目录
[1 硬件层面优化](#1 硬件层面优化)
[1.1 CPU优化](#1.1 CPU优化)
[1.2 内存优化](#1.2 内存优化)
[1.3 存储优化](#1.3 存储优化)
[1.4 网络优化](#1.4 网络优化)
[2 系统配置优化](#2 系统配置优化)
[2.1 操作系统配置](#2.1 操作系统配置)
[2.2 MySQL服务配置](#2.2 MySQL服务配置)
[3 库表结构优化](#3 库表结构优化)
[4 SQL及索引优化](#4 SQL及索引优化)
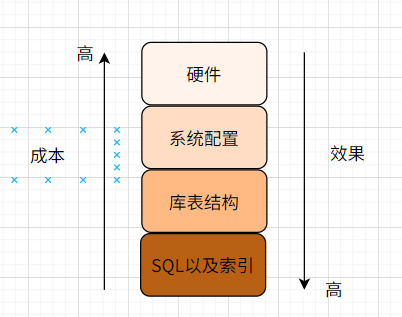
mysql可以从四个层面考虑优化,分别是
- 硬件
- 系统配置
- 库表结构
- SQL及索引
从成本和优化效果来看,从以上四方面优化如下
1 硬件层面优化
1.1 CPU优化
选择高性能多核处理器,可以有效提升高并发处理能力
1.2 内存优化
- MySQL InnoDB存储引擎使用缓冲池缓存数据页和索引,足够多的内存可以让更多的数据缓存,减少磁盘I/O操作
- 增加物理内存同时需要调整MySQL服务配置innodb_buffer_pool_size,一般设置为物理内存70%~80%
1.3 存储优化
- 使用SSD,提供更好地磁盘IO能力
- 如果不能完全使用SSD替换,可以考虑部分替换
- 比如将redo日志,undo日志,binlog日志等重要日志存储路径指向SSD磁盘
1.4 网络优化
- 提高网络吞吐能力
- 减少网络传输
2 系统配置优化
2.1 操作系统配置
- 增加文件描述符限制ulimit -n
- tcp参数调优
|-----------------------|-----------------------------------|----------------------------------------------------------|
| 参数 | 作用 | 影响 |
| tcp_window_scaling | 允许网络连接两端使用比标准创建大小(65535字节)更大的接收窗口 | 对于跨广域网或者数据中心间的数据传输非常有用 可以减少由于网络延迟造成的传输瓶颈 |
| net.ipv4.tcp_fastopen | 允许三次握手期间传输数据 减少了建立新连接的时间 | 对于频发短连接场景有利 |
| tcp_keepalive_time | tcp连接多久没有活动后开始发送保活探测包 | 适当调整该配置可以帮助更快地检测到断开的连接 避免长时间占用资源等待无响应的客户端 避免设置太短产生不必要的流程 |
| tcp_tw_reuse | 允许将TIME_WAIT状态的套接字用于新的相同四元组连接 | 可以更快复用TIME_WAIT状态端口 |
- 选择合适的文件系统,比如ext4或者xfs
- 禁用 atime 更新,减少不必要的磁盘写入
2.2 MySQL服务配置
|--------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 参数 | 说明 |
| max_connections | 最大连接数 连接的创建意味需要分配系统资源,内存和文件描述符等 当连接建立时分配内存=线程栈空间 (thread_stack)+基本的连接管理结构(较小且固定) 当执行全表扫描时分配读缓冲区(read_buffer_size) 当执行没有索引的联接查询时分配连接缓冲区(join_buffer_size) 当需要排序操作时分配排序缓冲区(sort_buffer_size) 当需要使用临时表时分配临时表缓冲区(tmp_table_size, max_heap_table_size),如果需要临时表超过该内存大小时,会使用磁盘存储临时表 如果系统内存不足时,将会使用磁盘swap内存,导致性能降低 因此需要设置合适的连接数 |
| max_user_connections | 单个用户允许的最大连接数 |
| back_log | 暂存的连接数,超过最大连接数小于该设置值时不立即失败,而是等待资源释放 |
| wait_timeout | jdbc连接空闲一定时间后断开连接 |
| interactive_timeout | mysql client连接空闲一定时间后断开 |
| sort_buffer_size | 排序缓冲区,可以加速order by或group by 给每个连接分配排序缓冲区 |
| join_buffer_size | 表关联缓冲区,当表关联不走索引时,使用到该缓冲区,将驱动表一部分数据读取到该缓冲区,然后与被驱动表进行关联查询,查询完成后,清理缓冲区,继续将驱动表剩余数据读取到缓冲区进行关联查询 给每个连接分配表关联缓冲区 |
| innodb_thread_concurrency | innodb并发线程数 默认值为0,表示不限制 通常设置cpu核心数或者核心数的2倍 |
| innodb_buffer_pool_size | innodb缓冲区大小 一般为物理内存的70%~80% |
| innodb_lock_wait_timeout | 行锁锁定时间 默认值50s |
| innodb_flush_log_at_trx_commit | redo日志落盘时机 * 设置为0:表示每次事务提交时都将redo日志写入redo日志缓冲区,数据库宕机时可能会丢失数据 * 设置为1时(默认值),表示每次事务时都会将redo日志持久化到磁盘,数据最安全,不会因为数据库或者系统宕机导致数据丢失,但是性能差一点 * 设置为2时,表示每次提交事务时都只是将redo日志写到操作系统缓存(page cache)中,这种情况数据库宕机不会丢失数据,操作系统宕机的话,如果page cache中的数据没来的及写入磁盘文件的话就会丢失数据 |
| sync_binlog | binlog落盘时机 * 为0时(默认),表示每次提交事务只写到os 缓存page cache中,由操作系统自行判断什么时候执行fsync写入磁盘,服务器宕机时有可能丢失数据 * 为1时,表示每次提交事务都会执行fsync写入磁盘 * 当>1时,表示每次提交事务都写入到os缓存page cache中,当积累N个事务后调用fsync写入磁盘,服务其宕机时最多丢失N个事务 |
- 如何判断服务器的内存达到瓶颈?
- 查看服务器状态,得到命中innodb缓存的命中率,命中率过小时说明缓冲中的数据被频繁的交换
` `show` `global` `status` `like` `'innodb%read%'\G;|--------------------------------------|--------------------------------------|
| 参数 | 说明 |
| nnodb_buffer_pool_reads | 从物理磁盘读取页的次数 |
| nnodb_buffer_pool_read_ahead | 预读的次数 |
| nnodb_buffer_pool_read_ahead_evicted | 预读的页但是没有后续被读取到缓冲池的页替换的页的数量 用于判断预读的效率 |
| nnodb_buffer_pool_read_requests | 从缓冲池中读取页的次数 |
| nnodb_buffer_pool_read_requests | 总共读入的字节数 |
| nnodb_data_reads | 发起读取的次数,每次读取可能读取多个页 |
3 库表 结构 优化
- 选择合适的字段类型
- 选择合适的字段大小
- 选择合适的存储引擎
- 大表拆小表
4 SQL及索引优化
参见索引优化章节