(一) asdfghjklx 在虚拟机上 安装java
来,我们先给虚拟机上安装javaJDK。注意,后面我们会按照如下步骤来操作有:
-
把javaJDK文件上传到服务器上。
-
解压文件。
-
配置环境变量。
来,分别操作如下:
1. 上传文件到虚拟机 。用FinalShell传输工具将JDK导入到opt目录下面的software文件夹下面(opt/software文件夹是我们自己创建的)\
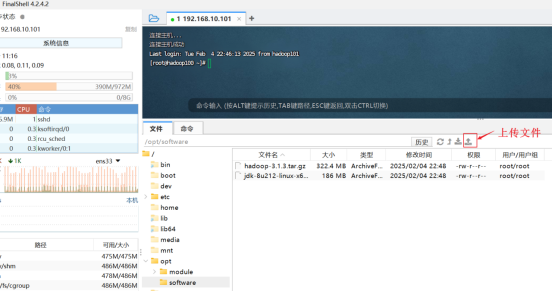
2. 解压文件 。把刚才创建的文件解压出来。
(1)检查软件包是否上传成功
在解压之前,看看上传是否成功了。使用cd命令进入到opt/software目录,再使用ls命令,查看是否已经上传成功。
看到如下结果:jdk-8u212-linux-x64.tar.gz
(2)解压JDK到/opt/module目录
确认上传成功之后,在software目录下,运行如下命令
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
这条命令的解释如下:
-
tar:这是 Linux 系统中用于归档和压缩文件的命令行工具。
-
-z:表示通过 gzip 压缩格式来处理文件,因为文件 jdk-8u212-linux-x64.tar.gz 是一个经过 gzip 压缩的 tar归档文件。
-
-x:表示解压(extract)操作,即从归档文件中提取出内容。
-
-v:表示在解压过程中显示详细的信息(verbose),会输出正在解压的文件名等信息。
-
-f:指定要处理的归档文件名,后面跟着的 jdk-8u212-linux-x64.tar.gz 就是要解压的文件。
6.-C /opt/module/:其中 -C 选项表示切换目录(change directory),后面跟着的 /opt/module/ 是指定解压后的文件存放的目标目录。也就是说,解压后的文件会被放置到 /opt/module/这个目录下。
这条命令的作用就是将 jdk-8u212-linux-x64.tar.gz 这个经过gzip压缩的 tar归档文件解压到 /opt/module/目录中,并在解压过程中显示详细信息。
3. 配置JDK环境变量
环境变量是操作系统中用来存储系统和应用程序运行时所需信息的动态命名值。这些变量可以被系统、应用程序或用户脚本访问和使用,它们为软件提供了一种灵活的方式来获取配置信息,而不需要在代码中硬编码特定的路径或设置。
一般情况下我们会去修改配置文件,并补充一个环境变量,但是,今天给大家介绍一种新的处理方式。
先说一个背景知识:当用户登录系统时,系统会执行一系列的初始化脚本,这些脚本用于设置用户的环境变量、别名等信息。/etc/profile 是系统级别的全局配置文件,当用户进行登录操作时,该文件会被执行,而 /etc/profile 脚本里包含了对 /etc/profile.d 目录下脚本的扫描和执行逻辑。
所以,我们可以把需要用到的环境变量配置到一个新的.sh文件中,再把这个新的文件放在profile.d目录下。
(1)新建/etc/profile.d/my_env.sh文件
使用的命令是: vi /etc/profile.d/my_env.sh
在打开的文件中输入如下内容
#JAVA_HOME #是注释
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin其中:export是把一个变量导出为环境变量
PATH:JAVA_HOME/bin 是将 JAVA_HOME/bin 目录添加到 PATH 环境变量中,这样在终端中就可以直接执行 JAVA_HOME/bin 目录下的 Java 相关命令,而无需输入完整的文件路径。:wq
(2)保存后退出。按下:wq回车。
(3)source一下/etc/profile文件,让新的环境变量PATH生效
source /etc/profile4. 测试JDK是否安装成功
在任意目录下,运行 java -version,如果能看到以下结果,则代表Java安装成功。
java version "1.8.0_212"
如果不生效,就重新启动一下系统, 然后再试一次。
(二) 在虚拟机上 安装Hadoop
前面已经成功安装了javaJDK,接下来安装hadoop。基本步骤与安装java一致:先用finalshell将hadoop-3.1.3.tar.gz导入到opt目录下面的software文件夹下面,然后解压,最后配置环境变量。
-
使用finalshell上传。这里直接鼠标拖动操作即可。
-
解压。进入到Hadoop安装包路径下,cd /opt/software/ ,再解压安装文件到/opt/module下,对应的命令是:
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
这个命令的功能与解压java类似,这里不再重复解释了。
5)将Hadoop添加到环境变量
请注意,我们已经将hadoop解压到了/opt/module/hadoop-3.1.3目录下。打开/etc/profile.d/my_env.sh文件,并在my_env.sh文件末尾添加如下内容:
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin保存并退出,按下:wq并回车
(3)让修改后的文件生效
使用source命令让配置文件生效。
source /etc/profile6)测试是否安装成功
使用hadoop version检查hadoop是否安装成功。
如果看到: Hadoop 3.1.3 表示成功。
( 三 ) 运行 官方Word C ount 程序
在安装hadoop时,它自带了很多的示例代码,其中有一个是用来统计词频的程序,下面我们来看一下如何去运行这个示例代码。
(1)在hadoop-3.1.3文件下面创建一个wcinput文件夹
(2)在wcinput文件下创建一个word1.txt和一个word2.txt文件
分别编辑word1.txt文件和word2.txt文件内容
hadoop yarn
hadoop mapreduce
root
root(3)执行程序。回到Hadoop目录下,/opt/module/hadoop-3.1.3,运行命令:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount wcinput wcoutput命令说明如下:
-
整体功能。该命令的主要功能是运行 Hadoop 自带的 wordcount(单词计数)示例程序,对输入路径 wcinput 下的文本文件进行单词统计,并将统计结果输出到 wcoutput 路径。
-
hadoop jar :这是在 Hadoop 环境中用于启动 Java 程序(通常是 MapReduce 作业)的标准命令格式。hadoop 是 Hadoop 命令行工具,jar 表示要执行一个 Java 可执行 JAR 文件。
-
share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar:这是指定要运行的 Java JAR 文件的路径。该 JAR 文件包含了 Hadoop 自带的各种示例程序,例如 wordcount、pi 等。3.1.3 是 Hadoop 的版本号,不同版本的 Hadoop,其示例 JAR 文件的版本号可能不同。
-
Wordcount:这是指定要运行的具体示例程序名称。在 hadoop-mapreduce-examples-3.1.3.jar 中包含了多个示例程序,wordcount 是其中一个经典的 MapReduce 程序,用于统计输入文本中每个单词出现的次数。
-
wcinput:这是指定输入数据的路径。wordcount 程序会从该路径下读取要进行单词统计的文本文件。
-
wcoutput:这是指定输出结果的路径,它会自动被创建出来 。wordcount 程序运行结束后,会将统计结果输出到该路径下。需要注意的是,该输出路径在程序运行前不能已经存在,否则会抛出错误。
(4)查看结果
使用cat命令去查看wcoutput下的运行结果。
(四)Hadoop的目录结构
Hadoop目录结构
1)查看Hadoop目录结构
进入到hadoop-3.1.3下,它的几个重要目录如下
(1)bin目录:存放对Hadoop相关服务(hdfs,yarn,mapred)进行操作的脚本
(2)etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
(3)lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
(4)sbin目录:存放启动或停止Hadoop相关服务的脚本
(5)share目录:存放Hadoop的依赖jar包、文档、和官方案例
( 五 ) Hadoop的组成
在Hadoop3.X中,hadoop一共有四个组成部分:MapReduce计算,Yarn资源调度,HDFS数据存储,Common辅助工具。
- HDFS架构
Hadoop Distributed File System, 简称HDFS,是一个分布式文件系统。
(1)NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间,副本数,文件权限),以及每个文件的块列表和块所在的DataNode等。
(2)DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。
(3)Secondary NameNode(2nn): 每隔一段时间对NameNode元数据备份。
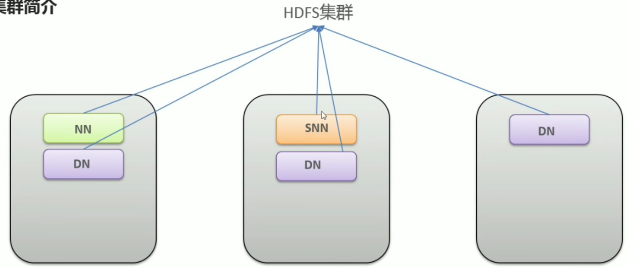
HDFS集群:一主加三从,额外再配一个小秘书
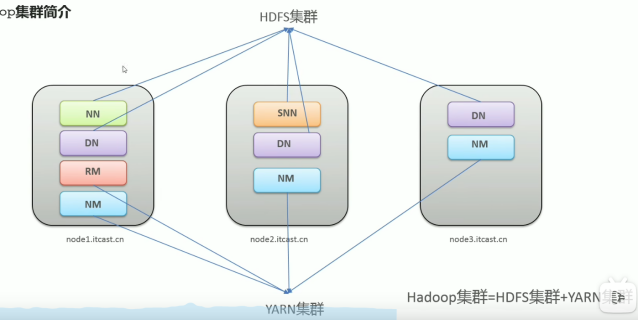
- YARN架构概述
Yet Another Resource Negotiator,简称YARN,另一种资源协调者,是Hadoop的资源管理器。
(1)ResourceManager(RM):整个集群资源(内存,CPU等)的老大
(2)NodeManager(NM): 单个节点服务器资源老大
(3)Application Master(AM): 单个任务运行的老大
(4)Container: 容器,相当于一台独立的服务器,里面封装了任务运行时所需要的资源:如内存、cpu、磁盘、网络等等。
3.MapReduce架构概述
MapReduce将计算过程分为两个阶段:Map和Reduce
(1)Map阶段并行处理输入数据
(2)Reduce阶段对Map结果进行汇总
