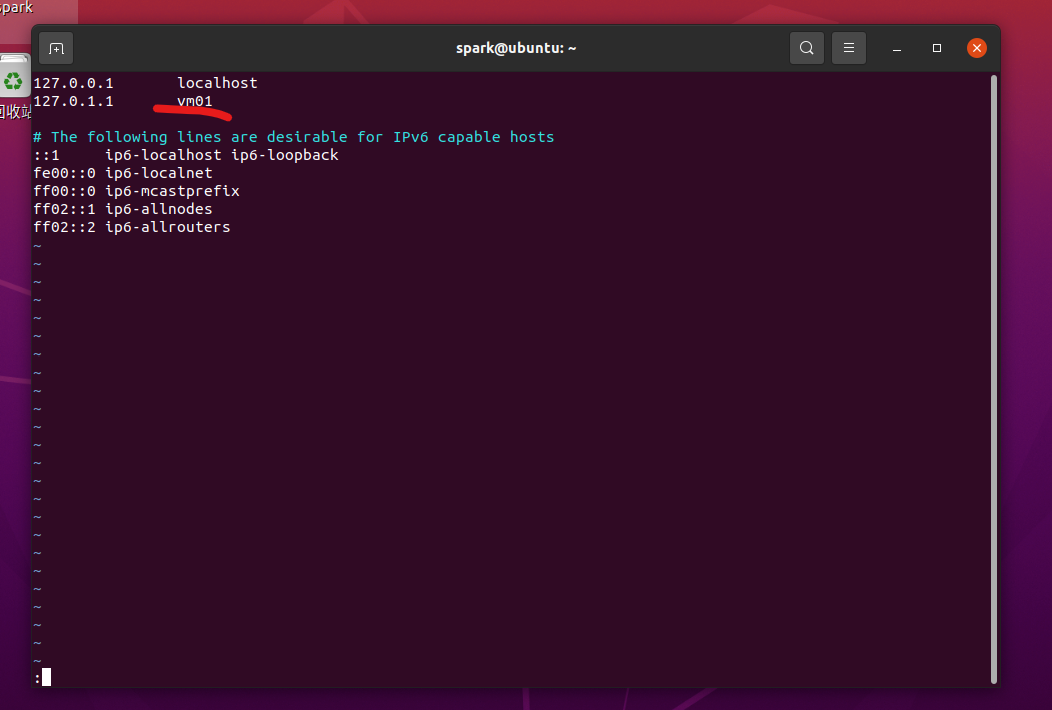
2.更改了主机名,还需要修改/etc/hosts文件,在这个文件设定了IP地址与主机名的对应关系,类似DNS域名服务器的功能
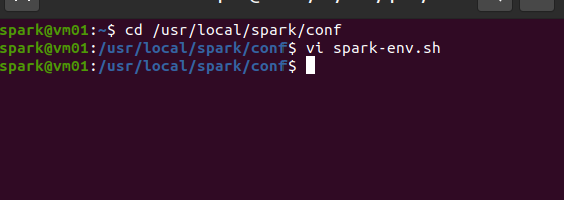
3.修改spark相关配置文件,包括spark-env.sh和slave两个文件
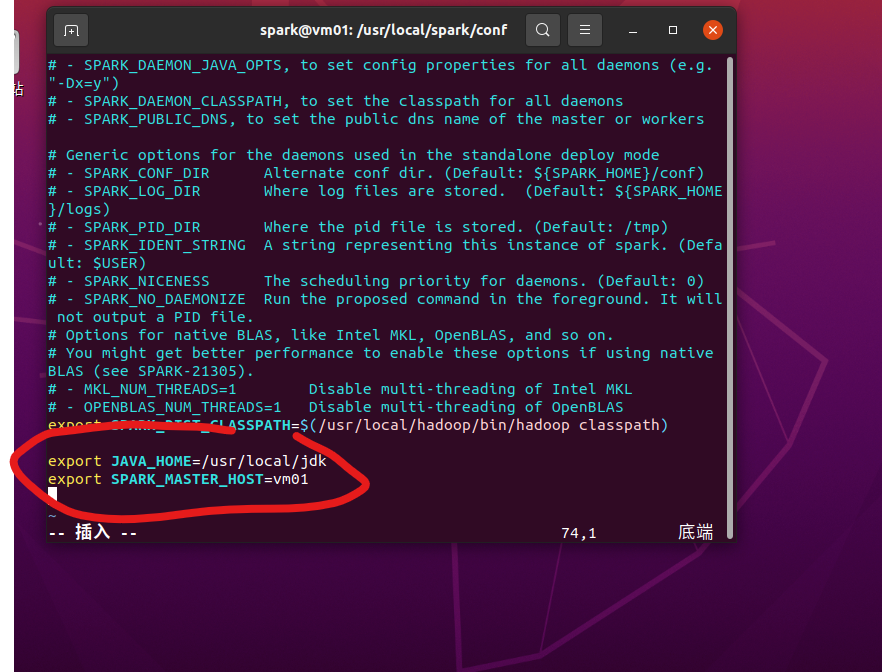

4.将localhost改为vm01 保存退出
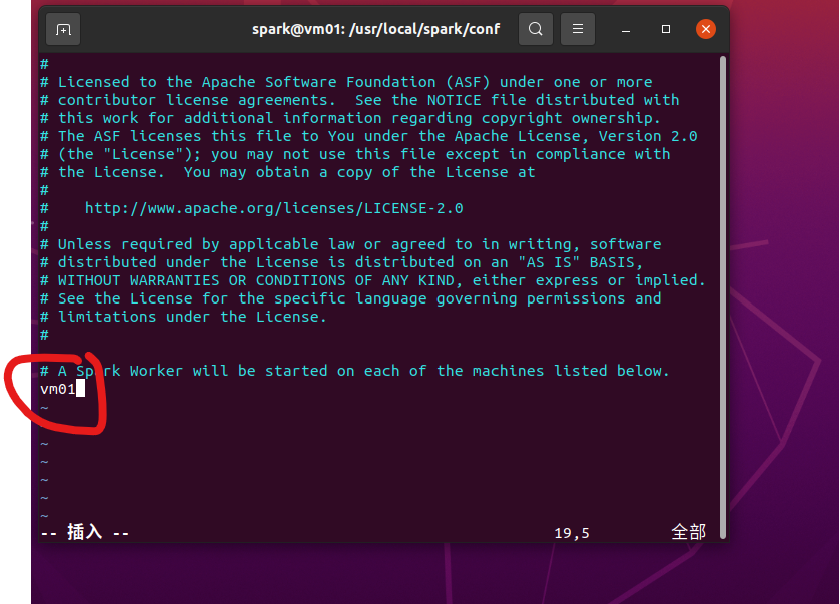
5.重启spark集群 出现worker和master表示成功

