文章目录
- [0 前言](#0 前言)
- [1 广告推荐的基本流程](#1 广告推荐的基本流程)
- [2 场景和baseline初步框定](#2 场景和baseline初步框定)
- [3 一个入门小例子感受--淘宝用户购物行为数据可视化分析](#3 一个入门小例子感受--淘宝用户购物行为数据可视化分析)
- [4 基础项目选型](#4 基础项目选型)
- 推荐资料
- 后记
0 前言
一起学习吖~~
一个好的推荐项目,首先不能是宏大全面囊括的而应该是针对某场景问题针对性拓展的,因此我们应该有场景->baseline ->改进点->效果这几个部分。其中建议说出:每个部分为啥会work?为啥别的别的方法不行?优化方案的增量来自啥(对信息的挖掘还是引入新的信息)?虽然你选了baseline但是你还得了解最前沿是啥?
1 广告推荐的基本流程
我们其实可以分为:召回,精排,粗排这几个方向。
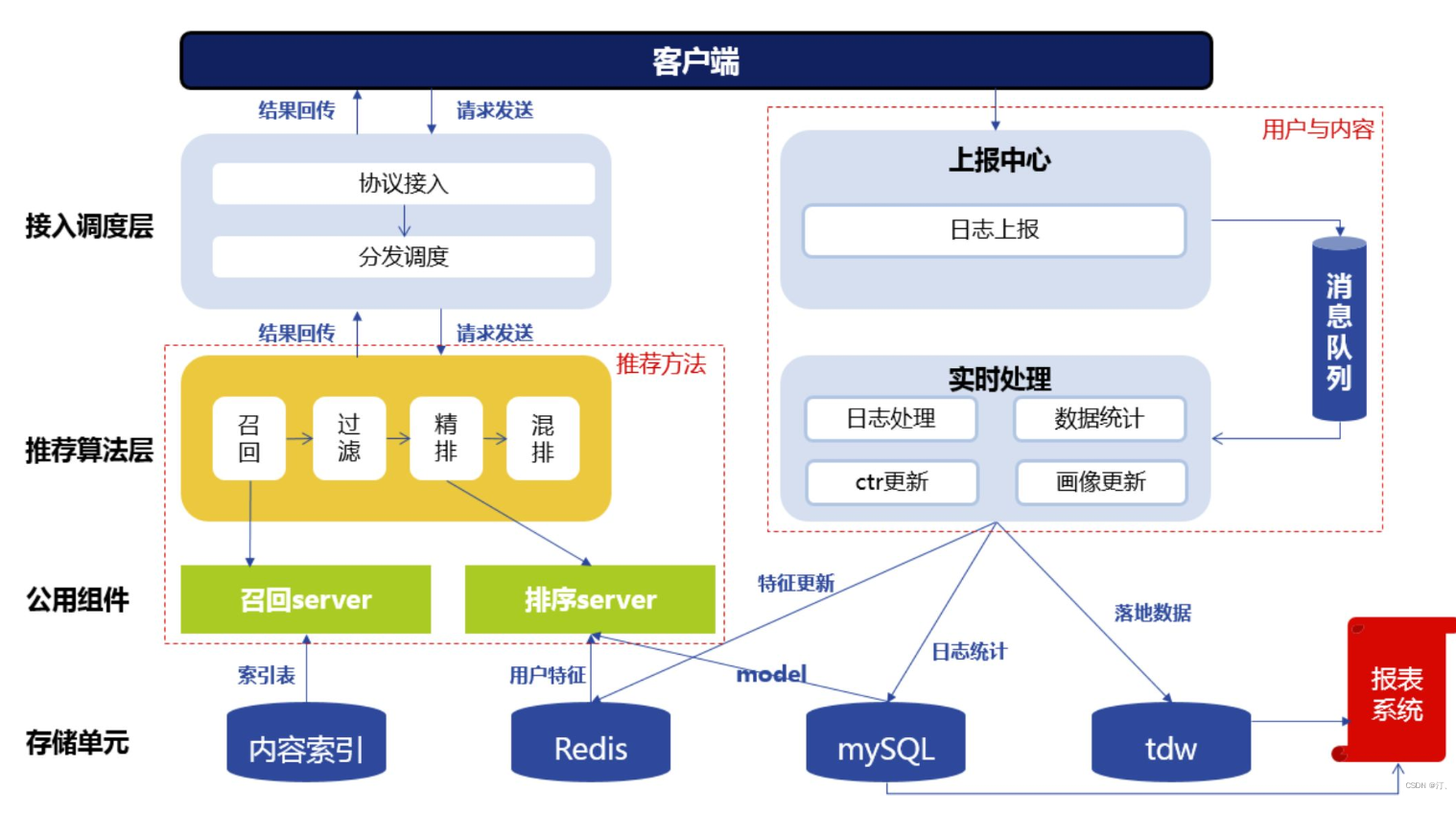
2 场景和baseline初步框定
2.1召回场景
召回要关注负样本的构造、双塔以及改进,工业用的都是双塔模型,我们的baseline可以选择规则召回/协同过滤。
2.2排场景
数据量不够大没必要加粗排,不建议在自己的项目加粗排。
2.3精排场景
排序侧重:特征交叉率、行为序列类、多目标类和trigger建模类选用传统的机器学习做baseline.
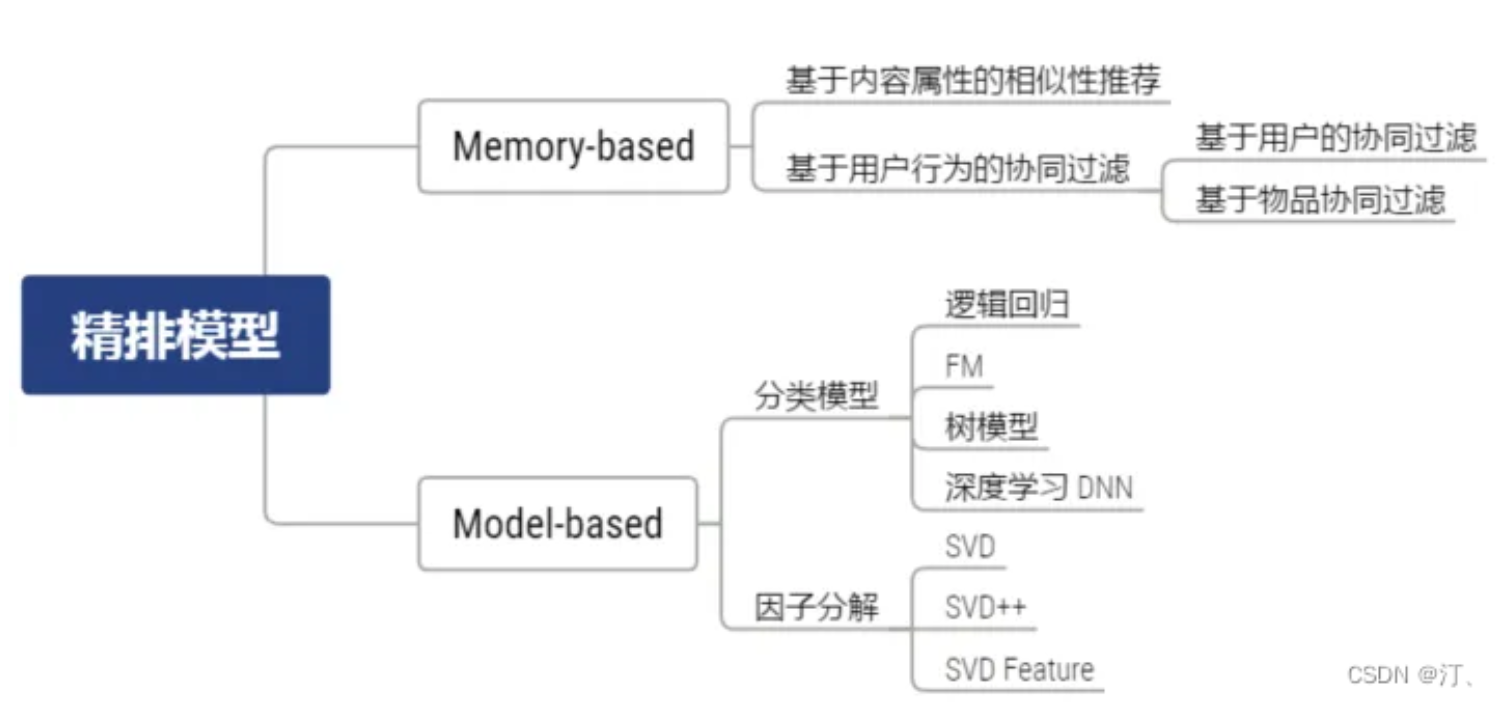
3 一个入门小例子感受--淘宝用户购物行为数据可视化分析
3.1 数据集介绍
数据获取 数据中有5个维度的字段,其分别表示用户id、商品id、用户行为类型、商品类别以及时间信息。 其中,行为类型分为浏览,收藏,加购物车,购买,对应1,2,3,4

3.2 数据分析目标
本次分析的目的是从多个维度分析用户数据、行为数据、商品数据,发现能够提升销售的建议。
1.时间维度
分析用户一天或者一周的销售分析,分析出一年内哪个时间段PV和uv值的情况趋势
分析出一年内哪个时间段PV和uv值的情况趋势
你提到的淘宝购物行为分析中涉及的 UV 和 PV,是常用的用户行为统计指标,具体含义如下:
UV(Unique Visitor,独立访客数)
- 定义 :在一定时间范围内,访问某个网站、某个页面或某个商品的不同用户的数量。
- 特点:同一个用户多次访问只计为1,反映的是访问人数。
- 应用:衡量用户覆盖面和人气,比如某个商品或类目有多少唯一用户关注。
PV(Page View,页面浏览量)
- 定义 :在一定时间范围内,某个网站或页面被访问的总次数。
- 特点:同一个用户多次访问都会被计数,反映的是访问量。
- 应用:衡量页面的受欢迎程度和用户活跃度,比如商品页面被浏览了多少次。
在电商购物行为分析中的意义
- UV代表有多少不同的用户对商品或网站产生过兴趣,是广度的指标。
- PV代表用户浏览的频率和深度,反映用户粘性和活跃度。
- 高UV+高PV意味着商品或页面既有较多用户关注,也有较高的访问频次,说明热度高。
- 通过分析UV和PV的变化趋势,可以发现用户关注的时间段、热门商品、潜在用户行为等。
python
# 计算每天的PV(页面浏览量)
pv = data.groupby('date')['user_id'].count().reset_index()
pv = pv.rename(columns={'user_id': 'pv'})
print("\n每天的PV(前5行):")
print(pv.head())
# 计算每天的UV(独立访客数)
uv = data.groupby('date')['user_id'].apply(lambda x: len(x.unique())).reset_index()
uv = uv.rename(columns={'user_id': 'uv'})
print("\n每天的UV(前5行):")
print(uv.head())
# 可视化PV和UV趋势图
fig, axes = plt.subplots(2, 1, sharex=True, figsize=(10,8))
pv.plot(x='date', y='pv', ax=axes[0], color='red', legend=False)
axes[0].set_title('每日PV')
uv.plot(x='date', y='uv', ax=axes[1], color='green', legend=False)
axes[1].set_title('每日UV')
plt.xticks(rotation=45)
plt.tight_layout()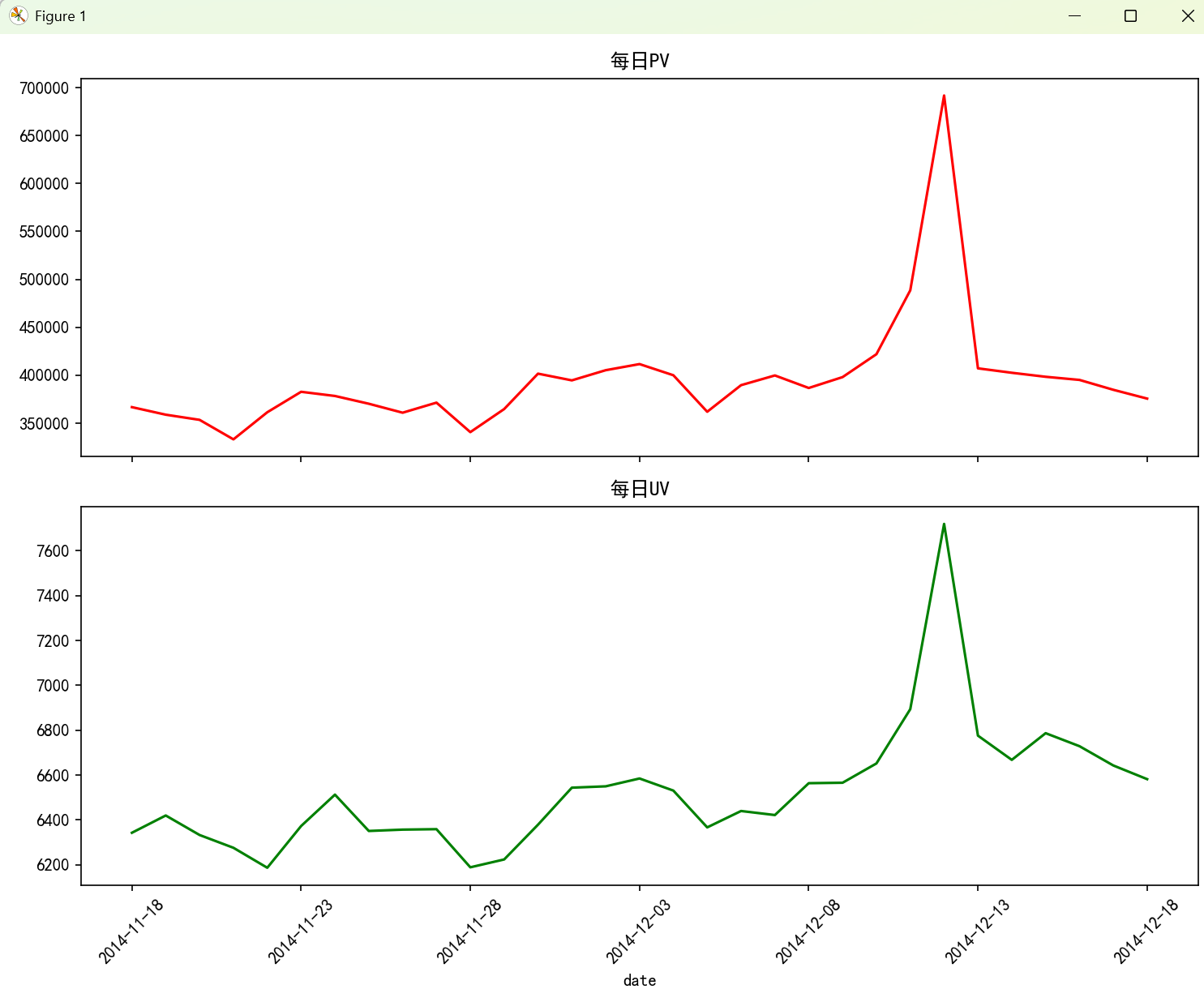
按照月PV和UV我们发现12月12日是一个高PV和高UV的时间段,可能和营销活动有关。
python
# 计算每小时的PV
pv_hour = data.groupby('hour')['user_id'].count().reset_index()
pv_hour = pv_hour.rename(columns={'user_id': 'pv_hour'})
print("\n每小时PV:")
print(pv_hour)
# 计算每小时的UV
uv_hour = data.groupby('hour')['user_id'].apply(lambda x: len(x.unique())).reset_index()
uv_hour = uv_hour.rename(columns={'user_id': 'uv_hour'})
print("\n每小时UV:")
print(uv_hour)
# 每小时PV折线图
plt.figure(figsize=(10,5))
plt.plot(pv_hour['hour'], pv_hour['pv_hour'], color='blue', linewidth=1, linestyle='-')
plt.title('每小时PV情况分布')
plt.xlabel('小时')
plt.ylabel('PV')
plt.xticks(rotation=45)
plt.grid(True)
plt.show()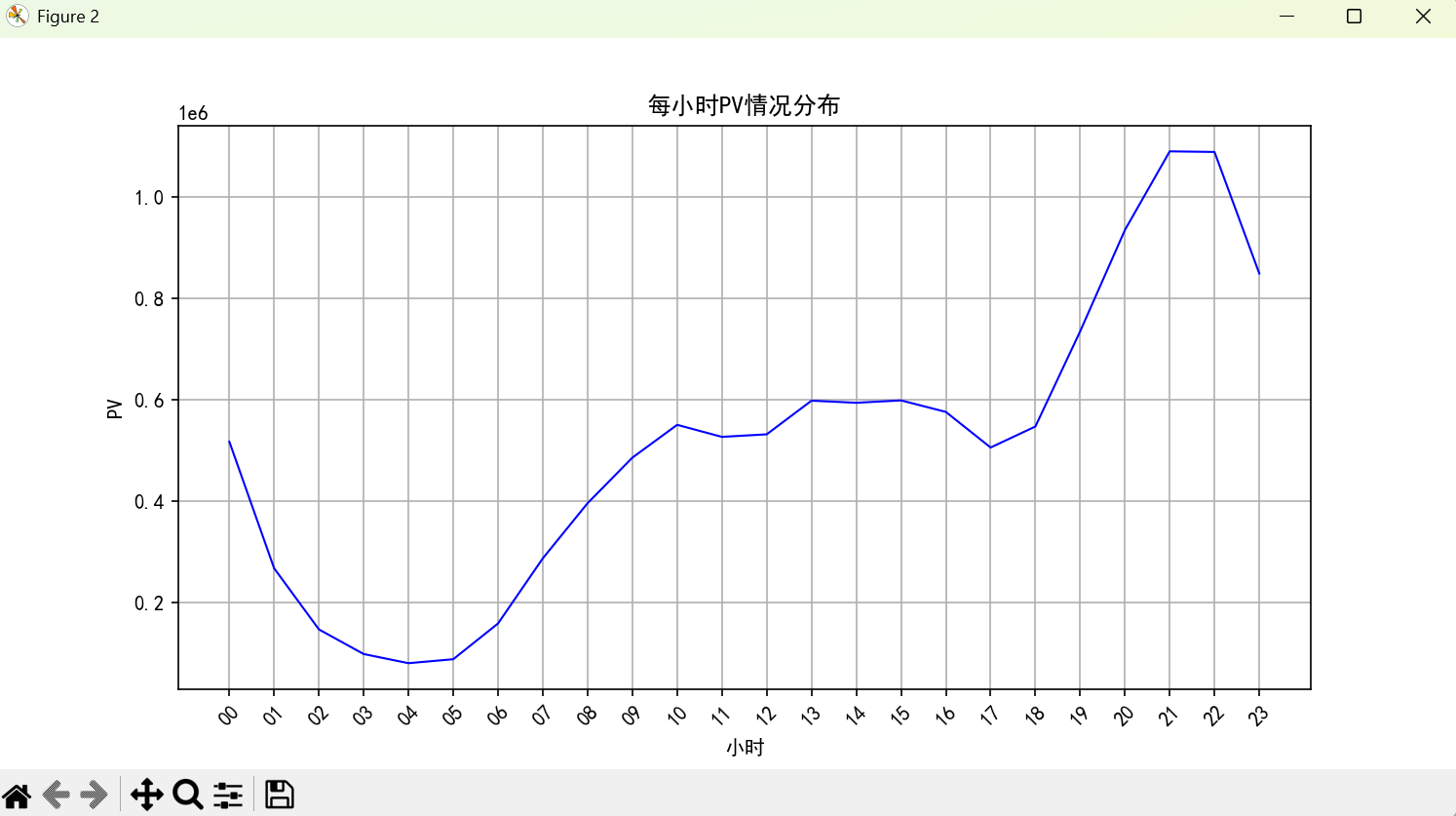
按照每日的小时划分,用户主要活跃在19-23这个期间。
python
# 选取2014-12-12这一天的数据
data_1212 = data[data['date'] == '2014-12-12']
# 该日每小时PV
hour_1212 = data_1212.groupby('hour')['user_id'].count().reset_index()
hour_1212 = hour_1212.rename(columns={'user_id': 'hour_1212'})
print("\n2014-12-12 每小时PV:")
print(hour_1212)
# 该日每小时UV
uv_hour_1212 = data_1212.groupby('hour')['user_id'].apply(lambda x: len(x.unique())).reset_index()
uv_hour_1212 = uv_hour_1212.rename(columns={'user_id': 'uv_hour_1212'})
print("\n2014-12-12 每小时UV:")
print(uv_hour_1212)
# 绘制2014-12-12 每小时UV折线图
plt.figure(figsize=(10,5))
plt.plot(uv_hour_1212['hour'], uv_hour_1212['uv_hour_1212'], color='red')
plt.title('2014-12-12 每小时UV')
plt.xlabel('小时')
plt.ylabel('UV')
plt.xticks(rotation=45)
plt.grid(True)
plt.show()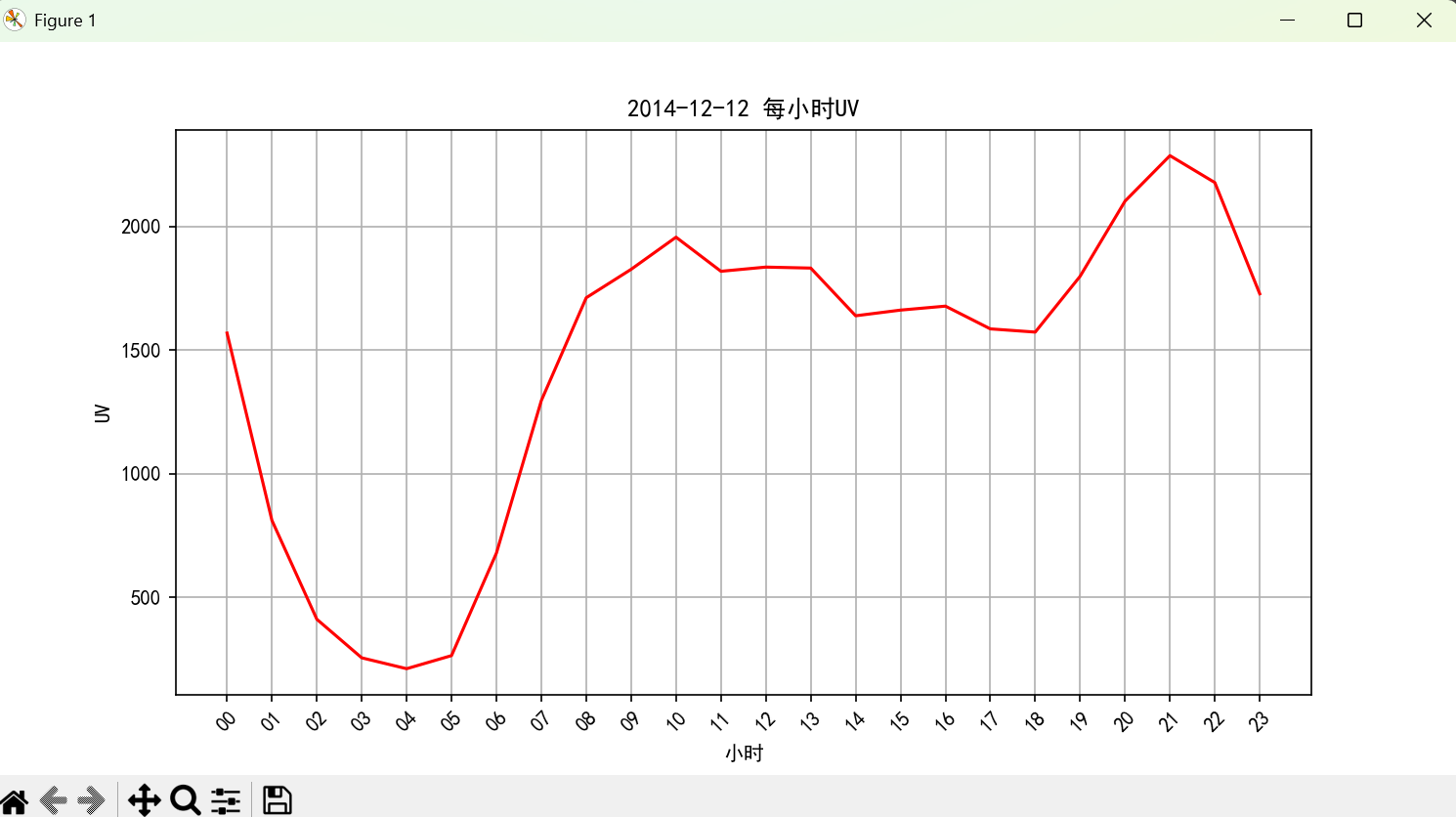
单独查看双十二当天,发现在8:30出现跃升发,可能是活动影响。
2.产品维度
分为热搜产品和类别(浏览量前十的商品),热卖产品和类别(购买量前十的商品),分析商品推送是否有效 。
python
# 计算每种行为的 one-hot 编码列
one_hot_df = pd.get_dummies(data['behavior_type'])
# 拼接 user_id, item_id 和 one-hot 编码
user_item_behavior_df = pd.concat([data[['user_id', 'item_id']], one_hot_df], axis=1)
# 浏览量前十商品(行为类型1)
top1_10 = user_item_behavior_df.groupby('item_id')[1].sum().sort_values(ascending=False).head(10)
print("\n浏览量前十商品及数量:")
print(top1_10)
# 购买量前十商品(行为类型4)
top4_10 = user_item_behavior_df.groupby('item_id')[4].sum().sort_values(ascending=False).head(10)
print("\n购买量前十商品及数量:")
print(top4_10)
# 浏览量前十商品对应的购买量
pv_10_buy = []
for item_id in top1_10.index:
buy_count = user_item_behavior_df.loc[user_item_behavior_df['item_id'] == item_id, 4].sum()
pv_10_buy.append({'商品ID': item_id, '购买量': buy_count})
print("\n浏览量前十商品对应购买量:")
print(pv_10_buy)
# 购买量前十商品对应的浏览量
buy_10_pv = []
for item_id in top4_10.index:
pv_count = user_item_behavior_df.loc[user_item_behavior_df['item_id'] == item_id, 1].sum()
buy_10_pv.append({'商品ID': item_id, '浏览量': pv_count})
print("\n购买量前十商品对应浏览量:")
print(buy_10_pv)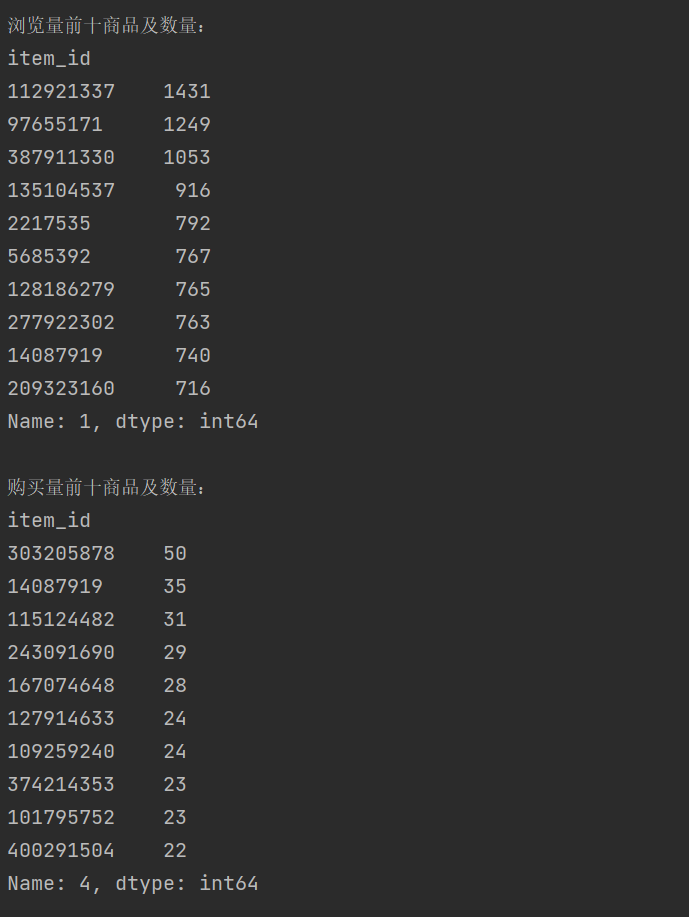

3.行为维度
行为维度主要是分析行为转化率 用户维度分为FRM分析模型对用户进行分解,分析出用户的购买时间,购买频数,购买金额。
python
# 按行为类型和小时统计用户数(PV)
behavior = data.groupby(['behavior_type', 'hour'])['user_id'].count().reset_index()
behavior = behavior.rename(columns={'user_id': 'count'})
print("按行为类型和小时统计的行为计数:")
print(behavior.head())
# 设置matplotlib 中文显示
plt.rcParams['font.sans-serif'] = ['SimHei']
# 创建子图,2行1列,共享x轴
fig, axes = plt.subplots(2, 1, sharex=True, figsize=(10, 8))
# behavior_type==1的数据画在第一个子图(一般代表浏览)
sns.lineplot(x='hour', y='count', hue='behavior_type', data=behavior[behavior.behavior_type == 1], ax=axes[0])
axes[0].set_title('行为类型为1的小时分布')
# behavior_type!=1的数据画在第二个子图
sns.lineplot(x='hour', y='count', hue='behavior_type', data=behavior[behavior.behavior_type != 1], ax=axes[1])
axes[1].set_title('行为类型不为1的小时分布')
plt.tight_layout()
plt.show()
# 计算各行为类型总计数
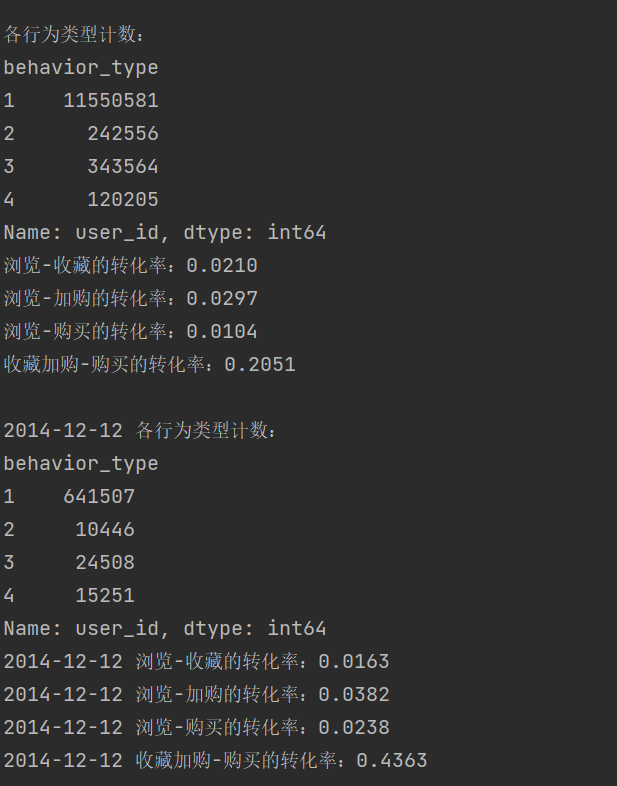
behavior_type = data.groupby('behavior_type')['user_id'].count()
print("\n各行为类型计数:")
print(behavior_type)
# 提取各行为数值(确保索引存在,否则会报错)
look_num = behavior_type.get(1, 0)
hide_num = behavior_type.get(2, 0)
add_num = behavior_type.get(3, 0)
buy_num = behavior_type.get(4, 0)
# 计算转化率
look_hide = hide_num / look_num if look_num else 0
look_add = add_num / look_num if look_num else 0
look_buy = buy_num / look_num if look_num else 0
ha_buy = buy_num / (hide_num + add_num) if (hide_num + add_num) else 0
print(f'浏览-收藏的转化率:{look_hide:.4f}')
print(f'浏览-加购的转化率:{look_add:.4f}')
print(f'浏览-购买的转化率:{look_buy:.4f}')
print(f'收藏加购-购买的转化率:{ha_buy:.4f}')
# 选取2014-12-12这一天数据
data_1212 = data.loc[data['date'] == '2014-12-12']
behavior_type_1212 = data_1212.groupby('behavior_type')['user_id'].count()
print("\n2014-12-12 各行为类型计数:")
print(behavior_type_1212)
look_num = behavior_type_1212.get(1, 0)
hide_num = behavior_type_1212.get(2, 0)
add_num = behavior_type_1212.get(3, 0)
buy_num = behavior_type_1212.get(4, 0)
look_hide = hide_num / look_num if look_num else 0
look_add = add_num / look_num if look_num else 0
look_buy = buy_num / look_num if look_num else 0
ha_buy = buy_num / (hide_num + add_num) if (hide_num + add_num) else 0
print(f'2014-12-12 浏览-收藏的转化率:{look_hide:.4f}')
print(f'2014-12-12 浏览-加购的转化率:{look_add:.4f}')
print(f'2014-12-12 浏览-购买的转化率:{look_buy:.4f}')
print(f'2014-12-12 收藏加购-购买的转化率:{ha_buy:.4f}')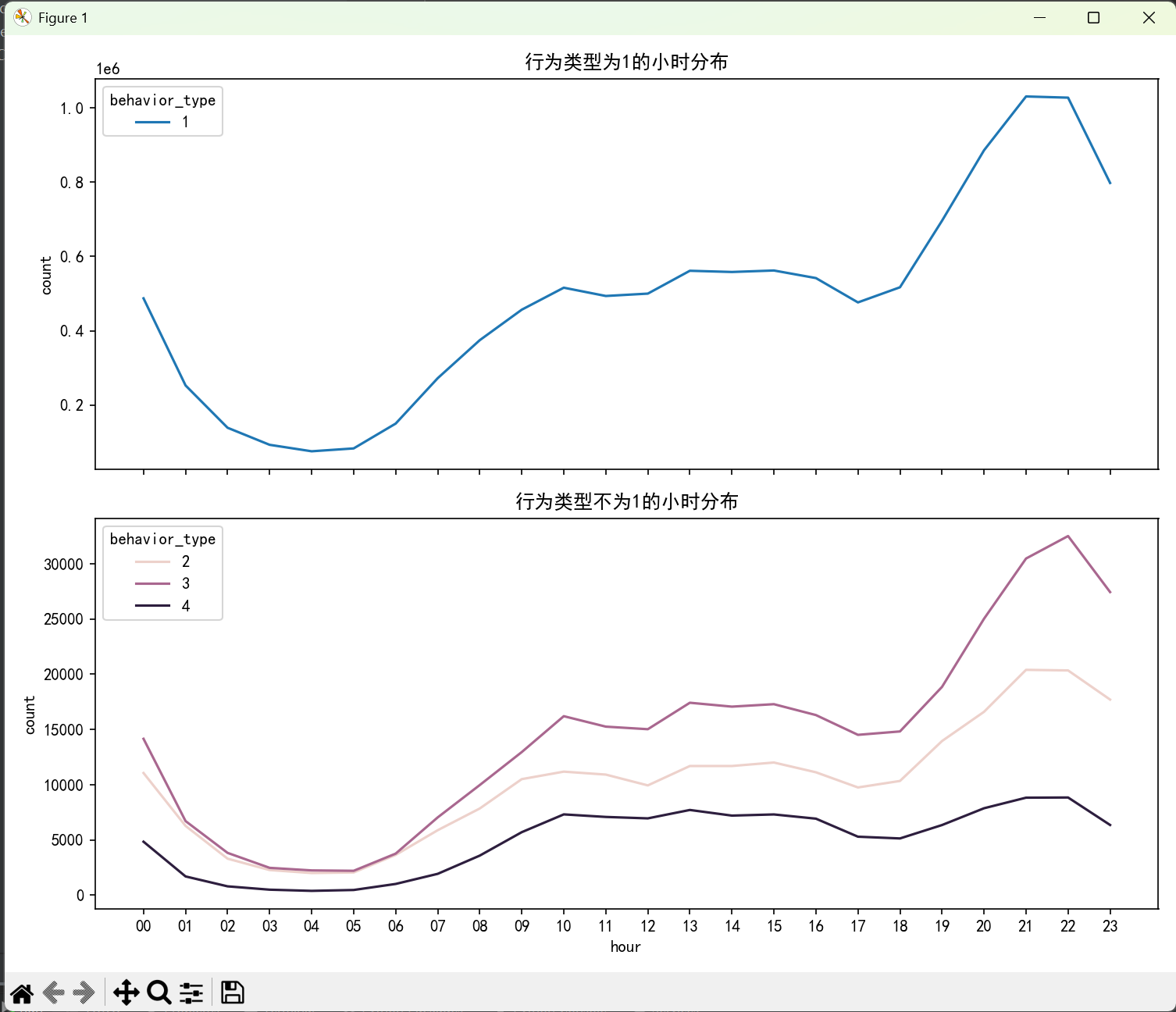
从以上两个图可以看出四条行为类型的的趋势项接近,浏览量高的时候,购买和加购收藏的也逐渐提高, 四条线都是10-16处于平稳,无论是点击量,加购收藏量,还是购买量都在这个时间段处于不怎么波动状态。 而18-23点可以明显感觉到点击量上涨的很快,同样加购收藏也随之增多,购买量也有一定的上升坡度。
4.用户维度
python
import pandas as pd
import matplotlib.pyplot as plt
# 假设 data 已经加载,包含至少列 ['user_id', 'behavior_type', 'date']
# 计算每个用户的购买次数(行为类型为4代表购买)
user_buy_num = data[data.behavior_type == 4].groupby('user_id')['behavior_type'].count().reset_index()
user_buy_num = user_buy_num.rename(columns={'behavior_type': 'count'})
print("用户购买次数统计(前5条):")
print(user_buy_num.head())
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体
# 用户购买次数分布图(用户id作为x轴,购买次数作为y轴)
user_buy_num.plot(x='user_id', y='count', kind='bar', color='blue', figsize=(12, 5), legend=False)
plt.title('用户购买次数情况')
plt.xlabel('用户ID')
plt.ylabel('购买频次')
plt.tight_layout()
plt.show()
# 计算不同用户购物的天数(去重日期)
user_buy_n = data[data.behavior_type == 4].groupby('user_id')['date'].apply(lambda x: len(x.unique())).reset_index()
user_buy_n = user_buy_n.rename(columns={'date': 'count'})
print("\n各用户购买天数统计(前5条):")
print(user_buy_n.head())
# 计算复购用户数量比例(购买天数大于1的用户比例)
d_rate = (user_buy_n['count'] > 1).sum() / user_buy_n['count'].count()
print(f"\n复购用户比例:{d_rate:.4f}")
# 计算用户每日购买次数(行为类型为4)
data1 = data.copy()
data1['action'] = 1 # 把每条行为标记为1,方便count计数
user_buy_d = data1[data1.behavior_type == 4].groupby(['user_id', 'date'])['action'].count().reset_index()
print("\n用户每日购买次数(前5条):")
print(user_buy_d.head())
# 计算每个用户复购的间隔天数
# 这里 date 需要转换为 datetime 类型,如果还没转换:
user_buy_d['date'] = pd.to_datetime(user_buy_d['date'])
user_buy_p = user_buy_d.groupby('user_id')['date'].apply(lambda x: x.sort_values().diff().dropna())
print("\n复购间隔天数示例(部分):")
print(user_buy_p.head())
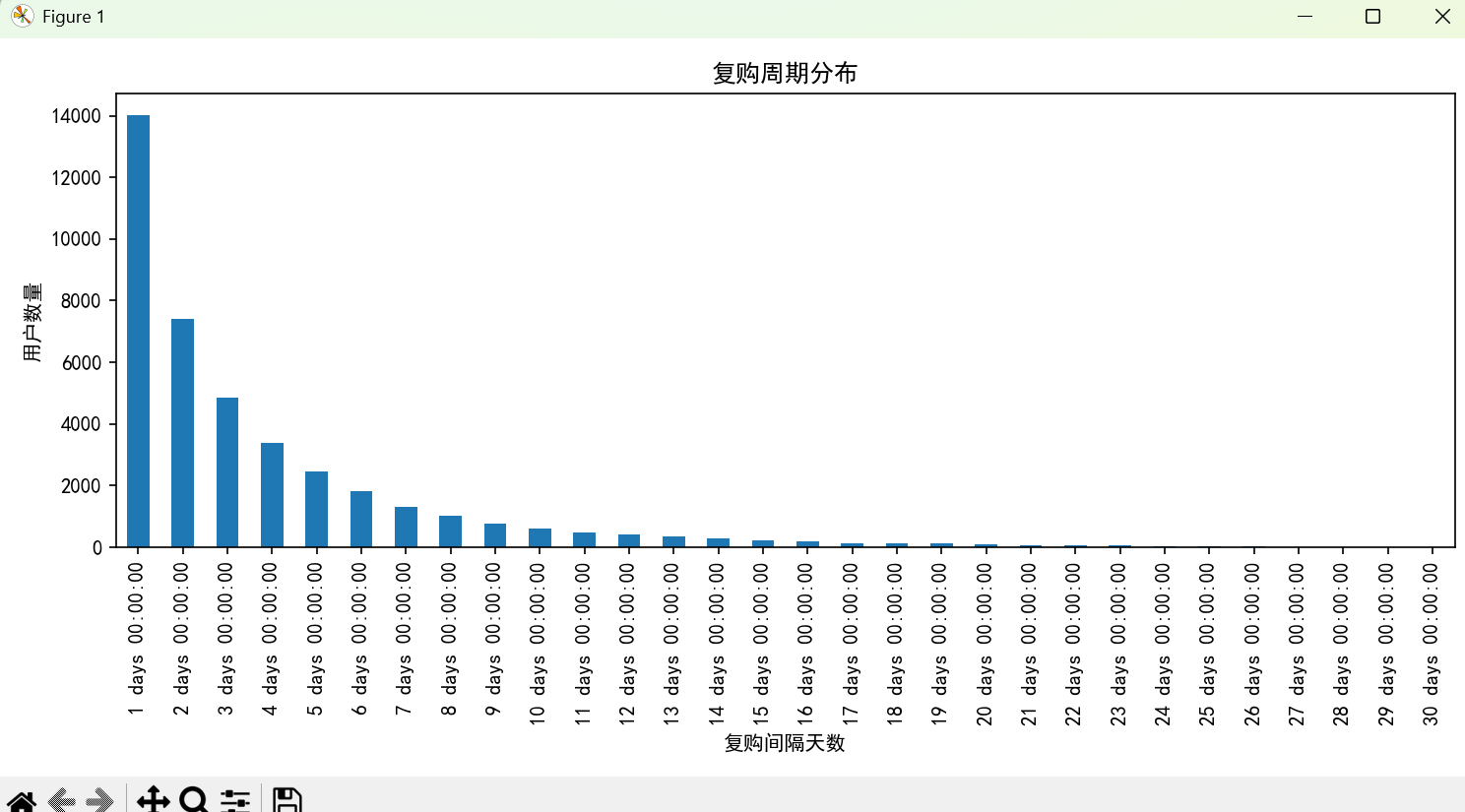
# 绘制复购周期分布图
plt.rcParams['font.sans-serif'] = ['SimHei']
user_buy_p.value_counts().sort_index().plot(kind='bar', figsize=(10, 5))
plt.xlabel('复购间隔天数')
plt.ylabel('用户数量')
plt.title('复购周期分布')
plt.tight_layout()
plt.show()
# 重置索引,准备合并
user_buy_p = user_buy_p.reset_index()
user_buy_p = user_buy_p.drop(columns='level_1')
user_buy_p = user_buy_p.rename(columns={'date': 'date_diff'})
print("\n处理后的复购周期数据(前5条):")
print(user_buy_p.head())
# 合并购买次数和复购间隔
rfm = pd.merge(user_buy_num, user_buy_p, on='user_id')
print("\n合并后的RFM数据(前5条):")
print(rfm.head())
# 给复购间隔和购买次数打分,分成两组,qcut分位数切分
# 复购间隔是 Timedelta,需要转换成天数
rfm['date_days'] = rfm['date_diff'].dt.days
# 对复购间隔打分,天数越少分越高(这里labels倒过来)
rfm['score_date'] = pd.qcut(rfm['date_days'], 2, labels=['1', '0'])
# 对购买次数打分,次数越多分越高
rfm['score_count'] = pd.qcut(rfm['count'], 2, labels=['0', '1'])
# 合并打分,形成rfm标签
rfm['rfm'] = rfm['score_count'].astype(str) + rfm['score_date'].astype(str)
print("\nRFM打分示例(前5条):")
print(rfm[['user_id', 'count', 'date_days', 'score_count', 'score_date', 'rfm']].head())
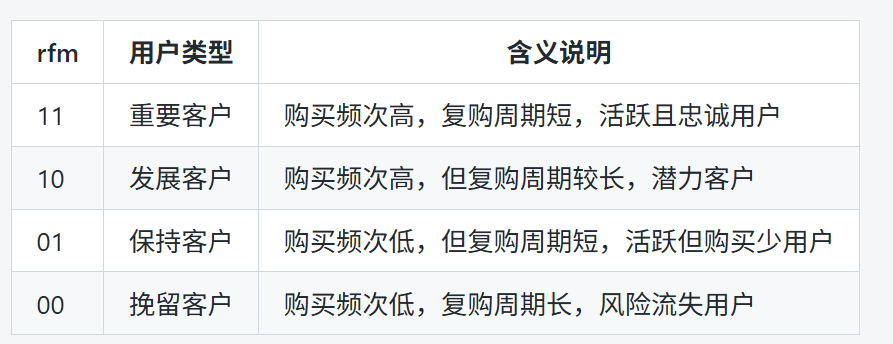
# 根据rfm标签映射用户类型
rfm = rfm.assign(user_type=rfm['rfm'].map({
'11': '重要客户',
'01': '保持客户',
'10': '发展客户',
'00': '挽留客户'
}))
# 汇总用户类型数量
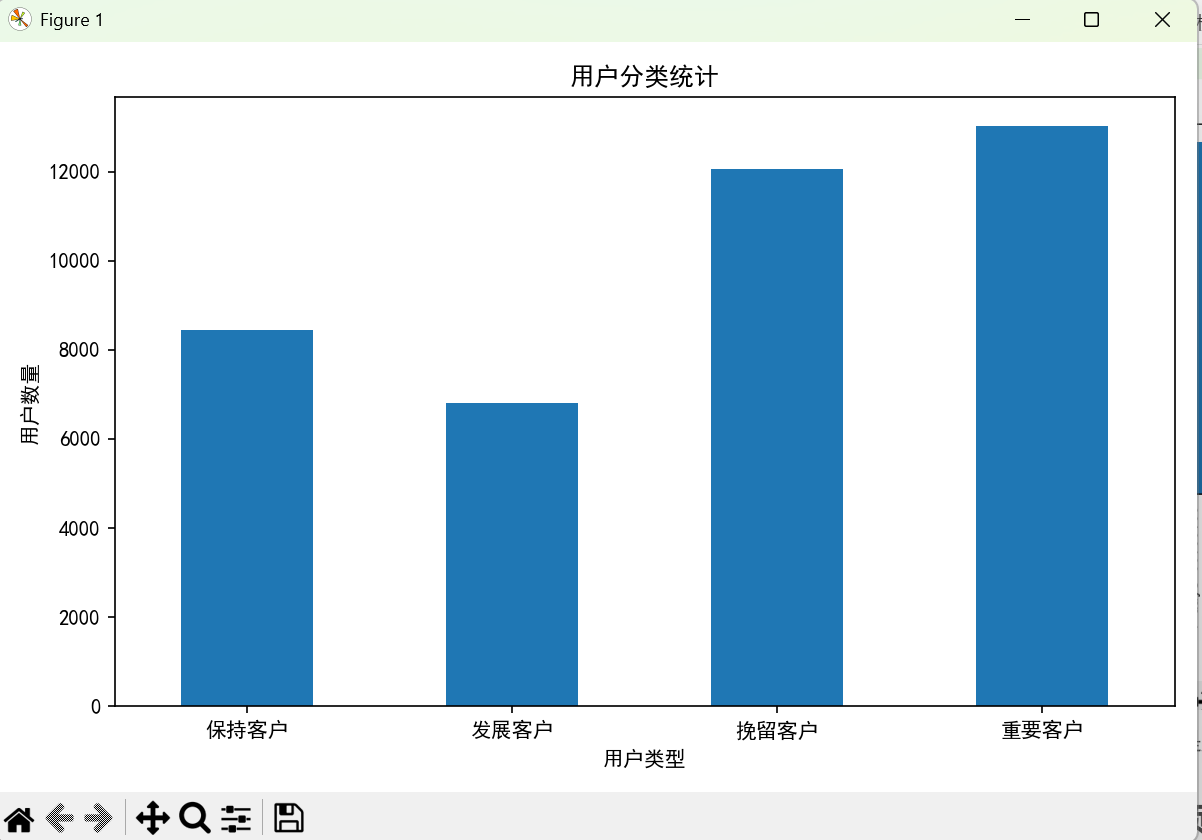
type_sum = rfm.groupby('user_type')['rfm'].count().reset_index(name='count')
print("\n用户类型统计:")
print(type_sum)
# 绘制用户类型柱状图
type_sum.plot(x='user_type', y='count', kind='bar', legend=False, figsize=(8, 5))
plt.xlabel('用户类型')
plt.ylabel('用户数量')
plt.title('用户分类统计')
plt.xticks(rotation=0)
plt.tight_layout()
plt.show()
# 计算用户每日各行为次数
user_day_buy = data1.groupby(['date', 'user_id', 'behavior_type'])['action'].count().reset_index()
user_day_buy = user_day_buy.rename(columns={'action': 'count'})
print("\n用户每日各行为次数(前5条):")
print(user_day_buy.head())
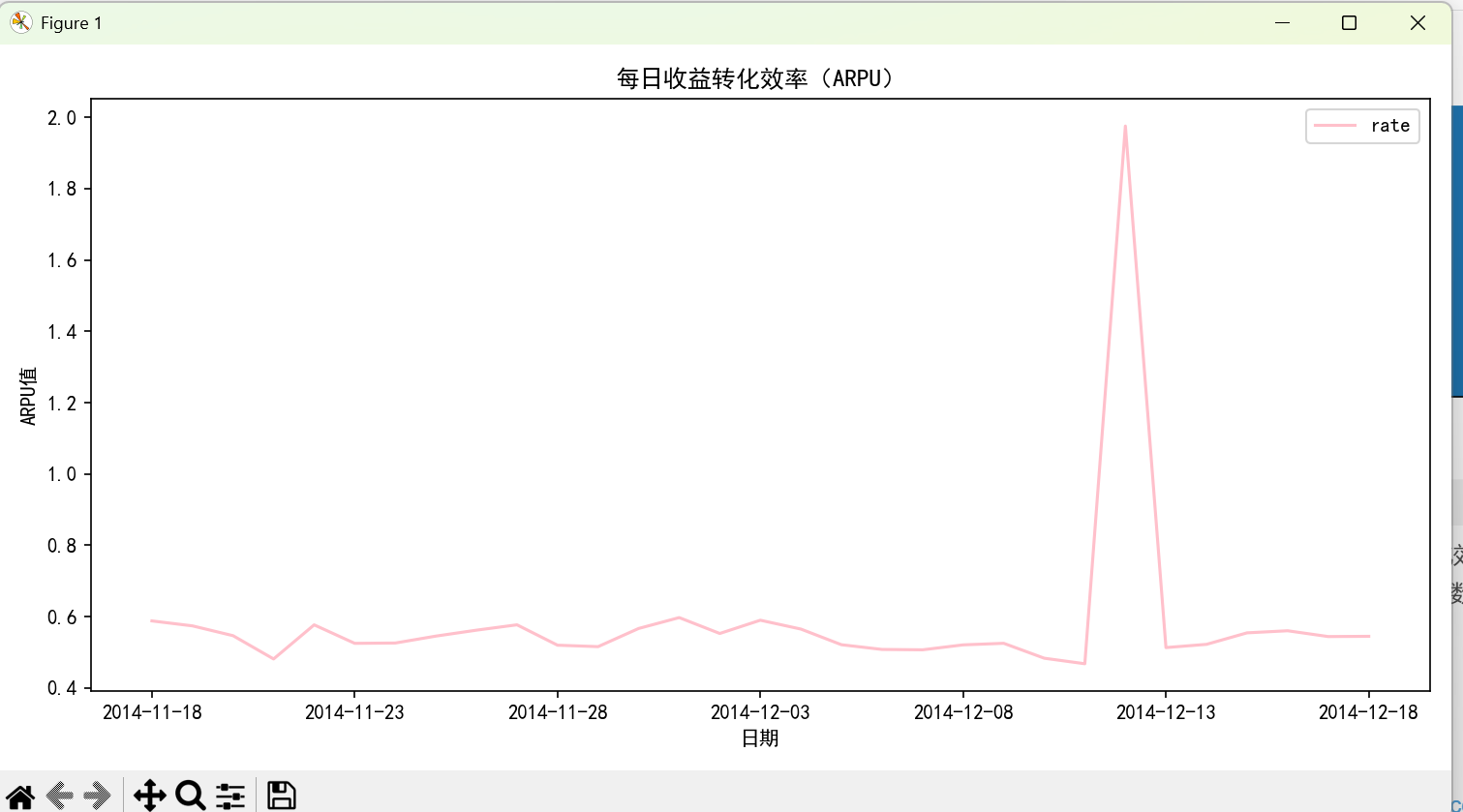
# 计算ARPU(每日购买总数 / 当日活跃用户数)
ARPU = user_day_buy.groupby('date').apply(
lambda x: x[x['behavior_type'] == 4]['count'].sum() / x['user_id'].nunique()
).reset_index(name='rate')
print("\nARPU(前5条):")
print(ARPU.head())
ARPU.plot(x='date', y='rate', color='pink', figsize=(10, 5))
plt.title('每日收益转化效率(ARPU)')
plt.xlabel('日期')
plt.ylabel('ARPU值')
plt.tight_layout()
plt.show()
# 计算每日消费用户人数和下单率
user_day_buy1 = data[data.behavior_type == 4].groupby(['date', 'user_id'])['behavior_type'].count().reset_index()
user_day_buy1 = user_day_buy1.rename(columns={'behavior_type': 'count'})
buy_rate = user_day_buy1.groupby('date').apply(
lambda x: x['count'].sum() / x['user_id'].count() # 总购买次数 / 购买用户数,代表平均购买频次
).reset_index(name='rate')
print("\n每日平均购买频次(下单率)前5条:")
print(buy_rate.head())
plt.rcParams['font.sans-serif'] = ['SimHei']
buy_rate.plot(x='date', y='rate', color='pink', figsize=(10, 5))
plt.title('每日下单率')
plt.xlabel('日期')
plt.ylabel('平均购买频次')
plt.tight_layout()
plt.show()①购买频次
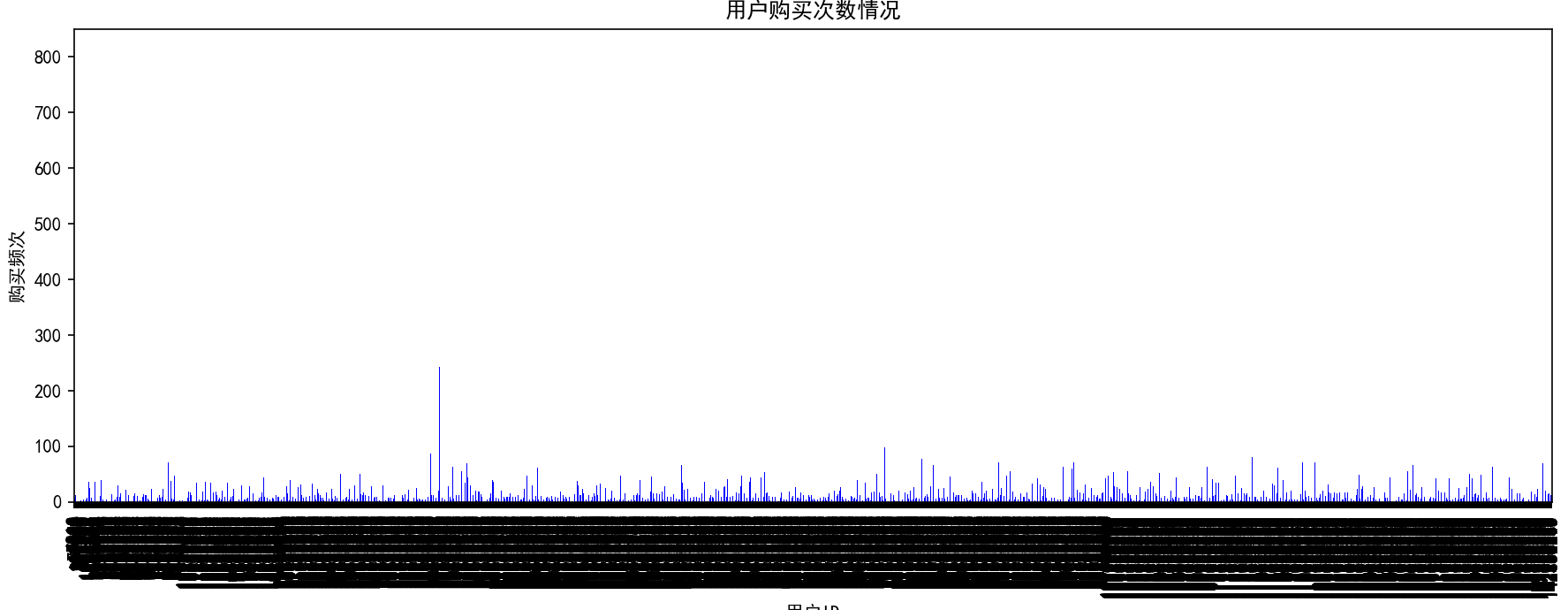
②复购率 = 复购用户数量 / 有购买行为的用户数量
复购间隔是用户最新一次购买时间和上一次购买时间的间隔。复购间隔=最新一次购物时间-上一次购物时间
③RFM思想是用时间(Recency)、频次(Frequency)、金额(Monetary)三个指标,量化用户行为,分层划分客户价值,从而帮助企业精准营销和客户管理的一种经典模型和方法。
④计算平台的每日活跃用户对每日收益的转化效率,APRU=日总的购买次数/日登录次数
⑤下单率=日购买的用户数总数/日总的登录次数
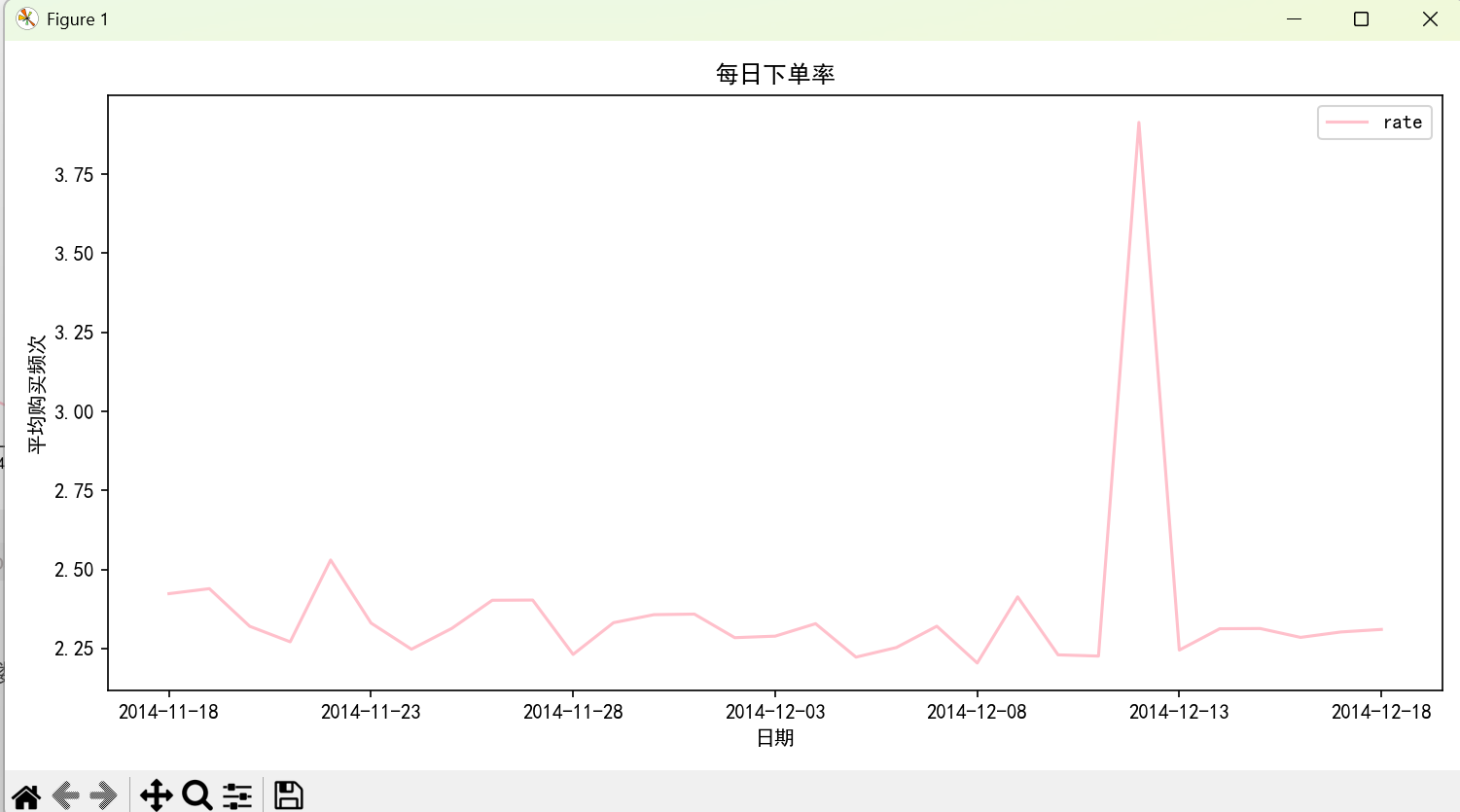
根据上图的下单率可知在1212那天有一个下单高峰,其他大部分时间下单率处于2.25-2.50之间。
4 基础项目选型
4.1场景
开源项目?目前比较火的开源的新闻推荐系统,但是我更偏向的是电商系统。尚硅谷有个电商推荐系统 ,但是我感觉偏向于开发而不是算法,之前有尝试过开发,因此不想将时间花费在开发环境配置上面。
比赛项目?这大概是最可取的,但是比赛的场景有点过于极端,我最开始就是选取的有个OTTO比赛,后来发现确实展现不了个人思考。
自己手搓一个?我更倾向于这个,那应该会很有意思。结合我自己的背景(对LLama模型较为熟悉且组里有足够的资源),或许能否选一个合适的场景,合适的数据集;然后自己实验LLMma等替换获得更好的效果呢??
所以,接下来:我们需要多看论文,选定场景和数据集和baseline!✌
推荐资料
https://github.com/Doragd/Algorithm-Practice-in-Industry
后记
"越知道知识的广阔,越觉察自己的浅陋"
学习新的知识往往是又惊喜又伤心的(物理层面上表现为热泪盈眶),惊喜是我又发现了一个个宝藏,伤心的是居然有这么庞大的知识我一无所知之前还和别人侃侃而谈,而且这么多知识啥时候才能统统入脑呢?往往会想到苏轼"寄蜉蝣于天地,渺沧海之一粟。哀吾生之须臾,羡长江之无穷。知不可乎骤得,托遗响于悲风。",对我来说,解决这种彷徨无措的方法只有一个:实践,干就完了。像胡适说的"怕什么真理无穷,进一寸有进一寸的欢喜"