名人说:路漫漫其修远兮,吾将上下而求索。------ 屈原《离骚》
创作者:Code_流苏(CSDN) (一个喜欢古诗词和编程的Coder😊)目录
- 一、命名实体识别(NER)基础
- [1. 什么是命名实体识别?](#1. 什么是命名实体识别?)
- [2. 常见的实体类型](#2. 常见的实体类型)
- [3. NER的技术实现](#3. NER的技术实现)
- [(1) 基于规则的方法](#(1) 基于规则的方法)
- [(2) 统计机器学习方法](#(2) 统计机器学习方法)
- [(3) 深度学习方法](#(3) 深度学习方法)
- [(4) 预训练语言模型](#(4) 预训练语言模型)
- [4. NER的标注方式](#4. NER的标注方式)
- 二、深入理解命名实体识别
- [1. NER的应用场景](#1. NER的应用场景)
- [2. NER评估指标](#2. NER评估指标)
- [3. 领域适应与迁移学习](#3. 领域适应与迁移学习)
- 三、关系抽取基础
- [1. 什么是关系抽取?](#1. 什么是关系抽取?)
- [2. 关系类型与表示](#2. 关系类型与表示)
- [3. 关系抽取的技术方法](#3. 关系抽取的技术方法)
- [(1) 基于规则的方法](#(1) 基于规则的方法)
- [(2) 基于监督学习的方法](#(2) 基于监督学习的方法)
- [(3) 基于远程监督的方法](#(3) 基于远程监督的方法)
- [(4) 基于预训练语言模型的方法](#(4) 基于预训练语言模型的方法)
- 四、NER与关系抽取实战
- [1. 使用spaCy进行NER实践](#1. 使用spaCy进行NER实践)
- [2. 使用Hugging Face进行BERT-NER微调](#2. 使用Hugging Face进行BERT-NER微调)
- [3. 构建端到端信息抽取系统](#3. 构建端到端信息抽取系统)
- 五、命名实体识别与关系抽取的实际应用
- [1. 知识图谱构建](#1. 知识图谱构建)
- [2. 企业智能应用](#2. 企业智能应用)
- [3. 学术研究与医疗应用](#3. 学术研究与医疗应用)
- 六、总结与展望
👋 专栏介绍 : Python星球日记专栏介绍(持续更新ing)
✅ 上一篇 : 《Python星球日记》 第70天:Seq2Seq 与Transformer Decoder
欢迎回到Python星球🪐日记!今天是我们旅程的第71天。
在自然语言处理(NLP)领域,理解文本中的实体及其关系是构建智能系统的基础。今天,我们将探索命名实体识别 和关系抽取这两项核心技术,它们共同构成了信息抽取的重要环节,为知识图谱、智能问答和文本分析等应用提供关键支持。
一、命名实体识别(NER)基础
1. 什么是命名实体识别?
命名实体识别 (Named Entity Recognition,简称NER)是指从非结构化文本中识别并提取特定类型的实体(如人名、地名、组织名等)的过程。它是信息抽取和知识图谱构建的第一步,为文本理解奠定基础。
举个例子,在句子"马克·扎克伯格于2004年在哈佛大学创立了Facebook"中,NER系统会识别出:
- "马克·扎克伯格" → 人名(PERSON)
- "2004年" → 时间(DATE)
- "哈佛大学" → 组织名(ORGANIZATION)
- "Facebook" → 组织名(ORGANIZATION)
2. 常见的实体类型
命名实体通常分为以下几种类型:
| 实体类型 | 描述 | 示例 |
|---|---|---|
| PERSON | 人名 | 马云、李彦宏、比尔·盖茨 |
| LOCATION | 地理位置 | 北京、黄河、埃菲尔铁塔 |
| ORGANIZATION | 组织机构名 | 腾讯、清华大学、联合国 |
| DATE | 日期时间 | 2023年、5月1日、下午三点 |
| MONEY | 货币金额 | 100元、$50、5000万美元 |
| PERCENT | 百分比 | 50%、三分之一 |
| EVENT | 事件 | 世界杯、奥运会 |
| PRODUCT | 产品 | iPhone、Tesla Model 3 |
注意:不同的NER系统可能会定义不同的实体类型集合,根据具体应用场景进行调整。
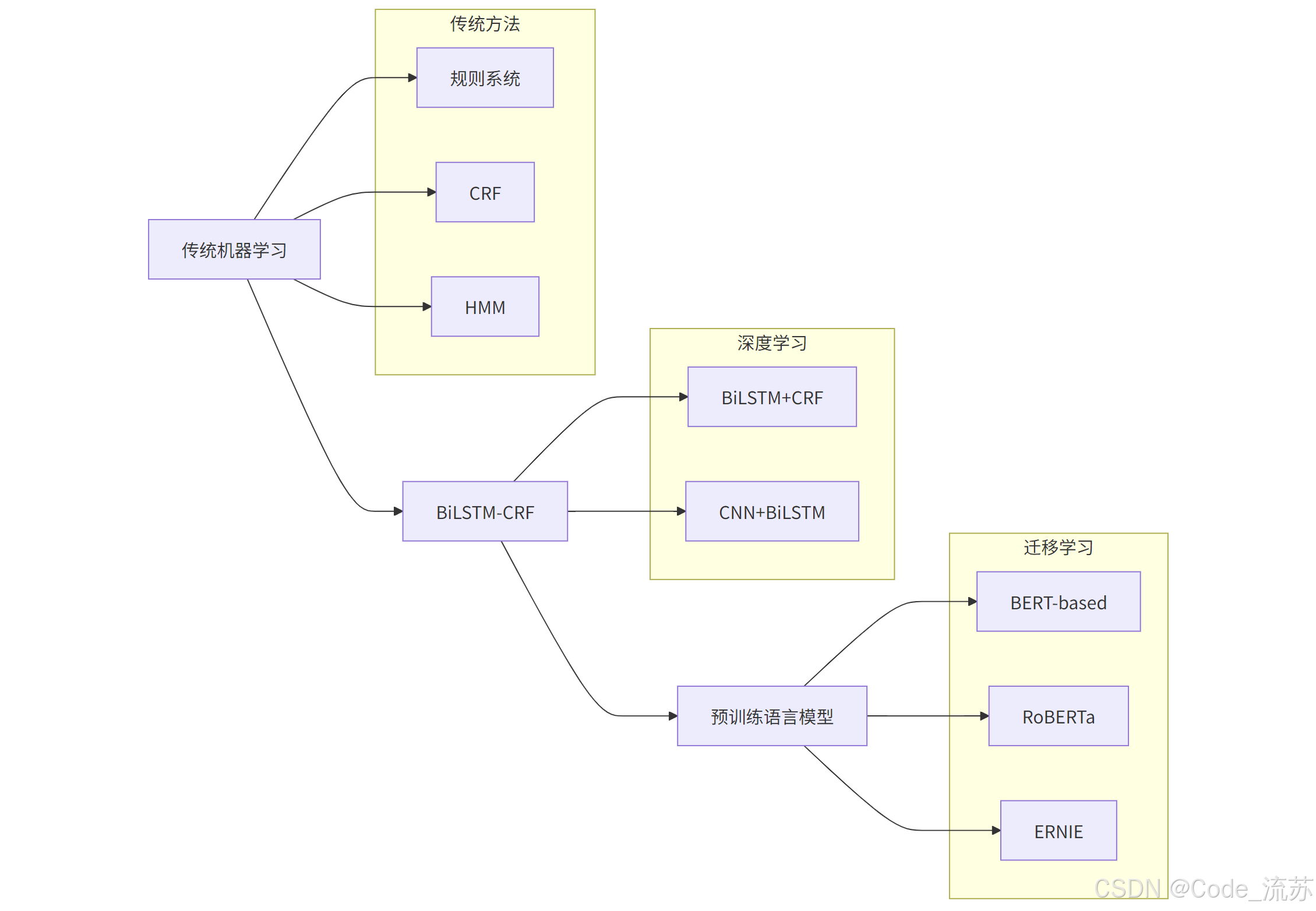
3. NER的技术实现
NER技术经历了从规则到深度学习的演进历程:
(1) 基于规则的方法
最早的NER系统主要依靠人工编写的规则 和匹配模式。虽然在特定领域可以达到不错的效果,但缺乏泛化能力,维护成本高。
(2) 统计机器学习方法
