文章目录
- 从数据层面减少过拟合现象
-
- 一、过拟合及数据上常用的方法
-
- [1. 收集更多真实数据](#1. 收集更多真实数据)
- [2. 数据增强(Data Augmentation)](#2. 数据增强(Data Augmentation))
- [3. 预训练](#3. 预训练)
- [4. 数据清洗与去噪](#4. 数据清洗与去噪)
- [5. 处理类别不平衡](#5. 处理类别不平衡)
- [6. 特征工程与降维](#6. 特征工程与降维)
- [7. 合理的数据划分与验证](#7. 合理的数据划分与验证)
- [8. 高级数据增强技术](#8. 高级数据增强技术)
- [9. 数据分布修正](#9. 数据分布修正)
- 二、小结
从数据层面减少过拟合现象
一、过拟合及数据上常用的方法
过拟合是机器学习中的常见问题,可以通过以下方法提升数据的多样性和质量,帮助模型学习更普适的规律:
1. 收集更多真实数据
减少过拟合现象的最好方式之一是采集更多(高质量的)数据。我们可以通过以下方法获得更多数据:
-
直接扩增:人工标注新数据(最直接有效的方法)。
-
间接生成:利用生成模型(如GAN、VAE、Diffusion Models)合成高质量数据。
- 注意事项:需验证生成数据的分布是否与真实数据一致,避免引入虚假模式。
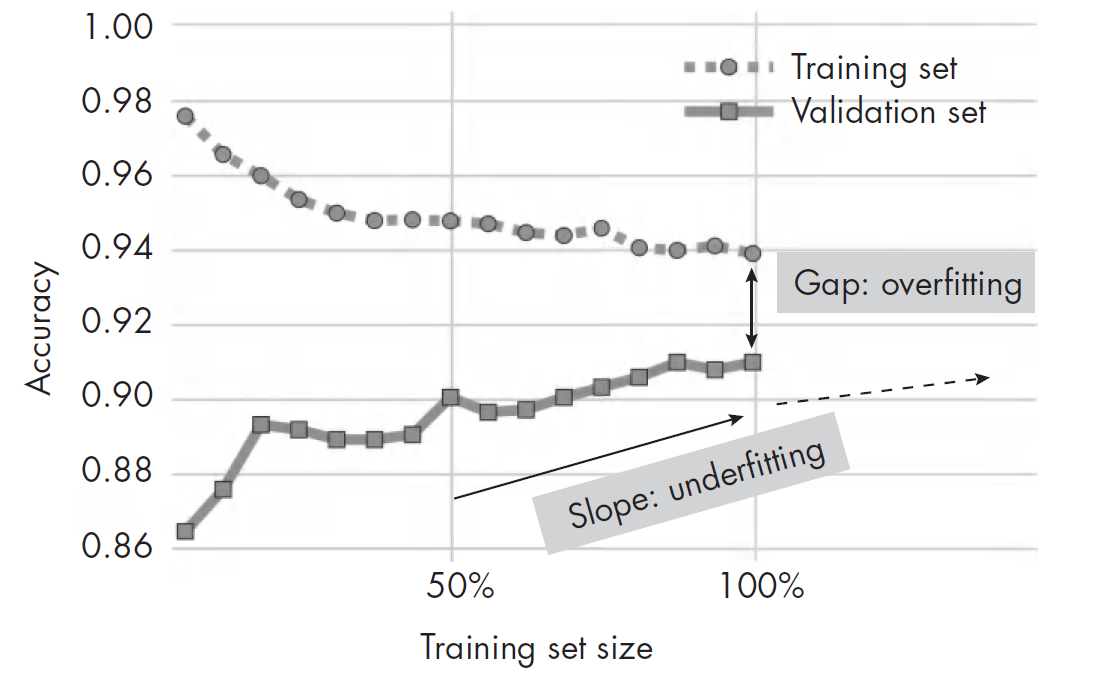
如下图所示,随着训练集的增大,模型在验证集上的准确性也会提高。
2. 数据增强(Data Augmentation)
- 核心思想:通过对现有数据进行合理变换,生成新样本,增加数据多样性,它能在不采集额外数据的情况下扩数据集。
- 具体方法 :
- 图像领域 :旋转、翻转(水平/垂直)、裁剪、缩放、添加噪声、调整亮度/对比度、模糊等。
- 注意 :避免破坏标签有效性(例如垂直翻转数字"6"可能变为"9")。

- 注意 :避免破坏标签有效性(例如垂直翻转数字"6"可能变为"9")。
- 文本领域:同义词替换、随机插入/删除词语、回译(翻译成其他语言再译回)、随机交换句子顺序等。
- 音频领域:变速、加噪、时移、改变音高。
- 结构化数据:添加高斯噪声、生成对抗样本(需保证特征分布合理)。
- 图像领域 :旋转、翻转(水平/垂直)、裁剪、缩放、添加噪声、调整亮度/对比度、模糊等。
- 优势:低成本扩展数据集,迫使模型关注不变性特征(如物体形状而非位置)。
3. 预训练
- 核心思想:通过自监督学习、迁移学习以及小样本学习等方法进行预训练,减少过拟合现象的发生。
- 具体方法
- 自监督学习:通过大型无标签数据集对神经网络进行预训练。
- 迁移学习:针对大型有变迁数据集进行迁移学习。
- 小样本学习:数据集非常小,例如每个标签只有几个样本,这时候监督学习并不适用。如分类器需要在无法获取更多有标签数据的情况下工作,我们可以考虑小样本学习。
4. 数据清洗与去噪
- 剔除异常值:通过统计方法(如Z-score、IQR)或可视化识别异常样本。
- 修正错误标签 :
- 人工审核:对高置信度但预测错误的样本重新标注。
- 半自动方法:使用交叉验证筛选标签不一致的样本。
- 标准化/归一化:消除特征量纲差异,防止模型对某些特征过度敏感。
5. 处理类别不平衡
- 过采样(Oversampling) :
- 简单复制少数类样本(可能导致过拟合)。
- SMOTE(Synthetic Minority Oversampling Technique):通过插值生成新样本。
- 欠采样(Undersampling) :
- 随机删除多数类样本(可能丢失重要信息)。
- Tomek Links:移除多数类中与少数类边界重叠的样本。
- 混合策略:如SMOTEENN(SMOTE + 清理欠采样)。
- 损失函数调整:使用加权交叉熵,赋予少数类更高权重(非数据层面,但常配合使用)。
6. 特征工程与降维
- 特征选择 :
- 过滤法(卡方检验、互信息)。
- 嵌入法(LASSO正则化、基于树模型的特征重要性)。
- 特征降维 :
- 线性方法:PCA(主成分分析)。
- 非线性方法:t-SNE、UMAP(更适合可视化)。
- 目的:减少冗余特征,降低模型复杂度对噪声的敏感性。
7. 合理的数据划分与验证
- 严格分离训练集/验证集/测试集 :
- 避免数据泄漏(例如同一患者的不同切片分到不同集合)。
- 确保分布一致(如时间序列数据需按时间划分)。
- 交叉验证 :
- 使用K折交叉验证评估模型稳定性。
- 对小型数据集尤其重要(如5折或留一法)。
8. 高级数据增强技术
- Mixup :线性混合两个样本的特征和标签(如 x n e w = λ x 1 + ( 1 − λ ) x 2 x_{new} = λx_1 + (1-λ)x_2 xnew=λx1+(1−λ)x2, y n e w = λ y 1 + ( 1 − λ ) y 2 y_{new} = λy_1 + (1-λ)y_2 ynew=λy1+(1−λ)y2)。
- Cutout/CutMix :
- Cutout:随机遮挡图像区域。
- CutMix:用另一图像的局部区域替换当前图像。
- AutoAugment:基于强化学习自动搜索最优增强策略(如Google的图像增强策略库)。
9. 数据分布修正
- 对抗性数据增强:针对模型弱点生成对抗样本并加入训练集(提升鲁棒性)。
- 领域自适应:若数据来自不同分布(如不同设备采集),对齐特征分布(如使用对抗训练或CORAL损失)。
二、小结
通过以上方法,可以从数据层面降低模型对训练集噪声和局部特征的依赖,提升泛化能力。需结合具体任务选择组合策略(如医疗图像需谨慎使用几何变换,NLP任务需保持语义一致性)。
当神经网络分类器出现过拟合现象时,意味着模型在训练数据上表现很好,但在未见过的测试数据上表现较差。模型学习到了训练数据中的噪声和特有模式,而不是普适的规律。从数据层面入手,以下是一些常用的减少过拟合的方法: