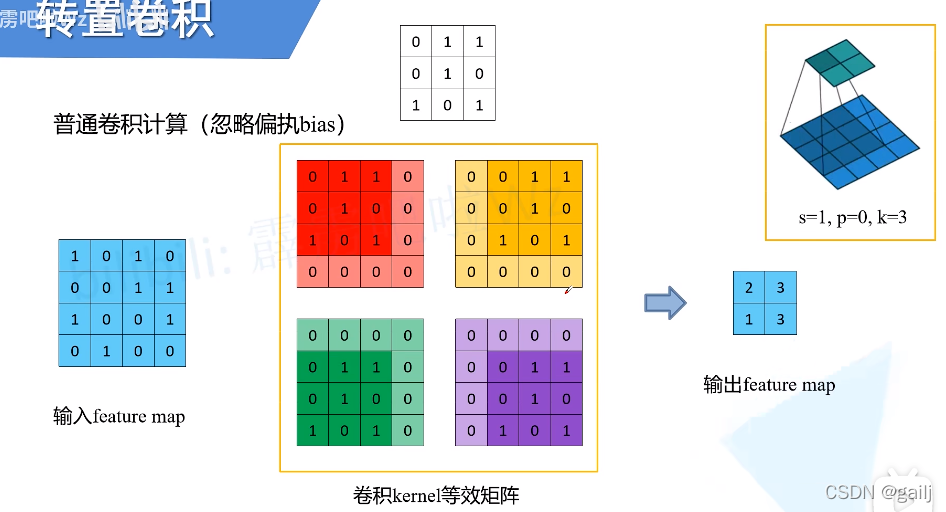
普通卷积
普通卷积大家应该都比较熟悉了,如果不熟悉的话,可以参考我之前的博客,或者去网上自行百度。这里主要想补充两个知识点。一:卷积核参数量怎么算? 二:如何高效的并行运算卷积滑窗?
卷积核参数量怎么算?
假设现在有一张单通道的灰度图,卷积核大小是3×3,输出通道是10。那么参数量就是3×3×1×10 因为输入是单通道 所以进行一次运算
假设现在有一张三通道的彩色图,卷积核大小是3×3,输出通道是10。那么参数量就是3×3×3×10 因为输入是单通道 所以分别进行三次运算 然后相加
不是一个卷积核对三个通道做运算,而是三个卷积核对三通道做运算(即每个卷积核只对一个通道运算)
输出通道就是卷积核重复的次数 每次可以关注到图像不同的特征 比如颜色、纹理、边缘等
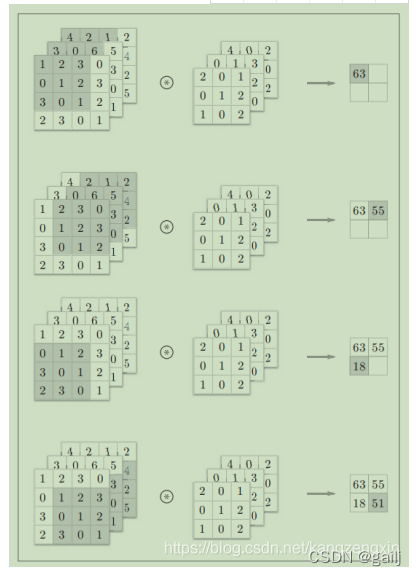
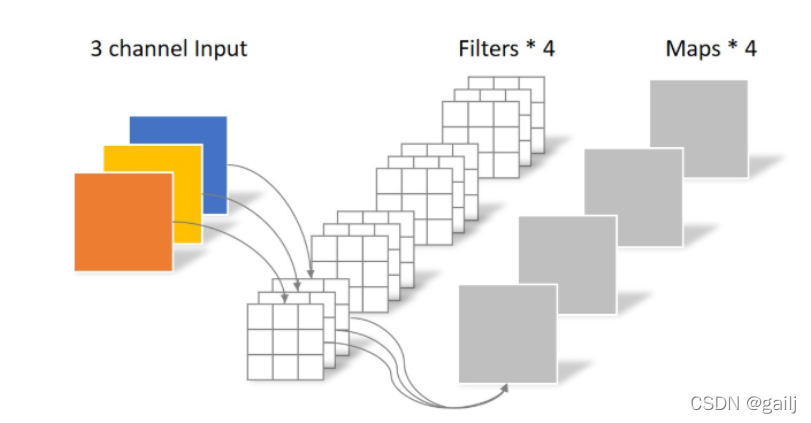
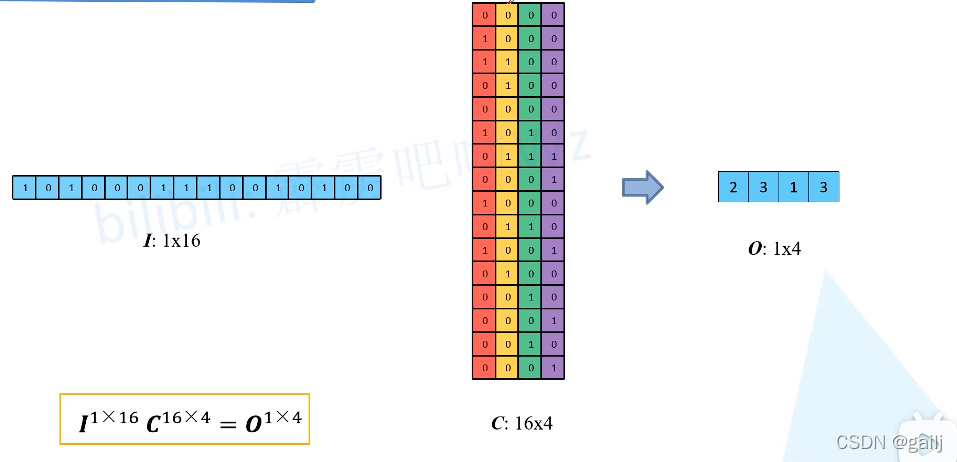
在GPU中如何并行计算
正常是一下一下滑动的 但是GPU可以并行 这样就太慢了
答案就是展开成一维向量 卷积核每次扫荡不到的地方取0 四次扫荡用四个向量表示 与输入向量相乘 等同于上图的过程
1×1卷积
** 1×1卷积很常见的,比如在Resnet中。它通常有两个作用,**
降维( dimension reductionality )。比如,一张500 * 500且厚度depth为100 的图片在20个filter上做1*1的卷积,那么结果的大小为500×500×20。就是改变了输入和输出的通道数,可以减少参数。
增加非线性 。卷积层之后经过激励层,1*1的卷积在前一层的学习表示上添加了非线性激励( non-linear activation ),提升网络的表达能力;很明显,增加了非线性,因为相当于又进行了一次运算
参数小 已经见过有的论文 用这个卷积替换全连接层改变维度 参数大大降低
可分离卷积
可分离卷积主要有两种类型:空间可分离卷积和深度可分离卷积。
空间可分离卷积:
