引言:TiDB 分布式数据库技术架构概述
TiDB 作为一款开源的分布式 NewSQL 数据库,在分布式数据库技术领域具有重要地位。与传统的单机数据库相比,TiDB 具有纯分布式架构,拥有良好的扩展性,支持弹性的扩缩容;支持标准 SQL,对外暴露 MySQL 网络协议,并兼容大多数 MySQL 语法;默认支持高可用,在少数副本失效的情况下能够自动进行数据修复和故障转移;支持 ACID 事务,满足强一致需求场景;具有丰富的工具链生态,覆盖数据迁移、同步、备份等多种场景。
TiDB 的技术架构设计充分借鉴了 Google Spanner 和 F1 的分布式架构理念(119),采用计算存储分离的设计,将整体架构拆分成多个模块,各模块之间互相通信,组成完整的 TiDB 系统。其核心架构包括三个层次:计算层 (TiDB Server)、存储层 (TiKV Server)和调度层(PD Server),同时集成了 TiFlash 列式存储引擎以支持 HTAP(混合事务分析处理)能力。
本文将从技术架构、核心机制、分布式能力、存储生态和调度管理五个维度,对 TiDB 的技术实现进行全面深入的分析和调研。
https://docs.pingcap.com/zh/tidb/stable/tidb-architecture/一、TiDB 整体技术架构分析
1.1 三层架构设计与组件功能
TiDB 采用清晰的三层架构设计,每个层次都有明确的功能定位和技术实现。计算层由 TiDB Server 组成,负责将 SQL 翻译成 Key-Value 操作,转发给存储层 TiKV,然后组装 TiKV 返回的结果并返回给客户端。这一层的节点都是无状态的,节点本身并不存储数据,节点之间完全对等。
存储层包括 TiKV Server 和 TiFlash 两种存储引擎。TiKV 是分布式事务型键值数据库,提供满足 ACID 约束的分布式事务接口,通过 Raft 协议实现数据复制和一致性保证。TiFlash 则是列式存储引擎,通过 Multi-Raft Learner 协议实时从 TiKV 复制数据,确保与 TiKV 之间的数据强一致性。
调度层 由 PD(Placement Driver)Server 组成,作为集群的 "大脑",负责存储集群拓扑结构、存储服务器元数据、提供 TiDB Dashboard 管理界面、为分布式事务分配事务 ID、管理时间戳 Oracle(TSO)等关键功能(7)。PD 还负责集群的资源调度、副本管理和负载均衡。
1.2 各层通信机制与数据流转
TiDB 各层之间通过高效的通信机制实现数据流转。在数据映射层面,TiDB 将关系型数据转换为 Key-Value 格式存储。每个表分配唯一的 TableID,每行数据分配 RowID(优先使用整数型主键),按照Key: tablePrefix{TableID}_recordPrefixSep{RowID}的规则编码,Value 存储序列化的列数据。
索引数据的映射同样采用结构化编码。主键和唯一索引按照Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue编码,Value 存储对应的 RowID;普通二级索引则在 Key 末尾添加 RowID 以支持范围查询。这种编码方式确保了相同表或索引的数据在 TiKV 的 Key 空间中连续排列,便于高效的范围查询和全表扫描。
TiDB Server 与 TiKV 之间通过 KV 协议进行通信,将 SQL 操作转换为具体的 Key-Value 操作。TiDB Server 首先解析 MySQL 协议包,进行语法和语义分析,生成并优化查询计划,然后执行查询计划并处理数据。在这个过程中,TiDB Server 需要与 TiKV 交互获取数据,最终将结果返回给用户。
1.3 HTAP 架构设计与技术实现
TiDB 的 HTAP(混合事务分析处理)架构是其核心技术优势之一。架构中包含行存储引擎 TiKV 和列存储引擎 TiFlash ,两者自动复制数据并保持强一致性(117)。TiDB Server 可以同时从 TiKV 和 TiFlash 读取数据,根据查询特征和统计信息智能选择最优存储引擎,甚至在同一查询内混合使用两种存储以提供最佳查询性能(112)。
TiFlash 以低消耗不阻塞 TiKV 写入的方式实时复制数据,同时提供与 TiKV 相同的一致性读取,保证读取到最新数据(101)。TiKV 和 TiFlash 之间的数据使用 Raft 分布式协议准实时同步,在保证数据一致性的前提下将同步延迟控制在秒级(109)。这种设计彻底改变了传统数据处理模式,通过一套系统同时支持 OLTP 和 OLAP 工作负载,消除了数据孤岛和 ETL 延迟(113)。
二、TiDB 核心技术机制深度剖析
2.1 TSO 时间戳分配机制与实现
TiDB 的 ** 时间戳 Oracle(TSO)** 是实现分布式事务和 MVCC(多版本并发控制)的核心机制。PD(Placement Driver)承担 TSO 角色,为集群内各组件分配时间戳,这些时间戳用于为事务和数据分配时间标记,对启用 Percolator 模型至关重要。
TSO 时间戳采用 64 位格式,由两部分组成:46 位物理时间戳 (自 1970 年 1 月 1 日以来的 UNIX 时间戳,单位为毫秒)和18 位逻辑时间戳(递增计数器)。逻辑时间戳用于处理一毫秒内的多个时间戳请求或时钟逆转情况,确保时间戳始终递增而不会倒退,从而保证 TSO 时间戳的完整性。
TSO 的生成和分配机制具有高性能和高可用性特点。PD Leader 节点负责生成和分配 TSO,逻辑时间部分占用 TSO 的低位(通常是低 18 位),作为数值计数器在同一物理时间下区分不同时间戳(2)。这种设计既保证了时间戳的全局唯一性,又提供了足够的并发处理能力。
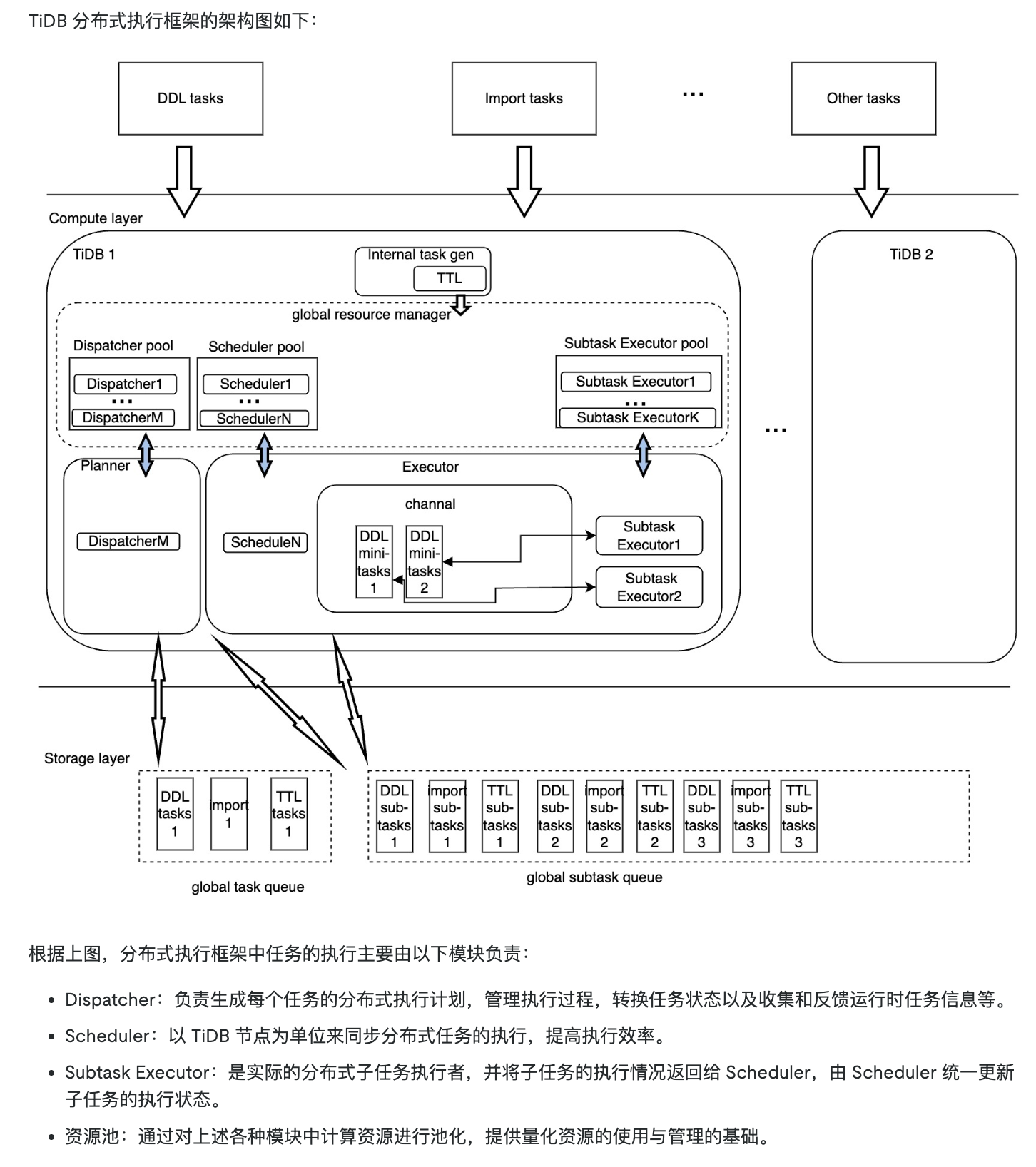
2.2 分布式执行框架(DXF)架构与功能
从 TiDB v7.1.0 开始引入的 ** 分布式执行框架(DXF)** 进一步发挥了分布式架构的资源优势。该框架的目标是对基于该框架的任务进行统一调度与分布式执行,并提供整体和单个任务两个维度的资源管理能力。
DXF 主要用于处理数据库中非核心的事务型负载(TP)和分析型查询(AP)任务,如 DDL 语句、IMPORT INTO、TTL、ANALYZE 等操作。这些任务通常需要处理整个模式或数据库对象中的所有数据,可能需要周期执行但频率较低,如果资源控制不当容易对核心业务造成影响。
DXF 框架包含三个核心模块:Dispatcher 负责生成任务的分布式执行计划、管理执行过程、转换任务状态以及收集和反馈运行时任务信息;Scheduler 以 TiDB 节点为单位同步分布式任务的执行,提高执行效率;Subtask Executor是实际的分布式子任务执行者,将子任务执行情况返回给 Scheduler。
2.3 MVCC 多版本并发控制机制
TiDB 实现了 ** 多版本并发控制(MVCC)** 机制,start_ts 同时作为事务获取的数据库快照版本,意味着事务只能读取 start_ts 时刻的数据库数据(28)。TiDB 的快照隔离(Snapshot Isolation,SI)通过 MVCC 机制在分布式环境下实现了高效的读写分离与事务隔离,为每个数据修改生成全局唯一的时间戳版本号(29)。
TiKV 中的每个 Key 都关联多个版本,由时间戳决定。架构确保读操作始终访问数据的最新提交版本,新写操作生成新版本但不会立即覆盖现有版本(30)。TiDB 使用 MVCC 机制实现事务,写入新数据时不会直接替换旧数据,而是保留旧数据的同时以时间戳区分版本。
MVCC 的实现通过在 Key 后面添加版本号完成。没有 MVCC 时,TiKV 可看作简单的 Key-Value 对;有了 MVCC 之后,同一个 Key 的多个版本按版本号降序排列(版本号较大的在前),便于快速定位最新版本。这种设计既保证了数据的一致性,又提供了优异的并发性能。
2.4 分布式事务处理机制
TiDB 采用 Google 的Percolator 事务模型 (两阶段提交的变体)确保分布式事务的正确完成(8)。Percolator 源自 Google 论文,是一种基于列族存储的分布式事务协议,被 TiDB 深度改造并应用于 TiKV 层。其核心思想是将每行记录拆分为 Primary、Write、Lock 和 Data 等列(9)。