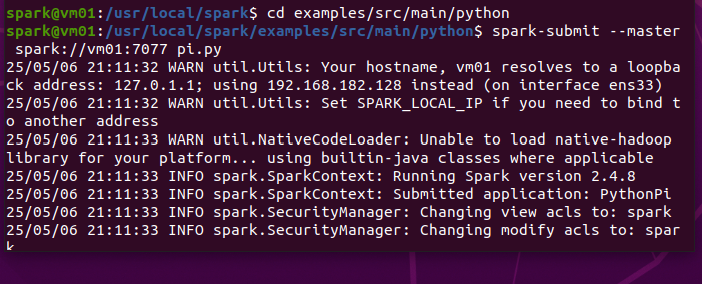
6.测试:
7.在浏览器输入:http://vm01:8080/ 查看
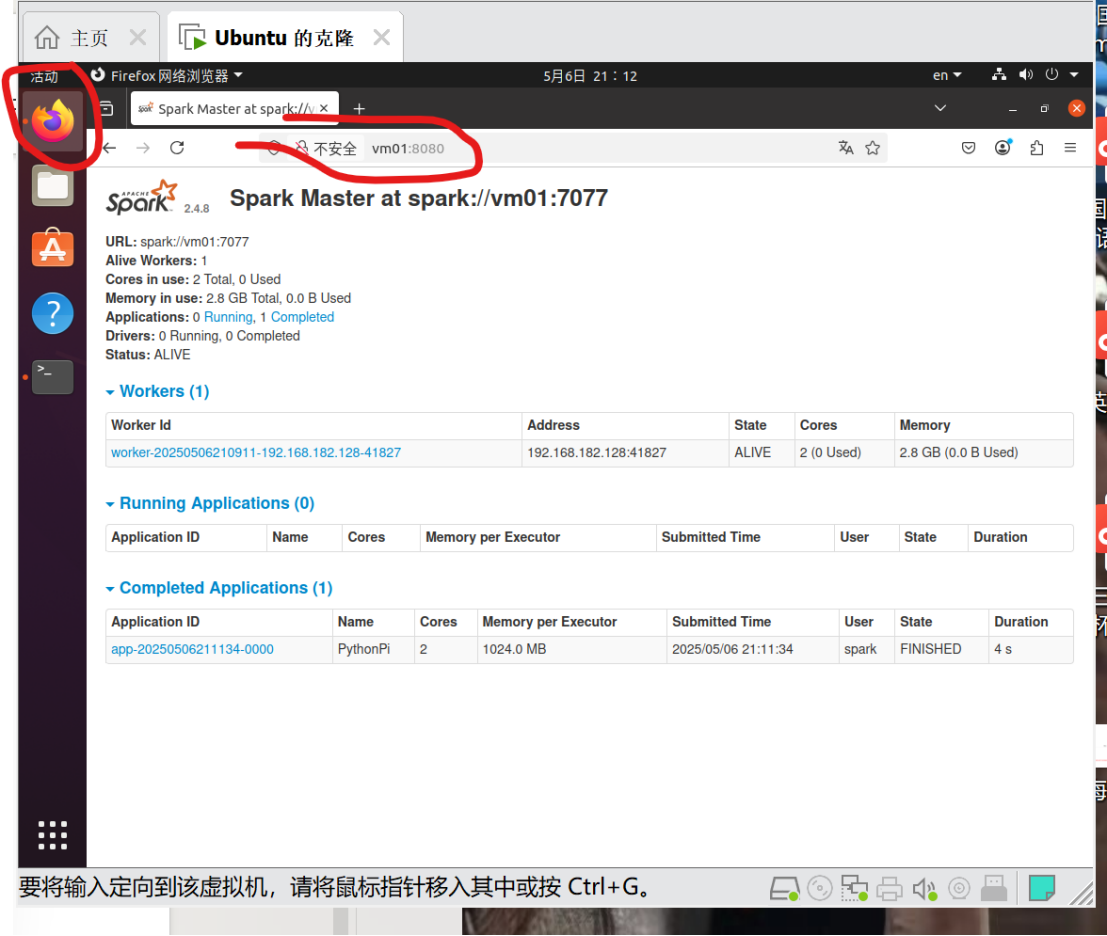
1.先查看虚拟机的默认名称,将其修改为vm01
2.更改了主机名,还需要修改/etc/hosts文件,在这个文件设定了IP地址与主机名的对应关系,类似DNS域名服务器的功能
3.修改spark相关配置文件,包括spark-env.sh和slave两个文件
4.将localhost改为vm01 保存退出
5.重启spark集群 出现worker和master表示成功
6.测试:
7.在浏览器输入:http://vm01:8080/ 查看