Kafka是消息队列的一种实现,类似的还有RocketMQ 和 RabbitMQ
消息队列的基本形态,就是有N个生产者,N个消费者
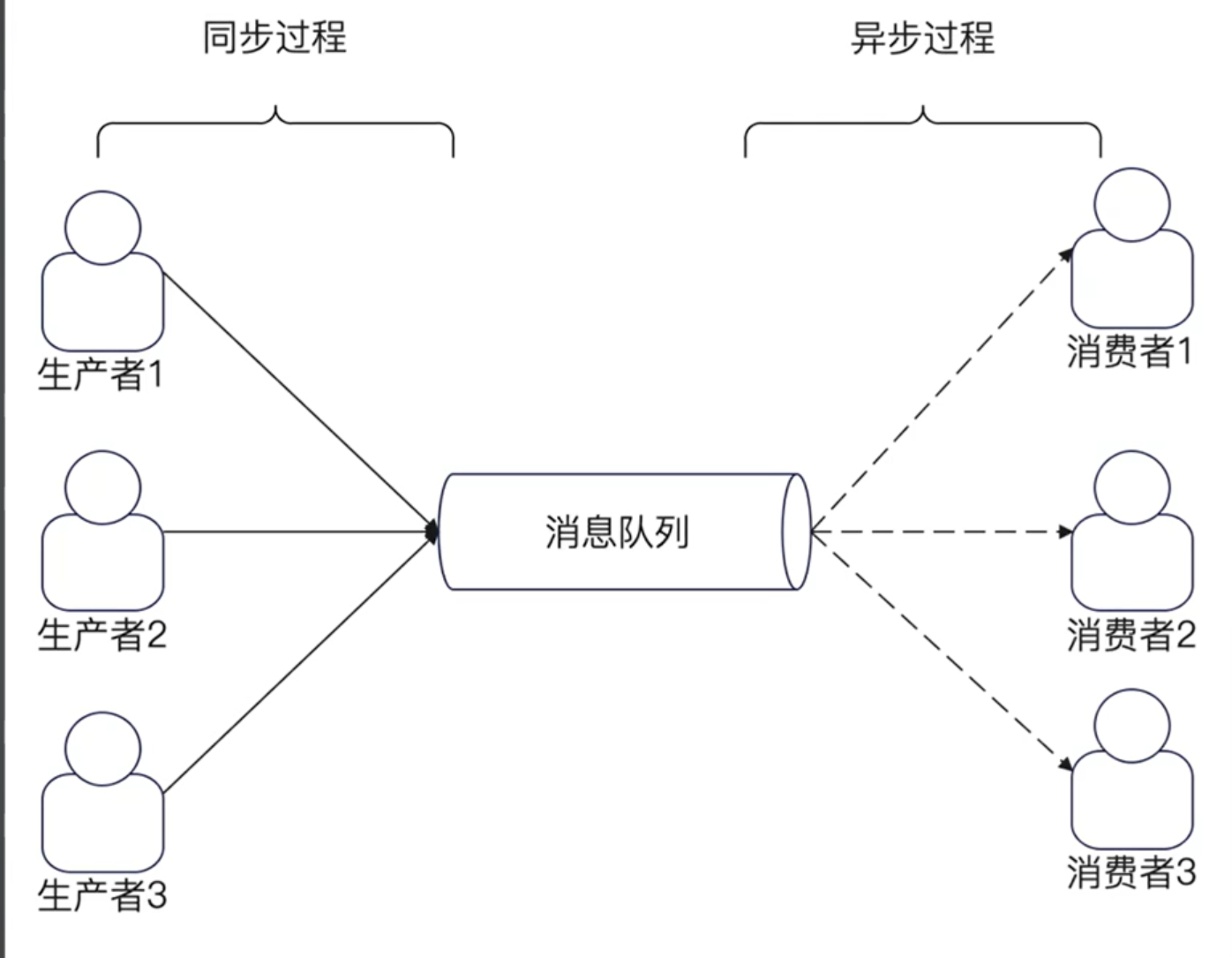
这种形态下,生产者和消费者就解耦了
Kafka中的基本概念
- 生产者 producer
- 消费者 consumer
- broker 可以理解为消息服务器
- topic与分区(partition)
- 消费者组和消费者
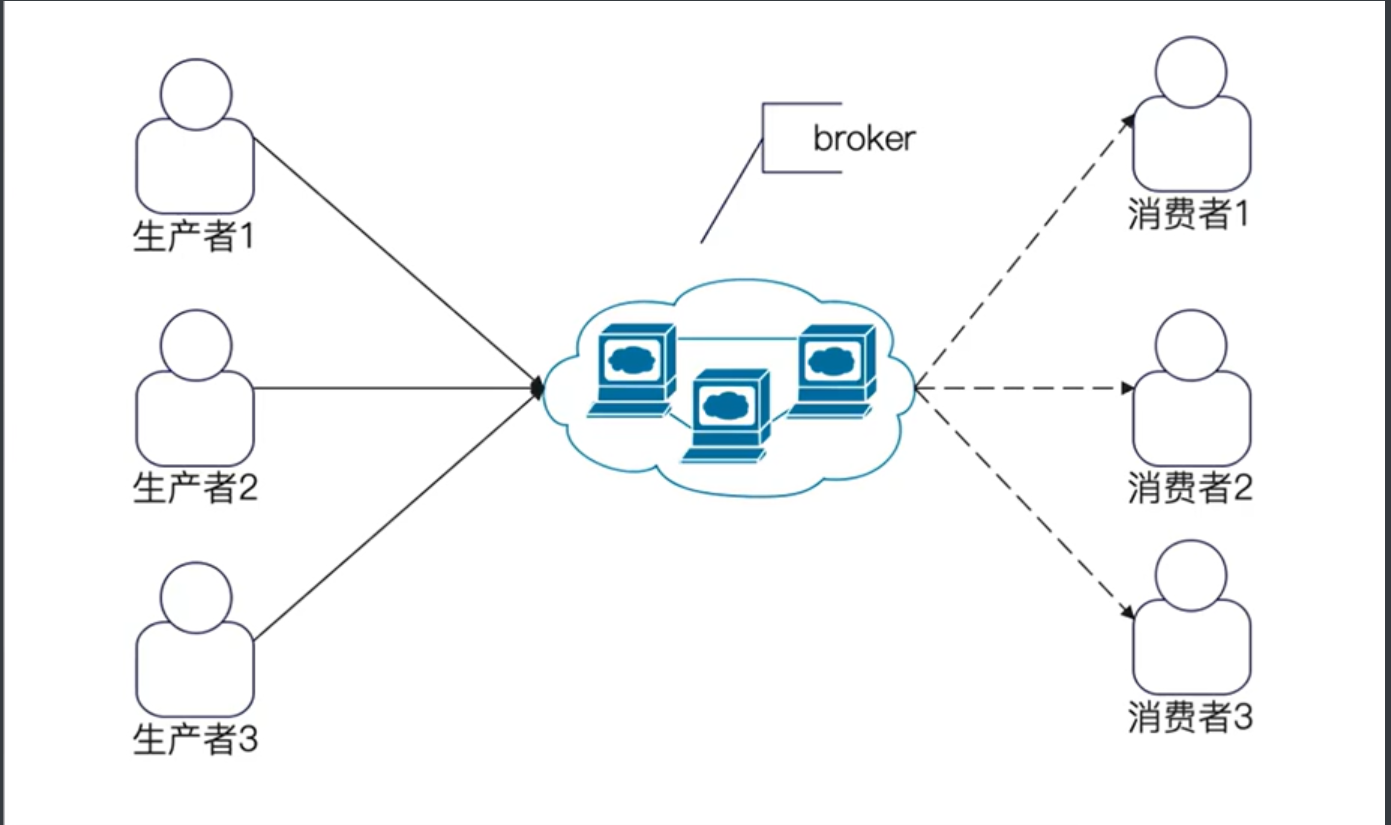
Broker
Broker 的意思是"中间人",是一个逻辑上的概念。
在实际中,一个broker就是一个消息队列进程,也可以认为一个broker就是一台机器。
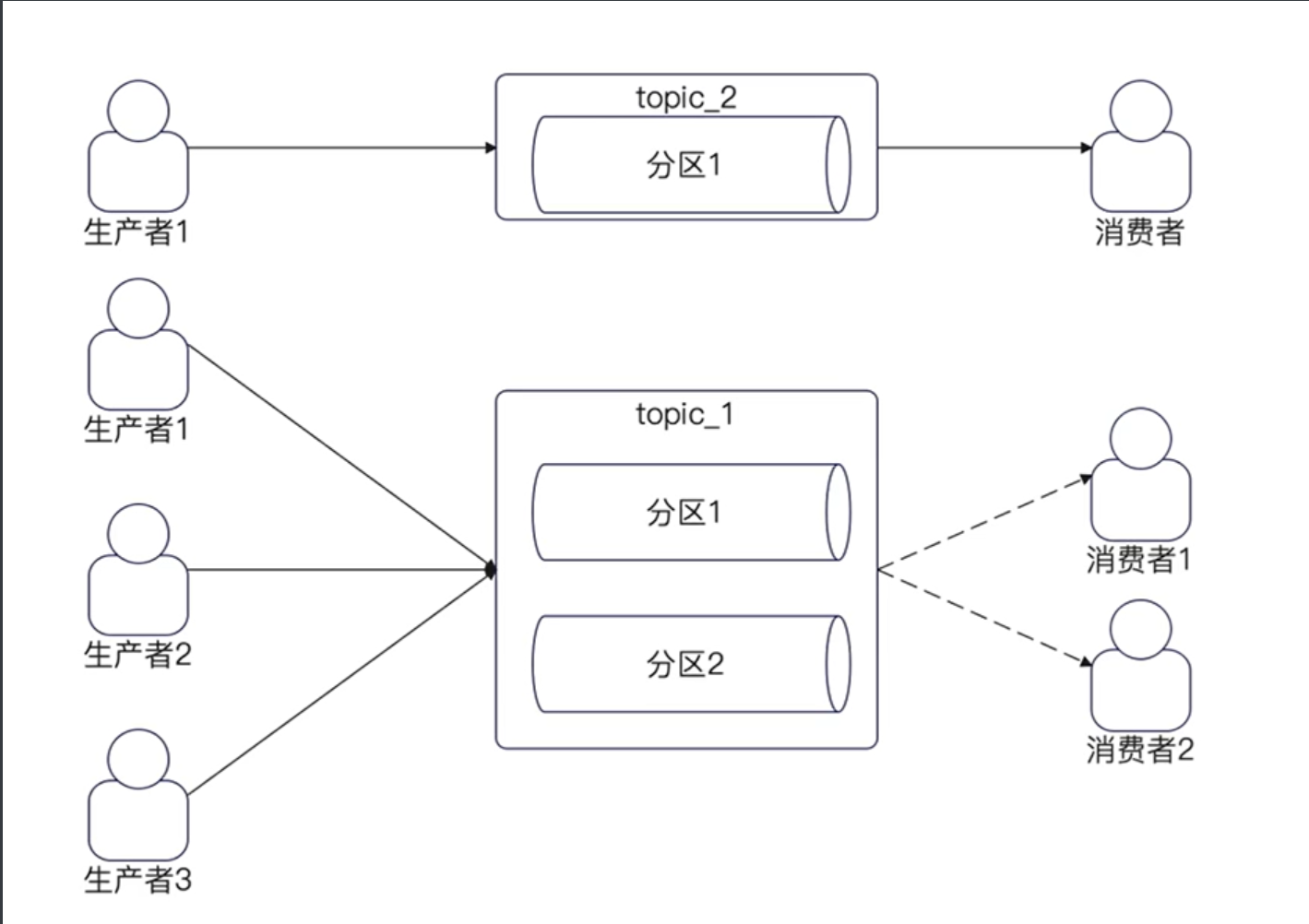
topic 和 分区
Topic 是消息队列上代表不同业务的东西
简单来说,一个业务场景就是一个topic。
而一个topic有多个分区。
需要多少分区:max(发送者总速率/单一分区写入速率,发送者总速率/单一消费者速率)+buffer
下图中topic1有两个分区,而topic2有一个分区
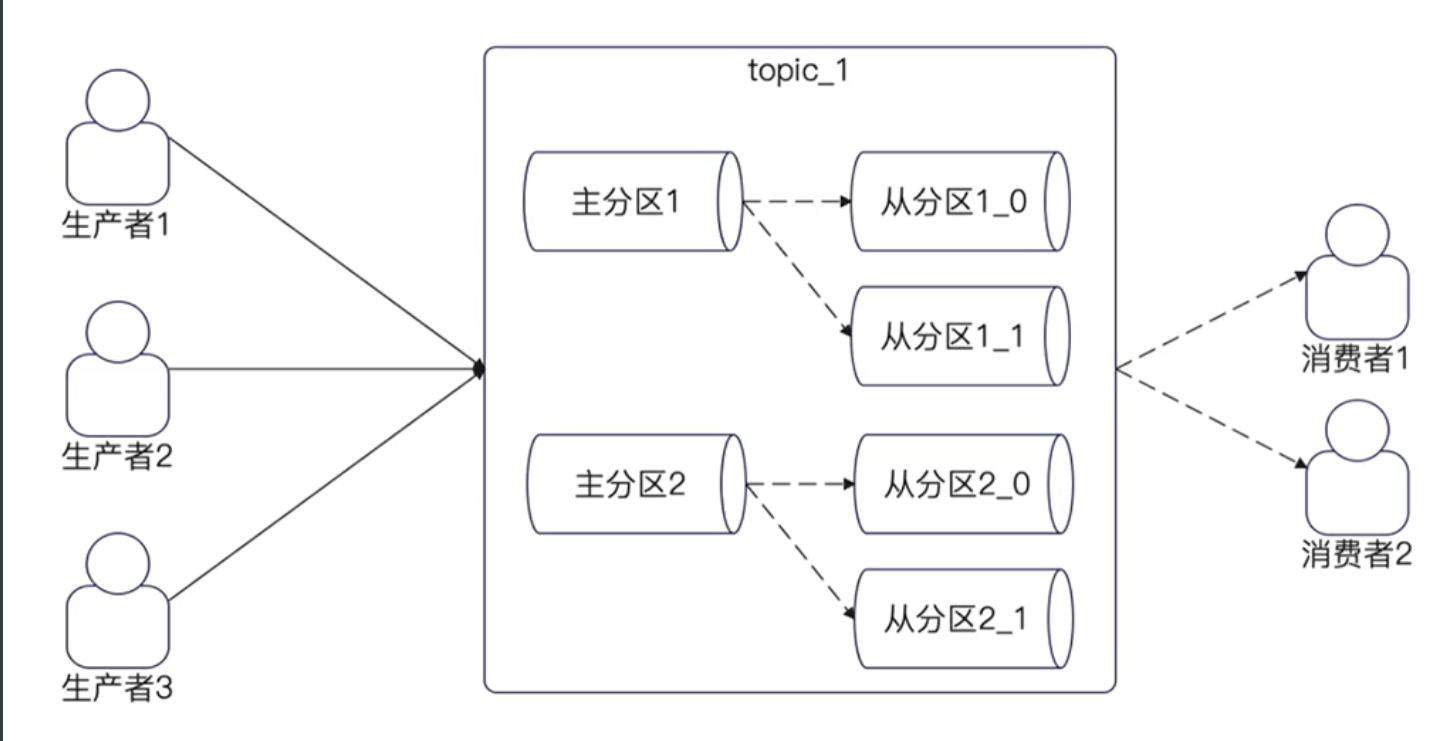
主分区和从分区
实际上,我们说某个topic有多少个分区的时候,指的是有多少个主分区。
但是事实上,Kafka为了保证高可用和数据不丢失,分区有主分区和从分区。
当发送消息到Kafka上的时候,Kafka会把消息写入主分区之后,再同步到从分区。
如下图所示,每一个分区实际上是一主两从(不是固定的规则)的结构。
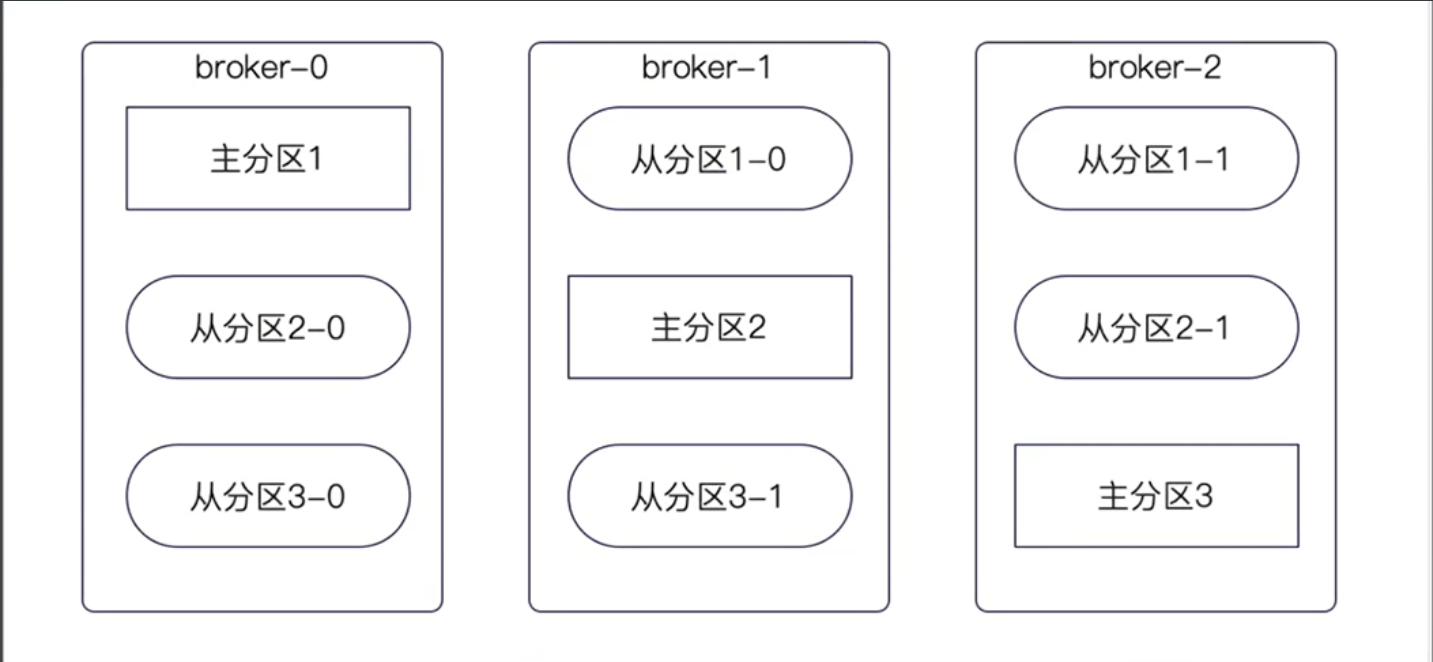
分区和broker的关系
正常情况下,同一个topic的分区会尽量均匀分散到所有的broker上。
这意味着两件事:
- 主分区之间,不会在同一个broker上。
- 同一个分区的主分区和从分区,也不会在同一个broker上。
核心目标:保证当某个broker崩溃的时候,对业务的影响最小,满足上面两个要求的话,某一个broker崩溃,最多导致topic的某一个主分区不可用,不至于完全不可用。
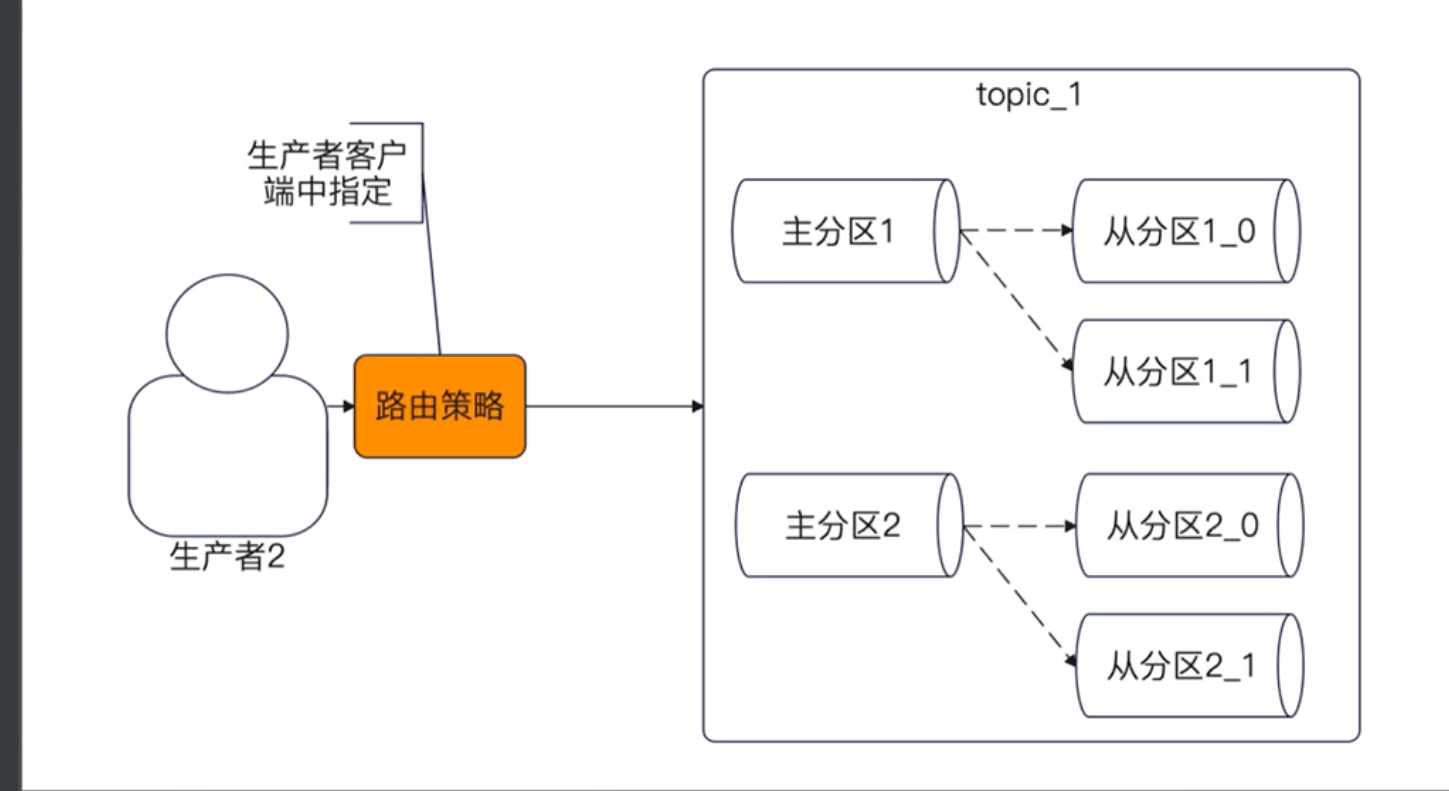
分区和生产者的关系
正常情况下吗,一个topic 都会有多个分区,所以发送者在发送消息的时候,就需要选择一个目标分区。
比较常用的有三种:
- 轮询:一个分区发送一次,挨个轮流。
- 随机:随机挑选一个。
- 哈希:根据消息中的key来筛选一个目标分区。
遵循QPS均匀比较好
也可以自己设计一些比较复杂的路由策略,用在面试中效果会比较好。
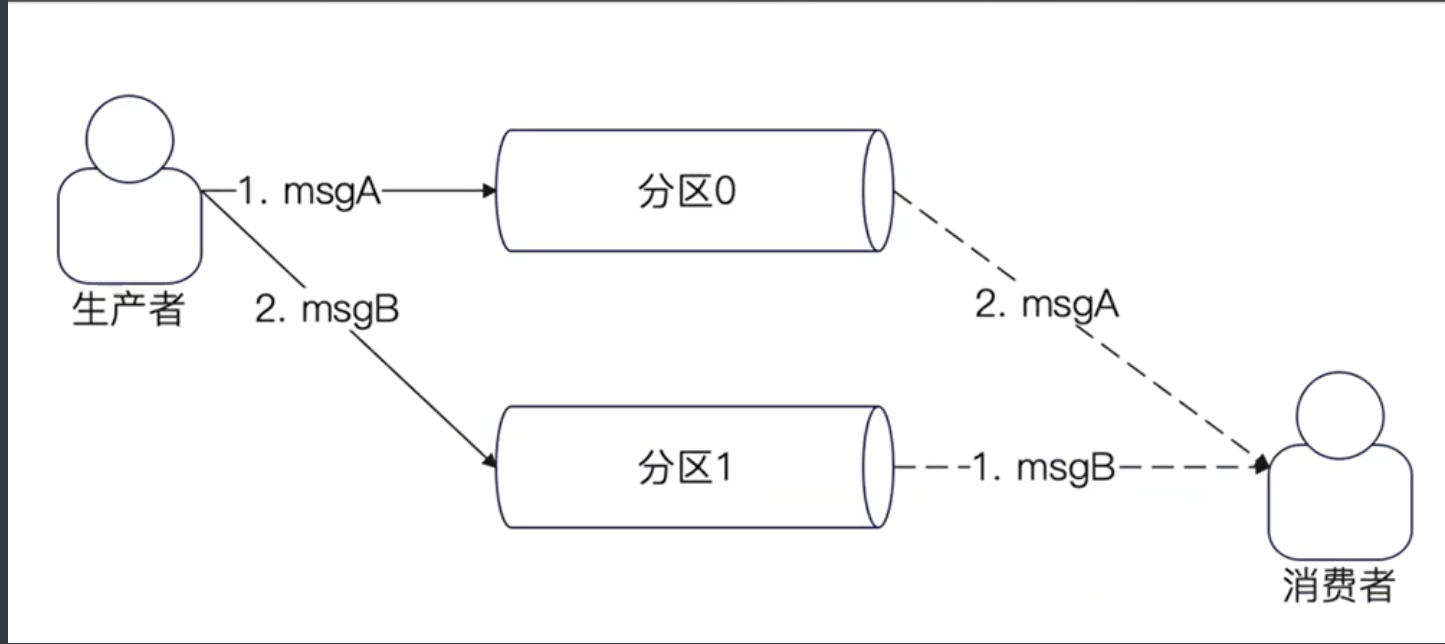
分区和消息有序性
Kafka中的消息有序性保证是以分区为单位的。
也就是说,一个分区内的消息是有序的。即,消息在一个分区内的顺序,就是分区的消息被消费的顺序。
因此,如果要做到全局有序,就只能有一个分区。
如果要做到业务有序,就需要保证业务的消息都丢到同一个分区里面。
下图是一个不同分区上的消息失序的例子。生产者发送msgA和msgB,但是消费者的消费顺序是msgB,msgA。
