目录
[1. 应用程序分层](#1. 应用程序分层)
[1.1. 应用程序分层简介](#1.1. 应用程序分层简介)
[1.1.1. 三层结构](#1.1.1. 三层结构)
[1.1.2. 分层的优点](#1.1.2. 分层的优点)
[1.1.3. 分层命名](#1.1.3. 分层命名)
[1.2. 应用程序分层实现](#1.2. 应用程序分层实现)
[1.3. 在分层项目中实现查询业务](#1.3. 在分层项目中实现查询业务)
[2. 封装通用的BaseDao](#2. 封装通用的BaseDao)
[2.1. 封装通用的DML操作](#2.1. 封装通用的DML操作)
[2.2. 封装通用的查询操作](#2.2. 封装通用的查询操作)
[3. 总结](#3. 总结)
前言
本文讲解JDBC中的应用程序分层
个人主页:艺杯羹
系列专栏:JDBC
1. 应用程序分层
1.1. 应用程序分层简介
应用程序分层是指通过创建不同的包来实现项目的分层,将项目中的代码根据功能做具体划分,并存放在不同的包下
1.1.1. 三层结构
三层结构就是将整个业务应用划分为:表述层、业务逻辑层 、数据访问层(数据持久层)
区分层次的目的即为了"高内聚低耦合 "的思想。在软件体系架构设计中,分层式结构是最常见,也是最重要的一种结构
现在解释一下,什么是高内聚和低耦合
内聚 :模块内部各元素之间的关联紧密程度。那么高内聚,就是模块内各元素紧密关联,内部关联程度高
耦合 :模块之间相互依赖的程度。那么低耦合,就是模块之间的依赖程度低
1.1.2. 分层的优点
- 化繁为简 :分层将系统拆分成若干层,每一层解决部分问题,把大问题拆成独立子问题,降低单个问题的规模与复杂度,实现复杂系统关键分解
- 扩展灵活 :分层结构可扩展性佳,新增功能无需改动现有代码,利于业务逻辑复用,支撑系统演进
- 便于维护 :功能封装于不同层,层间耦合低,修改某层代码,只要接口不变,就不会严重影响其他层
1.1.3. 分层命名
表述层:web 或 controller
业务层:service
数据访问层:dao (Data Access Object)
数据访问层: 增删改查的操作,为业务层提供原始数据支持
业务逻辑层: 衔接表述层与数据层
**表述层:**展示处理结果
1.2. 应用程序分层实现
通过思维导图先看看这个包结构是怎样的
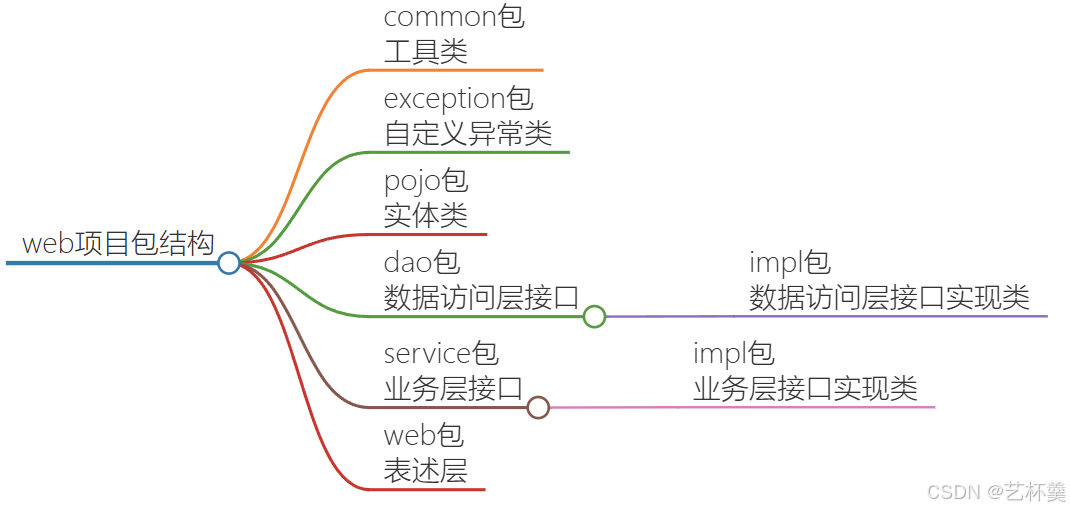
"pojo" 是 "Plain Old Java Objects" 的缩写,即简单的 Java 对象
"impl" 是 "implementation" 的缩写
"dao" 是 "Data Access Object" 的缩写,即数据访问对象
1.3. 在分层项目中实现查询业务
接下来通过这个包结构,来实现一个查询业务
可以先新建一个java项目,再把这些包创建好
为了更好的一个效果,我这里就先放出完成这个项目的图,现在只要创建包,和包一 一对应就好
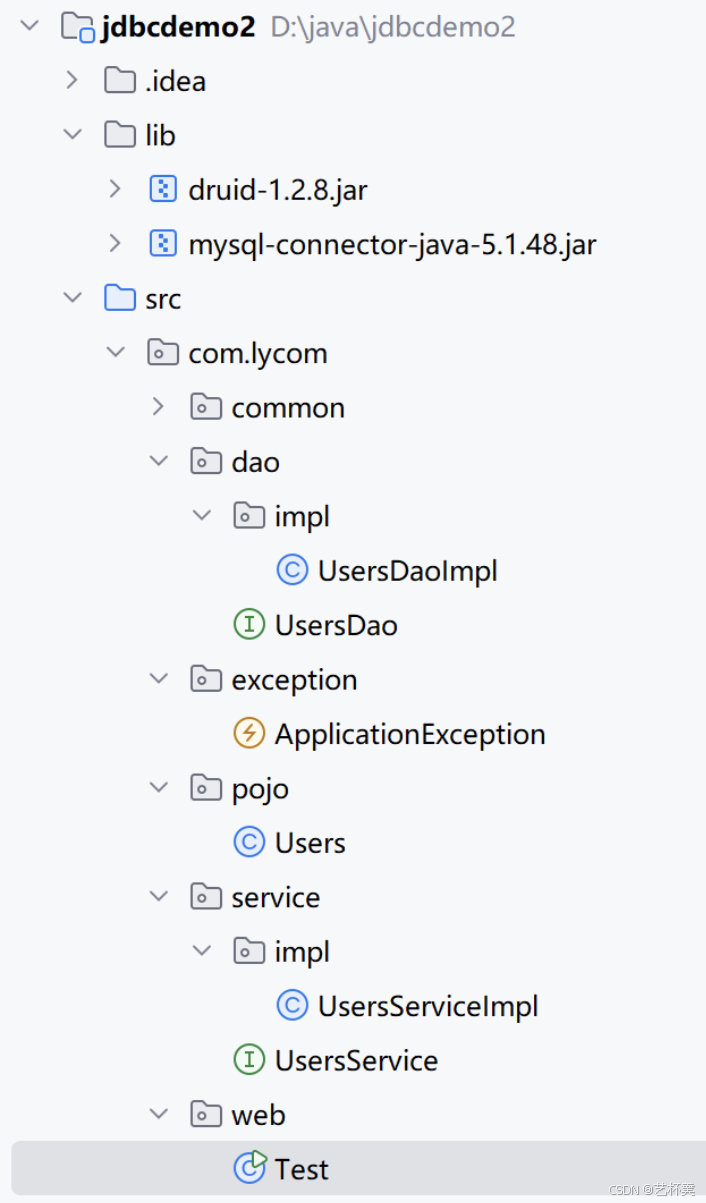
实现的业务为:根据用户ID查询用户业务
先讲一下要点:
-
写的顺序是:数据访问层 ----> 业务层 ----> 表示层
-
接口的命名要看操作的那张表
例如:UsersDao
接口的实现类命名,先写接口名,后面加Impl
对应接口即:UsersDao
-
在service包中为业务管理接口
要在后面加上service
例如:UsersService 用户管理 以service结尾
- 在dao包中写一个用户UserDao接口
java
public interface UsersDao {
// 根据用户ID查询用户
Users selectUsersById(int userid);
}- UserDaoImpl接口实现类
java
/**
* UsersDao接口的实现类,负责用户数据的数据库操作
*/
public class UsersDaoImpl implements UsersDao {
/**
* 根据用户ID查询用户信息
*
* @param userid 待查询的用户ID
* @return 包含用户信息的Users对象,如果未找到则返回null
* @throws ApplicationException 当数据库操作发生异常时抛出
*/
@Override
public Users selectUsersById(int userid) {
// 数据库连接资源
Connection conn = null;
PreparedStatement ps = null;
ResultSet rs = null;
Users users = null;
try {
conn = JdbcDruidUtil.getConnection();
ps = conn.prepareStatement("select * from users where userid = ?");
ps.setInt(1, userid);
rs = ps.executeQuery();
while (rs.next()) {
// 手动ORM映射:将数据库记录转换为Java对象
users = new Users();
users.setUserid(rs.getInt("userid"));
users.setUsername(rs.getString("username"));
users.setUserage(rs.getInt("userage"));
}
} catch (Exception e) {
e.printStackTrace();
throw new ApplicationException("查询用户信息失败: " + e.getMessage());
} finally {
JdbcDruidUtil.closeResource(rs, ps, conn);
}
return users;
}
}- 在service包中添加UserService接口
java
public interface UsersService {
Users findUsersById(int userid);
}- UserServiceImpl接口实现类
java
public class UsersServiceImpl implements UsersService {
/**
* 根据用户ID查询用户业务
* @param userid
* @return
*/
@Override
public Users findUsersById(int userid) {
// 实例化userdaoimpl对象
UsersDao ud = new UsersDaoImpl();
// 通过这个对象下的这个方法来返回结果
return ud.selectUsersById(userid);
}
}- 最终在web层中进行表现
java
public class Test {
public static void main(String[] args) {
// 实例化业务逻辑层的UsersServiceImpl类
UsersService us = new UsersServiceImpl();
// 给里面传输值
Users u = us.findUsersById(1);
// 最终做最后的显示
System.out.println(u);
}
}写完后,对应着那个表,就看的很明白了
都是一层一层调用的
2. 封装通用的BaseDao
封装通用的 BaseDao 是在数据访问层中,将各类数据操作(如增删改查等 DML 操作)中重复、共性的代码抽取整合,形成一个基础的数据访问接口或类。其他具体的 Dao(如 UserDao、ProductDao 等)可继承或实现它,从而复用通用的数据操作逻辑,减少代码冗余,提升开发效率,同时便于统一维护和管理数据访问相关的代码,确保数据操作的规范性和一致性
因为dao是数据访问层,而数据访问层就是实现增删改查的操作,所以接下来就封装这些操作
2.1. 封装通用的DML操作
- BaseDao接口
java
/**
* 在dao包里创建通用接口
*/
public interface BaseDao {
/**
* 通用的DML操作方法
*/
int executeUpdate(String sql,Object[] param);
}- BaseDaoImpl接口实现类
java
/**
* 通用接口实现类
*/
public class BaseDaoImpl implements BaseDao {
/**
* 通用的DML操作方法
*/
@Override
public int executeUpdate(String sql, Object[] param) {
Connection conn = null;
PreparedStatement ps = null;
int row;
try{
conn = JdbcDruidUtil.getConnection();
ps = conn.prepareStatement(sql);
// 得到参数的个数
ParameterMetaData pd = ps.getParameterMetaData();
// 循环一次,得到一个?的值
for(int i =0;i<pd.getParameterCount();i++){
ps.setObject(i+1,param[i]);
}
// 返回受影响的条数
row = ps.executeUpdate();
}catch (Exception e){
e.printStackTrace();
// 通过自定义异常解决异常耦合问题
throw new ApplicationException(e.getMessage());
}finally{
JdbcDruidUtil.closeResource(ps,conn);
}
return row;
}
}- UsersDao接口
java
public interface UsersDao extends BaseDao {
/**
* 根据用户ID查询用户
*
*/
Users selectUsersById(int userid);
/**
* 修改用户信息
*/
int updateUsersById(Users users);
}- UsersDaoImpl接口实现类
java
public class UsersDaoImpl extends BaseDaoImpl implements UsersDao {
/**
* 根据用户ID查询用户
* @param userid
* @return
*/
@Override
public Users selectUsersById(int userid) {
Connection conn =null;
PreparedStatement ps = null;
ResultSet rs = null;
Users users = null;
try{
conn = JdbcDruidUtil.getConnection();
ps = conn.prepareStatement("select * from users where userid = ?");
ps.setInt(1,userid);
rs = ps.executeQuery();
while(rs.next()){
// 手动orm映射
users = new Users();
users.setUserid(rs.getInt("userid"));
users.setUsername(rs.getString("username"));
users.setUserage(rs.getInt("userage"));
}
}catch(Exception e){
e.printStackTrace();
// 通过自定义异常解决异常耦合问题
throw new ApplicationException(e.getMessage());
}finally{
JdbcDruidUtil.closeResource(rs,ps,conn);
}
return users;
}
/**
* 修改用户信息
*/
@Override
public int updateUsersById(Users users) {
String sql = "update users set userage = ? where userid = ? ";
Object[] param = new Object[]{users.getUserage(),users.getUserid()};
return this.executeUpdate(sql,param);
}
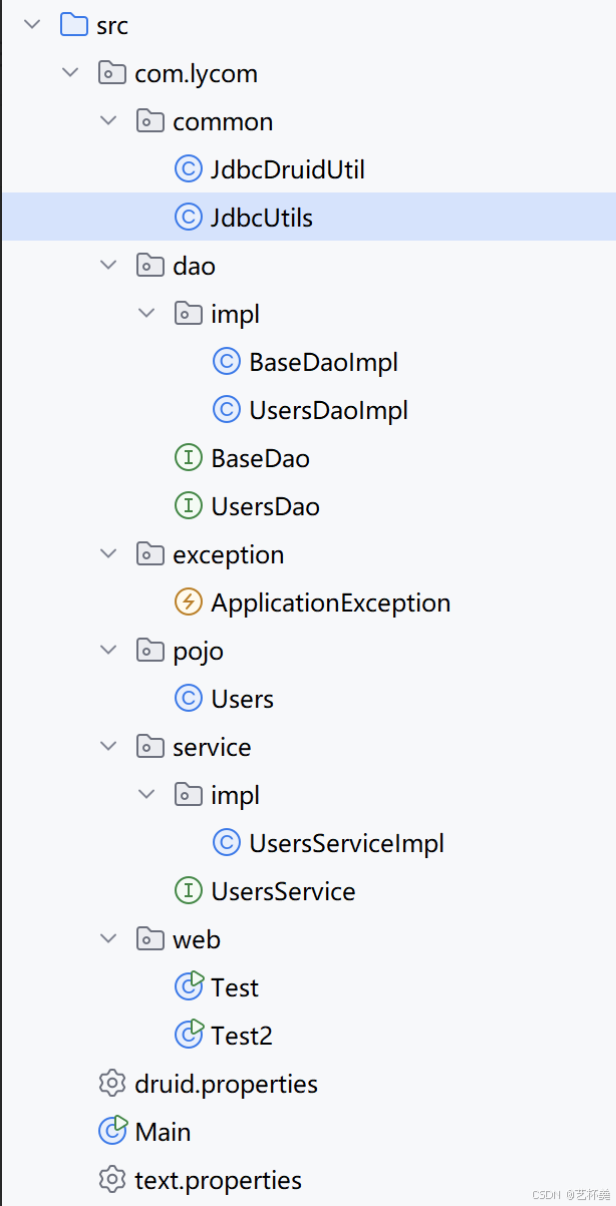
}最终在项目栏是这样的
2.2. 封装通用的查询操作
查询操作会更复杂一些
- BaseDao接口
java
/**
* 通用接口
*/
public interface BaseDao {
/**
* 通用的DML操作方法
*/
int executeUpdate(String sql,Object[] param);
/**
* 通用查询方法
* 要求:实体类的属性名必须要与表的列名相同。
*/
// 有可能返回一条或多条数据
// 此时,会泛型T会报错有两个解决方案
// 1, 在BaseDao后面加上<T>
// 2. 将这个方法转换成泛型,如下
<T> List<T> select(String sql,Object[] param,Class<T> clazz);
}- BaseDaoImpl接口实现类
java
/**
* 通用接口实现类
*/
public class BaseDaoImpl implements BaseDao {
/**
* 通用的DML操作方法
*/
@Override
public int executeUpdate(String sql, Object[] param) {
Connection conn = null;
PreparedStatement ps = null;
int row;
try{
conn = JdbcDruidUtil.getConnection();
ps = conn.prepareStatement(sql);
// 得到参数的个数
ParameterMetaData pd = ps.getParameterMetaData();
for(int i =0;i<pd.getParameterCount();i++){
ps.setObject(i+1,param[i]);
}
row = ps.executeUpdate();
}catch (Exception e){
e.printStackTrace();
// 通过自定义异常解决异常耦合问题
throw new ApplicationException(e.getMessage());
}finally{
JdbcDruidUtil.closeResource(ps,conn);
}
return row;
}
/**
* 通用查询方法
*/
@Override
public <T> List<T> select(String sql, Object[] param, Class<T> clazz) {
Connection conn = null;
PreparedStatement ps = null;
ResultSet rs = null;
List<T> list = new ArrayList<>();
try{
conn = JdbcDruidUtil.getConnection();
ps = conn.prepareStatement(sql);
// 得到参数的个数
ParameterMetaData pd = ps.getParameterMetaData();
for(int i =0;i<pd.getParameterCount();i++){
ps.setObject(i+1,param[i]);
}
rs = ps.executeQuery();
// 获取结果集信息
ResultSetMetaData rm = rs.getMetaData();
while(rs.next()){
// OMR映射
// 通过反射实例化实体类对象
T bean = clazz.newInstance();
// 实体类的属性名必须要和表的列名相同。
// 因为后面会映射
for(int i=0;i<rm.getColumnCount();i++){
// 得到列名
String columnName = rm.getColumnName(i+1);
// 获取列的值
Object value = rs.getObject(columnName);
//通过BeanUtil工具类讲值映射到对象中
BeanUtils.setProperty(bean,columnName,value);
}
list.add(bean);
}
}catch (Exception e){
e.printStackTrace();
throw new ApplicationException(e.getMessage());
}finally{
JdbcDruidUtil.closeResource(rs,ps,conn);
}
return list;
}
}- UsersDao接口
java
public interface UsersDao extends BaseDao {
/**
* 根据用户ID查询用户
*
