引言
在YOLO v1取得巨大成功之后,Joseph Redmon等人在2016年提出了YOLO v2(也称为YOLO9000),这是一个在准确率和速度上都取得显著提升的版本。YOLO v2不仅保持了v1的高速特性,还通过一系列创新技术大幅提高了检测精度,使其能够处理更复杂的检测任务。本文将深入解析YOLO v2的核心改进和技术细节。
YOLO v2的主要改进
YOLO v2相对于v1进行了多方面的优化,主要包括:
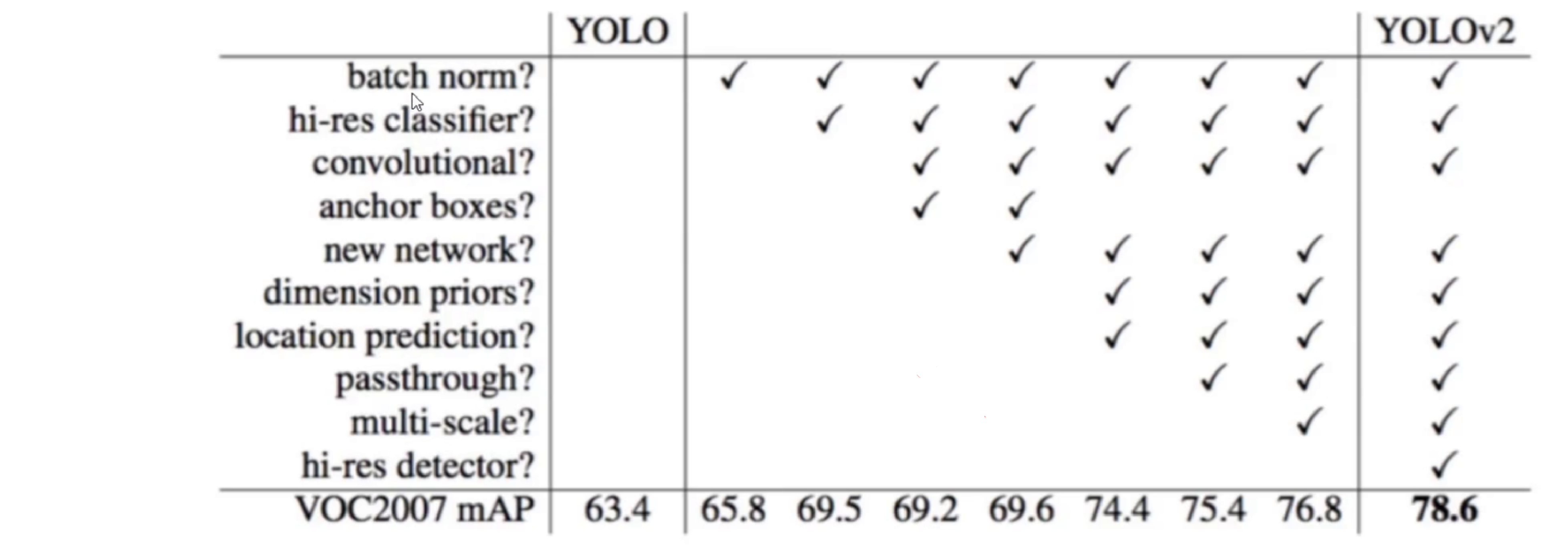
1. 高分辨率分类器(High Resolution Classifier)
YOLO v1在224×224分辨率下预训练分类器,然后切换到448×448进行检测训练。而v2直接在448×448分辨率下进行10个epoch的分类器微调,使网络适应更高分辨率的输入。
2. 批量归一化(Batch Normalization)
v2在所有卷积层后添加了批量归一化层,这一改进:
- 提高了模型收敛速度
- 减少了过拟合
- 可以移除dropout而不会导致过拟合
- 带来了超过2%的mAP提升
3. 锚框机制(Anchor Boxes)
YOLO v2摒弃了v1中完全依赖网格预测边界框的方式,转而采用Faster R-CNN风格的锚框(anchor boxes):
- 使用k-means聚类在训练集边界框上自动学习先验框尺寸
- 最终选择了5个最具代表性的先验框尺寸(相比Faster R-CNN的9个更高效)
- 每个网格单元预测5个边界框(v1只有2个)
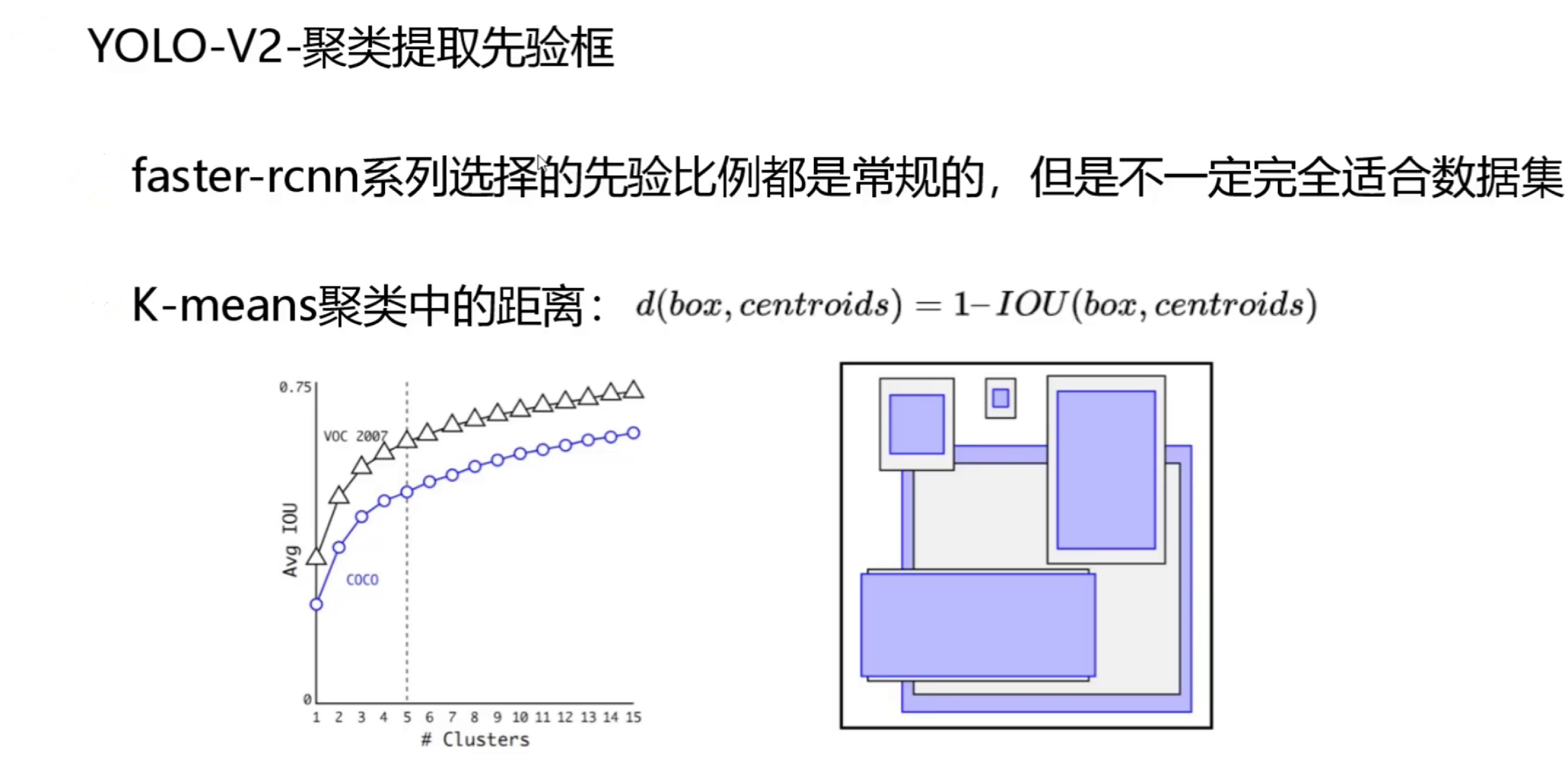
4. 维度聚类(Dimension Clusters)
YOLO v2创新性地使用k-means聚类来确定最佳的先验框尺寸:
python
# 使用IOU作为距离度量进行k-means聚类
d(box, centroid) = 1 - IOU(box, centroid)这种基于IOU的聚类方法比传统的欧氏距离更适合目标检测任务,最终在COCO数据集上选择了5个聚类中心作为先验框尺寸。
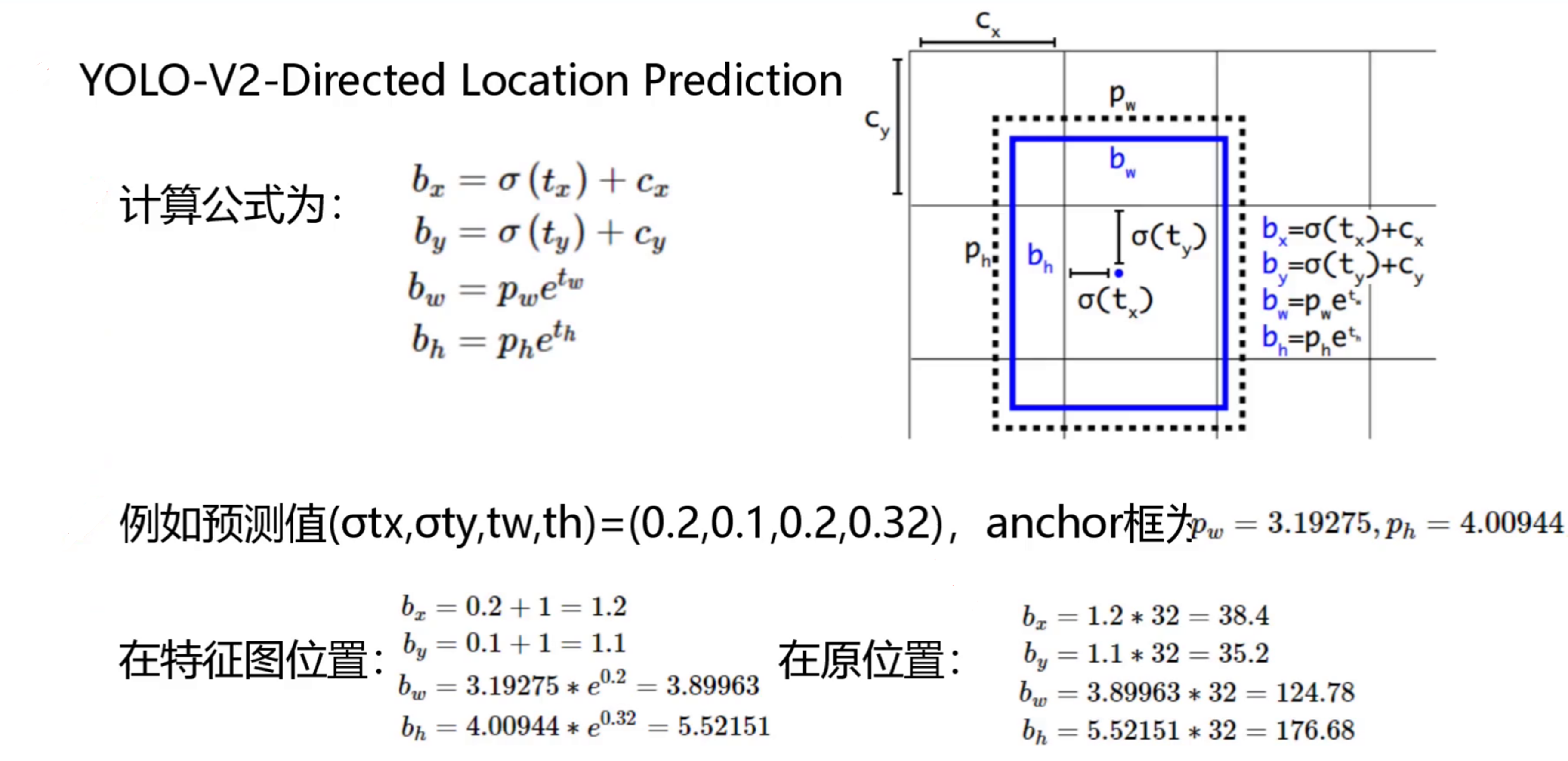
5. 直接位置预测(Direct Location Prediction)
YOLO v2改进了边界框中心坐标的预测方式:
-
预测相对于网格单元左上角的偏移量(tx, ty)
-
使用sigmoid函数将偏移量限制在0-1范围内
-
预测公式为:
bx = σ(tx) + cx by = σ(ty) + cy bw = pw * e^(tw) bh = ph * e^(th)其中(cx,cy)是网格单元左上角坐标,(pw,ph)是先验框的宽高。
6. 细粒度特征(Fine-Grained Features)
YOLO v2添加了一个直通层(passthrough layer),将前面26×26×512的特征图与13×13×1024的特征图连接起来:
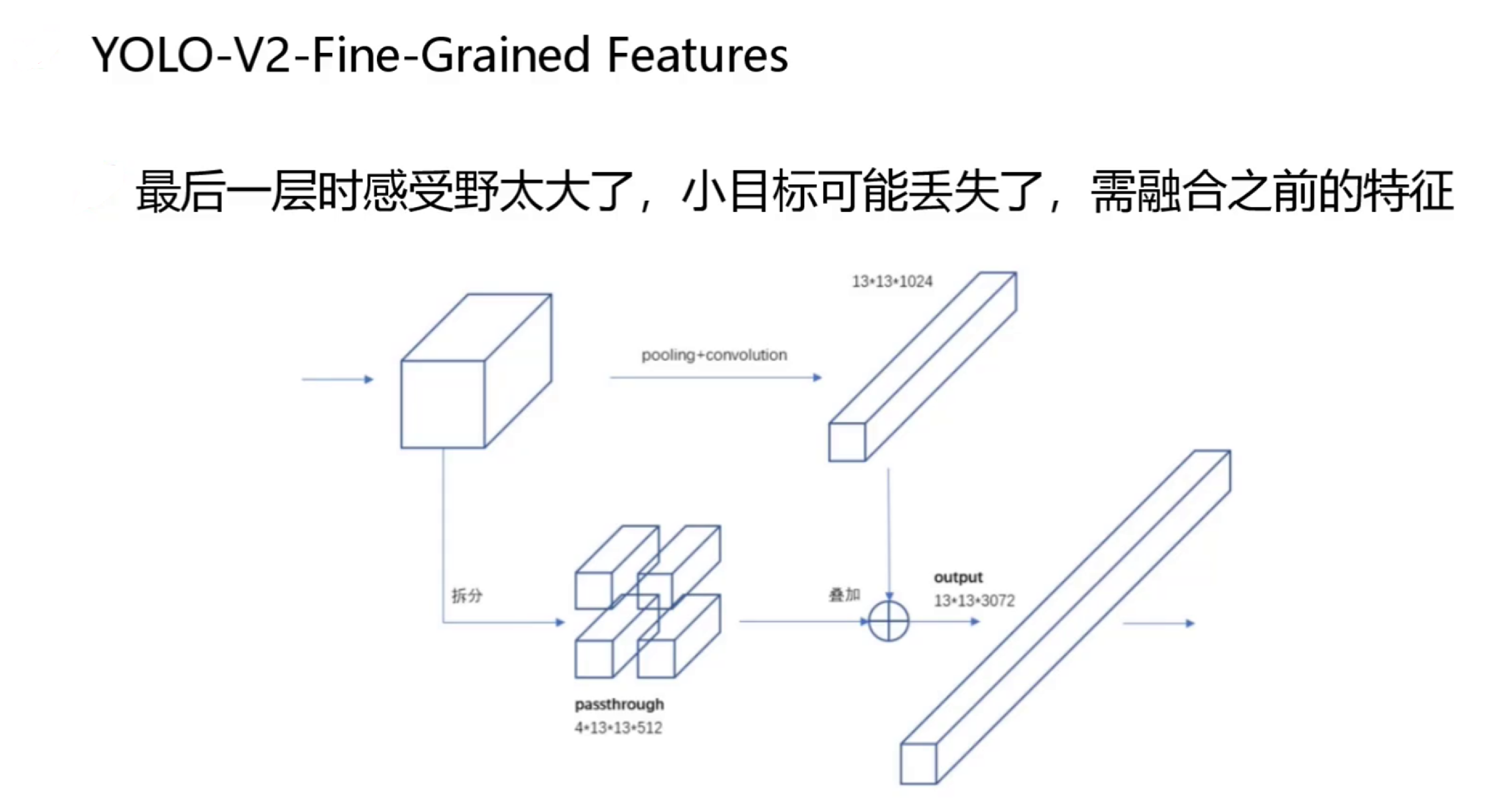
- 将高分辨率特征图(26×26)重组为低分辨率(13×13×4)
- 与原始低分辨率特征图连接(13×13×(1024+512*4)=13×13×3072)
- 这种特征融合方式有助于检测小物体
7. 多尺度训练(Multi-Scale Training)
YOLO v2移除了全连接层,使网络可以接受任意尺寸的输入:
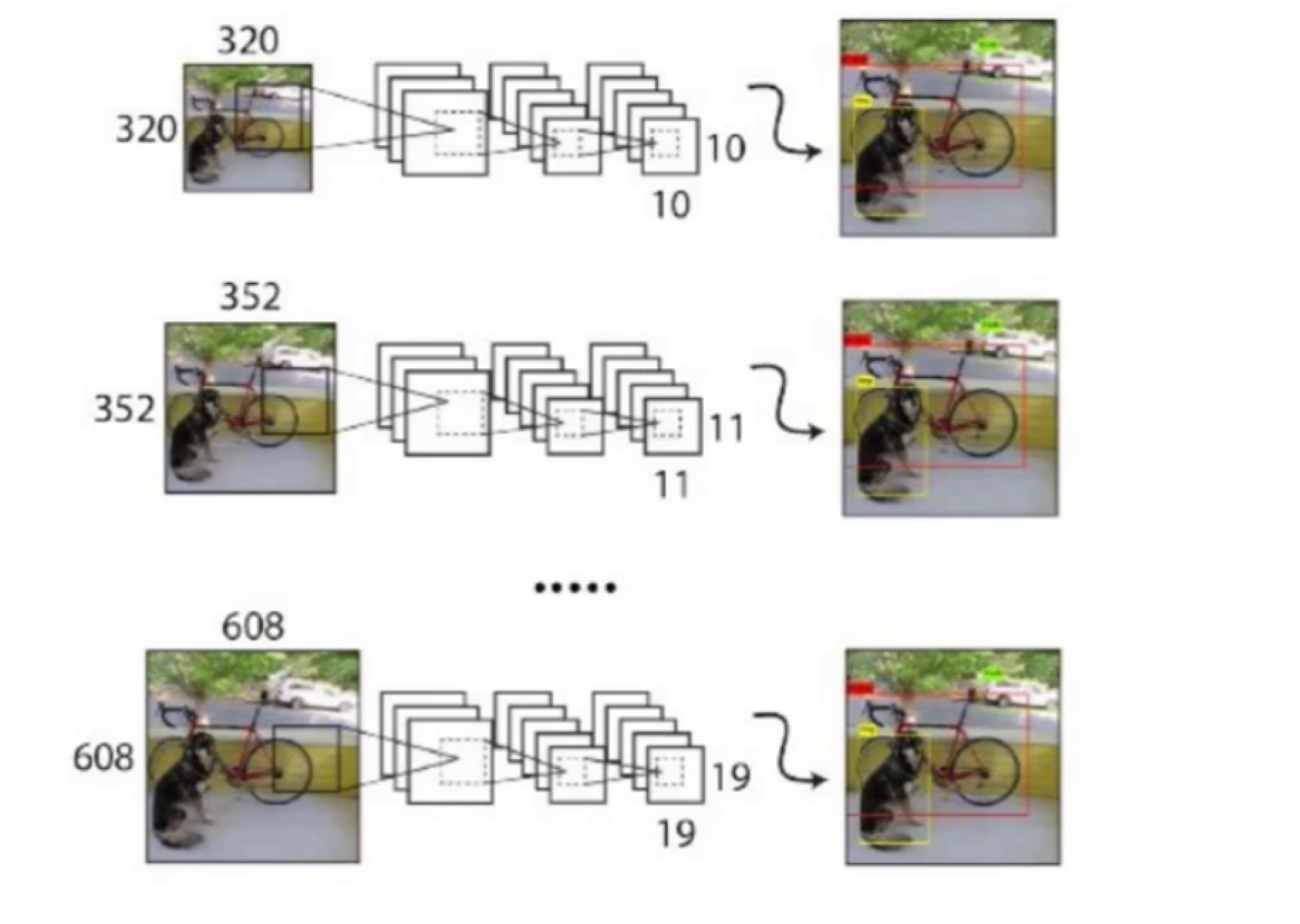
- 每10个batch就随机选择一个新的输入尺寸
- 从{320, 352, ..., 608}(32的倍数)中随机选择
- 使模型能够适应不同分辨率的检测任务
- 较小的尺寸(如288×288)可实现高达90FPS的速度
- 较大的尺寸(如544×544)可获得更高的mAP
YOLO v2网络架构

YOLO v2采用了名为Darknet-19的主干网络:
- 19个卷积层
- 5个最大池化层
- 借鉴了VGG16的思想,但计算量更少
- 使用全局平均池化代替全连接层进行分类
- 在检测任务中移除了最后的卷积层和全局平均池化,添加了三个3×3卷积层和一个1×1卷积层
YOLO v2性能提升
通过这些改进,YOLO v2在多个方面超越了v1:
- 准确率:在PASCAL VOC 2007上,mAP从63.4%提升到78.6%
- 速度:保持实时性(40-90FPS,取决于输入尺寸)
- 灵活性:可以处理不同分辨率的输入
- 类别数:YOLO9000版本可以检测超过9000个物体类别
YOLO v2的局限性
尽管YOLO v2取得了显著进步,但仍存在一些不足:
- 对小物体的检测精度仍有提升空间
- 密集物体检测时容易出现漏检
- 边界框定位精度不如两阶段方法
应用实践
在实际使用YOLO v2时,有几个关键点需要注意:
- 锚框尺寸选择:应根据自己的数据集重新运行k-means聚类
- 输入尺寸选择:需要在速度和精度之间权衡
- 数据增强:适当的数据增强可以显著提升模型性能
结语
YOLO v2通过一系列精心设计的改进,在保持YOLO系列高速特性的同时,显著提升了检测精度。其引入的锚框机制、维度聚类、多尺度训练等技术对后续的目标检测算法发展产生了深远影响。虽然现在已经有了更新的YOLO版本,但YOLO v2中的许多创新思想仍然值得学习和借鉴。