分区和消费者组,消费者的关系
在Kafka中,消费者都是归属于某一个消费者组的。
**一个消费者组可以看作是关心这个topic的一个业务方。**比如说在创建用户的时候,搜素关心新用户,推荐也关心新用户,那么搜索自己是一个消费者组,推荐也是一个消费者组。
**同一个消费者组里面,一个分区最多只有一个消费者。**也就是在同一个消费者组里面:
- 一个消费者可以消费多个分区的数据。
- 一个分区在同一时刻,只可能被一个消费者消费。
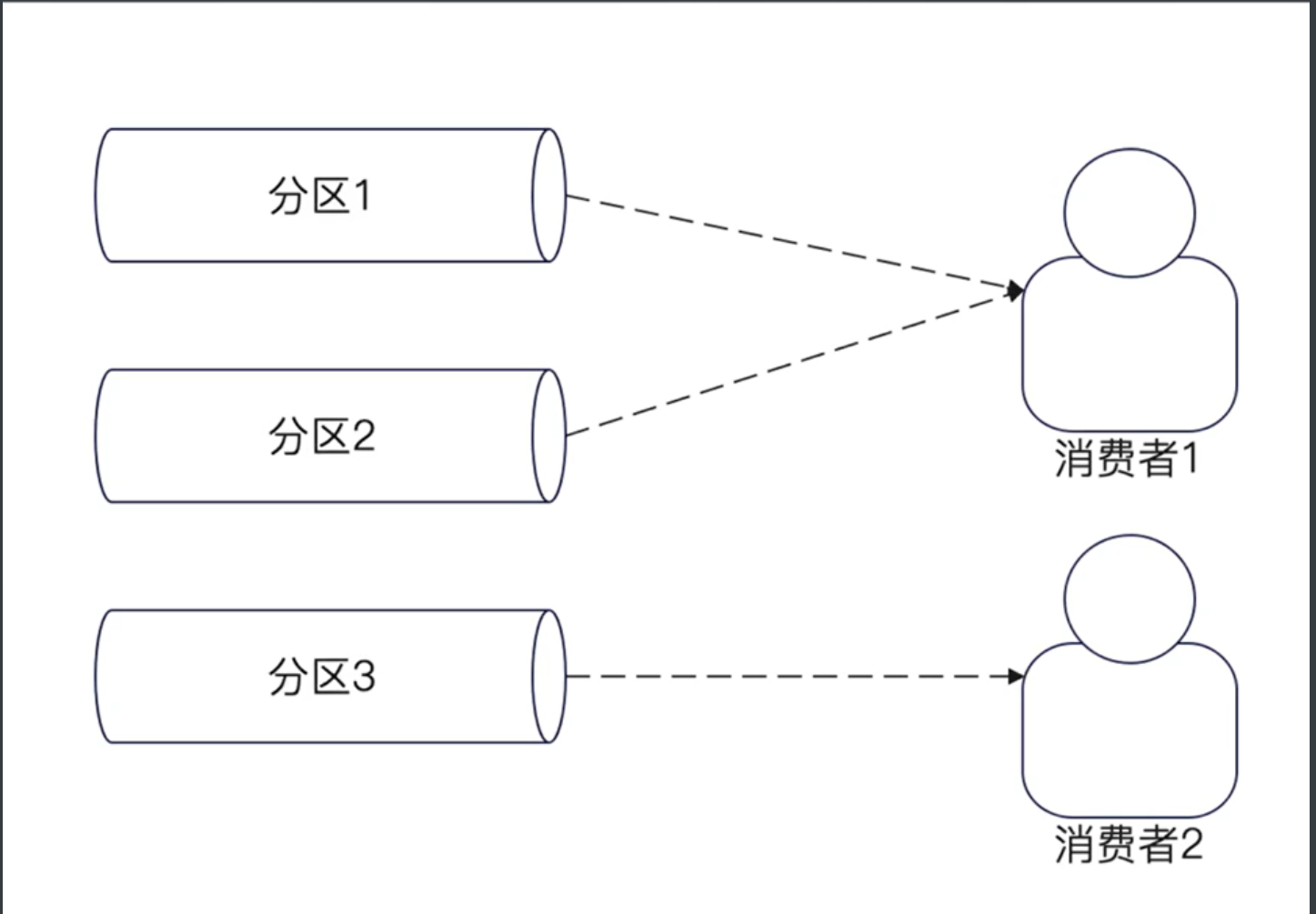
最多一个消费者的内涵
一个分区最多一个消费者!!!
下图中的分区2被两个消费者消费,这种是不允许的。
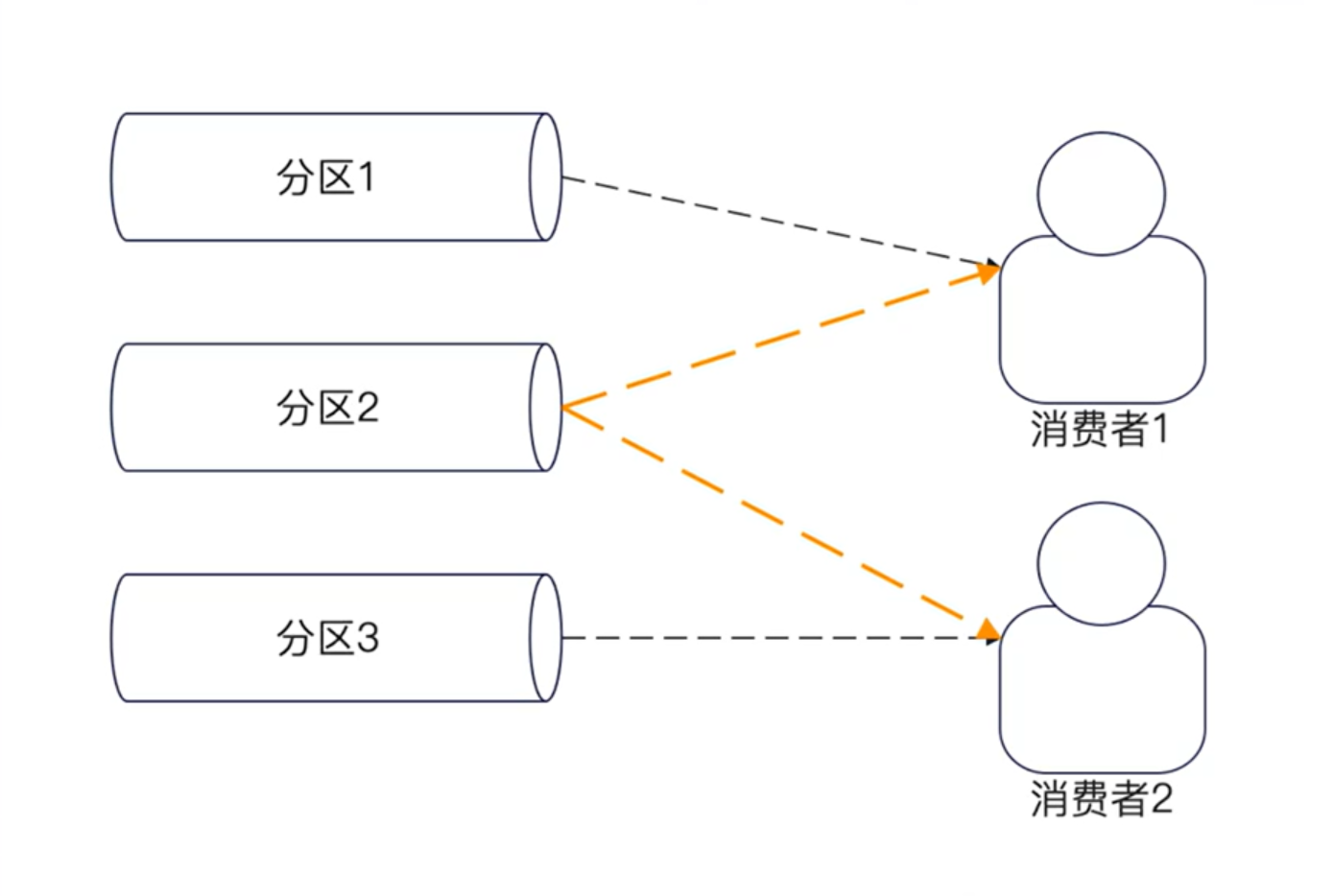
由此衍生出来:
-
如果一个topic有N个分区,那么同一个消费者组最多有N个消费者。多于这个数字的消费者会被忽略。
-
如果消费者性能很差,那么并不能通过无限增加消费者来提高消费速率。
这就是典型的面试热点:消息积压问题。
面试题:消息积压问题
消息积压问题 (Message Backlog / Message Queue Backlog)是指消息系统(如 Kafka、RabbitMQ、RocketMQ 等)中的消息生产速度大于消费速度,导致未被及时处理的消息不断堆积,形成队列积压。
一、具体表现
- 消息队列的未消费消息数量持续上升。
- 消费者处理延迟增加,甚至发生超时或阻塞。
- 系统下游(如数据库、缓存)负载飙升,进一步加剧问题。
二、常见原因
消费者处理能力不足
- 单个消费者处理速度慢(CPU、IO瓶颈等)。
- 消费者数量不足,未充分利用并行处理能力。
-
消费逻辑复杂或存在性能问题
- 业务逻辑太重,如耗时操作、远程调用、数据库慢查询等。
- 消费端存在阻塞、锁竞争、批处理效率低等问题。
-
系统异常或崩溃
- 消费者崩溃未及时恢复。
- 消息堆积后触发重试机制,造成雪崩效应。
-
消息生产突增
- 突发业务高峰(如秒杀、双十一)。
- 上游程序错误导致消息量异常增长。
-
消息队列配置不合理
- 分区/主题配置不当,消费者未能均匀分担压力。
- 消息堆积阈值设置过高,未能及时预警。
三、危害
- 消息处理延迟,影响业务实时性(如用户通知、订单处理等)。
- 可能导致系统雪崩,甚至消息丢失或重复消费。
- 增加恢复难度,影响用户体验与系统稳定性。
四、解决思路
| 问题类型 | 解决方案 |
|---|---|
| 消费能力不足 | 增加消费者实例、优化消费逻辑、批量处理消息 |
| 消费慢 | 引入异步处理、使用缓存、优化数据库操作 |
| 系统异常 | 设置监控报警、自动拉起消费者、实现幂等重试机制 |
| 消息突增 | 实现流量削峰(如削峰队列、限流器)、分布式消费 |
| 配置不合理 | 合理设置分区数、消费组数、预警阈值 |
Docker 中如何部署Kafka
Kafka 早期版本(< 2.8) 需要依赖 Zookeeper 来管理元数据(如 topic、broker 信息),但从 Kafka 2.8 开始引入 了 KRaft 模式(Kafka Raft Metadata Mode) ,也就是所谓的 "无 Zookeeper 模式"。
1.手动拉取镜像
bash
docker pull bitnami/kafka:3.6.02.创建并启动Kafka
清爽版,下面有专门的注释
bash
docker run -d \
--name kafka \
-p 9092:9092 \
-p 9094:9094 \
-e KAFKA_CFG_NODE_ID=0 \
-e KAFKA_CFG_AUTO_CREATE_TOPICS_ENABLE=true \
-e KAFKA_CFG_PROCESS_ROLES=controller,broker \
-e KAFKA_CFG_LISTENERS=PLAINTEXT://0.0.0.0:9092,CONTROLLER://0.0.0.0:9093,EXTERNAL://0.0.0.0:9094 \
-e KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://192.168.24.101:9092,EXTERNAL://192.168.24.101:9094 \
-e KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT \
-e KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=0@localhost:9093 \