事务处理流程包括以下关键步骤:事务开始时从 PD 获取 start_ts,在所有需要写操作的行中选择一个作为 primary,其他作为 secondary;上锁成功后写入 D 列更新新版本数据,以 start_ts 为版本号(11)。TiDB 事务基于 Percolator 模型,从 PD 获取时间戳作为 Commit TS,提交 primary key。整个提交过程的关键路径包括至少两次 TiDB 和 TiKV 之间的网络交互,而 Async Commit 机制减少了一次写 TiKV 的延时,是对原始 Percolator 事务模型的重要改进(14)。
2.5 协处理器(Coprocessor)机制
** 协处理器(Coprocessor)** 是 TiDB 实现计算下推的关键技术。TiDB 收到查询语句后进行分析,计算出物理执行计划,组织成 TiKV 的 Coprocessor 请求,然后根据数据分布分发到所有相关的 TiKV 节点。TiKV 收到请求后根据算子对数据进行过滤聚合,然后返回给 TiDB(22)。
Coprocessor 的设计充分考虑了分布式查询的性能优化。TiDB 根据执行计划将 KeyRange 带上表元信息组织成 TiKV 的 KeyRange,从缓存或 PD 获取每个 KeyRange 所在的 Regions 信息,将查询请求切分成以 Range 为单位的子任务,并行下发到对应的 TiKV 节点(25)。
由于 TiDB 下推的是树状结构表达式,Coprocessor 选择了由下而上递推的 **RPN(逆波兰表示法)** 进行计算。RPN 是树的后序遍历,在每个节点知道自己有几个子节点时等价于原本的树结构。执行表达式时使用栈结构缓存中间值(26)。这种设计使得复杂的 SQL 计算能够在存储层高效执行,大大减少了数据传输开销。
三、TiDB 分布式能力技术分析
3.1 Region 数据分片机制与管理策略
TiDB 采用基于Range 的分片策略,将整个 Key-Value 空间分成多个连续的 Key 段,每个段称为一个 Region,用 [StartKey,EndKey) 左闭右开区间描述。每个 Region 默认存储 256MiB 数据(可配置),这一设计参考了 Google Spanner 的 multi-raft-group 副本机制。
Region 的分裂和合并机制确保了数据分布的动态平衡。当 Region 大小达到阈值(默认 96MB)或写入次数触发分裂条件时,PD 自动将其分裂为两个子 Region;当检测到 Region 写入热点(如连续写入导致的 Range 热点)时,PD 会触发强制分裂(123)。TiKV 会尽量保持每个 Region 中保存的数据在合适大小,当 Region 大小超过限制(默认 384MiB)后自动分裂为两个或更多子 Region;当 Region 因大量删除变得太小(默认 54MiB)时,TiKV 会将相邻小 Region 合并为一个。
Region 管理还支持基于负载的分裂策略。Load Base Split 在选择分裂位置时试图平衡分裂后两个 Region 的访问负载,避免跨 Region 访问,且通过该策略分裂的 Region 不会快速合并(44)。这种智能的分片管理机制确保了系统能够根据数据增长和访问模式自动调整,保持良好的性能和扩展性。
3.2 Multi-Raft 协议架构与实现
TiDB 的存储层 TiKV 采用Multi-Raft 架构 ,将数据划分为多个 Region(数据分片),每个 Region 独立运行 Raft 协议。每个 Region 对应一个 Raft Group,包含多个副本(通常为 3 个),其中一个作为 Leader 处理客户端读写请求,负责日志复制和提交;其他作为 Follower 同步 Leader 的 Raft 日志(48)。
Raft 协议的实现包括以下关键组件:Leader 选举 机制确保在节点故障时能够快速选出新的 Leader;成员变更 操作支持添加副本、删除副本、转移 Leader 等操作;日志复制保证数据变更通过 Raft 日志安全可靠地同步到复制组的每个节点。根据 Raft 协议,只需要同步复制到多数节点即可认为数据写入成功。
TiKV 的 Multi-Raft 实现还包括动态分裂策略,当 Region 大小超过阈值(默认 512MB)时触发 Split 操作生成子 Region。所有 Raft Group 共享全局线程池,通过优先级队列调度不同 Region 的 IO 请求,关键系统操作(如 Leader 转移)享有更高调度优先级。系统还采用局部性优化,将同一物理节点上的多个 Region 副本分配到不同磁盘路径,利用 NUMA 绑定减少跨核访问延迟(82)。
3.3 故障恢复与自动平衡机制
TiDB 基于 Raft 的多数派选举协议提供金融级 100% 数据强一致性保证 ,在不丢失大多数副本的前提下实现故障自动恢复(auto-failover),无需人工介入(55)。故障恢复机制具有以下特点:单个实例失效时,如不是 Raft Leader 则服务完全不受影响;如是 Raft Leader 则重新选出新 Leader,自动恢复服务(57)。
TiDB 能够在毫秒级内通过回退和重试自动解决问题,确保故障转移过程对客户端应用无缝。网关层和计算层无状态,故障转移只需在其他位置立即重启,应用应实现连接重试逻辑(56)。TiDB Operator 支持通过自动扩容 Pod 实现故障自动转移功能,该功能默认开启,超过设定时间后开始执行故障自动转移(60)。
自动平衡机制通过 PD 的调度策略实现。PD 作为集群的 "大脑",通过一系列调度器实现 Region 的副本放置与负载均衡,均衡各节点负载(Region 数量、存储空间、读写流量)。调度触发条件为节点 Region 数量差值超过 balance-region-threshold(默认 5),调度优先级为优先迁移非 Leader 副本以减少对业务影响(123)。
3.4 负载均衡与数据迁移策略
TiDB 内置的 **PD(Placement Driver)** 通过调度策略动态优化数据分布。当连续 3 次检测到热点时触发调度,通过分裂 Region(Split)和迁移 Peer(Move)实现负载转移,迁移过程采用限速机制(默认 512MB/s)避免影响在线业务(62)。
数据迁移主要出现在以下场景:扩容新节点时需要在新老 TiKV 节点间做 balance,老节点数据向新节点搬迁;下线节点时需要将下线 TiKV 上的数据搬迁到现有节点;Placement-rule 突然发生变更(副本规则发生变更)(63)。
负载均衡策略包括多个维度的优化:Leader 数量均衡 通过 balance-leader-scheduler 保持不同节点的 Leader 均衡;Region 数量均衡 通过 balance-region-scheduler 保持不同节点的 Peer 均衡;热点均衡 通过 hot-region-scheduler 保持不同节点的读写热点 Region 均衡(121)。PD 支持动态添加和删除调度器,可通过 pd-ctl 直接操作,如使用 scheduler show 查看当前运行的调度器,使用 scheduler remove balance-leader-scheduler 删除指定调度器(122)。
3.5 多副本管理与容灾能力
TiDB 从 v5.0 开始引入Placement Rules 副本规则系统 ,指导 PD 为不同类型数据生成相应调度(67)。该系统允许用户精细控制任何一段连续数据的副本数量、Raft 角色、放置位置等属性,并可配合 tidb_replica_read 参数实现读写分离,读在 follower 节点,写在 leader 节点(72)。
容灾能力设计考虑了多种部署场景。以 3 副本配置为例,PD 确保每个 Region 的 3 个副本分别放置在 3 个不同的 Zone(Z1、Z2、Z3)中(70)。TiDB Cloud 将 TiFlash 节点均匀部署到区域内不同可用区,建议每个集群配置至少 2 个 TiFlash 节点并创建至少 2 个数据副本以保证生产环境高可用(73)。
数据一致性通过多层防护机制确保:Checksum 校验对 Raft 日志和 SST 文件进行校验以检测数据损坏;数据采用多副本存储,副本通过 Multi-Raft 协议同步事务日志,多数派写入成功事务才能提交,确保数据强一致性且少数副本故障时不影响可用性(74)。TiCDC 提供单向同步,为保证主备数据一致性,业务账号禁止写入备库,副本间通过 Raft 协议保证数据一致性和高可用,对用户完全透明,可保证任一数据中心失效后服务可用且不发生数据丢失(79)。
四、TiDB 存储生态系统技术架构
4.1 TiKV 存储引擎架构设计与性能特点
TiKV 是分布式事务型键值数据库,提供满足 ACID 约束的分布式事务接口,通过 Raft 协议实现数据复制和一致性保证。TiKV 采用分层存储架构围绕 RocksDB 引擎构建,每个 Region 对应独立的 Raft 日志流,通过逻辑隔离保证不同 Region 日志独立性。新一代日志引擎采用 LSM-tree 优化结构,相比原生 RocksDB 减少 50% 写放大(82)。
