首先在finalshell中打开第一个虚拟机,打开文件/opt/software,cd进入,准备解压文件spark-3.1.1-bin-hadoop3.2.tgz
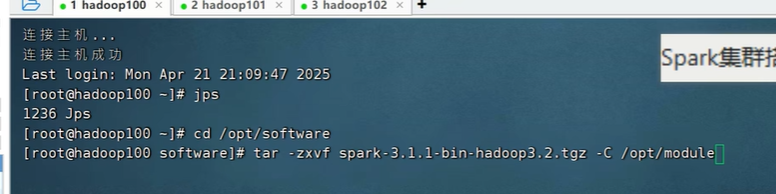 在/opt/module中重命名文件为spark-yarn
在/opt/module中重命名文件为spark-yarn
修改环境变量:在/etc/profile.d中打开my_env.sh文件修改
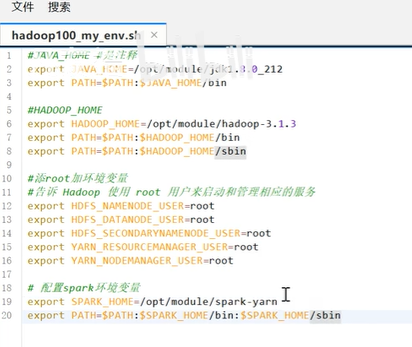
使用source /etc/profile命令使其重新生效
使用echo $PATH命令验证
使用xsync /etc/profile.d命令同步

找到hadoop的配置文件 /opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml
添加如下配置
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
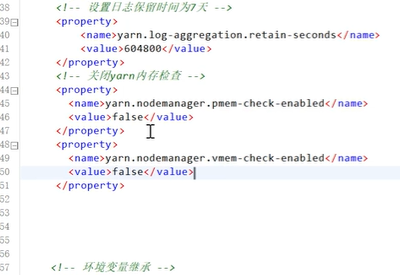
使用xsync /opt/module/hadoop-3.1.3/etc/hadoop/同步
修改yarn配置
workers.tempalte 改成 workers,spark-env.sh.template 改成 spark-env.sh,
spark-defaults.conf.template 改成 spark-defaults.conf。
然后,在workers文件中添加
FanLing001
FanLing002
FanLing003
在spark-env.sh文件中,添加如下
SPARK_MASTER_HOST=FanLing001
SPARK_MASTER_PORT=7077
HADOOP_CONF_DIR=/opt/module/hadoop-3.1.3/etc/hadoop
YARN_CONF_DIR=/opt/module/hadoop-3.1.3/etc/hadoop
export SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://FanLing001:8020/directory"
在spark-defaults.conf文件中,添加如下
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop100:8020/directory
spark.yarn.historyServer.address=FanLing001:18080
spark.history.ui.port=18080
同步配置文件到其他设备。xsync /opt/module/spark-yarn/sbin