一、应用层
应用层是程序员最关心的一层,需要自定义数据传输的格式 ,即前(客户端)后(服务器)端交互的接口,然后调用传输层的 socket api 来实现网络通信。
自定义数据传输的协议,主要是定义两个部分:
- 通信的内容。
- 通信的数据格式。
1、通信的内容
通信的内容根据用户需求确定。一般用户不会表达自己的需求,就需要产品经理来沟通和定制。比如一个外卖程序的主页,需要显示你附近的商家列表,它的内容就可以是:
请求:
- 用户信息(根据用户喜好显示商家)
- 位置信息(显示附近的商家)
响应:商家列表。
每个商家的数据:
- 商家的名称
- 商家的图片
- 商家的评分
- 商家的简介
- 商家的距离
- ............
2、通信的数据格式
- 行文本 :将所有数据排成一行 。比如 qq 发送一条信息包含的内容有 发送用户 id、接收用户 id、发送时间、发送内容。但这种方法可读性很差,以前常用,现在就很少用了。
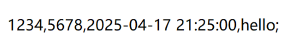
- xml :通过标签,对数据进行解释说明 。这种方法虽然可读性好,但是引入了很多标签,占用的网络带宽更多了 ,而网络带宽是服务器中最贵的资源。所以这种方法也很少用于网络通信了,更多的是作为本地的配置文件。
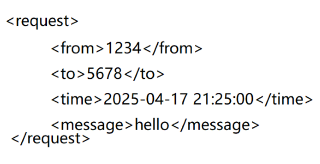
- JSON :当前最流行的方式,用 {} 作为界限、用 ; 分隔键值对、用 : 分割键和值。适用于不是特别缺带宽的场景。

- google protobuffer :会将传输的数据按一定的规则编码成二进制的比特位 ,然后进行传输。这种方式可读性非常差 ,但是消耗的网络带宽最少,适用于特别缺带宽的场景。
- 还有一些现成的应用层协议 ,可以直接使用,在后续会重点学习HTTP。
二、传输层
我们虽然不需要实现传输层的代码,但是需要调用传输层提供的 api 。因此我们需要了解传输层协议的数据格式,才能更好地使用传输层的 api。
1、UDP 协议

端口号 就不用多说了,他就是 2 个字节的无符号整数,0~65535 ,不能超过这个范围,也尽量不要设置 0-1023 知名端口号,它们是专供一些常用的应用层协议使用的。
UDP 长度 也是 2 个字节,即64 KB ,这就意味着一个 UDP 数据报能存储的数据长度有限制 。就比如搜索服务器投放广告,在 30 年前,广告很少也很简单,并且计算机内存也就 1 MB,那时候 64 KB 就很充足。但是现在,广告越来越多和复杂,不仅有文字还有很多图片,计算机内存通常也是 16 GB、32 GB 等,64 KB 就远远不够用了。对于这个问题,有几个设想方案:
- 在应用层对数据进行拆分传输。行不通,因为开发量很大,数据拆分涉及到的问题很复杂。部分数据丢包了如何处理;某部分数据出错如何处理;发送和接收的顺序不一致时该如何处理.........
- 换成 TCP 协议,它以字节为传输的基本单位,没有明确的上限。
- 升级 UDP 协议,扩充长度为 4 个字节。行不通,协议标准虽然好升级,但是协议的实现是由操作系统开发商厂家们决定的,如果升级出了问题损失的厂家。并且还必须让所有设备都进行升级,如果一个是新版,一个是旧版,也是无法通信的。所以 UDP 升级的成本很大,用一个新的协议替代 UDP 是成本最低的。
校验和 用于校验数据报在传输中是否出错 。数据本质上是通过电信号、光信号、电磁波以高低电平、光电磁波频率来表述 0、1 比特组成的数据。在环境中可能会收到磁场等环境的影响,随机概率性地让高频 1 变为了低频 0,或者从 0 变为 1。这种出错无法完全避免,只能辨别数据是否出错。校验和就是一种解决方案:发送方将数据报中的每个字节0、1进行累加为 16 位的整数然后填充到 UDP 报头的校验和字段;接收方收到数据报后,按同样的方法计算一遍校验和,看是否跟数据报中的校验和相等,不相等就表示出错了,直接丢掉数据。当让也会存在某一个 0 变为 1,某一个 1 变为 0,虽然出错了但是校验和没变的情况,但发生的概率很小。如果在对准确性特别敏感的场景,就需要更精准的其它算法。比如海明码,他能鉴别哪一位出错并自动纠错,但算法更加复杂,代价更大。
UDP 的应用场景:


最常见的是 DHCP:把电脑插到路由器上,该协议会自动给电脑分配一个 IP 地址,而不需要手动配置。还有就是 DNS,会在后续学习。更多的场景是应用在分布式系统 中,服务器间的通信 ,因为服务器都在同个机房,网络环境简单 ,不容易丢包 ;UDP 的传输效率也比较高适合分布式场景。
2、TCP 协议
TCP 协议段格式:
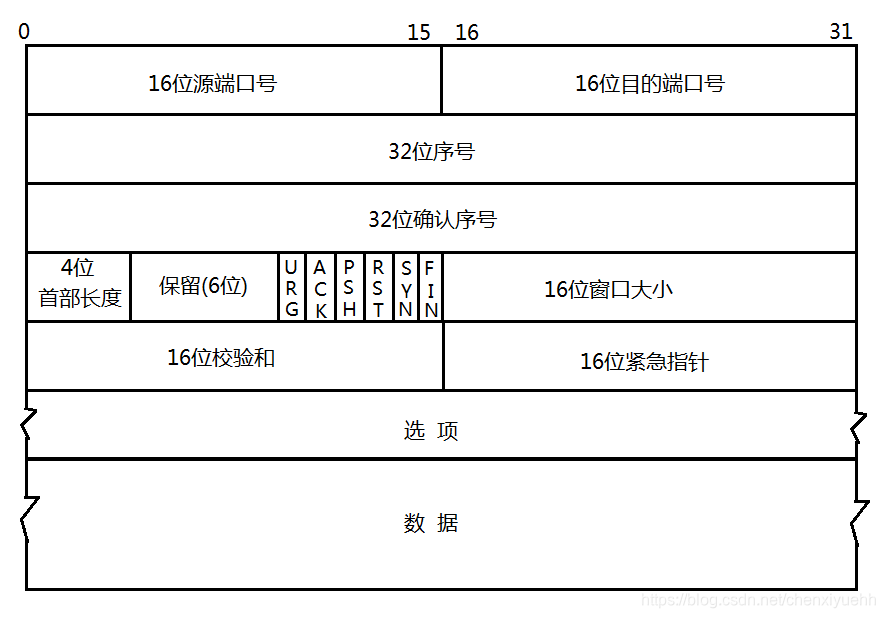
- 源端口号、目的端口号:告知发收双方设备运行的是哪个程序。
- 首部长度 :说明 TCP 报头的长度 。4 位可以代表 0~15,每个数的单位都是 4 个字节 ,那么首部长度可以代表 0~60 字节。图中前 5 行每行占 4 字节,那么共占 20 字节。而选项可有可没有,剩下的字节长度 就是选项的长度,占 0~40 字节。
- 保留 :UCP 很难实现升级,但又受到 64KB 的限制。保留位就可以在以后升级需要的时候用,同时也不会变动其他部分的格式。
- 校验和:与 UDP 一致。
2.1、可靠传输
我们实现不了传输的数据 100% 发送给对方,因为就算软件层面做到了对各种情况的处理,但硬件出了问题软件层面是没有办法的。因此,可靠传输指的是:能知道对方是否收到我发送的数据 。如果没有收到 (丢包),会做出一些措施补救。
2.1.1、确认应答
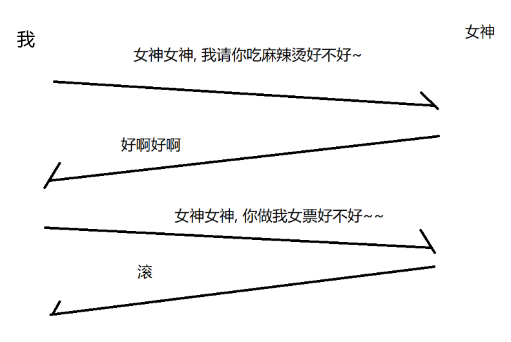
接收方收到数据后,会回应一个 "应答报文 " (acknowledge, ack)来表明收到数据。比如下面的场景中,女神回复我后,我才知道女神收到了消息,否则就认为消息 "丢包" 了。
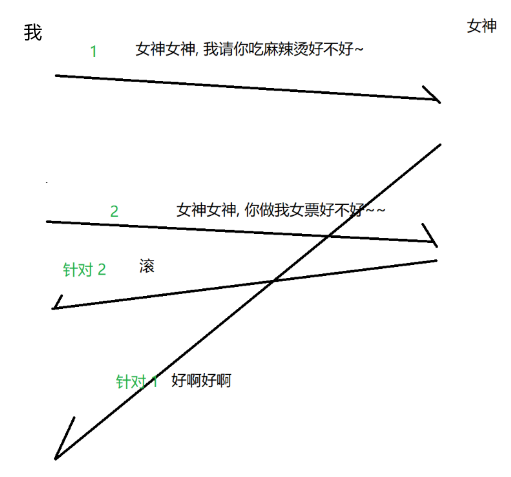
网络中也有可能发生 "后发先至" 的情况,因为数据报传输的路线不同的,有的交换机/路由器 "拥堵",有的 "畅通"。如下面的场景,我误认为女神答应做我的女朋友。
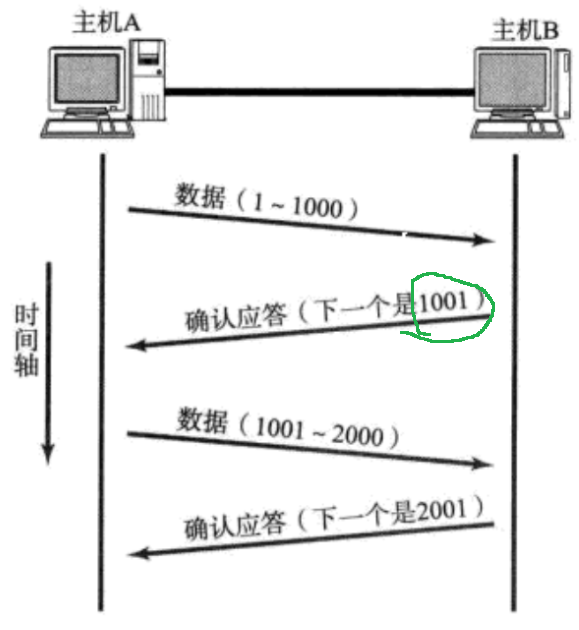
序号 就是1、2;确认序号 就是针对1、针对2。它们都是以字节为单位进行编号 的。因为编号是连续递增的,所以序号 保存的是 TCP 载荷的第一个字节的编号 ,就可以知道后续每个字节的编号。而确认序号 保存的是 TCP 载荷的最后一个字节的下一个字节的编号 ,用于告诉发送方:1、这之前序号的字节我都收到了。2、你从该确认序号的位置开始继续发送。TCP 接收数据时,会在操作系统内维护一个 "接收缓冲区" ,在缓冲区里根据序号进行重排序,解决了后发先至的问题。
确认序号只在应答报文中生效 ,即关键字段中 ACK 为 1。

2.1.2、超时重传
确认应答 机制针对的是数据成功发送的情况 ,通过 ack 告诉发送方已收到。而超时重传 机制,针对的是数据发送失败的情况(丢包),重新发送的策略。
超时 可以判断是否丢包 ,传输数据时,只要超过超时时间,还没收到 ack 就认为丢包。重传 可以减小丢包的概率。比如丢包的概率是 10%,那么再重新发送一次,丢包的概率就减小到 10% x 10% = 1%。

没有收到 ack 有两种情况:1、发送数据报丢包 。2、应答报文丢包 。针对1,重传没有问题。针对2 ,重传会发生接收方收到多个重复数据报的问题。如果是转账场景,本来转 500,却转了 1000。
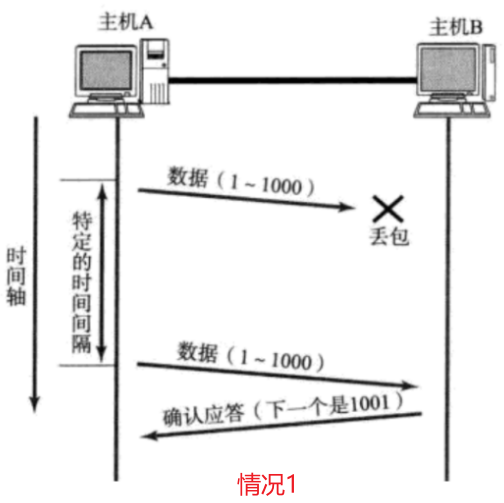
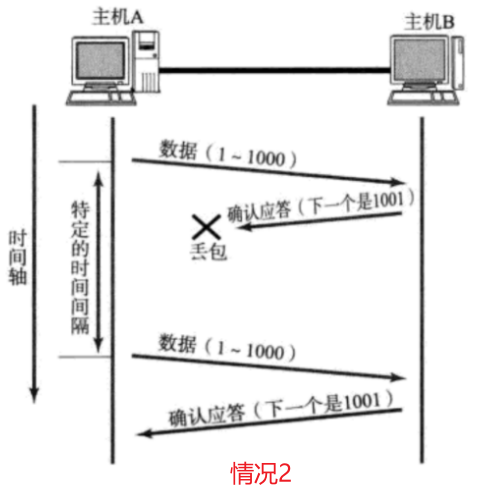
针对这种情况,TCP 做了处理:在接收缓冲区中,会对收到的数据报根据序列号进行去重。
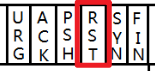
超时重传的超时时间 是动态变化 的,对于同一个数据报,重传的次数每增加一次 ,超时时间就会延长 。因为如果再次丢包,表示该网络传输的丢包概率不止 10%,频繁重传可能还会加重网络故障的程度。重传的次数/时间是有上限的,当达到上限后还是丢包 ,TCP 就会重置,即复位报文中会将 RST (reset)置1 。然后释放连接,相当于删除之前保存的对方的信息。
网络上所说TCP 可靠性是由 "三次握手" 实现的,是错误的说法 。三次握手是 TCP 建立连接时的策略,连接建立好后就没有三次握手的事情了。
2.2、连接管理
TCP 是有连接 的,具体表现就是通信双方会保存对方的信息(IP、端口号)。连接建立的过程就是保存对方信息的过程,由三次握手实现;连接断开的过程就是删除对方信息的过程,由四次挥手实现。
2.2.1、三次握手(连接建立)
(1)什么是三次握手
三次握手,传输的是没有带载荷 (业务数据)的数据报 ,通过双方互相同步 (synchronized,通知)、应答 的方式建立可靠的连接。
关键流程:三次握手,必定是客户端先发起请求,建立连接。
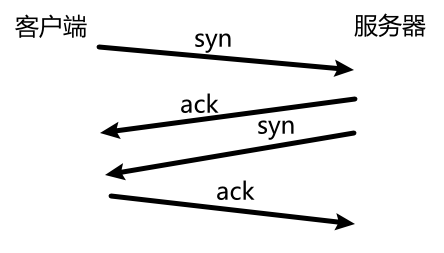
- 客户端发起一个同步报文(syn):告诉服务器,我要跟你建立连接,请你保存我的信息。
- 服务器返回一个应答报文(ack):回应客户端:收到,我会保存。
- 服务器也发起一个同步报文(syn):到苏客户端,我也要和你建立连接,请你保存我的信息。
- 客户端也返回一个应答报文(ack):回应服务器:收到,我会保存。
事实上,服务器的 ack 和 syn 都是操作系统内核控制 的,程序员无法在应用层干。操作系统一次合并传输两个数据 ,提高效率 ,因为每次数据传输的封装分用有开销。
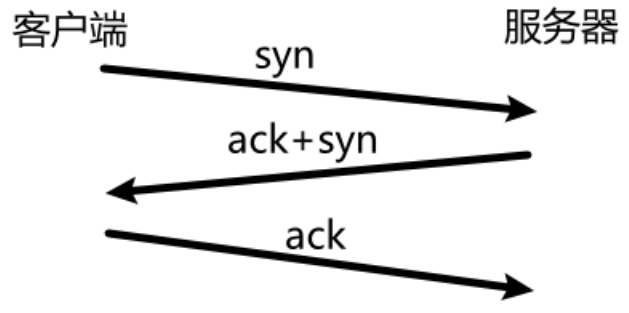

(2)三次握手的意义
- 验证通信链路是否通畅:三次握手是可靠传输的前提条件,目的是验证传输的链路中是否存在问题,而不是传输数据(比如首发地铁,先跑一次空车,看铁路是否有异常)。
- 验证通信双方的发、收能力是否正常:
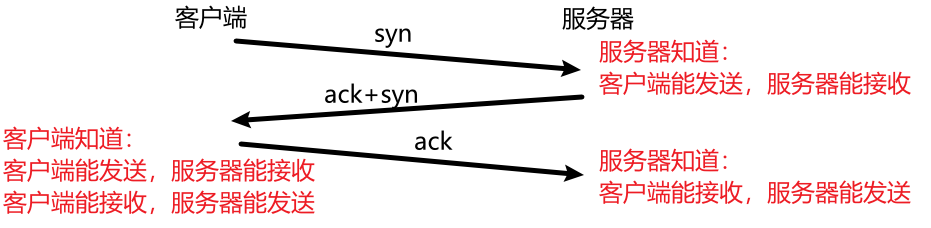
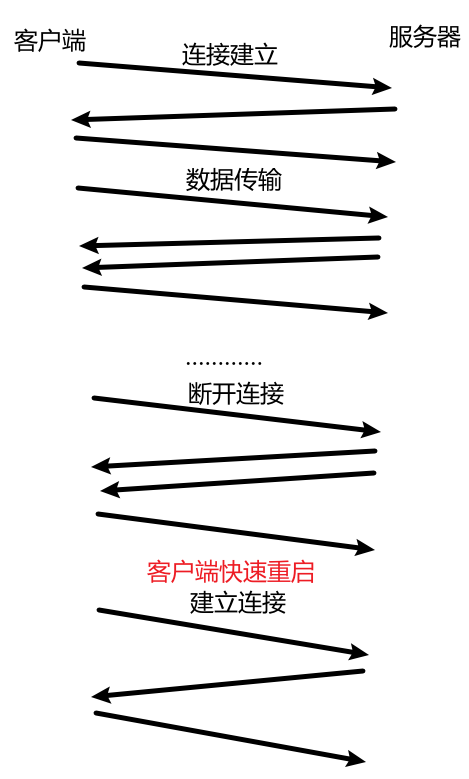
- 同步通信双方的序列号 :连接建立过程中,TCP 数据有起始序列号 ,即传输的第一个数据报的载荷的第一个字节的序号(SYN、FIN 占一个序列号),客户端、服务器都有各自的序列号系统。这个起始序列号是一个随机值 ,并且每次连接的起始序列号都很不同,这是为了:客户端与服务器建立第一次连接,并传输数据;然后客户端快速重启,与服务器建立第二次连接,并传输数据。但是,第一次连接后传输的某个数据可能会因为网络延迟,延后到第二次连接后到达 ,此时我们应该丢掉该数据 。如何辨别该数据是否是第一次连接传输的呢?就看它的序列号是否与本次连接的起始序号有很大的差异,如果有,就说明不是本次连接的。
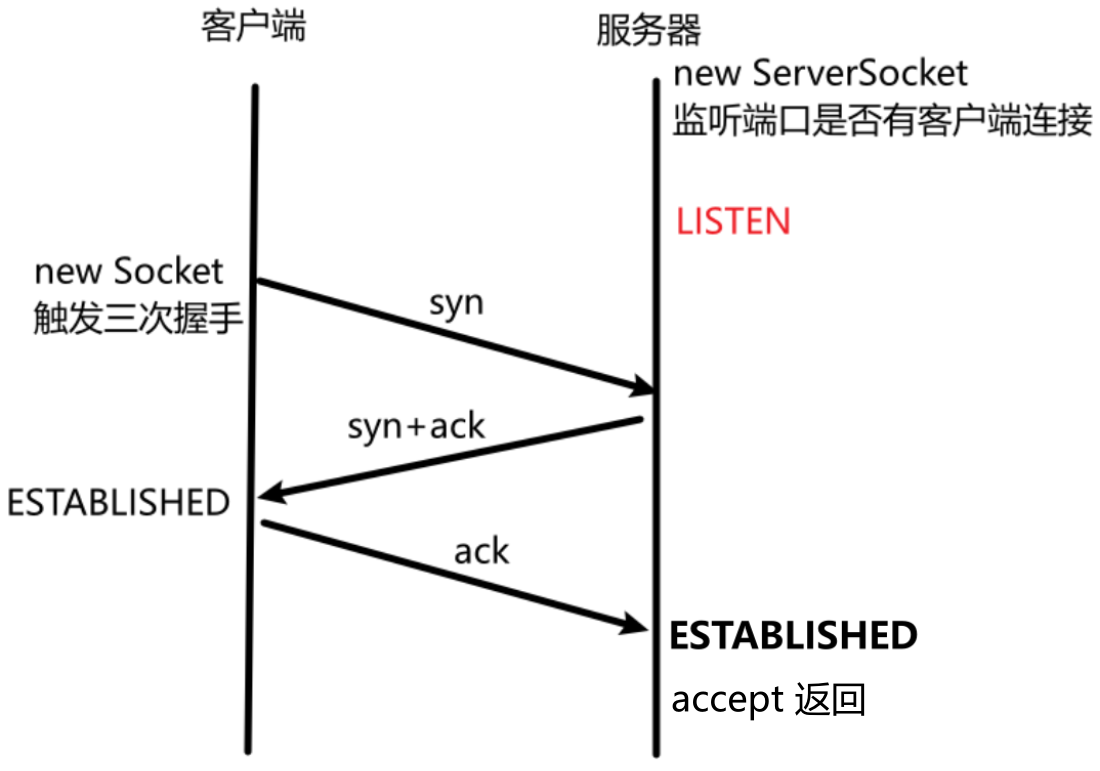
(3)三次握手的 TCP 的状态
TCP 的状态很多很复杂,我们只需要了解几个比较重要的:
- LISTEN :服务器 new ServerSocket 就会进入该状态,表示对服务器端口的监听,表示服务器存在。当端口上有客户端过来,就可以 accept 了。
- ESTABLISHED :服务器、客户端完成三次握手后 ,就进入该状态。表示服务器与客户端的连接已经建立好了。
- 客户端 new Socket 触发三次握手;accept 阻塞等待完成连接;三次握手完成后,accept 返回 Socket 对象。
2.2.2、四次挥手(连接断开)
(1)什么是四次挥手
四次挥手可能是客户端主动发起 的,也可能是服务器主动发起的。
关键过程:
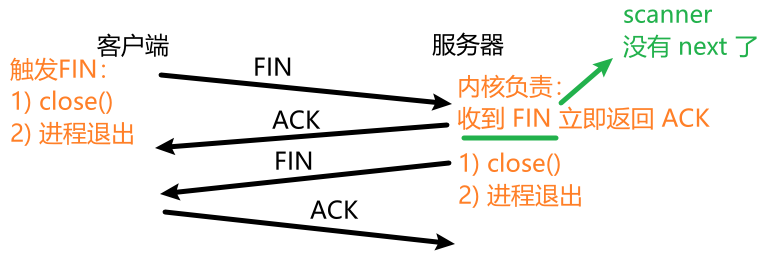
- 客户端告诉服务器:我要和你断开连接,请你删除我的信息。
- 服务器回应收到。
- 服务器也告诉客户端:我也要和你断开连接,请你删除我的信息。
- 客户端回应收到。
跟三次握手不同的是,四次挥手不完全由操作系统内核控制,而是和应用层代码也有关系 。之所以叫四次挥手 ,而不是三次挥手,就是因为中间的 FIN 是由应用层程序控制的,中间的 FIN 与 ACK 可能不在同一时刻发生 ,合并不一定发生。
不合并的情况:hasNext 返回 false 后,close 之前,还有其他逻辑,ACK 和 FIN 间隔比较长。
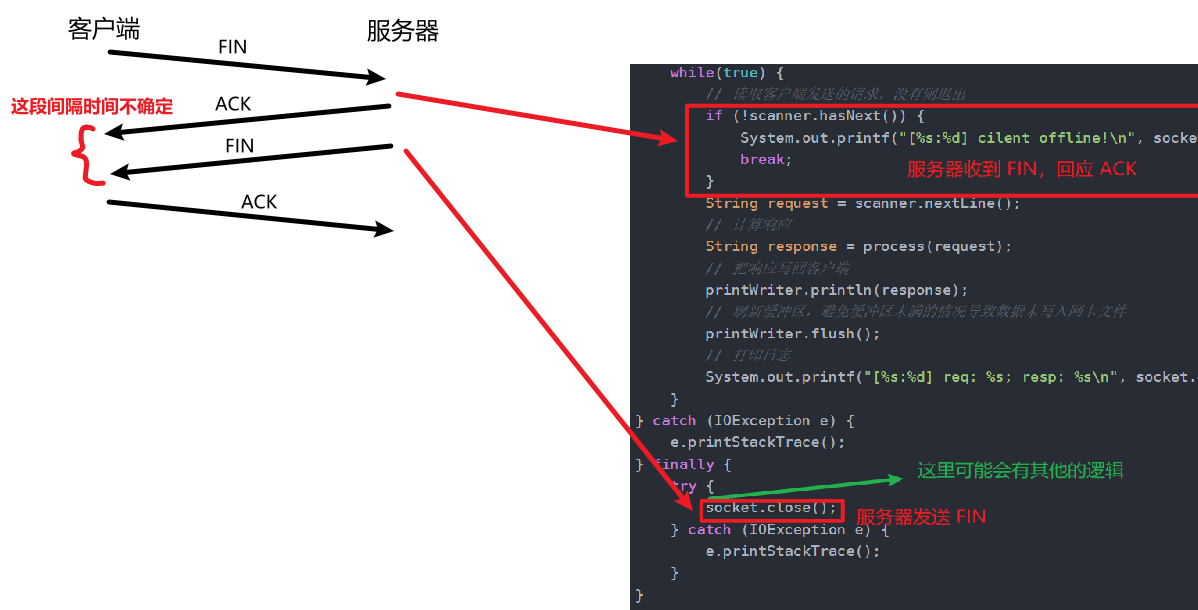
合并 的情况:间隔时间本身不长 ,服务器 ACK 还延迟应答 。这属于特殊情况,是一种优化手段,合并的情况肯定效率更高,所以还是叫四次挥手,而不是三次挥手。
(2)四次挥手的意义
四次挥手就是为了释放空间,删除保存的对方信息。
(3)四次挥手的 TCP 状态
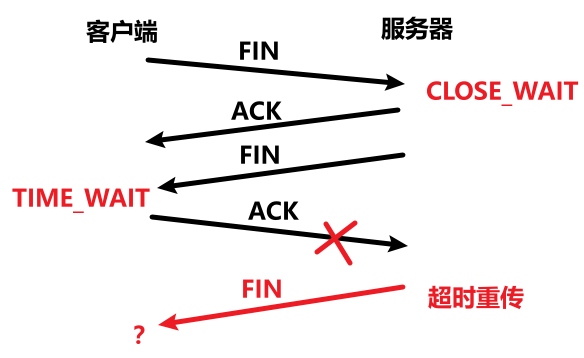
- CLOSE_WAIT :被动 断开连接的一方 进入的状态。收到对方发来的 FIN,回应 ACK 的同时,进入该状态,表示等待 close 。这个状态持续时间很短,如果发现有大量连接都处于此状态 ,说明大概率存在文件泄露。
- TIME_WAIT :主动 断开连接的一方 进入的状态。收到对方发来的 FIN,回应 ACK 的同时,进入该状态,表示等待连接彻底释放 。因为回应的 ACK 可能会丢包 ,那么对方就会超时重传 FIN,如果主动方回应 ACK 后立即释放连接 ,那么重传的数据就无人处理 。所以会等待 2*MSL 的时间,MSL 是一个充裕的时间,比如 Linux 上是 60s,能够给予充分的时间完成一趟 FIN 或 ACK 传输。
三次握手、四次挥手的过程,大部分工作由操作系统内核完成,应用层代码涉及的部分很少。但是我们还是需要学习,因为有助于理解、调试程序。
2.3、提高传输效率
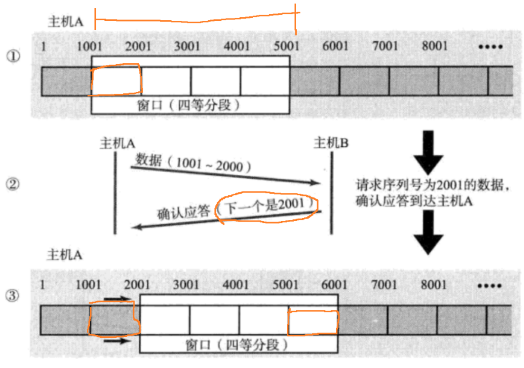
2.3.1、滑动窗口
(1)什么是滑动窗口
虽然确认应答、超时重传机制保证了 TCP 的可靠性 ,但同时也降低了传输效率:每发送一条数据,就需要等待回应一条 ack 报文。
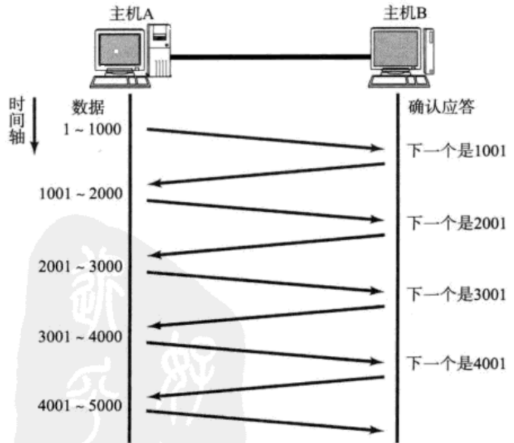
滑动窗口 机制能缓解传输效率降低的问题 。首先,批量发送滑动窗口大小个数的一批数据 ,然后在等待 ack 回应。等到一个 ack ,滑动窗口就向后滑动一格并发送一条数据。(之所以没有等待一批 ack 后再发送一批数据,是因为 ack 之间是有一个先后顺序的,对应了发送数据的先后顺序。如果直接等待一批,那么先后顺序就没有了,也就不知道回应的是哪一条数据。)
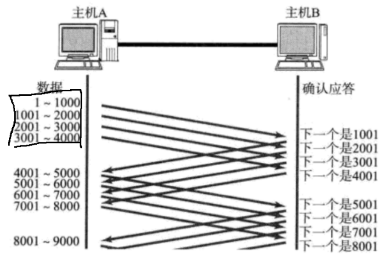
就相当于还没有等完滑动窗口内的数据的 ack,就提前发送了下一条数据。如下图中,接收到 2001 的 ack 就认为 1001-2000 已收到,立即发送 5001-6000。窗口内都是等待 ack 的数据,当收到 ack 的速度很快,那么窗口就滑动起来了。
(2)滑动窗口下,应对丢包的处理
- ack 丢包:
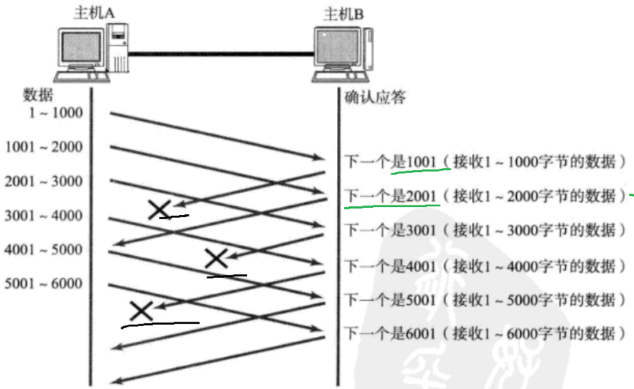
**不做任何处理。**虽然 1~1000、2001~3000、3001~4000 的 ack 丢包了,但是 1001~2000 的 ack 能表示 2001 之前的数据都已经收到,4001~5000 的 ack 能表示 5001 之前的数据都已经收到。之后的 ack 能替代之前的 ack。若是最后一个 ack 丢包,那么就会触发超时重传机制。
- 数据包丢包:
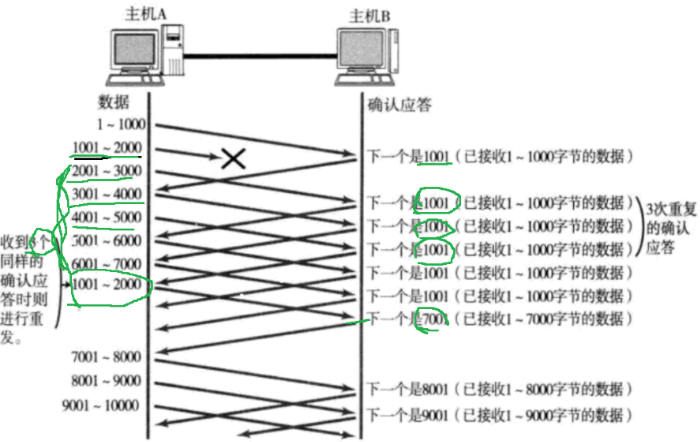
快速重传。如图为例子,若 1001~2000 丢包,那么 B 就会反复向 A 索要 1001。当 A 感知到 B 多次索要后,就会重传 1001~2000。而此时 B 的接收缓冲区已经有了 1~ 7000,那么会继续索要 7001,后续照常执行。
其实,滑动窗口、快速重传 机制 与 确认应答、超时重传 机制是共存的。当 TCP 的传输数据量大时,就启用滑动窗口、快速重传机制。当 TCP 的传输数据量小时,就启用确认应答、超时重传机制。
2.3.2、流量控制
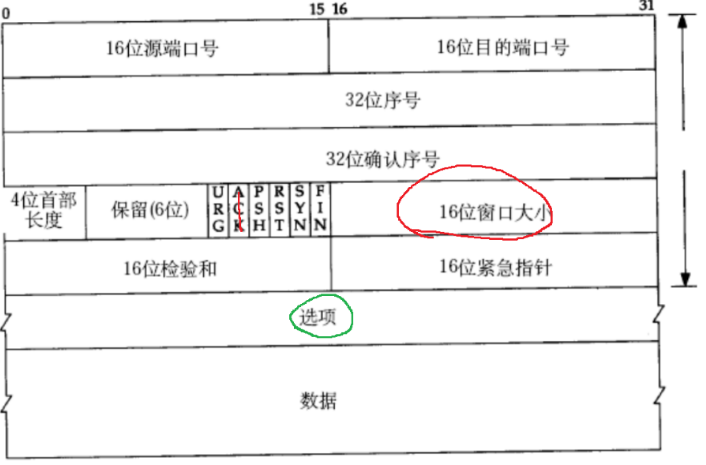
流量控制 ,控制的是发送方窗口大小。如果窗口过大,发送速度快,而接受速度跟不上,就容易丢包,又得重传。因此我们需要根据接收方的接收速度 ,来调整发送方的窗口大小 。接收速度,就是从接收缓冲区 read 的速度,那如何衡量 read 的速度 呢?就是接收缓冲区剩余的容量 ,容量多就表明 read 速度快。接收方返回的 ack 报文中的 16 位窗口大小 (若不是 ack 报文,窗口大小字段无意义 )位置会存储接收缓冲区容量 ,返回给发送方,据此控制滑动窗口大小。但 16 位并不意味着发送方的滑动窗口最多只能控制在 64 kb 的大小。因为选项 中有一个项是窗口扩展因子 :滑动窗口大小 = 16 窗口大小 << 窗口扩展因子 。这意味着 2 的指数级增长,因为左移一位就代表 x 2 倍。
补充:read 时会先在接收缓冲区中按序号排好数据,再 read。比如 1001~2000 应在 2001~3000 之前被接收。但 2001~3000 先到达,此时接收缓冲区就会阻塞,等到 1001~2000 入队后再 read。
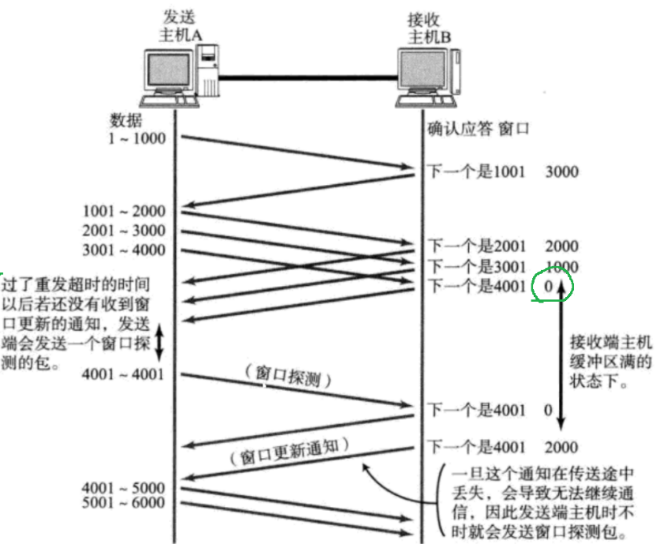
如下图为例,演示 A 控制滑动窗口的过程 :一开始 B 收到数据后不消费,存储在接收缓冲区中,最后接收缓冲区容量为 0,A 收到窗口大小为 0 的 ack 就会停止发送数据(因为缓冲区已经没容量了,继续发送只会丢包)。当缓冲区有容量后,B 会主动发送窗口更新通知 ,告知可以继续传输数据。在 A 未收到窗口更新通知的这段时间里,A 会周期性地发送 不带业务数据的窗口探测 包,避免因窗口更新通知丢包 ,而导致 A 一直保持等待的状态 。
2.3.3、拥塞控制
实际上传输的路径处于复杂的网络中,因此滑动窗口的小大 不仅要考虑接收方的速度**,还要考虑整条传输路经上每个节点的速度** 。拥塞控制 的的核心思想就是"尝试 ":如果丢包 ,说明路径中右节点的速度更不上,就减小窗口大小 ,减小速度。如果没丢包 ,就适当增大速度。
下图展示了拥塞控制的滑动窗口大小的变化过程:
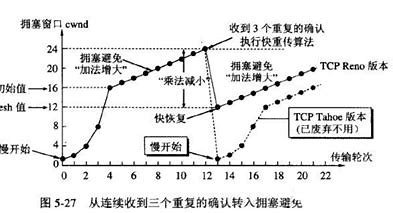
- 一开始慢启动,窗口大小很小,处于试探状态。
- 若没有丢包,就指数增长,快速增大窗口大小。
- 增长到一个阈值 后,就线性增长,增长速率放慢。
- 增长到一定程度,触发丢包:
- 旧版本(已废弃):直接回到慢启动 的状态,然后再指数增长 ,但阈值减小 ,再线性增长。
- 为了使 TCP 的传输效率更稳定 ,新版本的做法是:回到新阈值位置 ,再线性增长。
而滑动窗口的最终大小 ,由流量控制的窗口 (发送方维护)和拥塞控制的窗口 (接收方返回 ack 通知)共同决定,取较小值。
2.3.4、延时应答
为了提高传输效率 ,我们应在保证可靠性的基础上,增大滑动窗口大小。如何增大滑动窗口大小:辅助手段是,等待一段时间后应答,让接收方(消费者)消费更多的数据,留出更多的剩余接收缓冲区(前提是等待的这段时间里,发送方没有持续发送很多数据包)。这不仅能增大滑动窗口 ,还能减少 ack 的个数 (后续的 ack 可以反应前面序号的数据都已经收到,所以可以减少),从而节省带宽(数据的传输需要封装分用)。
但并不是所有的包都能延时应答:
- 当发送的数据量多时,隔一定的数据包个数应答一次。
- 当发送的数据量少时,隔一定的时间应答一次(起码间隔时间不能超过超时重传的超时时间)。
2.3.5、捎带应答
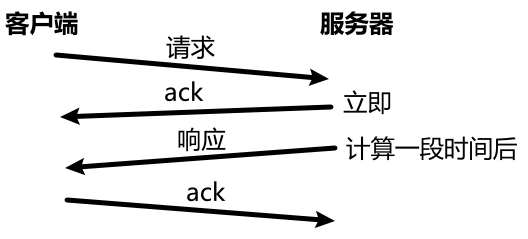
客户端发送请求,服务器接收到请求后会立即返回 ack 。而服务器发送响应 是在进行一段计算后 执行的。ack 仅含报头(ack 为 1、携带确认序号、窗口大小),而数据包相反,含载荷(ack 为 0,确认序号、窗口大小位无效)。当延迟应答发生 ,返回的数据包刚好能捎带 ack 的报头信息 ,让两次传输合并为一次 ,提高传输效率。
2.4、面向字节流
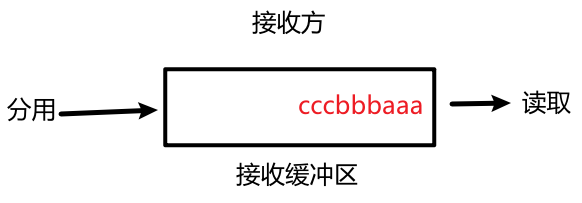
发送方连续发送几个数据包时,接收方分用去掉报头,将载荷放入接收缓冲区,当接收方应用层 read 时,就难以判断一个数据包载荷的边界在哪 ,数据包黏在了一起,即 "粘包问题":
解决粘包问题,有以下方法:
- 以特定的分隔符结尾。
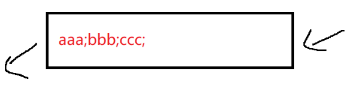
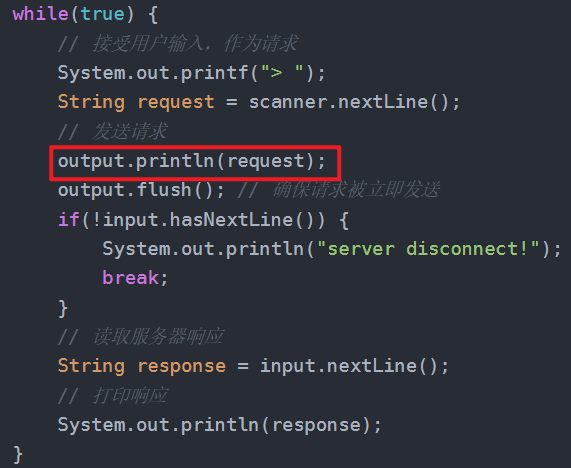
在之前的 TCP 网络通信编程中,我们是以 '\n' 为分隔符的。
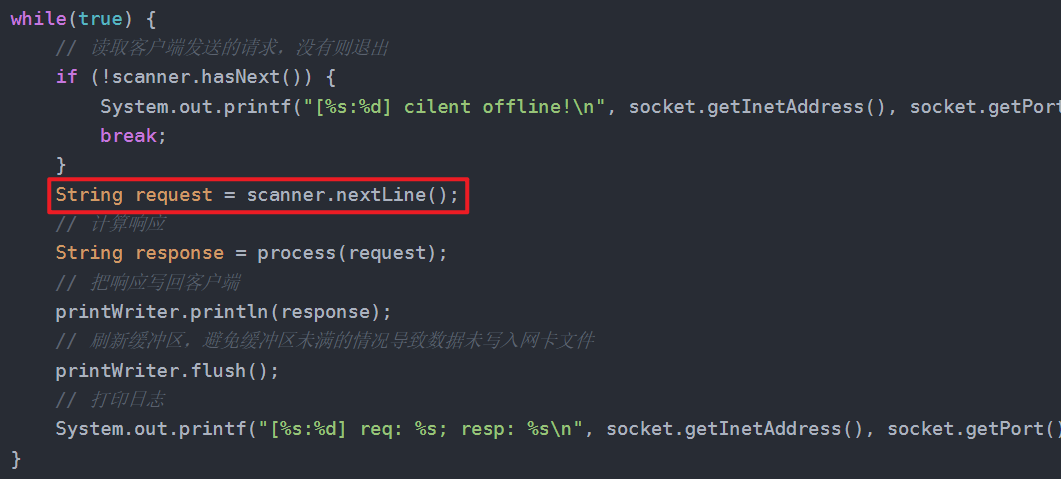
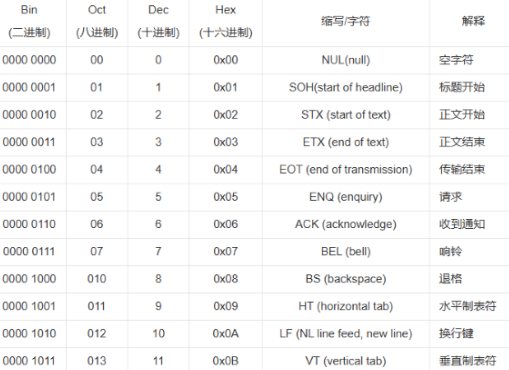
但注意正文中不能有分隔符,不然会错误分割。我们可以用 ascii 码中的不可见字符,来作为分隔符,因为里面很多字符现在都不怎么用了:
- 在每个载荷的开头存放一个 2 字节的数字,表示数据包载荷的长度。read 时,首先读取 2 字节,根据该数字来决定读取几个字节作为一个数据包。

同样,字符流也会存在粘包问题,比如向文本文件写入结构化数据,就可以将每个结构化数据写成一行,再以换行符分隔。而 UDP 不存在这样的问题 ,因为它每次发送、传输 的是一个 DatagramPacket ,对应了一个完整的应用层数据包。
实际开发中,常基于知名的框架/库进行开发,这些框架/库已经在底层处理好粘包问题。但有时需要做 "专用" 的东西,就需要 diy 处理。
2.5、异常情况
- 进程崩溃 :此时进程退出,PCB 销毁,那么文件描述符表也会随之销毁,那么 socket 打开的网卡文件也随之销毁,随即发送 FIN。但此时连接还没被断开,因为需要完成四次挥手后才完全断开。
- 主机关机 :关机也会导致进程退出,如果关机关得慢,连接断开的过程与进程崩溃一样。如果关机关得快 ,发送 FIN 后 还没有等到 ack ,就已经关机了。此时对端也发送 FIN ,就没有 ack 回应,随后触发超时重传 ,达到上限次数后,就会发送重置报文 ,单方断开连接 ,把对方的信息删除。而对方也因关机,删除了内存中保存的自己的信息。
- 主机断电 :断电是瞬间的事,连FIN 都没发出 。如果断电方是接收方 ,发送方 继续发送数据,而没有 ack ,然后超时重传,然后重置断开连接 ;如果断电方是发送方 ,那接收方 就不知道是发送方暂时没有发数据,还是出现了异常,就会一直处于阻塞等待的状态 。为了避免上述情况,接收方和发送方会互传 "心跳包 ",来感知对方是否存在 。当接收方发送心跳包,发送方没有回应,就表明发送方已断开连接。这个机制在分布式系统中非常重要,当请求量大时,会让几台机器一起处理,当网关服务器感知到某一台机器挂了,就会把请求均分给剩下的 3 台服务器,让整体的服务更稳定。TCP 协议虽然提供了心跳,但周期较长;有些场景我们需要更灵敏的感知,需要更短的周期,我们就要在应用层写代码实现。
- 网线断开:跟主机断电的连接断开操作一样。
2.6、TCP 报头的其它字段

- URG :"紧急指针"有效 ,16 位紧急指针字段 里存储的数字,代表从当前位置往后多少个字节的位置的数据先传输。比如 1~1000 的数据包,紧急指针是 1000,那么就先传输 1001~2000 的数据包。
- ACK:应答报文。
- PSH:催促接收方,尽快读取接收缓冲区中的数据。
- RST:复位报文。(单方面断开连接)
- SYN:同步报文。
- FIN:结束报文。
网络通信大部分情况优先考虑 TCP;机房内部传输,不太容易丢包的环境,比如分布式系统,使用效率更高的 UDP;不要求严谨的可靠,但要求效率比 TCP 高,就会使用其它的协议。
三、网络层
1、IP 协议
网络层的 IP 协议主要负责:
- 地址管理:用 IP 地址描述网络上各个设备的的位置。
- 路由选择:挑选出合适的传输路径。
IP 协议报文结构:
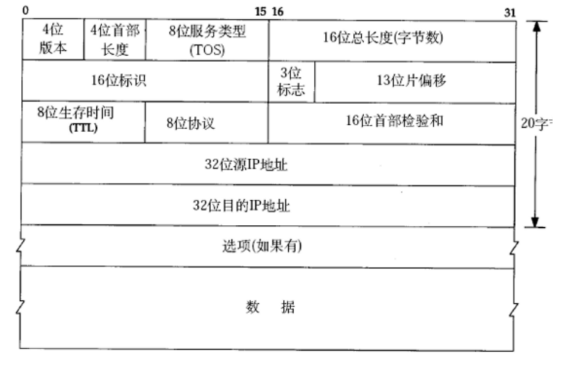
- 4 位版本:ipv4、ipv6。可能还有其他版本,但是没有推广使用。
- 4 位首部长度:IP 协议中,报头变长(可能有选项)。0~15,每个数表示 4 字节,可表示 60 字节。选项最大占 40 字节。
- 8 位服务类型 :其中 4 位无效 (3 位优先权字段已弃用,1 位保留字段必须置为 0 不用管)。剩余 4 位表示4 种状态 ,不可同时存在,只能选一个。分别表示:最小延时 (发送、接收数据的时间尽量短)、最大吞吐量 (单位时间内可传输的数据尽量多)、最高可靠性 (在 IP 层面尽量避开繁忙的节点,减小丢包的概率)、最小成本(消耗的系统资源最少)。但是实际开发中不会设置。
- 16 位总长度 :IP 报头+载荷 ,最大表示 64 KB。当数据总长度超过 64 KB,IP 协议支持拆包/组包。过程如下:
将整个 IP 数据包分成几部分,放到几个 IP 数据包的载荷中:
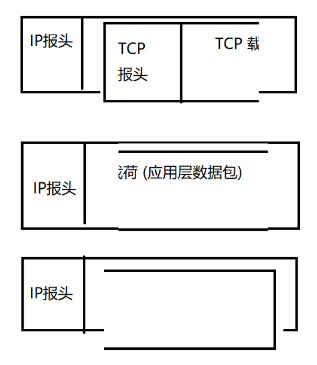
用到以下字段:

- 16 位标识:这几个 IP 数据包的 16 位标识相同,表示拆自同一个 IP 数据包。
- 3 位标志 :一位不用;一位表示是否触发了拆包 ;一位表示该 IP 数据包是否是最后一个数据包(类似于链表中的空引用)。
- 13 位片偏移 :描述每个数据包的相对顺序。(有可能会发生先发后至的情况)
- 8 位生存时间:该 IP 数据包最多能在网络上经过几个路由器转发。每经过一次,TTL-1。当 TTL 为 0,则表示无法到达,丢弃。TTL 的默认值一般是 32/64/128。例如:初始 TTL 为 64,经过 64 - 46 = 18 次路由器转发到达搜狗。
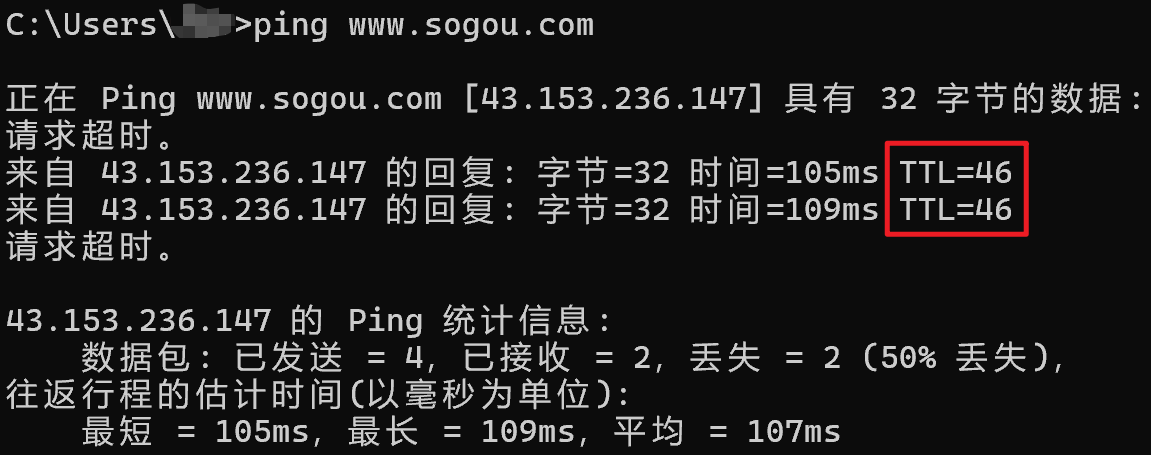
追踪中间的转发节点有哪些:
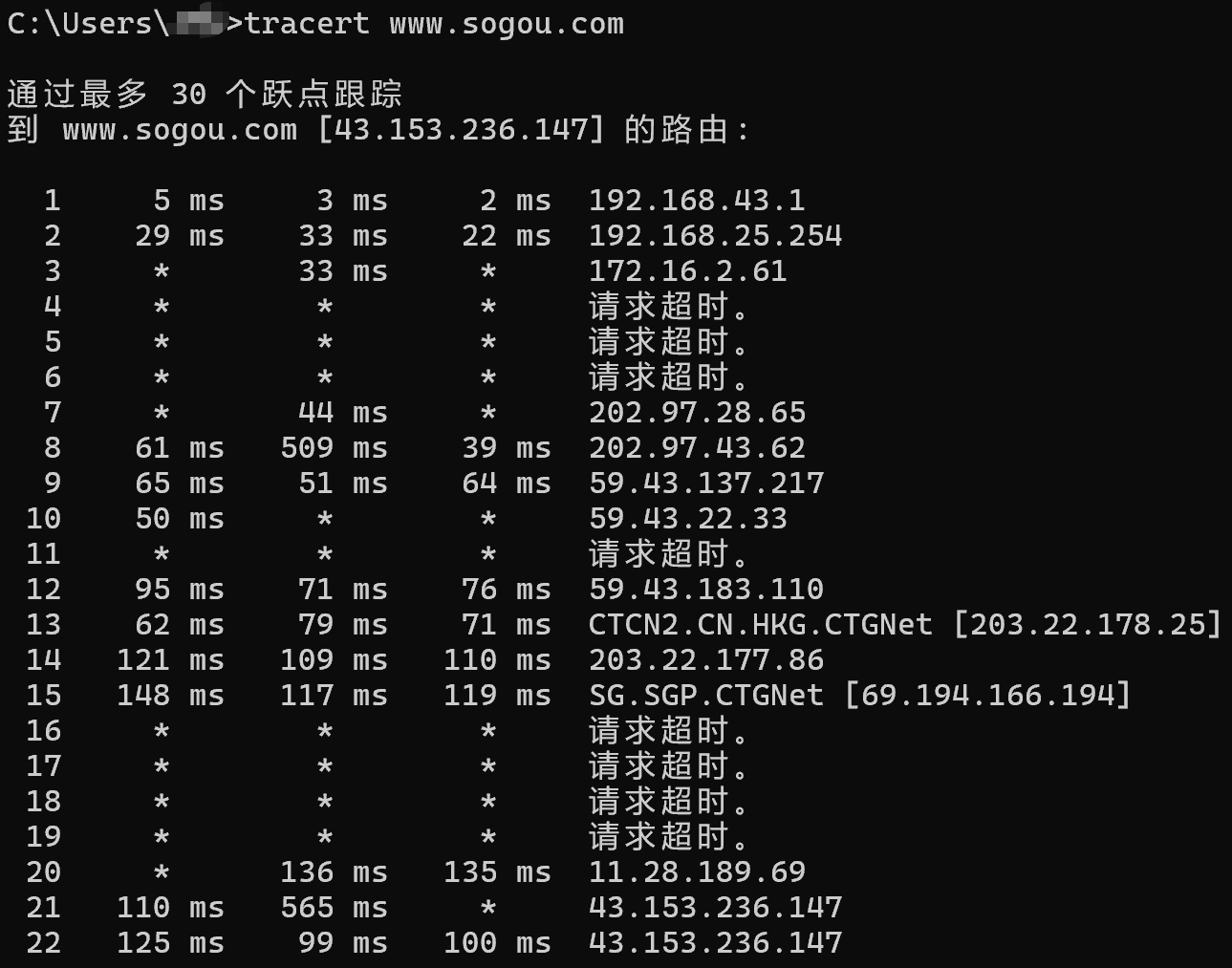
为什么要设置 TTL 生存时间:IP 数据包的转发必要目的 IP,若 目的 IP 错误,或者目的 IP 对应的主机突然下线,数据包就会在网络中无限转发。
- 8 位协议:表示协议类型,用于区分网络层的载荷交给传输层的哪个协议来处理(UDP/TCP)。 PS:对于传输层的载荷,用 "目的端口" 来区分交给应用层的哪个应用程序来处理。
- 16 位首部校验和:网络层只校验首部。载荷部分的传输层数据由传输层的 UDP/TCP 校验。
- 32 位源/目的 IP 地址:用于标识源/目的设备的位置。
2、地址管理
2.1、IPv4 地址资源有限
下图是 IPv4 地址的点分十进制表示(便于人识别),每个部分占一个字节,取值 0~255。

但是计算机直接识别 32 位 0/1 组成的整数,可表示 0 ~ 2^32-1(42亿多),在以前这是足够的,但在移动互联网时代,每个人都有一部或多部手机,IPv4 地址已经不够用了。
2.2、解决方案
- 动态分配 IP 地址:上网的主机才分配地址,不上网的主机就不分配。在早期可行,后续 IP 地址资源进一步紧张,单纯使用这个方案,不可行。
- NAT 机制(网络地址映射):不再是每个设备都有一个唯一的 IP 地址,而是允许不同局域网内有相同的 IP 地址。
- 升级为 IPv6 地址:NAT 只是提升了 IP 地址的利用效率,但没有从根本上解决问题。IPv4 使用 4 个字节表示 IP 地址;IPv6 使用 16 个字节表示 IPv6 地址。相当于 42 亿的四次方的 IP 地址范围,可让地球上的每一粒沙子分配一个 IP 地址(电子设备的核心元素"硅"是从沙子中提取出来的)。
IPv6 在全球的普及度低(IPv4 和 IPv6 不兼容,需要更换路由器设备,成本太高),但在中国普及度达 80% 多。中国不计成本,让三大运营商升级路由器、让各大互联网公司升级应用支持 IPv6 协议,这样做的原因是为了把 "互联网土地资源" 分配的权力掌握在自己手上(IPv4 协议体系由美国制定,且控制权大。美国与伊拉克的战争中,曾让伊拉克全国断网 3 年,让伊拉克消失在互联网中)。可观看纪录片了解更详细的历史:电子监听、全国断网,棱镜门背后,中国如何从末路狂奔到世界之巅_哔哩哔哩_bilibili
虽然在中国 IPv6 的使用率仍然很低,但是我们已经做好了设施准备,就算未来某时被某国以控制 IPv4 的使用作为威胁,也不再害怕。
2.3、NAT (网络地址转换)
2.3.1、IP 地址分类
所有的 IP 地址分为两大类:
- 内网/私网 IP:在同一个局域网内唯一。
以三种格式开头:
a) 10.*
b) 172.16-172.31.*
c) 192.168.* (家用路由器常见格式)
- 外网/公网 IP:在整个网络上唯一。以其余格式开头的 IP 地址。
2.3.2、网络转发情况
现有 A、B 两设备:
a) A、B 在同一局域网中:同一局域网中设备的 IP 地址唯一,直接转发。
b) A、B 在不同局域网中:不可直接相互转发。
c) A 是内网 IP,B 是外网 IP:A 可主动访问 B;B 不可主动访问 A(不同局域网内的 IP 地址可能相同,B 无法辨别是哪个局域网中的 IP),但 A 主动访问过 B 后,B 可以原路返回。
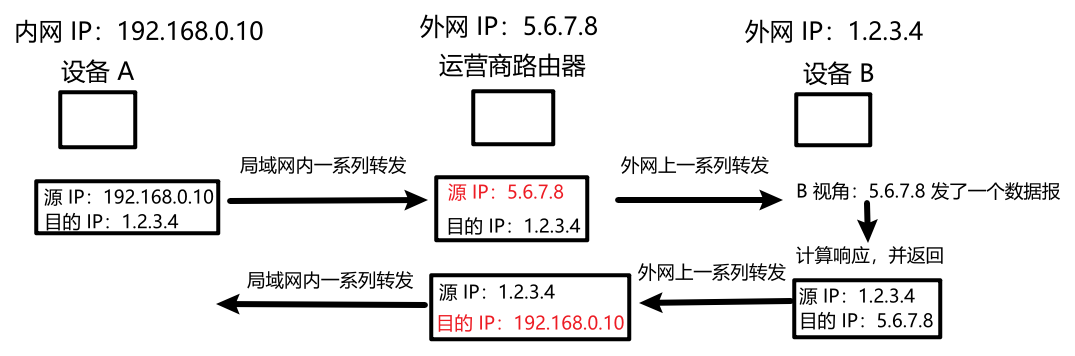
d) A、B 都是外网 IP:可不涉及 NAT 机制,直接转发。
原本一个外网 IP 代表一个设备,现在就是一个外网 IP 代表很多个局域网内的所有设备了。
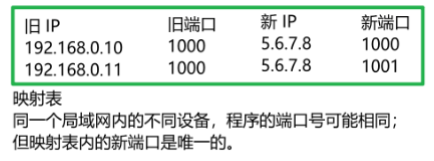
2.3.3、NAPT(网络地址端口转换)
那么在返回请求的路线中,运营商路由器,如何分辨同一个局域网内的不同内网 IP 呢?端口不仅可以区分一台主机上的不同程序,还能区分不同主机上的不同程序。因此引入端口辅助映射 ,区分同一局域网内,不同内网 IP。
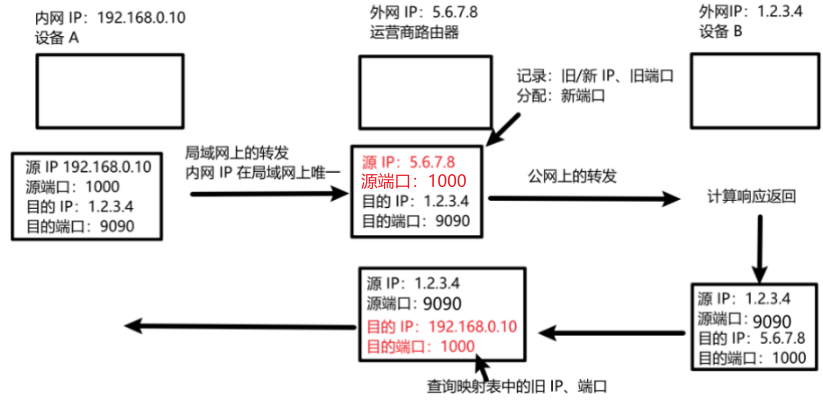
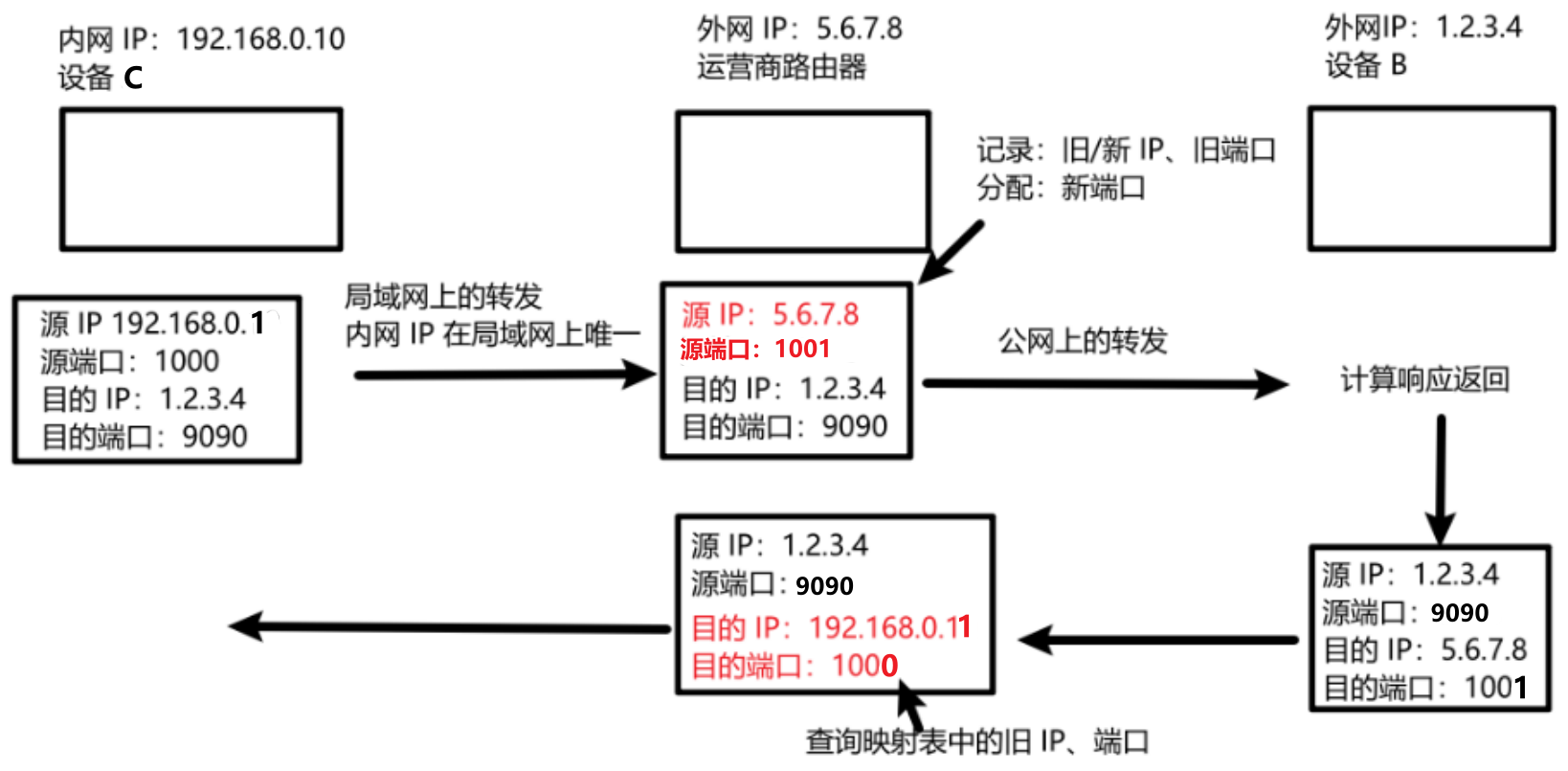
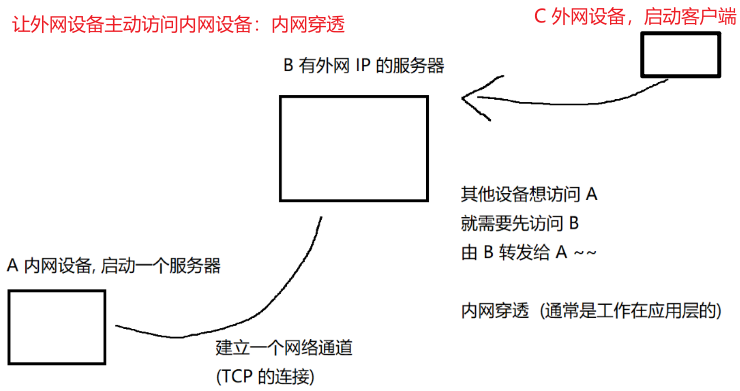
PS:也能实现外网设备主动访问内网设备,那就是内网穿透技术,在应用层实现:
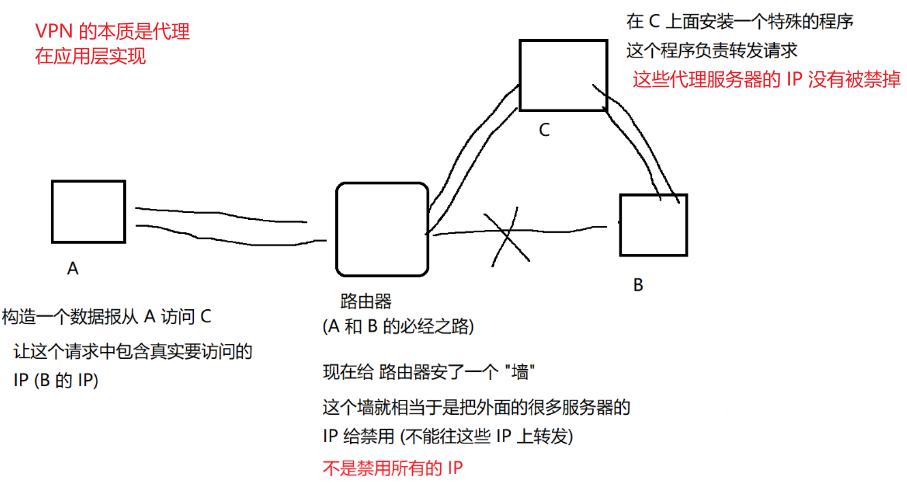
2.3.4、NAT 带来的好处
NAT 机制不仅可以缓解 IP 地址资源紧缺的问题,还能加强普通用户的网络安全性:因为外网设备无法主动访问内网设备,所以我们只要不去主动访问有病毒的网站,就不会被入侵。
2.4、网段划分
一个 IP 地址分为两个部分:网络号和主机号。比如 192.168.2.1,192.168.2 表示网络号,1 表示主机号。
同一个局域网中 ,网络号必须相同,主机号必须不相同 ;相邻的局域网 (由路由器连接),网络号必须不同。如果不满足以上要求,则无法正常上网。家用路由器的 LAN 口 IP 习惯上设置主机号为 1;路由器会为接入 LAN 口的设备自动分配主机号(DHCP 功能,基于 UDP 应用层协议)。光猫也是路由器,只不过有一个口插光纤,它可以转换光信号和电信号。下图是我家网路的简单示意图:
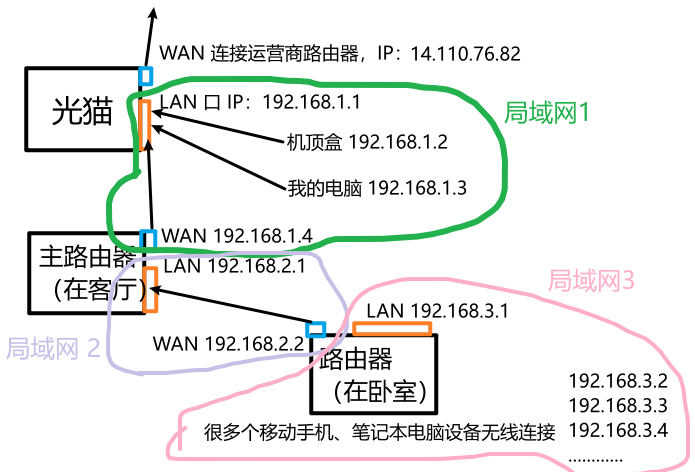


家用路由器的 IP,通常是前 3 个字节属于网络号,但企业/学校/组织机构的路由器就不一定是这种格式了。那么网段划分的通用方法 是什么?子网掩码 :使用 ipconfig 查看主机的网络信息,每一组对应一个网络接口(网卡/虚拟网卡,又分为有线/无线网卡)。将子网掩码转为二进制,左边都是 1,右边都是 0,1 对应的 IP 部分就是网络号 。家用路由器的子网掩码一般是 255.255.255.0,因为家庭的设备比较少,主机号范围 0~ 255 足够用了;如果是企业级的设备很多,就需要减少左边 1 的个数了。 默认网关就是我的电脑连接的路由器的 LAN IP 地址(网络的出入口)。

2.5、三种特殊的 IP 地址
- 网络地址(主机号全0):表示网段本身,不能分配给任何设备。形如:192.168.1.0。
- 广播地址(主机号全1):发送到这个地址的数据包将转发给该网络中的所有设备。形如:192.168.255。广播地址由网络层的 IP 协议所支持,只能基于 UDP 协议使用(UDP 是无连接的,TCP 是有连接的,发送方需与该局域网内的所有设备建立连接才可实现,显然困难得多)。广播地址,要区别于微信群聊,群聊是在应用层写程序实现,可以基于 UDP/TCP(把消息发送给服务器,服务器获取成员列表循环依次转发给成员)。应用场景:手机投屏。手机不知道电视的 IP,但可以将数据包转发给广播地址,广播地址转发给局域网内所有设备,安装了投屏软件的设备就会做出响应,如电视。然后电视做出响应,告知手机我的 IP 地址。最后手机就将要播放的视频地址发送给手机 IP。
- 回环地址(127.*):通过该地址发送的数据,能通过该地址接收。通常使用 127.0.0.1,在 Windows 系统中的别名为 localhost。
2.6、固定的划分方式
子网掩码是现代的网络划分方式,在教科书上还有一种过时的固定划分方式,他将网络划分分为 5 类(需要简单记忆):
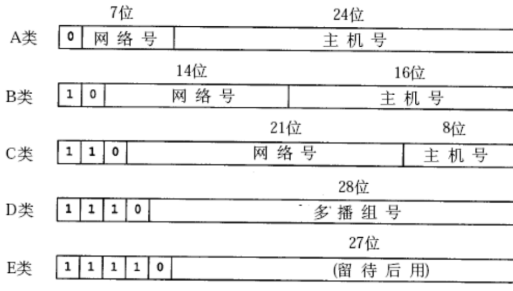
A、B 类的主机号范围都很大,现实世界的局域网用不了这么多设备,IP 地址浪费严重。
3、路由选择
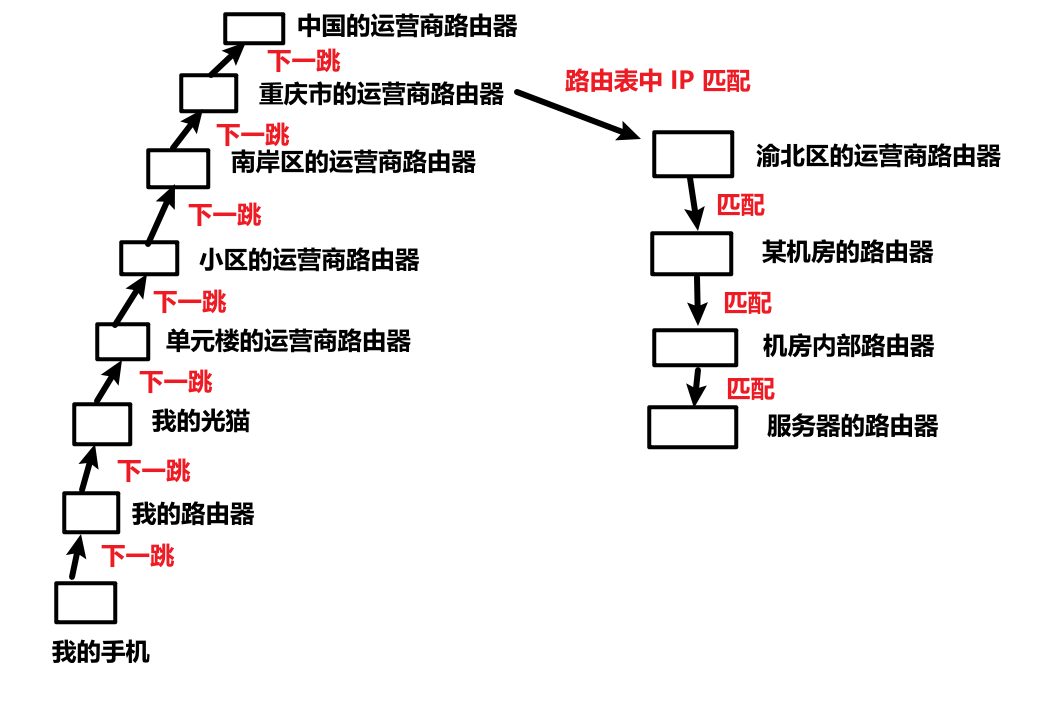
路由选择就是从起点到终点,规划一条合适的路径 。路由器无法获得整个网络的全局信息,只能获得相邻设备的情况 ,因此路由器的路由选择是探索式的:每个路由器都会维护一个"路由表 ",是目的 IP 网络号、网络接口(WAN/LAN)的映射关系表 ,将目的 IP 发送给该路由器,它就会在路由表里查询是否包含目的 IP。如果包含,则直接转发给 WAN/LAN;如果不包含,就转发给默认的路径,即下一跳(next hop)对应的设备,通常是更高一级的路由器。下面举一个例子,从我家发送数据到目的 IP 是重庆市渝北区某个服务器的 IP:
四、数据链路层
负责相邻两个节点间的数据传输。常见协议:
- 以太网(IEEE 802.3):通过网线/光纤传输。
- Wifi(IEEE 802.11):通过无线信号传输。
1、以太网帧格式

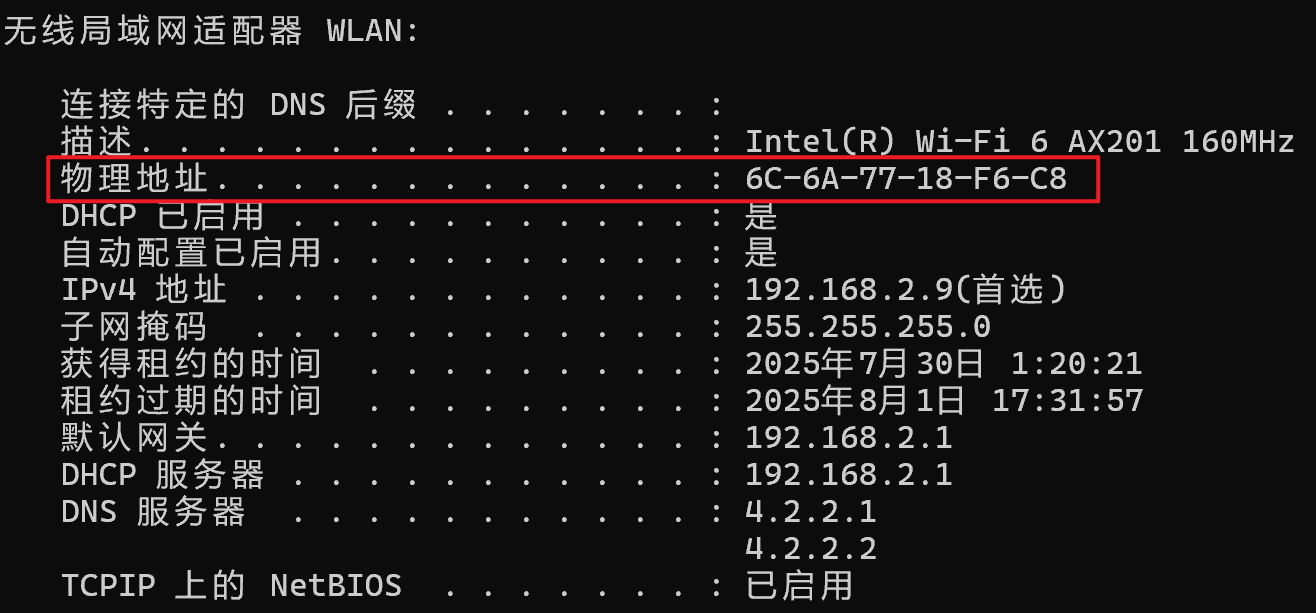
- 目的/源地址 :指的 mac/物理地址,有 6 个字节,范围比 IPv6 小但比 IPv4 大很多,可以唯一标识设备,在出厂时写死在网卡中,有些软件绑定设备就是用的 mac 地址。使用 ipconfig /all 查询网络的所有信息:
网络层的 IP 地址用于路线规划(描述整个路程起点、终点),数据传输层的 mac 地址用于具体执行(描述每个子区间的起点、终点):

- **类型:**载荷交给哪个协议处理。有三种值,以十六进制表示:IP、ARP、RARP。
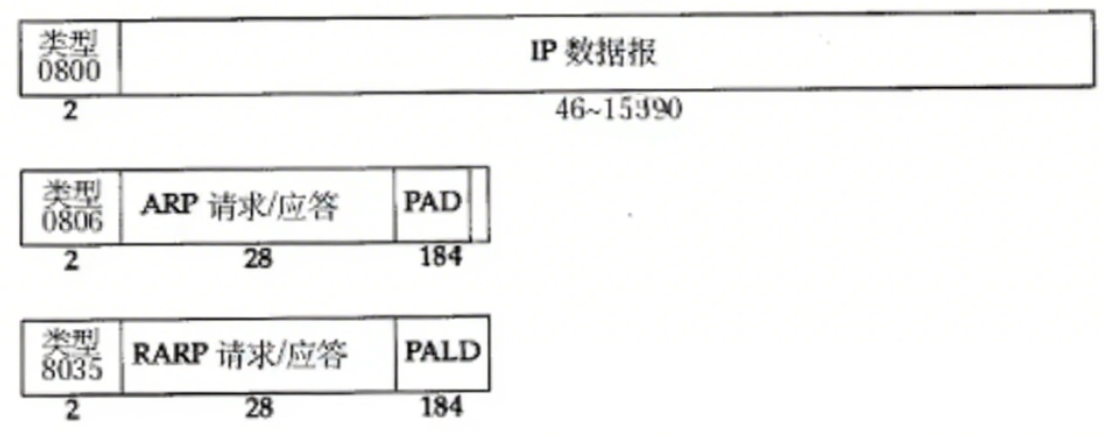
ARP 协议报文 :A 向 B 转发数据,不仅要知道 B 的 IP,还要知道 B 的 mac。在网络层,路由器需要构建路由表,存储目的 IP 和 WAN/LAN 接口的映射关系。在数据链路层,交换机需要构建转发表 ,存储目的 mac 和具体网络端口的映射关系 。ARP 协议报文协助构建转发表 ,可根据 IP 地址获取对应设备的 mac 地址:因为局域网中的网络设备随时可能下线、上限,因此 ARP 报文会周期性触发进行更新,ARP 广播给局域网中所有设备,请求每个设备的 mac 地址,它们收到 ARP 请求后进行响应,包含自己的 mac 地址。
- **数据:**最大字节 1500 只针对以太网,取决于硬件结构,其他协议上限可能不同。这个上限称为最大传输单元(MTU)。1500 字节是一个非常小的值,相当于 1KB 多点,因此 IP 数据包的载荷用不了 64 KB,它的长度在数据链路层就已经限制了,需要拆包。
- **CRC:**一种校验和算法。
五、DNS
全称域名解析系统 ,为应用层协议提供域名解析支持。一个域名对应一个 IP 地址,因为IP 地址不好记,就用具有实际意义的单词来代替。

使用 DNS 的另一个好处:更换机器(IP 地址),只需要更新 DNS 系统中的域名和 IP 地址的映射关系即可,对用户来说没有变化。
早期的 DNS 系统 ,通过 hosts 文件表示,但随着网站数目变多,手动更新 hosts 文件频繁(网站上线/消亡),就非常麻烦了。
C:\Windows\System32\drivers\etc\hosts:一般都是空的,#是注释。
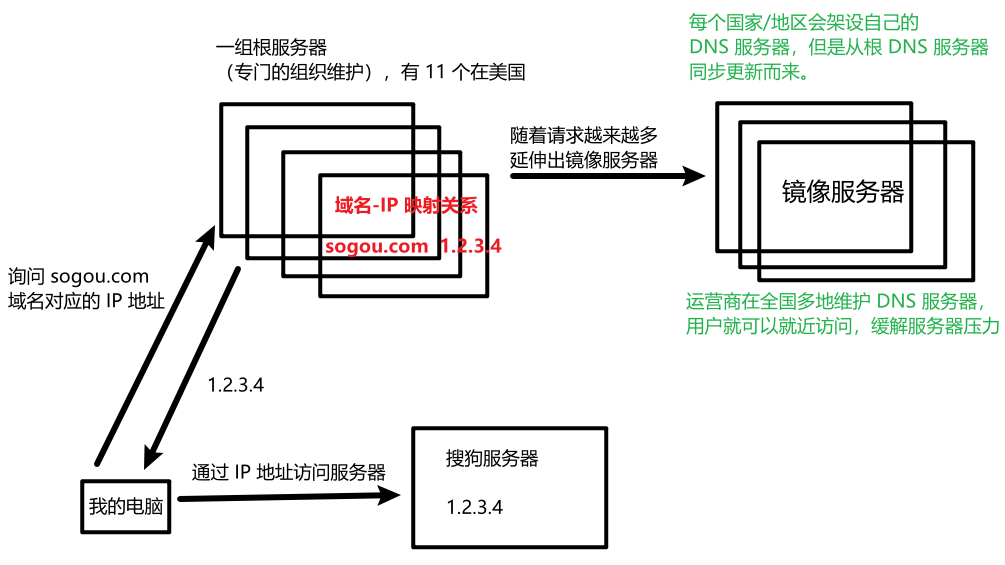
现在的 DNS 系统 通过一组 DNS 服务器完成域名解析,但随着全世界的请求越来越多,开始寻求其它缓解方法:
- 缓存域名解析结果,大幅降低访问 DNS 服务器的频率:当首次访问域名,会向 DNS 服务器查询 IP 地址,然后操作系统、浏览器会保存该映射关系。在缓存未过期的一段时间内,再次访问同样的域名,就可以在缓存中直接获取 IP 地址。
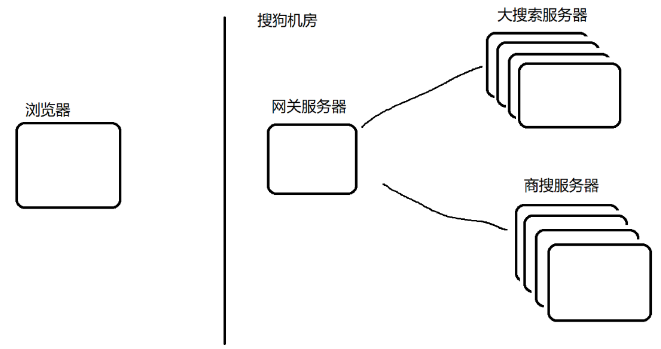
- 分布式系统,引入更多的硬件资源:
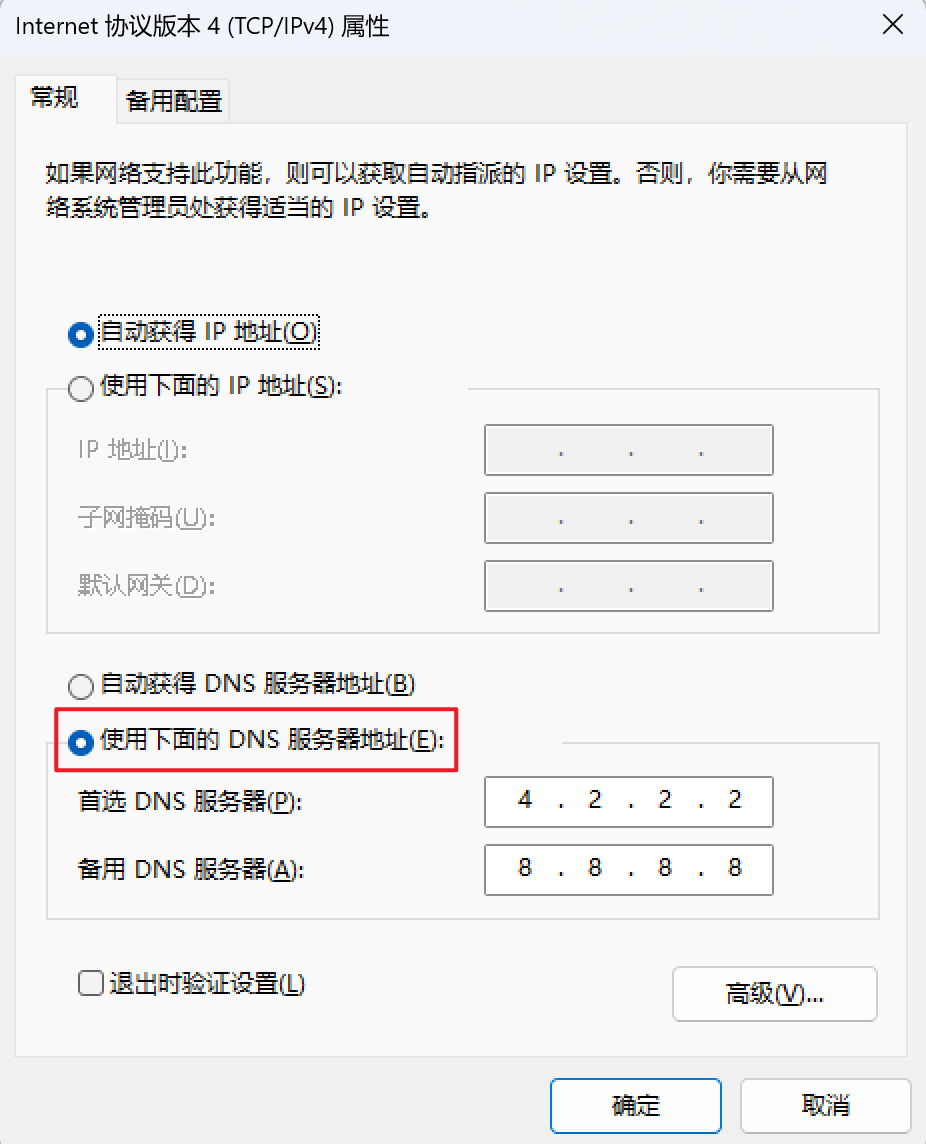
当浏览器打不开网站时,大概率是 DNS 服务器挂了,那么就可以在电脑上配置,更换 DNS 服务器 IP 地址(可以用谷歌的 DNS 服务器 8.8.8.8):
查看网络连接-》WLAN-》右键属性-》双击 Internet 协议版本 4(TCP/IPv4)-》将自动改为自己设置: