视频相比图像包含更多信息:运动信息、时序信息、背景信息等等。
原先处理视频的方法:
- CNN + LSTM:CNN 抽取关键特征,LSTM 做时序逻辑;抽取视频中关键 K 帧输入 CNN 得到图片特征,再输入 LSTM,进行时间戳上的融合,得到视频的特征。最后将 LSTM 最终时刻的特征接一个 FC 层得到最终结果。
- 3D 网络:输入 3D CNN,模型参数量大。
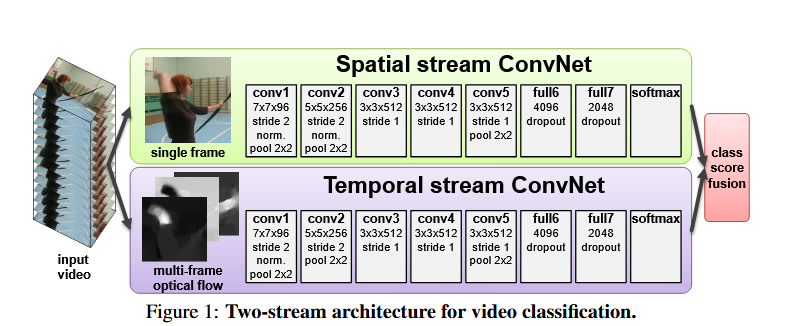
作者认为 CNN 本身适合处理静态信息(如物体的形状、大小、颜色等)而非运动信息。于是采取另一个网络(光溜网络)抽取运动信息,CNN 只需要学习输入光流和最后动作信息之间的映射。
最后的融合有两种方式:1)late fusion:两个 logits 加权平均得到最终结果;2)将 argmax 结果作为特征再训练一个 SVM 分类器。
光流是描述视频中物体的运动信息,对每个点实际上都是需要计算的,故而是一种密集表示。在本文中,作者将光流值压缩至 0,255,采用 JPEG 存储。(光流的弊端------存储空间大、提取速度慢)
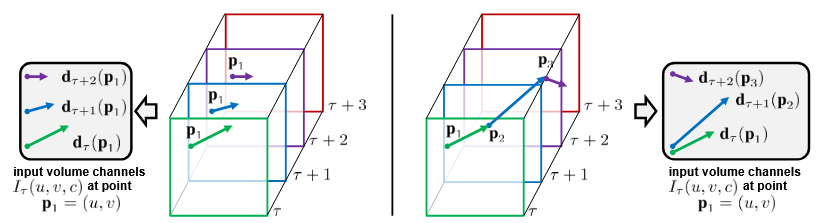
在本文中,光流采取了两种方式:1)简单叠加:每个点多次光流的叠加,光流点位置不更新;2)按轨迹叠加:每一帧都根据光流轨迹,更新光流点位置。(在本文实验中第一种方式更好,但实际上第二种更合理。)
在光流网络中,对所有视频首先 rescale 至 256,再固定抽取 25 帧(不管视频多长,等间距抽取),对抽取出来的每一帧都做 10 crop(每一帧裁剪 4 个边和 1 个中心,翻转之后再 crop 五张图)。
实验结果

- 空间流网络:使用预训练模型更好,可以直接使用从 ImageNet 上预训练的模型。
- From scratch:从头训练,效果更差。
- Pre-trained + fine-tuning:微调整个模型。因为数据集过小,担心过拟合,实验了 dropout ratio=0.9
- Pre-trained + last layer:微调最后一层,不担心过拟合。
- 时间流网络:简单叠加效果更好
- Single-frame:输入是单张光流图。
- Optical flow stacking、 Trajectory stacking:简单叠加和按轨迹叠加。
总结
之前的深度学习方法没有利用运动信息,导致效果远不如手工特征,由此引入运动信息------光流;同时双流网络的应用同时表明了,当魔改单个网络无法解决时,可以给模型提供一些先验信息,往往能大幅简化。同时也证明了数据的重要性,更多更好的数据能够提升模型效果、泛化性等一系列问题。