查找的基本概念
基本概念
查找:在数据集合中寻找满足某种条件的数据元素的过程
查找表(查找结构):用于查找的数据集合称为查找表,它由同一类型的数据结构元素(或记录)组成
关键字:唯一标识该元素的某个数据项的值,使用基于关键字的查找,查找结果应该是唯一的
对查找表的常见操作
①查找符合条件的数据元素
②插入、删除某个数据元素
只需要进行操作①--静态查找表--著需要关注查找速度
也要进行操作②--动态查找表--还需要关注插入、删除操作是否方便实现
查找算法的评价指标
查找长度:查找运算中,需要对比关键字次数
平均查找长度(ASL):查找过程中进行关键字比较次数的平均值
通常考虑查找成功、查找失败两种情况下的ASL
顺序查找
算法思想
从头到尾/从尾到头依次查找
基本实现
c
typedef struct{
ElemType *elem;
int TableLen;
}SSTable;
//顺序查找
int Search_Seq(SSTable ST,ElemType key){
int i;
for(i = 0;i<ST.TableLen && ST.elem[i] != key;++i);
return i==ST.TableLen?-1:i;
}实现(哨兵)
c
typedef struct{
ElemType *elem;
int TableLen;
}SSTable;
//顺序查找
int Search_Seq(SSTable ST,ElemType key){
ST.elem[0] = key; //查找表中从1号位置开始存放数据,0号位置存放"哨兵"
int i;
for(i = ST.TableLen;ST.elem[i] != key;--i);
return i; //查找成功,返回元素下标;查找失败,返回0
}优点:无需判断是否越界,执行效率更高(但是并没有质的提升)
效率分析
查找成功:ASL=(n+1)/2 时间复杂度:O(n)
查找失败:ASL=n+1 时间复杂度:O(n)
顺序查找的优化(对有序表)
以查找表中元素递增存放为例:
若查找到某个元素大于查找目标,则可判定为查找失败(后面的元素都大于查找目标)
ASL(失败) = (1+2+......+n+n)/n+1 = n/2+n/(n+1)
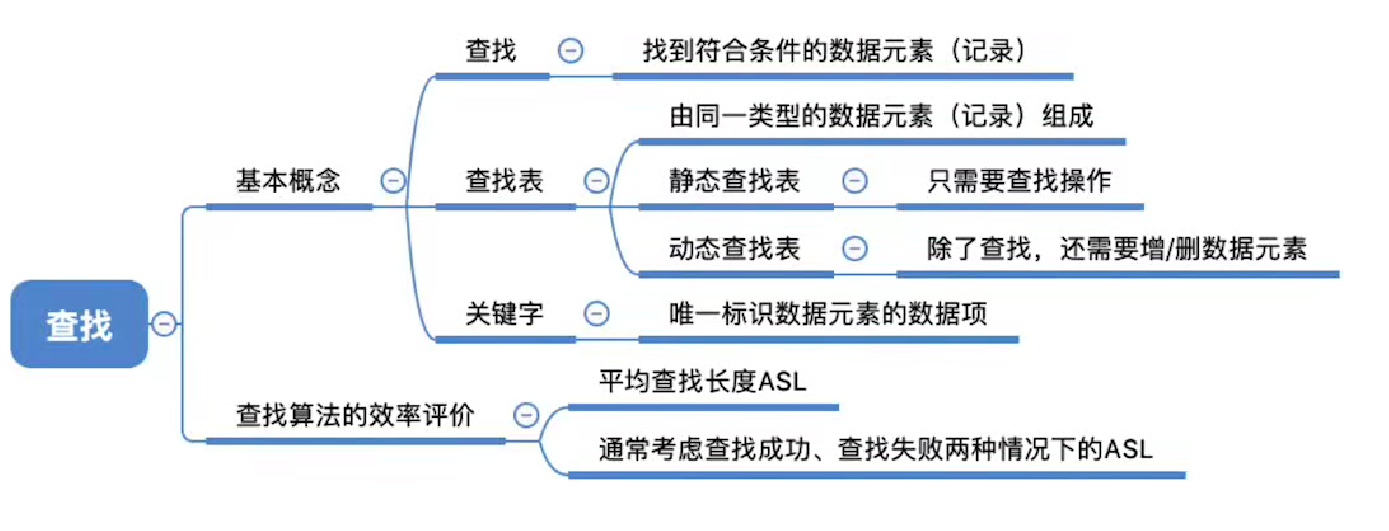
查找算法判定树分析ASL
一个成功节点的查找层数 = 自身所在的层数
一个失败节点的查找长度 = 其父节点所在的层数
默认情况下,各种成功情况或失败情况都等概率发生
折半查找(考察频率高)
算法思想
又称"二分查找",仅适用于有序的顺序表
每次将查找范围折半,逐步缩小查找区间,直到找到目标元素或查找区间为空。
前提 :数据必须是有序的(通常是升序)。
取中间元素:
- 计算中间下标
mid = (low + high) // 2。
比较中间元素和目标值:
- 若
target == arr[mid]:查找成功。 - 若
target < arr[mid]:继续在左半部分查找。 - 若
target > arr[mid]:继续在右半部分查找。
重复步骤 2-3,直到找到目标或范围为空(low > high)。
算法实现
c
typedef struct{
ElemType *elem;
int TableLen;
}SSTable;
int Binary_Search(SSTable L,ElemType key){
int low = 0,high = L.TableLen-1,mid;
while(low<=high){
mid = (low+high)/2; //取中间位置
if(L.elem[mid] == key)
return mid; //查找成功返回所在位置
else if(L.elem[mid]<key)
low = mid+1; //从后半部分查找
else
high = mid-1; //从前半部分查找
}
return -1;
}查找效率分析
例:
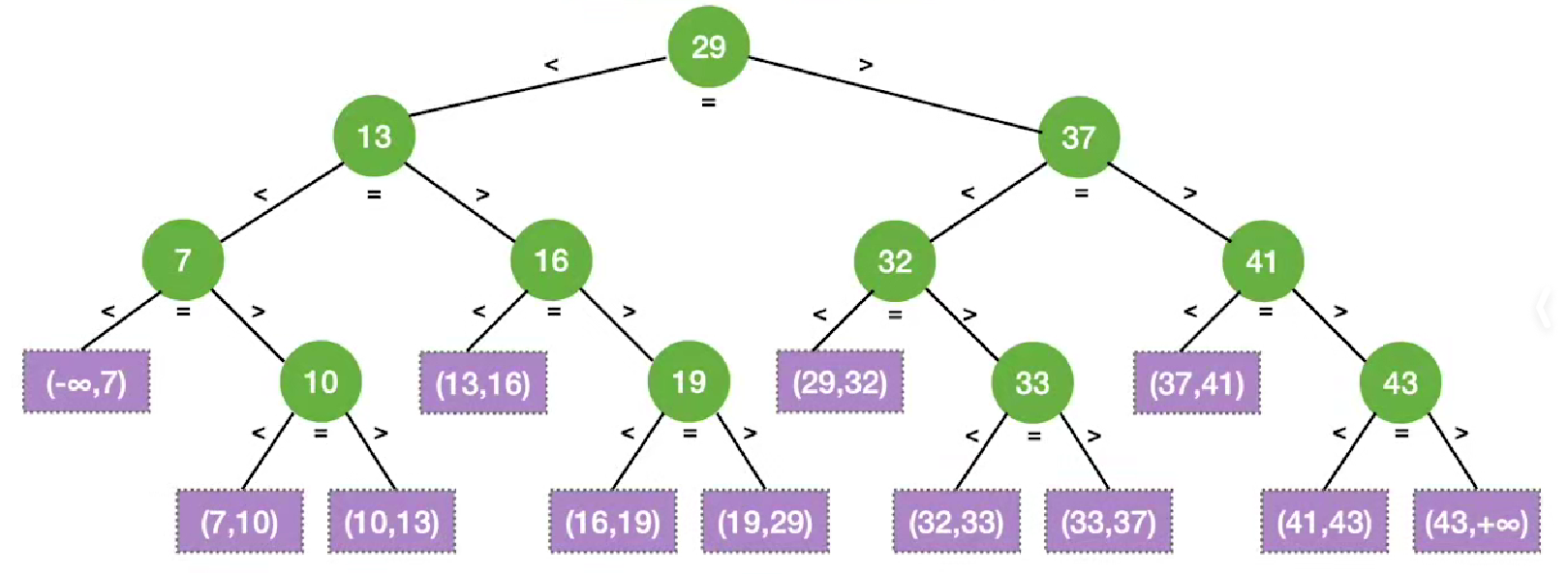
ASL(成功) = (1*1 + 2*2 + 3*4 + 4*4)/11 = 3
ASL(失败) = (3*4+4*8)/12 = 11/3
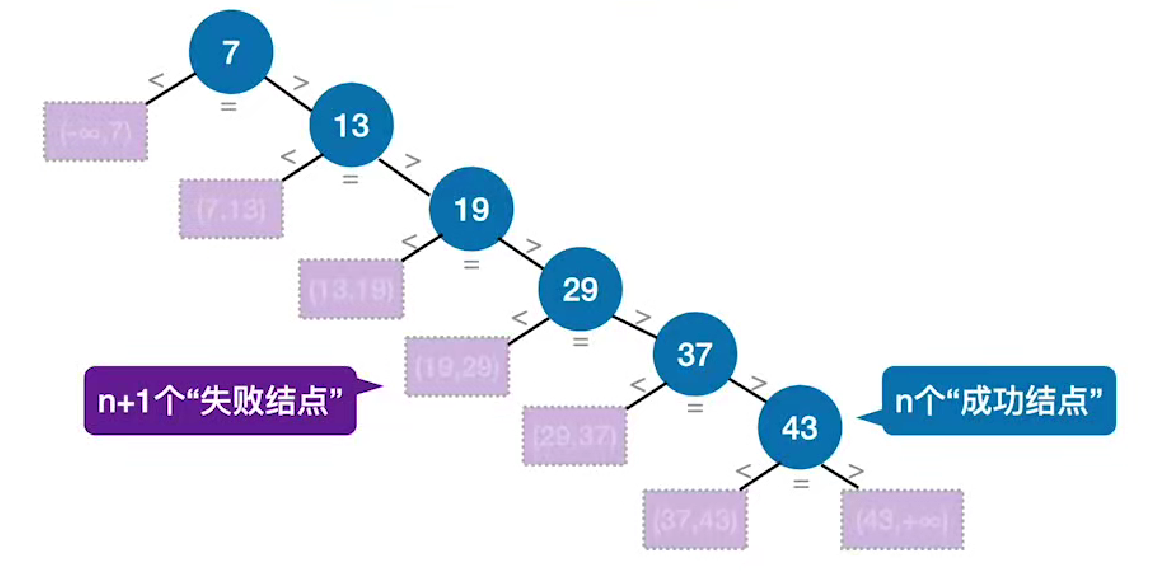
查找判定树的构造
如果当前low和high之间有奇数个元素,则mid分割后,左右两部分元素个数相等
如果当前low和high之间有偶数个元素,则mid分割后,左半部分比右半部分少一个元素
折半查找的判定树中,若mid = (low+high)/2 则对于任何一个结点,必有:右子树个数-左子树个数 = 0或1
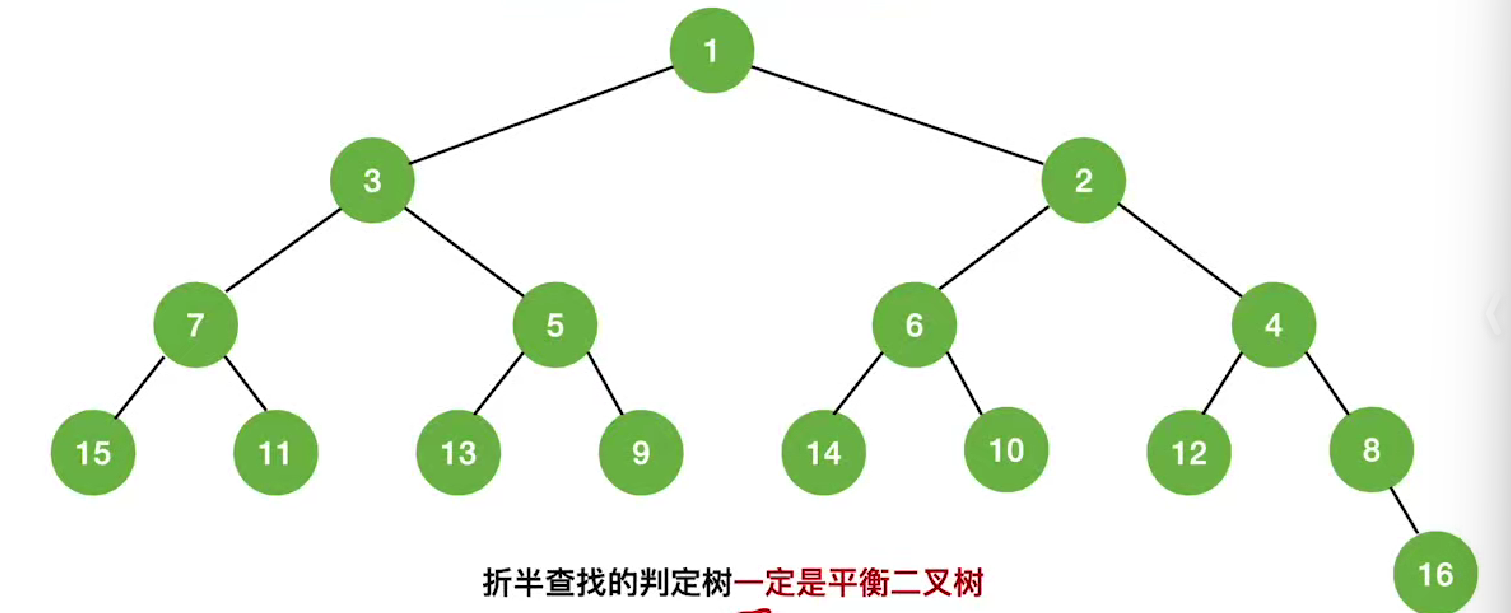
折半查找的判定树一定只有最下面一层是不满的
h = [log2(n+1)]
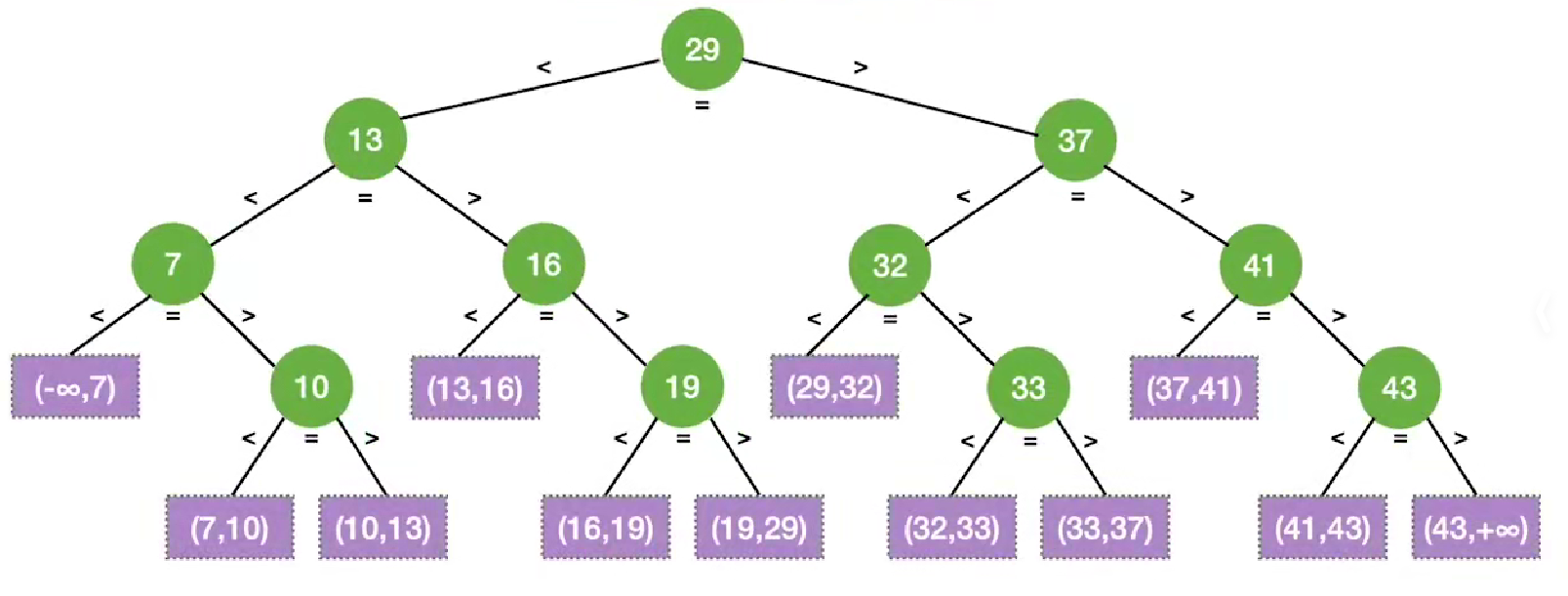
判定树结点关键字:左<中<右,满足二叉排序树的定义
失败节点:n+1(等于成功结点的空链域数量)
折半查找的查找效率
树高h = [log2(n+1)] 查找成功ASL ≤ h 查找失败ASL ≤ h
时间复杂度O(log2n)
!WARNING
折半查找的速度一定比顺序查找更快?
❌ 一般情况下,折半查找比顺序查找表现优秀,但不是所有情况下折半查找都更快
若mid = (low+high)/2(向上取整) ?
左子树结点数-右子树结点数 = 0或1
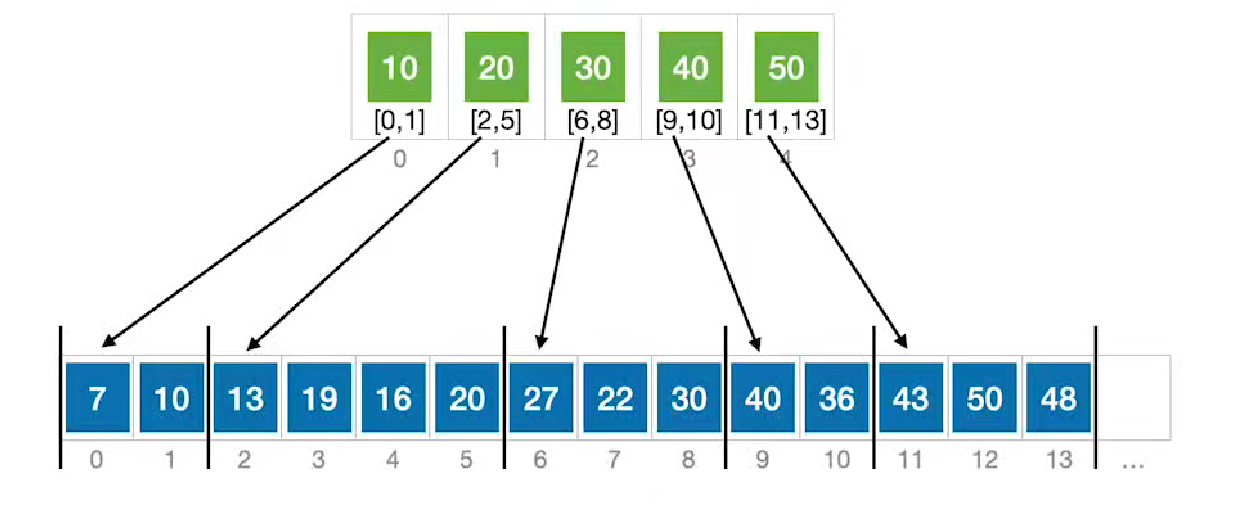
分块查找(手算模拟+平均查找长度)
分块查找的算法思想
eg. 第一个区间:≤10 第二个区间:≤20 ......
"索引表"中保存每个分块的最大关键字和存储的区间
特点:块内无序,块间有序
c
typedef struct{
ElemType maxValue;
int low,high;
}Index;
//顺序表存储实际元素
ElemType List[100];算法过程:
①在索引表中确定待查记录所属的分块(可顺序、可折半)
②在块内顺序查找
用折半查找查索引
若索引表中不包含目标关键字,则折半查找索引表最终停在low>high,要在low所指的分块中进行查找
low超出索引表的范围时,查找失败
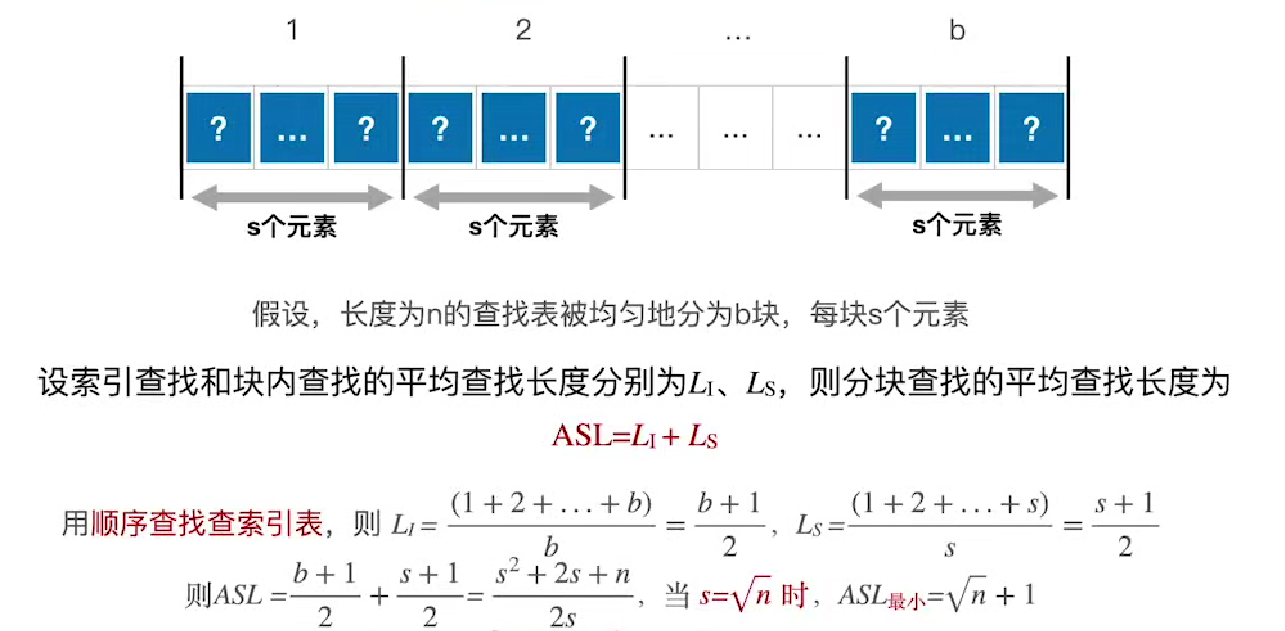
查找效率分析(ASL)
共有14个元素可能被查找,各自被查找的概率为1/14
若索引表顺序查找
7(2)、10(3)、13(3)......
若索引表折半查找(一般不考、计算量大)
30(4)✔、27(2)❌
查找失败的情况(更复杂,一般不考)
【可能会考的情况】(顺序查找,效率和最优分块)
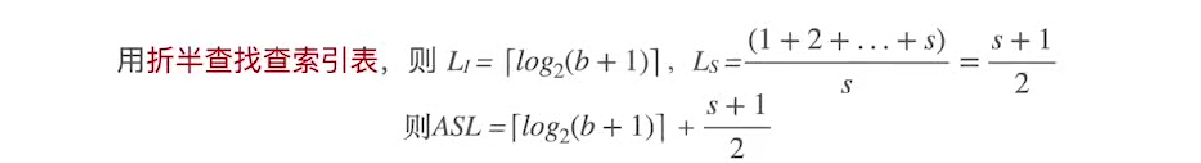
【拓展思考】
若查找表是"动态查找表",更好的实现方式 -- 使用链式存储
(否则在目标关键字插入时,需要大量元素的移动)