ARM模块【来源于BiSeNet】:细化特征图的注意力,增强重要特征并抑制不重要的特征。
Attention Refinement Module (ARM) 详解
ARM (Attention Refinement Module) 是 BiSeNet 中用于增强特征表示的关键模块,它通过注意力机制来细化特征图,突出重要特征并抑制不重要的特征。下面从多个角度深入理解 ARM 模块。
1. ARM 的核心设计思想
ARM 的设计基于以下两个核心思想:
- 全局上下文感知:通过全局平均池化捕获图像级的上下文信息
- 通道注意力机制:自适应地重新校准通道特征响应
这种设计使网络能够:
- 增强与语义相关的特征通道
- 抑制噪声或不重要的特征通道
- 在不增加计算复杂度的前提下提升特征表示能力
2. ARM 的详细结构分析
分解 ARM 的结构:
python
class AttentionRefinementModule(nn.Module):
def __init__(self, in_chan, out_chan, *args, **kwargs):
super(AttentionRefinementModule, self).__init__()
# 特征变换层
self.conv = ConvBNReLU(in_chan, out_chan, ks=3, stride=1, padding=1)
# 注意力生成分支
self.conv_atten = nn.Conv2d(out_chan, out_chan, kernel_size=1, bias=False)
self.bn_atten = nn.BatchNorm2d(out_chan)
self.sigmoid_atten = nn.Sigmoid()2.1 特征变换层 (self.conv)
- 使用一个 3×3 的卷积 + BN + LeakyReLU
- 将输入特征从
in_chan维变换到out_chan维 - 保持空间尺寸不变 (stride=1, padding=1)
2.2 注意力生成分支
-
全局平均池化:
- 对每个通道的所有空间位置取平均值
- 将 H×W×C 的特征图压缩为 1×1×C 的通道描述符
-
1×1 卷积 (
self.conv_atten):- 学习通道间的相关性
- 无偏置项,减少参数数量
-
批归一化 (
self.bn_atten):- 稳定训练过程
- 加速收敛
-
Sigmoid 激活 (
self.sigmoid_atten):- 将注意力权重归一化到 0,1 范围
- 实现特征的软选择
3. ARM 的前向传播过程
python
def forward(self, x):
# 1. 特征变换
feat = self.conv(x)
# 2. 生成注意力图
atten = F.avg_pool2d(feat, feat.size()[2:]) # 全局平均池化
atten = self.conv_atten(atten) # 1×1卷积
atten = self.bn_atten(atten) # 批归一化
atten = self.sigmoid_atten(atten) # 激活
# 3. 应用注意力
out = torch.mul(feat, atten) # 逐通道相乘
return out3.1 数学表达
输出特征可以表示为:
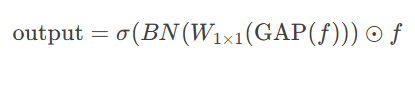
3.2 计算流程图示
输入特征 [ C × H × W ]
↓
3×3 Conv+BN+ReLU → 特征变换 [ C' × H × W ]
↓ ↓
全局平均池化 [C'×1×1] |
↓ |
1×1 Conv [C'×1×1] |
↓ |
BN |
↓ ↓
Sigmoid → 注意力权重 [C'×1×1]
↓
逐通道乘法 → 输出特征 [ C' × H × W ]4. ARM 的特点与优势
4.1 轻量高效
- 仅增加少量参数 (一个 1×1 卷积)
- 计算开销主要来自全局平均池化,但这是非常轻量的操作
4.2 与 SE 模块的对比
ARM 与 SENet 中的 SE 模块类似,但有重要区别:
| 特性 | ARM | SE 模块 |
|---|---|---|
| 位置 | 用于语义分割任务 | 用于图像分类任务 |
| 输入 | 来自上下文路径的多尺度特征 | 单一尺度特征 |
| 输出 | 直接用于后续分割 | 用于分类 |
| 设计目标 | 保持空间信息 | 通道重校准 |
| 典型应用 | BiSeNet 中的特征细化 | ResNet 等分类网络中的增强 |
4.3 在 BiSeNet 中的作用
在 BiSeNet 中,ARM 被应用于不同尺度的特征:
- ARM32:处理最深层特征 (32倍下采样)
- ARM16:处理中间层特征 (16倍下采样)
- ARM8:处理较浅层特征 (8倍下采样)
这种多尺度注意力机制使网络能够:
- 在深层捕获全局语义信息
- 在中间层平衡语义和细节
- 在浅层保留更多空间细节
5. ARM 的变体与改进
5.1 Attentionout 模块(正常残差,通道注意VS空间注意)
python
class Attentionout(nn.Module):
def __init__(self, out_chan, *args, **kwargs):
self.conv_atten = nn.Conv2d(out_chan, out_chan, kernel_size=1,bias=False)
self.bn_atten = nn.BatchNorm2d(out_chan)
self.sigmoid_atten = nn.Sigmoid()
def forward(self, x):
atten = self.conv_atten(x) # 直接处理特征图,而非池化后的
atten = self.bn_atten(atten)
atten = self.sigmoid_atten(atten)
out = torch.mul(x, atten)
x = x + out # 添加残差连接
return out特点:
- 不使用全局池化,直接处理空间特征
- 添加了残差连接
- 生成空间注意力图而非通道注意力
5.2 SAR 模块 (Spatial Attention Refinement)【局部注意】
python
class SAR(nn.Module):
def __init__(self, in_chan, mid, out_chan):
self.conv_reduce = ConvBNReLU(in_chan, mid, 1, 1, 0)
self.conv_atten = nn.Conv2d(2, 1, kernel_size=3, padding=1, bias=False)
def forward(self, x):
x_att = self.conv_reduce(x)
low_attention_mean = torch.mean(x_att, 1, True) # 通道均值
low_attention_max = torch.max(x_att, 1, True)[0] # 通道最大值
low_attention = torch.cat([low_attention_mean, low_attention_max], dim=1)
spatial_attention = self.sigmoid_atten(self.bn_atten(self.conv_atten(low_attention)))
x = x * spatial_attention # 空间注意力
return x特点:
- 同时考虑通道均值和最大值
- 生成空间注意力图
- 使用 3×3 卷积捕获局部空间关系
6. ARM 的实际效果
在实际应用中,ARM 模块能够:
- 增强语义特征:使网络更关注与类别相关的区域
- 抑制背景噪声:降低无关背景区域的响应
- 改善小目标检测:通过多尺度注意力增强小目标的特征
- 提升模型鲁棒性:对光照变化、遮挡等更具适应性
在 BiSeNet 的论文中,ARM 模块的引入带来了约 2-3% 的 mIoU 提升,而计算代价仅增加不到 1%。
7. 总结
ARM 模块是 BiSeNet 中高效且有效的注意力机制,它通过:
- 全局上下文建模
- 通道注意力重校准
- 多尺度特征细化
显著提升了语义分割的性能,同时保持了模型的轻量级特性。这种设计思想也被后续许多实时分割网络所借鉴和发展。