
贪吃蛇脱缰自动向右走:脱缰的野蛇
#include <curses.h>
#include <stdlib.h>
struct snake{
int hang;
int lie;
struct snake *next;
};
struct snake *head;
struct snake *tail;
void initNcurse()
{
initscr();
keypad(stdscr,1);
}
int hasSnakeNode(int i,int j)
{
struct snake *p;
p = head;
while(p != NULL){
if(p->hang==i && p->lie==j){
return 1;
}
p=p->next;
}
return 0;
}
void gamepic()
{
int hang;
int lie;
move(0,0);
for(hang=0;hang<20;hang++){
if(hang == 0){
for(lie=0;lie<20;lie++){
printw("--");
}
printw("\n");
}
if(hang>=0 && hang<=19){
for(lie=0;lie<=20;lie++){
if(lie==0||lie==20){
printw("|");
}else if(hasSnakeNode(hang,lie)){
printw("\[\]");
}
else{
printw(" ");
}
}
printw("\n");
}
if(hang == 19){
for(lie=0;lie<20;lie++){
printw("--");
}
printw("\n");
}
}
printw("by shijintao");
printw("\n");
}
void addNode()
{
struct snake *new;
new =(struct snake *)malloc(sizeof(struct snake));
new->hang=tail->hang;
new->lie=tail->lie+1;
tail->next = new;
tail = new;
new->next = NULL;
}
void initSnake()
{
struct snake *p;
while(head != NULL){
p=head;
head=head->next;
free(p);
}
head = (struct snake *)malloc(sizeof(struct snake));
head->hang=2;
head->lie=2;
head->next=NULL;
tail = head;
addNode();
addNode();
}
void deleteNode()
{
struct snake *p;
p = head;
head = head->next;
free(p);
}
void moveSnake()
{
addNode();
deleteNode();
if(tail->hang==0||tail->hang==20||tail->lie==20||tail->lie==0){
initSnake();
}
}
int main()
{
int con;
initNcurse();
initSnake();
gamepic();
while(1){
moveSnake();
gamepic();
refresh();
usleep(100000);
}
getch();
endwin();
return 0;
}

这边最主要改动的代码地方在于main函数里面的
主要是我们要先想一下如果只是一味的想让这个蛇自己往右边走(这个右边就是代码效果,也没有设置方向,就是新节点的插入导致一个向右边走的效果),肯定要把监测右方向键给去掉,然后死循环就可以实现l,不断的moveSnake(不断的addNode,deleteNode)
while(1){
moveSnake();
gamepic();
refresh();
usleep(100000);
}
原始代码中,getch() 函数的调用确实会导致屏幕刷新。这是因为 getch() 在等待用户输入时,会隐式触发一次屏幕刷新 。
1. getch() 的隐式刷新机制
在 ncurses 中,getch() 不仅用于获取用户输入,还会执行以下操作:
- 刷新屏幕 :在等待按键时,ncurses 会自动将当前缓冲区内容渲染到屏幕上。
- 处理输入事件 :捕获用户按下的键并返回其 ASCII 码(或特殊键的编码,如方向键)。
因此,当你在循环中调用 getch() 时,即使没有显式调用 refresh(),屏幕也会被刷新。这解释了为什么你之前的代码能正常显示画面。
2. 为什么现在需要显式调用 refresh() ?
在你的新代码中,循环结构发生了变化:
while(1){
moveSnake(); // 更新蛇位置
gamepic(); // 绘制画面
refresh(); // 显式刷新屏幕
usleep(100000); // 延时控制速度}
这里的关键区别是:蛇的移动不再依赖用户输入 ,而是通过定时器自动更新(usleep())。因此:
- 如果没有 refresh(),绘制操作(gamepic())的结果只会停留在缓冲区,无法显示。
- usleep() 是纯延时函数,不会触发屏幕刷新,必须手动调用 refresh()。
3. 两种实现方式的对比
|------------------------------------------|-------------------|
| 旧代码(依赖 getch() ) | 新代码(自动移动) |
| 蛇仅在用户按键时移动 | 蛇自动持续移动 |
| getch() 隐式刷新屏幕 | 必须显式调用 refresh() |
| 游戏节奏由用户控制 | 游戏节奏由 usleep() 控制 |
4. 最佳实践建议
- 始终显式调用 refresh() :即使在有 getch() 的场景中,显式刷新能让代码逻辑更清晰,避免依赖隐式机制。
- 分离输入处理和画面刷新 :在自动移动的游戏中,用户输入(如方向键)和屏幕刷新是独立的操作,需要分别处理。
总结
原始代码之所以能正常显示,是因为 getch() 在等待输入时隐式刷新了屏幕。而在新的自动移动实现中,由于没有依赖 getch(),必须通过 refresh() 手动刷新屏幕才能看到蛇的移动效果。这是 ncurses 编程中的一个常见细节,理解它有助于写出更健壮的代码!
贪吃蛇风骚走位之支持方向变换
那么问题来了,方向的改变要监测键盘的按键需要一个while(1)循环(不断的检测用户的输入) 还有,蛇的脱缰的走也需要一个while(1)循环支持,就是这两个while(1)需要同时跑,那么我们现在单线程,就是目前无法一心二用,所以我们还做不了,需要学习多线程。
Linux多线程概念引入及编码实现
我们做贪吃蛇的时候不是要需要控制按方向键和moveSnake(脱缰的野蛇)且 要同时运行且都是要用while死循环去进行接收吗,那么我们单线程就无法做到了,这个时候要学习多线程,这样我们就是可以同时执行两个死循环。
所以我们先学习一下多线程的基本原理
想让我们先看个单线程的例子
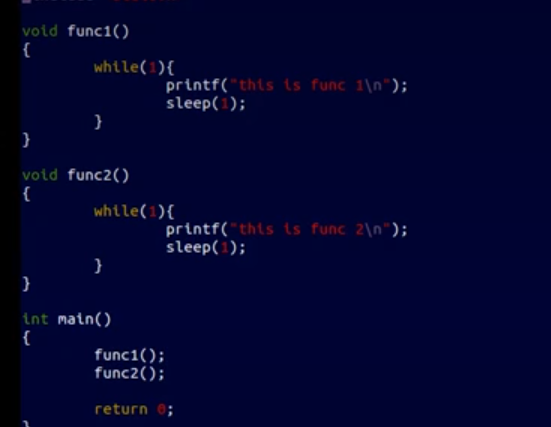
我想通过这个单线程的返回结果,和等下多线程的返回结果做对比就很容易理解多线程的意思了;
因为在单线程环境下,函数是顺序执行的。当调用 FUNC1 时,即使里面有sleep操作,它也只是让执行流程暂停一下,并不会切换到其他函数执行,所以会先输出this is FUNC1,等待sleep时间过后再继续输出this is FUNC1。
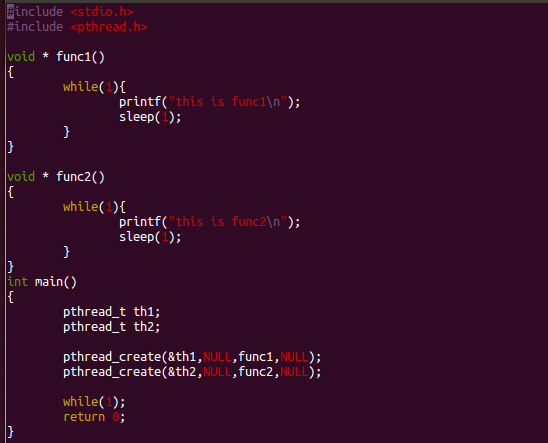
假如现在这段代码变成了多线程
在多线程环境下,当一个线程执行到类似sleep操作时,它会暂停执行一段时间,这时操作系统会调度其他可运行的线程。
假设存在FUNC1和FUNC2两个函数分别在不同线程中执行:
- 当
FUNC1所在线程执行到sleep时,该线程会进入休眠状态,此时操作系统会寻找其他可运行的线程,很可能就会找到FUNC2所在线程(如果FUNC2线程处于可运行状态),然后开始执行FUNC2。 - 当
FUNC2执行到类似sleep操作后,它也会暂停,操作系统又会重新调度,此时FUNC1线程休眠时间结束的话,可能会继续执行FUNC1;如果FUNC1还没结束休眠,且还有其他可运行线程,就可能会执行其他线程。
这种线程间的切换和执行顺序,取决于操作系统的线程调度机制,没有办法精确地预测哪个线程会在特定时刻执行,除非使用线程同步机制(如锁、条件变量、信号量等)来控制线程的执行顺序。例如在 Java 中,可以使用join方法让一个线程等待另一个线程执行完毕;或者使用同步块和wait、notify方法来控制线程间的协作和执行顺序。
通过下面的例子学习一下
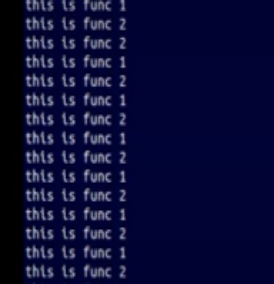
运行后是这样的 一直循环这个两句话,就是说不一定每次调用的都是一样的(在多核是同时运行,在单核是他们去争夺cpu资源),但是可以保证他们可以同时运行的(这就够了)
- #include <pthread.h> :引入 POSIX 线程库的头文件,该库用于在 C 语言中实现多线程编程,后续用到的 pthread_t 类型以及 pthread_create 等函数声明都在这个头文件中。
- func1 和 func2 是两个线程函数。它们的返回类型为 void * ,这是 POSIX 线程库中线程函数的标准返回类型要求。
- 每个函数内部都有一个无限循环 while(1) 。在循环中,先通过 printf 输出相应的提示信息("this is func1\n" 或 "this is func2\n" ),然后调用 sleep(1) 让线程暂停 1 秒钟。这使得线线程变量声明 :pthread_t th1; 和 pthread_t th2; 声明了两个 pthread_t 类型的变量,pthread_t 用于标识线程,th1 和 th2 分别用来标识即将创建的两个不同线程。
- 线程创建 :
- pthread_create(&th1,NULL,func1,NULL); 调用 pthread_create 函数创建了一个新线程,该线程的标识符存储在 th1 中。第二个参数 NULL 表示使用默认的线程属性;第三个参数 func1 指明这个新线程要执行的函数是 func1 ;第四个参数 NULL 表示不向 func1 函数传递额外参数 。
- 同理,pthread_create(&th2,NULL,func2,NULL); 创建了另一个线程,其标识符为 th2 ,执行函数为 func2 。
- 无限循环与程序结束 :while(1); 是一个无限循环,这里的作用是防止 main 函数执行结束。因为在多线程程序中,如果主线程(main 函数所在线程)执行完毕退出,那么其他子线程也会被操作系统强制终止。通过这个无限循环,让主线程一直保持运行状态,从而使得创建的 th1 和 th2 线程能持续执行它们各自的任务。return 0; 理论上不会执行到,不过按照 main 函数的规范,需要有返回值声明。
整体功能
这段代码实现了一个简单的多线程程序,创建了两个线程分别执行 func1 和 func2 函数,这两个线程会并发地不断打印各自的提示信息并间隔 1 秒。但代码存在一些不足,比如没有对线程的返回值进行处理,也没有合理的方式来终止线程或主线程,实际应用中可以进一步完善,比如添加信号处理机制来结束程序等 。
- 程会不断重复打印信息并间隔 1 秒。