-e KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER \
-v kafka-data:/bitnami/kafka \
bitnami/kafka:3.6.0
bash
docker run -d \
--name kafka \
#Kafka 内部使用的端口
-p 9092:9092 \
#Kafka 提供给宿主机或外部客户端访问的端口
-p 9094:9094 \
#Kafka 节点 ID,必须在集群中唯一,这里是 0 (单节点时设置成 0 即可)
-e KAFKA_CFG_NODE_ID=0 \
#是否允许自动创建 topic,开发测试建议开启;线上建议关闭(手动管理更安全)
-e KAFKA_CFG_AUTO_CREATE_TOPICS_ENABLE=true \
#设置本节点既充当 controller 又充当 broker(KRaft 模式支持分离角色,但单节点要全包)。
-e KAFKA_CFG_PROCESS_ROLES=controller,broker \
#定义 Kafka 要监听哪些协议/端口。
#PLAINTEXT://0.0.0.0:9092:内部通信(集群内组件用)。
#CONTROLLER://0.0.0.0:9093:用于 KRaft 元数据 controller 间通信。
#EXTERNAL://0.0.0.0:9094:暴露给外部客户端使用。
-e KAFKA_CFG_LISTENERS=PLAINTEXT://0.0.0.0:9092,CONTROLLER://0.0.0.0:9093,EXTERNAL://0.0.0.0:9094 \
#设置 Kafka 向客户端"宣传"的地址(外部怎么连)。
#PLAINTEXT://192.168.24.101:9092:容器内其他服务连接时使用服务名 192.168.24.101
#EXTERNAL://192.168.24.101:9094:宿主机通过 192.168.24.101:9094 访问 Kafka。
-e KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://192.168.24.101:9092,EXTERNAL://192.168.24.101:9094 \
#定义每个 listener 对应的协议(这里全部使用明文 PLAINTEXT)
-e KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,EXTERNAL:PLAINTEXT \
#声明 controller 的投票者(即 controller 之间的通信)。
#0@kafka:9093:ID 为 0 的节点,其 controller 地址是 localhost:9093。
#单节点配置即可,集群中要配置多个。
-e KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=0@localhost:9093 \
#告诉 Kafka 哪个 listener 是 controller 用的。
-e KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER \
#使用 Docker volume kafka-data 来持久化 Kafka 数据(日志、topic 等),即使容器删除数据也不会丢失。
-v kafka-data:/bitnami/kafka \
bitnami/kafka:3.6.03.验证Kafka是否创建完成
bash
INFO ... Kafka successfully initialized
INFO ... Starting Kafka server
INFO ... [KafkaServer id=0] started (kafka.server.KafkaServer)当最后出现"started"或"ready"字样,就表示 Broker 已经监听并可用。