Beats是一个开放源代码的数据发送器。我们可以把Beats作为一种代理安装在我
们的服务器上,这样就可以比较方便地将数据发送到Elasticsearch或者Logstash
中。Elastic Stack提供了多种类型的Beats组件。

Beats可以直接将数据发送到Elasticsearch或者发送到Logstash,基于Logstash
可以进一步地对数据进行处理,然后将处理后的数据存入到Elasticsearch,最后
使用Kibana进行数据可视化。
1、FileBeat简介
FileBeat专门用于转发和收集日志数据的轻量级采集工具。它可以为作为代理安
装在服务器上,FileBeat监视指定路径的日志文件,收集日志数据,并将收集到
的日志转发到Elasticsearch或者Logstash。
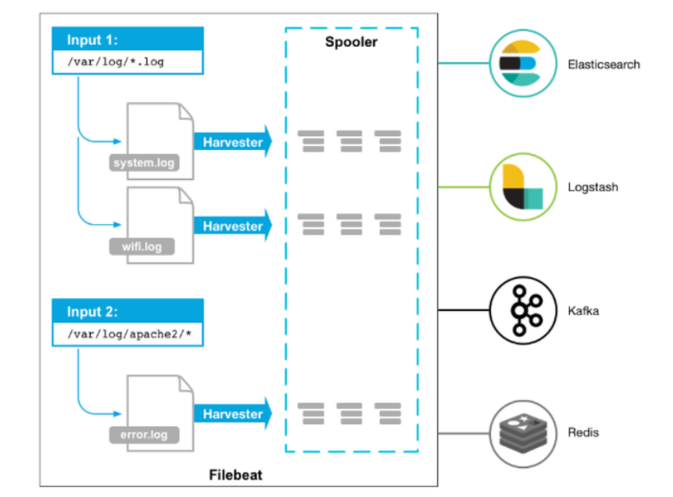
2、FileBeat的工作原理
启动FileBeat时,会启动一个或者多个输入(Input),这些Input监控指定的日
志数据位置。FileBeat会针对每一个文件启动一个Harvester(收割机)。
Harvester读取每一个文件的日志,将新的日志发送到libbeat,libbeat将数据收
集到一起,并将数据发送给输出(Output)。
3、安装FileBeat
安装FileBeat只需要将FileBeat Linux安装包上传到Linux系统,并将压缩包解压
到系统就可以了。
FileBeat官方下载地址:
https://www.elastic.co/cn/downloads/past-releases/filebeat-7-6-1
上传FileBeat安装到Linux,并解压。
1 tar ‐xvzf filebeat‐7.6.1‐linux‐x86_64.tar.gz ‐C ../usr/local/es
4、使用FileBeat采集MQ日志到Elasticsearch
4.1、需求分析
在资料中有一个mq_server.log.tar.gz压缩包,里面包含了很多的MQ服务器日
志,现在我们为了通过在Elasticsearch中快速查询这些日志,定位问题。我们需
要用FileBeats将日志数据上传到Elasticsearch中。
问题:
首先,我们要指定FileBeat采集哪些MQ日志,因为FileBeats中必须知道采集存放
在哪儿的日志,才能进行采集。
其次,采集到这些数据后,还需要指定FileBeats将采集到的日志输出到
Elasticsearch,那么Elasticsearch的地址也必须指定。
4.2、配置FileBeats
FileBeats配置文件主要分为两个部分。
-
inputs
-
output
从名字就能看出来,一个是用来输入数据的,一个是用来输出数据的。
4.2.1、input配置
bash
1 filebeat.inputs:
2 ‐ type: log
3 enabled: true
4 paths:
5 ‐ /var/log/*.log
6 #‐ c:\programdata\elasticsearch\logs\*在FileBeats中,可以读取一个或多个数据源。
FileBeats配置文件 - input

