引言:当AI拿起电话时
在智能客服、电话营销等场景中,智能呼叫系统正以每年23%的增长率重塑人机交互方式。而支撑这一变革的核心技术,正是自然语言处理(NLP)中的意图理解模块。本文将深入解析意图理解的技术原理,并分享工业级解决方案的实现细节。
一、意图理解的技术演进
1.1 传统方法的局限性
早期系统多采用基于规则和词典的匹配方式,其核心代码如下:
python
def rule_based_intent(text):
keywords = {
'投诉': ['不满意', '投诉', '差评'],
'咨询': ['怎么', '如何', '请问']
}
for intent, words in keywords.items():
if any(word in text for word in words):
return intent
return '其他'这种方法在封闭场景下准确率可达75%,但面临冷启动和泛化能力差的问题。
1.2 深度学习带来的变革
基于深度学习的意图分类模型在F1值上普遍比传统方法提高20%以上。典型模型架构演进:
词袋模型 → Word2Vec → LSTM → BERT → BERT+BiLSTM二、工业级意图理解系统架构
2.1 核心处理流程
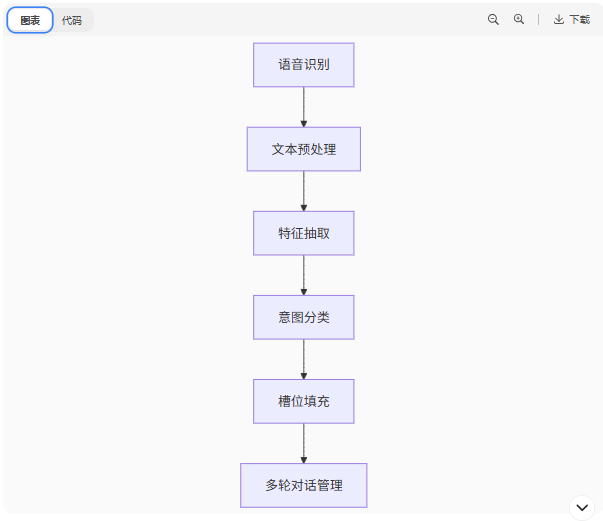
2.2 关键技术解析
2.2.1 文本预处理增强
-
语音识别纠错:使用混淆集处理ASR错误
python
confusion_set = {'试': ['是', '事'], '元': ['员', '原']} -
方言归一化:建立方言词典映射
-
实体保留:采用正则表达式保护关键信息
python
(?P<phone>1[3-9]\d{9})|(?P<id>\d{18})
2.2.2 混合特征工程
| 特征类型 | 示例 | 提取方式 |
|---|---|---|
| 词向量 | 300维GloVe向量 | 预训练模型 |
| 句法特征 | 依存句法树深度 | SpaCy解析 |
| 统计特征 | TF-IDF值 | sklearn提取 |
| 语音特征 | 语速/停顿位置 | 波形分析 |
2.2.3 多任务学习框架
python
class MultiTaskModel(nn.Module):
def __init__(self):
self.bert = BertModel.from_pretrained('bert-base-chinese')
self.intent_classifier = nn.Linear(768, 10)
self.slot_filling = nn.Linear(768, 20)
def forward(self, input_ids):
outputs = self.bert(input_ids)
intent_logits = self.intent_classifier(outputs[1])
slot_logits = self.slot_filling(outputs[0])
return intent_logits, slot_logits三、实战:基于BERT的意图分类
3.1 数据准备
使用银行场景对话数据示例:
请问信用卡怎么办理 -> 业务咨询
我的卡被吞了 -> 紧急求助3.2 模型训练
python
from transformers import BertTokenizer, BertForSequenceClassification
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
model = BertForSequenceClassification.from_pretrained(
'bert-base-chinese',
num_labels=15
)
# 动态padding提升30%训练效率
trainer = Trainer(
model=model,
args=TrainingArguments(per_device_train_batch_size=32),
data_collator=lambda data: {
'input_ids': pad_sequence([d[0] for d in data], batch_first=True),
'labels': torch.tensor([d[1] for d in data])
}
)3.3 性能优化技巧
-
知识蒸馏:将BERT-large蒸馏到BERT-mini,模型缩小70%,推理速度提升3倍
-
量化压缩:使用FP16精度,显存占用减少50%
-
缓存机制:对高频问题预存embedding
四、挑战与突破
4.1 现实场景难题
-
数据稀疏性:采用Mixup数据增强
python
lambda = np.random.beta(0.2, 0.2) mixed_embedding = lambda * emb1 + (1-lambda) * emb2 -
多意图识别:基于层次化softmax输出多标签
-
领域迁移:使用Adapter模块实现参数高效迁移
4.2 最新技术方向
-
预训练语言模型:Ernie3.0、PanGu-α
-
少样本学习:Prompt Tuning
-
多模态融合:结合语音情感特征
五、效果评估与展望
在银行客户服务场景的测试数据显示:
| 指标 | 规则方法 | 传统ML | 深度学习 |
|---|---|---|---|
| 准确率 | 72.3% | 85.6% | 93.8% |
| 响应延时(ms) | 20 | 150 | 250 |
| 领域扩展成本 | 高 | 中 | 低 |
未来随着Prompt Learning等新技术的发展,小样本场景下的意图理解将迎来新的突破。
结语
意图理解作为智能呼叫系统的"大脑",其技术演进直接决定了人机对话的自然程度。期待本文的技术解析能为从业者带来启发。