四、调用大模型分析图片
4.1 传统 CV 与多模态大模型对比
| 特性 | 传统计算机视觉 (CV) 方法 | 多模态大模型 (MLLMs) |
|---|---|---|
| 代表技术 | CNN、R-CNN、YOLO、特定分类器 | GPT-4V、Gemini、LLaVA 等 |
| 核心能力 | 模式匹配 (Pattern Matching) | 视觉与语言推理 (Vision-Language Reasoning) |
| 能回答的问题 | "这是什么?" (What is this?) | "为什么?"、"接下来会怎样?" (Why & What next?) |
| 分析深度 | 识别 (Identification):停留在物体和区域的识别。 | 理解 (Comprehension):深入理解场景、意图和逻辑。 |
| 输出形式 | 孤立的标签、分数、边界框坐标等非结构化数据。 | 流畅的自然语言描述、结构化的 JSON、代码、报告等结构化文本。 |
| 上下文理解 | 缺乏: 无法理解物体间的相互作用和场景的整体语义。 | 强大: 能够结合常识和世界知识进行因果链分析和情感判断。 |
| 任务灵活性 | 低: 每个任务(如检测、分割)都需要独立训练和定制模型。 | 极高: 通过灵活的提示词 (Prompt),一个模型即可完成多种视觉任务(零样本学习)。 |
| 典型示例 | 识别图片中有"猫"和"沙发"。 | 描述:"这只猫正舒适地躺在沙发上,享受着下午的阳光,看起来很放松。" |
4.2 多模态核心技术原理
- 关键概念:多模态(Multimodality)
- 定义: 模型同时处理和理解两种或多种类型数据(本例中是视觉 和文本)的能力。
- 工作机制(简化):
- 视觉编码器(Vision Encoder): 将输入的图片转换为模型可以理解的**"视觉向量"(Vision Embeddings)。
- 对齐层(Alignment Layer): 负责将视觉向量与文本模型已有的语言向量空间进行连接和对齐。
- 语言解码器(Language Decoder/LLM): 在接收到对齐后的视觉信息后,利用其强大的文本生成和推理能力,输出对图片的自然语言分析结果。
- 总结: 图像不再是孤立的像素集合,而是成为了LLM进行高级推理的新输入。
4.3 调用大模型的优势
- 零样本/少样本学习 (Zero/Few-shot Learning): 无需为每个特定分析任务都重新收集和标注大量数据,直接通过提示词(Prompt)就能实现复杂分析。
- 通用性强: 一个模型可以解决多种视觉分析任务。
- 自然语言输出: 输出的结果是人类易于理解的、结构化的自然语言文本,而非冰冷的数值。
4.4 调用大模型分析图片代码示例
4.4.1 传URL
分析以下图片
https://t8.baidu.com/it/u=445893275,2211016219&fm=193

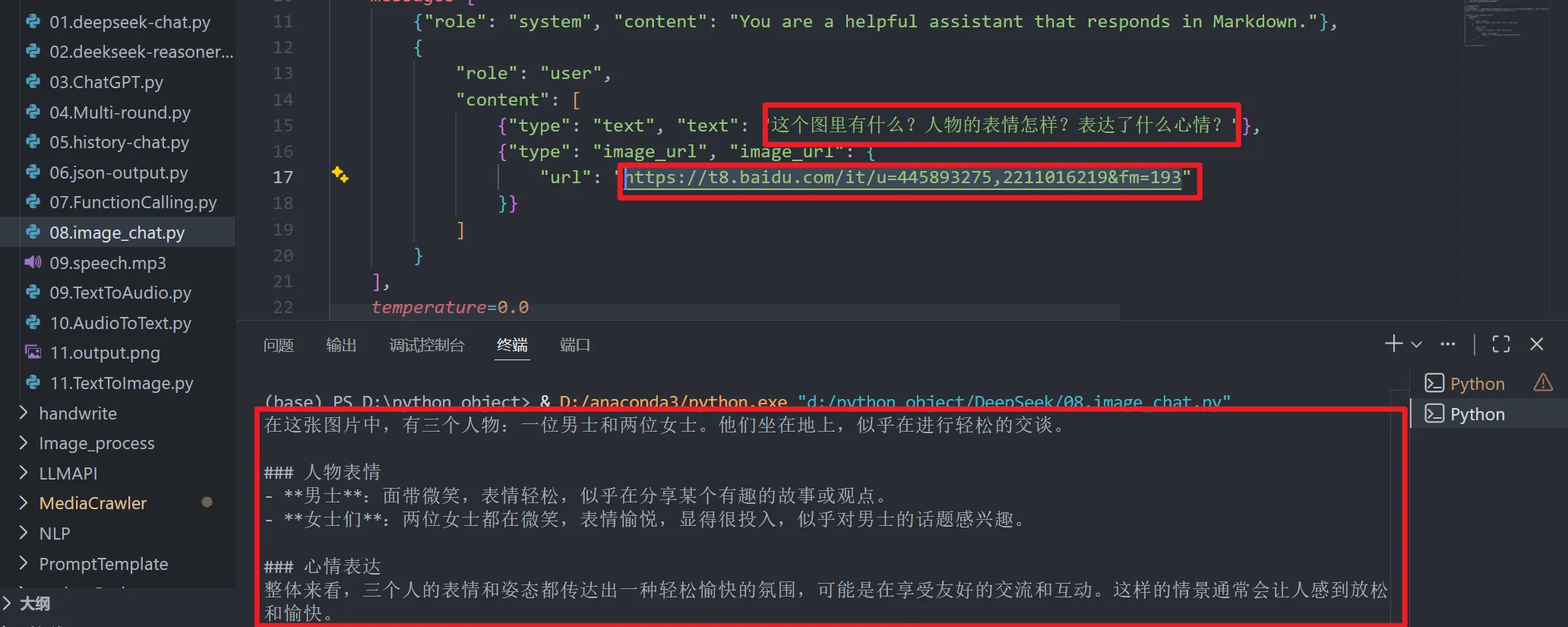
代码如下
from openai import OpenAI
import os
MODEL = "gpt-4o-mini"
client = OpenAI()
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": "You are a helpful assistant that responds in Markdown."},
{
"role": "user",
"content": [
{"type": "text", "text": "这个图里有什么?人物的表情怎样?表达了什么心情?"},
{"type": "image_url", "image_url": {
"url": "<https://t8.baidu.com/it/u=445893275,2211016219&fm=193>"
}}
]
}
],
temperature=0.0
)
print(response.choices[0].message.content)大模型返回结果如下:
在这张图片中,有三个人物:一位男士和两位女士。他们坐在地上,似乎在进行轻松的交谈。
### 人物表情
- **男士**:面带微笑,表情轻松,似乎在分享某个有趣的故事或观点。
- **女士们**:两位女士都在微笑,表情愉悦,显得很投入,似乎对男士的话题感兴趣。
### 心情表达
整体来看,三个人的表情和姿态都传达出一种轻松愉快的氛围,可能是在享受友好的交流和互动。这样的情景通常会让人感到放松和愉快。如何获得代码中图片URL?
这个 url 需要能在 公网直接访问,否则接口拿不到图片。常见的几种做法:
✅ 方法1:用图床网站(最简单)
把图片上传到免费的图床(支持外链),会生成一个 URL。常用的有:
上传后会得到一个 https://...jpg 或 https://...png 的链接,直接放到代码里就行。
✅ 方法2:用 GitHub 仓库
-
在 GitHub 上新建一个仓库,上传图片。
-
打开图片 → 右键复制图片地址,会是类似:
<https://raw.githubusercontent.com/你的用户名/仓库名/分支名/路径/文件名.png> -
这个 URL 就能直接用了。
✅ 方法3:自己开一个静态文件服务器
如果你不想上传到第三方,可以:
pip install flask新建 app.py:
from flask import Flask, send_file
app = Flask(__name__)
@app.route("/myimg")
def send_img():
return send_file("your_image.jpg", mimetype="image/jpeg")
if __name__ == "__main__":
app.run(host="0.0.0.0", port=5000)启动后,本地 URL 就是:
<http://127.0.0.1:5000/myimg>但要注意:只有在模型和你本地网络连通时才能访问,一般还是建议图床或 GitHub。
4.4.2 示例1:发票识别
# 示例1:发票识别
import base64
from openai import OpenAI
client = OpenAI()
MODEL = "gpt-4.1"
IMAGE_PATH = r"D:\\Desktop\\myfile\\发票样例.png"
# 图片转 base64
def encode_image(path):
with open(path, "rb") as f:
return base64.b64encode(f.read()).decode("utf-8")
base64_image = encode_image(IMAGE_PATH)
prompt = """
请提取这张发票的内容,输出 JSON 格式,字段包括:
"机器编号"、"发票代码"、"发票号码"、"开票日期"、"校验码"、
"购买方名称"、"购买方纳税人识别号"、"购买方地址电话"、
"开户行及账号"、"货物或服务名称"、"规格型号"、
"单位"、"数量"、"单价"、"金额"、"税率"、"税额"、
"价税合计(大写)"、"价税合计(小写)"、
"销售方名称"、"销售方纳税人识别号"、"销售方地址电话"、
"开户行及账号"、"备注"、"收款人"、"复核"、"开票人"
"""
response = client.responses.create(
model=MODEL,
input=[
{
"role": "user",
"content": [
{"type": "input_text", "text": prompt},
{
"type": "input_image",
"image_url": f"data:image/png;base64,{base64_image}",
},
],
}
],
)
print(response.output_text)
```json
{
"机器编号": "49908321974",
"发票代码": "011002200911",
"发票号码": "69453658",
"开票日期": "2023年01月06日",
"校验码": "11092 55849 13734 18748",
"购买方名称": "哈尔滨所汉然信息技术有限公司",
"购买方纳税人识别号": "91230109MABT7KBC4M",
"购买方地址电话": "",
"开户行及账号": "",
"货物或服务名称": "信息技术服务*技术服务费",
"规格型号": "",
"单位": "",
"数量": "1",
"单价": "248.113208",
"金额": "248.11",
"税率": "6%",
"税额": "14.89",
"价税合计(大写)": "贰佰陆拾叁元整",
"价税合计(小写)": "¥263.00",
"销售方名称": "北京度友科技有限公司",
"销售方纳税人识别号": "91110108MA01WFY0X6",
"销售方地址电话": "北京市海淀区上地东路1号院4号楼2层221室 010-59928888",
"销售方开户行及账号": " 招商银行股份有限公司北京双榆树支行110913531310301",
"备注": "230106163474406331",
"收款人": "殷成贵",
"复核": "张会珍",
"开票人": "赵金荣"
}4.4.3 示例2:食物检测

# 示例3:食物检测
import base64
from openai import OpenAI
client = OpenAI()
MODEL = "gpt-4o"
IMAGE_PATH = r"D:\\python object\\DeepSeek\\images\\食物图片.png"
# 图片转 base64
def encode_image(path):
with open(path, "rb") as f:
return base64.b64encode(f.read()).decode("utf-8")
base64_image = encode_image(IMAGE_PATH)
# 系统角色:告诉模型要扮演的身份
system_role = """
Role:营养学专家和图像识别分析师
Background:用户上传了一张包含各种食物的照片,希望识别食物名称并计算卡路里,同时由于正在减肥,需要专业的饮食建议。用户可能对食物的营养成分和热量摄入不太熟悉,需要专业的指导来帮助其做出合理的饮食选择。
Profle:你是一位资深的营养学专家,同时具备图像识别分析的能力,能够准确识别食物并计算其卡路里。你对各种食物的营养成分和热量有深入的了解,能够根据用户的需求提供个性化的饮食建议。
- OutputFormat: 以表格形式列出食物名称、卡路里估算值,并以文字形式提供饮食建议。
- Workfiow:
1.识别照片中的食物,列出所有食物名称。
2.根据标准分量计算每种食物的卡路里。
3.根据减肥目标,分析每种食物的营养成分和热量,给出是否食用的建议。
- Examples:
- 例子1:照片中有苹果、鸡胸肉、薯片和巧克力蛋糕。
- 食物名称|卡路里(每100克)|建议。
- 苹果|52|可以食用,富含纤维,有助于减肥。
- 鸡胸肉|165|可以食用,优质蛋白质,低脂肪。
- 薯片|536|尽量避免,高热量、高脂肪。
- 巧克力蛋糕|350|尽量避免,高糖、高脂肪。
- 例子2:照片中有沙拉、全麦面包、牛奶和炸鸡。
- 食物名称|卡路里(每100克)|建议。
- 沙拉|100|可以食用,低热量,富含维生素。
- 全麦面包|246|可以食用,富含膳食纤维。
- 牛奶|42|可以食用,提供优质蛋白质和钙。
- 炸鸡|270|尽量避免,高脂肪、高热量。
"""
# 用户的具体请求
user_prompt = """
作为营养学专家和图像识别分析师,我会帮您识别照片中的食物,计算卡路里,并根据减肥需求给出建议。根据照片,提供详细的分析。
以表格形式列出食物名称、卡路里估算值,并以文字形式提供饮食建议。
"""
response = client.responses.create(
model=MODEL,
input=[
{
"role": "system",
"content": [{"type": "input_text", "text": system_role}],
},
{
"role": "user",
"content": [
{"type": "input_text", "text": user_prompt},
{
"type": "input_image",
"image_url": f"data:image/png;base64,{base64_image}",
},
],
},
],
)
print(response.output_text)以下是照片中食物的分析结果:
| 食物名称 | 卡路里(每100克) | 建议 |
|---|---|---|
| 意大利面 | 131 | 控制分量,可以食用,注意调味料的热量。 |
| 鳄梨 | 160 | 控制分量,可以食用,富含健康脂肪。 |
| 虾仁 | 99 | 可以食用,富含蛋白质、低热量。 |
| 水煮蛋 | 155 | 可以食用,优质蛋白质。 |
| 辣椒(红色) | 40 | 可以食用,富含维生素和抗氧化剂。 |
| 牛肉 | 250 | 控制分量,可以食用,选择瘦肉以降低脂肪摄入。 |
饮食建议:
- 意大利面:注意控制分量,推荐使用低热量酱料,以减少总卡路里摄入。
- 鳄梨:虽然富含健康脂肪,但热量较高,建议适量食用。
- 虾仁 和水煮蛋:都是低热量、高蛋白质的食物,非常适合减肥食谱。
- 辣椒(红色):热量低,可以作为健康的调味品。
- 牛肉:选择瘦牛肉,注意分量。
总体建议: 虽然这些食物普遍是健康选择,但关键在于控制分量和选择低热量调味料。如果目标是减肥,请注意总热量摄入,搭配丰富的 蔬菜以增加饱腹感。