TiKV 使用 Facebook 的 RocksDB 和 Raft 等技术,项目最初受 Google Spanner 和 HBase 启发(85)。TiKV 针对高并发读写进行了优化,能够处理大量数据请求,适合需要高吞吐量和低延迟的应用场景(83)。其核心设计包括:使用 RocksDB 作为本地存储引擎,这是一个针对 Flash 存储优化的高性能 Key-Value 数据库,基于 LSM 树存储引擎;数据写入通过 Raft 接口而非直接写入 RocksDB,确保数据的强一致性和高可用性(81)。
TiKV 的性能特点体现在多个方面:高扩展性 通过 Region 分片和动态分裂合并实现;高可用性 通过 Raft 协议的多副本机制保证;高性能 通过协处理器下推计算、优化的存储引擎配置等技术实现;强一致性通过 Raft 协议和 Percolator 事务模型确保分布式事务的 ACID 特性。
4.2 RocksDB 配置优化与性能调优
TiKV 对 RocksDB 进行了深度定制 ,通过 RocksDbOptions 和 RocksCfOptions 封装类管理数据库和列族选项。TiKV 采用 RocksDB 作为存储引擎,其块缓存配置通过 BlockCacheConfig 结构体进行精细控制,针对不同 CF(Column Family)设置不同优化策略(93)。
RocksDB 线程池用于 Compact 和 Flush 任务,默认大小为 8。遇到 Write Stall 时可先调大 rocksdb.max-background-jobs 取值,如仍存在问题可将 rocksdb.max-sub-compactions 设置为 2 或 3(90)。
压缩策略优化遵循以下原则:压缩级别与 CPU 占用呈正相关 ,建议 OLTP 场景使用 ZSTD 3-6 级,分析场景可提升至 9-12 级;块大小设置 遵循 "热数据小,冷数据大" 原则,热表 64KB,归档表 128-256KB;分层压缩策略 为 Level 0-4 使用 ZSTD 6 级,Level 5 + 使用 ZSTD 12 级以平衡性能与空间(88)。
如果平均行大小小于 512 字节,可将默认列族的所有压缩级别设置为 "zstd"(89)。这些优化策略充分考虑了不同工作负载的特点,通过精细化配置实现了存储性能的最大化。
4.3 TiFlash 列式存储引擎架构与实现
TiFlash 是 TiDB HTAP 架构的关键组件 ,作为 TiKV 的列存扩展,通过 Raft Learner 协议异步复制,提供与 TiKV 相同的快照隔离支持(96)。TiFlash 主要用于分析处理(AP),以列式格式存储数据,通过 Raft 日志实时从 TiKV 同步数据更新,延迟在秒级以内。
TiFlash 采用DeltaTree 存储引擎 ,由一组 Segment 构成,Segment 按需进行分裂及合并。DeltaTree 对 Delta Layer 和 Stable Layer 采用不同结构,分别针对写入和读取场景进行优化。在接受来自 Raft 层的全量数据快照(Raft Snapshot)时,构建 ColumnFileBig 而非 ColumnFileInMemory(97)。
DeltaTree 的架构设计充分参考了 B+Tree 和 LSM Tree 的设计思想。从整体上看,DeltaTree 将表数据按照主键进行 range 分区,切分后的数据块称为 Segment;Segment 内部采用类似 LSM Tree 的分层结构,以支持列式存储上的实时更新(98)。
TiFlash 的核心特性包括:异步复制 以 Raft Learner 角色进行异步数据复制,节点宕机或网络高延迟时不影响 TiKV 业务;一致性 提供与 TiKV 相同的快照隔离支持,通过复制进度校验保证读取最新数据;智能选择 TiDB 可自动选择 TiFlash 列存或 TiKV 行存,甚至在同一查询内混合使用;计算加速通过列存读取效率提升和协处理器下推为 TiDB 分担计算。
4.4 TiFlash 与 TiKV 数据同步机制
TiFlash 通过Multi-Raft Learner 协议 从 TiKV 同步数据,具有实时性特点:数据变更几乎无延迟同步至 TiFlash。TiKV 与 TiFlash 的协同核心在于 Multi-Raft Learner 协议,当 TiKV Leader 提交日志后,TiFlash Learner 通过异步重放日志实现数据同步,从根本上保证了两份存储的数据一致性(95)。
数据同步机制包括全量和增量两种方式。TiFlash 通过 Region 的 leader 节点进行数据全量和增量同步,增量同步通过 Raft Log 异步复制,相当于 MySQL 的 redo log 同步(105)。TiFlash 节点和 TiKV 节点进行复制同步期间发生网络延迟或抖动不会影响 TiKV 运行,TiFlash 和 TiKV 一样提供快照隔离支持并保证读取数据最新(105)。
TiFlash 部署完成后不会自动同步数据 ,需要手动指定需要同步的表。TiFlash 以 learner 角色接入 TiDB 集群,支持表粒度的数据同步,部署后默认情况下不会同步任何数据,需要按照按表构建 TiFlash 副本流程完成指定表的数据同步(110)。这种设计提供了灵活的数据同步控制,用户可根据业务需求选择性地同步特定表的数据。
4.5 HTAP 场景下的存储协同工作机制
在 HTAP 场景下,TiDB 的行存储引擎 TiKV 和列存储引擎 TiFlash自动复制数据并保持强一致性 (117)。TiDB Server 可以同时从 TiKV 和 TiKV 读取数据,TiDB 和 TiSpark 可按照与 TiKV 相同的 Coprocessor 协议下推任务到 TiFlash,计算层的 MPP 能够在 TiFlash 之间做数据交换,拥有更强的分析计算能力(108)。
TiDB 引入 TiFlash 列存引擎后实现了真正的 HTAP 架构,核心组件包括:TiDB Server 负责 SQL 解析、优化、生成执行计划;PD 负责集群元数据管理和调度;实时数据同步通过 Raft 协议实现 TiKV 到 TiFlash 的实时数据复制(113)。
TiDB 的 HTAP 架构具有以下优势:一体化处理 通过一套系统同时支持 OLTP 和 OLAP 工作负载,消除数据孤岛和 ETL 延迟;智能选择 根据查询特征和统计信息自动选择最优存储引擎,甚至在同一查询内混合使用;实时同步 TiKV 和 TiFlash 之间通过 Raft 协议准实时同步,延迟控制在秒级;资源隔离 建议 TiFlash 与 TiKV 部署在不同节点,实现计算资源的有效隔离(109)。
这种架构彻底改变了传统数据处理模式,让实时决策成为可能。TiDB 通过创新的存储引擎设计和智能查询优化,解决了传统数据架构中 OLTP 和 OLAP 分离带来的诸多问题(114)。
五、TiDB 系统调度与管理能力分析
5.1 PD 调度器架构设计与核心功能
PD(Placement Driver)作为 TiDB 集群的 **"大脑"**,其调度器采用分布式架构,由多个节点组成,这些节点通过 Raft 协议保证数据的一致性和高可用性。每个 PD 节点都维护着集群的元数据信息,并通过定期的心跳检测和数据同步确保集群状态的一致性(126)。
PD 的核心功能包括:存储集群拓扑结构 ,维护整个 TiDB 集群的物理和逻辑结构信息;存储服务器元数据 ,记录每个 TiKV 节点的状态、容量、性能等信息;提供 TiDB Dashboard 管理界面 ,为用户提供可视化的集群监控和管理功能;为分布式事务分配事务 ID ,确保事务 ID 的全局唯一性;管理时间戳 Oracle(TSO) ,为分布式事务和 MVCC 提供时间戳服务(7)。
PD 调度器内置了多种智能调度策略 ,可根据不同业务场景和需求自动选择最优调度方案,包括基于负载的调度、基于成本的调度、基于优先级的调度等(126)。这些策略能够综合考虑集群的资源使用情况、数据分布、访问模式等因素,实现智能化的资源分配和负载均衡。
5.2 集群监控体系与性能指标
TiDB 的监控系统由Prometheus 和 Grafana 组成,从 Grafana 仪表板可监控 TiDB 的各种运行指标,包括系统资源监控指标、客户端连接和 SQL 操作指标、内部通信和 Region 调度指标等(128)。
关键监控指标包括:内存使用情况 统计每个 TiDB 实例的内存使用,分为进程占用内存和 Golang 堆内存;CPU 使用情况 统计每个 TiDB 实例的 CPU 使用情况(127);活跃连接数 所有 TiDB 实例的活跃连接数、每个 TiDB 实例的连接数;TiDB CPU 所有 TiDB 实例的平均 CPU 利用率、最大 CPU 利用率与最小 CPU 利用率的差值(138)。
其他重要指标还包括:打开文件描述符数 不同 TiDB 实例打开的文件描述符统计;goroutine 数 不同 TiDB 实例的 goroutine 数量;Go GC 持续时间 不同 TiDB 实例的 GC 时间统计;Go 线程数 不同 TiDB 实例的线程数量(130);Go GC 次数 每个 TiDB 实例的 Golang GC 执行次数;事务 Region 数量 90% 分位 单个事务写入的 Region 数量的 90% 分位;存储合并查询反馈 QPS 存储合并查询的 Feedback 信息的每秒操作数量(132)。
5.3 运维管理工具生态系统
TiDB 提供了完善的运维管理工具链 。TiDB Dashboard 是内建于 PD 组件的 Web UI(v4.0 + 版本),无需额外部署,提供监控、诊断和管理 TiDB 集群的功能(134)。TiDB Dashboard 提供了丰富的监控页面,包括性能概览仪表板,这是 TiDB v6.1.0 引入的性能分析和调优工具(138)。
TiUP 从 TiDB 4.0 开始作为包管理器,极大简化了 TiDB 生态系统中不同集群组件的管理,现在只需一行 TiUP 命令即可运行任何组件(137)。TiUP 是 TiDB 的组件管理平台,用于扩展 TiDB 生态边界,集成并管理 TiDB 生态的所有组件,方便用户进行多组件多版本管理,目前已广泛用于客户生产环境,支持部署、升级、扩缩容、备份恢复、配置变更等 TiDB 全生命周期管理的全自动化运维(139)。
运维管理还包括命令行工具和 API 接口。pd-ctl 提供了丰富的命令用于 PD 集群管理,如查看当前运行的调度器、添加或删除调度器等操作(122)。TiDB 还提供了完善的 SQL 接口用于集群管理和监控,用户可通过标准 SQL 语句查询系统状态、性能指标等信息。
5.4 生产环境部署与配置最佳实践
TiDB 生产环境部署有严格的配置要求。生产环境必须部署至少 3 个 PD 节点 ,TiKV 节点数应为奇数(推荐 3/5/7 个)以避免脑裂问题。安全加固包括启用 TLS 加密和设置 SQL 防火墙等生产环境必做措施(142)。
Kubernetes 环境部署需要先安装 TiDB Operator,生产级 TiDB 集群还需根据 TiDB 集群环境要求调整 Kubernetes 集群配置,并根据本地 PV 配置为集群配置本地 PV 以满足 TiKV 的低延迟本地存储需求(146)。
生产环境部署建议采用以下最佳实践:节点规划 PD 节点至少 3 个以保证高可用,TiKV 节点数为奇数避免脑裂,TiDB 节点可根据并发需求扩展;硬件配置 选择高性能服务器,配置充足的 CPU、内存和高速存储设备;网络优化 使用高速低延迟网络,建议使用 RDMA 网络降低 TiKV 延迟;存储配置 为 TiKV 配置高性能本地存储,为 TiFlash 配置大容量存储设备;安全配置启用 TLS 加密、设置合理的访问控制策略、定期审计和监控。
5.5 故障诊断与性能优化方法论
TiDB 提供了系统化的故障诊断和性能优化方法 。性能瓶颈诊断通过比较事务中平均 SQL 处理延迟与 TiDB 连接空闲时间来确定瓶颈是否在 TiDB(152)。性能优化包括:启用 prepared plan cache 和 JDBC 可大幅提升吞吐量、显著降低延迟、显著降低平均 TiDB CPU 利用率;在 TiKV 中启用 asyncio 和 raft-engine 可改善吞吐量性能(151)。
故障诊断流程包括:系统优化 故障排除可帮助识别系统性能瓶颈并进行优化;索引优化 如因索引缺失或使用不当导致慢查询,根据查询逻辑和表结构创建或调整索引;参数调整 通过后台登录数据库查看集群状态、锁、执行计划、索引、表健康度等信息,修改或优化相关参数(全局、当前会话)解决问题(149)。
性能优化方法论包括:查询优化 通过慢查询分析、执行计划分析等手段优化 SQL 查询;索引优化 根据查询模式创建合适的索引,优化索引使用策略;配置调优 调整 TiDB、TiKV、PD 的配置参数以适应特定工作负载;硬件优化 根据性能瓶颈增加硬件资源或升级硬件配置;架构优化根据业务发展调整集群架构,如增加节点、调整副本数量等。
5.6 安全管理与权限控制机制
TiDB 的权限管理系统基于MySQL 5.7 ,支持数据库对象的细粒度访问控制,同时引入了 MySQL 8.0 的 RBAC(基于角色的访问控制)和动态权限机制(153)。
RBAC 机制 中,角色是一系列权限的集合,支持创建角色、删除角色、向角色授予权限、向用户授予角色等操作(155)。TiDB 支持细粒度权限控制,可通过权限管理限制用户或角色对数据库的操作,包括控制用户或角色的读写权限、表级权限、列级权限等,使用 GRANT 语句授予权限、REVOKE 语句撤销权限(159)。
TiDB Dashboard 的安全机制 与 TiDB SQL 的账户系统一致,访问 TiDB Dashboard 的用户基于 TiDB SQL 用户权限进行认证和授权,因此 TiDB Dashboard 需要有限权限或仅需要只读权限(158)。这种设计确保了 Web 界面的访问控制与数据库的权限管理体系保持一致,简化了安全管理复杂度。
安全管理最佳实践包括:最小权限原则 为用户和应用分配最小的必要权限;角色管理 使用 RBAC 机制创建和管理角色,简化权限分配;访问控制 通过防火墙、TLS 加密等技术限制网络访问;审计日志 启用审计功能,记录重要操作和访问行为;定期审查定期审查用户权限和访问日志,及时发现和处理安全风险。
结语:TiDB 技术架构总结与发展展望
TiDB 作为一款领先的开源分布式 NewSQL 数据库,其技术架构展现了多项创新和优势。通过对 TiDB 技术文档的全面分析,我们可以得出以下核心结论:
技术架构优势:TiDB 采用清晰的三层架构设计,计算层、存储层、调度层各司其职,通过高效的通信机制实现协同工作。其 HTAP 架构通过 TiKV 行存储和 TiFlash 列存储的有机结合,实现了 OLTP 和 OLAP 的一体化处理,彻底改变了传统数据处理模式。
核心技术创新:TiDB 在多个关键技术领域实现了重要创新。TSO 时间戳分配机制确保了分布式事务的一致性;MVCC 多版本并发控制提供了优异的并发性能;基于 Percolator 的分布式事务模型保证了 ACID 特性;协处理器机制实现了计算的高效下推;Multi-Raft 架构提供了强大的分布式能力和故障恢复能力。
分布式能力卓越:TiDB 通过 Region 分片、Multi-Raft 协议、智能调度等技术,实现了强大的分布式处理能力。其自动故障恢复、负载均衡、数据迁移等机制确保了系统的高可用性和良好的扩展性,能够支撑 PB 级数据规模和高并发访问。
存储生态完善:TiDB 的存储生态系统包括 TiKV 行存储引擎和 TiFlash 列存储引擎,两者通过 Raft 协议实现强一致性的数据同步。这种设计不仅提供了优异的事务处理性能,还具备了强大的分析处理能力,满足了现代企业对 HTAP 数据库的需求。
管理运维便捷:TiDB 提供了完善的监控体系、运维工具链和安全管理机制。从 TiUP 包管理器到 TiDB Dashboard,从 Prometheus 监控到 RBAC 权限控制,整个管理运维体系设计得非常完善,大大降低了运维复杂度。
展望未来,TiDB 在以下几个方向具有广阔的发展前景:
技术发展趋势:随着云原生技术的发展,TiDB 在 Kubernetes 环境下的部署和管理将更加成熟;随着人工智能和机器学习技术的融合,TiDB 的智能查询优化和自适应调优能力将进一步提升;随着 5G 和物联网技术的普及,TiDB 在实时数据处理和边缘计算场景的应用将更加广泛。
应用场景拓展:TiDB 在金融、电商、物联网、智能制造等领域的应用将不断深化,特别是在需要高并发、强一致、可扩展的业务场景中,TiDB 将发挥越来越重要的作用。其 HTAP 能力将帮助更多企业实现实时业务决策和分析。
生态系统完善:TiDB 的开源生态系统将继续发展壮大,更多的工具和组件将被集成到 TiDB 生态中,包括数据迁移工具、备份恢复工具、性能分析工具等。同时,TiDB 与其他开源项目的集成将更加紧密,为用户提供更加完整的技术解决方案。
TiDB 作为分布式数据库技术的重要代表,其技术架构和实现机制为分布式数据库的发展提供了重要参考。随着技术的不断进步和应用场景的不断拓展,TiDB 有望在未来的分布式数据库市场中占据更加重要的地位,为企业数字化转型提供强有力的技术支撑。
参考资料
1 TimeStamp Oracle (TSO) in TiDBhttps://docs.pingcap.com/tidb/dev/tso
2 tso是什么组成的 - #25,来自 zhaokede - TiDB 的问答社区https://asktug.com/t/topic/1030699/25
3 How does a PD server generate timestamps?https://ask.pingcap.com/t/how-does-a-pd-server-generate-timestamps/49
4 Time Synchronization in Distributed Systems: TiDB's Timestamp Oraclehttps://www.pingcap.com/blog/how-an-open-source-distributed-newsql-database-delivers-time-services/
5 How to obtain the TSO of a TiDB cluster for use as the start-ts in a CDC changefeedhttps://ask.pingcap.com/t/how-to-obtain-the-tso-of-a-tidb-cluster-for-use-as-the-start-ts-in-a-cdc-changefeed/7193
6 TiCDC FAQshttps://docs.pingcap.com/tidb/v6.5/ticdc-faq/
7 Large Scale OLTP\nDatabases ar(pdf)https://static.pingcap.com/files/2024/05/15225840/Use-Case-Large-Scale-OLTP.pdf
8 TiDB Optimistic Transaction Modelhttps://docs-archive.pingcap.com/tidb/v3.0/optimistic-transaction
9 TiDB 如何实现分布式事务的 ACID 特性?_编程语言-CSDN问答https://ask.csdn.net/questions/8824854
10 TiDB-从0到1-分布式事务 - 墨天轮https://www.modb.pro/db/1795262908145930240
11 TIDB:分布式事务算法Percolator学习笔记_51CTO博客_tidb 分布式事务https://blog.51cto.com/tidb/5579337
12 TiDB事务方案_tidb分布式事务-CSDN博客https://blog.csdn.net/qq_40586495/article/details/128818718
13 TiDB分布式事务处理机制-阿里云开发者社区https://developer.aliyun.com/article/1463466
14 Async Commit 原理介绍-腾讯云开发者社区-腾讯云https://cloud.tencent.com/developer/article/1819795?areaSource=106000.9
15 TiDB Distributed eXecution Framework (DXF)https://docs.pingcap.com/tidb/stable/tidb-distributed-execution-framework/
16 Exploring TiDB's Distributed eXecution Framework (DXF)https://www.pingcap.com/event/exploring-tidbs-distributed-execution-framework-dxf/
17 mysql Schemahttps://docs.pingcap.com/tidb/stable/mysql-schema
18 TiDB 8.1.1 Release Noteshttps://docs.pingcap.com/tidb/stable/release-8.1.1/
19 TiDB 7.4.0 Release Noteshttps://docs.pingcap.com/tidb/dev/release-7.4.0
20 TiDB 7.2.0 Release Noteshttps://docs.pingcap.com/tidb/v8.1/release-7.2.0/
21 TiDB - 体系架构 - 学弟Craze - 博客园https://www.cnblogs.com/jiamiing/p/19025190
22 博客 - TiDB Coprocessor 学习笔记 | TiDB 社区https://tidb.net/blog/59ac27b0
23 Beginner's Question: What is a Coprocessor?https://ask.pingcap.com/t/beginners-question-what-is-a-coprocessor/2171
24 TiKV Coprocessorhttps://tikv.github.io/tikv-dev-guide/understanding-tikv/coprocessor/intro.html
25 Coprocessor in TiKVTiDB 的 Coprocessor 概念灵感来自于 HBase, 目前 TiDB - 掘金https://juejin.cn/post/6844903784821309454
26 TiKV 源码解析系列:向量化计算与表达式计算框架-CSDN博客https://blog.csdn.net/weixin_39895862/article/details/116013181
27 TiDB 源码阅读(六):TiDB Coprocessor 源码解析 - Jiajun的技术笔记https://jiajunhuang.com/articles/2025_10_12-tidb_source_code_coprocessor.md.html
28 TiDB Optimistic Transaction Modelhttps://docs.pingcap.com/tidbcloud/optimistic-transaction
29 TiDB快照隔离:MVCC在分布式系统实现-CSDN博客https://blog.csdn.net/gitblog_00671/article/details/151825448
30 Understanding MVCC in TiDB for High-Concurrency Applicationshttps://www.pingcap.com/article/understanding-mvcc-in-tidb-for-high-concurrency-applications/
31 Questions about the Commit Phase in TiDB 2PChttps://ask.pingcap.com/t/questions-about-the-commit-phase-in-tidb-2pc/3507
32 How does TiDB achieve repeatable read?https://ask.pingcap.com/t/how-does-tidb-achieve-repeatable-read/2755
33 Ensuring Data Consistency in Distributed Databases | TiDBhttps://www.pingcap.com/article/ensuring-data-consistency-in-distributed-databases/
34 Ensuring Data Consistency in Finance with Distributed SQLhttps://www.pingcap.com/article/ensuring-data-consistency-in-finance-with-distributed-sql/
35 TiKV RocksDB 读写原理整理 - TiDB 社区技术月刊 | TiDB Bookshttps://tidb.net/book/tidb-monthly/2023/2023-02/feature-indepth/tikv-rocksdb
36 RocksDB 简介_rocketsdb-CSDN博客https://blog.csdn.net/junior77/article/details/121796044
37 【赵渝强老师】TiDB的MVCC机制-腾讯云开发者社区-腾讯云https://cloud.tencent.com/developer/article/2517772
38 MVCC可以保存多少历史版本? - TiDB 的问答社区https://asktug.com/t/topic/1006694
39 tidbmvcc多版本保存机制及其对性能的影响https://blog.51cto.com/u_15550868/5570697
40 Partitioned Raft KVhttps://docs-archive.pingcap.com/tidb/v7.3/partitioned-raft-kv
41 Split Regionhttps://docs.pingcap.com/tidb/dev/sql-statement-split-region/
42 Tune Region Performancehttps://docs.pingcap.com/tidb/dev/tune-region-performance/
43 TiDB数据分片:Region划分与负载均衡-CSDN博客https://blog.csdn.net/gitblog_00737/article/details/151825670
44 Load Base Splithttps://docs.pingcap.com/tidb/v8.5/configure-load-base-split/
45 Best Practices for TiKV Performance Tuning with Massive Regionshttps://docs-archive.pingcap.com/tidb/v6.4/massive-regions-best-practices/
46 How is the merging of regions initiated?https://ask.pingcap.com/t/how-is-the-merging-of-regions-initiated/8607
47 Table Attributeshttps://docs.pingcap.com/tidbcloud/table-attributes/
48 TiDB一致性协议:Multi-Raft实现细节-CSDN博客https://blog.csdn.net/gitblog_00862/article/details/151825431
49 博客 - TiKV 组件 Raft 协议底层实现深度解析 | TiDB 社区https://tidb.net/blog/9584aa2f
50 TiKV Overviewhttps://docs.pingcap.com/tidb/v5.4/tikv-overview
51 Multi-rafthttps://tikv.org/deep-dive/scalability/multi-raft/
52 TiDB:Raft与Multi Raft_tidb mutiraft-CSDN博客https://blog.csdn.net/JSWANGCHANG/article/details/122534755
53 以TiDB为例解析云原生数据库 - VitoChen - 博客园https://www.cnblogs.com/vitochen/p/18701404
54 Automatic Failover | PingCAP Docshttps://docs.pingcap.com/tidb-in-kubernetes/v1.3/use-auto-failover
55 TiDB 架构及设计实现-CSDN博客https://blog.csdn.net/weixin_33763244/article/details/92512980
56 High Availability in TiDB Cloud Starter and Essentialhttps://docs.pingcap.com/tidbcloud/serverless-high-availability/
57 15分中了解TIDB - TiDB 的问答社区https://asktug.com/t/topic/1015849
58 Automatic Failoverhttps://docs-archive.pingcap.com/tidb-in-kubernetes/v1.0/use-auto-failover/
59 TiDB 中文手册\nPingCAP Inc.\n20230(pdf)https://docs-download.pingcap.com/pdf/tidb-v3.0-zh-manual.pdf
60 Kubernetes 上的 TiDB 集群故障自动转移_节点宕机,有状态服务pod无法自动迁移-CSDN博客https://blog.csdn.net/weixin_42241611/article/details/125678288
61 TiProxy Load Balancing Policieshttps://docs.pingcap.com/tidb/dev/tiproxy-load-balance/
62 TiDB热点问题解决:数据分布均衡策略-CSDN博客https://blog.csdn.net/gitblog_00477/article/details/151823774
63 博客 - TiDB:TiKV 副本搬迁原理及常见问题 | TiDB 社区https://tidb.net/blog/c25328d1
64 tidb扩缩容原理及常见问题https://blog.csdn.net/TiDBer/article/details/141477547
65 TiDB数据分片:Region划分与负载均衡-CSDN博客https://blog.csdn.net/gitblog_00737/article/details/151825670
66 TiDB Data Migration (DM) Best Practiceshttps://docs.pingcap.com/tidb/v6.5/dm-best-practices
67 Placement Ruleshttps://docs.pingcap.com/tidb/v8.4/configure-placement-rules/
68 TiDB Schedulinghttps://docs.pingcap.com/tidb/stable/tidb-scheduling/
69 Placement Rules in SQLhttps://docs.pingcap.com/tidb/v7.5/placement-rules-in-sql/
70 Schedule Replicas by Topology Labelshttps://docs-archive.pingcap.com/tidb/v4.0/schedule-replicas-by-topology-labels
71 TiDB集群方案与Replication原理_tidb集群方案与replication原理 csdn-CSDN博客https://blog.csdn.net/ajffaj/article/details/127157286
72 博客 - TiDB 数据库 placement-rules 使用指南 | TiDB 社区https://tidb.net/blog/26a9c334
73 High Availability with Multi-AZ Deploymentshttps://docs.pingcap.com/tidbcloud/high-availability-with-multi-az
74 突破数据可靠性极限:TiDB高可用架构设计与故障自愈指南-CSDN博客https://blog.csdn.net/gitblog_00595/article/details/148944797
75 DR Auto-Sync:TiDB 同城两中心自适应同步复制技术解析_tidb数据库双活-CSDN博客https://blog.csdn.net/weixin_42241611/article/details/147014095
76 博客 - TiDB 数据库核心原理与架构_Lesson 01 TiDB 数据库架构概述课程整理 | TiDB 社区https://tidb.net/blog/beeb9eaf
77 High Availability FAQshttps://docs.pingcap.com/tidb/v5.4/high-availability-faq
78 TiDB_完全acid兼容的数据库-CSDN博客https://blog.csdn.net/g1607058603/article/details/88845664
79 TiDB日常使用规范概述 作为一家全球性的连锁餐饮企业,公司在处理海量数据、复杂业务流程方面面临巨大的挑战。为了解决这些 - 掘金https://juejin.cn/post/7526761867457462323
80 TiCDC Data Replication Capabilitieshttps://docs.pingcap.com/tidb/v6.5/ticdc-data-replication-capabilities/
81 Overviewhttps://tikv.org/docs/dev/reference/architecture/overview/
82 博客 - TiKV 组件 Raft 协议底层实现深度解析 | TiDB 社区https://tidb.net/blog/9584aa2f
83 【TiDB系列文章】TiKV Server 介绍_tikv-server-CSDN博客https://blog.csdn.net/weixin_67032322/article/details/144445749
84 TiKV Overviewhttps://docs.pingcap.com/tidb/dev/tikv-overview
85 Conceptshttps://tikv.org/docs/3.0/concepts/overview/
86 Architecturehttps://tikv.org/docs/dev/reference/architecture/introduction/
87 TiKV 组件原理_悟空聊架构的技术博客_51CTO博客https://blog.51cto.com/passjava/14284231
88 TiDB数据压缩:分布式数据库存储空间优化全景指南-CSDN博客https://blog.csdn.net/gitblog_00423/article/details/151841637
89 TiDB Best Practices on Public Cloudhttps://docs.pingcap.com/tidb/stable/best-practices-on-public-cloud/
90 博客 - TiDB 单机三节点混合部署的最佳实践 | TiDB 社区https://tidb.net/blog/f4b0d262
91 TIDB 优化--TiKV 性能参数调优_tikv cpu控制参数-CSDN博客https://blog.csdn.net/weixin_36135773/article/details/79767379
92 Tune TiKV Memory Parameter Performancehttps://docs.pingcap.com/tidb/stable/tune-tikv-memory-performance/
93 TiKV存储引擎优化:RocksDB集成与性能调优-CSDN博客https://blog.csdn.net/gitblog_00619/article/details/150703242
94 tikv学习1 - 吃草的青蛙 - 博客园https://www.cnblogs.com/tiantao36/p/18843906
95 TiDB存储引擎深度剖析:TiKV与TiFlash协同-CSDN博客https://blog.csdn.net/gitblog_00701/article/details/151819936
96 TiFlash 源码阅读(一)TiFlash 存储层概览 | TiDB Bookshttps://tidb.net/book/tidb-monthly/2022/2022-04/update/tiflash-storage
97 TiFlash DeltaTree 存储引擎设计及实现分析 - Part 1 | TiDB Bookshttps://tidb.net/book/book-rush/features/tiflash-code/tiflash-deltatree
98 不同存储结构的文件磁盘io操作次数_TiDB 的列式存储引擎是如何实现的?-CSDN博客https://blog.csdn.net/weixin_39616477/article/details/111126077
99 转帖9.2 TiFlash 架构与原理_51CTO博客_tiflash 数据结构https://blog.51cto.com/u_11529070/9218121
100 TiFlash 源码解读(四) | TiFlash DDL 模块设计及实现分析_TiDB社区干货传送门的技术博客_51CTO博客https://blog.51cto.com/tidb/5570636
101 TiFlash Overviewhttps://docs.pingcap.com/tidb/v8.1/tiflash-overview/
102 8.存储引擎TiFlash_用tiflash后clickhouse语法用不用改-CSDN博客https://blog.csdn.net/phoenix9311/article/details/110439190
103 以TiDB为例解析云原生数据库 - VitoChen - 博客园https://www.cnblogs.com/vitochen/p/18701404
104 深入解析TiFlash:TiDB生态中的HTAP利器-易源AI资讯 | 万维易源https://www.showapi.com/news/article/6706c7dc4ddd79f11a3b655e
105 python项目连接kingbase_mob6454cc769a22的技术博客_51CTO博客https://blog.51cto.com/u_16099314/12749519
106 【赵渝强老师】TiDB的列存引擎:TiFlash-腾讯云开发者社区-腾讯云https://cloud.tencent.cn/developer/article/2514157
107 Use an HTAP Clusterhttps://docs.pingcap.com/tidbcloud/use-htap-cluster/
108 以TiDB为例解析云原生数据库 - VitoChen - 博客园https://www.cnblogs.com/vitochen/p/18701404
109 博客 - 实战丨证券 HTAP 混合业务场景的难点问题应对 | TiDB 社区https://tidb.net/blog/537fcebb
110 8.存储引擎TiFlash_用tiflash后clickhouse语法用不用改-CSDN博客https://blog.csdn.net/phoenix9311/article/details/110439190
111 HTAP 数据库实战:如何用 TiDB 实现 OLTP 与 OLAP 的无缝切换_tidb olap oltp 如何实现-CSDN博客https://blog.csdn.net/2503_92849134/article/details/149760357
112 TiDB + TiFlash : 朝着真 HTAP 平台演进-CSDN博客https://blog.csdn.net/chigangdou7652/article/details/100928058
113 TiDB与TiFlash协同:HTAP场景最佳实践-CSDN博客https://blog.csdn.net/gitblog_00440/article/details/151827524
114 超强HTAP数据库TiDB:实时分析+事务处理一体化-CSDN博客https://blog.csdn.net/gitblog_00427/article/details/151820197
115 tidb 表多少数据量才触发索引_mob6454cc769a22的技术博客_51CTO博客https://blog.51cto.com/u_16099314/13062727
116 TiDB:掌握开源NewSQL数据库核心架构与实践-CSDN博客https://blog.csdn.net/weixin_26907223/article/details/150574744
117 Explore HTAPhttps://docs.pingcap.com/tidb/v6.1/explore-htap
118 tidb为什么比mysql快 tidb优点_doscommand的技术博客_51CTO博客https://blog.51cto.com/u_12935/14076379
119 TiDB数据库的HTAP革命-易源AI资讯 | 万维易源https://www.showapi.com/news/article/66f4b53b4ddd79f11a1a7ab7
120 分布式数据库TiDB架构及资源调度隔离简介_t-dbse-CSDN博客https://blog.csdn.net/qq_22727355/article/details/78795588
121 TiDB 最佳实践系列(二)PD 调度策略最佳实践_max-snapshot-count-CSDN博客https://blog.csdn.net/weixin_42241611/article/details/130200116
122 Best Practices for PD Schedulinghttps://docs.pingcap.com/tidb/dev/pd-scheduling-best-practices/
123 TiDB数据分片:Region划分与负载均衡-CSDN博客https://blog.csdn.net/gitblog_00737/article/details/151825670
124 TiDB Schedulinghttps://docs.pingcap.com/tidbcloud/tidb-scheduling/
125 【TiDB 最佳实践系列】PD 调度策略最佳实践-CSDN博客原文来源: https://tidb.本文将详细介绍 PD - 掘金https://juejin.cn/post/7290457366121480244
126 TiDB中PD调度器概述-阿里云开发者社区https://developer.aliyun.com/article/1463451
127 TiDB Monitoring Metricshttps://docs.pingcap.com/tidb/v6.1/grafana-tidb-dashboard
128 TiDB Monitoring FAQs | PingCAP Docshttps://docs.pingcap.com/tidb/v7.1/monitor-faq
129 TiDB Dashboard Monitoring Pagehttps://docs.pingcap.com/tidb/dev/dashboard-monitoring
130 TiDB Monitoring Metricshttps://docs-archive.pingcap.com/tidb/v3.0/grafana-tidb-dashboard
131 TiDB Dashboard中关键监控指标 - TiDB 的问答社区https://asktug.com/t/topic/1046245
132 TiDB 重要监控指标详解_怎么看tidb的gc时间-CSDN博客https://blog.csdn.net/junior77/article/details/121692324
133 监控系统中指标上报方式pullpushhttps://blog.51cto.com/u_12196/13531701
134 Deploy TiDB Dashboardhttps://docs.pingcap.com/tidb/v6.1/dashboard-ops-deploy
135 Access TiDB Dashboardhttps://docs.pingcap.com/tidb/dev/dashboard-access
136 TiDB Dashboard Introductionhttps://docs.pingcap.com/tidb/v6.1/dashboard-intro
137 TiUP Overviewhttps://docs.pingcap.com/tidb/dev/tiup-overview
138 TiDB Dashboard Monitoring Pagehttps://docs.pingcap.com/tidb/dev/dashboard-monitoring
139 TiDB\nTiDB 开源分布式关系型数据库 TiDB PR(pdf)https://download.pingcap.com/TiDB_ProductPortfolio_2020.pdf
140 博客 - 知乎 TiDB 实践系列 | tidb-operator 生产实战篇(TiDB v8) | TiDB 社区https://tidb.net/blog/e32b968d
141 Deploy a TiDB Cluster Using TiUPhttps://docs.pingcap.com/tidb/stable/production-deployment-using-tiup/
142 TiDB集群搭建与运维指南_tidb数据库搭建-CSDN博客https://blog.csdn.net/jjj_web/article/details/150224465
143 博客 - 离线部署tidb-8.5.3 | TiDB 社区https://tidb.net/blog/a052a61c
144 WiFi万能钥匙鲲鹏服务器部署 TiDB 集群实战指南_TiDB社区干货传送门的技术博客_51CTO博客https://blog.51cto.com/tidb/13963578
145 TiDB单机模拟部署生产环境集群(闭坑实践,亲测有效)_tidb单机部署用于生产-CSDN博客https://blog.csdn.net/qq_43403676/article/details/124906989
146 TiDB in Kubernetes 用户文档 PingCA(pdf)https://docs-download.pingcap.com/pdf/tidb-in-kubernetes-v1.2-zh-manual.pdf
147 TiDB升级全流程与后问题深度排查:从平滑迁移到故障修复-CSDN博客https://blog.csdn.net/gitblog_00389/article/details/148944800
148 TiDB Troubleshooting Maphttps://docs.pingcap.com/tidb/v5.4/tidb-troubleshooting-map/
149 【TiDBer 唠嗑茶话会 138】你有哪些 TiDB 故障排除经验? - TiDB 的问答社区https://asktug.com/t/topic/1033162
150 TiDB常见故障和问题的处理_tidb数据库并不好-CSDN博客https://blog.csdn.net/weixin_43871785/article/details/133577187
151 Overview for Analyzing and Tuning Performancehttps://docs.pingcap.com/tidbcloud/tidb-cloud-tune-performance-overview/
152 Performance Analysis and Tuninghttps://docs.pingcap.com/tidb/v8.3/performance-tuning-methods/
153 Securityhttps://docs.pingcap.com/tidbcloud/security-concepts/
154 产品文档 | 平凯星辰(pdf)https://download.pingcap.com.cn/file/PingCAP-Database-Security-White-Paper-V7.1.pdf
155 Role-Based Access Controlhttps://docs.pingcap.com/tidb/stable/role-based-access-control
156 Privilege Managementhttps://docs-archive.pingcap.com/tidb/v2.1/privilege-management
157 自主访问权限控制-分布式融合数据库HTAP-私有云产品-安全配置手册-访问控制 - 天翼云https://www.ctyun.cn/document/10021453/10785668
158 Secure TiDB Dashboard | PingCAP Docshttps://docs.pingcap.com/tidb/v6.1/dashboard-ops-security
159 TiDB的安全和权限管理_tidb数据库如何限制导出权限-CSDN博客https://blog.csdn.net/weixin_43871785/article/details/133544777