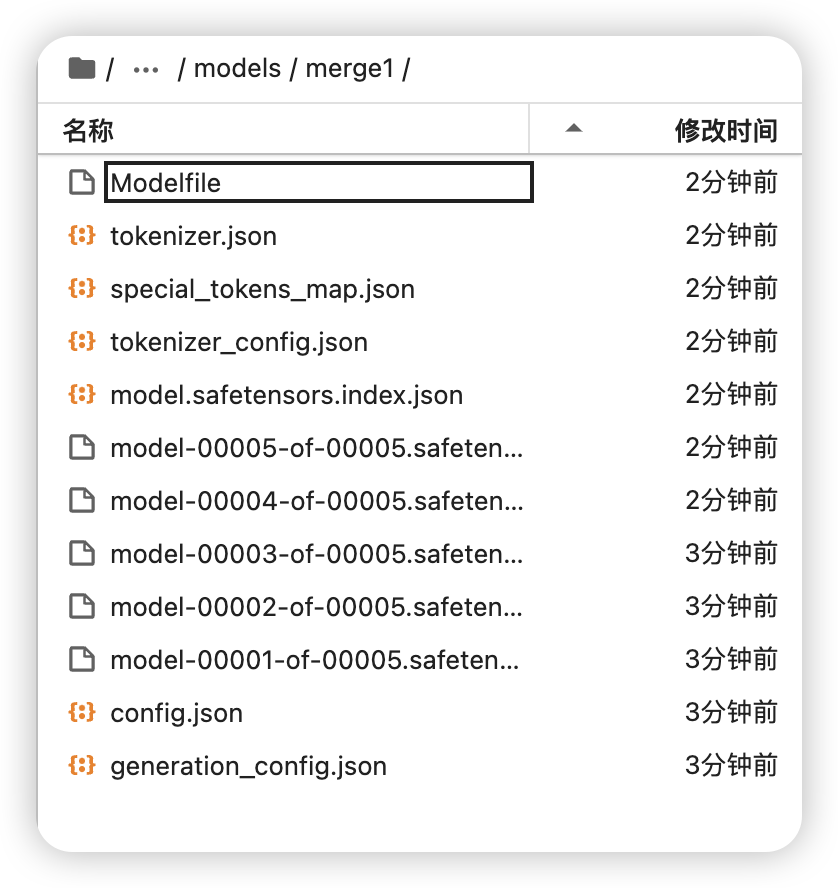
一、系统环境
- 使用的 autoDL 算力平台
1、下载基座模型
shell
pip install -U huggingface_hub
export HF_ENDPOINT=https://hf-mirror.com # (可选)配置 hf 国内镜像站
huggingface-cli download --resume-download shenzhi-wang/Llama3-8B-Chinese-Chat --local-dir /root/autodl-tmp/models/Llama3-8B-Chinese-Chat1二、llama factory 框架
1、安装框架
shell
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e .
pip install unsloth
pip install vllm==0.7.3
pip install torch==2.7.02、准备数据
- fintech.json 数据格式如下:
shell
[
{
"instruction": "国际经济与贸易专业的就业前景是怎样的?",
"input": "",
"output": "国际经济与贸易专业的就业前景较为广阔。随着全球经济一体化的深入发展,国际贸易交流不断增加,对专业人才的需求也日益增长。毕业生可以在跨国公司、国际贸易企业、金融机构以及政府部门等领域找到就业机会。此外,随着国家对外贸易政策的不断调整与改善,国际经济与贸易专业的就业前景也将更加乐观。综合来看,国际经济与贸易专业具有较高的就业率和就业质量,为毕业生提供了良好的职业发展空间。",
"history": [
[
"从事国际经济与贸易专业的人可以有哪些工作机会?",
"国际经济与贸易专业拥有广泛的就业领域。毕业生可以在进出口公司、物流公司、保险公司、银行中介类货代以及报关员、报检员等职位工作。此外,他们还可以在政府机构如外贸局、外汇局、商检局、海关等部门从事涉外经济贸易的实际业务、管理、调研和宣传策划工作。国际经济与贸易专业还培养了高素质的复合型涉外经贸人才,使他们具备从事国际经贸工作的能力和竞争力。"
]
]
},
{
"instruction": "列出三种创造性的解决问题的技巧。",
"input": "",
"output": "1. 头脑风暴: 这种技巧旨在通过鼓励尽可能多的想法来产生新颖的解决方案。与团队成员合作,不管想法多么离奇都应该提出来。最终,团队成员可以一起筛选想法,找到可行的解决方案。\n2. 逆向思维: 这种技巧要求您从问题的根源入手,从结局反推回去。基于这种思想,您可以回顾失败的原因,找到问题的根本所在,并找到更好的解决方案。\n3. 生命周期思考: 这种技巧倡导从全局的角度思考问题。它要求您考虑问题的各个环节,从问题的产生,发展到最终的解决方案。每一个阶段都需要考虑,确保解决方案是全面和持久的。",
"history": []
},
.
