一、双亲委派机制(类加载机制中,最经常考到的问题)
类加载的第一个环节中,根据类的全限定类名(包名+类名)找到对应的.class文件的过程。
JVM中进行类加载的操作,需要以来内部的模块"类加载器"(class loader)
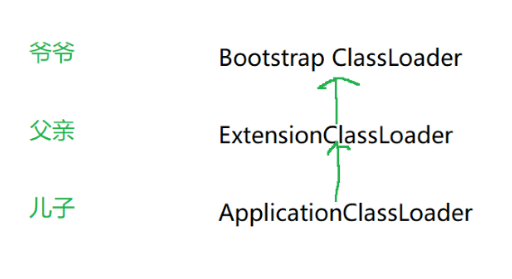
JVM自带了三种类加载器
Bootstrap ClassLoader 负责在Java的标准库中进行查找
ExtensionClassLoader 负责在Java的扩展库中进行查找
ApplicationClassLoader 负责在Java的第三方库/当前项目中进行查找
其中,Java的扩展库是JDK自带的,但是不是标准约定的库,是JDK的厂商自行扩展的功能。现在很少涉及到,一般都是使用第三方库。
Java的官方(Oracle)推出Java的标准文档,其他的厂商就会依据官方的文档,开发对应的JDK(官方确实也开发了JDK,还有一些第三方的,比如知名的OpenJDK,比如知名大厂也会有自己版本的JDK)
不同厂商,都能保证,标准约定的功能都是包含的,并且表现一致。但是这些厂商也会根据需要,扩展出一些功能出来。
这三类加载器之间,存在"父子关系"(不是父类子类,继承关系),每个类加载器中有一个parent这样的属性,保存了自己的父亲是谁。这是在JVM的源码中已经写死的。

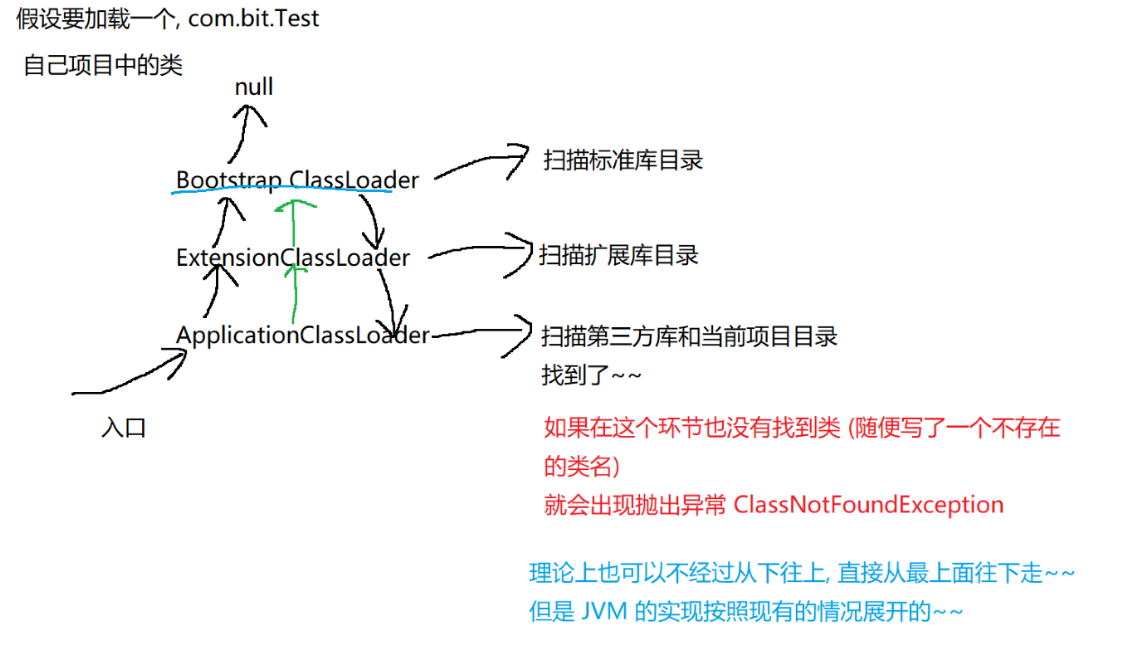
双亲委派模型的目的,是为了确保三个类加载的优先级:标准库优先加载,第三方库/当前项目类最后加载。比如自己写一个类,和标准库恰好重复了。java.lang.String。此时JVM保证加载的仍然是标准库的String,而不是你自己写的。
双亲委派模型也是可以打破的。程序员在特定场景下,也可以实现自己的类加载器(实现库/框架 可能涉及到),自己实现的类加载器可以让他遵守,也可以不遵守。
二、JVM的垃圾回收机制 GC
C/C++ 这样的编程语言中,申请内存的时候,是需要用完了手动进行释放的
C 申请内存
-
局部变量
-
全局变量 不需要手动释放
-
动态申请 malloc 通过 free 进行释放的
C++ 申请内存
-
局部变量
-
全局变量 / 静态变量
-
动态申请 new 通过 delete 进行释放
这样的释放操作,容易遗忘(执行不到)就会导致 "内存泄露"
malloc
free
逻辑代码
-
条件判定 触发 return
-
抛出异常
很多编程语言,引入了 垃圾回收 机制
不需要程序员写代码手动释放内存,会有专门的逻辑,帮助自动进行释放
垃圾回收,大大的解放了程序员,提高了开发效率
Java, Python, Go, PHP, JS.... 大多数主流语言都包含 GC 功能
为啥 C/C++ 没有引入 GC 呢?
C++ 的设计的核心理念,有两个(C++ 的红线)
-
和 C 兼容 (C 语言写的代码,用 C++ 编译器可以正常编译运行的)
-
把性能发挥到极致
隔壁会有很多的技巧 提高 "性能"
++i 代替 i++
通过返回 右值引用 代替返回值对象
通过引用传参代替值传参
通过 constexpr 增加编译期做的工作,减少运行时开销
...................
引入 GC 会影响性能, 引入了额外的运行时开销。
很早之前,C++ 的标准委员会讨论这个事情。
C++ 引入了 "智能指针",可以一定程度的解决内存泄露的问题。(虽然可用性,远不如 GC,总比 C 语言啥都不做,直接摆烂强
在对性能有要求的开发场景中 C++ 是无可替代的
AI
游戏引擎
搜索引擎 (现在 java 性能也赶上来不少,也有 java 实现的版本了...)
交易系统 (股票,基金,外汇,期货...)
操作系统级的开发
...................
挑战者,Rust,尝试挑战 C++ 的生态位
走高性能的路线
主打优势,能够很好的应对内存错误问题
(内存泄露,内存访问越界...)
Rust 通过特殊的语法,在编译期做检查的。
假设代码写出内存泄露,编译通过不了
目前,Rust 发展下来,也变的语法非常复杂了
为什么GC 会影响执行效率?因为触发 GC 的时候,可能会涉及到 STW 问题
stop the world 世界都停止
- GC 回收的内存区域是哪个部分呢?
IVM
程序计数器
元数据区
栈
堆 => GC 主要回收这个区域
- GC 的目的是为了释放内存,是以字节为单位"释放"嘛?
不是的,而是以"对象为单位"
正在使用的内存 不回收
不再使用(尚未回收) 不回收
没有使用的区域 回收
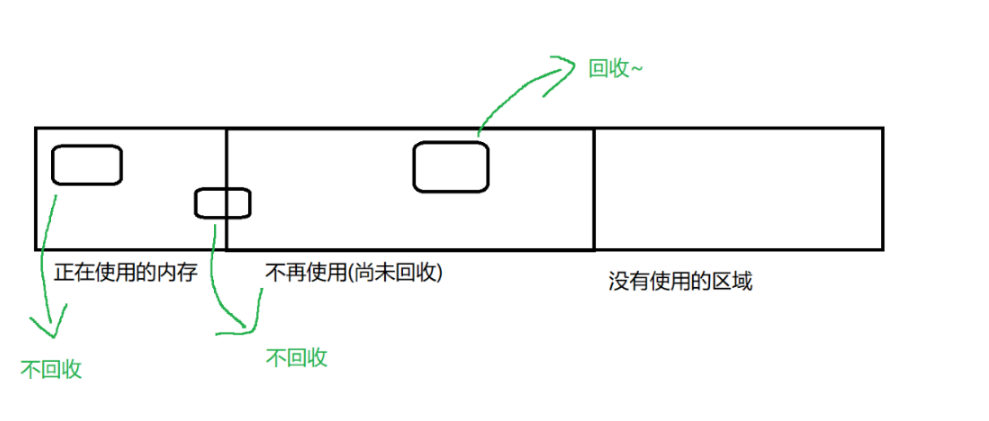
按照对象为维度进行回收,更简单方便。
如果是按照"字节维度",就可能针对每个对象都得描述出哪部分需要回收,哪部分不需要。比较麻烦了。
堆上的内存 => new 的对象
- 如何回收?
-
找出垃圾,区分出哪些对象是垃圾(后续代码不再使用)
-
释放这些垃圾对象的内存
如何"找出垃圾" ?
由于在 Java 中使用对象,都是通过 "引用" 来进行的,使用对象,无非是使用对象的属性/方法,都要通过对象的引用进行。.前面的部分就是指向对象的引用。
如果一个对象已经没有任何引用指向它了,此时这个对象就注定无法被使用了。
判断一个对象是否是垃圾这个问题比较抽象,因此我们将其转换成判断是否有引用指向这个对象,这样子问题就比较具体了。
JVM 内部是有一些办法可以做到的以上这种解决方案的,周大佬 《深入理解 Java 虚拟机》 这本书介绍了两种方案:
*面试的时候,区分好,看面试官是咋问的:
-
让你介绍下 垃圾回收 中如何判定对象是垃圾的 两个方案都可以介绍
-
让你介绍 JVM 中如何判定对象是垃圾的 别说引用计数
-
引用计数(Java 没有使用,Python,PHP... 采用的方案)
简单粗暴的方案。
给每个对象都分配了一个 "计数器"
- 引用计数 Java 没有使用,Python,PHP... 采用的方案
简单粗暴的方案。
给每个对象都分配了一个 "计数器"
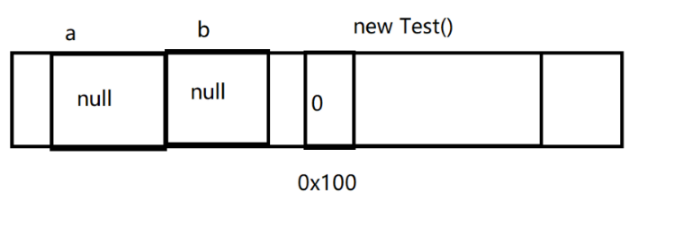
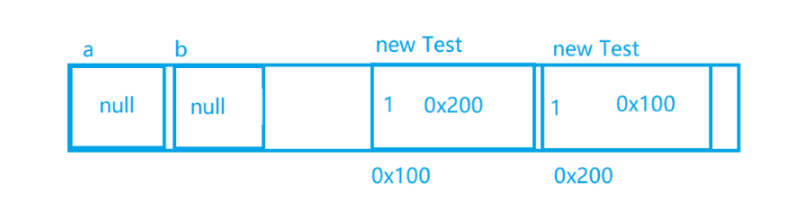
Test a = new Test();
Test b = a;
a = null;
b = null;
当引用计数为 0,此时对象就没有任何引用指向了。
对象就是 垃圾了
Python / PHP 等语言
会搭配其他垃圾回收机制,识别当前的引用是否构成循环引用
两个弊端
- 消耗额外的内存空间较大。
如果对象本身很小(就 4 个字节)
计数器占了俩字节,相当于额外的内存空间多了 50%
- 循环引用问题 (类似于死锁)
class Test {
Test t;
}
Test a = new Test();
Test b = new Test();
a.t = b
b.t = a
此时,这俩对象的引用计数是 1,不能释放。
但是,这俩对象却无法通过任何引用来访问到。
AB 相互证明对方不是垃圾
实际上 AB 都是垃圾
以下是图中的文字内容:
```
- 可达性分析 Java 使用的方案
在 Java 代码中,每个 "可访问的对象" 一定是可以通过一系列的引用操作,访问到的。
Node build() {
Node a = new Node();
Node b = new Node();
Node c = new Node();
Node d = new Node();
Node e = new Node();
Node f = new Node();
Node g = new Node();
a.left = b;
a.right = c;
b.left = d;
b.right = e;
e.left = g;
c.right = f;
return a;
}
Node root = build(); 构建二叉树
此时通过 root 这个引用,是可以访问到这个树上的任何一个对象的
此时通过 root 这个引用,是可以访问到这个树上的任何一个对象的
root => a
root.left => b
root.left.left => d
root.left.right.left => g
...........
假设,写 root.right.right = null
这样的代码会使 f 无法被访问到(f 已经没有引用指向了)
假设,写 root.right = null
这样的代码使 c 不可达。由于 f 必须依赖 c,f 也一起不可达
JVM 安排专门的线程,负责上述的 "扫描" 的过程
会从一些特殊的引用开始扫描 (GC roots)
-
栈上的局部变量 (引用类型)
-
常量池里指向的对象 (final 修饰的,引用类型)
-
元数据区 (静态成员,引用类型)
这三组里可能有很多变量
以这些变量为起点,尽可能的往里访问所有可能被访问到的对象
但凡被访问到的对象,都 "标记为可达"
JVM 又能够知道所有的对象列表,去掉 "标记为可达的",剩下的就是垃圾了
不引入额外的内存空间
但是需要消耗较多的时间,进行上述扫描过程,这些过程中也是容易触发STW的
(时间换了空间)
另外这里也不会涉及到 "循环引用"
如何释放垃圾 (回收内存)
关于内存回收,涉及到几种算法.
- 标记 - 清除
标记,就是可达性分析,找到垃圾的过程.
清除,直接释放这部分的内存(相当于直接调用 free / delete 释放这个内存给操作系统)
存在内存碎片问题
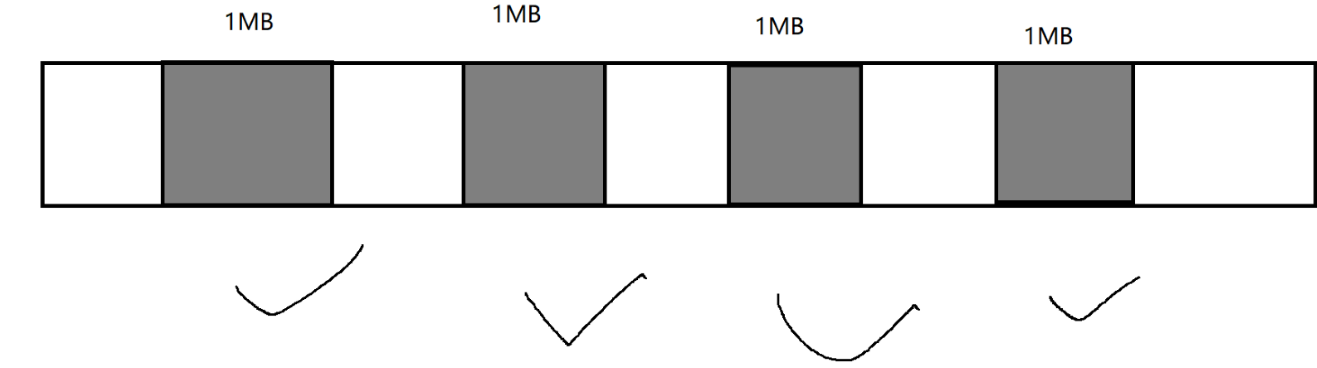
总的空闲内存空间,是比较多的 (一共 4MB)
但是这些空闲空间,不连续.
在申请内存的时候,都是在申请连续的内存空间
当尝试申请 2MB 的内存时候,就会申请失败
- 复制算法解 决内存碎片
把不是垃圾的对象,复制到另外一侧
把整个空间都释放掉
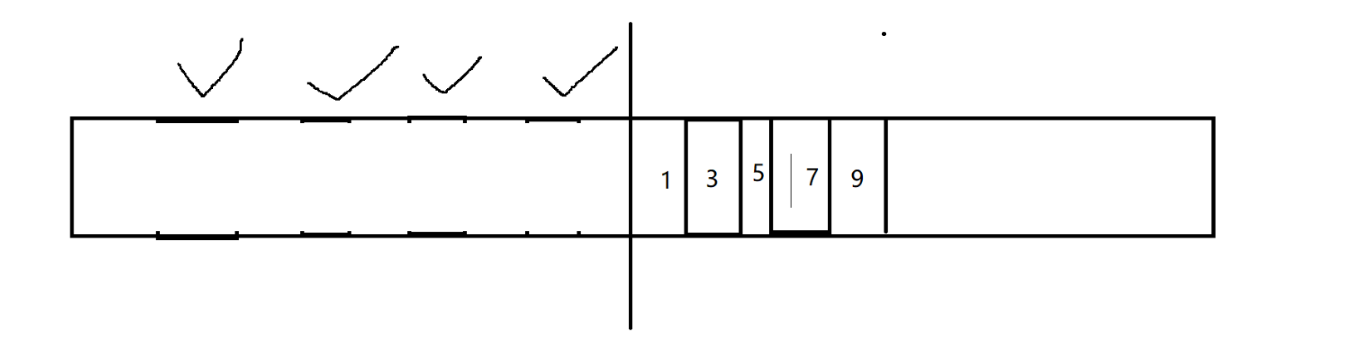
很好的解决了内存碎片问题。
弊端:
-
内存浪费比较多
-
如果存活的对象比较多/比较大,复制开销非常明显的
-
标记 - 整理 类似于顺序表删除元素 - 搬运元素
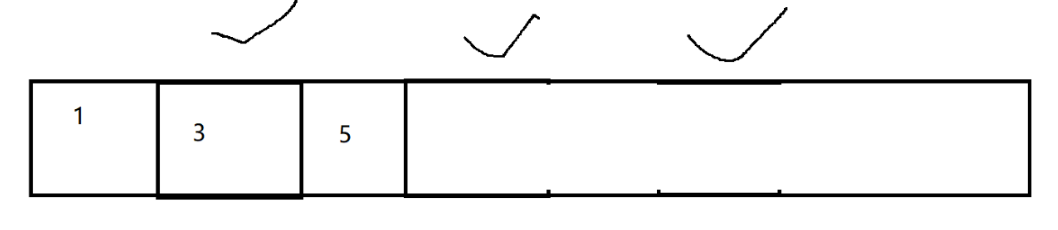
- 分代回收 (综合方案), 把上述几个方案,结合起来,扬长避短
整个堆空间,分成 "新生代" "老年代"
年轻对象 年老对象
年龄:一个对象经过垃圾回收扫描线程的轮次
对于年轻对象来说,是容易成为垃圾的。
年老对象,则不容易成为垃圾
可达性分析中,JVM 会不停使用线程扫描这些对象是否是垃圾。每隔一定时间,扫描一次。如果一个对象扫描一次,不是垃圾,年龄就 + 1。一般来说年龄超过 15 (可以配) 的就进入老年代。
"要死早死了"
比如 C 语言,已经存在了 50 年了,可以遇见到这个 C 语言还有很大的希望再活 50 年
> 和 C 语言同时期的 C++ 语言,都死的差不多...
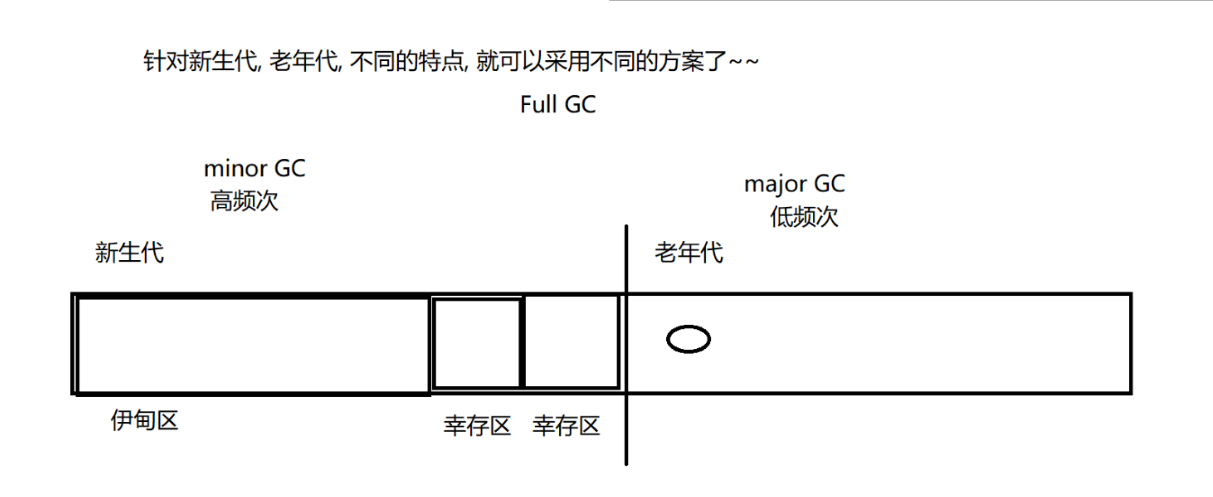
刚创建的新鲜对象放到伊甸区。如果对象活过一轮 GC,进入幸存区。
新对象,大多数是生命周期非常短的 "朝生夕死",经验规律。这俩幸存区,同一时刻使用一个(相当于复制算法,分出两个部分)。每次经过一轮 GC,都会淘汰掉幸存区中的一大部分对象,把存活的对象和伊甸区中新存活下来的对象,复制算法拷贝到另一个幸存区。新生代非常适合复制算法的。
如果这个对象在新生代中存活多轮之后,就会进入老年代。老年代的对象由于生命周期大概率很长,没有必要频繁扫描。如果这个对象非常大,不适合使用复制算法了。直接进入老年代
老年代回收内存采取的是 标记-清除 / 标记-整理(取决于垃圾回收器的具体实现了)
主流垃圾收集器详解
1.G1垃圾收集器(GarbageFirst)
定位:自Java11起成为默认收集器,是目前最主流的垃圾收集器。
核心特点:
采用分区堆(Region)设计,将堆内存划分为多个大小相等的块(通常为1MB~32MB)。
通过优先回收垃圾最多的Region("GarbageFirst"策略)实现高效回收。
支持大内存(几十GB级别),同时保持可控的STW(StopTheWorld)停顿时间。
2.ZGC垃圾收集器(ZGarbageCollector)
定位:新一代低延迟收集器,未来可能逐步取代G1。
核心特点:
突破性低延迟,STW时间可控制在1ms以内。
同样采用分区堆设计,但通过染色指针(ColoredPointers)和读屏障(LoadBarriers)技术实现并发标记与整理。
支持超大堆内存(TB级别),适合现代高性能应用。