一、Kafka安装与配置
步骤:
1、使用XFTP将Kafka安装包kafka_2.12-2.8.1.tgz发送到master机器的主目录。
2、解压安装包:
tar -zxvf ~/kafka_2.12-2.8.1.tgz3、修改文件夹的名字,将其改为kafka,或者创建软连接也可:
mv ~/kafka_2.12-2.8.1 ~/kafka4、修改配置文件,Kafka包含生产者、消费者、ZooKeeper、Kafka集群节点等四个角色,因此需要修改对应的4个配置文件即可。Kafka的配置文件夹在解压文件夹里面的config文件夹内,先执行以下命令进入到对应的目录:
cd ~/kafka/config(1)修改zookeeper.properties配置文件:
# 指定ZooKeeper的数据目录
dataDir=/home/hadoop/zkdata
# 指定ZooKeeper的端口(这个应该不用改)
clientPort=2181(2)修改consumer.properties配置文件:
# 配置Kafka集群地址
bootstrap.servers=master:9092,slave1:9092,slave2:9092(3)修改producer.properties配置文件:
# 配置Kafka集群地址
bootstrap.servers=master:9092,slave1:9092,slave2:9092(4)修改server.properties配置文件(找到对应的参数修改):
# 指定ZooKeeper集群
zookeeper.connect=master:2181,slave1:2181,slave2:2181上述内容修改完毕后保存。
5、将上面配置修改好后的Kafka安装文件夹使用scp命令分发给slave1、slave2两个节点:
scp -r ~/kafka hadoop@slave1:~
scp -r ~/kafka hadoop@slave2:~6、分发完成以后,在++++每个节点++++上修改server编号:
cd ~/kafka/config
vim server.properties找到broker.id项,master、slave1、slave2三台机器分别标识为1、2、3:
broker.id=1
broker.id=2
broker.id=3
7、配置环境变量,三台机器都要配置:
vim ~/.bashrc在文件末尾添加以下内容:
export KAFKA_HOME=/home/hadoop/kafka
export PATH=$KAFKA_HOME/bin:$PATH保存文件,然后刷新环境变量或重新启动命令行终端:
source ~/.bashrc二、集群启动测试
Kafka作为一个分布式应用程序,它依赖ZooKeeper提供协调服务,因此要启动Kafka,必须先启动ZooKeeper集群,再启动Kafka集群。
步骤:
1、启动好ZooKeeper以后,在三台机器上执行以下命令启动Kafka:
kafka-server-start.sh -daemon ~/kafka/config/server.properties用jps命令在三台机器上都能看到Kafka进程的话,说明Kafka集群服务启动成功。
三、集群功能测试
集群启动成功后,还需测试其功能是否能正确使用,Kafka自带很多种Shell脚本供用户使用,包括生产消息、消费消息、Topic管理等,下面利用Shell脚本来测试Kafka集群的功能。
步骤:
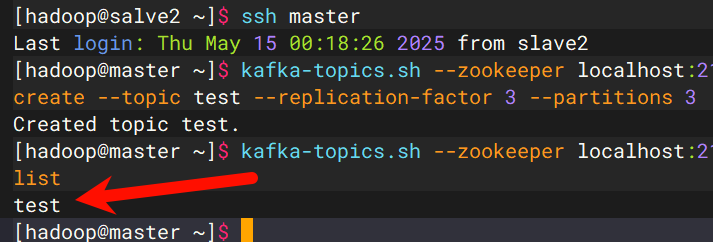
1、创建Topic:
kafka-topics.sh --zookeeper localhost:2181 --create --topic test --replication-factor 3 --partitions 32、查看Topic列表:
kafka-topics.sh --zookeeper localhost:2181 --list能够看到第1步创建的test则创建Topic成功。
3、启动消费者:
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test这样就打开了一个终端消费者,消费test Topic中的消息,但目前该Topic中还没有消息,因此这个进程会没有任何反应,这是正常的。
4、另外打开一个终端,启动生产者向test Topic发送消息:
kafka-console-producer.sh --broker-list localhost:9092 --topic test在这个生产者终端上输入消息,然后按回车发送,发送完之后,如果刚才那个消费者终端上,能够查看到消费了对应的消息的话,说明Kafka集群可以正常对消息进行生产和消费了。
生产者slave1发送消息:

消费者master接受到消息:
