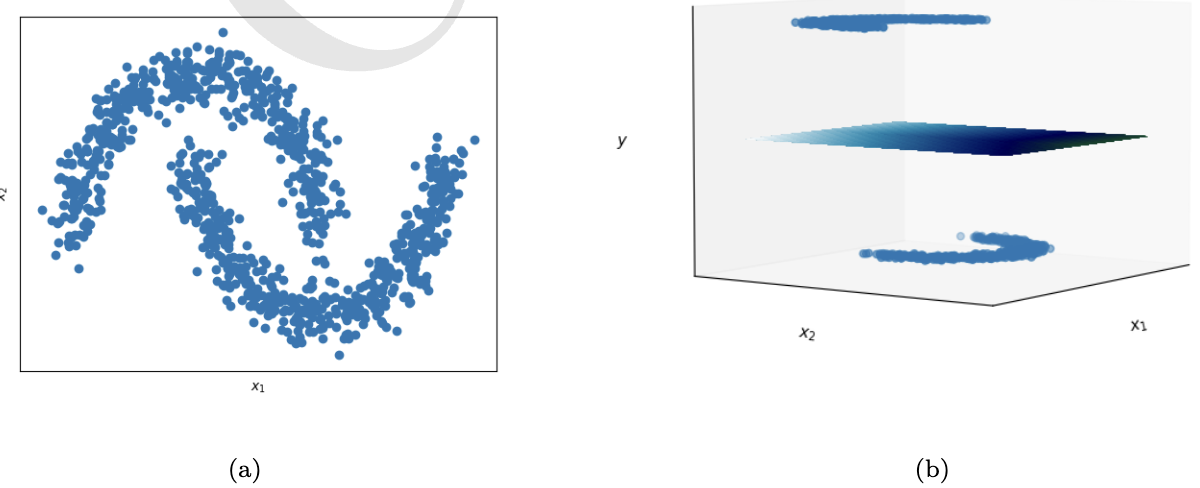
更多的2-分类问题 { ( x i , y i ) } \{(\boldsymbol{x}_i,y_i)\} {(xi,yi)}, x i ∈ R n \boldsymbol{x}_i\in\text{R}^n xi∈Rn, y i ∈ { − 1 , 1 } y_i\in\{-1,1\} yi∈{−1,1}, i = 1 , 2 , ⋯ , m i=1,2,\cdots,m i=1,2,⋯,m不是线性可分的,即不存在超平面将 { x i ∣ i = 1 , 2 , ⋯ , m } \{\boldsymbol{x}_i|i=1,2,\cdots,m\} {xi∣i=1,2,⋯,m}按对应 y i y_i yi的不同取值而分隔开(如下图(a))。解决这类问题的方法是进行坐标变换,将样本特征数据 { x i } \{\boldsymbol{x}_i\} {xi}通过合适的映射 ϕ : R n → R n ′ \boldsymbol{\phi}:\text{R}^n\rightarrow\text{R}^{n'} ϕ:Rn→Rn′( n ′ ≥ n n'\geq n n′≥n),在一个维度更高的空间内将问题转换为线性可分问题(如下图(b))。
即求解有约束优化问题
{ min 1 2 w ⊤ H w + c ⊤ ϕ ( z ) s.t. y i ( ϕ ( x i ) ⊤ , 1 ) w ≥ 1 − ϕ ( z i ) ϕ ( z ) ≥ o i = 1 , 2 , ⋯ m ( 1 ) \begin{cases} \min\quad \frac{1}{2}\boldsymbol{w}^\top\boldsymbol{Hw}+\boldsymbol{c}^\top\phi(\boldsymbol{z})\\ \text{s.t.\ }\quad y_i(\phi(\boldsymbol{x}_i)^\top,1)\boldsymbol{w}\geq1-\phi(z_i)\\ \quad\quad\ \ \phi(\boldsymbol{z})\geq\boldsymbol{o} \end{cases}\quad i=1,2,\cdots m\quad(1) ⎩ ⎨ ⎧min21w⊤Hw+c⊤ϕ(z)s.t. yi(ϕ(xi)⊤,1)w≥1−ϕ(zi) ϕ(z)≥oi=1,2,⋯m(1)
的对偶问题
{ min 1 2 μ ⊤ Q ′ μ − μ ⊤ 1 s.t. μ ⊤ y = 0 o ≤ μ ≤ c ( 2 ) \begin{cases} \min\quad\frac{1}{2}\boldsymbol{\mu}^\top\boldsymbol{Q'\mu}-\boldsymbol{\mu}^\top\boldsymbol{1}\\ \text{s.t.\ \ }\quad\boldsymbol{\mu}^\top\boldsymbol{y}=0\\ \quad\quad\ \ \ \boldsymbol{o}\leq\boldsymbol{\mu}\leq\boldsymbol{c} \end{cases}\quad(2) ⎩ ⎨ ⎧min21μ⊤Q′μ−μ⊤1s.t. μ⊤y=0 o≤μ≤c(2)
其中
Q ′ = ( y 1 y 1 ϕ ( x 1 ) ⊤ ϕ ( x 1 ) y 1 y 2 ϕ ( x 1 ) ⊤ ϕ ( x 2 ) ⋯ y 1 y m ϕ ( x 1 ) ⊤ ϕ ( x m ) y 2 y 1 ϕ ( x 2 ) ⊤ ϕ ( x 1 ) y 2 y 2 ϕ ( x 2 ) ⊤ ϕ ( x 2 ) ⋯ y 2 y m ϕ ( x 2 ) ⊤ ϕ ( x m ) ⋮ ⋮ ⋱ ⋮ y m y 1 ϕ ( x m ) ⊤ ϕ ( x 1 ) y m y 2 ϕ ( x m ) ⊤ ϕ ( x 2 ) ⋯ y m y m ϕ ( x m ) ⊤ ϕ ( x m ) ) \boldsymbol{Q}'=\begin{pmatrix}y_1y_1\boldsymbol{\phi}(\boldsymbol{x}_1)^\top\boldsymbol{\phi}(\boldsymbol{x}_1)&y_1y_2\boldsymbol{\phi}(\boldsymbol{x}_1)^\top\boldsymbol{\phi}(\boldsymbol{x}_2)&\cdots&y_1y_m\boldsymbol{\phi}(\boldsymbol{x}_1)^\top\boldsymbol{\phi}(\boldsymbol{x}_m)\\y_2y_1\boldsymbol{\phi}(\boldsymbol{x}_2)^\top\boldsymbol{\phi}(\boldsymbol{x}_1)&y_2y_2\boldsymbol{\phi}(\boldsymbol{x}_2)^\top\boldsymbol{\phi}(\boldsymbol{x}_2)&\cdots&y_2y_m\boldsymbol{\phi}(\boldsymbol{x}_2)^\top\boldsymbol{\phi}(\boldsymbol{x}_m)\\\vdots&\vdots&\ddots&\vdots\\y_my_1\boldsymbol{\phi}(\boldsymbol{x}_m)^\top\boldsymbol{\phi}(\boldsymbol{x}_1)&y_my_2\boldsymbol{\phi}(\boldsymbol{x}_m)^\top\boldsymbol{\phi}(\boldsymbol{x}_2)&\cdots&y_my_m\boldsymbol{\phi}(\boldsymbol{x}_m)^\top\boldsymbol{\phi}(\boldsymbol{x}_m)\end{pmatrix} Q′= y1y1ϕ(x1)⊤ϕ(x1)y2y1ϕ(x2)⊤ϕ(x1)⋮ymy1ϕ(xm)⊤ϕ(x1)y1y2ϕ(x1)⊤ϕ(x2)y2y2ϕ(x2)⊤ϕ(x2)⋮ymy2ϕ(xm)⊤ϕ(x2)⋯⋯⋱⋯y1ymϕ(x1)⊤ϕ(xm)y2ymϕ(x2)⊤ϕ(xm)⋮ymymϕ(xm)⊤ϕ(xm)
直接寻求映射 ϕ : R n → R n ′ \boldsymbol{\phi}:\text{R}^n\rightarrow\text{R}^{n'} ϕ:Rn→Rn′( n ′ ≥ n n'\geq n n′≥n)并计算矩阵 Q ′ \boldsymbol{Q}' Q′会使计算量爆炸式增长。克服这一困难的方法之一是所谓的"核函数技巧 ":
将 ϕ ( x ) ⊤ ϕ ( y ) \boldsymbol{\phi}(\boldsymbol{x})^\top\boldsymbol{\phi}(\boldsymbol{y}) ϕ(x)⊤ϕ(y)视为函数 κ : R n ′ × R n ′ → R \kappa: \text{R}^{n'}\times\text{R}^{n'}\rightarrow\text{R} κ:Rn′×Rn′→R,则对 { x i ∣ x i ∈ R n , i = 1 , 2 , ⋯ , m } \{\boldsymbol{x}_i|\boldsymbol{x}i\in\text{R}^n,i=1,2,\cdots,m\} {xi∣xi∈Rn,i=1,2,⋯,m}, κ ( x , y ) \kappa(\boldsymbol{x},\boldsymbol{y}) κ(x,y)若矩阵 Q κ = ( κ ( x 1 , x 1 ) κ ( x 1 , x 2 ) ⋯ κ ( x 1 , x m ) κ ( x 2 , x 1 ) κ ( x 2 , x 2 ) ⋯ κ ( x 2 , x m ) ⋮ ⋮ ⋱ ⋮ κ ( x m , x 1 ) κ ( x m , x 2 ) ⋯ κ ( x m , x m ) ) \boldsymbol{Q}{\kappa}=\begin{pmatrix}\kappa(\boldsymbol{x}_1,\boldsymbol{x}_1)&\kappa(\boldsymbol{x}_1,\boldsymbol{x}_2)&\cdots&\kappa(\boldsymbol{x}_1,\boldsymbol{x}_m)\\\kappa(\boldsymbol{x}_2,\boldsymbol{x}_1)&\kappa(\boldsymbol{x}_2,\boldsymbol{x}_2)&\cdots&\kappa(\boldsymbol{x}_2,\boldsymbol{x}_m)\\\vdots&\vdots&\ddots&\vdots\\\kappa(\boldsymbol{x}_m,\boldsymbol{x}_1)&\kappa(\boldsymbol{x}_m,\boldsymbol{x}_2)&\cdots&\kappa(\boldsymbol{x}_m,\boldsymbol{x}_m)\end{pmatrix} Qκ= κ(x1,x1)κ(x2,x1)⋮κ(xm,x1)κ(x1,x2)κ(x2,x2)⋮κ(xm,x2)⋯⋯⋱⋯κ(x1,xm)κ(x2,xm)⋮κ(xm,xm)
半正定,称 κ ( x , y ) \kappa(\boldsymbol{x},\boldsymbol{y}) κ(x,y)为核函数 。事实上向量间的内积 κ ( x , y ) = x ⊤ y \kappa(\boldsymbol{x},\boldsymbol{y})=\boldsymbol{x}^\top\boldsymbol{y} κ(x,y)=x⊤y就是一个核函数,内积的多项式 κ ( x , y ) = ( γ x ⊤ y + 1 ) d \kappa(\boldsymbol{x},\boldsymbol{y})=(\gamma\boldsymbol{x}^\top\boldsymbol{y}+1)^d κ(x,y)=(γx⊤y+1)d, γ > 0 \gamma>0 γ>0, d > 0 d>0 d>0也是一个核函数,径向基函数 κ ( x , y ) = e − γ ∥ x − y ∥ 2 \kappa(\boldsymbol{x},\boldsymbol{y})=e^{-\gamma\lVert\boldsymbol{x}-\boldsymbol{y}\rVert^2} κ(x,y)=e−γ∥x−y∥2( γ > 0 \gamma>0 γ>0)被称为万能核函数。对给定的核函数 κ ( x , y ) \kappa(\boldsymbol{x},\boldsymbol{y}) κ(x,y),使得 κ ( x , y ) = ϕ ( x ) ⊤ ϕ ( y ) \kappa(\boldsymbol{x},\boldsymbol{y})=\phi(\boldsymbol{x})^\top\phi(\boldsymbol{y}) κ(x,y)=ϕ(x)⊤ϕ(y),二次规划(2)中的
Q ′ = ( y 1 y 1 κ ( x 1 , x 1 ) y 1 y 2 κ ( x 1 , x 2 ) ⋯ y 1 y m κ ( x 1 , x m ) y 2 y 1 κ ( x 2 , x 1 ) y 2 y 2 κ ( x 2 , x 2 ) ⋯ y 2 y m κ ( x 1 , x m ) ⋮ ⋮ ⋱ ⋮ y m y 1 κ ( x m , x 1 ) y m y 2 κ ( x m , x 2 ) ⋯ y m y m κ ( x m , x m ) ) , \boldsymbol{Q}'=\begin{pmatrix}y_1y_1\kappa(\boldsymbol{x}_1,\boldsymbol{x}_1)&y_1y_2\kappa(\boldsymbol{x}_1,\boldsymbol{x}_2)&\cdots&y_1y_m\kappa(\boldsymbol{x}_1,\boldsymbol{x}_m)\\y_2y_1\kappa(\boldsymbol{x}_2,\boldsymbol{x}_1)&y_2y_2\kappa(\boldsymbol{x}_2,\boldsymbol{x}_2)&\cdots&y_2y_m\kappa(\boldsymbol{x}_1,\boldsymbol{x}_m)\\\vdots&\vdots&\ddots&\vdots\\y_my_1\kappa(\boldsymbol{x}_m,\boldsymbol{x}_1)&y_my_2\kappa(\boldsymbol{x}_m,\boldsymbol{x}_2)&\cdots&y_my_m\kappa(\boldsymbol{x}_m,\boldsymbol{x}_m)\end{pmatrix}, Q′= y1y1κ(x1,x1)y2y1κ(x2,x1)⋮ymy1κ(xm,x1)y1y2κ(x1,x2)y2y2κ(x2,x2)⋮ymy2κ(xm,x2)⋯⋯⋱⋯y1ymκ(x1,xm)y2ymκ(x1,xm)⋮ymymκ(xm,xm) ,
则(2)为二次规划问题。设其最优解 μ 0 \boldsymbol{\mu}0 μ0,计算支持向量下标集 s = { i ∣ 0 ≤ i ≤ m , 0 < μ 0 i < C } s=\{i|0\leq i\leq m, 0<\mu{0_i}<C\} s={i∣0≤i≤m,0<μ0i<C},记 m s = ∣ s ∣ m_s=|s| ms=∣s∣,可算得参数
b 0 = 1 m s ∑ j ∈ s ( y j − ∑ i ∈ s μ i y i κ ( x i , x j ) ) b_0=\frac{1}{m_s}\sum\limits_{j\in s}\left(y_j-\sum\limits_{i\in s}\mu_iy_i\kappa(\boldsymbol{x}_i,\boldsymbol{x}_j)\right) b0=ms1j∈s∑(yj−i∈s∑μiyiκ(xi,xj))
进而算得决策函数
F ( x ) = ∑ i ∈ s μ 0 i y i κ ( x , x i ) + b 0 F(\boldsymbol{x})=\sum_{i\in s}\mu_{0_i}y_i\kappa(\boldsymbol{x},\boldsymbol{x}_i)+b_0 F(x)=i∈s∑μ0iyiκ(x,xi)+b0
对新的样本特征数据 x \boldsymbol{x} x,分类预测值为
sign ( F ( x ) ) . \text{sign}(F(\boldsymbol{x})). sign(F(x)).