随后出现了基于条件随机场 (CRF)、隐马尔可夫模型(HMM)等统计模型的方法,将NER视为序列标注问题,通过手工特征工程提升性能。
(3) 深度学习方法
BiLSTM-CRF模型结合了双向LSTM捕获上下文信息的能力和CRF建模标签依赖关系的优势,成为NER任务的经典架构。
python
# BiLSTM-CRF模型的简化PyTorch实现
class BiLSTM_CRF(nn.Module):
def __init__(self, vocab_size, tag_to_ix, embedding_dim, hidden_dim):
super(BiLSTM_CRF, self).__init__()
self.embedding_dim = embedding_dim
self.hidden_dim = hidden_dim
self.vocab_size = vocab_size
self.tag_to_ix = tag_to_ix
self.tagset_size = len(tag_to_ix)
# 词嵌入层
self.word_embeds = nn.Embedding(vocab_size, embedding_dim)
# 双向LSTM
self.lstm = nn.LSTM(embedding_dim, hidden_dim // 2,
num_layers=1, bidirectional=True)
# 映射到标签空间
self.hidden2tag = nn.Linear(hidden_dim, self.tagset_size)
# CRF层的转移矩阵
self.transitions = nn.Parameter(
torch.randn(self.tagset_size, self.tagset_size))(4) 预训练语言模型
BERT等预训练语言模型的出现极大提升了NER性能,它们能够捕获丰富的上下文语义信息,为下游任务提供强大的特征表示。
python
# 使用BERT进行NER的简化示例
from transformers import BertForTokenClassification, BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
model = BertForTokenClassification.from_pretrained('bert-base-chinese', num_labels=len(tag_list))
# 输入处理
tokens = tokenizer.tokenize(text)
inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True)
# 预测
outputs = model(**inputs)
predictions = torch.argmax(outputs.logits, dim=2)4. NER的标注方式
NER任务常用的标注方式有:
- BIO标注:B-开始,I-内部,O-外部
- BIOES标注:B-开始,I-内部,O-外部,E-结束,S-单个实体
例如,对于句子"张三在北京大学学习":
张/B-PER 三/I-PER 在/O 北/B-ORG 京/I-ORG 大/I-ORG 学/I-ORG 学/O 习/O

二、深入理解命名实体识别
1. NER的应用场景
命名实体识别作为信息抽取的基础环节,在众多应用场景中扮演着关键角色:
- 搜索引擎优化:识别查询中的实体,提供更精准的搜索结果
- 智能问答系统:理解问题中的关键实体,检索相关信息
- 知识图谱构建:自动从文本中提取实体,作为知识图谱的节点
- 舆情分析:识别文本中提及的人物、组织、地点等,进行情感分析
- 医疗信息处理:从医疗文献中提取疾病、药品、症状等专业术语
- 法律文档处理:识别法律文书中的当事人、案由、日期等关键信息
2. NER评估指标
评估NER系统性能通常使用以下指标:
- 精确率(Precision):正确识别的实体数量 / 系统识别出的所有实体数量
- 召回率(Recall):正确识别的实体数量 / 文本中实际存在的所有实体数量
- F1值:精确率和召回率的调和平均,计算公式为 2 * (Precision * Recall) / (Precision + Recall)
对于NER任务,评估时需要完全匹配实体的边界和类型才算正确识别。
3. 领域适应与迁移学习
通用NER系统在特定领域(如医疗、法律、金融等)可能表现不佳,需要进行领域适应:
- 数据增强:使用领域内数据扩充训练集
- 迁移学习:利用预训练模型,在领域数据上进行微调
- 半监督学习:结合少量标注数据和大量未标注数据
三、关系抽取基础
1. 什么是关系抽取?
