FunASR是一个由阿里云智能团队开源的语音识别工具。它旨在通过发布工业级语音识别模型的训练和微调,促进学术研究和工业应用之间的交流,推动语音识别生态的发展。

今天来试着搭建下。
1、先贴上github地址。
https://github.com/modelscope/FunASR2、创建环境
conda create -n funasr python==3.10后台回复"conda"可拿到Ubuntu conda安装包
3、安装
安装方式我看着有三种,一种docker安装。一种源码安装。一种直接安装
咱们先来体验下直接安装的方式
pip install -U funasr4、安装比较顺利,直接安装成功。试着运行下。
funasr ++model=paraformer-zh ++vad_model="fsmn-vad" ++punc_model="ct-punc" ++input=asr_example_zh.wav5、运行后会先下载模型
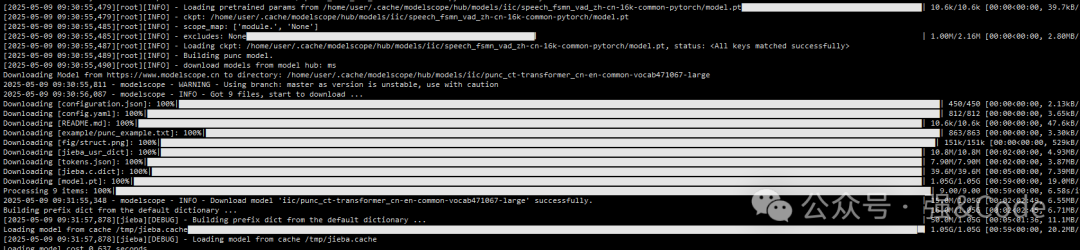
这个模型比较小,下载得很快。
接着再试下。报错了,看着是参数不对。
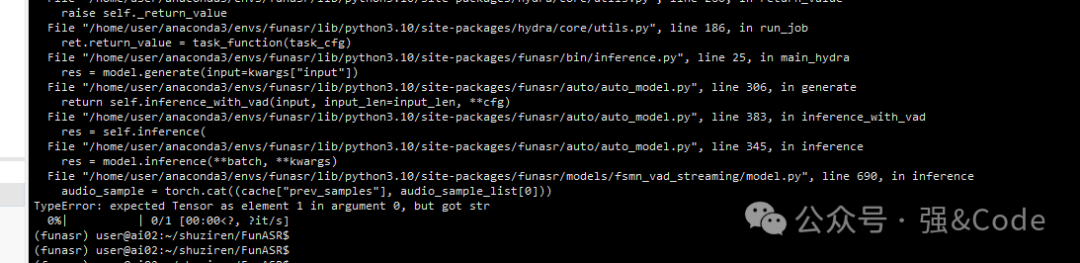
5、代码执行下试试
from funasr import AutoModel# paraformer-zh is a multi-functional asr model# use vad, punc, spk or not as you needmodel = AutoModel(model="paraformer-zh", vad_model="fsmn-vad", punc_model="ct-punc", # spk_model="cam++", )res = model.generate(input=f"{model.model_path}/example/asr_example.wav", batch_size_s=300, hotword='魔搭')print(res)
OK,完美运行。
搜到一个funasr的网站,不知道是不是官网,上面提供安装包https://funasr.com/#/
这就是简单的复现方法,如果大家在搭建的过程中有什么问题的话,欢迎留言,大家一起讨论学习。