作者:IvanCodes
日期:2025年5月13日
专栏:Hive教程
内容导航
-
-
- 一、表的 DDL 操作 (非创建)
- 二、分区的 DDL 操作
- 三、洞察元数据:SHOW 命令的威力
- 结语:DDL 与 SHOW,Hive 管理的双翼
- 练习题
-
- 一、选择题
- 二、代码题
- 练习题答案
-
- 一、选择题答案
- 二、代码题答案
-
在 Apache Hive 中,数据定义语言 (DDL) 不仅仅局限于创建表 (CREATE TABLE)。为了有效地管理和维护数据仓库中的数据结构,Hive 提供了一系列丰富的 DDL 命令来修改表属性、管理分区以及查看元数据信息。本文将重点介绍这些核心的 DDL 操作和常用的 SHOW 命令,帮助您更自如地驾驭 Hive。
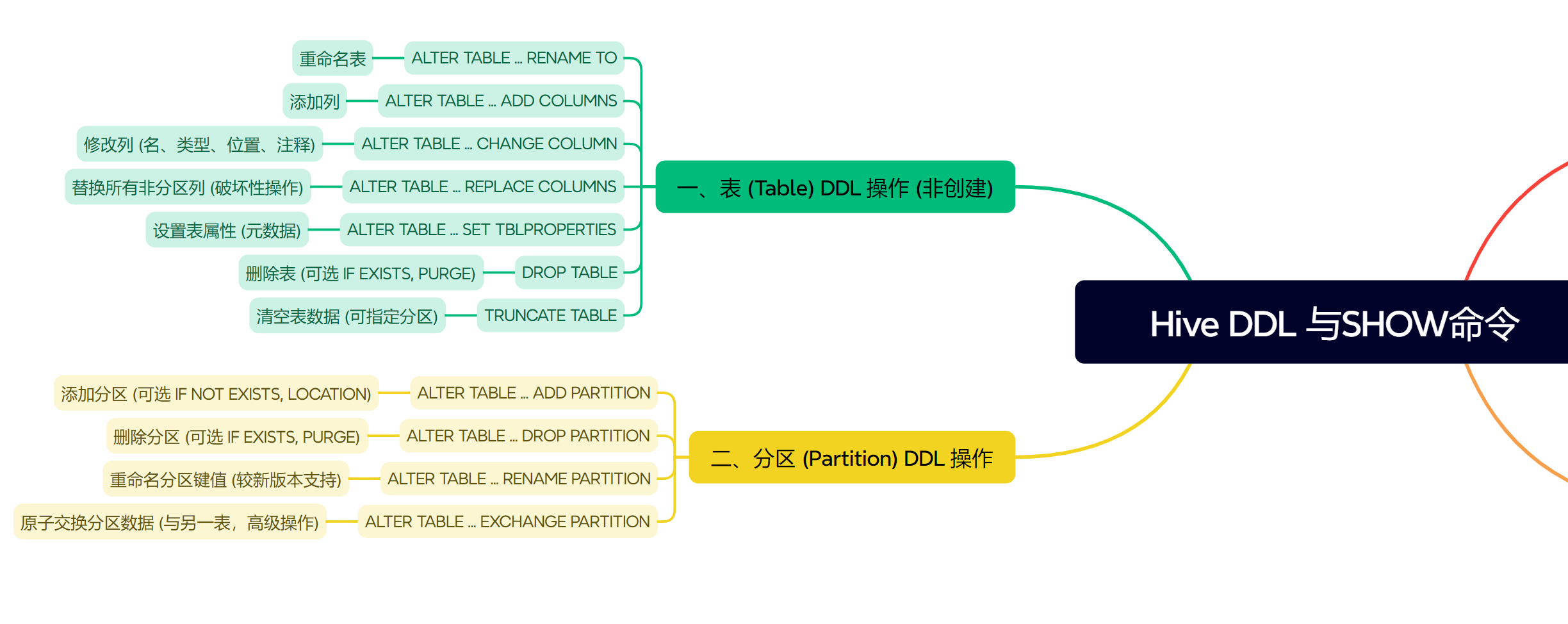
一、表的 DDL 操作 (非创建)
一旦表被创建,我们经常需要对其结构或属性进行调整。
ALTER TABLE ... RENAME TO:重命名表
用于修改现有表的名称。
语法:
sql
ALTER TABLE old_table_name RENAME TO new_table_name;案例:
sql
ALTER TABLE user_logs RENAME TO application_logs;ALTER TABLE ... ADD COLUMNS:添加列
向表中添加新的列。新添加的列会出现在现有列之后,或者如果表有分区,会出现在非分区列的末尾,分区列之前。
语法:
sql
ALTER TABLE table_name ADD COLUMNS (new_col1_name data_type [COMMENT 'comment'], new_col2_name data_type [COMMENT 'comment'], ...);案例:
sql
ALTER TABLE application_logs ADD COLUMNS (ip_address STRING COMMENT 'User IP address', browser_info STRING);ALTER TABLE ... CHANGE COLUMN:修改列
可以修改列的名称、数据类型、注释以及在表中的位置。这是一个非常灵活但也需要谨慎使用的操作,特别是修改数据类型时,需要考虑数据兼容性。
语法:
sql
ALTER TABLE table_name CHANGE COLUMN old_col_name new_col_name new_data_type [COMMENT 'comment'] [FIRST | AFTER existing_col_name];案例:将 browser_info 列重命名为 client_agent 并移动到 ip_address 列之后
sql
ALTER TABLE application_logs CHANGE COLUMN browser_info client_agent STRING COMMENT 'Client user agent' AFTER ip_address;ALTER TABLE ... REPLACE COLUMNS:替换所有列
此操作会移除表中所有现有的非分区列,并用指定的新列集合替换它们。这是一个具有破坏性的操作。
语法:
sql
ALTER TABLE table_name REPLACE COLUMNS (new_col1_name data_type [COMMENT 'comment'], ...);案例:(谨慎使用)
sql
-- 假设要完全重构 product_details 表的列
-- ALTER TABLE product_details REPLACE COLUMNS (item_id INT, item_name STRING, price DECIMAL(8,2));ALTER TABLE ... SET TBLPROPERTIES:设置表属性
用于添加或修改表的元数据属性,例如注释、是否为外部表(虽然通常在创建时定义)等。
语法:
sql
ALTER TABLE table_name SET TBLPROPERTIES ('property_name' = 'property_value', ...);案例:给表添加一个描述性注释
sql
ALTER TABLE application_logs SET TBLPROPERTIES ('comment' = 'System application access logs.');DROP TABLE:删除表
用于删除一个已存在的表。对于内部表,会同时删除元数据和 HDFS 上的数据;对于外部表,仅删除元数据。
语法:
sql
DROP TABLE [IF EXISTS] table_name [PURGE];IF EXISTS:如果表不存在,命令不会报错。PURGE:删除表时,数据不会进入 HDFS 回收站(如果启用了回收站)。
案例:删除一个名为old_temp_data的表,如果它存在的话
sql
DROP TABLE IF EXISTS old_temp_data;TRUNCATE TABLE:清空表数据
删除表中的所有行,但保留表结构和元数据。对于分区表,可以指定清空特定分区的数据。
语法:
sql
TRUNCATE TABLE table_name [PARTITION (partition_spec)];案例:清空 staging_area 表的所有数据
sql
TRUNCATE TABLE staging_area;二、分区的 DDL 操作
分区是 Hive 中重要的性能优化手段。
ALTER TABLE ... ADD PARTITION:添加分区
为一个已存在的分区表添加新的分区。可以同时指定分区的存储位置。
语法:
sql
ALTER TABLE table_name ADD [IF NOT EXISTS] PARTITION (partition_col1=val1, partition_col2=val2, ...) [LOCATION 'hdfs_path_to_partition_data']
[PARTITION (partition_col1=val3, partition_col2=val4, ...) [LOCATION '...'] ...];案例:为 application_logs 表(假设按 dt 和 country 分区)添加一个新分区
sql
-- 假设 application_logs 表已按 (dt STRING, country STRING) 分区
ALTER TABLE application_logs ADD IF NOT EXISTS PARTITION (dt='2023-11-15', country='US') LOCATION '/data/logs/app/2023-11-15/US';ALTER TABLE ... DROP PARTITION:删除分区
从分区表中删除一个或多个分区。与DROP TABLE类似,对于内部表的分区,会删除元数据和数据;对于外部表的分区,通常只删除元数据(行为可能受 Hive 版本和配置影响)。
语法:
sql
ALTER TABLE table_name DROP [IF EXISTS] PARTITION (partition_col1=val1, ...), PARTITION (partition_col1=val2, ...) [PURGE];案例:删除 application_logs 表的特定分区
sql
ALTER TABLE application_logs DROP IF EXISTS PARTITION (dt='2023-01-01', country='CA');ALTER TABLE ... RENAME PARTITION:重命名分区(较新版本支持)
修改一个现有分区的分区键值。这在需要更正错误的分区值或调整分区策略时很有用。
语法:
sql
ALTER TABLE table_name PARTITION (partition_col1=old_val1, ...) RENAME TO PARTITION (partition_col1=new_val1, ...);案例:将分区 dt='2023-OCT' 重命名为 dt='2023-10'
sql
-- 假设表 sales_monthly 按 (dt STRING) 分区
ALTER TABLE sales_monthly PARTITION (dt='2023-OCT') RENAME TO PARTITION (dt='2023-10');ALTER TABLE ... EXCHANGE PARTITION:交换分区(高级操作)
允许在两个具有相同表结构(列定义、文件格式等)的表之间原子地交换一个或多个分区的数据和元数据。常用于数据加载和发布的场景。
语法:
sql
ALTER TABLE table_A EXCHANGE PARTITION (partition_spec) WITH TABLE table_B;案例:将 staging_table 的一个分区数据交换到 production_table
sql
-- 假设 staging_table 和 production_table 结构相同且都按 (load_date DATE) 分区
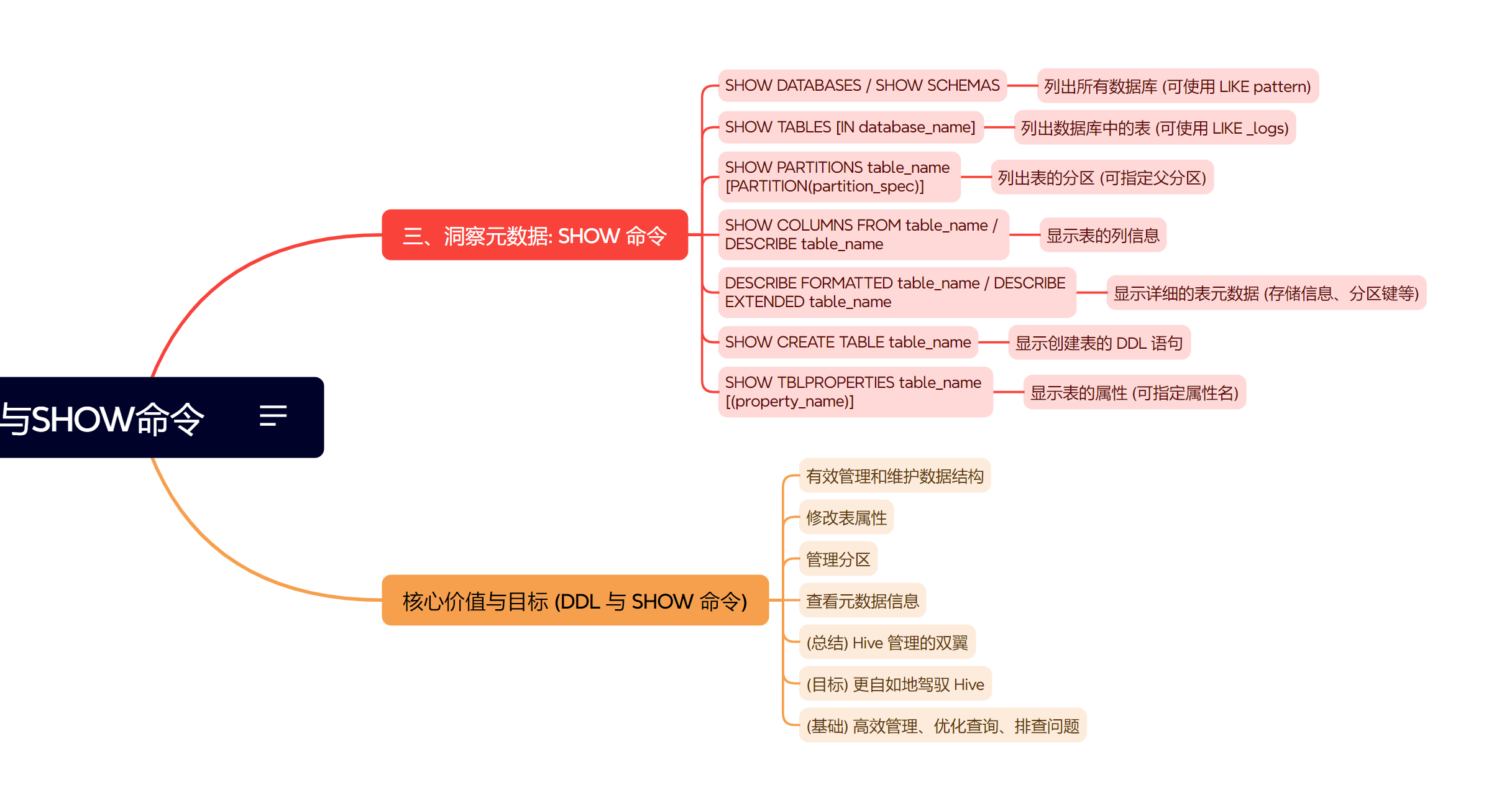
ALTER TABLE production_table EXCHANGE PARTITION (load_date='2023-11-16') WITH TABLE staging_table;三、洞察元数据:SHOW 命令的威力
SHOW 命令是查看 Hive 元数据信息的必备工具。
SHOW DATABASES或SHOW SCHEMAS:列出所有数据库
语法:
sql
SHOW DATABASES;
SHOW SCHEMAS;
SHOW DATABASES LIKE 'pattern*'; -- 支持通配符案例:
sql
SHOW DATABASES;
SHOW DATABASES LIKE 'prod_*';SHOW TABLES [IN database_name]:列出数据库中的表
语法:
sql
SHOW TABLES; -- 列出当前数据库的表
SHOW TABLES IN my_database;
SHOW TABLES LIKE '*_logs'; -- 支持通配符案例:
sql
USE default;
SHOW TABLES;
SHOW TABLES IN staging_db LIKE 'temp_*';SHOW PARTITIONS table_name [PARTITION(partition_spec)]:列出表的分区
语法:
sql
SHOW PARTITIONS table_name;
SHOW PARTITIONS table_name PARTITION(country='US'); -- 列出指定分区下的子分区(如果有多级分区)案例:
sql
SHOW PARTITIONS application_logs;
SHOW PARTITIONS application_logs PARTITION(dt='2023-11-15');SHOW COLUMNS FROM table_name或DESCRIBE table_name:显示表的列信息
语法:
sql
SHOW COLUMNS FROM table_name;
DESCRIBE table_name;案例:
sql
DESCRIBE application_logs;DESCRIBE FORMATTED table_name或DESCRIBE EXTENDED table_name:显示详细的表元数据
提供比DESCRIBE更全面的信息,包括存储信息、分区键、表属性等。
语法:
sql
DESCRIBE FORMATTED table_name;
DESCRIBE EXTENDED table_name;案例:
sql
DESCRIBE FORMATTED application_logs;SHOW CREATE TABLE table_name:显示创建表的 DDL 语句
这对于复制表结构或理解表是如何创建的非常有用。
语法:
sql
SHOW CREATE TABLE table_name;案例:
sql
SHOW CREATE TABLE application_logs;SHOW TBLPROPERTIES table_name [('property_name')]:显示表的属性
语法:
sql
SHOW TBLPROPERTIES table_name;
SHOW TBLPROPERTIES table_name ('comment'); -- 显示特定属性的值案例:
sql
SHOW TBLPROPERTIES application_logs;
SHOW TBLPROPERTIES application_logs ('comment');结语:DDL 与 SHOW,Hive 管理的双翼
熟练运用 Hive 的各类 DDL 操作和 SHOW 命令,是高效管理 Hive 数据仓库、优化查询性能以及排查问题的基础。从调整表结构到精细化管理分区,再到深入洞察元数据,这些
命令共同构成了数据工程师与 Hive 交互的日常语言。通过不断的实践,您将更加得心应手地驾驭这个强大的数据工具。
练习题
一、选择题
-
以下哪个命令用于将 Hive 表
old_log重命名为archived_log?A.
RENAME TABLE old_log TO archived_log;B.
ALTER TABLE old_log RENAME TO archived_log;C.
MODIFY TABLE old_log NAME archived_log;D.
UPDATE TABLE old_log SET NAME = archived_log; -
要查看表
employees的详细元数据信息,包括存储格式和表属性,应使用哪个命令?A.
SHOW TABLE employees;B.
DESCRIBE employees;C.
SHOW CREATE TABLE employees;D.
DESCRIBE FORMATTED employees; -
哪个命令用于从分区表
daily_sales中删除dt='2023-01-15'这个分区?A.
DELETE PARTITION (dt='2023-01-15') FROM daily_sales;B.
DROP PARTITION daily_sales (dt='2023-01-15');C.
ALTER TABLE daily_sales DROP PARTITION (dt='2023-01-15');D.
TRUNCATE TABLE daily_sales PARTITION (dt='2023-01-15');
二、代码题
-
场景 :你有一个名为
customer_profiles的表,当前包含列customer_id INT, name STRING, email STRING。
要求:- 向该表添加一个新的列
phone_number STRING,并添加注释 'Customer contact phone number'。 - 修改
email列的名称为email_address,并将其数据类型更改为STRING(假设它已经是STRING,这里仅演示改名)。
请编写完成上述操作的 HQL 语句。
- 向该表添加一个新的列
-
场景 :你有一个按
log_date DATE和event_type STRING分区的表event_stream。
要求:- 列出
event_stream表中所有log_date为 '2023-11-16' 的分区。 - 显示
event_stream表的完整创建 DDL 语句。
请编写完成上述操作的 HQL 语句。
- 列出
练习题答案
一、选择题答案
- B .
ALTER TABLE old_log RENAME TO archived_log; - D .
DESCRIBE FORMATTED employees; - C .
ALTER TABLE daily_sales DROP PARTITION (dt='2023-01-15');
二、代码题答案
- 修改
customer_profiles表结构:
sql
-- 添加新列
ALTER TABLE customer_profiles ADD COLUMNS (phone_number STRING COMMENT 'Customer contact phone number');
-- 修改列名(和类型,如果需要的话)
ALTER TABLE customer_profiles CHANGE COLUMN email email_address STRING;- 查看
event_stream表信息:
sql
-- 列出特定分区下的子分区 (这里假设 event_type 是子分区)
SHOW PARTITIONS event_stream PARTITION(log_date='2023-11-16');
-- 显示表的创建DDL
SHOW CREATE TABLE event_stream;