这是一篇2025年发表在arxiv中的LLM领域论文,是一篇非常全面的综述类论文,介绍了当前主流的强化学习方法在LLM上的应用,文章内容比较长,但建议LLM方面的从业人员反复认真阅读。
写在最前面
为了方便你的阅读,以下几点的注意事项请务必了解:
- 该系列文章每个字都是我理解后自行翻译并写上去的,可能会存在笔误与理解错误,如果发现了希望读者能够在评论区指正,我会在第一时间修正错误。
- 阅读这个系列需要你有基本的 LLM 相关基础知识,有时候我会直接使用英文名词,因为这些词汇实在不容易找到符合语境的翻译。
- 原文可能因为版面限制存在图像表格与段落不同步的问题,为了更方便阅读,我会在博文中重新对图像表格进行排版,并做到引用图表的文字下方就能看到被引用的图表。因此可能会出现一张图片在博客中多处位置重复出现的情况。
- 对于原文中的图像,我会在必要时对图像描述进行翻译并附上我自己的理解,但如果图像描述不值得翻译我也不会强行写上去。
Basic Information
- 论文标题:LLM Post-Training: A Deep Dive into Reasoning Large Language Models
- 原文链接: https://arxiv.org/abs/2502.21321
- 发表时间:2025年03月24日
- 发表平台:arxiv
- 预印版本号:v2 Mon, 24 Mar 2025 09:34:38 UTC (3,729 KB)
- 作者团队:Komal Kumar, Tajamul Ashraf, Omkar Thawakar, Rao Muhammad Anwer, Hisham Cholakkal, Mubarak Shah, Ming-Hsuan Yang, Phillip H.S. Torr, Fahad Shahbaz Khan, Salman Khan
- 院校机构:
- Mohamedbin Zayed University;
- University of Central Florida;
- University of California;
- Google DeepMind;
- University of Oxford;
- 项目链接: 【暂无】
- GitHub仓库: https://github.com/mbzuai-oryx/Awesome-LLM-Post-training
Abstract
大型语言模型 (LLM) 已经彻底改变了自然语言处理领域,并催生了丰富的应用。基于海量网络数据的预训练为这些模型奠定了基础,但学界如今正逐渐将重点转向训练后技术,以期取得进一步的突破。预训练提供了广泛的语言学基础,而后训练方法则使 LLM 能够精炼知识、改进推理、提升事实准确性,并更有效地与用户意图和伦理考量保持一致。微调、强化学习、测试期间扩展已成为优化 LLM 性能、确保稳健性以及提高其在各种实际任务中的适应性的关键策略。本综述系统地探讨了训练后方法,分析了它们在超越预训练改进 LLM 方面的作用,并解决了诸如灾难性遗忘、奖励攻击、推理时间权衡等关键挑战。重点介绍了模型对齐、可扩展自适应、推理时间推理等领域的新兴方向,并概述了未来的研究方向。作者提供了一个公共代码库,用于持续跟踪这一快速发展领域的进展:https://github.com/mbzuai-oryx/Awesome-LLM-Post-training。
1. Introduction
当代大型语言模型 (LLM) 在广泛的任务领域展现出卓越的能力,不仅涵盖文本生成和问答,还包括复杂的多步骤推理。它们为自然语言理解、内容生成、自动推理、多模态交互等领域的应用提供支持。通过利用大量的自监督训练语料库,这些模型通常能够接近人类的认知,在现实世界中表现出令人印象深刻的适应性。
尽管取得了这些令人瞩目的成就,LLM 仍然存在一些关键缺陷。它们可能会生成误导性或事实上不正确的内容(通常被称为"幻觉"),并且可能难以在长篇论述中保持逻辑一致性。此外,LLM 中的推理概念仍然是一个有争议的话题。虽然这些模型可以生成看似逻辑连贯的答案,但它们的推理与类似人类的逻辑推理有着根本的区别。这种区别至关重要,因为有助于解释为什么 LLM 能够在相对简单的逻辑任务中产生令人信服的输出。与基于显式规则和事实的符号推理不同,LLM 以隐式和概率的方式运行。就本文而言,LLM 中的"推理"是指其基于数据中的统计模式生成逻辑连贯响应的能力,而非明确的逻辑推理或符号操作。此外,纯粹通过下一个 tokens 预测训练的模型可能无法满足用户期望或道德标准,尤其是在模糊或恶意场景下。这些问题凸显了制定专门策略以解决 LLM 输出中的可靠性、偏差、情境敏感性问题的需求。
LLM 的训练大致可分为两个阶段:
- pre-training 预训练阶段:通常依赖于大规模语料库的下一个标记预测目标;
- post-training 后训练阶段:包含多轮微调和对齐。后训练机制旨在通过改进模型行为并使输出与人类意图保持一致,从而减轻 LLM 的局限性,从而减少偏差或不准确性。
将 LLM 适配到特定领域任务通常需要用到诸如微调之类的技术,虽然能够实现特定任务的学习,但存在过拟合的风险,并且计算成本较高。为了应对这些挑战,强化学习 (RL) 等方法通过利用动态反馈和优化顺序决策来增强适应性。此外,低秩自适应 (LoRA) 、适配器(adapters)、检索增强生成 (RAG) 等扩展技术的进步,提高了计算效率和事实准确性。这些策略与分布式训练框架相结合,有助于大规模部署,并进一步提升 LLM 在不同应用中的可用性 Fig. 1。通过这些有针对性的培训后干预措施,LLM 能够更好地契合人类意图和伦理要求,最终提升其在现实世界中的适用性。作者总结了后训练的一些关键阶段。
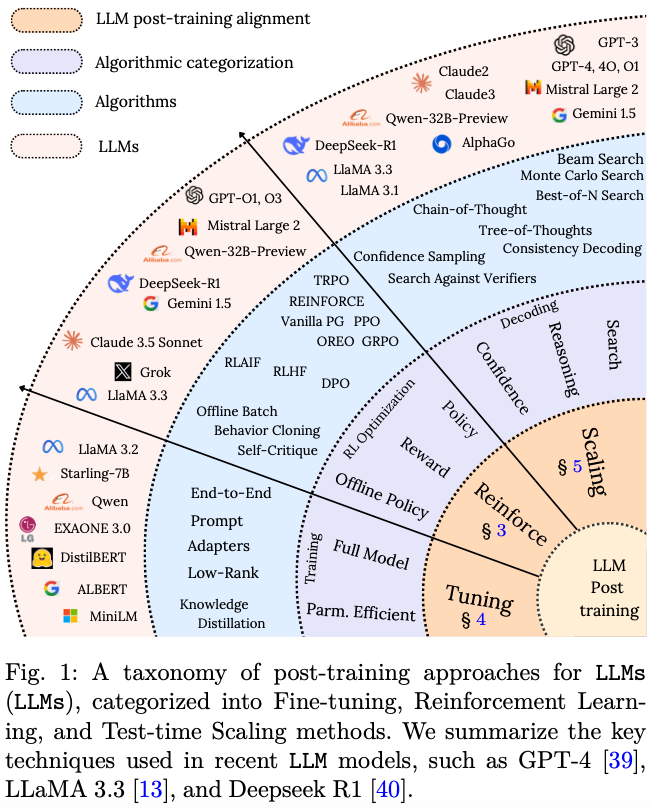
a). Fine-Tuning in LLMs
微调 (fine-tuning) 通过在精选数据集上更新参数,使预训练的 LLM 适应特定任务或领域。虽然 LLM 在大规模预训练后具有良好的泛化能力,但微调可以提升情绪分析、问答、医疗诊断等特定领域应用等任务的性能。微调通常采用监督学习,旨在使模型与任务需求保持一致,但也带来了诸如过拟合、计算成本高、数据偏差敏感性等挑战;像 LoRA 这样的高效技术以及 adapter 通过更新显式参数来学习特定任务的自适应性,从而显著降低计算开销。随着模型的专业化,它们可能会难以实现领域外的泛化,这凸显了特异性和多功能性之间的权衡。

b). Reinforcement Learning in LLMs
在传统的强化学习中,agent与结构化环境交互,使用离散动作在状态之间转换,同时最大化累积奖励。强化学习领域(例如机器人、棋盘游戏、控制系统)具有明确定义的状态-动作空间和清晰的目标。LLM 中的强化学习则截然不同。LLM 不是从有限的动作集中选择 token,而是从庞大的词汇表中选择token,其演化状态包含一个不断增长的文本序列。这使得规划和评估分配变得复杂,因为选择token的影响可能要到后面才会显现。基于语言的强化学习反馈也比较稀疏、主观且具有延迟性,依赖于启发式评估和用户偏好,而不是明确的性能指标。此外,与通常针对单一目标进行优化的传统强化学习不同,LLM 必须平衡多个目标(有时甚至相互冲突)。将基于过程的奖励(例如,CoT)与基于结果的评估(例如,响应质量)相结合的混合方法有助于改进学习。因此,LLM 的强化学习需要专门的优化技术来处理高维输出、非平稳目标和复杂的奖励结构,以确保响应保持上下文相关性并符合用户期望。
c). TestTimeScalinginLLMs
测试时扩展 (TestTimeScaling) 可以在不改变核心架构的情况下优化模型性能和效率。它能够在最小化计算开销的同时实现更好的泛化,这对于提升 LLM 的性能和效率至关重要,有助于提升跨任务的泛化能力,但也带来了巨大的算力挑战。平衡性能和资源效率需要在推理过程中采取有针对性的策略。诸如 CoT 推理和思维树 (ToT) 框架之类的技术通过将复杂问题分解为顺序或树状结构的步骤来增强多步骤推理。此外,基于搜索的技术可以迭代探索可能的输出,从而有助于优化响应并确保更高的事实准确性。这些方法与LoRA、adapter、RAG 等方法相结合,优化了模型处理大规模复杂领域特定任务的能力。RAG通过动态检索外部知识来提高事实准确性,从而减轻了静态训练数据的局限性。分布式训练框架利用并行处理来管理大规模模型的高计算需求。测试时扩展通过根据任务复杂性动态调整参数来优化推理。修改深度、宽度或活跃层可以在计算效率和输出质量之间取得平衡,使其在资源有限或多变的条件下具有价值。尽管取得了进展,但扩展仍存在一些挑战,例如收益递减、推理时间更长、环境影响,特别是当测试而不是训练期间执行搜索技术时。确保可及性和可行性对于维持高质量 LLM 部署至关重要。

1.1 Prior Surveys
近期关于强化学习和LLM的综述虽然提供了宝贵的见解,但往往侧重于特定方面,而对关键的后训练部分的涉及不足。许多著作探讨了强化学习技术,例如基于人类反馈的强化学习 (RLHF) 、基于人工智能反馈的强化学习 (RLAIF) 、直接偏好优化 (DPO) ,但却忽略了微调、扩展和实际应用所必需的关键基准。此外,这些研究甚至没有探索强化学习在各种框架(例如基于 GRPO 的 DeepSeek R1 )中的情况,即使在没有人工标注的监督微调的情况下,也没有展现其潜力。其他综述探讨了LLM 在传统强化学习任务(例如多任务学习和决策制定)中的应用,但它们主要对LLM的功能进行分类,而不是研究测试时扩展和集成的后训练策略。类似地,关于 LLM 推理的研究讨论了学习推理技术,但缺乏如何将微调、强化学习、扩展相结合的结构化指导,以及对软件库和实现工具方式,进一步限制了它们的实用性。相比之下,本文通过系统地涵盖微调、强化学习、扩展作为相互关联的优化策略,提供了Fig.1所示的 LLM 后训练的全面视角。提供实用资源------基准、数据集、教程以帮助改进 LLM 以用于实际应用。
1.2 Contributions
本文的主要贡献如下:
- 对 LLM 的后训练方法进行了全面而系统的回顾,涵盖了微调、RL 、缩放作为模型优化的组成部分;
- 提供了后训练技术的结构化分类法,阐明了它们的作用和相互联系,并提出了对优化 LLM 以用于实际部署的开放挑战和未来研究方向的见解;
- 介绍评估后训练效果所必需的关键基准、数据集、评估指标,提供了实用指导,确保为实际应用提供结构化的框架;
2. Background
LLM 通过学习基于海量文本数据预测序列中下一个token,从而彻底改变了推理方式。使用最大似然估计 (MLE),最大化给定输入生成正确序列的概率,通过最小化负对数似然来实现:
L M L E = − ∑ t = 1 T log P θ ( y t ∣ y < t , X ) L_{MLE}=-\sum^{T}{t=1}\log{P{\theta}(y_{t}|y_{<t},X)} LMLE=−t=1∑TlogPθ(yt∣y<t,X)
此处, X X X 表示输入,例如提示或上下文。 Y = ( y 1 , y 2 , ... , y T ) Y=(y_{1},y_{2},\dots,y_{T}) Y=(y1,y2,...,yT) 是相应的目标输出序列; P θ ( y t ∣ y < t , X ) P_{\theta}(y_{t}|y_{<t}, X) Pθ(yt∣y<t,X) 表示给定前面的 token 输入模型对token y t y_{t} yt 的预测概率。

随着模型规模增长涌现的推理能力,尤其是在包含代码和数学内容的多样化数据进行训练时。然而,尽管LLM 能力惊人,但仍难以在长序列上保持连贯性和上下文相关性。克服这些局限性需要一种结构化的序列生成方法,这与强化学习 (RL) 天然契合。
由于LLM以自回归的方式生成文本,每个token的预测都依赖于之前生成的token,因此该过程可以建模为马尔可夫决策过程 (MDP) 中的序列决策问题。在这种情况下,状态 s t s_{t} st表示已经生成的token序列,动作 a t a_{t} at表示下一个token,奖励 R ( s t , a t ) R(s_{t},a_{t}) R(st,at)评估输出的质量。LLM的策略 π θ \pi_{\theta} πθ经过优化,以最大化预期回报:
J ( π θ ) = E ∑ t = 0 ∞ γ t R ( s t , a t ) J(\pi_{\theta})=E\left\\sum\^{\\infty}_{t=0}\\gamma\^{t}R(s_{t},a_{t})\\right J(πθ)=Et=0∑∞γtR(st,at)
其中 γ \gamma γ 是折扣因子,它决定了未来奖励对当前决策的影响程度 。 γ \gamma γ 越高,长期奖励的重要性就越高。强化学习的主要目标是学习一种策略,以最大化预期累积奖励(通常称为回报),需要在探索(尝试新的行动以发现其效果)和利用(利用已知的、能产生高回报的行动)之间取得平衡。LLM 使用静态数据优化似然函数,而强化学习则通过动态交互来优化预期回报。为了确保 LLM 生成的响应不仅在统计上具有可能性,而且与人类偏好相符,超越静态优化方法至关重要。虽然基于似然性的训练可以从海量语料库中捕获模式,但它缺乏在交互环境中改进决策所需的适应性。通过利用结构化方法来最大化长期目标,模型可以动态调整其策略,平衡探索和利用,从而改进推理、连贯性和一致性。

【Note】原文的这张 Fig2 非常重要,是第二章节的精华。
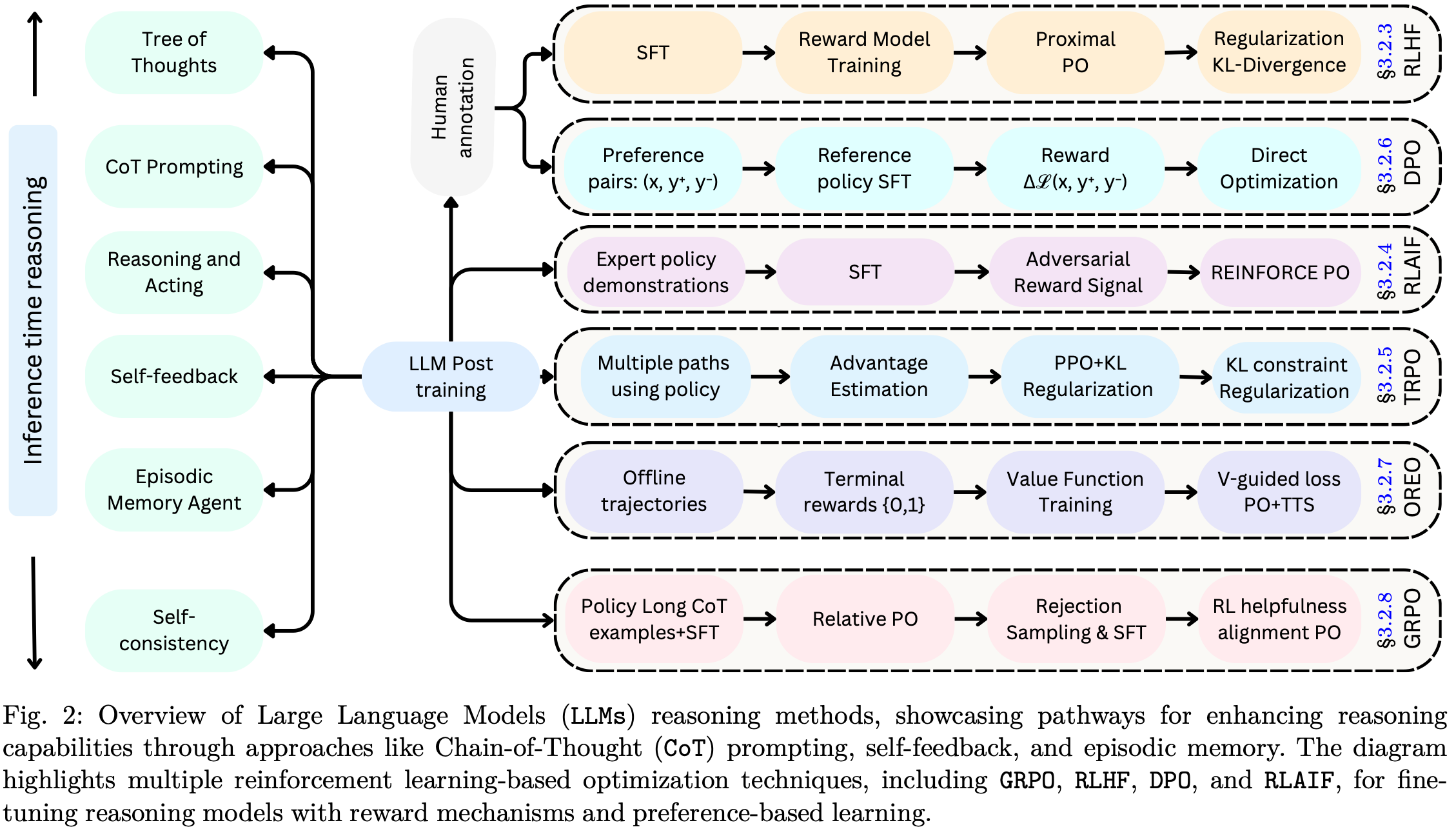
2.1 RL based Sequential Reasoning
LLM 中采用的思路链推理自然地被定义为强化学习 (RL) 问题。从这个角度来看,每个中间推理步骤都被视为一个有助于最终答案的动作。目标函数 J ( π θ ) J(\pi_{\theta}) J(πθ) 表示策略 π θ \pi_{\theta} πθ 的预期奖励,它反映了模型在多个推理步骤中的表现。策略梯度更新由下式给出:
∇ θ J ( π θ ) = E r ∑ t = 1 T ∇ θ log π θ ( x t ∣ x 1 : t − 1 ) A ( s t , a t ) \nabla_{\theta}J(\pi_{\theta})=E_{r}\left\\sum\^{T}_{t=1}\\nabla_{\\theta}\\log{\\pi_{\\theta}(x_{t}\|x_{1:t-1})A(s_{t},a_{t})}\\right ∇θJ(πθ)=Ert=1∑T∇θlogπθ(xt∣x1:t−1)A(st,at)
其中,优势函数 A ( s t , a t ) A(s_{t}, a_{t}) A(st,at) 将奖励分配给各个步骤,确保整个推理过程通过即时奖励和延迟奖励得到优化。此类公式如逐步奖励分解,对于提升 LLM 在复杂推理任务上的可解释性和性能至关重要。在传统的强化学习公式中 agent 为:
Value function: V ( s ) = E future return ∣ s , Action-value (Q-) function: Q ( s , a ) = E future return ∣ s , a , Advantage function: A ( s , a ) = Q ( s , a ) − V ( s ) \begin{align} \text{Value function: } V(s) &= E\\text{future return} \| s, \nonumber\\ \text{Action-value (Q-) function: } Q(s,a) &= E\\text{future return} \| s, a, \nonumber \\ \text{Advantage function: } A(s,a) &= Q(s,a)-V(s) \nonumber \end{align} Value function: V(s)Action-value (Q-) function: Q(s,a)Advantage function: A(s,a)=Efuture return∣s,=Efuture return∣s,a,=Q(s,a)−V(s)
A ( s , a ) A(s,a) A(s,a) 衡量在状态 s s s 下采取特定动作 a a a 与agent通常预期相比基线 V ( s ) V(s) V(s) 的成绩。
2.2 Early RL Methods for Language Modeling
此处简要概述将强化学习应用于语言生成任务的先前方法。这些最初的研究通过直接调整决策模型 p θ p_{\theta} pθ 的参数来最大化奖励,从而训练该模型。下面是一些策略梯度方法:
Policy Gradient (REINFORCE)
REINFORCE 算法是一种++根据模型行动获得的奖励来调整策略的改进决策方法++ 。该算法并非直接学习每种情况下的最佳行动,而是不断改进不同行动被选择的可能性,从而随着时间的推移逐渐改善结果。在每一步中,模型都会根据其过去决策的表现来更新其参数 θ \theta θ:
θ ← θ + α ( G − b ) ∑ t = 1 T ∇ θ log π θ ( a t ∣ s t ) \theta\leftarrow\theta+\alpha(G-b)\sum^{T}{t=1}\nabla{\theta}\log{\pi_{\theta}}(a_{t}|s_{t}) θ←θ+α(G−b)t=1∑T∇θlogπθ(at∣st)
G G G 表示模型在一集中累积的总奖励; b b b 是有助于减少方差的基线值使学习更稳定; ∇ θ log π θ ( a t ∣ s t ) \nabla_{\theta}\log{\pi_{\theta}(a_{t}|s_{t})} ∇θlogπθ(at∣st) 衡量 θ \theta θ 的微小变化对在给定状态 s t s_{t} st 下选择动作的概率的影响程度; α \alpha α 是学习率,控制每一步策略更新的程度。

Curriculum Learning with MIXER
Ranzato 等人提出了一种从++最大似然估计 (MLE) 到强化学习的渐进式过渡方法++。总体损失是一个加权组合:
L = λ ( t ) L M L E + ( 1 − λ ( t ) ) L R L L=\lambda(t)L_{MLE}+(1-\lambda(t))L_{RL} L=λ(t)LMLE+(1−λ(t))LRL
其中 λ ( t ) \lambda(t) λ(t) 随训练时间而减小,这种设置有助于模型轻松实现强化学习目标,并缓解训练与推理之间的不匹配问题。
Self-Critical Sequence Training (SCST)
SCST 通过将模型的采样输出与其自身的最佳(贪婪)预测进行比较,改进了策略梯度方法。SCST 不使用任意基线,而是++使用模型自身得分最高的输出,确保更新能够直接提升相对于模型当前认为的最佳响应的性能++。梯度更新如下:
∇ θ J ( π θ ) ≈ ( r ( y s , r ( y ^ ) ) ∇ θ log π θ ( y s ) \nabla_{\theta}J(\pi_{\theta})\approx\left(r(y^{s},r(\hat{y})\right)\nabla_{\theta}\log{\pi_{\theta}}(y^{s}) ∇θJ(πθ)≈(r(ys,r(y^))∇θlogπθ(ys)
其中 y s y_{s} ys 是采样序列; y ^ \hat{y} y^ 是贪婪输出; r ( y ) r(y) r(y) 表示评估指标,例如用于翻译的 BLEU 或用于图像字幕的 CIDEr。由于基于差值 r ( y s ) − r ( y ^ ) r(y^{s})-r(\hat{y}) r(ys)−r(y^) 学习,因此模型经过明确训练,以生成在评估指标下得分高于自身基线的输出。如果采样输出优于贪婪输出,模型就会强化该序列;否则会抑制该序列。这种直接反馈回路确保训练符合所需的评估标准,而不仅仅是最大化似然值。通过利用模型自身的最佳预测作为基线,SCST 可以有效地降低方差并稳定训练,同时优化实际性能指标。最小风险训练 (MRT) 直接最小化输出分布的预期风险。给定一个特定于任务的损失 Δ ( y , y ∗ ) \Delta(y,y^{*}) Δ(y,y∗),将生成的输出 y y y与参考 y ∗ y^{*} y∗进行比较,MRT目标定义为:
L M R T ( θ ) = ∑ y ∈ Y p θ ( y ∣ x ) Δ ( y , y ∗ ) L_{MRT}(\theta)=\sum_{y\in Y}p_{\theta}(y|x)\Delta(y,y^{*}) LMRT(θ)=y∈Y∑pθ(y∣x)Δ(y,y∗)
该公式将评估指标(例如 1-BLEU)直接纳入训练中,从而实现策略的细粒度调整。
Advantage Actor-Critic (A2C/A3C)
强化学习方法(如 REINFORCE)完全依赖于策略梯度,而策略梯度的方差较大,导致学习不稳定且效率低下。由于奖励信号在不同轨迹上波动,更新可能会产生噪声,从而导致收敛缓慢或不稳定。为了缓解这个问题,Actor-Critic 方法将两个组件组合在一起:++一个参与者和一个评论家++ 。参与者是一个策略 π θ ( a t ∣ s t ) \pi_{\theta}(a_{t}|s_{t}) πθ(at∣st),用于选择状态 s t s_{t} st 下的动作 a t a_{t} at ;评论家是一个价值函数 V ϕ ( s t ) V_{\phi}(s_{t}) Vϕ(st),用于评估状态的预期回报。评论家提供更稳定的学习信号,减少策略更新的方差,并实现连续动作空间中的高效学习。参与者更新由策略梯度定理指导,其中第 2.1 节中定义的优势函数 A ( s t , a t ) A(s_{t},a_{t}) A(st,at) 决定了动作 a t a_{t} at 相对于状态 s t s_{t} st 的预期值有多好。学习率为 α \alpha α 的策略更新为:
θ ← θ + α A ( s t , a t ) ∇ θ log π θ ( a t ∣ s t ) \theta\leftarrow\theta+\alpha A(s_{t},a_{t})\nabla_{\theta}\log{\pi_{\theta}(a_{t}|s_{t})} θ←θ+αA(st,at)∇θlogπθ(at∣st)
同时,使用时间差分学习来更新评论家,以最小化其估计值与实际回报之间的平方误差:
ϕ ← ϕ − β ∇ ϕ ( V ϕ ( s t ) − G t ) 2 \phi\leftarrow\phi-\beta\nabla_{\phi}\left(V_{\phi}(s_{t})-G_{t}\right)^{2} ϕ←ϕ−β∇ϕ(Vϕ(st)−Gt)2
其中 β \beta β是 critic 的学习率。为了提高稳定性和效率,允许从近期状态进行学习,从而实现更快的收敛。使用神经网络进行函数逼近可以确保有效处理高维输入,如Natural Gradient Method自然梯度法等高级变体使用Fisher信息矩阵调整更新,从而提高收敛速度。
一个早期例子是 Barto 的 Actor-Critic 模型,其中批评者使用线性函数 V ϕ ( s t ) V_{\phi}(s_{t}) Vϕ(st),而参与者遵循线性策略。A2C(Advantage Actor-Critic)和 A3C(Asynchronous Advantage Actor-Critic)等现代方法通过在多个环境中并行训练扩展了这种方法,从而实现了更快、更稳定的学习。利用批评者的价值估计,Actor-Critic 方法可以稳定学习,提高样本效率,并加速收敛,使其在复杂的决策任务中更加有效。
Connection with Modern Methods
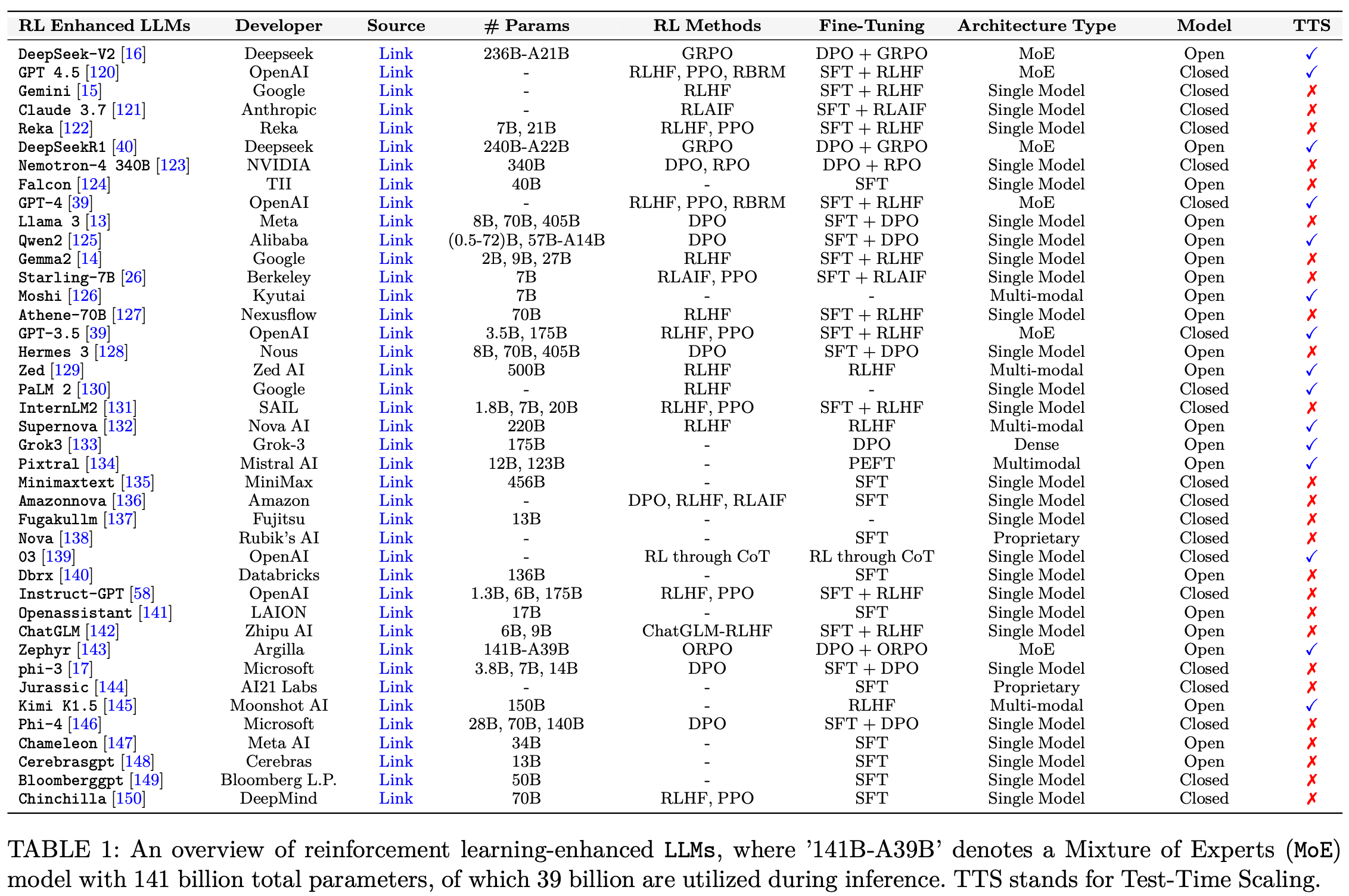
早期的强化学习方法:REINFORCE、MIXER、SeqGAN、SCST、MRT 、Actor-Critic算法为 LLM 中的序列推理奠定了数学基础。这些方法为诸如暴露偏差和高方差等难题提供了初步解决方案。现代方法,如使用 PPO 的大规模人类反馈强化学习 (RLHF) 和高级奖励模型、群体相对策略优化 (GRPO) ,都直接建立在这些思想之上。++通过整合复杂的奖励信号并利用高效的策略更新++ ,现代的 LLM 实现了改进的推理能力、安全性、与人类价值观的一致性,并为鲁棒的多步推理和提高生成文本的质量铺平了道路。Table.1 概述了近期模型,包括它们的参数、架构类型、所采用的强化学习方法。
【Note】原文的表中有超链接可以直接点开查看。
3. Reinforces LLMs
从方法论的角度来看,将强化学习融入LLM推理通常遵循四个核心步骤:
- Supervised Fine-Tuning(SFT):首先构建一个预训练的语言模型,然后在一个由高质量人工示例组成的监督数据集上进行细化。此阶段确保模型达到符合格式和风格准则的基准;
- Reward Model (RM) Training:收集微调模型生成的输出,并对其进行人工偏标记。然后对奖励模型进行训练,使其能够复制这些基于标签的分数或排名,从而有效地学习将生成文本映射到标量值的连续奖励函数;
- RL Fine-Tuning:最后,通过策略梯度算法(例如 PPO)优化主语言模型,以最大化奖励模型的输出。通过迭代此循环,LLM 学会在准确性、实用性和风格连贯性等关键维度上生成符合人类偏好的响应;
- Reward Modeling and Alignment:作者开发了复杂的奖励函数,借鉴人类偏好、对抗性反馈或自动化指标等,用于引导模型获得连贯、安全、符合情境的输出。这些奖励对于在多步骤推理过程中有效地分配信用至关重要;
早期将 LLM 与人类偏好对齐的方法利用了经典的 RL 算法,例如 PPO 和信赖域策略优化 (TRPO) ,这些算法通过最大化预期累积奖励来优化策略,同时通过agent目标函数和 KL 散度正则化对策略更新施加约束。目前,已经出现了针对这些可扩展的基于偏好的优化方法的改进替代方案,例如直接偏好优化 (DPO) 和组相对策略优化 (GRPO) ,它们将对齐目标重新表述为基于人类token的偏好数据上的排名的对比损失函数。与依赖于显式奖励模型和评价网络的 PPO 和 TRPO 不同,DPO 和 GRPO 分别利用对数似然比和组内奖励比较来直接优化策略,从而消除了对显式价值函数近似的需求,同时保留了偏好一致的学习动态。从经典的基于强化学习的对齐到基于偏好的直接优化的转变引入了新的公式,例如对比排序损失、策略似然比正则化和分组优势估计,这些将在后续章节中解释。
3.1 Reward modeling
设 X X X 为可能的查询空间(例如,用户提示)。对于每个查询 x ∈ X x \in X x∈X 收集一个或多个候选生成结果 { y j } j = 1 m x \{y_{j}\}^{m_{x}}{j=1} {yj}j=1mx,其中 m s m{s} ms 是查询 x x x 的候选响应数量。通常,这些响应是由语言模型或策略在不同的采样或提示条件下生成的。人工标注者会对这些响应提供偏好判断。这些偏好判断可以采取多种形式:
- Pairwise preference :对于同一查询 x x x 的两个响应 y j y_{j} yj 和 y k y_{k} yk ,判断 y j y_{j} yj 是否优于 y k y_{k} yk;
- Rankings :候选答案的部分或全部排序,例如 y j 1 ≻ y j 2 ≻ ⋯ ≻ y j m x y_{j_{1}}\succ y_{j_{2}}\succ\dots\succ y_{j_{m_{x}}} yj1≻yj2≻⋯≻yjmx;
每个生成或每个生成对的此类人类偏好数据表示为 r j r_{j} rj,其中 r j r_{j} rj 可以是标签、等级、指示偏好程度的索引,故整体数据集 D D D 由 N N N 个带注释的示例组成:
D = { ( x i , { y j i } m i ) j = 1 , { preferences i } } i = 1 N D=\{(x^{i},\{y^{i}{j}\}^{m{i}}){j=1},\{\text{preferences}^{i}\}\}^{N}{i=1} D={(xi,{yji}mi)j=1,{preferencesi}}i=1N
在实际使用过程中,大规模的询问 x x x 从真实或模拟的用户询问中采样得到。候选响应 { y j } j = 1 m x \{y_{j}\}^{m_{x}}{j=1} {yj}j=1mx 同样从基底模型、beam search、解码策略中采样得到。人工标注员会根据预先定义的标准(例如质量、正确性、有用性等)提供成对或排名反馈,以判断响应的质量。作者训练一个参数模型奖励模型 R θ ( x , y ) R{\theta}(x,y) Rθ(x,y) 简称奖励模型,将每个 (query,respinse) 对 ( x , y ) (x, y) (x,y) 映射到一个标量分数。目标是让 R θ R_{\theta} Rθ 反映一致性或偏好程度,满足以下条件,其中 Y Y Y 是所有可能的响应空间:
R θ : X × Y → R R_{\theta}: X\times Y \to R Rθ:X×Y→R
为了训练 R θ R_{\theta} Rθ,作者使用 D D D 中的人类偏好标签来定义合适的基于排名的损失,如下所述。
I. Bradley--Terry Model (Pairwise)
对于成对偏好,使用 Bradley-Terry 模型。假设数据集对于给定的查询 x x x,人类注释者更喜欢 y j y_{j} yj 而不是 y k y_{k} yk 则将其表示为 y j ≻ y k y_{j}\succ y_{k} yj≻yk。在 Bradley-Terry 模型下 y j y_{j} yj 优于 y k y_{k} yk 的概率为:
P ( y j ≻ y k ∣ x ; θ ) = e x p ( R θ ( x , y j ) ) e x p ( R θ ( x , y j ) ) + e x p ( R θ ( x , y k ) ) P(y_{j}\succ y_{k}|x;\theta)=\frac{exp(R_{\theta}(x,y_{j}))}{exp(R_{\theta}(x,y_{j}))+exp(R_{\theta}(x,y_{k}))} P(yj≻yk∣x;θ)=exp(Rθ(x,yj))+exp(Rθ(x,yk))exp(Rθ(x,yj))
通过 ++最大化++ 观察到的偏好的可能性(等效++最小化++ 负对数似然)来训练 R θ R_{\theta} Rθ:
L B T ( θ ) = − ∑ ( x , y j ≻ y k ) ∈ D log P ( y j ≻ y k ∣ x ; θ ) L_{BT}(\theta)=-\sum_{(x,y_{j}\succ y_{k})\in D}\log{P(y_{j}\succ y_{k}|x; \theta)} LBT(θ)=−(x,yj≻yk)∈D∑logP(yj≻yk∣x;θ)
II. Plackett--Luce Model (Rankings)
当 m m m 个响应的全部或部分排名可用时,即
y j 1 ≻ y j 2 ≻ ⋯ ≻ y j m y_{j_{1}}\succ y_{j_{2}}\succ \dots \succ y_{j_{m}} yj1≻yj2≻⋯≻yjm
Plackett-Luce模型将此排名的概率分解为:
P ( y j 1 , ... , y j m ∣ x ; θ ) = ∏ l = 1 m e x p ( R θ ( x , y j l ) ) ∑ k = l m e x p ( R θ ( x , y j k ) ) P(y_{j_{1},\dots,y_{j_{m}}}|x;\theta)=\prod^{m}{l=1}\frac{exp(R{\theta}(x,y_{j_{l}}))}{\sum^{m}{k=l}exp(R{\theta}(x,y_{j_{k}}))} P(yj1,...,yjm∣x;θ)=l=1∏m∑k=lmexp(Rθ(x,yjk))exp(Rθ(x,yjl))
其负对数似然为:
L P L ( θ ) = − ∑ ( x , r a n k ) ∈ D ∑ l = 1 m log e x p ( R θ ( x , y j l ) ) ∑ k = l m e x p ( R θ ( x , y j k ) ) L_{PL}(\theta)=-\sum_{(x,rank)\in D}\sum^{m}{l=1}\log{\frac{exp(R{\theta}(x,y_{j_{l}}))}{\sum^{m}{k=l}exp(R{\theta}(x,y_{j_{k}}))}} LPL(θ)=−(x,rank)∈D∑l=1∑mlog∑k=lmexp(Rθ(x,yjk))exp(Rθ(x,yjl))
实践中最小化所有偏好数据中基于排名的损失之和(或平均值):
L ( θ ) = 1 ∣ D ∣ ∑ ( x , { y } , prefs ) ∈ D L r a n k i n g ( θ ; x , { y j } , prefs ) L(\theta)=\frac{1}{|D|}\sum_{(x,\{y\},\text{prefs})\in D}L_{ranking}(\theta;x,\{y_{j}\},\text{prefs}) L(θ)=∣D∣1(x,{y},prefs)∈D∑Lranking(θ;x,{yj},prefs)
其中 L r a n k i n g L_{ranking} Lranking 可以是 L B T L_{BT} LBT 或 L P L L_{PL} LPL。虽然奖励模型 R θ ( x , y ) R_{\theta}(x,y) Rθ(x,y) 提供了反映人类偏好的标量奖励信号,但这与常见的强化学习概念(尤其是优势函数)相关。奖励可分为显性奖励和隐性奖励。

3.1.1 Explicit Reward Modeling
显式奖励模型直接基于预定义规则、启发式方法、人工注释来定义奖励函数。这种奖励结构包含来自人类或经过训练以接近人类判断(例如,排名或成对比较)的专用AI模块的直接数字信号。这种方法可以生成精确的奖励估算,但规模化时可能耗时或成本高昂。其典型用例包括"红队"演习(其中专家评估毒性输出的严重程度),或领域专家任务(其中正确性必须由主题专家验证)。
3.1.2 Implicit Reward Modeling
隐性奖励模型通过观察到的行为、互动或偏好信号间接推断奖励,利用机器学习技术来揭示潜在的奖励结构。它从用户互动指标(例如点赞数、接受率、点击模式、会话参与时间)中获取信号。虽然可以以最小的开销积累海量数据集,但这种方法可能以牺牲内容质量或真实性为代价来利用参与启发法的行为。
为文本生成任务定义奖励函数是一个不适定问题 ill-posed problem。现有的 LLM 中的强化学习方法要么关注生成过程的结果(结果奖励建模),要么关注生成过程的结果(过程奖励建模),以此来塑造 LLM 的行为。下文将解释这两种奖励建模范式。
3.1.3 Outcome Reward Modeling
衡量最终结果(例如,最终答案是否符合事实或是否解决了用户的疑问)。该模型易于实现,但可能无法深入了解结论的得出过程。在短响应任务中很常见,因为用户主要关注的是最终语句的正确性或简洁性;对于长响应任务,基于结果的奖励可能会导致信用分配问题,即哪些特定的操作或状态会导致特定的奖励结果。
3.1.4 Process Reward Modeling
在推理的中间步骤分配反馈,以激励连贯、逻辑一致、结构良好的CoT。这种方法对于涉及数学推导、法律论证、代码调试等任务尤其有用。在这些任务中,通往答案的路径与最终的陈述同样重要,各个步骤中分配的奖励可以提高透明度和稳健的逐步推理。然而,这需要更复杂的注释过程,例如,需要"gold"推理步骤或部分信用评分。过程奖励可以与结果奖励相结合,以形成强大的多阶段训练信号。
3.1.5 Iterative RL with Adaptive Reward Models
自适应奖励模型是一种训练方法,旨在通过迭代改进奖励模型和策略模型来持续提升 LLM 的性能。这种方法解决了 reward hacking 和奖励模型漂移的挑战,当大规模 RL 训练期间奖励模型与预期目标不一致时,可能会发生这些问题。RL 过程分为多个迭代,其中模型以循环方式进行训练。每次迭代后,奖励模型都会根据最新的模型行为和人类反馈进行更新。奖励模型并非静态的,而是会随着时间的推移而发展,以更好地适应人类的偏好和任务要求。这种自适应性可确保奖励信号在模型改进时保持准确性和相关性。重复迭代过程,直到模型性能达到稳定状态或达到预期基准。奖励模型和策略模型共同演进,每次迭代都会使它们更接近最佳匹配。
3.2 Policy Optimization
一旦训练出一个能够捕捉人类偏好的奖励模型 R θ ( x , y ) R_{\theta}(x,y) Rθ(x,y),就可以将其集成到强化学习框架中以优化策略 π θ \pi_{\theta} πθ。本质上用 R θ ( x , y ) R_{\theta}(x,y) Rθ(x,y) 替换/增强 环境的原生奖励信号,使agent专注于针对给定查询 x x x 生成人类偏好的响应 y y y。在典型的 RL 符号中:
- 语言建模中每个状态 s s s 都可以解释为下一个token的部分对话或部分生成过程;
- 每个动作 a a a 都是要生成的下一个token或文本chunk;
- 策略 π ϕ ( a ∣ s ) \pi_{\phi}(a|s) πϕ(a∣s) 是下一个token的条件分布,由 ϕ \phi ϕ 参数化;
目标是找到在 R θ R_{\theta} Rθ 条件下最大化预期奖励的 ϕ \phi ϕ,设 x x x 为用户查询, y ∼ π θ ( ⋅ ∣ x ) y\sim\pi_{\theta}(\cdot|x) y∼πθ(⋅∣x) 为生成的响应,求解:
max ϕ E x ∼ X E y ∼ π ϕ ( ⋅ ∣ x ) \[ R θ ( x , y ) ] \max_{\phi}E_{x\sim X}E_{y\\sim\\pi_{\\phi}(\\cdot\|x)}\[R_{\\theta}(x,y)] ϕmaxEx∼XEy∼πϕ(⋅∣x)\[Rθ(x,y)]
平均而言对于从策略 π θ \pi_{\theta} πθ 中得出的用户查询 x x x 和响应 y y y,希望奖励模型的得分 R θ ( x , y ) R_{\theta}(x,y) Rθ(x,y)尽可能高。
Policy Gradient and Advantage
现代算法(例如 PPO、GRPO、TRPO)依赖于策略梯度。Fig.5 对这些主要的强化学习框架进行了结构化比较。每个框架都建立在不同的策略学习、参考建模、奖励计算原则之上。优势函数 A ( s , a ) A(s,a) A(s,a) 量化了动作 a a a 比基线预期回报 V ( s ) V(s) V(s) 好多少。从高层次上讲,更新策略 π ϕ \pi_{\phi} πϕ 使得对于具有正优势的动作 a a a 的 π θ ( a ∣ s ) \pi_{\theta}(a|s) πθ(a∣s) 增加,对于具有负优势的动作 π θ ( a ∣ s ) \pi_{\theta}(a|s) πθ(a∣s) 则减少。 t t t 时刻的优势 A t A_{t} At 可以写成:
A t = Q ( s t , a t ) − V ( s t ) A_{t}=Q(s_{t},a_{t})-V(s_{t}) At=Q(st,at)−V(st)
其中 Q ( s t , a t ) Q(s_{t},a_{t}) Q(st,at) 是从 s t s_{t} st 开始采取行动 a t a_{t} at 时的预期未来回报(未来奖励的总和,包括 R θ R_{\theta} Rθ)。当使用奖励模型 R θ R_{\theta} Rθ 时:
- 将 R θ ( x , y ) R_{\theta}(x,y) Rθ(x,y) 解释为对生成的响应 y y y 的直接或最终奖励;
- 策略的未来回报将影响后续token被 R θ R_{\theta} Rθ 给予正评分的可能性;
- 优势函数仍然可以捕捉特定生成步骤与基线性能 V ( s t ) V(s_{t}) V(st) 相比的优劣程度;

3.2.1 Odds Ratio Preference Optimization (ORPO)
最简单的方法是 ORPO,它++直接根据成对的人类偏好来优化策略++。ORPO 不是先学习一个单独的奖励模型,然后再运行标准的强化学习,而是根据人类标签更新策略以增加偏好响应,相对于非偏好响应的可能性。其关键思想是观察比值比:
π θ ( y j , x ) π θ ( y k , x ) \frac{\pi_{\theta}(y_{j},x)}{\pi_{\theta}(y_{k},x)} πθ(yk,x)πθ(yj,x)
其中 y j y_{j} yj 是针对给定查询 x x x 的首选响应, y k y_{k} yk 是次首选响应。
Pairwise Preference Probability
在许多直接偏好方法(如Bradley--Terry类)中:
P ϕ ( y j ≻ y k ∣ x ) = σ ( ln π ϕ ( y j ∣ x ) π ϕ ( y k ∣ x ) ) = 1 1 + e x p ( ln π θ ( y k ∣ x ) π ϕ ( y j ∣ x ) ) P_{\phi}(y_{j}\succ y_{k}|x)=\sigma\left(\ln{\frac{\pi_{\phi}(y_{j}|x)}{\pi_{\phi}(y_{k}|x)}}\right)=\frac{1}{1+exp\left(\ln{\frac{\pi_{\theta}(y_{k}|x)}{\pi_{\phi}(y_{j}|x)}}\right)} Pϕ(yj≻yk∣x)=σ(lnπϕ(yk∣x)πϕ(yj∣x))=1+exp(lnπϕ(yj∣x)πθ(yk∣x))1
其中 σ ( ⋅ ) \sigma(\cdot) σ(⋅) 是 sigmoid logitic 函数。如果策略 π θ \pi_{\theta} πθ 赋予 y j y_{j} yj 的概率高于 y k y_{k} yk,则概率 π ϕ ( y j ∣ x ) π ϕ ( y k ∣ x ) \frac{\pi_{\phi}(y_{j}|x)}{\pi_{\phi}(y_{k}|x)} πϕ(yk∣x)πϕ(yj∣x) 超过 1,使得 y j y_{j} yj 更有可能成为模型的优选结果。
在 ORPO 中,通常对数据集中的所有对 { ( x , y j , ≻ y k ) } \{(x,y_{j},\succ y_{k})\} {(x,yj,≻yk)} 定义一个负对数似然损失:
L O R P O ( ϕ ) = − ∑ ( x , y j ≻ y k ) ∈ D log ( P ϕ ( y j ≻ y k ∣ x ) ) L_{ORPO}(\phi)=-\sum_{(x,y_{j}\succ y_{k})\in D}\log{\left(P_{\phi}(y_{j}\succ y_{k}|x)\right)} LORPO(ϕ)=−(x,yj≻yk)∈D∑log(Pϕ(yj≻yk∣x))
代入 logistic 形式可得:
L O R P O ( ϕ ) = − ∑ ( x , y j ≻ y k ) ∈ D log ( π ϕ ( y j ∣ x ) π ϕ ( y j ∣ x ) + π ϕ ( y k ∣ x ) ) L_{ORPO}(\phi)=-\sum_{(x,y_{j}\succ y_{k})\in D}\log{\left(\frac{\pi_{\phi}(y_{j}|x)}{\pi_{\phi}(y_{j}|x)+\pi_{\phi}(y_{k}|x)}\right)} LORPO(ϕ)=−(x,yj≻yk)∈D∑log(πϕ(yj∣x)+πϕ(yk∣x)πϕ(yj∣x))
这也可以解释为在每次成对比较中最大化正确(首选)标签的对数优势比。
Interpretation via Odds Ratios
通过调教每个偏好标签 ( y j ≻ y k ) (y_{j}\succ y_{k}) (yj≻yk) 作为 odds π ϕ ( y j ∣ x ) π ϕ ( y k ∣ x ) \frac{\pi_{\phi}(y_{j}|x)}{\pi_{\phi}(y_{k}|x)} πϕ(yk∣x)πϕ(yj∣x)的约束,ORPO 推动策略增加其在 y j y_{j} yj 上的概率,同时在 y k y_{k} yk 上减小。从对数空间来看:
ln π ϕ ( y j ∣ x ) π ϕ ( y k ∣ x ) \ln{\frac{\pi_{\phi}(y_{j}|x)}{\pi_{\phi}(y_{k}|x)}} lnπϕ(yk∣x)πϕ(yj∣x)
该值越高,表示选择 y j y_{j} yj 而非 y k y_{k} yk 的可能性越大。因此,最小化 L O R P O ( ϕ ) L_{ORPO(\phi)} LORPO(ϕ) 可以使 π ϕ \pi_{\phi} πϕ 与人类标记的偏好保持一致。

3.2.2 Proximal Policy Optimization (PPO) in LLMs
一种流行的策略优化方法是 PPO,这是一种旨在++使 LLM 与人工反馈保持一致的策略++ 。给定一个由 θ \theta θ 参数化的策略 π θ \pi_{\theta} πθ 和一个奖励函数 R R R,PPO 通过优化一个在探索和稳定性之间取得平衡的裁剪目标来更新策略 。如果 r t ( θ ) = π θ ( a t ∣ s t ) π θ r e f ( a t ∣ s t ) r_{t}(\theta)=\frac{\pi_{\theta}(a_{t}|s_{t})}{\pi_{\theta_{ref}}(a_{t}|s_{t})} rt(θ)=πθref(at∣st)πθ(at∣st) 表示在状态 s t s_{t} st 下某个动作 a t a_{t} at 的概率比,则裁剪后的 PPO 目标为:
L P P O ( θ ) = E t min ( r t ( θ ) , A t , clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A t ) L^{PPO}(\theta)=E_{t}\left\\min{(r_{t}(\\theta),A_{t},\\text{clip}(r_{t}(\\theta),1-\\epsilon,1+\\epsilon)A_{t})}\\right LPPO(θ)=Etmin(rt(θ),At,clip(rt(θ),1−ϵ,1+ϵ)At)
A t A_{t} At 是优势函数的估计量, ϵ \epsilon ϵ 是控制与先前策略允许偏差的超参数。 A t A_{t} At 使用基于奖励和学习到的价值函数的广义优势估计 (GAE) 计算得出。PPO 的裁剪目标限制了更新后的策略分布与原始策略的偏离程度。这种适度调整可以避免语言生成中出现灾难性的变化,并保持训练的稳定性。
Policy Optimization with KL Penalty
在使用 PPO 进行强化学习微调的过程中,策略 π \pi π 会进行优化以最大化奖励,同时保持接近基础模型 ρ \rho ρ。修改后的奖励函数包含一个 KL 散度惩罚:
J ( π ) = E ( x , y ) ∼ D r ( x , y ) − β K L ( π ( ⋅ ∣ x ) ∣ ∣ ρ ( ⋅ ∣ x ) ) J(\pi)=E_{(x,y)\sim D}\leftr(x,y)-\\beta KL(\\pi(\\cdot\|x)\|\|\\rho(\\cdot\|x))\\right J(π)=E(x,y)∼Dr(x,y)−βKL(π(⋅∣x)∣∣ρ(⋅∣x))
其中 β \beta β 控制惩罚强度。KL 项 K L ( π ∣ ∣ ρ ) KL(\pi||\rho) KL(π∣∣ρ) 可防止对agent奖励 r ( x , y ) r(x,y) r(x,y) 过度优化(即reward hacking)。

3.2.3 Reinforcement Learning from Human Feedback (RLHF)
RLHF 通过直接的人类偏好信号来改进 LLM,使其更符合人类的期望。该过程涉及三个主要步骤:
- 使用高质量标记数据在预训练模型上执行 SFT,以建立强大的语言和事实能力;
- 使用人工注释的生成响应排名来训练奖励函数 R,使其能够预测偏好并提供标量奖励信号;
- 在 RLHF 流程中采用 PPO,通过使用人类提供的偏好分数(或排名)来塑造 R,从而指导策略更新;
这确保了模型优先考虑与人类偏好行为一致的输出。在嘈杂或部分奖励信号条件下的稳健性能使 PPO 非常适合文本生成任务,这种任务中大动作空间和细微的奖励定义很常见。
3.2.4 Reinforcement Learning from AI Feedback (RLAIF)
RLAIF 是 RLHF 的替代方案,用AI生成的反馈取代了人工注释。RLAIF 不依赖于人工标记的偏好,而是采用一个二级高性能语言模型来生成偏好标签,然后将其用于训练奖励模型。该奖励模型指导基于强化学习的目标模型微调。RLAIF 无需人工注释,从而减少了数据收集所需的成本和时间,能够在保持高性能和模型对齐的同时,无需大量人工干预即可实现大规模模型对齐。实证研究表明,RLAIF 是 RLHF 的一种可扩展且高效的替代方案,使其成为强化学习驱动的语言模型优化的一个有前景的方向。

3.2.5 Trust Region Policy Optimization (TRPO)
TRPO 是另一种广泛使用的策略优化方法,它先于 PPO 提出,并与其有着相同的根本目标:提高强化学习更新的稳定性。TRPO 优化策略更新,同时确保其保持在受约束的信任区域内,该信任区域以 KL 散度衡量。
TRPO 不使用像 PPO 这样的修剪目标,而是通过解决以下优化问题对策略更新实施硬约束:
max θ E t π θ ( a t ∣ s t ) π θ ( a t ∣ s t ) A t \max_{\theta} E_{t}\left\\frac{\\pi_{\\theta}(a_{t}\|s_{t})}{\\pi_{\\theta}(a_{t}\|s_{t})}A_{t}\\right θmaxEtπθ(at∣st)πθ(at∣st)At
满足以下约束:
E t D K L ( π θ o l d ( ⋅ ∣ s t ) ∣ ∣ π θ ( ⋅ ∣ s t ) ) ≤ δ E_{t}D_{KL}(\\pi_{\\theta_{old}}(\\cdot\|s_{t})\|\|\\pi_{\\theta}(\\cdot\|s_{t}))\leq\delta EtDKL(πθold(⋅∣st)∣∣πθ(⋅∣st))≤δ
其中 δ \delta δ是一个超参数,控制新策略与旧策略的差异程度。
与使用裁剪来近似此约束的 PPO 不同,TRPO 直接求解受约束的优化问题,确保每次更新不会在策略空间中移动过远。然而,解决此受约束问题需要计算成本高昂的二阶优化技术,例如共轭梯度法,这使得 TRPO 对于 LLM 等大规模模型效率较低。在实践中,PPO 因其简单易行、易于实现以及在 RLHF 等大规模应用中具有相当的性能而更受青睐。然而,TRPO 仍然是深度强化学习中稳定策略优化的重要理论基础。
3.2.6 Direct Preference Optimization (DPO)
DPO 是最近提出的一种从人类偏好数据中训练 LLM 的方法,无需借助传统的 RL 循环(例如在带有 PPO 的 RLHF 中)。DPO 不是学习单独的奖励函数更新策略梯度,而是++直接将人类偏好信号集成到模型的训练目标中++ 。因此,DPO 不是采用上述 PPO 目标,而是构建一个目标直接提高所选(偏好)响应的概率 y + y^{+} y+,同时降低次偏好响应的概率 y − y^{-} y−,所有这些都在一个对数似然框架内完成。DPO 损失不是用 clip 来限制策略变化,而是使用"winning"和"losing"响应的对数概率之差,在更新的参数中明确地编码了用户的偏好。
L D P O ( θ ) = E ( ( x , y + ) , y − ) ∼ D t r a i n σ ( β log π θ ( y + ∣ x ) π r e f ( y − ∣ x ) ) − β log π θ ( y − ∣ x ) π r e f ( y − ∣ x ) L^{DPO}(\theta)=E_{((x,y^{+}),y^{-})\sim D_{train}}\left \\sigma\\left( \\beta\\log{\\frac{\\pi_{\\theta}(y\^{+}\|x)}{\\pi_{ref}(y\^{-}\|x)}} \\right)- \\beta\\log{\\frac{\\pi_{\\theta}(y\^{-}\|x)}{\\pi_{ref}(y\^{-}\|x)}} \\right LDPO(θ)=E((x,y+),y−)∼Dtrainσ(βlogπref(y−∣x)πθ(y+∣x))−βlogπref(y−∣x)πθ(y−∣x)
π θ \pi_{\theta} πθ 是可学习策略; π r e f \pi_{ref} πref 是参考策略,通常是经过SFT训练好的模型; σ ( ⋅ ) \sigma(\cdot) σ(⋅) 是sigmoid函数; β \beta β是缩放参数; D t r a i n D_{train} Dtrain是三元组 ( x , y + , y − ) (x,y^{+},y^{-}) (x,y+,y−)的数据集,其中 y + y^{+} y+比 y − y^{-} y−更优;
关键在于 LLM 可以被视为一个"隐藏奖励模型":可以重新参数化偏好数据,使模型自身的对数概率反映出一个响应相对于另一个响应的偏好程度。通过直接调整偏好程度较高的响应相对于偏好程度较低的响应的对数似然,DPO 规避了基于强化学习方法的许多复杂性(例如,优势函数或显式裁剪)。

Perplexity Filtering for Out-of-Distribution Data
为了确保DPO训练数据符合分布(与 ρ \rho ρ对齐),使用困惑度 perplexity 对响应进行过滤。响应 y = ( y 1 , y 2 , ... , y T ) y=(y_{1},y_{2},\dots,y_{T}) y=(y1,y2,...,yT)的困惑度定义为:
P P ( y ) = e x p ( − 1 T ∑ i = 1 T log P ρ ( y i ∣ y < i ) ) PP(y)=exp\left(-\frac{1}{T}\sum^{T}{i=1}\log{P{\rho}(y_{i}|y_{<i})}\right) PP(y)=exp(−T1i=1∑TlogPρ(yi∣y<i))
其中 y i y_{i} yi 是第 i i i 个 token,只有困惑度低于阈值的响应(如 ρ \rho ρ 生成的响应的第 95 个百分位数)才会被保留。

3.2.7 Offline Reasoning Optimization (OREO)
OREO 是一种离线强化学习方法,旨在++通过优化soft Bellman 软贝尔曼方程来增强 LLM 的多步推理能力++ 。与依赖成对偏好数据的 DPO 不同,OREO 使用基于最终结果(例如,推理链的正确性)的稀疏奖励,并联合训练策略模型 π θ \pi_{\theta} πθ 和价值函数 V ϕ V_{\phi} Vϕ,以实现细粒度的信用分配。其核心目标是最小化软贝尔曼方程中的不一致性:
V ϕ ( s t ) − V ϕ ( s t + 1 ) = r ( s t , a t ) − β log π θ ( a t ∣ s t ) π r e f ( a t ∣ s t ) V_{\phi}(s_{t})-V_{\phi}(s_{t+1})=r(s_{t},a_{t})-\beta\log{\frac{\pi_{\theta}(a_{t}|s_{t})}{\pi_{ref}(a_{t}|s_{t})}} Vϕ(st)−Vϕ(st+1)=r(st,at)−βlogπref(at∣st)πθ(at∣st)
其中 s t + 1 = f ( s t , a t ) s_{t+1}=f(s_{t},a_{t}) st+1=f(st,at)是下一个状态; r r r是稀疏奖励; β \beta β 控制KL正则化。策略损失和价值损失分别为:
L V ( ϕ ) = 1 T ∑ t = 0 T − 1 ( V ϕ ( s t ) − R t + β ∑ i ≥ t log π θ ( a i ∣ s i ) π r e f ( a t ∣ s t ) ) L π ( θ ) = 1 T ∑ t = 0 T − 1 ( V ϕ ( s t ) − R t + β log π θ ( a i ∣ s i ) π r e f ( a t ∣ s t ) ) 2 + α L r e g \begin{align} L_{V}(\phi) &=\frac{1}{T}\sum^{T-1}{t=0}{\left(V{\phi}(s_{t})-R_{t}+\beta\sum_{i\geq t}\log{\frac{\pi_{\theta}(a_{i}|s_{i})}{\pi_{ref}(a_{t}|s_{t})}}\right)} \nonumber\\ L_{\pi}(\theta) &=\frac{1}{T}\sum^{T-1}{t=0}{\left(V{\phi}(s_{t})-R_{t}+\beta\log{\frac{\pi_{\theta}(a_{i}|s_{i})}{\pi_{ref}(a_{t}|s_{t})}}\right)}^{2}+\alpha L_{reg} \nonumber \end{align} LV(ϕ)Lπ(θ)=T1t=0∑T−1(Vϕ(st)−Rt+βi≥t∑logπref(at∣st)πθ(ai∣si))=T1t=0∑T−1(Vϕ(st)−Rt+βlogπref(at∣st)πθ(ai∣si))2+αLreg
其中 L r e g L_{reg} Lreg是偏离 π r e f \pi_{ref} πref的惩罚,是 α \alpha α正则化平衡;

3.2.8 Group Relative Policy Optimization (GRPO)
GRPO 通过++消除对单独价值函数的需求简化了 PPO 框架++ ,根据同一问题的多个采样输出的平均奖励来估计基线。GRPO 的主要贡献在于其消除了对单独价值模型的需求,而是根据一组采样的 LLM 输出来估计基线奖励。这显著降低了内存占用,并增强了策略学习的稳定性。该方法也与奖励模型的训练方式相一致,即通过比较不同的 LLM 生成的输出,而不是预测绝对值。
对于每个问题 q q q GRPO 从旧策略 π θ o l d \pi_{\theta}^{old} πθold 中采样一组输出 ( o 1 , o 2 , . . . , o G ) (o_1,o_2,...,o_G) (o1,o2,...,oG),奖励模型用于对组中的每个输出进行评分,得到奖励 ( r 1 , r 2 , ... , r G ) (r_{1},r_{2},\dots,r_{G}) (r1,r2,...,rG)。奖励通过减去组平均值并除以标准差进行归一化:
r ˉ i = r i − mean ( r ) std ( r ) \bar{r}{i}=\frac{r{i}-\text{mean}(r)}{\text{std}(r)} rˉi=std(r)ri−mean(r)
输出中每个token的优势 A ^ i , t \hat{A}{i,t} A^i,t 被设置为标准化奖励 r ˉ i \bar{r}{i} rˉi。
GRPO首先从从问题 q ∼ P ( Q ) q\sim P(Q) q∼P(Q)中采样,得到 π θ o l d ( O ∣ q ) \pi^{old}{\theta}(O|q) πθold(O∣q) 的输出 { o i } i = 1 G \{o{i}\}^{G}_{i=1} {oi}i=1G;定义上一个输出为:
J ( o i , θ , q ) = 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ min { r r a t i o , i , t , A ^ i , t , clip ( r r a t i o , i , t , 1 − ϵ , 1 + ϵ ) A ^ i , t } − β D K L π θ ∣ ∣ π r e f J(o_{i},\theta,q)=\frac{1}{|o_{i}|}\sum^{|o_{i}|}{t=1}{ \min{\{ r{ratio,i,t},\hat{A}{i,t},\text{clip}(r{ratio,i,t},1-\epsilon,1+\epsilon)\hat{A}{i,t} } \}-\beta D{KL}\\pi_{\\theta}\|\|\\pi_{ref} } J(oi,θ,q)=∣oi∣1t=1∑∣oi∣min{rratio,i,t,A^i,t,clip(rratio,i,t,1−ϵ,1+ϵ)A^i,t}−βDKLπθ∣∣πref
然后GROP的目标变为:
J G R P O ( θ ) = E q ∼ P ( Q ) 1 G ∑ i = 1 G J ( o i , θ , q ) J_{GRPO}(\theta)=E_{q\sim P(Q)}\left\\frac{1}{G}\\sum\^{G}_{i=1}{J(o_{i},\\theta,q)}\\right JGRPO(θ)=Eq∼P(Q)G1i=1∑GJ(oi,θ,q)
其中概率比定义为:
r r a t i o , i , t ≜ π θ ( o i , t ∣ q , o i < t ) π θ o l d ( o i , t ∣ q , o i < t ) r_{ratio,i,t}\triangleq \frac{\pi_{\theta}(o_{i,t} | q,o_{i<t})}{\pi^{old}{\theta}(o{i,t}|q,o_{i<t})} rratio,i,t≜πθold(oi,t∣q,oi<t)πθ(oi,t∣q,oi<t)
其中 ϵ \epsilon ϵ 是类似于 PPO 的裁剪超参数, β \beta β 调整 KL 散度惩罚,使新策略 π θ \pi_{\theta} πθ 不要过度偏离参考策略 π r e f \pi_{ref} πref,后者通常是初始的监督微调 (SFT) 模型。GRPO 可以应用于两种模式:结果监督Outcome Supervision 和过程监督Process Supervision。
Outcome Supervision
仅在每个输出结束时提供奖励。输出中所有 token 的优势 A i , t ^ \hat{A_{i,t}} Ai,t^ 被设置为归一化奖励 r ˉ i \bar{r}_{i} rˉi
r ˉ i = r i − mean ( r ) std ( r ) \bar{r}{i}=\frac{r{i}-\text{mean}(r)}{\text{std}(r)} rˉi=std(r)ri−mean(r)
Process Supervision
在每个推理步骤结束时提供奖励。每个 token 的优势 A i , t ^ \hat{A_{i,t}} Ai,t^ 计算为以下步骤中归一化奖励的总和,其中 index(j) 表示
A ^ i , t = ∑ index ( j ) ≥ t r ˉ i , index ( j ) \hat{A}{i,t}=\sum{\text{index}(j)\geq t}{\bar{r}_{i,\text{index}(j)}} A^i,t=index(j)≥t∑rˉi,index(j)
其中 index ( j ) \text{index}(j) index(j) 是第 j j j 步输出的末尾token索引;
GRPO 通过利用群体层面的优势,成为 DeepSeekR1 中经典 actor-critic 框架的有效替代方案,从而在不牺牲区分候选响应之间细粒度差异的能力的情况下降低训练成本。

3.2.9 Multi-Sample Comparison Optimization
多样本比较优化方法并非仅仅依赖于单对比较,而是同时比较多个响应,以促进多样性并减轻偏差。具体而言,给定查询 x x x 的一组响应 { y 1 , y 2 , ... , y n } \{y_{1},y_{2},\dots,y_{n}\} {y1,y2,...,yn},观察到排序 y 1 > y 2 > ⋯ > y n y_{1}>y_{2}>\dots>y_{n} y1>y2>⋯>yn 的概率由以下乘积决定:
P ( y 1 > y 2 ⋯ > y n ) = ∏ i e R ( x , y i ) ∑ j e R ( x , y j ) P(y_{1}>y_{2}\dots>y_{n})=\prod_{i}\frac{e^{R(x,y_{i})}}{\sum_{j}e^{R(x,y_{j})}} P(y1>y2⋯>yn)=i∏∑jeR(x,yj)eR(x,yi)
在这个公式中,每个响应 y i y_{i} yi 都在所有其他响应的背景下进行联合评估,确保比较不是孤立的成对事件,而是更广泛的排名框架的一部分,有助于捕捉更细微的偏好并减少潜在的偏见。
3.3 Pure RL Based LLM Refinement
Guo 等人的工作引入了两个主要模型:DeepSeek-R1-Zero 和 DeepSeek-R1。
- DeepSeek-R1-Zero:采用纯强化学习方法运作,不包括任何 SFT;
- DeepSeek-R1:结合冷启动数据并应用多阶段训练流程;
该方法包含几个步骤Fig.2:收集冷启动数据、进行强化学习训练、执行 SFT、使用蒸馏将知识迁移到较小的模型,以及解决语言混合和可读性等特定挑战。这种多阶段流程确保了模型的稳健性并符合人类的偏好,而蒸馏则能够高效部署较小的模型,且不会造成显著的性能损失。
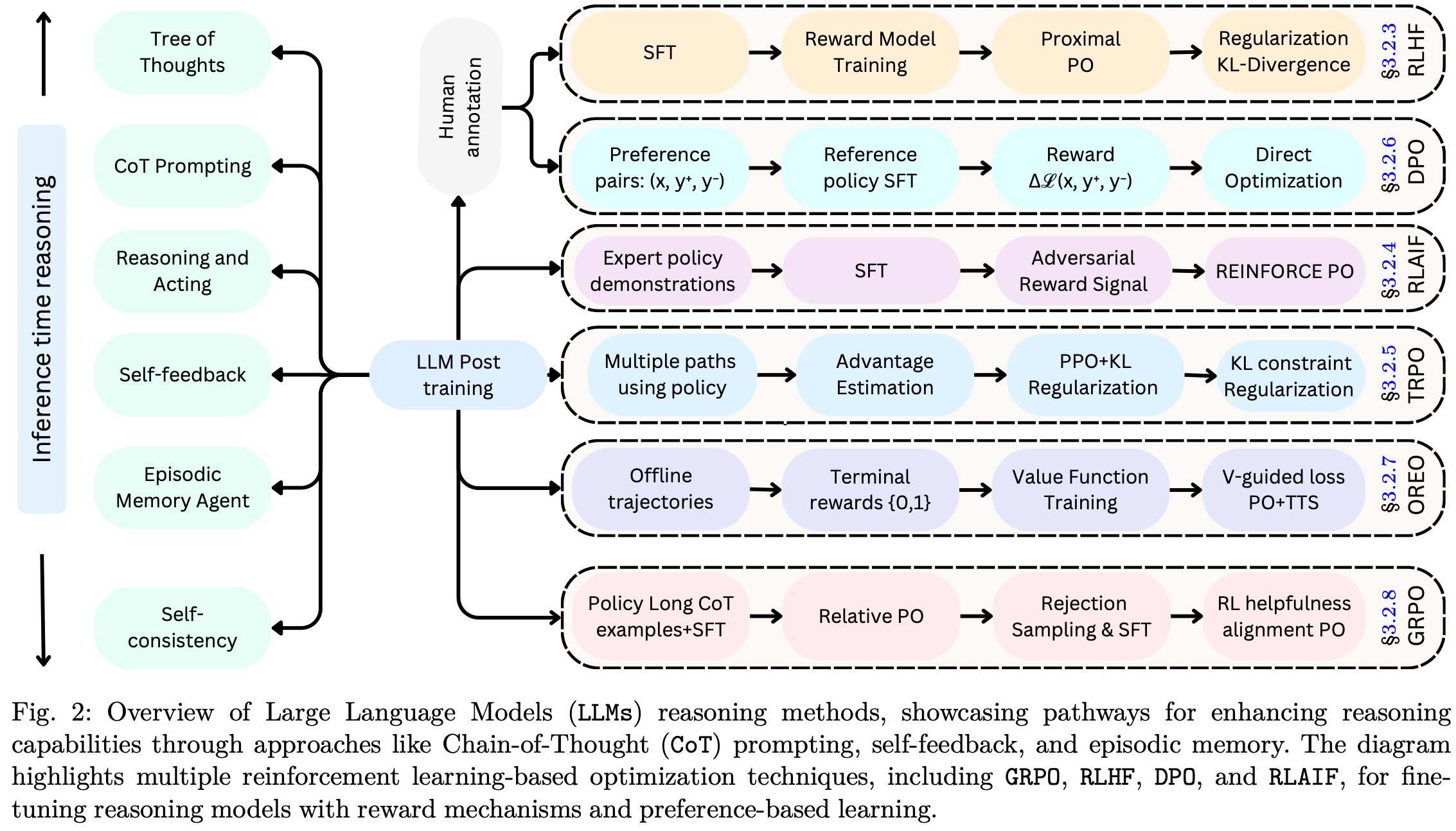
3.3.1 Cold-Start RL Phase
该过程始于冷启动 RL 阶段,在此阶段收集少量精选数据以微调初始或基础模型。在初步微调之后进行 RL(通常使用 GRPO 等算法)直到收敛。冷启动阶段对于在全面 RL 训练之前稳定模型至关重要,可防止纯 RL 驱动的更新可能引起的不稳定性。冷启动数据准备侧重于捕获人类可读的推理模式,以防止纯 RL 驱动的更新引起的不稳定性。此步骤生成具有一致 <reasoning_process> 和 <summary> 字段的 CoT 样式示例,通常涉及数千个精心挑选的样本。结构化的 CoT 格式和一致的字段可确保模型推理输出的清晰度和鲁棒性,从而减少错误并提高可解释性。

3.3.2 Rejection Sampling and Fine-tuning
该概念也应用于 WebGPT,一旦强化学习稳定下来就会采用拒绝采样机制生成高质量的响应,随后根据正确性、清晰度和其他质量指标进行筛选。这些过滤后的响应与其他数据集混合,以生成一个新的、更大的语料库,用于监督微调。拒绝采样确保只有高质量的输出才会用于进一步的训练,从而提高模型的整体性能和可靠性。在强化学习针对高风险推理任务收敛后,会使用拒绝采样来过滤大量生成的输出从而扩展训练集。这些新生成的推理示例(数量可能高达数十万)与现有的 SFT 数据混合,创建一个有一定规模的组合数据集(通常约为 80 万个样本)。拒绝采样和数据集扩展显著增强了模型对一般任务的覆盖率,同时保持了其推理能力。
3.3.3 Reasoning-Oriented RL
面向推理的强化学习利用了 GRPO,它++从当前策略中采样一组输出,并计算每个输出的奖励和优势++。奖励可以通过基于规则的检查来计算,例如,确保数学或代码任务中的解正确、强制使用结构化的 CoT 标签、惩罚不良的语言混合。GRPO 基于组的采样和奖励计算确保模型优先考虑高质量的结构化输出,从而增强其推理能力。
3.3.4 Second RL Stage for Human Alignment
第二个强化学习阶段通过引入额外的奖励信号和提示分布,进一步使模型与更广泛的人类偏好(例如,乐于助人、无害、创造力等)保持一致。第二个强化学习阶段确保模型与人类价值观保持一致,使其更加通用且具备情境感知能力。在此组合数据集上重新训练基础模型后,可以进行第二轮强化学习,使模型更贴近人类偏好(例如,乐于助人和无害)。此强化学习阶段对模型进行微调,使其更好地与人类价值观保持一致,确保输出不仅准确,而且符合情境。
3.3.5 Distillation for Smaller Models
蒸馏技术用于++将主模型的精炼能力迁移到较小的架构,从而在不牺牲太多性能的情况下实现更高效的部署++。它允许较小的模型继承高级推理能力,使其在具有挑战性的基准测试中具有竞争力,而无需承担全面强化学习训练的计算成本。蒸馏起着关键作用:表现最佳的模型 DeepSeek-R1 可以作为较小架构(例如 Qwen 或 Llama 系列,参数数量从 15 亿到 700 亿)的老师。这种迁移允许较小的模型继承高级推理能力,使其在具有挑战性的基准测试中具有竞争力,而无需承担全面强化学习训练的计算成本。
4. Supervised Finetuning in LLMs
如Fig.2 所示,微调是 LLM 训练后方案的基本组成部分。本节将总结不同类型的 LLM 微调机制。
4.1 Instruction Finetuning
在指令微调中,模型基于精心挑选的instruction(prompt)和response(completion)对进行训练。其主要目标是++引导 LLM 准确且有效地遵循用户提供的指令,无论其任务领域如何++。这通常需要编译涵盖多种任务类型(例如,摘要、问答、分类、创意写作)的大型、多样化的指令-响应数据集。T0、FLAN、Alpaca、Vicuna 和 Dolly 等模型展示了指令微调后的 LLM 如何凭借其增强的指令跟随能力,在零样本或少样本任务上超越基础模型。
4.2 Dialogue (Multi-turn) Finetuning
一些 LLM 会进行对话式微调以更好地处理多轮对话。与上面描述的指令微调不同,这里的++数据采用连续对话(多轮对话)的形式,而不是单个提示-响应对++。在这种方法中,训练数据由包含多个用户查询和系统响应的聊天记录组成,以确保模型学会在多轮对话中保持语境并生成连贯的回复。LaMDA和 ChatGPT 等模型凸显了对话微调后的 LLM 如何能够更具互动性和语境感知能力。虽然对话微调可能与指令微调重叠(因为许多指令都采用聊天格式),但专门的对话数据通常能带来更自然的多轮用户体验。
4.3 CoT Reasoning finetuning
思路链 (CoT) 推理微调旨在++教会模型逐步生成推理轨迹,而不仅仅是最终答案++ 。通过揭示中间的基本原理或想法,CoT 微调可以提高复杂任务(例如,数学应用题、多跳问答)的可解释性和准确性。在实践中,CoT 微调使用监督推理注释(通常由专家手工制定)来展示解决方案的展开方式。早期值得注意的研究包括思路链提示 和自洽性,最初将这一想法应用于提示;后续研究(例如,思路链提炼)将其应用于完全微调或师生范式。这些努力也扩展到了多模态领域,例如 LlaVA-CoT 和 LlamaV-o1,其中图像、QA、CoT 推理步骤用于 LLM 微调。
4.4 Domain-Specific (Specialized) Finetuning
LLM 需要在特定领域(例如生物医学、金融或法律)取得优异成绩时,会++使用领域特定的微调++。此时,使用一个包含领域相关文本和带标签示例的精选语料库来微调 LLM。例如,BioGPT 和 BiMediX 专注于生物医学文献,FinBERT 专注于金融文本,ClimatGPT 专注于气候和可持续性,CodeT5 专注于代码理解。这些领域的监督微调通常包括使用领域特定数据进行分类、检索或问答任务,以确保模型参数能够适应该领域的专业语言和概念。特定领域的微调也扩展到视觉语言模型,例如对遥感图像进行微调、对医学成像模式进行微调、对时空视频输入进行微调、用于图表理解。
4.5 Distillation-Based Finetuning
大型"教师"模型有时会用于生成带标签的数据或基本原理,然后由较小的"学生"模型对其进行微调,这通常称为知识蒸馏。在 LLM 的背景下,CoT 蒸馏就是一个例子,其中强大的教师 LLM 生成中间推理步骤,然后对学生 LLM 进行微调以重现最终答案和推理链。逐步蒸馏在最终答案的同时生成描述性基本原理,以便通过使用较小的数据集进行蒸馏来训练较小的模型。这种方法可以产生更轻量、更快的模型,即使在零样本或少样本任务中也能保留教师模型的大部分性能。
4.6 Preference and Alignment SFT
虽然 RLHF 并非纯监督学习,但始于一个监督偏好或对齐微调阶段。此阶段使用人工标记或人工排序的示例来训练模型,使其了解期望输出与不期望输出(例如,安全输出与有害输出)。通过对++显式偏好进行训练,模型会更加贴近用户价值观,从而减少有害或跑题的完成++。像 InstructGPT 这样的工作说明了在奖励模型训练和 RL 更新开始之前,监督偏好数据的重要性。
4.7 Efficient Finetuning
对 LLM 进行完全微调可能需要耗费大量的计算和内存,尤其是在模型规模增长到数百亿甚至数千亿个参数的情况下。为了应对这些挑战,参数高效微调 (PEFT) 技术引入了++一小组可训练的参数或可学习的提示,同时保持大部分模型权重不变++。LoRA、Prefix Tuning、Adapters 等方法通过在特定层中注入轻量级模块(或提示)来体现这一策略,从而显著减少了内存占用。
Fig.4 展示了这些技术如何融入更广泛的生态系统,该生态系统涉及 LLM 的系统级优化、数据管理、评估策略。PEFT 方法可以与量化和剪枝方法相结合,以进一步最大限度地降低内存使用量和计算开销,从而能够在较小的 GPU 甚至消费级硬件上进行微调。例如,QLoRA 将 4 位量化与低秩自适应统一起来,而 BitsAndBytes 提供了 8 位优化器,使 LLM 训练在受限环境中更加实用Table.2。
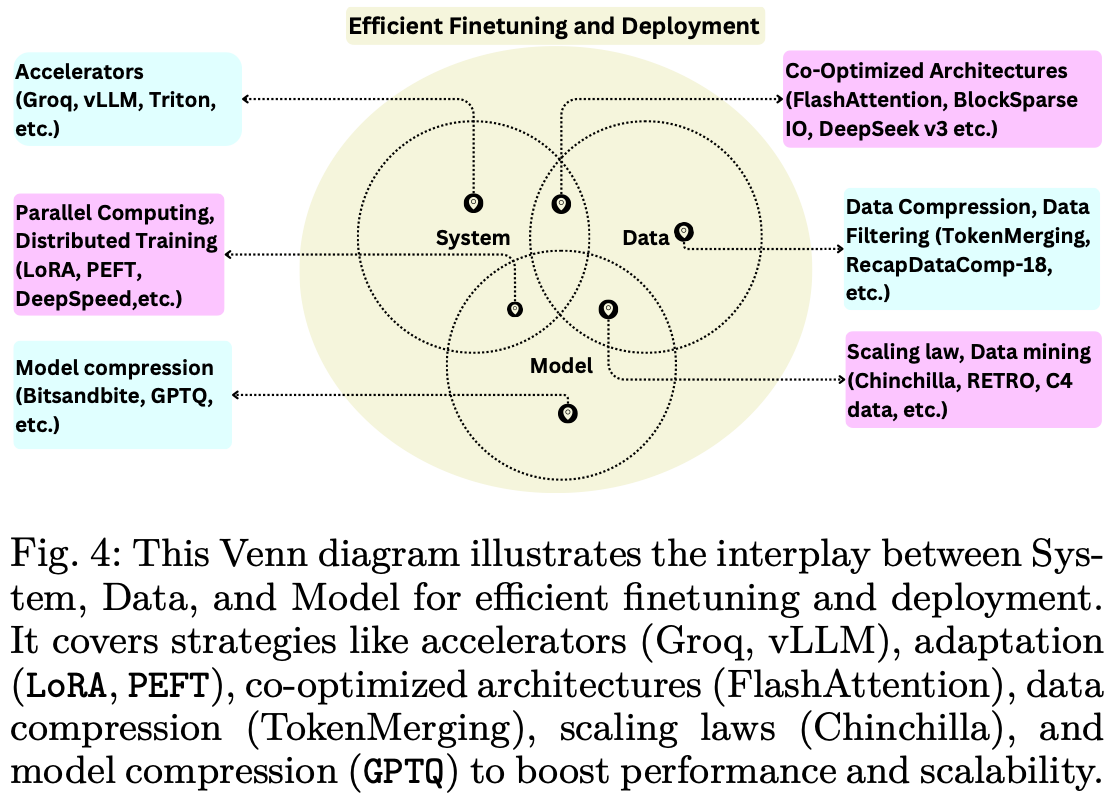
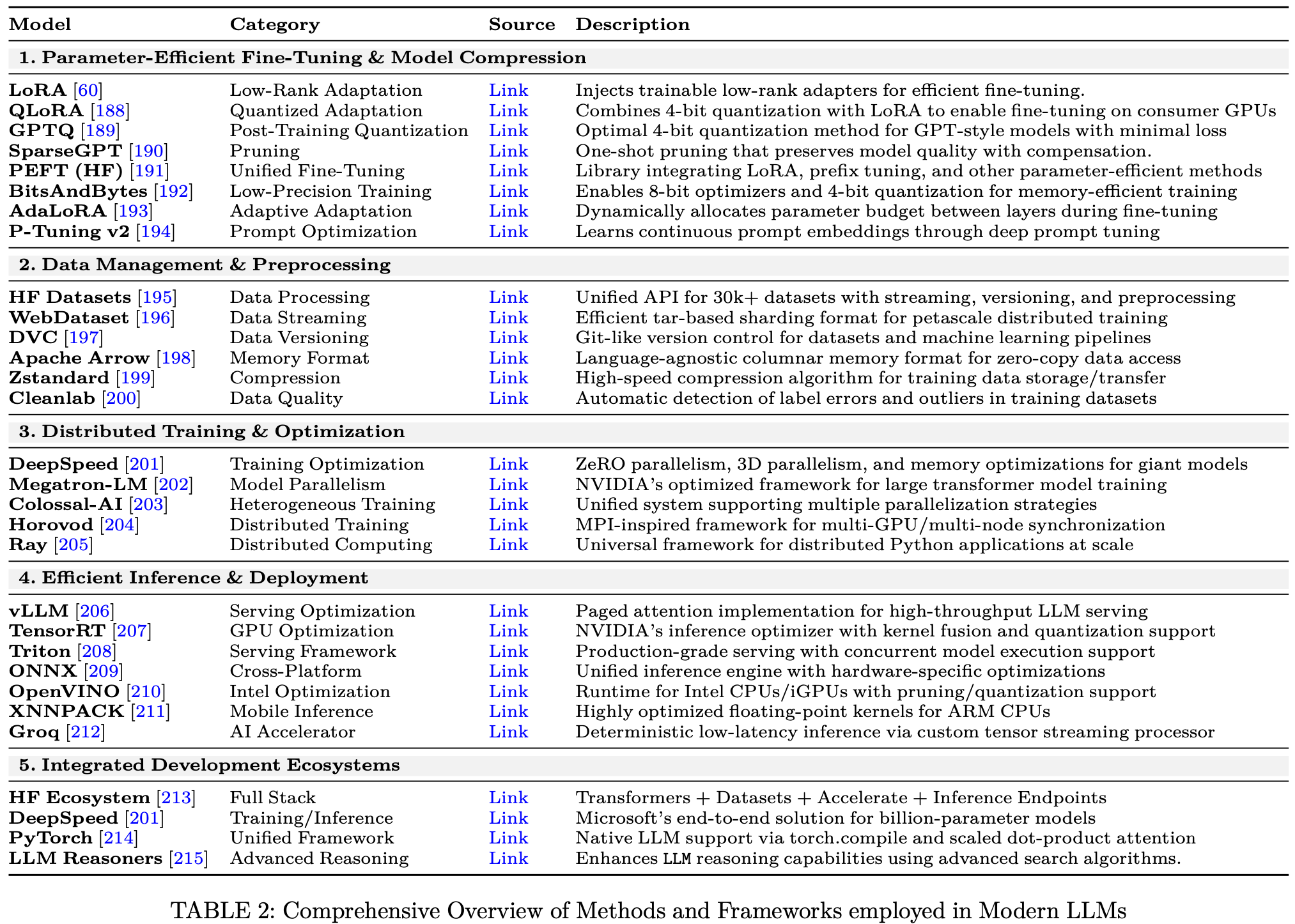
此外,这些 PEFT 方法仍然需要监督数据来指导适应过程,但可训练参数数量的减少使得使用领域内或特定任务的数据集变得更加可行。这对于数据可能有限或注释成本高昂的专业领域(例如医疗或软件开发)尤其有价值。Table.2 所示,PEFT (HF) 将多种方法(LoRA、前缀调整等)集成到一个库中,从而简化了在研究和生产环境中的部署。

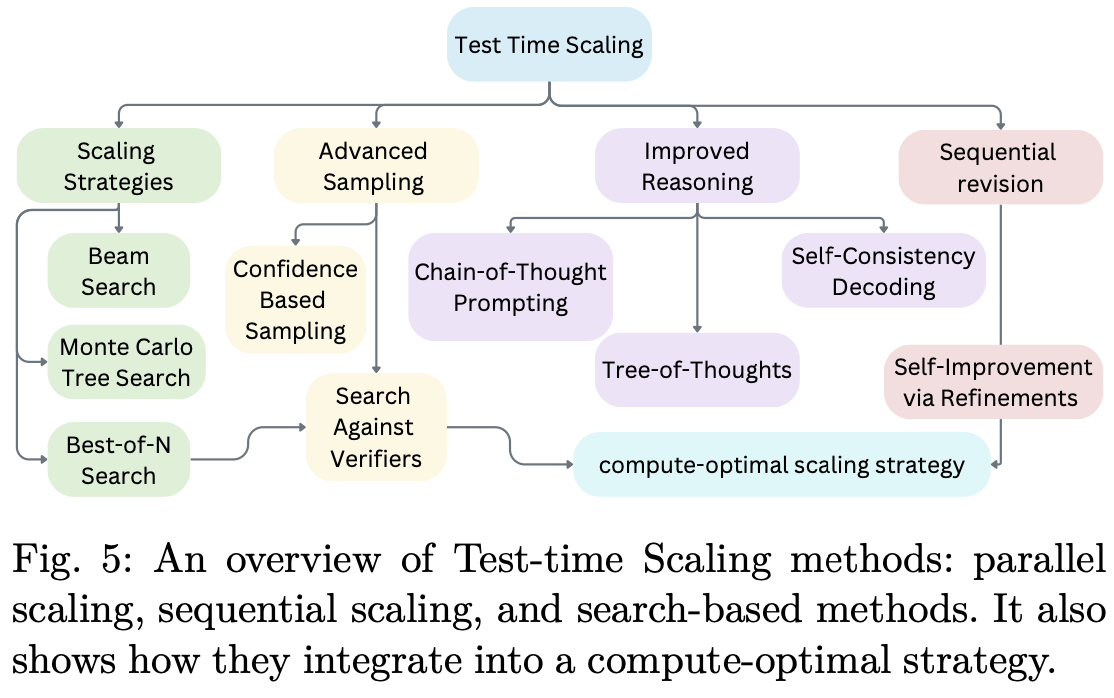
5 Test-time scaling Methods
强化学习会微调模型的策略,而测试时扩展 (TTS) 则通常无需模型更新即可在推理过程中增强推理能力。Fig.5 展示了 TTS 方法的分类,并根据其底层技术进行了分类。
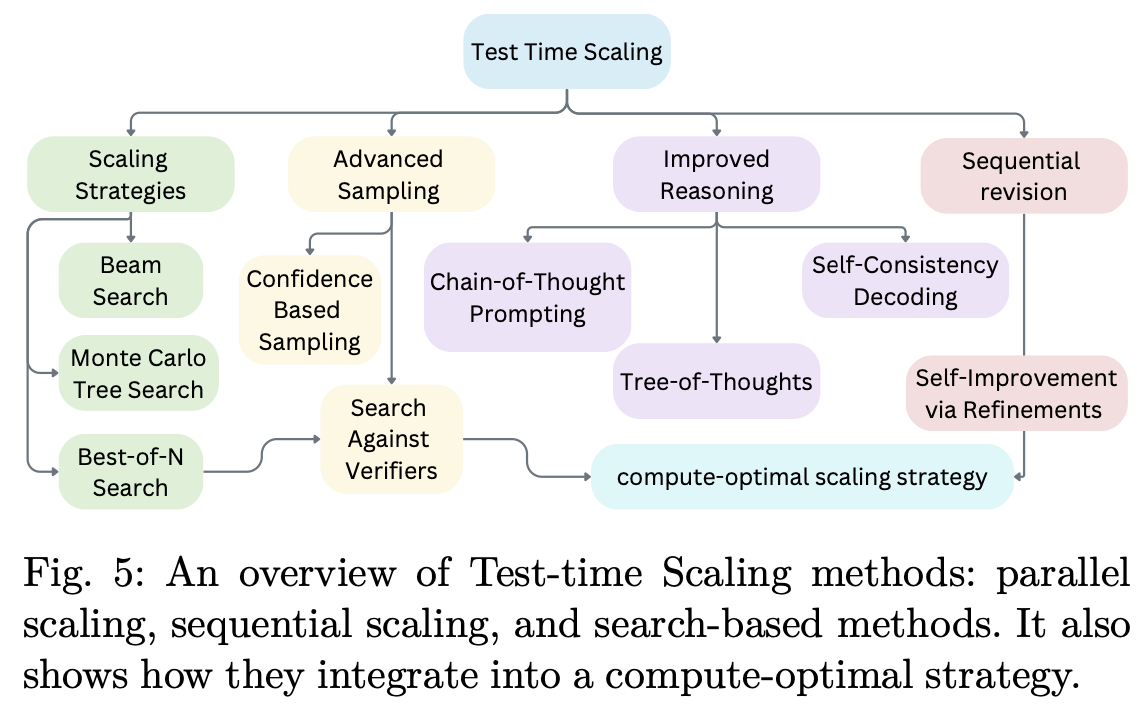
5.1 Beam Search
Beam Search 最初是在语音识别领域引入的,作为序列模型的解码策略而声名鹊起,后来被神经机器翻译和语音系统采用。随着 LLM 的流行,该算法已在许多文本生成任务中用于近似搜索。
集束搜索的概念类似于++剪枝广度优先搜索,其中每一步都保留前 N 个最高概率的部分序列("集束"),丢弃概率较低的路径++。通过限制集束宽度(N),它可以管理指数搜索空间,同时旨在找到接近最优的序列。这些集束在每个解码步骤中都会扩展,以找到多条可能的路径。在推理 LLM 中,这样的路径能够系统地并行探索多个推理链,并专注于最有希望的推理链,确保了高似然推理步骤得到考虑,与贪婪解码相比,这可以提高找到正确且连贯解决方案的几率。它传统上用于翻译、摘要和代码生成等任务,这些任务的目标是获得高度可能的正确序列。
虽然现代LLM通常倾向于使用随机采样(例如温度采样)来促进生成文本的多样性,但集束搜索 (beam search) 对于结构化推理问题仍然是一种有价值的技术。例如,思想树 (Tree-of-Thoughts) 框架允许插入不同的搜索算法来探索可能的"思想"或推理步骤的树;通常使用集束搜索(集束宽度为 b)来在每个推理步骤中维护 b 个最有希望的状态。集束搜索用于系统地探索数学谜题和规划问题等任务的解决步骤,修剪不太有希望的推理分支,从而提高模型解决问题的准确性。当人们希望模型在模型学习到的分布下输出单个最可能的推理路径或答案时,集束搜索仍然是测试时推理的强大基准。
5.2 Best-of-N Search (Rejection Sampling)
N 个候选输出中最优 (BoN) 搜索会生成 N 个候选输出(通常通过抽样实现),然后根据选定的标准(例如,奖励模型或模型自身的似然估计)选出最佳输出。从概念上讲,这是拒绝抽样的一种应用:++抽取多个样本,并拒绝除评分最高的结果之外的所有结果++。与逐步扩展和剪枝部分假设的集束搜索不同,BoN 只是独立地对完整解决方案进行抽样,从而实现了更大的多样性,但计算成本也更高。集束搜索系统性地瞄准最可能的序列,而 BoN 则可能通过强力抽样捕获高质量但概率较低的解决方案。

在 LLM 推理过程中,BoN 用于增强正确性或对齐性,而无需重新训练模型。通过采样多个答案并选择最佳候选(例如,通过奖励模型或检查器),BoN 可以有效提高 QA 或代码生成等任务的准确性。BoN 易于理解和实现,并且几乎不受超参数影响,N 是推理过程中唯一可以调整的参数。在强化学习环境中,BoN 采样可以作为一种基线探索机制,即生成许多 rollout,根据学习到的奖励选择最佳结果,然后继续进行,尽管这会增加计算开销。OpenAI 的 WebGPT 使用 BoN 通过奖励模型选择最佳答案,从而获得了强大的 QA 性能。BoN 还可用作一种简单的对齐方法,与其他训练后技术(例如 RLHF 和 DPO)相比具有很强的竞争力。研究表明,在足够稳健的奖励模型指导下,BoN 可以接近或匹配 RLHF 的结果。诸如推测性拒绝之类的替代方案基于此思想,并利用更好的奖励模型来提高效率。研究还强调了如果用于 BoN 的agent奖励函数不完善,则可能存在奖励黑客攻击的问题;如果 N 参数过大,则可能存在不稳定性问题。

5.3 Compute-Optimal Scaling
计算最优扩展策略 (COS) 是一种动态方法,旨在在 LLM 的推理过程中高效分配计算资源,从而在不产生不必要开销的情况下优化准确率。该方法不是对所有输入应用统一的采样策略,而是++利用预言机难度(真实成功率)或模型预测的难度(例如,来自偏好排序模型的验证者得分),将提示分为五个难度级别(从易到难)。分类完成后,该策略会调整计算分配++:较容易的提示会进行顺序细化,模型会迭代细化其输出以提高正确性;而较难的提示会触发并行采样或集束搜索,探索多种响应变体,以增加找到正确解决方案的可能性。这种双重方法平衡了探索(针对具有挑战性的输入)和细化(针对接近正确的响应),确保每单位计算工作量获得最佳性能。该方法在保持同等性能的同时,计算资源占用比传统的 Best-of-N 采样降低了四倍。其关键之处在于,通过将计算策略与问题难度相匹配,它避免了在琐碎案例上浪费资源,同时确保了复杂任务的采样多样性。本质上充当了 LLM 推理的"智能恒温器",根据输入复杂度动态调整计算工作量,从而更高效、更经济地部署大规模语言模型。

5.4 Chain-of-thought prompting
CoT 提示会++引导 LLM 生成中间推理步骤,而不是直接跳到最终答案++。通过将问题分解为逻辑子步骤,CoT 能够挖掘模型执行多步推理的潜在能力,从而显著提升数学应用题、逻辑谜题和多跳问答等任务的性能。
Wei 等人证明了 CoT 在算术和逻辑任务上的有效性,相比直接提示其效果显著提升。Kojima 等人引入了零样本 CoT,表明即使添加"让我们一步一步思考"这样的简单短语,也能在足够大的模型中触发连贯的推理。后续研究(例如,Wang 等人)将 CoT 与基于采样的策略(自一致性)相结合,以获得更高的准确率。如 5.4 节所述,CoT 格式的数据也已用于 SFT,并被证明有助于重塑模型响应,使其更具循序渐进性。

5.5 Self-Consistency Decoding
自洽性是 Wang 等人提出的一种解码策略。它被提出作为思路链式提示中简单贪婪解码的替代方案。它建立在对一个问题采样多条不同推理路径的思想之上,并首次证明对这些路径进行边缘化可以显著提高算术和推理问题的准确率。换句话说,它++允许模型以多种方式思考,然后信任共识,从而提高许多推理场景下的正确率++。
自洽方法的工作原理是从模型中抽取一组不同的推理链(通过即时工程来鼓励不同的 CoT,并使用温度抽样 ),然后让模型为每个链输出一个最终答案。该方法不是信任单个链,而是选择在这些多条推理路径中最一致的答案,实际上是在边缘化潜在推理之后的多数票或最高概率答案。直觉是,如果一个复杂问题有一个唯一的正确答案,那么不同的有效推理路径应该收敛到同一个答案。通过汇集许多链的结果,模型可以"决定"哪个答案最受支持。在应用中,人们可能会为一个数学问题抽取 20 个 CoT,看看哪个最终答案出现最频繁;然后将该答案作为模型的输出。这种方法将一次性 CoT 过程变成了一个模型交叉验证其答案的集合。它对于推理多样性有帮助的算术和常识推理任务特别有用。

自一致性通常与其他方法结合使用:例如,对多个链进行采样,然后将验证器应用于最常见的答案。它的优势在于无需新的训练,只需额外采样,使其成为一种流行的测试时扩展策略,可以从LLM中获得更可靠的答案。它也启发了其他变体,例如,通用自一致性将原始想法(仅适用于对单个最终答案进行多数投票的情况)扩展到更通用的生成任务,例如摘要和开放式问答。
5.6 Tree-of-thoughts
ToT 框架推广了思路链方法,允许++模型分支成多个可能的思维序列,而不是遵循单一的线性链++ 。因此,它借鉴了受人类问题解决启发的经典人工智能搜索方法,将语言模型推理问题表述为树状搜索。思路树将中间推理步骤视为搜索树中的"节点",并使用语言模型从给定状态扩展可能的后续步骤(思路)。该模型不是对一条较长的推理路径进行采样,而是探索一个分支思路树,并可以执行前瞻和回溯。在每一步,LLM 可能会生成几个候选的后续思路,然后启发式函数或价值函数评估每个部分解状态。然后,搜索算法(例如深度优先、广度优先、束搜索)浏览这棵树,决定进一步探索哪些分支。这种方法允许系统地探索不同的推理策略:如果一条路径走到死胡同,模型可以回到先前的状态并尝试不同的分支(这与专注于一条推理路径的标准推理理论不同)。实际上,推理理论是一个迭代的提示过程,模型会生成想法、评估想法并改进其方法,模仿人类如何在脑海中规划出解决问题的各种方法。
ToT 对于诸如谜题、规划任务或游戏等需要多步骤和策略探索的复杂问题尤其有用,并且通过系统地搜索解空间,其性能优于更简单的 CoT 方法。它提供了一个灵活的框架------人们可以根据任务插入各种生成策略(例如,抽样与提示)和搜索算法(BFS、DFS、A*、MCTS)。尽管计算量更大,但 ToT 表明,分配额外的"思考时间"(计算)来探索替代方案可以显著提高推理和规划性能。它催生了旨在改进或利用它来实现更好推理的后续研究,例如,多agent系统已与 ToT 相结合:不同的 LLM agent并行生成想法,验证agent修剪不正确的分支,从而比单agent ToT 提高准确性。

5.7 Graph of Thoughts
思维图谱 (GoT) 框架扩展了思维图谱 (ToT),++通过基于图的结构(而非严格的层次树)实现更灵活、更高效的推理过程++。两种方法的思维表示有所不同:在思维图谱 (ToT) 中,推理的每一步都被构建为树中具有固定父子关系的节点;而 GoT 将思维表示为图中的节点,从而实现了更具适应性的依赖关系和互连。
在思维扩展策略方面,ToT 遵循传统方法,即每一步生成多个思维候选,使用基于树的搜索策略进行探索,并基于启发式算法进行剪枝,最终选择最优路径。相比之下,GoT 则融合了基于图的思维扩展,使思维能够动态互联。这实现了三个关键的转换:聚合(将多个解决方案合并为一个统一的答案)、细化(随着时间的推移不断改进思维)、生成(生成多样化的候选)。GoT 并非在僵化的层级结构中摸索,而是使用容量指标对思维进行优先排序,并以最优方式探索路径,从而减少不必要的计算。
推理理论(ToT)的一个关键限制是其回溯受限:一旦分支被丢弃,就不会再被重新考虑。而"结果论"(GoT)通过允许迭代改进来克服这个问题,在迭代改进中,先前的想法可以被重新审视、修改和改进。这种迭代特性在复杂的推理任务中尤其有用,因为初始想法可能需要调整。此外,通过合并部分解决方案来减少冗余计算,GoT 的计算效率得到了显著提升。

5.8 Confidence-based Sampling
在基于置信度的抽样中,语言模型++会生成多个候选解决方案或推理路径,然后根据模型自身对每个结果的置信度对它们进行优先排序或选择++ 。这可以通过两种方式实现:(a) Selection:生成 N 个输出,并挑选对数概率最高的输出(即模型置信度最高的输出),本质上是按概率从 N 个输出中选取最佳,模型选择它认为最有可能正确的答案。(b) Guided Exploration:在探索推理树或多步解决方案时,使用模型的标记概率来决定扩展哪个分支(首先探索置信度较高的分支)。换句话说,++模型的概率估计充当了一种启发式方法,引导用户在解空间中搜索++。与纯随机抽样相比,基于置信度的方法会使过程偏向于模型认为正确的方向,从而有可能减少在低可能性(通常是不正确的)路径上浪费的探索。
基于置信度的策略已被纳入推理阶段,例如,基于树的 LLM 生成搜索会为每个可能的完成(叶子)分配一个置信度得分。该算法会根据这些置信度得分按比例对叶子进行采样,以决定要扩展哪些路径。一些推理方法会使用模型对答案的估计似然值来决定何时停止或是否提出后续问题。本质上,如果模型的置信度较低,则可能会触发进一步的推理(一种自我反思的形式)。基于置信度的选择也用于集成设置:例如,LLM 可能会生成多个答案,然后辅助模型评估每个答案正确的置信度,并选择置信度最高的答案。这在医学问答等任务中得到了探索,其中 LLM 给出答案和置信度得分,并且只有置信度高的答案才会被信任或返回。
5.9 Search Against Verifiers
LLM 中的这种验证方法++通过生成多个候选答案并使用自动验证系统选出最佳答案来提高答案质量++。该方法将重点从增加训练前的计算量转移到优化测试时的计算量,使模型能够通过结构化推理步骤或迭代细化在推理过程中"思考更长时间"。该方法主要包括两个步骤:
Generation :模型产生多个答案或推理路径,通常使用高温采样或多样化解码等方法;
Verification:验证器(例如奖励模型)会根据预定义的标准(例如正确性、一致性或与所需流程的一致性)评估这些候选方案。
验证器根据其评估重点进行分类:
- Outcome Reward Models (ORM):仅判断最终答案(例如,数学解决方案的正确性);
- Process Reward Models (PRM):评估推理步骤(例如,思维链中的逻辑连贯性),提供细粒度的反馈以修剪无效路径;
有几种技术属于这种范式可增强基于验证的优化。最佳 N 采样涉及生成多个答案并通过验证器(ORM/PRM)对它们进行排序,选择得分最高的答案,使其成为提高答案正确性的简单而有效的方法。带有 PRM 的束搜索会跟踪得分最高的推理路径(束)并尽早修剪低质量步骤,类似于思维树方法,在推理路径探索的广度和深度之间取得平衡。蒙特卡洛树搜索通过扩展有希望的推理分支、模拟推出和反向传播分数来平衡探索和利用,在搜索深度和验证置信度之间提供最佳权衡。多数投票(自洽)从多个样本中汇总答案并选择最常见的答案,避免显式验证器,这在多个响应的一致性表明正确性的环境中效果很好。

5.10 Self-Improvement via Refinements
这种方法指的是 LLM ++通过自我评估和迭代修订来增强其输出的能力++ 。此过程使模型能够在推理过程中动态地改进其响应,而不是仅仅依赖于预先训练的权重。一种值得注意的方法是自我改进 Self-Refinement ,其中 LLM 生成初始响应并对其进行评价,然后根据其自生成的反馈改进输出。此迭代过程持续进行,直到模型获得满意的结果。此类技术已被证明可以提高各种任务的性能,包括数学推理和代码生成。此过程遵循以下关键步骤:a) Initial Generation :模型生成答案或推理路径。b) Self-Critique :模型审查自身的响应并识别错误、不一致或需要改进的领域。c) Refinement :模型根据批评调整其响应并生成改进的版本。d) Iteration:该过程重复进行,直到输出达到预定义的质量阈值或停止改进。
另一种方法称为 Self-Polish ,其中++模型逐步细化给定的问题,使其更易于理解和解决。通过重新表述或重构问题,模型可以增强其理解并提供更准确的解决方案++。自抛光涉及逐步细化问题陈述,使其更易于理解和解决。该模型首先重新表述或重构问题以提高清晰度,然后将复杂的查询分解为更简单的子问题,并细化模糊的输入以确保精确理解。通过在解决问题之前重构问题,该模型可以提高其理解能力并生成更准确的解决方案。
5.11 Monte Carlo Tree Search
蒙特卡洛树搜索(MCTS)基于蒙特卡洛模拟在博弈树搜索中的应用。它因在游戏中的成功而声名鹊起,尤其是在 2016 年,它通过搜索由策略和价值网络引导的可能走法,为 AlphaGo 提供了支持。这以及它在其他棋盘游戏和电子游戏中的应用,证明了 MCTS 在不确定环境下进行序列决策的强大能力。
蒙特卡洛树搜索(MCTS)是一种随机搜索算法,++通过执行多次随机模拟来构建决策树++。它最擅长在游戏状态中寻找最佳走法,但它也适用于任何可以模拟结果的问题。该算法迭代地:(a) 根据启发式算法(例如 UCT,它选择具有较高置信区间的节点)从根节点选择一条路径;(b) 从该路径的末端扩展一个新节点(一个先前未访问过的状态);© 模拟从该新状态进行的随机滚动以获得结果(例如,游戏中的胜利或失败,或某种奖励); (d) 将结果反向传播到树上,以更新节点的值并为未来的选择提供参考。重复这些模拟数千次,可以将搜索集中在树中最有希望的分支上。本质上 MCTS 使用随机抽样来评估不同动作序列的潜力,逐渐使搜索偏向那些平均结果更好的动作序列。在 LLM 推理中,可以将文本生成视为一个决策过程,并借此探索不同的延续性。例如,对于给定的问题(根),每个可能的后续推理步骤或答案都是一个动作;模拟可以意味着让 LLM 继续得出最终答案(可能带有一些随机性),而奖励则可以是答案是否正确。通过反复执行此操作,MCTS 可以识别出哪条思路或答案链具有最高的经验成功率。MCTS 对推理的吸引力在于,它可以通过智能采样而非穷举采样来处理庞大的搜索空间,并且它自然地融入了不确定性和探索性。

最近,人们将蒙特卡洛树搜索 (MCTS) 与 LLM 相结合,以解决复杂的推理和决策任务。一个例子是使用 MCTS 进行查询规划:蒙特卡洛思维搜索,其中引导 LLM 提出一系列子问题以找到答案。Jay 等人使用了一种基于 MCTS 的算法,称为"蒙特卡洛推理器",该算法将 LLM 视为一个环境:每个节点代表一个提示(状态),每条边代表一个动作(例如,要提出的特定问题或要采取的步骤),并使用随机滚动来评估结果。这种方法使系统能够有效地探索可能的推理路径空间,并挑选出一条高回报的答案路径,在科学问答任务中的表现优于朴素抽样。同样,MCTS 也已应用于 LLM 的代码生成,算法探索不同的代码路径(使用模型提出代码补全方案并对其进行测试),以找到正确的解决方案。另一项工作将多个LLM与MCTS集成,将每个模型的输出视为一个分支,并使用奖励模型来模拟结果。早期结果表明,基于MCTS的推理可以解决单遍或贪婪方法经常遗漏的问题,尽管计算量更大。MCTS的缺点是其速度可能比直接采样或集束搜索慢得多,最近的研究正在通过提高效率(例如,通过状态合并)来解决这个问题。总的来说,MCTS将规划算法的优势引入LLM推理,使LLM能够通过模拟的部署"向前看",并做出更明智的推理选择,就像它在游戏中对AI所做的那样。

5.12 Chain-of-Action-Thought reasoning
LLM 在推理任务方面表现出色,但在推理时严重依赖外部指导(如验证者)或大量采样。现有的方法(如 CoT)缺乏自我修正和自适应探索的机制,限制了它们的自主性和泛化能力。Satori 引入了一种两阶段训练范式,其工作原理是++首先调整模型的输出格式,然后通过自我改进来增强其推理能力++。在第一阶段(格式调整)中,模型会接触由多agent框架生成的 10,000 条合成轨迹,该框架包含一个生成器、一个批评家、一个奖励模型。这种监督微调有助于模型使用元动作标记生成特定推理格式的输出,尽管它可能仍然难以在这些示例之外进行泛化。在第 2 阶段(通过强化学习进行自我改进)中,该模型采用 PPO 和"重启与探索"策略,这使得模型可以从中间步骤重新启动(无论这些步骤是否正确),以改进其推理过程。该模型会根据基于规则的正确性、反思奖励以及基于偏好的结果奖励模型反馈(详见第 5.9 节)的组合获得奖励,从而激励模型将更多计算资源分配给更棘手的问题,并在复杂任务测试期间实现扩展推理。
人们越来越多地探索多智能体框架和高级微调策略,以增强LLM的推理能力。多agent LLM训练 (MALT) 引入了一种结构化方法,其中生成、验证、改进步骤分布在专门的agent上,从而实现迭代式自我修正和改进的推理链。同样,优化偏好对齐仍然是确保 LLM 安全性和实用性的关键挑战。双因素偏好优化 (BFPO) 等方法将 RLHF 目标重构为单个监督学习任务,在保持稳健对齐的同时减少了人为干预。除了基于文本的推理之外,多模态思维可视化 (MVoT) 等多模态方法通过结合视觉表征扩展了思维理解提示 (CoT),显著提高了空间推理任务的性能。这些进步凸显了对结构化多智能体协作、安全意识优化和多模态推理日益增长的需求,以解决 LLM 推理中的根本局限性。
5.13 Pretraining vs. Test-time Scaling
预训练和 TTS 是两种提升 LLM 性能的不同策略,它们在计算成本和效率方面各有优劣。预训练涉及扩展模型参数或增加训练数据以增强能力,这需要大量的前期计算投入;TTS 优化了推理时间计算(例如迭代细化、基于搜索的解码或自适应采样),无需修改基础模型即可提升性能。
从性能与成本的角度来看,TTS 在简单到中等难度的任务(例如 MATH 基准测试)上取得的结果与规模大 14 倍的模型相当,同时在计算密集型场景中将推理成本降低了 4 倍 FLOP 。然而,对于最难的任务或推理计算约束较高的情况下,预训练仍然更具优势,因为规模更大的预训练模型本身就蕴含着更深层次的推理能力。

就用例而言,TTS 对于推理预算灵活,或基础模型已在任务中展现出合理能力的场景非常有用。相反,对于需要全新能力(例如,在新领域进行推理)的任务,预训练至关重要,因为单靠推理时间优化可能不够。
两种方法之间存在明显的权衡。TTS 降低了前期训练成本,使其对灵活的、随时可用的优化具有吸引力,但需要在推理时进行动态计算分配;预训练虽然初始成本较高,但能够保证性能的一致性,且无需额外的运行时开销,因此非常适合大规模 API 部署或对延迟敏感的应用程序。总而言之,TTS 和预训练本质上是互补的。未来的 LLM 系统可能会采用混合方法,其中较小的基础模型使用必要的知识进行预训练,而 TTS 通过自适应的按需计算动态增强响应。这种协同作用可以实现更具成本效益和效率的大规模模型部署。

6. Benchmarks of LLM Post-training Evaluation
为了评估 LLM 后训练阶段的成功,人们提出了一系列涵盖多个领域的基准测试:推理任务、对齐、多语言能力、通用理解以及对话、搜索任务。结构良好的评估框架能够确保全面理解 LLM 在各种任务中的优势和局限性。这些基准测试在 LLM 后处理阶段发挥着至关重要的作用,在此阶段,模型需要进行微调、校准、对齐和优化,以提高响应准确性、鲁棒性和伦理合规性。接下来将介绍主要的基准测试组。Table.3概述了这些基准测试组下的关键数据集。
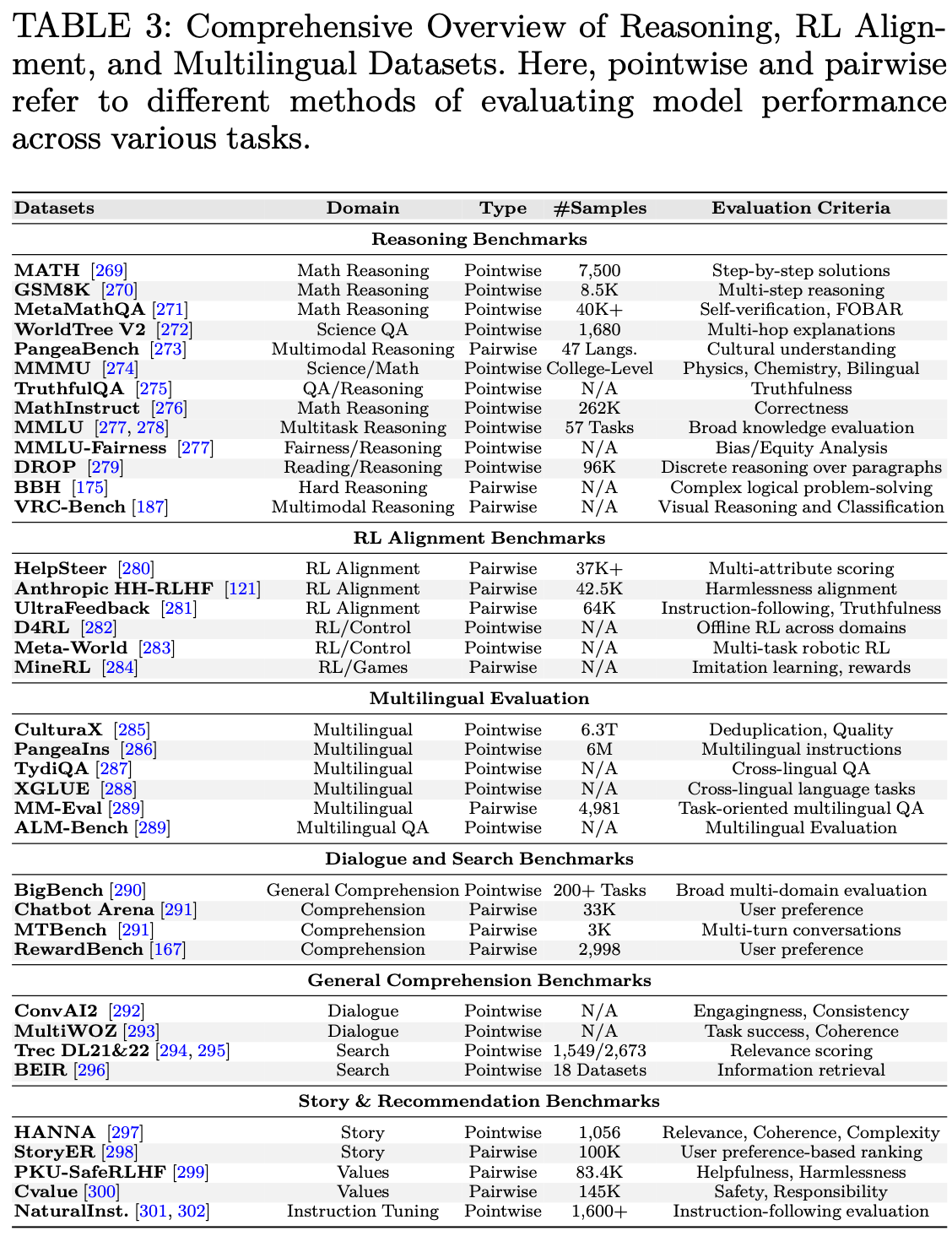
Reasoning Benchmarks.
这些基准测试评估 LLM 的逻辑、数学、科学推理能力。数学推理数据集(例如 MATH、GSM8K 和 MetaMathQA )测试模型在问题解决、多步算术、基于定理的问题表述方面的表现;科学和多模态推理基准测试(例如 WorldTree V2 和 MMMU)评估物理、化学、多模态理解方面的知识,这些知识对于 LLM 生成的回复中的事实核查和验证过程至关重要。此外,像 PangeaBench 这样的数据集将推理任务扩展到多语言和文化领域,使模型能够改进跨语言推理。这些基准测试有助于确定模型处理结构化知识和应用逻辑推理的能力。
RL Alignment Benchmarks
强化学习 (RL) 对齐基准是 LLM 对齐和训练后优化的核心。它们通过 RLHF 改进响应生成、道德约束和用户对齐输出。诸如 Help-Steer和 UltraFeedback 之类的数据集基于多属性评分和与用户指令的对齐情况来评估模型;Anthropic 的 HH-RLHF 探索了模型如何通过带有人类反馈的强化学习来学习人类偏好优化;D4RL 和 Meta-World 专注于机器人控制和离线 RL,这对自主模型决策具有重要意义;MineRL 将 RL 测试扩展到复杂环境(例如基于 Minecraft 的交互),这对于在自适应决策环境中训练 LLM 非常有用。
Multilingual Evaluation
多语言基准测试对于 LLM 后处理中的跨语言泛化、翻译自适应以及低资源语言的微调至关重要。CulturaX 和 PangeaIns 评估了超过 150 种语言的标记化、翻译、指令遵循,确保了模型输出的公平性和多样性。TydiQA 和 MM-Eval 针对双语和面向任务的多语言评估,从而提升了 LLM 的微调性能。这些数据集确保 LLM 不仅以英语为中心,而且针对多语言适应性进行了优化。
General Comprehension Benchmarks
通用理解基准有助于模型微调、响应连贯性和偏好优化。Chatbot Arena、MTBench 和 RewardBench 等数据集测试用户偏好建模和对话流畅性,这对于 LLM 响应排序和重排序方法至关重要。BigBench 评估广泛的多领域理解能力,而 MMLU 则衡量正确性和信息量。这些数据集有助于改进 LLM 的流畅性、事实正确性和开放式响应生成。
Dialogue and Search Benchmarks
对话和搜索基准在优化基于 LLM 检索的响应、多轮连贯性和信息检索准确性方面发挥着关键作用。ConvAI2 和 MultiWOZ 等数据集评估了多轮对话模型,这对于对话历史追踪和自适应响应微调至关重要。对于搜索相关性评估,BEIR 提供了大规模人工注释的判断,用于检索微调,确保 LLM 有效地生成和排序响应。TREC DL21/22 有助于文档相关性排序和事实检索。
7. Future Directions
作者收集了所有与 LLM 中训练后方法相关的论文,并分析了它们的趋势,如Fig.7所示。自 2020 年以来,强化学习技术在改进 LLM 方面的应用显著增加Fig.7 (a),这强调了对交互式 interactive approaches 方法的需求,例如人在回路强化学习和可扩展性。与此同时,由于奖励模型 reward modeling 的出现,人们对奖励建模Fig.7 (b)的兴趣稳步上升,但该领域仍在努力应对奖励攻击以及超越奖励攻击的鲁棒、故障感知奖励函数的设计。解码和搜索 Decoding and search Fig.7 (c)方法包括思想树和蒙特卡洛策略,旨在通过迭代自我批评来增强模型推理,但这些技术也需要可靠的不确定性估计器,以防止过多的计算开销。安全性、鲁棒性、可解释性同样成为核心关注点Fig.7 (d),这推动了偏差感知和不确定性感知强化学习方法的发展,这些方法超越了与人类不确定性的相关性,可以维护用户信任并防止对抗性攻击。另一个关键领域涉及个性化 personalization 和适应性 adaptation Fig.7 (e),其中为特定领域定制 LLM 的努力必须与隐私风险取得平衡,特别是当涉及企业数据或敏感个人信息时。
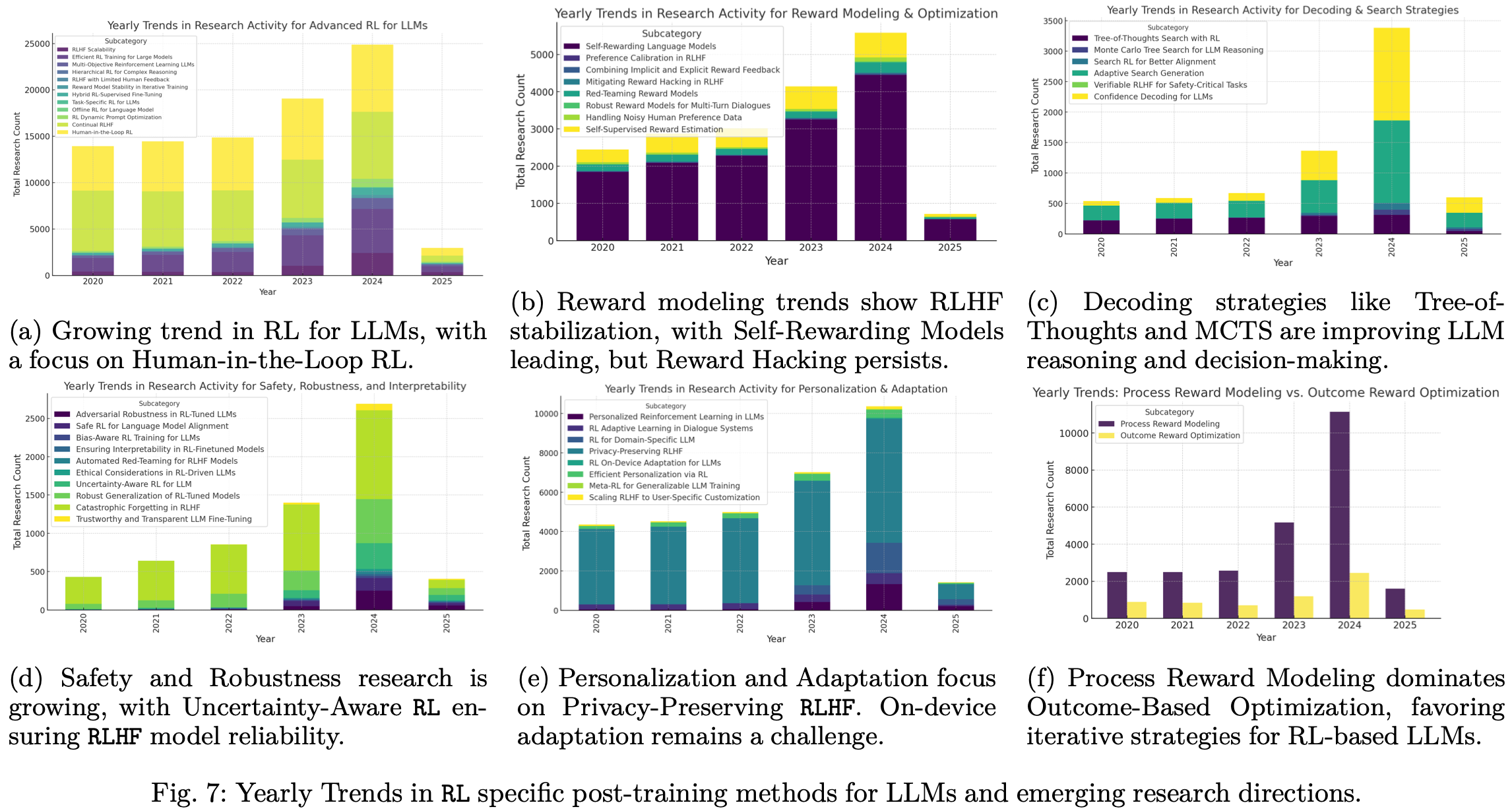
与此同时,过程 process 与结果奖励优化 outcome reward optimization Fig.7 (f)仍然是一个悬而未决的问题:虽然基于过程的奖励有助于指导渐进式改进,但以结果为中心的指标更简单,但可能无法捕捉关键的中间决策步骤。除了奖励结构之外,在新的任务上微调 LLM 仍然会遇到灾难性遗忘 catastrophic forgetting 和潜在数据泄露问题,这凸显了对参数高效方法和隐私保护策略(如差异隐私和联邦学习)的需求。人工反馈虽然对于对齐至关重要,但本质上成本高昂且范围有限;诸如 Constitutional AI 和 RLAIF 之类的方法试图将部分监督工作自动化,尽管它们引入了有关偏差校准和模型自洽性的新担忧。最后,测试间扩展和动态推理 dynamic reasoning 框架带来了进一步的挑战:模型必须学习何时为复杂查询分配更多计算,如何有效地调整验证模块,以及如何在面对对抗性输入时保持稳健的性能。这些相互融合的研究方向涵盖奖励建模、解码策略、可解释性、个性化、安全微调,凸显了强化学习在法学语言模型 (LLM) 中的多方面作用,并共同塑造了大规模语言模型开发的未来轨迹。下文将更详细地探讨其中一些方向。
Fine-tuning challenges
微调仍然是使LLM适应特定任务或领域的最直接的训练后方法之一,但它面临着一些尚未解决的挑战。一个根本问题是灾难性遗忘,当使用新数据更新LLM时,会导致其丢失或降低先前学习到的能力 。即使是像LoRA 这样大大减少可训练权重数量的高级PEFT方法,也无法完全解决这个问题。未来的研究可以探索更好的持续学习策略和正则化技术,使模型能够在不抹去旧技能的情况下获得新技能。例如,新的微调算法(例如CURLoRA)明确旨在稳定训练并在添加新任务的同时保留先验知识。有前景的研究方向包括基于课程的微调(逐步引入新事实或在已知事实的背景下引入新事实)以及结合检索或外部知识库的混合训练。例如,除了单纯调整模型的权重之外,还可以对 LLM 进行微调,使其在面对原始训练分布之外的查询时,能够查阅知识库或执行工具使用(例如数据库查询或计算)。这种检索增强 RAG 的微调可以让模型在推理时融入新信息,从而减少用新事实覆盖其内部权重的需要。另一种方法是训练模型明确地表示对新知识的不确定性,从而使模型能够在查询涉及预训练中未见的内容时说"我不知道"或听从外部来源。通过将权重更新与外部知识集成相结合,未来经过微调的 LLM 将保持更高的事实准确性,并降低对新信息的幻觉率。
Safe Fine-tuning
从伦理和安全角度来看,微调提出了一些重要的开放性研究问题。微调数据通常包含敏感或专有信息,如果模型记忆并随后重新生成这些数据,则可能导致隐私风险。最近的一项综合调查强调了微调阶段的漏洞,例如成员推断攻击(检测特定记录是否在微调集中)和数据提取(从模型输出中恢复部分微调数据)。降低这些风险是一个悬而未决的问题,人们正在积极探索诸如差分隐私微调(在权重更新中添加噪声)和联邦微调(数据永远不会离开用户设备,只有聚合更新才会发送到模型)之类的方法。然而,这些方法通常以牺牲模型效用为代价,或者需要仔细校准以避免性能下降。
Limitations of Human Feedback
人工反馈成本高昂且主观,解决人工反馈局限性的一个有希望的途径是使用人工智能反馈和自动化来协助或取代人类评估者。Anthropic 推出的 Constitutional AI 就是一个显著的例子:该模型不是依靠大量的人工反馈来判断每一种有害或有益的行为,而是以一套书面原则 "constitution" 为指导,并经过训练,以另一个人工智能模型作为评判者来批判和完善自身的反应。这方面的新兴方向包括 RLAIF 和其他半自动化反馈技术:使用强模型来评估或指导弱模型,甚至让多个 agent 讨论一个问题,并将他们的一致意见作为奖励信号。这种人工智能辅助反馈可以极大地扩展调优过程,并有助于克服人类专家时间有限的瓶颈。然而,它也提出了新的理论问题:如何确保人工智能评判者本身的一致性和正确性? 如果自动化偏好存在缺陷,则存在反馈循环或偏见回声风险。一个尚未解决的问题是,如何创建能够根据人类价值观进行校准的强大的人工智能反馈系统(或许可以定期通过人类监督或一系列不同的 constitution 原则进行"验证")。将人类反馈与人工智能反馈融合在一个分层方案中,可以为LLM提供一个可扩展且可靠的强化学习范式。
Test-time scaling challenges
TTS 的开放性挑战围绕着 如何高效可靠地编排推理时间流程。一个关键问题是,对于给定的查询,多少计算量才足够,以及如何动态地确定这一点?使用较少的资源可能会导致错误,但使用过多的资源则效率低下,并可能导致不一致。Snell 等人最近的研究解决了这个问题,他们提出了一个统一的框架,该框架包含一个"Proposer"和一个"Verifier",用于系统地探索和评估答案。在他们的框架中,提议者(通常是基础 LLM)生成多个候选解决方案,而验证者(另一个模型或启发式方法)则判断并选择最佳方案。最佳策略会因问题难度而异:对于较简单的查询,并行生成多个答案并从中选取最佳答案可能就足够了;而对于较难的问题,顺序、逐步推理并在每一步进行验证的效果会更好。未来的一个重要方向是构建自适应系统,其中 LLM 根据对问题复杂性的估计动态分配计算。这个想法与人工智能中的元认知相关,元认知使模型能够感知它们不知道什么或什么值得进一步思考。为 LLM 开发可靠的置信度指标或难度预测器是一个开放的研究领域,但如果这方面的进展能够使 TTS 变得更加实用,也就是说,模型只会在必要时"放慢速度思考",就像人类在解决难题上花费更多时间一样。此外,通过将推理时间扩展重新定义为概率推理问题,并采用基于粒子的蒙特卡洛方法,小型模型仅在 32 次部署中就达到了 o1 级准确率,在各种数学推理任务中的扩展效率提高了 4 到 16 倍。最近的研究表明,将测试时计算提炼到合成训练数据中可以产生协同的预训练效益,这也可以进一步探索。
Reward Modeling and Credit Assignment
当前的强化学习方法存在奖励泛化错误的问题,即模型过度优化表面指标,而非真正的推理质量。多步骤任务中终端奖励的稀疏性增加了信用分配的挑战,尤其是在长期推理场景中。像动态决策优化 (DPO) 这样的传统方法需要低效的成对偏好数据,并且无法有效利用失败轨迹。可以通过使用对比逐步评估将过程监督与基于结果的奖励相结合来研究混合奖励模型。这种方法能够对中间决策步骤进行更细致的评估,同时与长期目标保持一致。最近的研究表明,步骤级策略优化可以在保持安全约束的同时提高价值函数的准确性。可以通过适用于 Transformer 的时间差分学习来探索动态信用分配机制。这种调整可以增强模型捕捉长程依赖关系的能力,并优化在扩展序列上的奖励传播。可以通过对抗性数据增强将负面示例纳入强化学习循环,从而开发出故障感知训练策略。这可以通过系统地将模型置于具有挑战性的场景中,并鼓励更具弹性的策略学习,从而提高模型的鲁棒性。
Efficient RL Training and Distillation
目前 LLM 的强化学习方法需要耗费高昂的计算资源,而且其性能往往不如知识蒸馏技术 。这种低效率限制了可扩展性和实际部署,因为尽管蒸馏后的模型所需的训练开销较少,但其性能往往优于强化学习训练的模型。此外,纯强化学习方法难以在语言质量和推理能力提升之间取得平衡,从而造成了性能天花板。
开发混合框架是一个有趣的方向,该框架利用从大型模型中提炼出的知识来初始化强化学习策略,将强化学习的探索性优势与监督学习的稳定性相结合。同样,逐步增加任务复杂性,同时使用知识提炼来保持语言连贯性的课程抽样策略也能有所帮助。PEFT 方法可以在强化学习更新过程中发挥作用,在保持基础能力的同时增强推理能力。

Privacy-Preserving Personalization
为企业和个人用例定制模型会增加通过记忆暴露私人训练数据的风险,因此隐私保护 的适应性至关重要。有前景的解决方案包括:homomorphic instruction tuning 同态指令调优,它在推理过程中处理加密的用户查询,同时保持端到端加密;differential privacy via reward noising 奖励噪声实现差异隐私,它在对齐过程中将数学上有界的噪声引入 RLHF 偏好排序;federated distillation 联邦蒸馏,它从分散的用户特定模型中聚合知识,而无需共享原始数据。
Collaborative Multi-Model Systems
随着单模型的扩展接近物理极限,诸如多 agent LLM 协作之类的替代范式变得必要 。研究人员正在研究新兴的通信协议,这些协议可以训练模型开发用于模型间知识迁移的有损压缩"语言",例如 GenAINet;鲁棒集成,其中压力测试引发的专业化驱动基于故障分析自动划分问题空间;通过进化策略进行无梯度协同学习,旨在不依赖反向传播发现互补模型组合。
Multimodal RL Integration
多模态强化学习面临组合状态爆炸的难题,尤其是在超过 128k 个 token 的上下文中。克服这一问题的先驱方法包括:采用特定模态策略并带有交叉注意门控的分层注意力框架;压缩上下文同时保留关键推理片段的自适应截断策略;以及利用自监督复杂度预测来促进渐进式多模态整合的"闪现课程"方法。
Efficient RL Training
由于当前方法存在严重的样本效率低下和计算开销,高效的强化学习训练范式仍然是关键的研究前沿。解决诸如过度思考现象(过多的推理链会浪费宝贵的计算资源)等问题,需要采用诸如部分展开策略、采用学习到的压缩变换器的自适应长度惩罚机制,以及将蒙特卡洛树搜索 (MCTS) 与高级强化学习优化器相结合的混合架构等方法。这些创新对于将强化学习扩展到长上下文任务,同时最大限度地减少计算资源的浪费至关重要。

强化学习方法存在样本效率低下和计算开销大的问题,尤其是在扩展到超过 128k 个 token 的上下文时。"过度思考"现象(即模型生成过长的推理链)进一步降低了 token 效率并增加了部署成本。研究针对长上下文处理的部分部署策略,并结合闪存注意机制。开发长度惩罚机制,使用学习到的压缩转换器进行迭代式长短词法提炼。结合蒙特卡洛树搜索(MCTS)和 GRPO 的混合架构可以实现更好的探索与利用权衡。Xie 等人的并行工作通过自适应树搜索剪枝展示了有希望的结果。该领域仍存在一些未解决的挑战。不确定性传播仍然存在问题,因为当前的置信度估计器增加了大约 18% 的延迟开销,而灾难性遗忘导致强化学习微调过程中基础能力下降 29% 。此外,基准饱和也是一个问题,MMLU 得分与实际性能相关性较差(r = 0.34)。

8. Conclusion
本综述和教程系统地回顾了LLM的训练后方法,重点关注微调、强化学习和扩展。分析了关键技术,以及提升效率和与人类偏好相符的策略。此外,还探讨了强化学习在通过推理、规划和多任务泛化增强LLM方面的作用,并在代理环境范式中对其功能进行了分类。强化学习和测试时间扩展方面的最新进展显著提升了LLM的推理能力,使其能够应对日益复杂的任务。通过整合最新研究成果并识别尚未解决的挑战,旨在指导未来优化LLM以适应实际应用的努力。