改进模糊C均值时序聚类+编码器状态识别!IPOA-FCM-Transformer组合模型
目录
效果分析

基本描述
1.创新未发表!研究亮点!时序聚类+状态识别,IPOA-FCM-Transformer组合模型,运行环境Matlab2023b及以上。
2.excel数据,方便替换,先运行main1_IPOA-FCM对时序数据进行聚类、再运行main2_Transformer对聚类后的数据进行识别,其余为函数文件无需运行,可在下载区获取数据和程序内容,适用于交通、气象、负荷等领域。
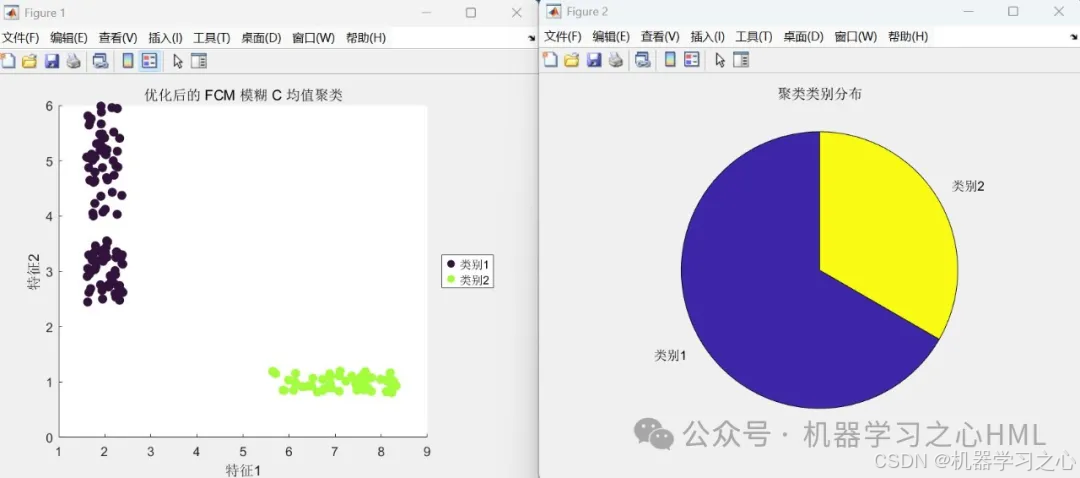
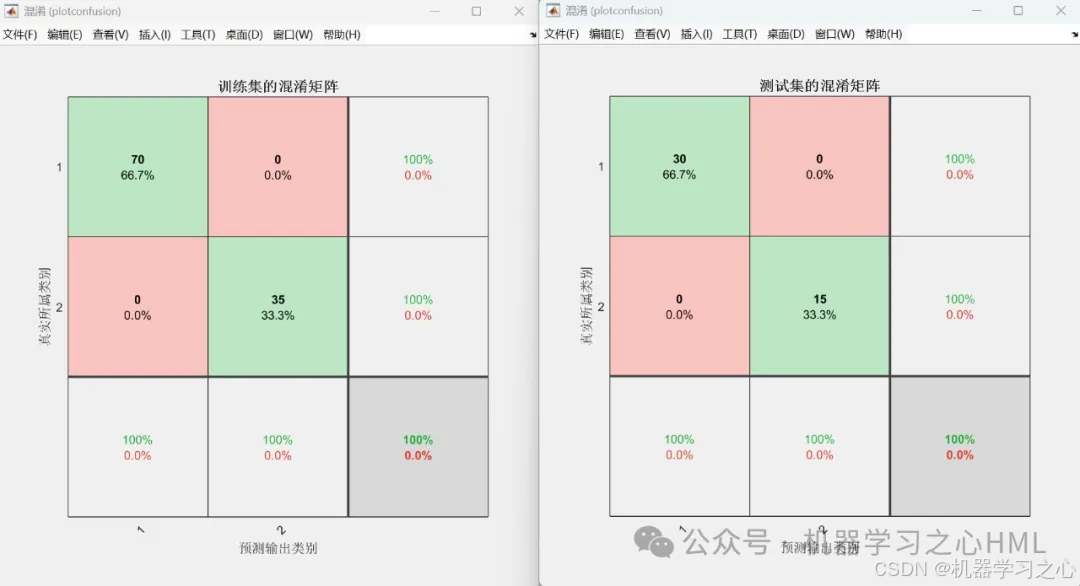
3.图很多,包括聚类效果图、分类识别效果图,混淆矩阵图。命令窗口输出分类准确率、灵敏度、特异性、曲线下面积、Kappa系数、F值。
4.附赠案例数据可直接运行main一键出图,注意程序和数据放在一个文件夹,运行环境为Matlab2023b及以上。
5.代码特点:参数化编程、参数可方便更改、代码编程思路清晰、注释明细。可在下载区获取数据和程序内容。
在MATLAB中,可以使用fcm函数实现FCM(Fuzzy C-Means)模糊C均值聚类。FCM是一种常用的聚类算法,它将每个数据点都分配到多个簇,根据隶属度来表示每个数据点属于不同簇的程度。改进的鹈鹕优化算法(IPOA)优化FCM模糊C均值聚类优化,优化参数模糊因子m、最大迭代次数。IPOA算法改进点如下:随机初始化种群、加入Levy飞行策略、动态参数调整。
代码实现的主要功能
main1_IPOA_FCM.m
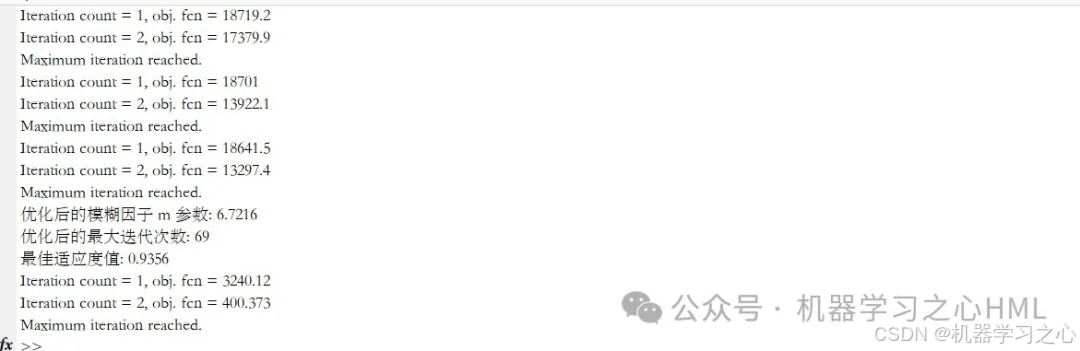
功能:通过改进的鹈鹕优化算法(IPOA)优化模糊C均值聚类(FCM)的参数(模糊因子 m 和最大迭代次数 maxIter),实现高效聚类,并可视化结果。
输出:优化后的聚类参数、聚类结果图、参数适应度三维关系图。
main2_Transformer.m
功能:基于聚类生成的标签,构建并训练Transformer模型,完成分类任务,评估模型性能。
输出:模型训练曲线、结果对比图、混淆矩阵、ROC曲线等性能指标。
算法流程与关键步骤
main1_IPOA_FCM.m
数据准备
读取数据集,转换为数值数组。
定义优化参数:模糊因子 m 和最大迭代次数 maxIter 的上下界。
IPOA优化
目标函数:通过FCM的聚类效果(如目标函数值或内部指标)评估参数质量。
优化过程:IPOA算法迭代搜索最优参数组合。
FCM聚类
使用优化后的参数重新运行FCM,生成聚类中心和隶属度矩阵。
根据隶属度分配样本到簇,统计各类样本数量。
可视化与分析
绘制聚类散点图、类别分布饼图。
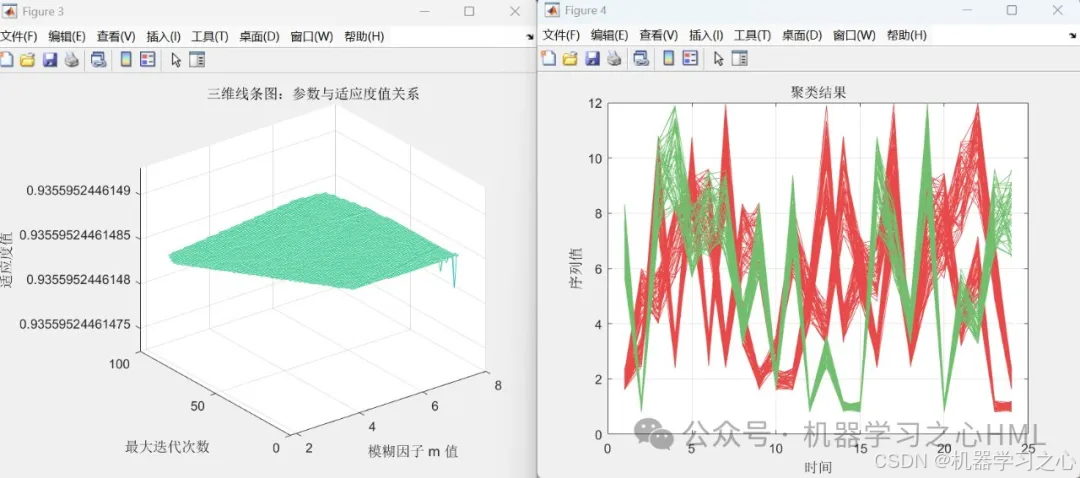
生成参数与适应度的三维关系图(插值平滑)。
main2_Transformer.m
数据预处理
划分训练集(70%)和测试集(30%)。
归一化数据,调整维度为适合Transformer输入的序列格式。
Transformer模型构建
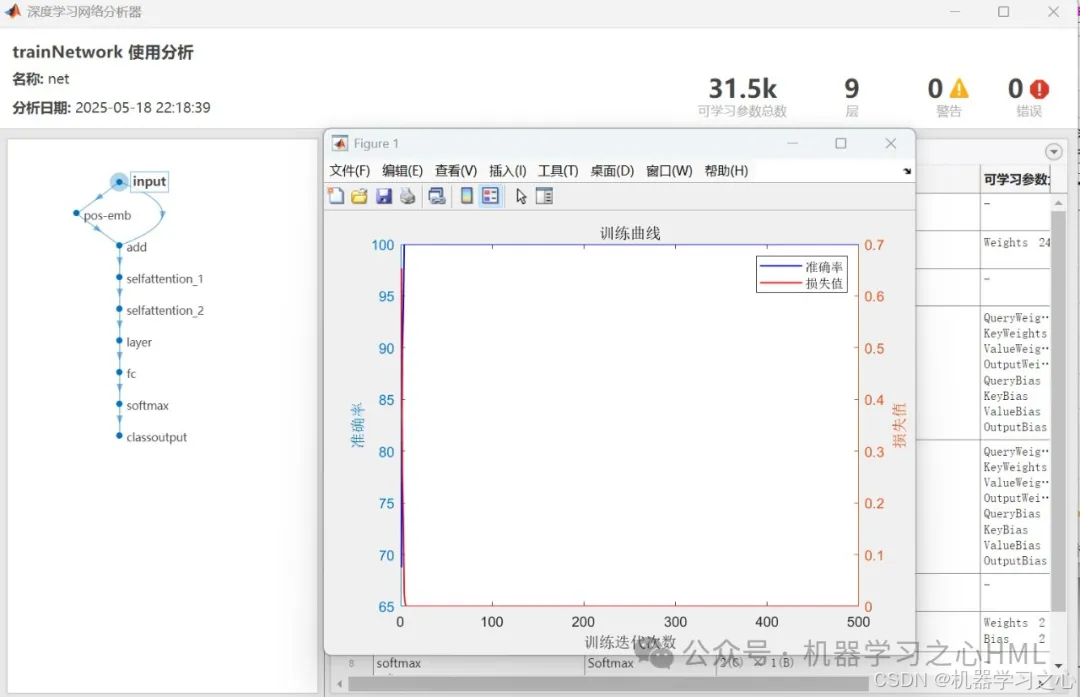
核心层:位置编码层(positionEmbeddingLayer)、自注意力层(selfAttentionLayer)、全连接层。
网络结构:输入序列 → 位置编码 → 自注意力 → 全连接分类。
模型训练与预测
使用Adam优化器,设置学习率调度策略。
训练模型并预测,输出分类结果。
性能评估
指标计算:训练集和测试集准确率。
可视化:训练曲线(准确率与损失值)、预测对比图、混淆矩阵、ROC曲线。
关键步骤总结
IPOA-FCM:通过群体智能优化算法动态调整聚类参数,提升FCM性能。
Transformer分类:将聚类结果作为监督信号,利用Transformer的序列建模能力完成分类任务。
端到端流程:从无监督聚类到有监督分类,实现数据驱动的建模与评估。
程序设计
- 完整程序和数据私信博主回复Matlab实现改进模糊C均值时序聚类+编码器状态识别!IPOA-FCM-Transformer组合模型。
clike
%% 清空环境变量
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc % 清空命令行
%% 分析数据
num_class = length(unique(res(:, end))); % 类别数(Excel最后一列放类别)
num_dim = size(res, 2) - 1; % 特征维度
num_res = size(res, 1); % 样本数(每一行,是一个样本)
num_size = 0.7; % 训练集占数据集的比例
% 标志位为1,打开混淆矩阵(要求2018版本及以上)
%% 设置变量存储数据
P_train = []; P_test = [];
T_train = []; T_test = [];
%% 划分数据集
for i = 1 : num_class
mid_res = res((res(:, end) == i), :); % 循环取出不同类别的样本
mid_size = size(mid_res, 1); % 得到不同类别样本个数
mid_tiran = round(num_size * mid_size); % 得到该类别的训练样本个数
end
%% 数据转置
P_train = P_train'; P_test = P_test';
T_train = T_train'; T_test = T_test';
%% 得到训练集和测试样本个数
M = size(P_train, 2);
N = size(P_test , 2);
%% 数据归一化
[P_train, ps_input] = mapminmax(P_train, 0, 1);
P_test = mapminmax('apply', P_test, ps_input);
t_train = categorical(T_train)';
t_test = categorical(T_test )';
%% 数据平铺
% 将数据平铺成1维数据只是一种处理方式
% 也可以平铺成2维数据,以及3维数据,需要修改对应模型结构
% 但是应该始终和输入层数据结构保持一致
P_train = double(reshape(P_train, num_dim, 1, 1, M));
P_test = double(reshape(P_test , num_dim, 1, 1, N));
%% 数据格式转换
for i = 1 : M
p_train{i, 1} = P_train(:, :, 1, i);
end
for i = 1 : N
p_test{i, 1} = P_test( :, :, 1, i);
end
%网络搭建
numChannels = num_dim;
maxPosition = 256;
numHeads = 4;
numKeyChannels = numHeads*32;参考资料
1 https://blog.csdn.net/kjm13182345320/article/details/129036772?spm=1001.2014.3001.5502
2 https://blog.csdn.net/kjm13182345320/article/details/128690229