申通快递(STO Express)作为中国领先的综合物流服务商,自1993年创立以来,始终秉持"正道经营、长期主义"的发展理念,深耕快递物流领域,开创了行业加盟制先河。经过30余年的发展,申通已成长为国家5A级物流企业,并跻身《财富》中国500强及全国工商联"中国民营企业500强"榜单,成为A股上市企业。目前,申通构建了覆盖全国300余城市的物流网络,拥有独立网点超5,000个、服务站点及门店逾55,000个,业务范围延伸至全球150多个国家和地区,形成了仓、揽、转、运、派全链路一体化服务能力。
在数字化时代,申通加速推进"数智化+网点生态"战略,通过技术创新与精细化运营提升服务效率。其科技力以多级信息安全防控体系为基底,保障万亿级包裹数据安全,同时依托全网数智化升级实现全链路降本增效。例如,漳州传化公路港枢纽的投用显著提升了闽南区域分拨效率,而AI预测模型则助力网点库存与路由规划的动态优化。此外,申通通过"五星五力"服务体系(运营力、体验力、差异力、价格力、科技力)深化客户合作,为商家提供定制化解决方案,满足从仓配一体化到即时配送的多元化需求。
通过对这些服务网点数据的深入分析,我们可以全面掌握申通快递在国内市场的布局特点与发展趋势。例如,通过分析各城市的网点密度、选址特征以及周边消费环境,可以精准洞察不同地区的物流需求差异,为申通未来的服务优化、新网点开设规划以及市场拓展策略提供有力的数据支持与决策依据。同时,用户也可以借助这些数据,方便快捷地查询到最近的申通快递网点,实现快速寄件或预约上门取件服务,极大地提升了用户体验。
申通快递网点位置查询:申通快递官网
我们第一步先找到服务网点数据的存储位置,然后看3个关键部分标头、 负载、 预览;
**标头:**通常包括URL的连接,也就是目标资源的位置;
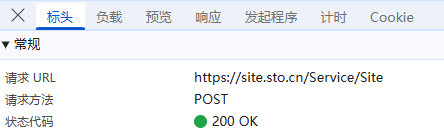
**负载:**对于POST请求:负载通常包含了传递的参数,这里我们可以看到它的传参包括各级行政区名称,是明文传输;
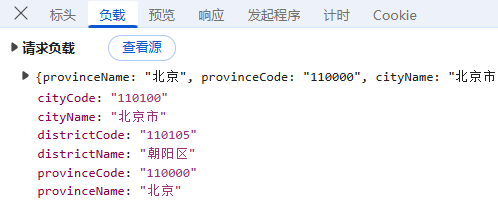
**预览:**指的是对响应内容的快速查看或摘要显示,可以帮助用户快速了解返回的数据结构或内容片段;
接下来就是数据获取部分,先讲一下方法思路,一共三个步骤;
方法思路
- 找到对应行政区划树的数据存储位置,生成一个行政区对应关系字典;
- 我们通过改变查询负载的内容(各级行政区名称),来遍历全国服务网点数据,获取所有服务网点的相关标签数据;
- 坐标转换,通过coord-convert库实现GCJ-02转WGS84;
**第一步:**通过页面测试发现,申通服务网点查询页面采用的策略是,通过三级行政区明文这样的结构数据,进行查询的;

接下来,我们找到行政区划树的数据存储位置,通过脚本把数据另存为本地json,通过读取json的三级行政区字典进行遍历全国服务网点信息;
完整代码#运行环境 Python 3.11
python
import requests
import json
import os
def fetch_and_save_area_tree_json_simplified():
url = "https://site.sto.cn/Service/AreaTree"
method = "POST"
headers = {
"accept": "application/json, text/plain, */*",
"referer": "https://www.sto.cn/",
"user-agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Mobile Safari/537.36 Edg/136.0.0.0",
"Content-Type": "application/json"
}
payload = {} # 空的 JSON 负载
area_tree_data = None # 用于存储解析后的数据
filename = "sto_area_tree_data.json" # 指定保存的文件名
try:
print(f"正在发送 {method} 请求获取行政区划数据: {url}")
response = requests.post(url, headers=headers, json=payload)
response.raise_for_status() # 检查HTTP状态码,非2xx会抛出异常
print(f"成功收到响应,状态码: {response.status_code}")
# 尝试解析JSON
try:
area_tree_data = response.json()
print("响应解析为 JSON 成功。")
except json.JSONDecodeError as e:
print(f"错误: JSON解析失败: {e}")
print(f"原始响应内容 (部分):\n{response.text[:500]}{'...' if len(response.text) > 500 else ''}")
# JSON解析失败,area_tree_data 将保持 None
except requests.exceptions.RequestException as e:
print(f"错误: 请求发生错误: {e}")
if hasattr(e, 'response') and e.response is not None:
print("错误状态码:", e.response.status_code)
#print("错误响应体:", e.response.text) # 简化,不打印错误响应体
# 请求失败,area_tree_data 将保持 None
except Exception as e:
print(f"错误: 发生未知错误: {e}")
# 发生其他错误,area_tree_data 将保持 None
# --- 保存数据到JSON文件 ---
if area_tree_data is not None:
try:
print(f"正在将数据保存到文件: {filename}")
with open(filename, 'w', encoding='utf-8') as f:
json.dump(area_tree_data, f, ensure_ascii=False, indent=4)
print(f"数据已成功保存到 {filename}")
except Exception as e:
print(f"错误: 保存文件时发生错误: {e}")
else:
print("未获取到有效行政区划数据,不保存文件。")
if __name__ == "__main__":
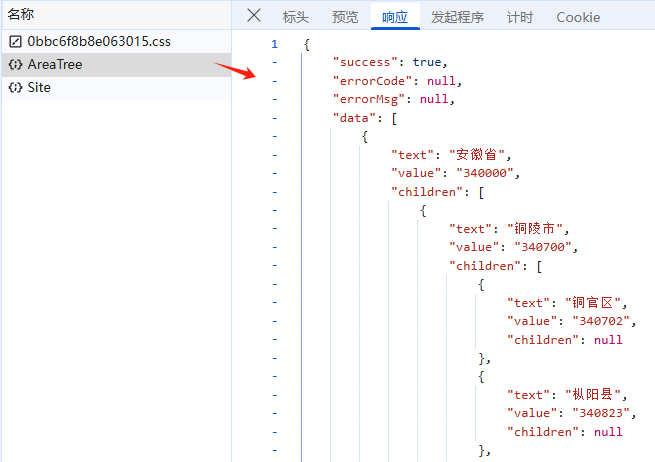
fetch_and_save_area_tree_json_simplified()等待脚本执行完成,将输出一个json文件sto_area_tree_data.json,为了更直观的展示,我们可以复制json里面的数据,并放在json可视化的工具里进行展示,这里用的在线工具是编辑器 | JSON For You | 在线JSON工具,我们可以看到三级行政区及其行政区编码;

**第二步:**读取之前生成的JSON文件,并使用这些数据来查询第三级(网点)信息,并根据标签进行保存,另存为csv;
方法思路
- 读取本地的 sto_area_tree_data.json 行政区划文件;
- 遍历该文件的层级结构,提取每个区县的名称和代码;
- 对于每个区县,调用申通的网点查询 API;
- 收集所有区县的网点数据;
- 将汇总的所有网点数据保存到一个 CSV 文件。
完整代码#运行环境 Python 3.11
python
import requests
import json
import pandas as pd
import os
import time # 导入 time 库用于添加延迟
# --- 文件路径配置 ---
AREA_TREE_FILE = "sto_area_tree_data.json" # 行政区划数据文件
OUTPUT_CSV_FILE = "all_sto_sites_data.csv" # 汇总保存的网点数据文件
# --- API 配置 ---
SITE_API_URL = "https://site.sto.cn/Service/Site"
SITE_API_HEADERS = {
"accept": "application/json, text/plain, */*",
"referer": "https://www.sto.cn/",
"user-agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Mobile Safari/537.36 Edg/136.0.0.0"
}
# --- 网点查询相关函数 ---
def fetch_sto_site_data(payload):
"""
发送请求获取申通网点数据。
返回一个列表(如果成功)或 None。
"""
url = SITE_API_URL
headers = SITE_API_HEADERS
try:
# print(f"正在请求数据,地区: {payload.get('provinceName', '')}-{payload.get('cityName', '')}-{payload.get('districtName', '')}") # 简化打印
response = requests.post(url, headers=headers, json=payload)
response.raise_for_status() # 检查HTTP状态码,非2xx会抛出异常
site_data_list = response.json()
# 检查解析结果是否为列表
if isinstance(site_data_list, list):
# print(f" -> 成功获取 {len(site_data_list)} 条网点数据。") # 简化打印
return site_data_list
else:
print(f" -> 警告: API返回数据结构与预期不符(不是列表)。原始响应前200字符: {response.text[:200]}{'...' if len(response.text) > 200 else ''}")
return None
except requests.exceptions.RequestException as e:
print(f" -> 请求发生错误: {e}")
return None
except json.JSONDecodeError:
print(" -> 错误: 无法解析响应为 JSON 格式。")
print(f" -> 原始响应内容前200字符: {response.text[:200]}{'...' if len(response.text) > 200 else ''}")
return None
except Exception as e:
print(f" -> 发生未知错误: {e}")
return None
def save_data_to_csv(data_list, filename):
"""
将数据列表保存到 CSV 文件。
"""
if not data_list:
print("没有数据可保存到 CSV。")
return
try:
df = pd.DataFrame(data_list)
df.to_csv(filename, index=False, encoding='utf-8-sig')
print(f"所有网点数据已成功保存到 {filename}")
except Exception as e:
print(f"保存 CSV 文件时发生错误: {e}")
# --- 行政区划数据处理函数 ---
def load_area_tree_data(filename=AREA_TREE_FILE):
"""
从本地 JSON 文件加载行政区划数据。
"""
if not os.path.exists(filename):
print(f"错误: 行政区划数据文件未找到: {filename}")
print("请先运行获取行政区划数据的脚本来生成此文件。")
return None
try:
print(f"正在从文件加载行政区划数据: {filename}")
with open(filename, 'r', encoding='utf-8') as f:
full_data = json.load(f)
print("行政区划数据加载成功。")
# 检查顶层结构并提取 data 列表
if isinstance(full_data, dict) and full_data.get("success") is True and isinstance(full_data.get("data"), list):
return full_data.get("data") # 返回 data 键对应的列表
else:
print("错误: 行政区划数据文件结构与预期不符(未找到 success=True 的字典或 data 列表)。")
# 可以打印部分数据结构帮助调试
# print(f"文件内容顶层键: {list(full_data.keys()) if isinstance(full_data, dict) else '非字典'}")
return None
except json.JSONDecodeError:
print(f"错误: 无法解析文件 {filename} 为 JSON 格式。")
return None
except Exception as e:
print(f"加载行政区划文件时发生错误: {e}")
return None
# 修改 traverse_area_tree 函数以匹配新的 JSON 结构 ("text", "value", "children")
def traverse_area_tree(data_list, current_province=None, current_province_id=None, current_city=None, current_city_id=None):
"""
遍历行政区划树数据,找到区县级别并生成其信息。
数据结构假设:[ { "text": "省", "value": "省ID", "children": [ { "text": "市", "value": "市ID", "children": [...] } ] } ]
Args:
data_list: 当前层级的行政区划列表。
current_province: 当前处理到的省级名称。
current_province_id: 当前处理到的省级ID。
current_city: 当前处理到的市级名称。
current_city_id: 当前处理到的市级ID。
Yields:
dict: 包含区县信息的字典 (provinceName, provinceCode, cityName, cityCode, districtName, districtCode)
"""
if not isinstance(data_list, list):
return # 不是列表则停止遍历当前分支
for item in data_list:
if not isinstance(item, dict):
continue
# 使用新的键名: "text" -> 名称, "value" -> ID, "children" -> 子节点列表
area_id = item.get("value")
area_name = item.get("text")
child_areas = item.get("children") # get() 返回 None 如果键不存在或值为 null
if area_name is None or area_id is None:
continue
# 根据嵌套层级判断省市县
# 注意直辖市的数据结构可能特殊,例如北京市下直接是区
if current_province is None: # 第一级:省/直辖市
# 确保 children 是列表,如果为 null 或非列表则跳过该分支
if isinstance(child_areas, list):
yield from traverse_area_tree(child_areas, current_province=area_name, current_province_id=area_id)
elif current_city is None: # 第二级:市 (对于直辖市,这层可能不存在或直接是区)
# 检查 children 是否为列表。如果是列表,继续遍历市下面的区县
# 如果 children 不是列表(比如为 null),则说明当前 area_name 可能已经是区县了(处理直辖市结构如北京、上海等)
if isinstance(child_areas, list):
yield from traverse_area_tree(child_areas, current_province=current_province, current_province_id=current_province_id, current_city=area_name, current_city_id=area_id)
else: # 如果第二级的 children 不是列表,则假设当前 item 就是一个区县
# 这适用于 省(直辖市) -> 区县... 的结构
# 此时,我们将市级名称和代码设置为与省级相同,或者根据实际API要求处理
# 这里设置为与省级相同,因为网点查询API需要cityCode和cityName
yield {
"provinceName": current_province,
"provinceCode": current_province_id,
"cityName": current_province, # 对于直辖市,市名通常与省名相同
"cityCode": current_province_id, # 对于直辖市,市代码通常与省代码相同
"districtName": area_name, # 当前项是区县名
"districtCode": area_id # 当前项是区县代码
}
else: # 第三级:区县 (在 省 -> 市 -> 区县 结构下)
# 这是标准的区县层级,不需要再检查 children
yield {
"provinceName": current_province,
"provinceCode": current_province_id,
"cityName": current_city,
"cityCode": current_city_id,
"districtName": area_name,
"districtCode": area_id
}
# --- 主执行逻辑 ---
def fetch_all_sto_sites():
"""
获取所有申通网点的数据,遍历区县并查询。
"""
all_site_data = [] # 存储所有网点数据
# 1. 加载行政区划数据
# load_area_tree_data 现在会返回 data 键下的列表
area_data_list = load_area_tree_data(AREA_TREE_FILE)
if area_data_list: # 检查 load_area_tree_data 是否成功返回列表
# 2. 遍历行政区划数据,获取区县列表
print("\n正在遍历行政区划数据,查找区县...")
district_payloads = []
# 调用遍历函数,并收集区县信息
for district_info in traverse_area_tree(area_data_list):
district_payloads.append(district_info)
print(f"找到 {len(district_payloads)} 个区县需要查询。")
# 在开始查询前,先创建一个空的CSV文件(参考您的代码)
save_data_to_csv([], OUTPUT_CSV_FILE)
# 3. 遍历区县列表,查询网点数据
if district_payloads:
print("\n开始按区县查询网点数据...")
total_districts = len(district_payloads)
# 可以选择只处理部分区县进行测试
# district_payloads = district_payloads[:10] # 只处理前10个区县
for i, payload in enumerate(district_payloads, 1):
print(f"\n处理第 {i}/{total_districts} 个区县: {payload.get('provinceName')}-{payload.get('cityName')}-{payload.get('districtName')}...")
site_data_for_district = fetch_sto_site_data(payload)
if site_data_for_district:
print(f" -> 获取到 {len(site_data_for_district)} 条网点数据。")
# 为每个网点数据添加查询时使用的省市县信息
for site in site_data_for_district:
site['ProvinceName_Query'] = payload.get('provinceName')
site['ProvinceCode_Query'] = payload.get('provinceCode')
site['CityName_Query'] = payload.get('cityName')
site['CityCode_Query'] = payload.get('cityCode')
site['DistrictName_Query'] = payload.get('districtName')
site['DistrictCode_Query'] = payload.get('districtCode')
# 将当前区县的数据直接保存到CSV,而不是全部收集后再保存
# 这可以避免一次性加载大量数据到内存,参考您提供的代码结构
try:
df_district = pd.DataFrame(site_data_for_district)
# 使用 append 模式 'a',header=False 表示不写入头部(第一次写入时会写入)
df_district.to_csv(OUTPUT_CSV_FILE, mode='a', header=not os.path.exists(OUTPUT_CSV_FILE) or os.stat(OUTPUT_CSV_FILE).st_size == 0, index=False, encoding='utf-8-sig')
print(f" -> 已追加 {len(site_data_for_district)} 条数据到 {OUTPUT_CSV_FILE}")
except Exception as e:
print(f" -> 错误: 保存区县数据到 CSV 时发生错误: {e}")
# 添加延迟,避免请求过快
time.sleep(0.2) # 延迟 0.2 秒,可以根据需要调整
print("\n所有区县网点数据查询完成。")
# 注意:由于是按区县追加保存,all_site_data 列表不再需要,最终结果在CSV文件中
else:
print("未找到区县信息,跳过网点查询。")
else:
print("行政区划数据加载失败,无法进行网点查询。")
print("\n程序执行完毕。")
if __name__ == "__main__":
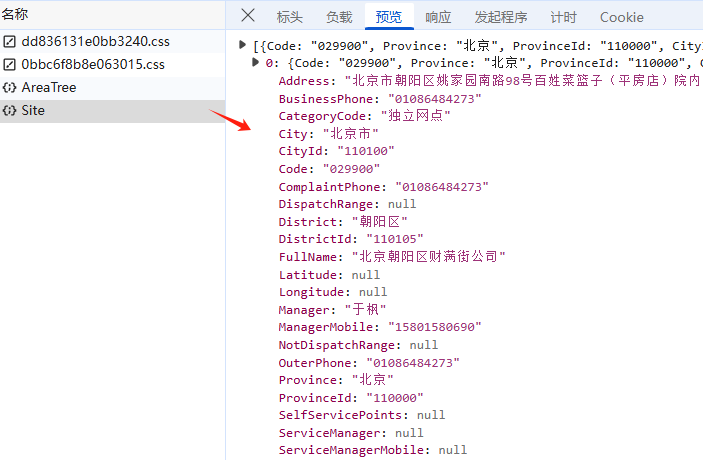
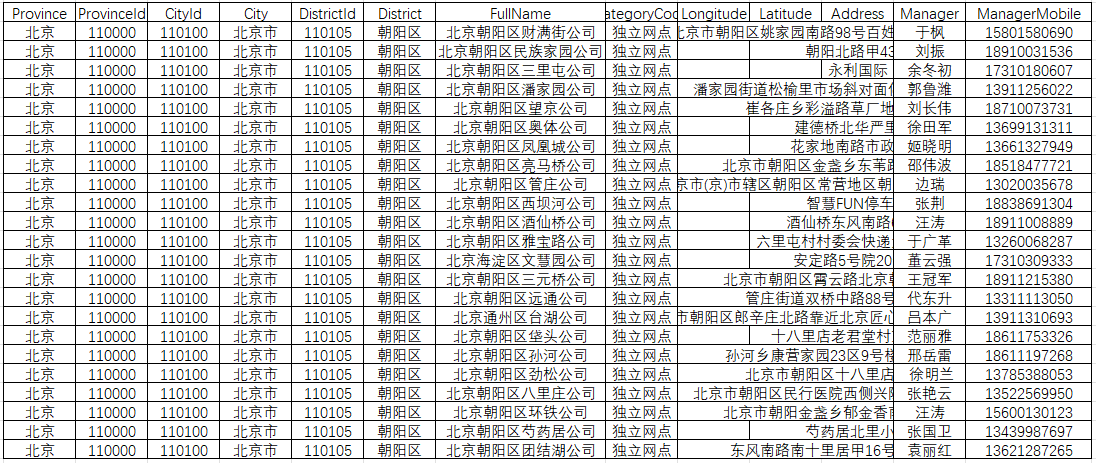
fetch_all_sto_sites()获取数据标签如下,Province(行政区)、ProvinceId(行政区编码)、CityId(市级编码)、City(市级)、 DistrictId(县级编码)、District(县级)、FullName(服务点名称)、Longitude,Latitude(坐标)、Address(详细地址)、Manager(经理)、ManagerMobile(经理电话),其他一些非关键标签,这里省略;
第三步: 地理编码和坐标系转换,这里因为我们获取的坐标系为空,需要把获取的门店地址进行地理编码,具体实现方法可以参考我这篇文章:地址转坐标:利用高德API进行批量地理编码_高德地图api-CSDN博客;
这里直接下载转换结果,坐标系GCJ-02,当然还有个别地址描述太模糊的或者格式无法识别,会查不出坐标,手动查一下坐标即可,大部分还是可以查到的,因为当前坐标系是GCJ02,需要批量转成WGS84/BD09的话可以用免费这个网站:批量转换工具:地图坐标系批量转换 - 免费在线工具 (latlongconverter.online),也可以通过coord-convert库实现GCJ-02转WGS84;
对CSV文件中的服务网点坐标列进行转换。完成坐标转换后,再将数据导入ArcGIS进行可视化;
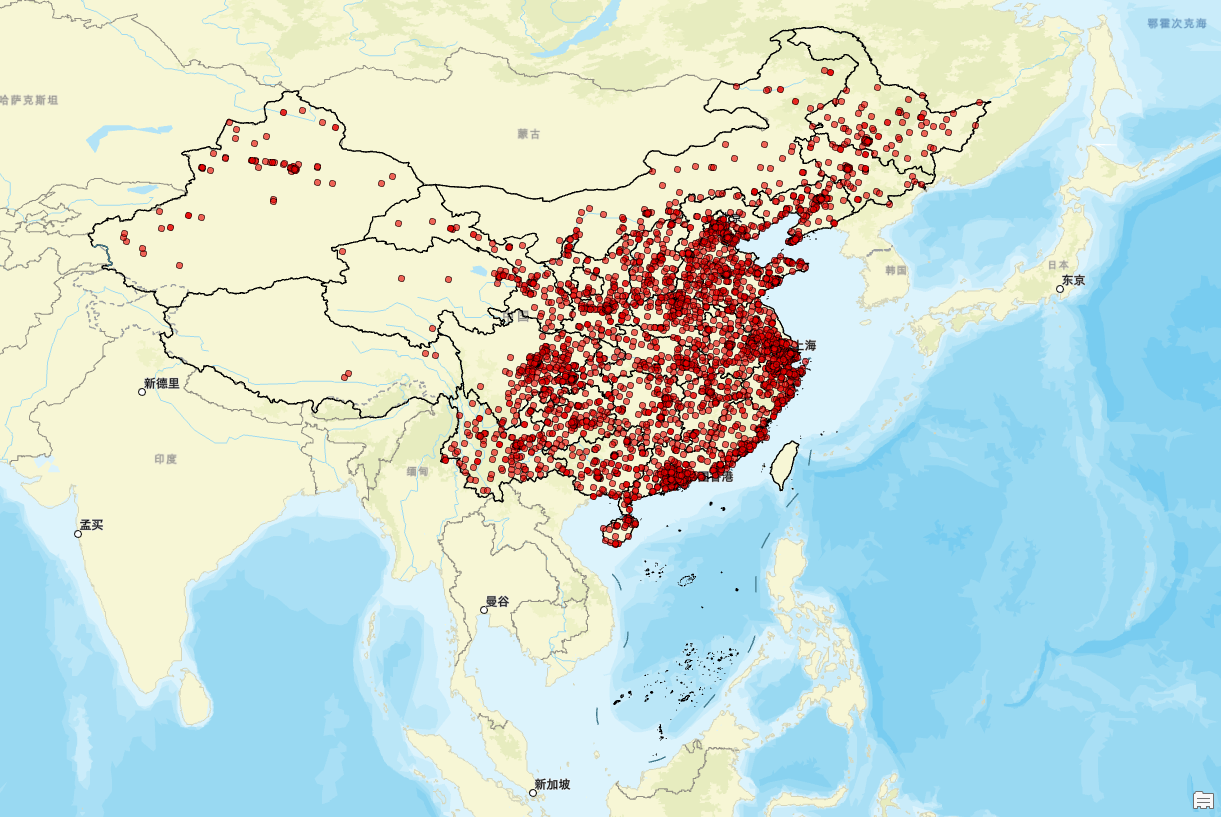
接下来,我们进行看图说话:
东部密集,西部稀疏: 在地图上可以清晰地看到,申通快递在东部沿海地区和中部地区的网点密度非常高。特别是在长三角、珠三角以及京津冀这样的经济核心区,网点几乎连成一片,显示出极高的覆盖度。这些区域不仅人口密集,而且商业活动频繁,是快递服务需求最大的地方。而在西部和北部,尤其是像西藏、新疆等边远省份,网点则显得零散得多,反映了这些地区相对较低的人口密度和经济发展水平。
城市集中,乡村覆盖: 大城市的中心及其周边地带,如北京、上海、广州等地,可以看到申通快递网点密布,形成了高效的服务网络。与此同时,在一些中小城市乃至乡镇,也有网点的存在,这表明申通正致力于扩大其在全国范围内的服务覆盖面,确保即使是较小的城市也能享受到便捷的快递服务。
交通干线沿线布局: 地图上的一个显著特点是,许多申通快递的网点都位于主要交通线路附近,比如高速公路旁或者铁路枢纽周围。这种布局策略有助于加快货物的运输速度,并提高整体物流效率,同时也便于与其他物流公司或节点之间的协作。
省会城市及重要交通枢纽是重点布局区域: 省会城市和其他重要的交通枢纽城市,例如武汉、成都等,拥有大量的申通快递网点。这些城市不仅是各自省份的政治、经济中心,也是物流的关键节点,因此成为了申通快递布局的重点区域。
边远地区和特殊地形区域分布较少: 对于那些地理位置偏远、地形复杂的地区,如山区或高原地带,申通快递的网点数量明显减少。然而,即便是在这些地方,通过与当地的合作或代理模式,仍然能够提供一定程度的服务,确保全国范围内都有一定的服务可达性。
文章仅用于分享个人学习成果与个人存档之用,分享知识,如有侵权,请联系作者进行删除。所有信息均基于作者的个人理解和经验,不代表任何官方立场或权威解读。