将一个卷积核分为两部分(降低计算复杂度,但并非所有的卷积核都可以分,如下图,必须得合适才行)最常见的情况是将3x3的卷积核划分为3x1和1x3的卷积 核,例如在Inception V3中就用到了,如下所示:
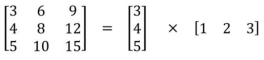
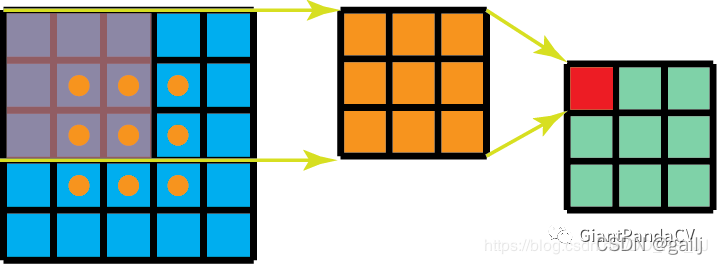
普通的3x3卷积在一个5x5的feature map上的计算方式如下图,每个位置需要9此惩罚,一共9个位置,整个操作要81次做乘法:
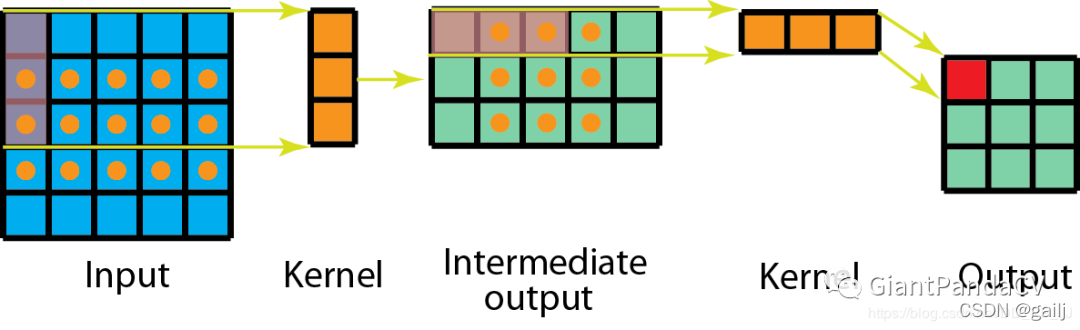
同样的状况在空间可分离卷积中的计算方式如下图,第一步先使用3x1的filter,所需计算量为:15x3=45;第二步使用1x3的filter,所需计算量为:9x3=27;总共需要72次乘法就可以得到最终结果,要小于普通卷积的81次乘法。
解释下这里的乘法 首先是1*3卷积进行扫荡15x3=45对于得到的结果(此时维度是3*5) 进行3*1扫荡9x3=27
深度可分离卷积:
深度可分离卷积,其实只对常规卷积做了一个很小的改动,但是带来的确是参数量的下降,这无疑为网络的轻量化带来了好处。深度可分离卷积主要分为两部分:逐通道卷积(Depthwise Convolution)、逐点卷积(pointwise)
逐通道卷积是在空间特征融合 ,逐点卷积是在通道特征融合(通过1*1卷积将通道之间的关系连接了起来)逐点卷积是深度上的延申 代表通道特征 通道卷积是在一张图片上延申 代表着空间特征
假设输入通道数是3,第一步用三个卷积和对三个通道分别做卷积,这样在一次卷积后,输出3个数。
这输出的三个数,再通过一个1x1x3的卷积核(pointwise核),得到一个数。
这里用1*1卷积 减少了参数量
假设输出通道是4,常规卷积的参数个数为:
N_std = 4 × 3 × 3 × 3 = 108
Separable Convolution的参数由两部分相加得到:
N_depthwise = 3 × 3 × 3 = 27
N_pointwise = 1 × 1 × 3 × 4 = 12
N_separable = N_depthwise + N_pointwise = 39巧妙地把最后的4转移出去 只在1*1卷积上体现
思考:卷积神经网络里面是否遇到卷积层就可以用可分离卷积替代?
相当于是将空间特征学习和通道特征学习分开的过程。 也就是这里带来的假设是这批数据的空间位置高度相关,但不同通道之间相互独立,那么这么做是有积极意义的,并且在参数量减少很多的情况下,获得性能更好的模型。
空洞卷积也叫膨胀卷积也叫扩张卷积 间隔取点
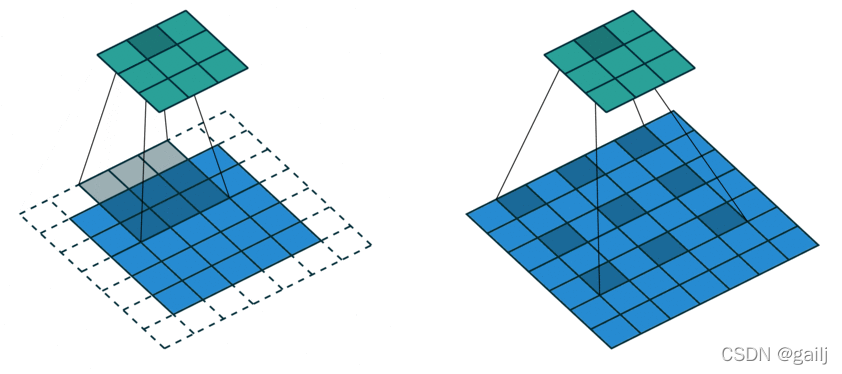
这就在不丢失特征分辨率的情况下扩大了感受野,进而对检测大物体有比较好的效果。所以总的来说,空洞卷积主要作用:不丢失分辨率的情况下扩大感受野;调整扩张率获得多尺度信息。但是对于一些很小的物体,本身就不要那么大的感受野来说,这就不那么友好了。
3D卷积
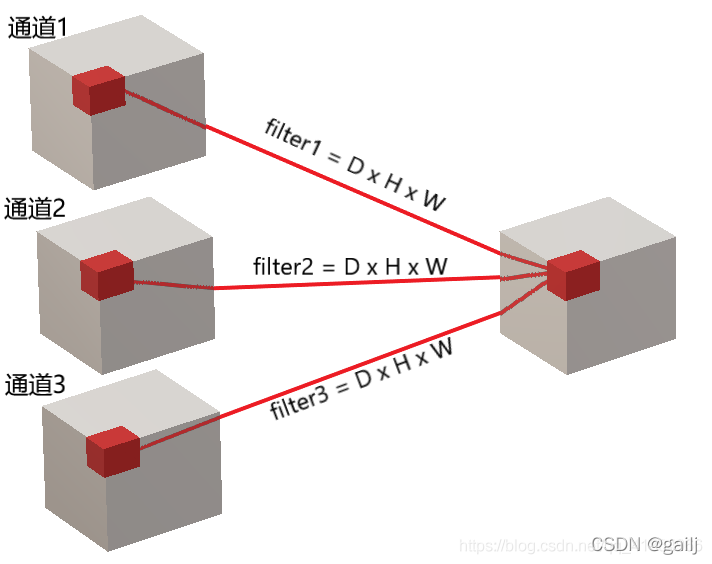
3D卷积的对象是三维图像,因此卷积核变成了depth×height×width,简写为D × H × W
** 多通道的3D卷积核shape为D × H × W × Channels Channels就是输出的通道数(滤波器的个数)**
** 比如说一下子是10帧,10张RGB图片,每张提取出RGB三个通道,如下图所示,比如通道1中是10个图片的R,通道2是10个图片的G,通道3是10个图片的B,然后这些分别与3D卷积核做运算,运算后得到3个结果嘛,3个结果再求和累加起来。其实过程和2D的差不多(回想,2D其实也是RGB,只不过每个RGB通道只有一张图)。**
只是增加了一个帧参数 与2D卷积类似