FileBeat配置文件 - output

4.3、配置文件
bash
1. 创建配置文件
1 cd /usr/local/es/filebeat‐7.6.1‐linux‐x86_64
2 touch filebeat_mq_log.yml
3 vim filebeat_mq_log.yml
2. 复制以下到配置文件中
1 filebeat.inputs:
2 ‐ type: log
3 enabled: true
4 paths:
5 ‐ /var/mq/log/server.log.*
6
7 output.elasticsearch:
8 hosts: ["192.168.21.130:9200", "192.168.21.131:9200", "192.168.21.132:
9200"]4.4、运行FileBeat
bash
1. 启动Elasticsearch
在每个节点上执行以下命令,启动Elasticsearch集群:
1 nohup /usr/local/es/elasticsearch‐7.6.1/bin/elasticsearch 2>&1 &
2. 运行FileBeat
1 ./filebeat ‐c filebeat_mq_log.yml ‐e
3. 将日志数据上传到/var/mq/log,并解压
1 mkdir ‐p /var/mq/log
2 cd /var/mq/log
3 tar ‐zxvf mq_server.log.tar.gz五、FileBeat是如何工作的
1、input和harvester
1.1、inputs(输入)
input是负责管理Harvesters和查找所有要读取的文件的组件
如果输入类型是 log,input组件会查找磁盘上与路径描述的所有文件,并为每个
文件启动一个Harvester,每个输入都独立地运行
1.2、Harvesters(收割机)
Harvesters负责读取单个文件的内容,它负责打开/关闭文件,并逐行读取每个
文件的内容,将读取到的内容发送给输出
每个文件都会启动一个Harvester
Harvester运行时,文件将处于打开状态。如果文件在读取时,被移除或者重命
名,FileBeat将继续读取该文件
2、FileBeats如何保持文件状态
FileBeat保存每个文件的状态,并定时将状态信息保存在磁盘的「注册表」文件
中
该状态记录Harvester读取的最后一次偏移量,并确保发送所有的日志数据
如果输出(Elasticsearch或者Logstash)无法访问,FileBeat会记录成功发送
的最后一行,并在输出(Elasticsearch或者Logstash)可用时,继续读取文件发
送数据
在运行FileBeat时,每个input的状态信息也会保存在内存中,重新启动FileBeat
时,会从「注册表」文件中读取数据来重新构建状态。
'
在/usr/local/es/filebeat-7.6.1-linux-x86_64/data目录中有一个Registry文
件夹,里面有一个data.json,该文件中记录了Harvester读取日志的offset。
六. Logstash
1、简介
Logstash是一个开源的数据采集引擎。它可以动态地将不同来源的数据统一
采集,并按照指定的数据格式进行处理后,将数据加载到其他的目的地。最开
始,Logstash主要是针对日志采集,但后来Logstash开发了大量丰富的插件,所
以,它可以做更多的海量数据的采集。
它可以处理各种类型的日志数据,例如:Apache的web log、Java的log4j日
志数据,或者是系统、网络、防火墙的日志等等。它也可以很容易的和Elastic
Stack的Beats组件整合,也可以很方便的和关系型数据库、NoSQL数据库、MQ等整
合。
1.1 经典架构
1.2 对比FileBeat
logstash是jvm跑的,资源消耗比较大
而FileBeat是基于golang编写的,功能较少但资源消耗也比较小,更轻量级
logstash 和filebeat都具有日志收集功能,Filebeat更轻量,占用资源更少
logstash 具有filter功能,能过滤分析日志
一般结构都是filebeat采集日志,然后发送到消息队列,redis,MQ中然后
logstash去获取,利用filter功能过滤分析,然后存储到elasticsearch中
FileBeat和Logstash配合,实现背压机制
2 安装Logstash和Kibana
bash
1. 下载Logstash
1 https://www.elastic.co/cn/downloads/past‐releases/logstash‐7‐6‐1
此处:我们可以选择资料中的logstash-7.6.1.zip安装包。
2. 解压Logstash到指定目录
1 unzip logstash‐7.6.1 ‐d /usr/local/es/
3. 运行测试
1 cd /usr/local/es/logstash‐7.6.1/
2 bin/logstash ‐e 'input { stdin { } } output { stdout {} }'
等待一会,让Logstash启动完毕。
1 Sending Logstash logs to /usr/local/es/logstash‐7.6.1/logs which is now co
nfigured via log4j2.properties
2 [2021‐02‐28T16:31:44,159][WARN ][logstash.config.source.multilocal] Ignori
ng the 'pipelines.yml' file because modules or command line options are speci
fied
3 [2021‐02‐28T16:31:44,264][INFO ][logstash.runner ] Starting Logst
ash {"logstash.version"=>"7.6.1"}
4 [2021‐02‐28T16:31:45,631][INFO ][org.reflections.Reflections] Reflections
took 37 ms to scan 1 urls, producing 20 keys and 40 values
5 [2021‐02‐28T16:31:46,532][WARN ][org.logstash.instrument.metrics.gauge.Laz
yDelegatingGauge][main] A gauge metric of an unknown type (org.jruby.RubyArra
y) has been create for key: cluster_uuids. This may result in invalid seriali
zation. It is recommended to log an issue to the responsible developer/devel
opment team.
6 [2021‐02‐28T16:31:46,560][INFO ][logstash.javapipeline ][main] Starting
pipeline {:pipeline_id=>"main", "pipeline.workers"=>2, "pipeline.batch.size"=
>125, "pipeline.batch.delay"=>50, "pipeline.max_inflight"=>250, "pipeline.sou
rces"=>["config string"], :thread=>"#<Thread:0x3ccbc15b run>"}
7 [2021‐02‐28T16:31:47,268][INFO ][logstash.javapipeline ][main] Pipeline
started {"pipeline.id"=>"main"}
8 The stdin plugin is now waiting for input:
9 [2021‐02‐28T16:31:47,348][INFO ][logstash.agent ] Pipelines runn
ing {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
10 [2021‐02‐28T16:31:47,550][INFO ][logstash.agent ] Successfully s
tarted Logstash API endpoint {:port=>9600}
然后,随便在控制台中输入内容,等待Logstash的输出。
1 {
2 "host" => "127.0.0.1",
3 "message" => "hello logstash",
4 "@version" => "1",
5 "@timestamp" => 2021‐02‐28:01:01.007Z
6 }