K-means和GMM(高斯混合模型)两种聚类算法的特点
K-means
- non-probabilistic
- 根据距离判断
- 硬分类
- 球形簇
GMM
- probabilistic
- 根据后验概率判断
- 软分类
- 每一个类是一个高斯分布
- 椭圆形簇
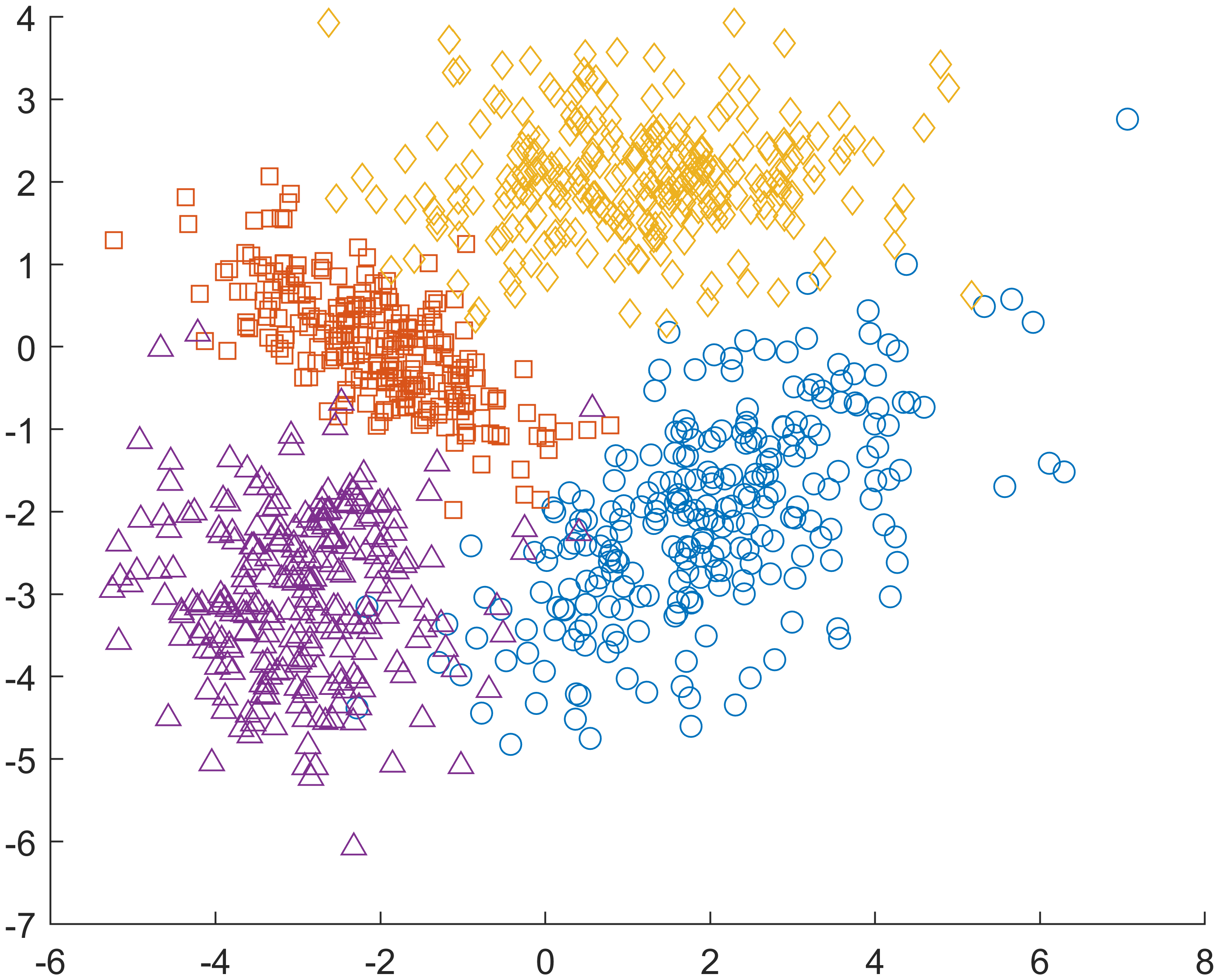
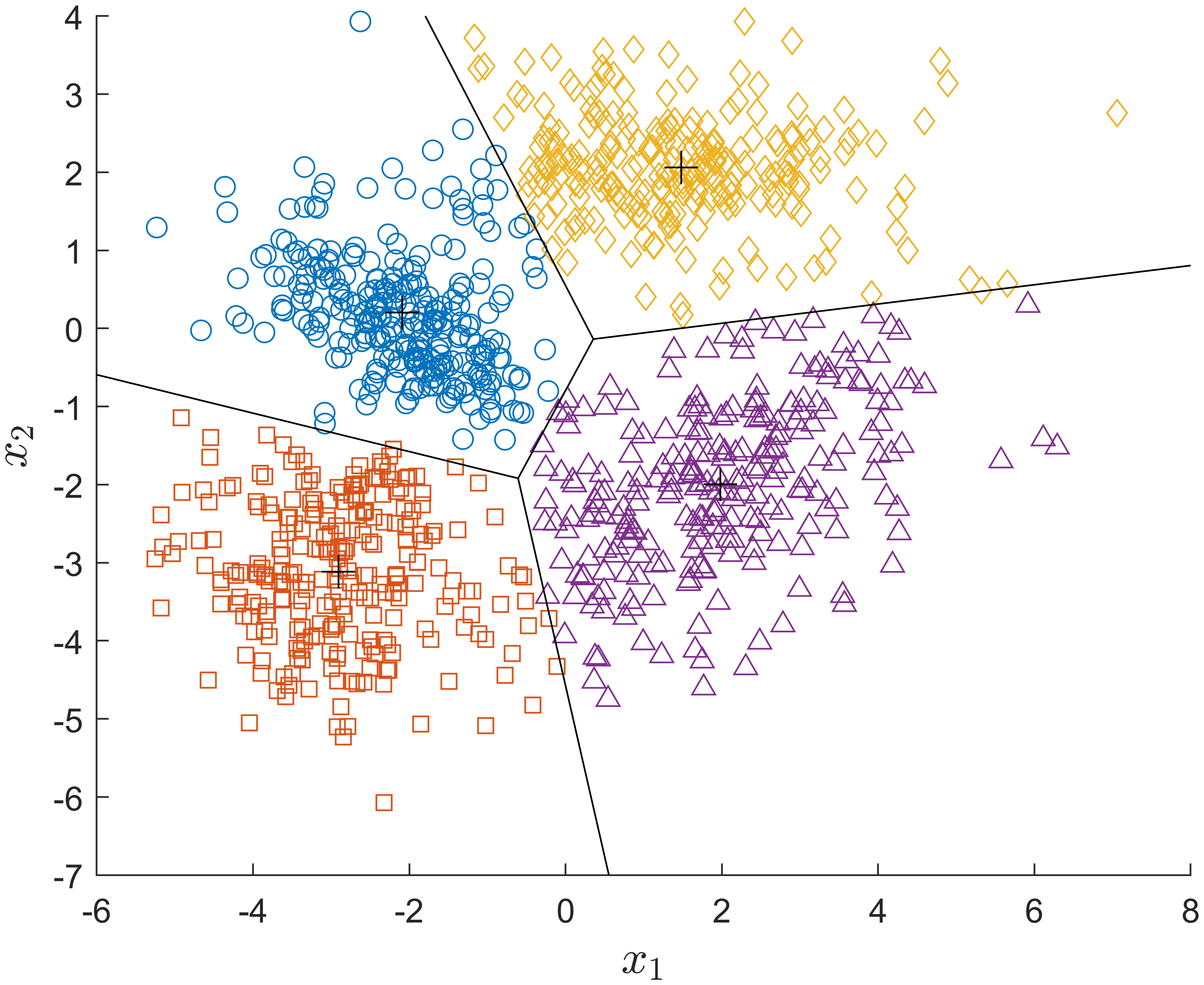
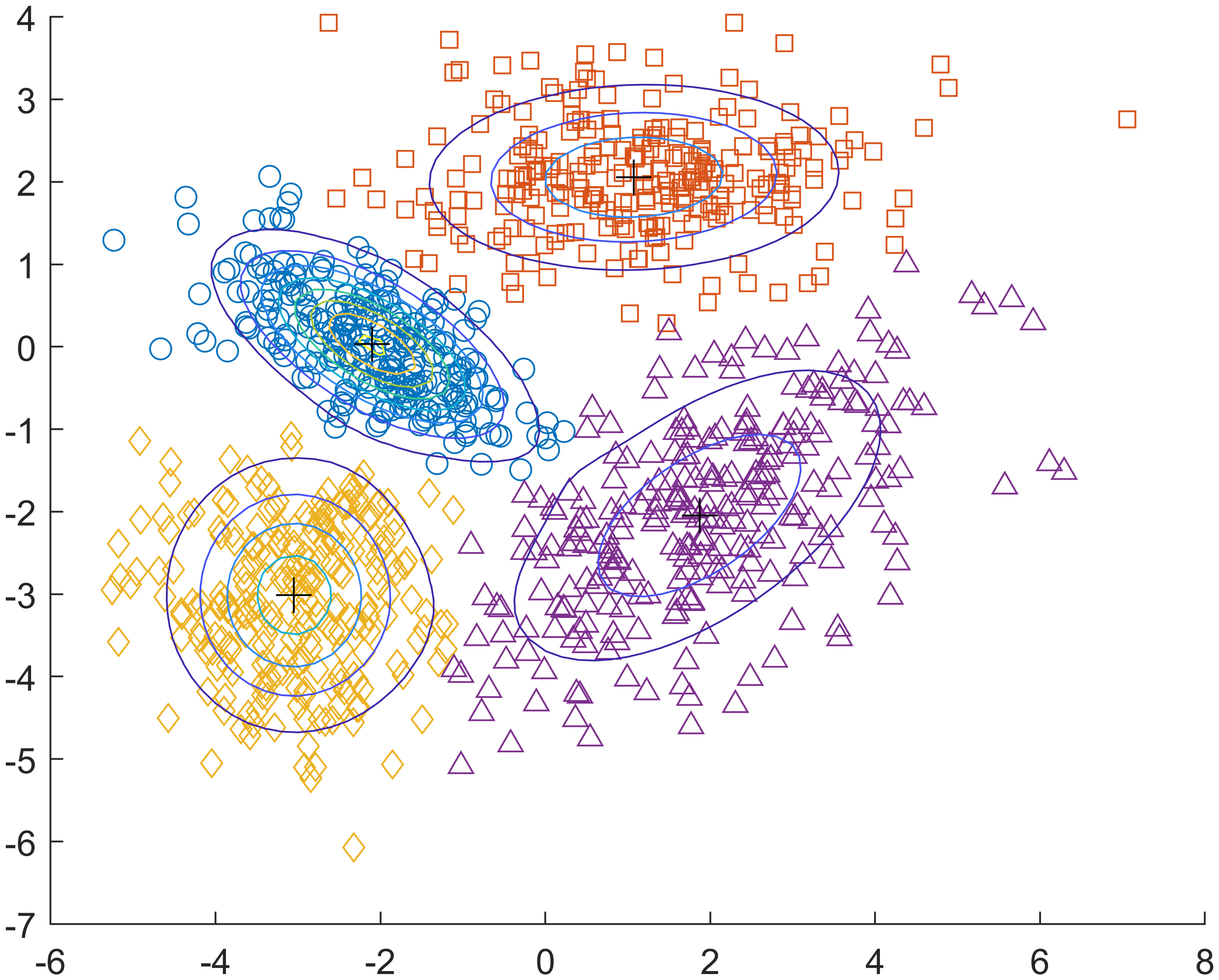
K均值可以看成是高斯混合模型的特例。
算法 K-Means
-
初始化 K K K, τ > 0 \tau > 0 τ>0和 { μ k ( 0 ) } k = 1 K \{\boldsymbol{\mu}k^{(0)}\}{k=1}^K {μk(0)}k=1K
-
repeat
-
E 步:更新簇分配
α i ( t + 1 ) ( k ) = { 1 , 若 k = arg min j = 1 , ⋯ , K ∥ x i − μ j ( t ) ∥ 2 0 , 否则 , i = 1 , ⋯ , n \alpha_i^{(t+1)}(k) = \begin{cases} 1, & \text{若 } k = \arg \min_{j=1,\cdots,K} \|{\bm x}_i - \boldsymbol{\mu}_j^{(t)}\|^2 \\ 0, & \text{否则} \end{cases}, \quad i=1,\cdots,n αi(t+1)(k)={1,0,若 k=argminj=1,⋯,K∥xi−μj(t)∥2否则,i=1,⋯,n -
M 步:更新簇中心
μ k ( t + 1 ) = ∑ i = 1 n α i ( t + 1 ) ( k ) x i ∑ i = 1 n α i ( t + 1 ) ( k ) , 对于 k = 1 , ⋯ , K \boldsymbol{\mu}k^{(t+1)} = \frac{\sum{i=1}^n \alpha_i^{(t+1)}(k) {\bm x}i}{\sum{i=1}^n \alpha_i^{(t+1)}(k)}, \quad \text{对于 } k=1,\cdots,K μk(t+1)=∑i=1nαi(t+1)(k)∑i=1nαi(t+1)(k)xi,对于 k=1,⋯,K -
计算得分:
J ( t + 1 ) = 1 n ∑ i = 1 n ∑ k = 1 K α i ( t + 1 ) ( k ) ∥ x i − μ k ( t + 1 ) ∥ 2 J^{(t+1)} = \frac{1}{n} \sum_{i=1}^n \sum_{k=1}^K \alpha_i^{(t+1)}(k) \|{\bm x}_i - \boldsymbol{\mu}_k^{(t+1)}\|^2 J(t+1)=n1i=1∑nk=1∑Kαi(t+1)(k)∥xi−μk(t+1)∥2 -
until ∣ J ( t + 1 ) − J ( t ) ∣ < τ |J^{(t+1)} - J^{(t)}| < \tau ∣J(t+1)−J(t)∣<τ
算法 使用EM和高斯混合模型聚类
-
初始化 K K K, τ > 0 \tau > 0 τ>0, { α k ( 0 ) , μ k ( 0 ) , Σ k ( 0 ) } k = 1 K \{\alpha_k^{(0)}, \mu_k^{(0)}, \Sigma_k^{(0)}\}_{k=1}^K {αk(0),μk(0),Σk(0)}k=1K
-
repeat
-
E步:更新簇成员
γ k ( t ) ( x i ) = α k ( t ) N ( x i ∣ μ k ( t ) , Σ k ( t ) ) ∑ k = 1 K α k ( t ) N ( x i ∣ μ k ( t ) , Σ k ( t ) ) \gamma_k^{(t)}({\bm x}_i) = \frac{\alpha_k^{(t)} \mathcal{N}({\bm x}i \mid \mu_k^{(t)}, \Sigma_k^{(t)})}{\sum{k=1}^K \alpha_k^{(t)} \mathcal{N}({\bm x}_i \mid \mu_k^{(t)}, \Sigma_k^{(t)})} γk(t)(xi)=∑k=1Kαk(t)N(xi∣μk(t),Σk(t))αk(t)N(xi∣μk(t),Σk(t)) -
M步:重新估计模型参数
μ k ( t + 1 ) = ∑ i = 1 n γ k ( t ) ( x i ) x i ∑ i = 1 n γ k ( t ) ( x i ) \mu_k^{(t+1)} = \frac{\sum_{i=1}^n \gamma_k^{(t)}({\bm x}_i) {\bm x}i}{\sum{i=1}^n \gamma_k^{(t)}({\bm x}i)} μk(t+1)=∑i=1nγk(t)(xi)∑i=1nγk(t)(xi)xi Σ k ( t + 1 ) = ∑ i = 1 n γ k ( t ) ( x i ) ( x i − μ ^ k ( t + 1 ) ) ( x i − μ ^ k ( t + 1 ) ) ⊤ ∑ i = 1 n γ k ( t ) ( x i ) \Sigma_k^{(t+1)} = \frac{\sum{i=1}^n \gamma_k^{(t)}({\bm x}_i) ({\bm x}_i - \hat{\mu}_k^{(t+1)}) ({\bm x}_i - \hat{\mu}k^{(t+1)})^ {\top} }{\sum{i=1}^n \gamma_k^{(t)}({\bm x}i)} Σk(t+1)=∑i=1nγk(t)(xi)∑i=1nγk(t)(xi)(xi−μ^k(t+1))(xi−μ^k(t+1))⊤ α k ( t + 1 ) = 1 n ∑ i = 1 n γ k ( t ) ( x i ) \alpha_k^{(t+1)} = \frac{1}{n} \sum{i=1}^n \gamma_k^{(t)}({\bm x}_i) αk(t+1)=n1i=1∑nγk(t)(xi) -
计算对数似然:
L ( { α k ( t + 1 ) , μ k ( t + 1 ) , Σ k ( t + 1 ) } k = 1 K ) = ∑ i = 1 n ln ( ∑ k = 1 K α k ( t + 1 ) N ( x i ∣ μ k ( t + 1 ) , Σ k ( t + 1 ) ) ) L(\{\alpha_k^{(t+1)}, \mu_k^{(t+1)}, \Sigma_k^{(t+1)}\}{k=1}^K) = \sum{i=1}^n \ln \left( \sum_{k=1}^K \alpha_k^{(t+1)} \mathcal{N}({\bm x}_i \mid \mu_k^{(t+1)}, \Sigma_k^{(t+1)}) \right) L({αk(t+1),μk(t+1),Σk(t+1)}k=1K)=i=1∑nln(k=1∑Kαk(t+1)N(xi∣μk(t+1),Σk(t+1))) -
until ∣ L ( { α k ( t + 1 ) , μ k ( t + 1 ) , Σ k ( t + 1 ) } k = 1 K ) − L ( { α k ( t ) , μ k ( t ) , Σ k ( t ) } k = 1 K ) ∣ < τ |L(\{\alpha_k^{(t+1)}, \mu_k^{(t+1)}, \Sigma_k^{(t+1)}\}{k=1}^K) - L(\{\alpha_k^{(t)}, \mu_k^{(t)}, \Sigma_k^{(t)}\}{k=1}^K)| < \tau ∣L({αk(t+1),μk(t+1),Σk(t+1)}k=1K)−L({αk(t),μk(t),Σk(t)}k=1K)∣<τ