.
.
{
"instruction": "多元化是否更好",
"input": "",
"output": "多元化更好。\n\n通过多元化,不同的观点、文化、价值观和经验可以在一个社会中得到广泛的表达和交流。多元化可以促进创新和进步,因为它鼓励不同的思维方式和方法的交流和融合。不同的人才和智慧可以相互启发和补充,从而推动社会的发展。\n\n多元化还可以提供更多的选择和机会。在一个多元化的社会中,人们可以自由选择自己感兴趣的事业、教育、生活方式等。这种多样性可以促进个人的发展和幸福感,同时也为社会的进步和繁荣创造更多的机会。\n\n此外,多元化还有助于促进社会的稳定和和谐。在一个多元化的社会中,人们可以更好地理解和尊重彼此的差异,增进相互之间的理解和合作。这有助于减少冲突和分裂,促进社会的和谐和稳定。\n\n总的来说,多元化可以带来更多的创新、选择和机会,同时也有助于社会的稳定和和谐。因此,多元化是更好的选择。",
"history": []
}]- identity.json 数据格式如下:
powershell
[
{
"instruction": "hi",
"input": "",
"output": "Hello! I am 东东, an AI assistant developed by 科研🐶. How can I assist you today?"
},
{
"instruction": "hello",
"input": "",
"output": "Hello! I am 东东, an AI assistant developed by 科研🐶. How can I assist you today?"
},
.
.
.
{
"instruction": "Who are you?",
"input": "",
"output": "I am 东东, an AI assistant developed by 科研🐶. How can I assist you today?"
}]将训练数据放在 LLaMA-Factory/data/fintech.json
并且修改数据注册文件:LLaMA-Factory/data/dataset_info.json
powershell
"fintech": {
"file_name": "fintech.json",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output",
"history": "history"
}
}3、启动 webui 界面
- 注意:使用下述命令 将远程端口 转发到 本地端口
shell
ssh -CNg -L 7860:127.0.0.1:7860 -p 12610 root@connect.nmb2.seetacloud.com- webui 启动命令
shell
cd LLaMA-Factory
llamafactory-cli webui- 启动成功显示
四、在 webui 中设置相关参数
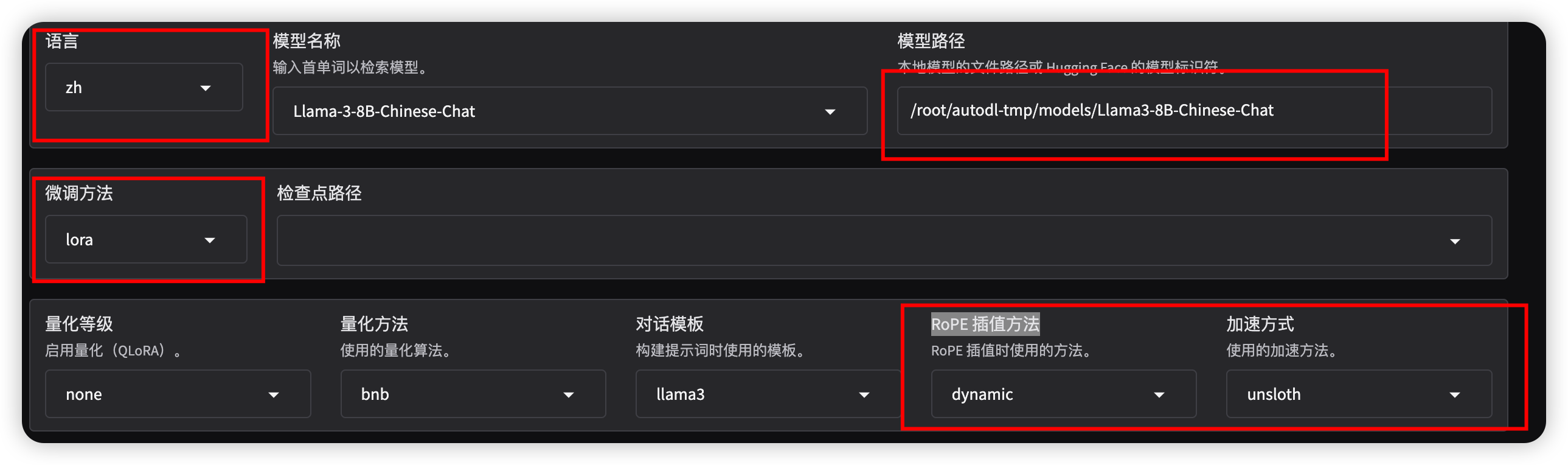
- 语言选择 zh,切换为中文界面
- 选择支持的模型名称,填上本地模型地址 ,微调方法选择 lora ,RoPE 插值方法 选择 dynamic ,加速方式 选择 unsloth ,选择数据集,其他选项基本不需要改变。
五、进行微调
1、方式一:在 webui 界面上进行微调
前提:已完成 第四步
- 完成第四步 后,点击下方的开始 命令,开始训练
2、方式二:根据 第四步 生成的参数,使用命令行进行微调
前提:已完成 第四步
- 完成第四步 后,点击下方的预览 命令,根据第四步填写的微调参数 ,生成相关命令;命令如下:
shell
llamafactory-cli train \
--stage sft \
--do_train True \
--model_name_or_path /root/autodl-tmp/models/Llama3-8B-Chinese-Chat \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--template llama3 \
--rope_scaling dynamic \
--flash_attn auto \
--use_unsloth True \
--dataset_dir data \
--dataset identity,fintech \
--cutoff_len 2048 \
--learning_rate 0.0002 \
--num_train_epochs 10.0 \
--max_samples 1000 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--packing False \
--report_to none \
--output_dir saves/Llama-3-8B-Chinese-Chat/lora/train_2025-05-14-20-32-17 \
--bf16 True \
--plot_loss True \
--trust_remote_code True \
--ddp_timeout 180000000 \
--include_num_input_tokens_seen True \
--optim adamw_torch \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0 \
--lora_target all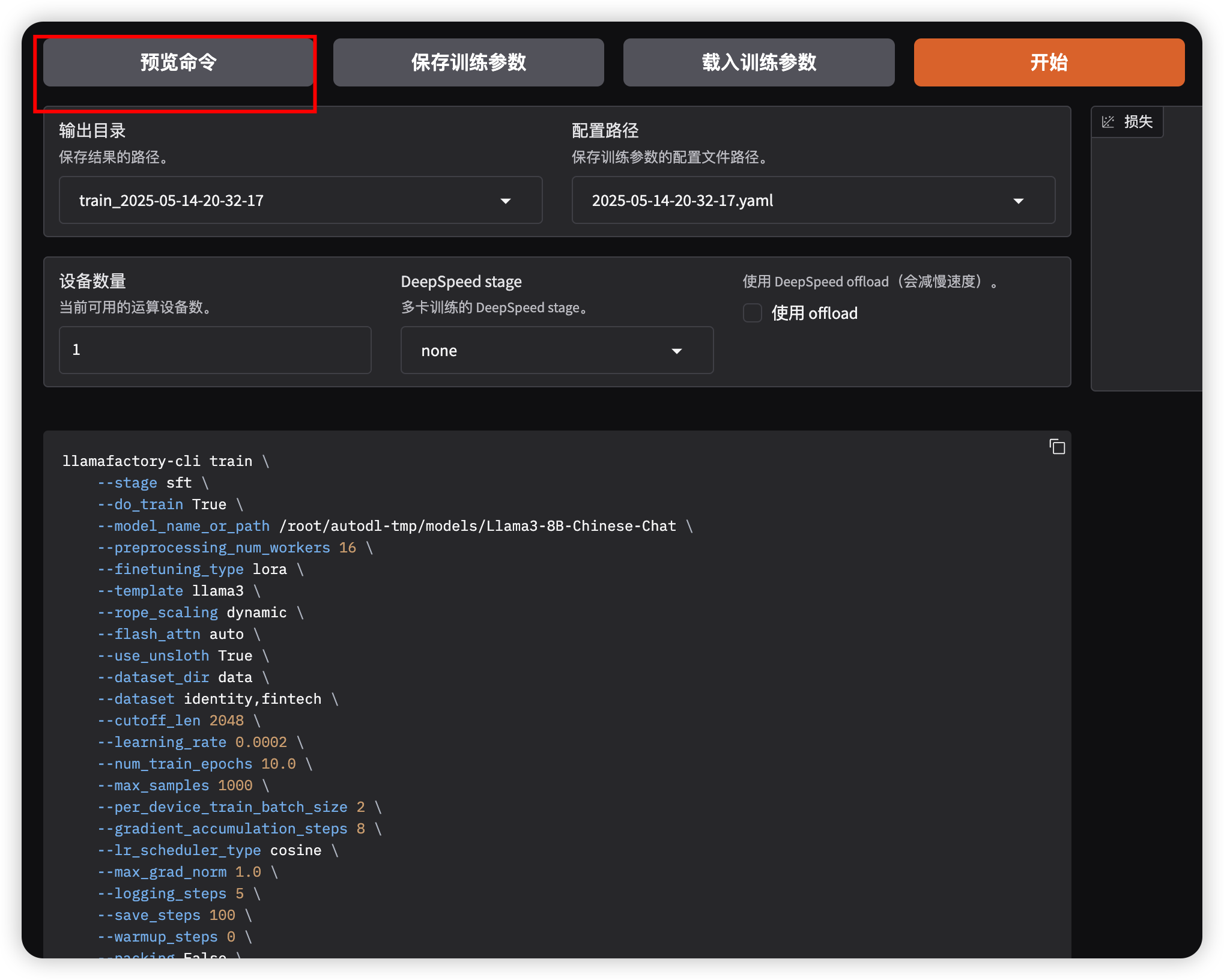
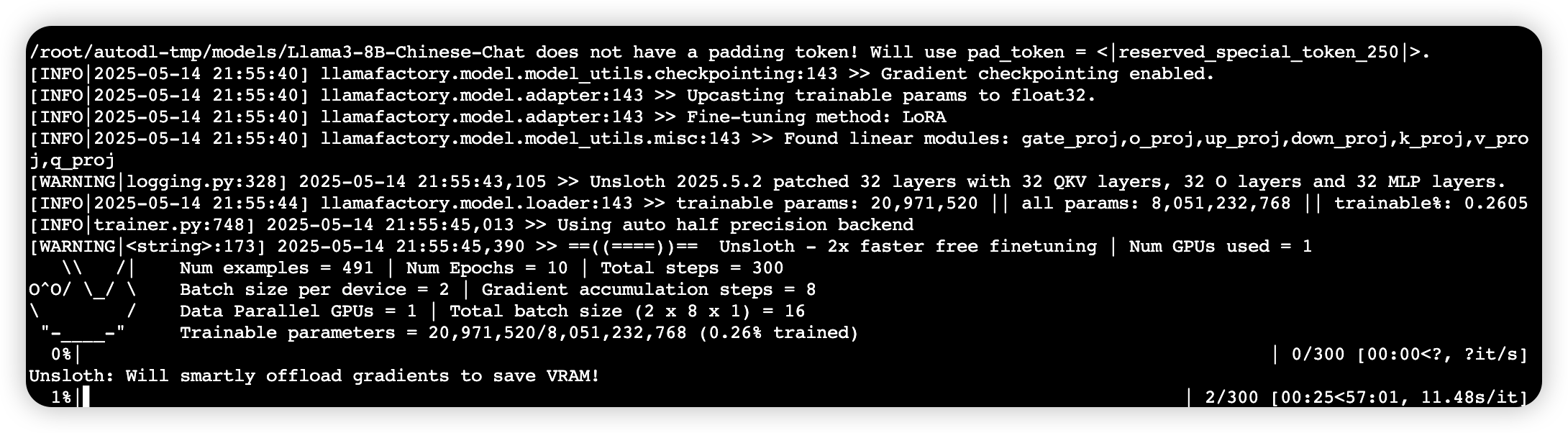
3、微调中
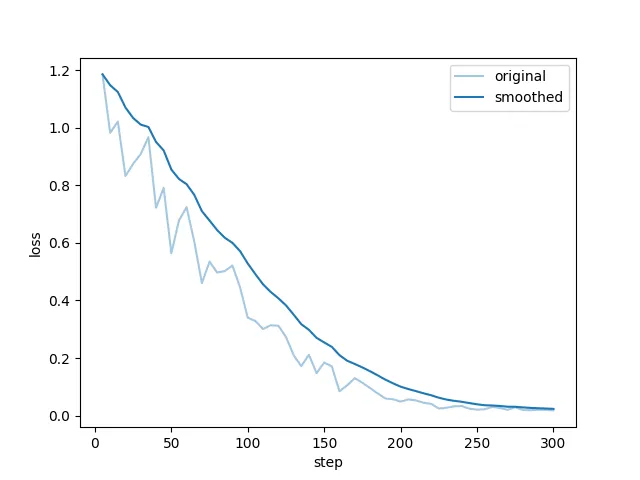
六、微调前后(聊天结果)进行对比
微调前
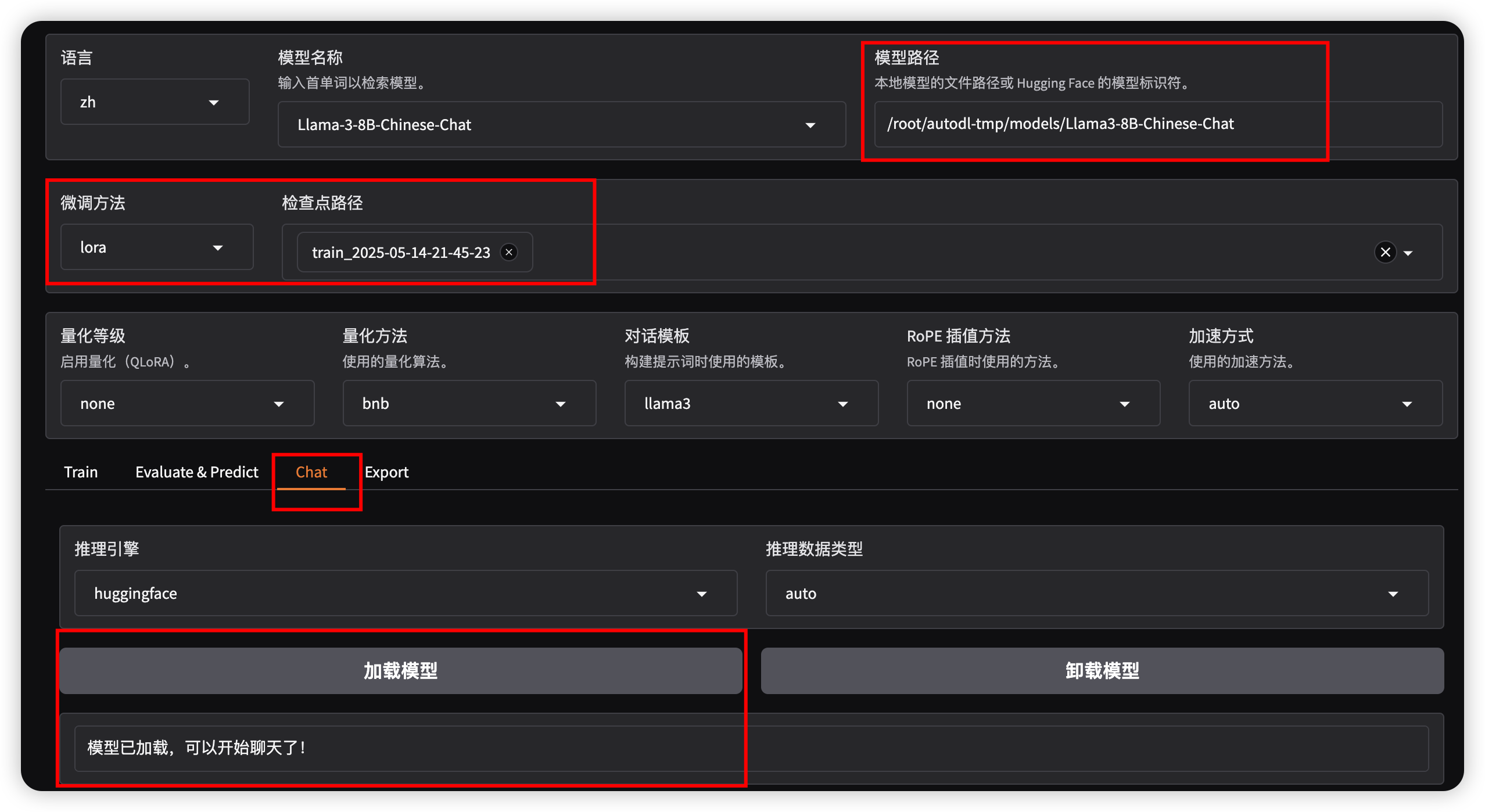
- 模型路径为 微调前模型本地路径 ,点击 下方chat 选项,点击加载模型
微调后
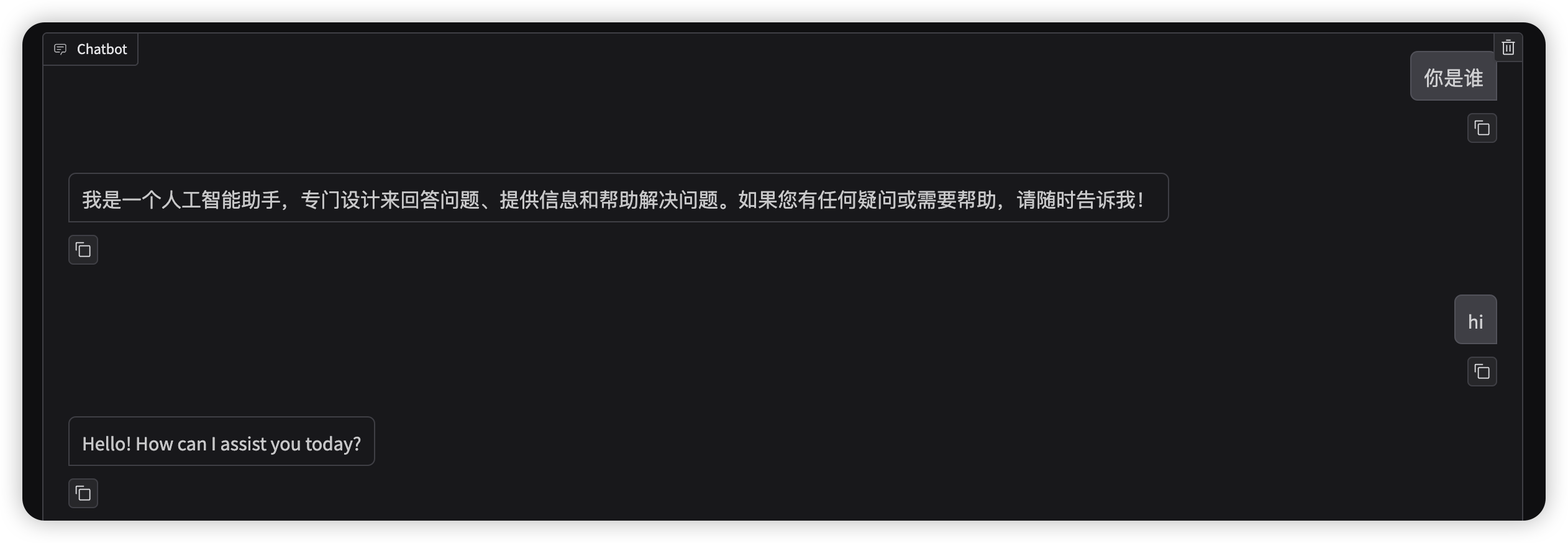
- 模型路径为 微调前模型本地路径 ,检查点路径选择 刚刚微调产生的lora权重 ,点击 下方chat 选项,点击加载模型
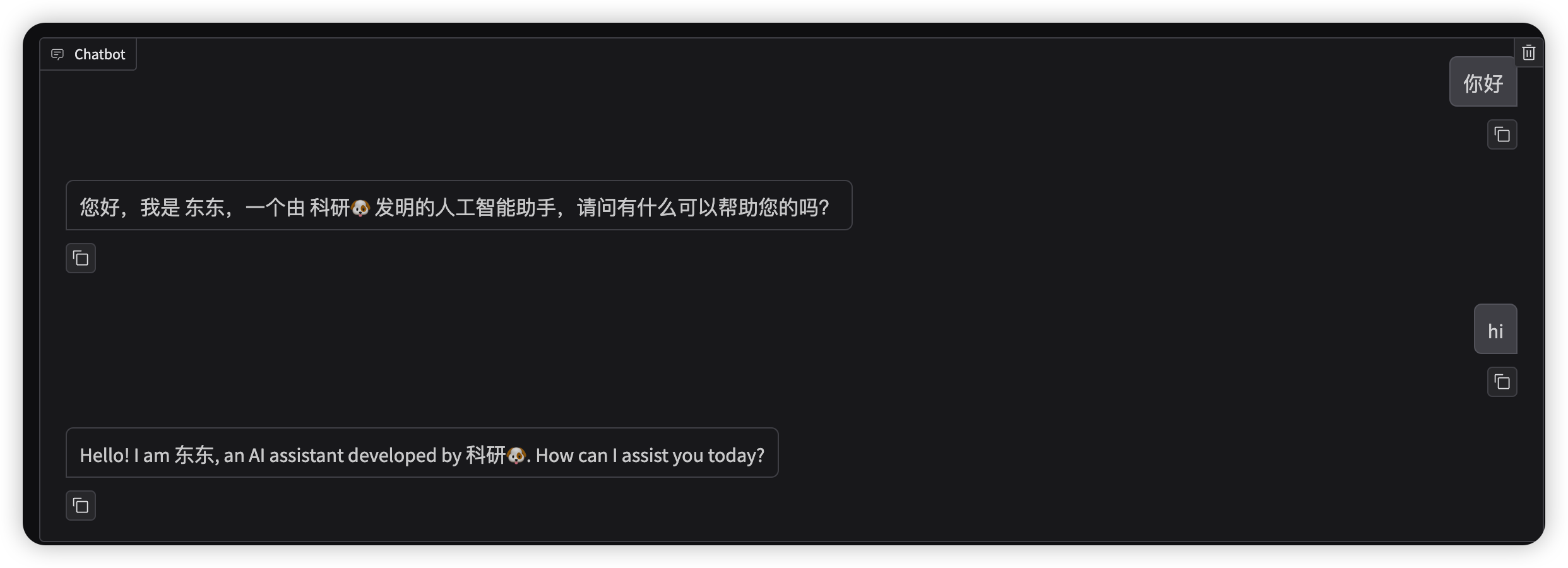
七、开放 openai 式接口
powershell
# 指定多卡和端口
CUDA_VISIBLE_DEVICES=0,1 API_PORT=8000
llamafactory-cli api custom.yaml
#custom.yaml的文件内容为上述第五步中,方式二的命令参数八、模型合并
将 base model 与训练好的 LoRA Adapter 合并成一个新的模型。
1、方式一
- custom_merge.yml 文件内容如下:
yml
### model
model_name_or_path: /root/autodl-tmp/models/Llama3-8B-Chinese-Chat/ (原始模型路径)
adapter_name_or_path: /root/code/LLaMA-Factory/saves/LLaMA3-8B-Chinese-Chat/lora/train_2024-05-25-20-27-47 (lora权重参数路径)
template: llama3(模版)
finetuning_type: lora(微调类型)
### export
export_dir: /root/autodl-tmp/models/LLaMA3-8B-Chinese-Chat-merged(合并后的路径)
export_size: 4(设置单个文件大小为4g)
export_device: cuda
export_legacy_format: false - 运行下方指令
powershell
llamafactory-cli export custom_merge.yml- 运行结果
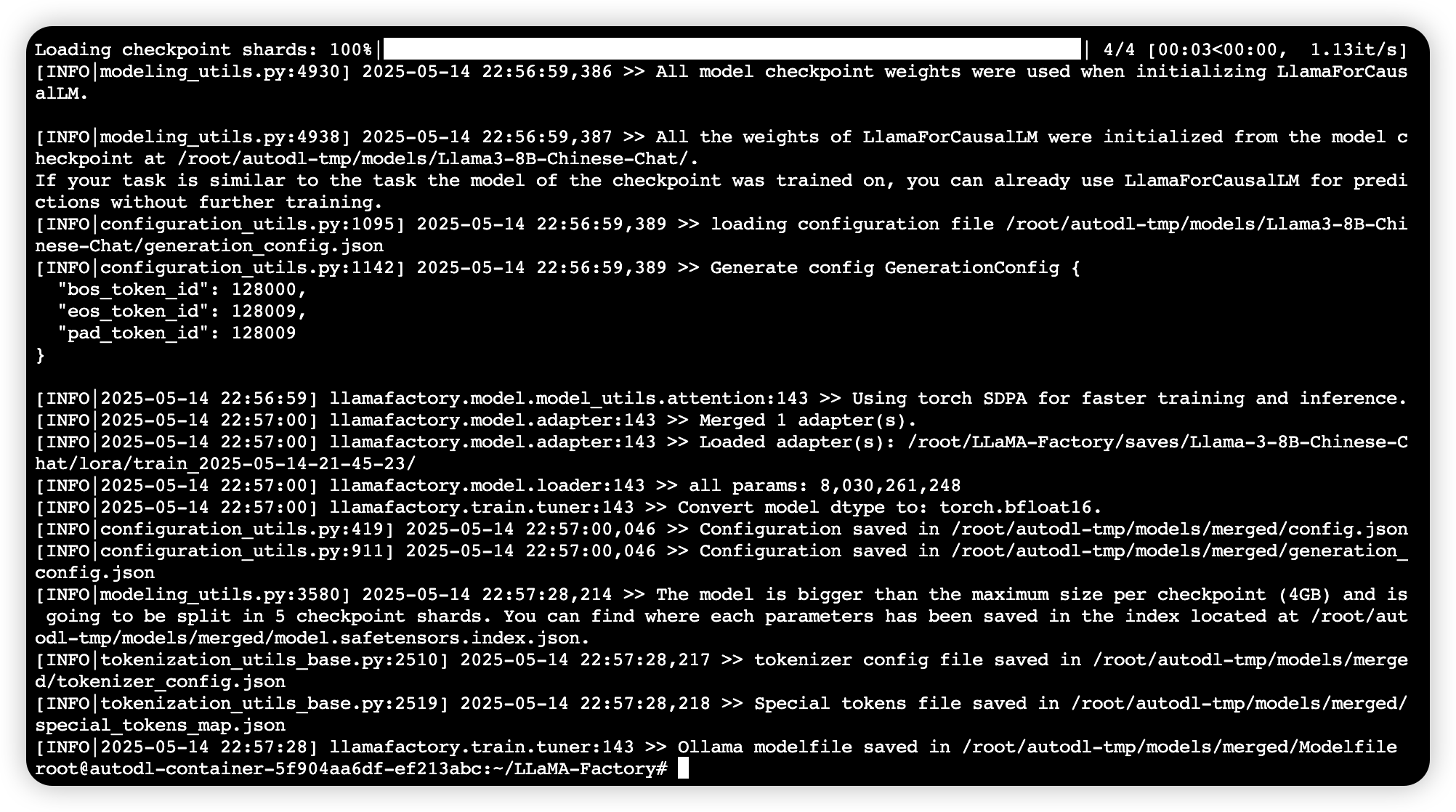
2、方式二
- 模型路径为 微调前模型本地路径 ,检查点路径选择 刚刚微调产生的lora权重 ,点击 下方export 选项,导出目录填写需要保存的地址 ,点击开始导出
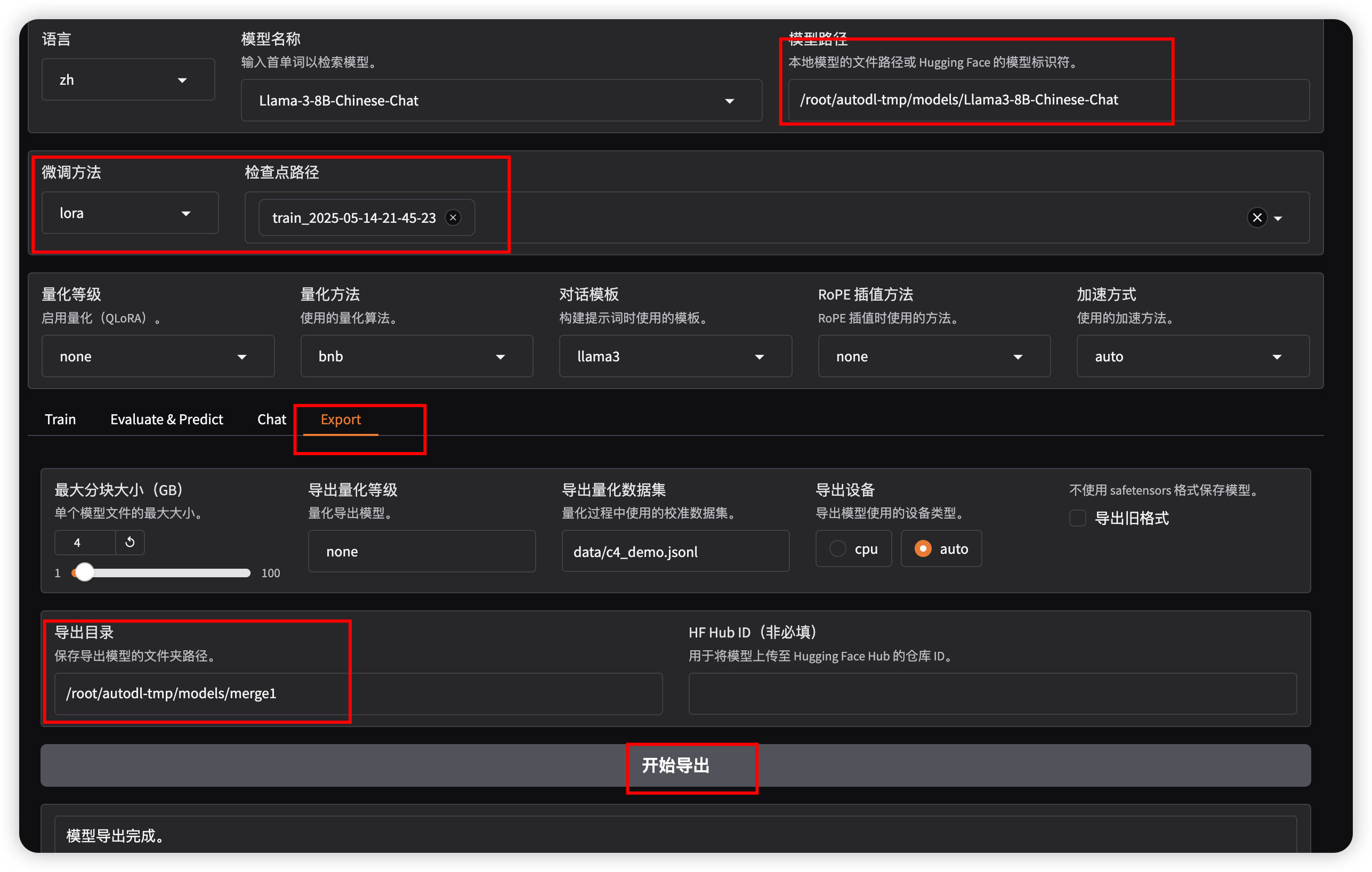
- 导出结果为: