手机打电话时如何将通话对方的声音在手机上识别成文字
--本地AI电话机器人
上一篇:手机打电话时由对方DTMF响应切换多级IVR语音应答(一)
下一篇:手机打电话时由对方DTMF响应切换多级IVR语音应答(二)
- 一、前言
本篇章的内容采用阿里的FunASR的模型和运算库,采用纯离线的方式(模型库下载完毕并加载后,可以完全关闭Wifi和4G后再识别),进行手机本地的ASR(语音转文字)识别。
由于本次只选用FunASR的离线部分的模型库,App初次加载ASR时,会从服务器单独下载8.15M的armeabi平台的so动态库,以及208M的asr_offline与vad的模型文件。存放与手机本地sdcard中,供App进行加载和使用。
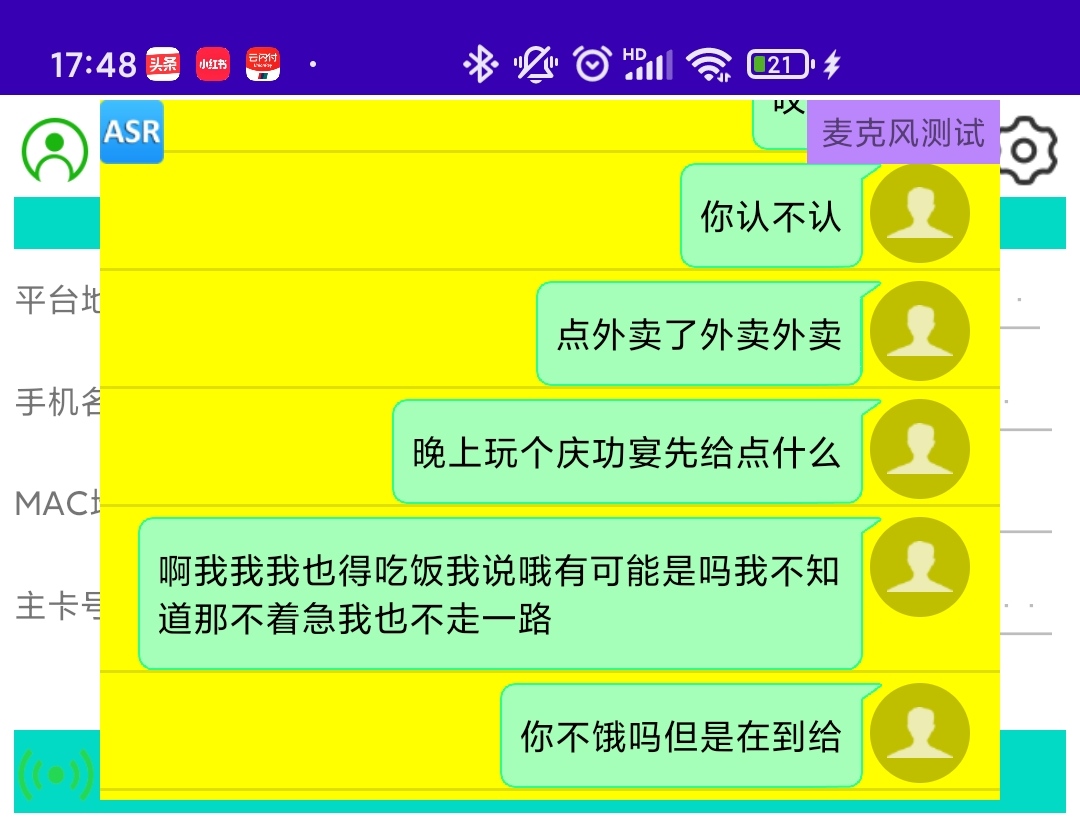
其实这个功能在2023年11月的时候已经在"智能拨号器App"中简单的调试了出来,效果也算勉强能看一看。但真正要达到商用的效果,还是得专项针对性的优化一番。在该App中的识别效果如下:
(由于FunASR的标点符号模型高达1.5G,太大了,此处不加载标点符号的模型)
智能拨号器App: http://120.78.211.195:8060/Dialer.apk
拨号器 SDK示例app :http://120.78.211.195:8060/sdk/SdkDemo.apk
USB蓝牙配件购买路径 (参考):https://item.taobao.com/item.htm?_u=pk10l4ccbcd&id=649368472986
- 二、目前业界的ASR识别的主流方向
业界内通常采用"端+云"的模式进行语音识别模块的运算,即:本地ASR通常采用轻量级的语音识别模型,能够处理简单的语音指令(如唤醒词、开灯/关灯等);而对于复杂的语音指令,则将语音信号上传至云端进行处理。
如下图的"车载语音的ASR识别"中,就将车载设备上接收到的语音数据,拆分为"本地ASR"和"云端ASR"两个部分。并将两个识别的结果已经对应的响应结果合并后,通过TTS模块进行语音的应答。
相关的"端+云"架构模式,可以参考下图:
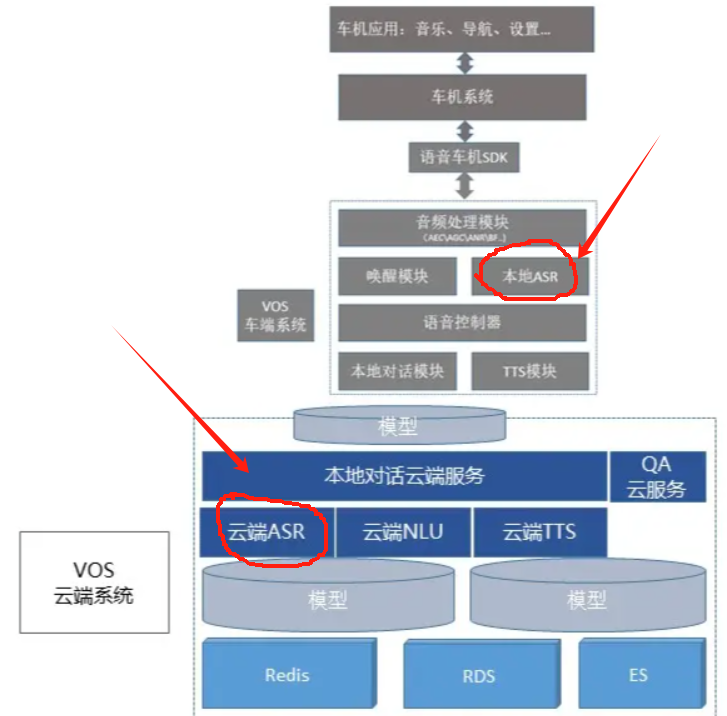
(图片来源:
《车载语音系统(VOS)的架构与技术实现》
在一个典型的"智能客服系统"的架构中,ASR识别引擎所处的架构大致为如下的位置:
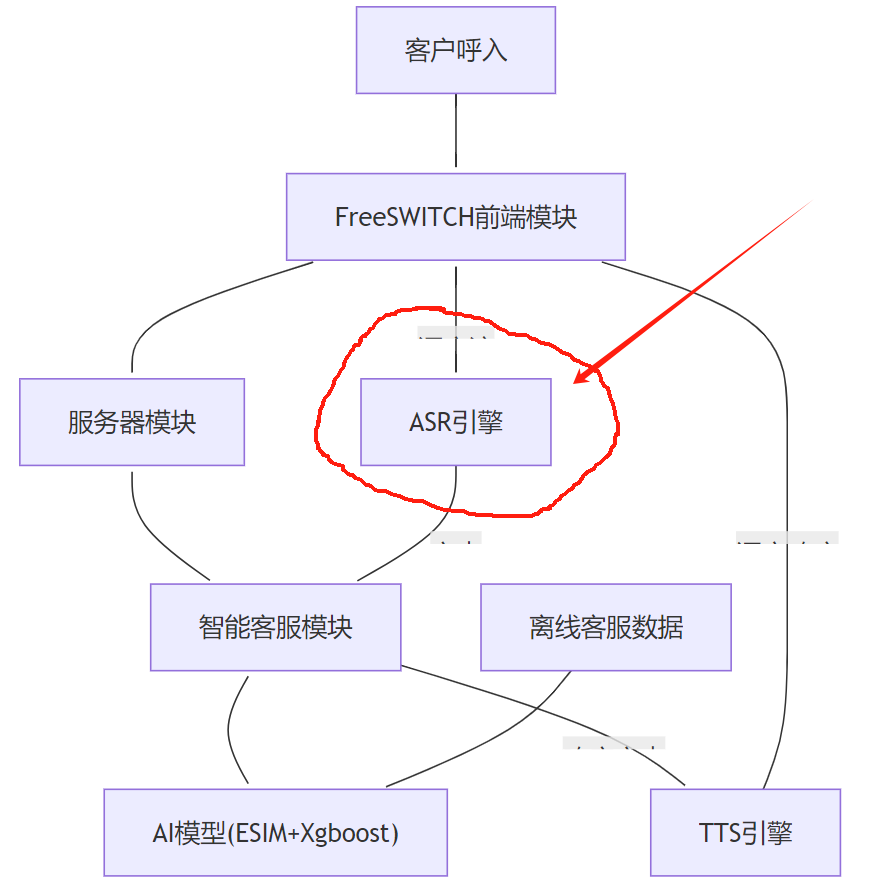
(图片来源:
《基于FreeSWITCH和AI的热门应用场景技术分析报告》
基于FreeSWITCH和AI的热门应用场景技术分析报告 )
- 三、ASR模型和库文件的加载
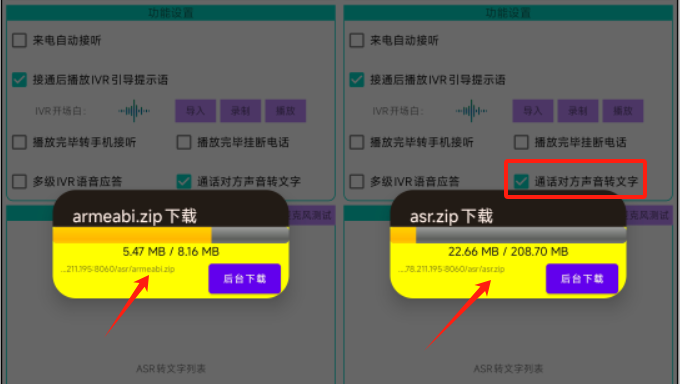
在SDK-Demo中,由于ASR识别使用的so动态库和模型库比较大,项目采用"动态加载"的方式,当界面中确实需要开启"通话对方声音转文字"的功能时,才主动从服务器拉取so库和ASR模型并进行加载。如下图所示:
(SDK-Demo的APK才4.3M,armeabi的so库就达8.15M,ASR仅离线模型就高达208M)
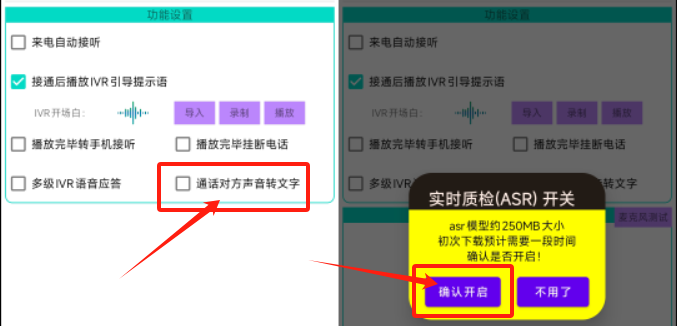
当界面中勾选对应的复选框后,App会判断是否之前已下载过该ASR模型库,若未下载则弹出【实时质检(ASR)开关】的提示框,由用户确认并手动下载对应的文件到手机本地SD卡。
用户确认开启后,将依次弹出两个异步的下载进度条框,依次下载【armeabi.zip】和【asr.zip】后并解压到SD卡的本地目录。供App做进一步的加载使用。如下图所示:
- 四、ASR的麦克风识别
App中,模型和so库下载并解压完毕后,SDK将对其进行动态加载。加载完毕后界面显示【通话语音实时ASR转文字】的区域。
用户可点击区域右侧的【麦克风测试】按钮(点击了之后文字显示就变为"停止录音"),进行手机本地的麦克风语音采集并根据这个语音数据进行ASR识别。识别后会同步将识别结果显示在【通话语音实时ASR转文字】的列表区域。如下图所示:
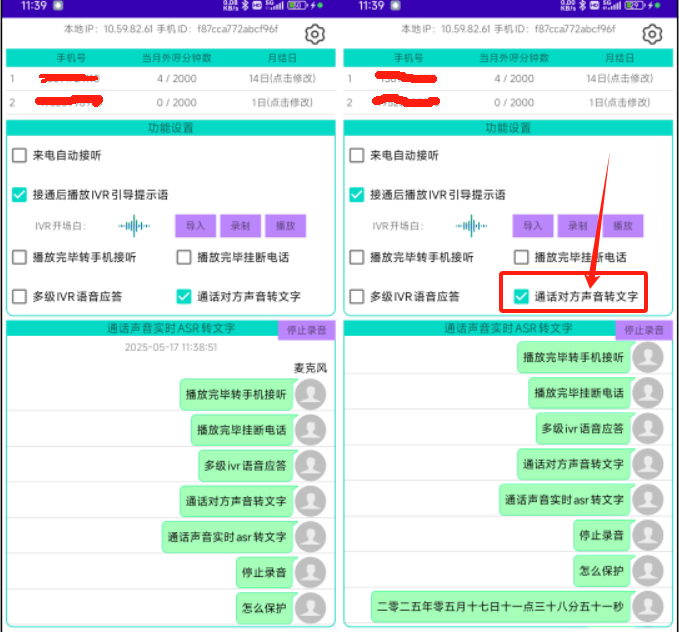
我们简单的使用汉语,对着麦克风念了几句话,识别结果可以参看图中的列表的内容。
可以看出,准确率还可以,但没有标点符号,并且识别效率太低。说完话之后要4-6秒才会识别出对应的结果。当前现状根本没法用在实时的商用场景。
- 五、ASR的电话通话识别
上一章讲述的是单上行通道(仅麦克风数据)的识别结果。我们简单的使用SDK-Demo的App,使用移动的手机卡来拨打10086和1008611这两个电话。
看看在App中"通话后播放IVR引导提示语"和"通话声音实时ASR转文字"的功能的识别和展示效果。如下图所示:
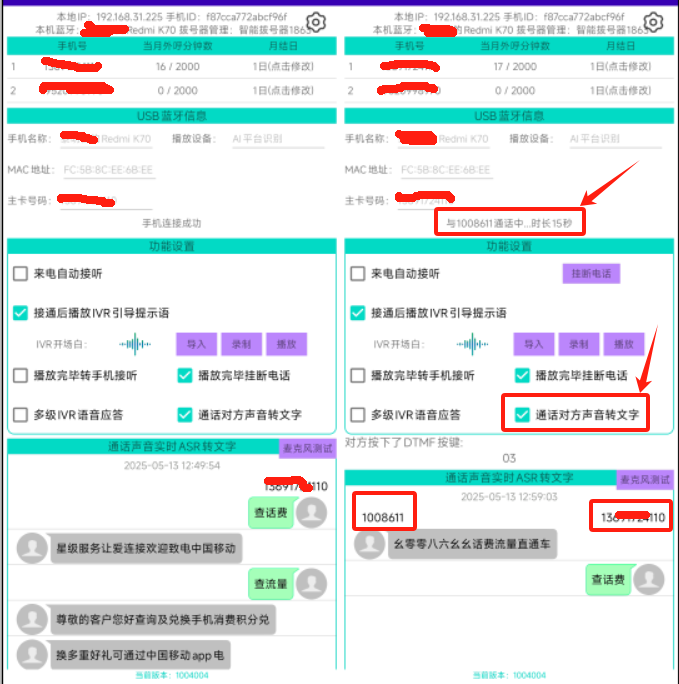
目前看来ASR的文字识别效果的准确率还可以。比如图片右侧的【136xxxxx110】号码,它说的话是在IVR中预先录制的"查话费/查流量/查余额"的语音。在识别过程中,ASR模型能够很好的识别我们往通话对方注入的语音,并转为文字进行展示。
通话列表左侧的10086和1008611返回的语音中,从文字内容来看,识别准确度应该还算可以,但有两点问题比较致命:
- 语音片段丢失,未被正常全部识别(估计可以通过加大缓冲区间来规避)
- 识别时效性太差,如上章所说,说一句话要4-6秒才会识别出结果,黄花菜都凉了。
- 六、总结
我们尝试在蓝牙电话SDK中,引入一些跟AI方向相关的算法和能力。本篇章中,我们想突破传统的业内"端+云"的做法,想仅仅依靠端侧的算力(毕竟智能手机处理性能这么强,存储空间又大)来独立完成ASR语音转文字的功能。
目前从实践的结果来看,算法和模型库不给力啊。当前暂时没有发现能够直接移植到手机、且完全不依赖网络,并能够获得比较良好的ASR识别的算法和模型库。
后面有机会的话,还是要深入挖掘这个方向,或者实在不行就随大流,部署一套"云"ASR识别的模型库,看看识别效果、实时性等的差异,进行整体对比。