下列代码就以径向基函数为核函数实现先行不可分问题的支持向量机模型。
python
import numpy as np #导入numpy
from scipy.optimize import minimize, LinearConstraint #导入minimize等
rbf = lambda x, y, gamma: np.exp(-gamma * np.linalg.norm(x - y) ** 2) #径向基函数
class SvmClassifier(Classification, SupervisedLearningModel): #支持向量机分类器
def __init__(self, C = 1e+4): #构造函数
self.kernel = rbf
self.C = C
self.tagVal = np.sign
def obj(self, mu): #优化问题目标函数
return 0.5 * (mu @ (self.Q @ mu)) - mu.sum()
def ynormalize(self, y, trained): #标签数据预处理
if not trained:
self.ymin = 0
self.ymax = 1
return (y - self.ymin) / (self.ymax - self.ymin)
def fit(self, X, Y, mu = None): #训练函数
print("训练中...,稍候")
m, n = X.shape
self.scalar = (len(X.shape) == 1)
self.X, self.Y = self.pretreat(X, Y)
if not isinstance(mu, np.ndarray):
if mu == None:
mu = np.random.random(m)
else:
mu = np.array([mu] * m)
sigma2 = X.var() * n
self.gamma = 1.0 / sigma2
Qk = np.array([[self.kernel(self.X[i], self.X[j], self.gamma)
for j in range(m)]
for i in range(m)])
self.Q = np.outer(self.Y, self.Y) * Qk
h = lambda x: self.Y @ x #等式约束函数
g1 = lambda x: identity(x) #不等式约束函数1
g2 = lambda x: self.C - identity(x) #不等式约束函数2
cons = [{'type': 'eq', 'fun': h}, #约束条件列表
{'type': 'ineq', 'fun': g1},
{'type': 'ineq', 'fun': g2}]
res = minimize(self.obj, mu, constraints = cons) #解约束优化问题
self.mu0 = res.x
self.support_ = np.where((self.mu0 > 1e-5) & (self.mu0 < self.C))[0]
self.b0 = (self.Y[self.support_]-(self.mu0[self.support_] * self.Y[self.support_])\
@ Qk[np.ix_(self.support_, self.support_)]).mean()
print("%d次迭代后完成训练。"%res.nit)
def F(self, w= None, X = None): #决策函数
self.K = lambda x: np.array([[self.kernel(x[i], self.X[j], self.gamma)
for j in self.support_]
for i in range(x.shape[0])])
return self.K(X) @ (self.mu0[self.support_] * self.Y[self.support_]) + self.b0程序中,第3行定义径向基函数 r b f ( x , y ) = e − γ ∥ x − y ∥ 2 rbf(\boldsymbol{x},\boldsymbol{y})=e^{-\gamma\lVert\boldsymbol{x}-\boldsymbol{y}\rVert^2} rbf(x,y)=e−γ∥x−y∥2。由于决策函数不再是线性的,故第4~48行定义的支持向量机分类器类SvmClassifier继承了SupervisedLearningModel(见博文《最优化方法Python计算:无约束优化应用------线性回归模型》)和Classification(见博文《最优化方法Python计算:无约束优化应用------线性回归分类器》)的属性与方法。类定义体中
- 第5~8行定义构造函数,C参数表示惩罚系数,缺省值为 1 0 4 10^4 104。kernel表示核函数,第6行设置为rbf。第7行将标签值函数tagVal设置为Numpy的sign函数,以便计算分类预测值。
- 第9~10行定义目标函数obj,返回值为 1 2 μ ⊤ Q ′ μ − μ ⊤ 1 \frac{1}{2}\boldsymbol{\mu}^\top\boldsymbol{Q}'\boldsymbol{\mu}-\boldsymbol{\mu}^\top\boldsymbol{1} 21μ⊤Q′μ−μ⊤1,即问题(2)的目标函数。
- 第11~15行重载标签数据归一化函数ynormalize。由于支持向量机模型中的标签数据不需要归一化,所以在训练时将self.ymin和self.ymax设置为0和1。第13行返回归一化后的标签数据。做了这样的调整,我们在进行预测操作时,式
y = y ⋅ ( max y − min y ) + min y y=y\cdot(\max y-\min y)+\min y y=y⋅(maxy−miny)+miny
仍保持 y y y的值不变,进而可保持SupervisedLearningModel的predict函数代码不变(见博文《最优化方法Python计算:无约束优化应用------线性回归模型》)。 - 第16~43行重载训练函数fit。对比程序4.1中定义的父类fit函数可见第17~25行的代码是保持一致的(仅将模型参数w改为mu)。
- 第26~27行计算样本特征数据X的方差 σ 2 \sigma^2 σ2,并将 γ \gamma γ参数设置为 1 n σ 2 \frac{1}{n\sigma^2} nσ21。其中,n为每个样本的特征个数。
- 第28~30行计算核矩阵 Q κ \boldsymbol{Q}_\kappa Qκ。
- 第31行计算问题(2)的目标函数系数矩阵 Q ′ \boldsymbol{Q}' Q′。
- 第32~34行分别定义问题(2)的等式约束条件 h ( μ ) = y ⊤ μ = o \boldsymbol{h}(\boldsymbol{\mu})=\boldsymbol{y}^\top\boldsymbol{\mu}=\boldsymbol{o} h(μ)=y⊤μ=o中的函数 h ( x ) \boldsymbol{h}(\boldsymbol{x}) h(x);不等式约束函数 g 1 ( μ ) = μ ≥ o \boldsymbol{g}_1(\boldsymbol{\mu})=\boldsymbol{\mu}\geq\boldsymbol{o} g1(μ)=μ≥o中的函数 g 1 ( x ) \boldsymbol{g}_1(\boldsymbol{x}) g1(x);不等式约束函数 g 2 ( μ ) = c − μ ≥ o \boldsymbol{g}_2(\boldsymbol{\mu})=\boldsymbol{c}-\boldsymbol{\mu}\geq\boldsymbol{o} g2(μ)=c−μ≥o中的函数 g 2 ( x ) \boldsymbol{g}_2(\boldsymbol{x}) g2(x)。注意, h ( x ) \boldsymbol{h}(\boldsymbol{x}) h(x)、 g 1 ( x ) \boldsymbol{g}_1(\boldsymbol{x}) g1(x)和 g 2 ( x ) \boldsymbol{g}_2(\boldsymbol{x}) g2(x)均为向量函数。
- 第35~37行定义问题(2)的约束条件列表cons。
- 第38行调用minimize函数求解优化问题(2),返回值赋予res。第39行将res的x属性赋予mu0。
- 第40行按条件 0 < μ 0 i < C 0<\mu_{0_i}<C 0<μ0i<C计算支持向量下标集support_。
- 第41~42行按式
b 0 = 1 m s ∑ j ∈ s ( y j − ∑ i ∈ s μ i y i κ ( x i , x j ) ) b_0=\frac{1}{m_s}\sum\limits_{j\in s}\left(y_j-\sum\limits_{i\in s}\mu_iy_i\kappa(\boldsymbol{x}_i,\boldsymbol{x}_j)\right) b0=ms1j∈s∑(yj−i∈s∑μiyiκ(xi,xj))
计算参数 b 0 b_0 b0。
- 第44~48行定义决策函数F。该函数的参数w和X分别表示权重向量和样本特征数据。由于支持向量机模型中不需要权重向量,所以该参数w没有实际意义。第45~47行定义辅助函数K(x),第48行利用K(x)按式
∑ i ∈ s μ 0 i y i κ ( x , x i ) + b 0 \sum_{i\in s}\mu_{0_i}y_i\kappa(\boldsymbol{x},\boldsymbol{x}_i)+b_0 i∈s∑μ0iyiκ(x,xi)+b0
计算决策函数F(X)的值。
例1 文件make_moons.csv(需要者可私信)包含了1000个3维空间的点,
| X | Y | label |
|---|---|---|
| -1.129064193 | -0.049046872 | 0 |
| ... | ... | ... |
| 1.275997495 | -0.424925687 | 1 |
| ... | ... | ... |
| -0.360415936 | 1.014813199 | 0 |
这些点投影到XY平面的图形如上图(a)所示。标签label取值0/1,用支持向量机训练分类器,需要将取值转换为-1/1。下列代码用该数据集中的66个训练一个SvmClassifier类对象,并用剩余数据对其进行测试。
python
import numpy as np #导入numpy
data = np.loadtxt('make_moons.csv', delimiter=',',
dtype = object, skiprows = 1) #读取数据文件
X = np.array(data).astype(float) #转换为数组
Y = np.array([-1.0 if y == 0 else 1.0 for y in X[:,2]]) #标签数据
X = np.delete(X, [2], axis = 1)
m = X.shape[0] #样本数
print('共有%d个数据样本'%m)
a = np.arange(m)
np.random.seed(1052) #随机种子
print('用%d个样本数据训练模型'%(m // 15))
train = np.random.choice(a, m // 15, replace = False) #训练数据下标
test = np.setdiff1d(a, train) #测试数据下标
moons = SvmClassifier() #构造模型
moons.fit(X[train], Y[train]) #训练模型
print('支持向量:%s'%moons.support_)
acc=moons.score(X[test], Y[test]) #测试模型
print('用其余%d个样本测试模型,正确率为%.2f'%(m - m // 15, acc * 100)+ '%')程序的第2~6行从文件中读取数据并转换为数组X,并从中拆分出标签数据Y。第7行读取样本数m。第12行随机选取m//15个样本作为训练数据集Xtrain、Ytrain,其余样本作为测试数据集Xtest、Ytest。第14行声明SvmClassifier类对象moons,作为支持向量机分类模型。注意,罚项系数C使用缺省值 1 0 4 10^4 104。第15行调用moons的fit函数用Xtrain、Ytrain对其进行训练。第16行输出支持向量下标集support_。第17行调用moons的score函数用Xtest、Ytest对其进行测试。运行程序,输出
python
共有1000个数据样本
用66个样本数据训练模型
训练中...,稍候
100次迭代后完成训练。
支持向量:[ 2 6 8 16 25 26 27 29 32 34 37 46 53 55 59 62]
用其余934个样本测试模型,正确率为100.00%训练所得模型测试效果不错!
例2 下列代码用井字棋数据文件tic-tac-toe.csv(数据集结构见博文《最优化方法Python计算:有约束优化应用------近似线性可分问题支持向量机》)的数据训练并测试由SvmClassifier实现的支持向量机分类模型,罚项系数C设置为 1 0 4 10^4 104。
python
import numpy as np #导入numpy
data = np.loadtxt('tic-tac-toe.csv', delimiter = ',', dtype = object) #读取数据文件
X = np.array(data) #转换为数组
Y = X[:, 9] #读取标签数据
X = np.delete(X, [9], axis = 1) #去掉标签列
m, n=X.shape
print('共有%d个数据样本'%m)
for i in range(m): #特征数据数值化
for j in range(n):
if X[i, j] == 'x':
X[i, j] = 1
if X[i, j] == 'o':
X[i, j] = -1
if X[i, j] == 'b':
X[i, j] = 0
X=X.astype(float)
Y = np.array([1 if y == 'positive' else #类别数值化
-1 for y in Y]).astype(int)
a = np.arange(m) #数据项下标
m1=100
np.random.seed(1264) #随机种子
print('随机抽取%d个样本作为训练数据。'%(m1))
train=np.random.choice(a,m1,replace=False) #训练数据下标
test = np.setdiff1d(a,train) #测试数据下标
tictactoe = SvmClassifier(C = 100.0) #创建模型
tictactoe.fit(X[train],Y[train]) #训练模型
print('支持向量:%s'%tictactoe.support_)
acc=tictactoe.score(X[test], Y[test]) * 100 #测试模型
print('对其余%d个样本数据测试,正确率:%.2f'%(m-m1,acc)+'%')程序的第2~18行从文件中读取数据并转换为数组X,并从中拆分出标签数据Y。第19~24行在数据集中随机选取100个作为训练用数据Xtrain,Ytrain,其余的作为测试用数据Xtest,Ytest。第25行声明SvmClassifier类对象tictactoc,创建核函数为rbf,正则化参数为 1 0 2 10^2 102的支持向量机模型。第26行训练该模型,第28行测试模型。运行程序,输出
python
共有958个数据样本
随机抽取100个样本作为训练数据。
训练中...,稍候
100次迭代后完成训练。
支持向量:[ 1 2 3 5 7 9 10 11 14 15 16 17 18 19 20 22 23 24 25 26 29 31 33 34
35 37 40 43 46 47 48 49 50 51 52 55 58 60 61 62 67 69 70 72 76 78 82 83
86 89 90 93 94 95 96 98 99]
对其余858个样本数据测试,正确率:99.30%与博文《最优化方法Python计算:有约束优化应用------近似线性可分问题支持向量机》中同一问题的计算结果比较,可见对此问题SvmClassifier类模型优于ALineSvc类模型。
写博不易,敬请支持:
如果阅读本文于您有所获,敬请点赞、评论、收藏,谢谢大家的支持!