关系抽取(Relation Extraction)是指从文本中识别并提取实体之间语义关系的过程。它是NER的延伸,共同构成结构化知识的关键环节。
2. 关系类型与表示
关系抽取的第一步是定义关系类型集合。常见的关系类型包括:
| 关系类型 | 描述 | 示例 |
|---|---|---|
| 从属关系 | 表示归属、隶属等 | (腾讯, 创始人, 马化腾) |
| 空间关系 | 表示地理位置相关性 | (故宫, 位于, 北京) |
| 时间关系 | 表示时间相关性 | (奥运会, 举办于, 2022年) |
| 社会关系 | 表示人际关系 | (马云, 创立, 阿里巴巴) |
| 因果关系 | 表示原因和结果 | (吸烟, 导致, 肺癌) |
关系通常表示为三元组形式:(头实体, 关系, 尾实体),如 (北京, 是, 中国首都)。
3. 关系抽取的技术方法
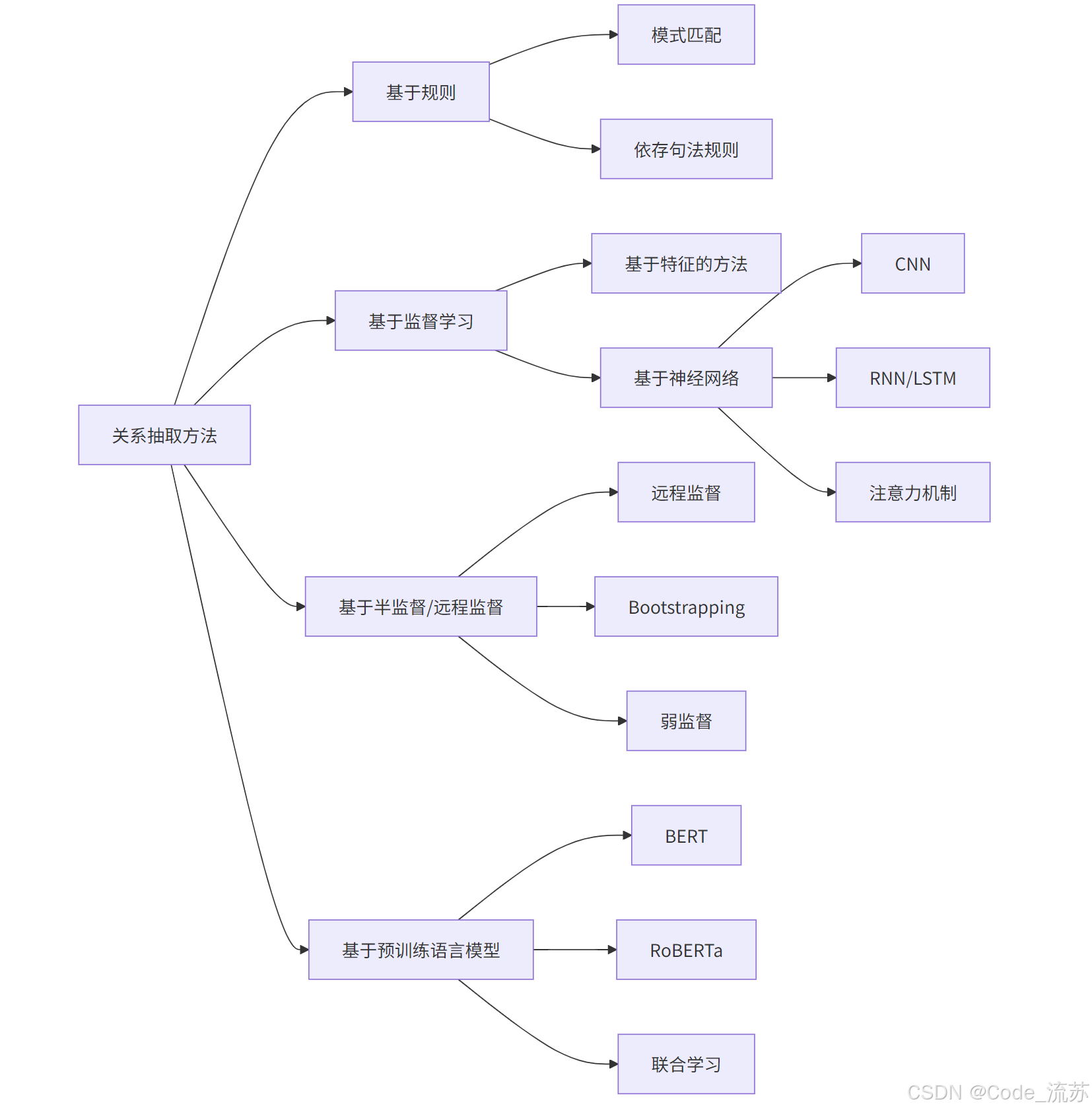
(1) 基于规则的方法
早期关系抽取主要基于人工定义的规则 和模式匹配,通过词法和句法分析来提取关系。
python
# 基于依存句法分析的简单关系抽取示例
import spacy
nlp = spacy.load("zh_core_web_sm")
text = "马云创立了阿里巴巴公司。"
doc = nlp(text)
# 基于依存关系的简单规则
for token in doc:
if token.dep_ == "ROOT" and token.pos_ == "VERB": # 谓语动词
subject = None
object = None
for child in token.children:
if child.dep_ == "nsubj": # 主语
subject = child.text
if child.dep_ == "dobj": # 宾语
object = child.text
if subject and object:
print(f"关系三元组: ({subject}, {token.text}, {object})")(2) 基于监督学习的方法
监督学习方法将关系抽取视为分类任务,给定一对实体和包含它们的句子,预测它们之间的关系类型。
早期使用手工特征 (词法、句法、位置信息等),后来发展为基于神经网络的方法:
python
# 使用BERT进行关系分类的示例
from transformers import BertForSequenceClassification, BertTokenizer
import torch
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
model = BertForSequenceClassification.from_pretrained('bert-base-chinese', num_labels=len(relation_types))
# 输入处理:为实体对添加特殊标记
def process_text(text, head_entity, tail_entity):
# 用特殊标记标注实体位置
marked_text = text.replace(head_entity, f"[E1]{head_entity}[/E1]")
marked_text = marked_text.replace(tail_entity, f"[E2]{tail_entity}[/E2]")
return marked_text
# 训练和预测
inputs = tokenizer(marked_text, padding=True, truncation=True, return_tensors="pt")
outputs = model(**inputs)
predicted_relation = torch.argmax(outputs.logits, dim=1).item()(3) 基于远程监督的方法
**远程监督(Distant Supervision)**是解决关系抽取标注数据不足问题的重要方法。其核心思想是:如果两个实体在知识库中存在某种关系,则包含这两个实体的句子很可能表达了这种关系。
python
# 远程监督示例:利用知识库自动标注训练数据
def generate_training_data(corpus, knowledge_base):
training_data = []
for sentence in corpus:
entities = extract_entities(sentence) # 假设有NER系统
# 找出句子中所有可能的实体对
for head_entity in entities:
for tail_entity in entities:
if head_entity != tail_entity:
# 在知识库中查找关系
relation = knowledge_base.query_relation(head_entity, tail_entity)
if relation:
# 生成训练样本
training_data.append({
'sentence': sentence,
'head': head_entity,
'tail': tail_entity,
'relation': relation
})
return training_data(4) 基于预训练语言模型的方法
BERT 等预训练模型极大提升了关系抽取性能,通过微调 和联合学习可以进一步优化效果。
python
# 使用BERT进行端到端关系抽取(实体识别 + 关系分类)
class JointNERAndRE(nn.Module):
def __init__(self, num_entity_types, num_relation_types):
super(JointNERAndRE, self).__init__()
self.bert = BertModel.from_pretrained('bert-base-chinese')
# NER分类器
self.ner_classifier = nn.Linear(self.bert.config.hidden_size, num_entity_types)
# 关系分类器
self.re_classifier = nn.Linear(self.bert.config.hidden_size * 2, num_relation_types)
def forward(self, input_ids, attention_mask, token_type_ids):
# BERT编码
outputs = self.bert(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids
)
sequence_output = outputs.last_hidden_state # 用于NER
pooled_output = outputs.pooler_output # 用于RE
# NER预测
ner_logits = self.ner_classifier(sequence_output)
# 关系预测(简化版)
re_logits = self.re_classifier(pooled_output)
return ner_logits, re_logits四、NER与关系抽取实战
1. 使用spaCy进行NER实践
spaCy是一个强大的NLP库,提供了高效的命名实体识别功能:
python
import spacy
from spacy import displacy
# 加载中文模型
nlp = spacy.load("zh_core_web_sm")
# 处理文本
text = "马云于1999年在杭州创立了阿里巴巴,并担任CEO直到2019年。"
doc = nlp(text)
# 提取命名实体
for ent in doc.ents:
print(f"实体: {ent.text}, 类型: {ent.label_}")
# 可视化
displacy.render(doc, style="ent", jupyter=True)
# 定义自定义实体类型
custom_labels = {
"人物": "PERSON",
"组织": "ORG",
"地点": "LOC",
"时间": "DATE"
}
# 训练自定义NER模型
from spacy.training.example import Example
# 准备训练数据
train_data = [
("马云于1999年在杭州创立了阿里巴巴。", {"entities": [(0, 2, "PERSON"), (3, 8, "DATE"), (9, 11, "LOC"), (14, 18, "ORG")]}),
# 更多训练数据...
]
# 创建空模型
nlp = spacy.blank("zh")
ner = nlp.add_pipe("ner")
# 添加实体标签
for _, annotations in train_data:
for ent in annotations.get("entities"):
ner.add_label(ent[2])
# 训练模型
optimizer = nlp.begin_training()
for i in range(100):
losses = {}
examples = []
for text, annots in train_data:
examples.append(Example.from_dict(nlp.make_doc(text), annots))
nlp.update(examples, drop=0.5, losses=losses)
print(f"Loss: {losses}")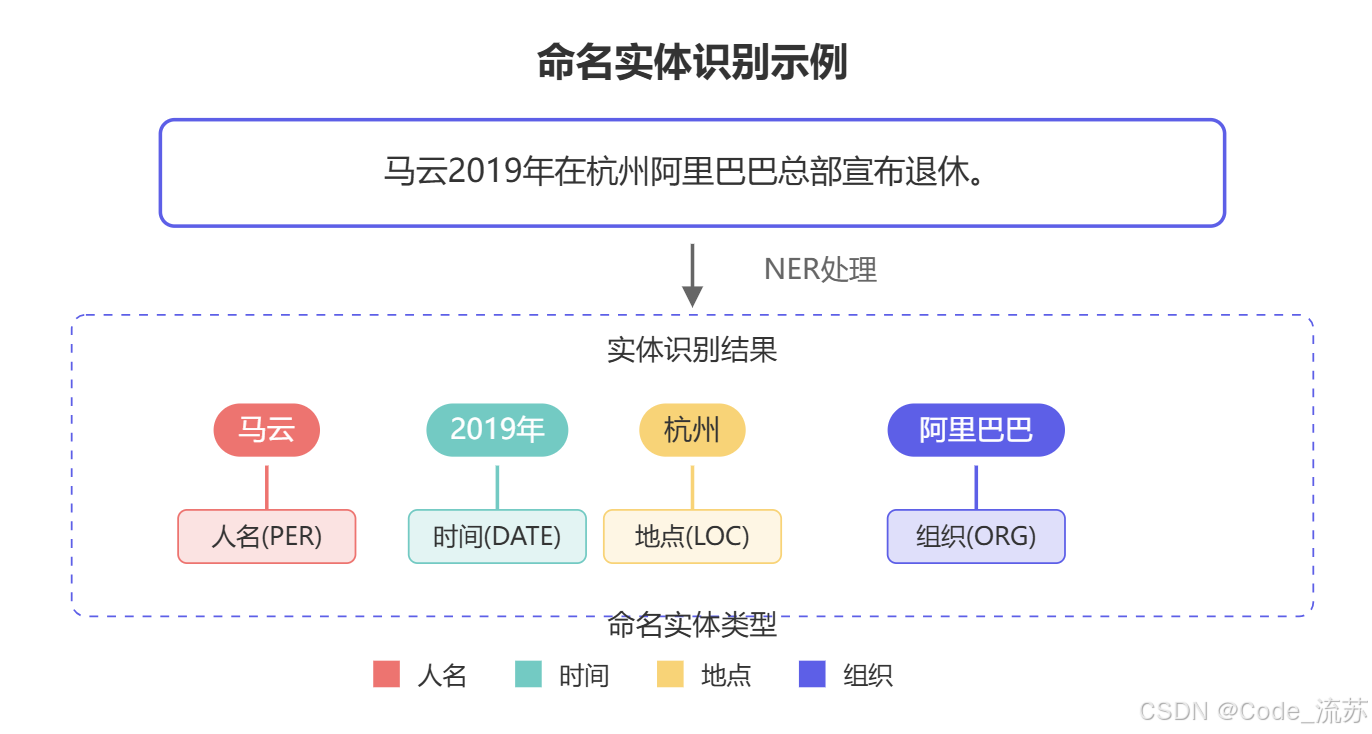
2. 使用Hugging Face进行BERT-NER微调
Hugging Face Transformers库提供了丰富的预训练模型和工具,便于进行NER模型的微调:
python
from transformers import AutoTokenizer, AutoModelForTokenClassification
from transformers import Trainer, TrainingArguments
from datasets import load_dataset
# 加载预训练模型和分词器
tokenizer = AutoTokenizer.from_pretrained("bert-base-chinese")
model = AutoModelForTokenClassification.from_pretrained(
"bert-base-chinese", num_labels=len(id2label), id2label=id2label, label2id=label2id
)
# 数据处理函数
def tokenize_and_align_labels(examples):
tokenized_inputs = tokenizer(
examples["tokens"], truncation=True, is_split_into_words=True
)
labels = []
for i, label in enumerate(examples["tags"]):
word_ids = tokenized_inputs.word_ids(batch_index=i)
label_ids = []
for word_id in word_ids:
if word_id is None:
label_ids.append(-100)
else:
label_ids.append(label[word_id])
labels.append(label_ids)
tokenized_inputs["labels"] = labels
return tokenized_inputs
# 加载数据集
dataset = load_dataset("conll2003") # 示例数据集,实际应使用中文NER数据集
tokenized_dataset = dataset.map(tokenize_and_align_labels, batched=True)
# 训练参数
training_args = TrainingArguments(
output_dir="./results",
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=3,
weight_decay=0.01,
)
# 训练
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"],
eval_dataset=tokenized_dataset["validation"],
tokenizer=tokenizer,
)
trainer.train()
# 保存模型
model.save_pretrained("./ner-model")
tokenizer.save_pretrained("./ner-model")3. 构建端到端信息抽取系统
结合NER和关系抽取,构建完整的信息抽取系统:
python
import spacy
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
# 1. 命名实体识别
nlp = spacy.load("zh_core_web_sm") # 或自定义训练的模型
# 2. 关系分类
tokenizer = AutoTokenizer.from_pretrained("bert-base-chinese")
relation_model = AutoModelForSequenceClassification.from_pretrained("./relation-model")
# 关系标签
relation_labels = {0: "无关系", 1: "创始人", 2: "位于", 3: "工作于", 4: "生产于"}
# 端到端信息抽取
def extract_information(text):
# 识别实体
doc = nlp(text)
entities = [(ent.text, ent.label_, ent.start_char, ent.end_char) for ent in doc.ents]
# 提取所有可能的实体对
entity_pairs = []
relations = []
for i, (head, head_type, h_start, h_end) in enumerate(entities):
for j, (tail, tail_type, t_start, t_end) in enumerate(entities):
if i != j: # 不考虑同一实体
# 为关系分类准备输入
marked_text = text[:h_start] + "[E1]" + head + "[/E1]" + text[h_end:t_start] + "[E2]" + tail + "[/E2]" + text[t_end:]
inputs = tokenizer(marked_text, return_tensors="pt", padding=True, truncation=True)
# 预测关系
with torch.no_grad():
outputs = relation_model(**inputs)
predicted_class = torch.argmax(outputs.logits, dim=1).item()
relation = relation_labels[predicted_class]
if relation != "无关系":
relations.append((head, relation, tail))
return entities, relations
# 演示
text = "马云于1999年在杭州创立了阿里巴巴,后来阿里巴巴总部设在杭州。"
entities, relations = extract_information(text)
print("实体:")
for entity in entities:
print(f"- {entity[0]} ({entity[1]})")
print("\n关系:")
for relation in relations:
print(f"- ({relation[0]}, {relation[1]}, {relation[2]})")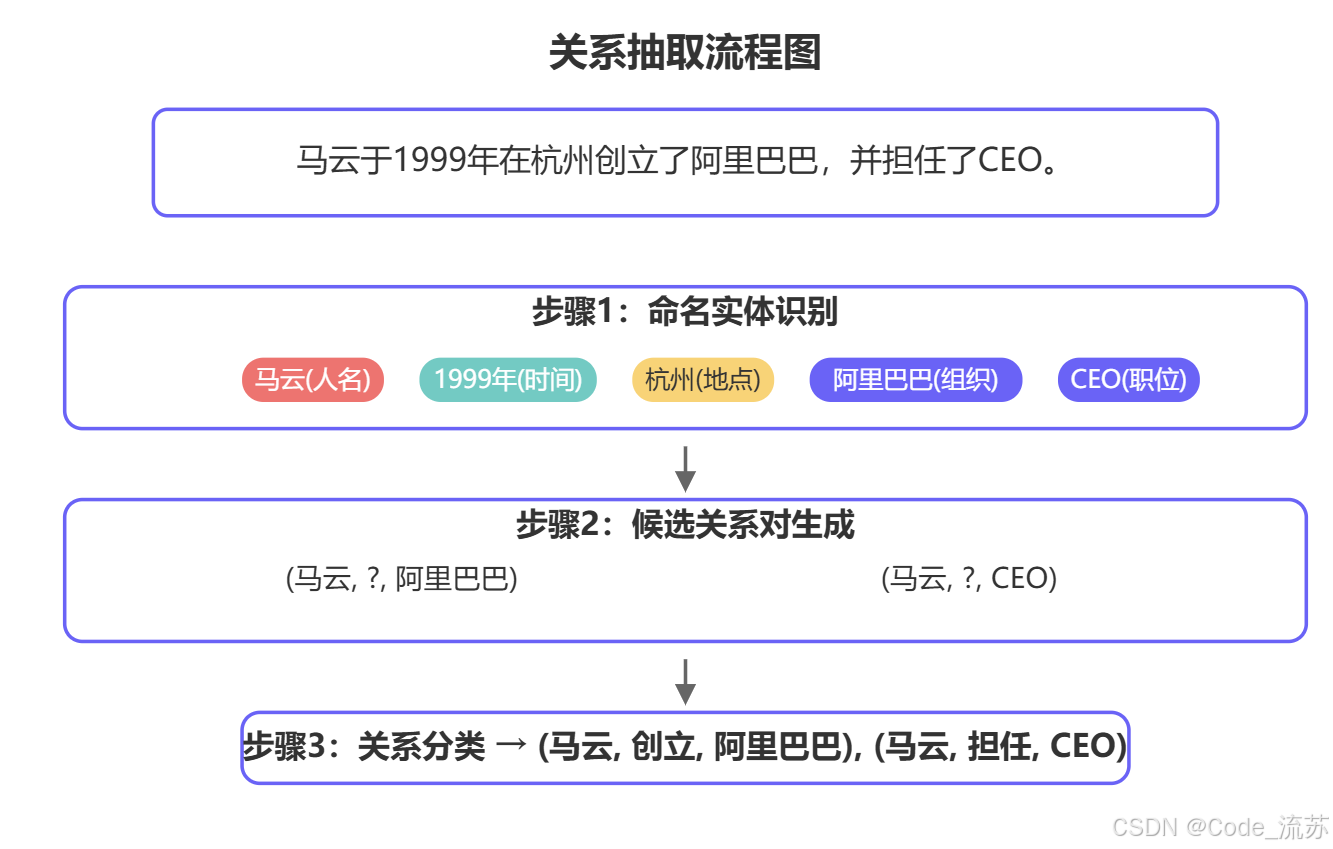
五、命名实体识别与关系抽取的实际应用
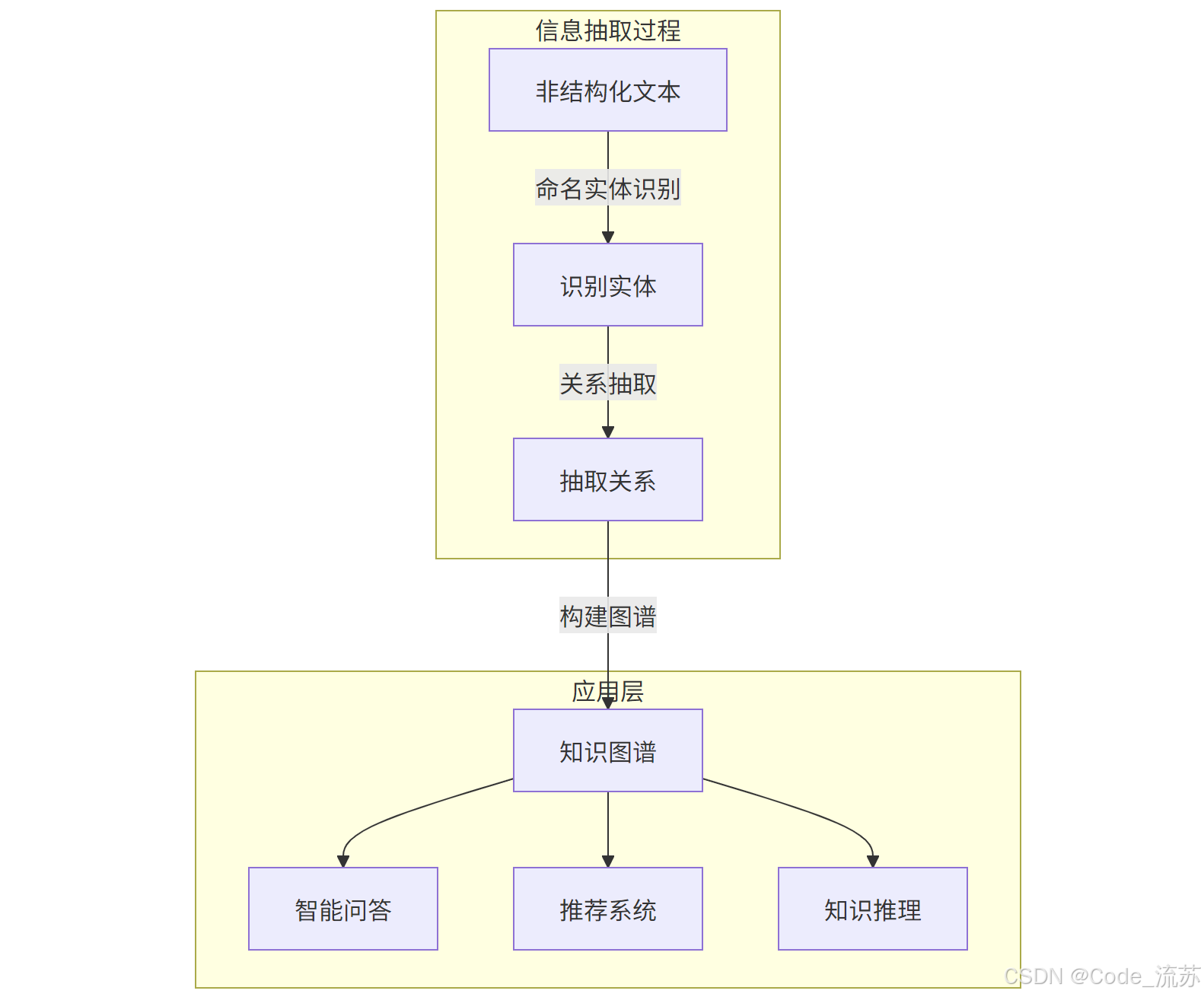
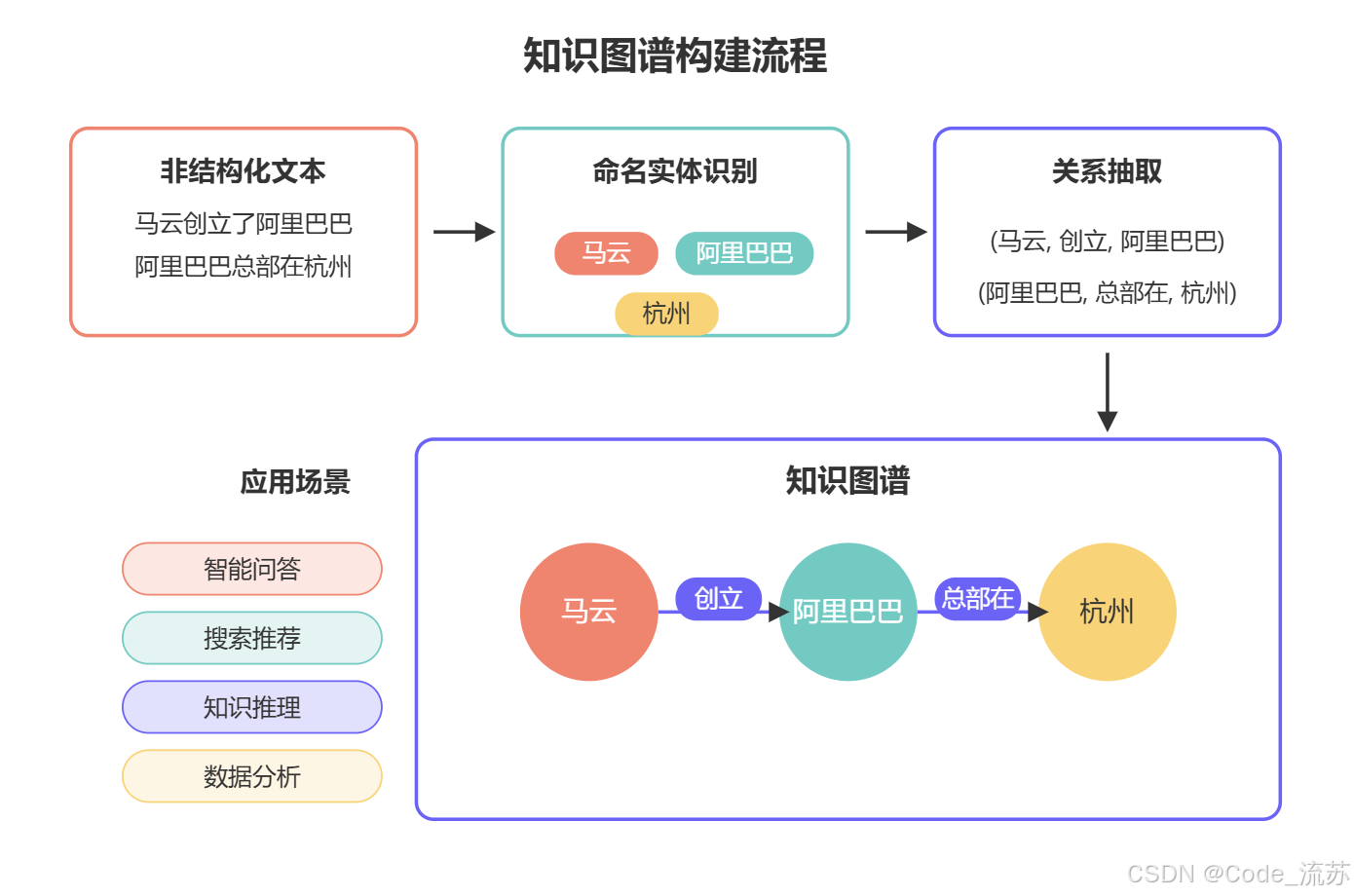
1. 知识图谱构建
命名实体识别 和关系抽取是构建知识图谱的两大基石。一个完整的知识图谱构建流程包括:
- 使用NER从大规模文本中识别实体,作为图谱中的节点
- 通过关系抽取确定实体间的连接,作为图谱中的边
- 实体链接与消歧,将识别出的实体链接到知识库中的规范实体
- 图谱存储与查询,通常使用图数据库(如Neo4j)进行存储和检索
python
# 简单的知识图谱构建示例
from py2neo import Graph, Node, Relationship
# 连接图数据库
graph = Graph("bolt://localhost:7687", auth=("neo4j", "password"))
# 清空数据库
graph.delete_all()
# 处理文本
text = "马云于1999年在杭州创立了阿里巴巴,后来阿里巴巴总部设在杭州。马化腾创办了腾讯,总部位于深圳。"
entities, relations = extract_information(text) # 前面定义的函数
# 创建实体节点
nodes = {}
for entity, entity_type, _, _ in entities:
if entity not in nodes:
node = Node(entity_type, name=entity)
nodes[entity] = node
graph.create(node)
# 创建关系
for head, relation_type, tail in relations:
if head in nodes and tail in nodes:
relationship = Relationship(nodes[head], relation_type, nodes[tail])
graph.create(relationship)
print("知识图谱构建完成!")2. 企业智能应用
在企业应用中,NER和关系抽取可以用于:
- 智能客服:自动识别用户问题中的关键实体和意图,提供精准回复
- 合同审核:提取合同中的关键主体、日期、条款等信息,辅助法务审核
- 商业智能:从行业报告中提取公司、产品、指标等信息,进行市场分析
- 风险监控:从新闻、社交媒体中提取实体关系,预警潜在风险
python
# 智能客服场景下的实体和意图提取示例
def analyze_customer_query(query):
# 1. NER识别实体
doc = nlp(query)
entities = {ent.label_: ent.text for ent in doc.ents}
# 2. 意图分类(简化示例)
intents = {
"查询订单": ["订单", "查询", "物流", "发货"],
"退换货": ["退货", "换货", "退款", "质量"],
"产品咨询": ["功能", "价格", "规格", "如何使用"]
}
query_intent = None
max_score = 0
for intent, keywords in intents.items():
score = sum(1 for word in keywords if word in query)
if score > max_score:
max_score = score
query_intent = intent
# 3. 构建结构化查询
result = {
"intent": query_intent,
"entities": entities
}
return result
# 测试
query = "我昨天买的iPhone 13什么时候能发货?订单号是2023051001"
analysis = analyze_customer_query(query)
print(f"意图: {analysis['intent']}")
print(f"实体: {analysis['entities']}")3. 学术研究与医疗应用
在学术研究和医疗领域,NER和关系抽取有着特殊的应用价值:
- 文献挖掘:从大量学术论文中提取研究主题、方法、结果等关键信息
- 医疗记录分析:从病历中提取症状、疾病、药物及其关系,辅助临床决策
- 药物相互作用分析:识别论文中描述的药物间相互作用,指导用药安全
python
# 医疗领域的实体和关系抽取示例
def analyze_medical_text(text):
# 加载医疗领域专用模型(这里为示例,实际需要训练)
medical_nlp = spacy.load("./medical_ner_model")
# 识别医疗实体
doc = medical_nlp(text)
entities = []
for ent in doc.ents:
entities.append({
"text": ent.text,
"type": ent.label_,
"start": ent.start_char,
"end": ent.end_char
})
# 识别医疗关系(简化示例)
relations = []
disease_entities = [e for e in entities if e["type"] == "DISEASE"]
symptom_entities = [e for e in entities if e["type"] == "SYMPTOM"]
drug_entities = [e for e in entities if e["type"] == "DRUG"]
# 疾病-症状关系
for disease in disease_entities:
for symptom in symptom_entities:
# 简单的基于距离的关系推断(实际系统需更复杂算法)
if abs(disease["start"] - symptom["end"]) < 50 or abs(symptom["start"] - disease["end"]) < 50:
relations.append({
"head": disease["text"],
"type": "has_symptom",
"tail": symptom["text"]
})
# 疾病-药物治疗关系
for disease in disease_entities:
for drug in drug_entities:
if abs(disease["start"] - drug["end"]) < 50 or abs(drug["start"] - disease["end"]) < 50:
relations.append({
"head": drug["text"],
"type": "treats",
"tail": disease["text"]
})
return {
"entities": entities,
"relations": relations
}
# 测试
medical_text = "患者表现为持续性头痛和发热,考虑为流感,建议服用布洛芬缓解症状,同时使用奥司他韦抗病毒治疗。"
result = analyze_medical_text(medical_text)
print("医疗实体:", [e["text"] + "(" + e["type"] + ")" for e in result["entities"]])
print("医疗关系:", [(r["head"], r["type"], r["tail"]) for r in result["relations"]])六、总结与展望
命名实体识别(NER)和关系抽取是信息抽取中的关键技术,为结构化知识的自动构建铺平了道路。通过本文的学习,我们掌握了:
- NER的基本原理与主流技术路线,从规则到深度学习
- 关系抽取的核心方法,包括监督学习和远程监督等方式
- 实战应用,使用spaCy和Hugging Face等工具进行模型训练和应用开发
- 行业应用案例,如何将这些技术应用到知识图谱、企业智能和医疗研究中
未来发展趋势
- 多模态信息抽取:结合图像、视频等多模态数据进行实体和关系识别
- 低资源场景优化:针对专业领域或小语种等数据稀缺场景的优化方法
- 知识图谱与大语言模型融合:将结构化知识与生成式模型结合,提升推理能力
- 可解释性研究:提高NER和关系抽取模型决策的可解释性和可信度
命名实体识别和关系抽取技术正逐步走向成熟,未来将与大语言模型、多模态技术深度融合,在各行各业发挥更加重要的作用。作为NLP的基础技术,它们值得每位AI从业者深入学习和掌握。
练习与思考
- 尝试使用spaCy训练一个针对特定领域(如医疗、法律或金融)的NER模型
- 探索远程监督方法构建关系抽取数据集的实际效果
- 结合BERT等预训练模型,实现端到端的信息抽取系统
- 思考:如何评估和优化NER和关系抽取模型在实际应用中的表现?
通过系统学习和实践,你已经具备了实现基础信息抽取系统的能力。下一步,可以尝试将这些技术与大语言模型结合,探索更加智能的文本理解与生成应用。
Happy coding!
祝你学习愉快,Python星球的探索者!👨🚀🌠
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
如果你对今天的内容有任何问题,或者想分享你的学习心得,欢迎在评论区留言讨论!