( 一 ) RDD的处理过程
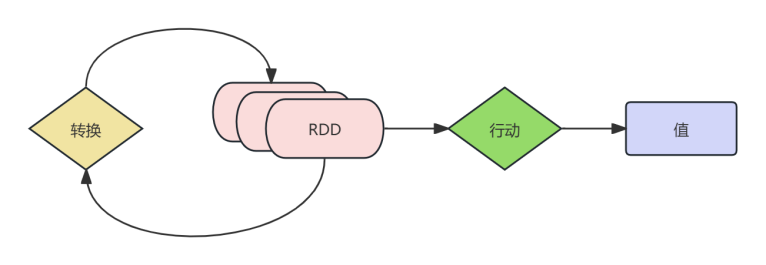
RDD经过一系列的"转换"操作,每一次转换都会产生不同的RDD,以供给下一次"转换"操作使用,直到最后一个RDD经过"行动"操作才会真正被计算处理。
- 延迟。RDD中所有的转换都是延迟的,它们并不会直接计算结果。相反,他们只是记住这些应用到基础数据集上的转换动作。只有当发生要求返回结果给driver的动作时,这些转换才会真正运行。
- 血缘关系。一个RDD运算之后,会产生新的RDD。
RDD经过一系列的"转换"操作,每一次转换都会产生不同的RDD,以供给下一次"转换"操作使用,直到最后一个RDD经过"行动"操作才会真正被计算处理。