*/
Users selectUsersById(int userid);
/**
* 修改用户信息
*/
int updateUsersById(Users users);
/**
* 根据用户姓名模糊查询
*/
List<Users> selectUsersByLikeName(String username);
}- UsersDaoImpl接口实现类
java
public class UsersDaoImpl extends BaseDaoImpl implements UsersDao {
/**
* 根据用户ID查询用户
* @param userid 用户ID
* @return 返回匹配的用户对象,如果未找到则返回null
* @throws ApplicationException 当数据库操作失败时抛出此异常
*/
@Override
public Users selectUsersById(int userid) {
Connection conn =null;
PreparedStatement ps = null;
ResultSet rs = null;
Users users = null;
try{
// 获取数据库连接
conn = JdbcDruidUtil.getConnection();
// 预编译SQL查询语句
ps = conn.prepareStatement("select * from users where userid = ?");
// 设置查询参数
ps.setInt(1,userid);
// 执行查询并获取结果集
rs = ps.executeQuery();
while(rs.next()){
// 手动将结果集映射为用户对象
users = new Users();
users.setUserid(rs.getInt("userid"));
users.setUsername(rs.getString("username"));
users.setUserage(rs.getInt("userage"));
}
}catch(Exception e){
e.printStackTrace();
throw new ApplicationException(e.getMessage());
}finally{
JdbcDruidUtil.closeResource(rs,ps,conn);
}
return users;
}
/**
* 根据用户ID更新用户年龄
* @param users 包含用户ID和新年龄的用户对象
* @return 返回受影响的行数,如果更新失败则返回0
* @throws ApplicationException 当数据库操作失败时抛出此异常
*/
@Override
public int updateUsersById(Users users) {
// SQL更新语句,仅更新用户年龄字段
String sql = "update users set userage = ? where userid = ? ";
// 设置SQL参数
Object[] param = new Object[]{users.getUserage(),users.getUserid()};
// 调用基类的通用更新方法
return this.executeUpdate(sql,param);
}
/**
* 根据用户名模糊查询用户列表
* @param username 用于模糊匹配的用户名关键字
* @return 返回匹配的用户列表,如果未找到则返回空列表
* @throws ApplicationException 当数据库操作失败时抛出此异常
*/
@Override
public List<Users> selectUsersByLikeName(String username) {
// SQL模糊查询语句
String sql = "select * from users where username like ?";
// 设置模糊查询参数,使用%通配符
Object[] param = new Object[]{"%"+username+"%"};
// 调用基类的通用查询方法,使用反射创建用户对象
return this.select(sql,param,Users.class);
}
}3. 总结
本文讲解了应用分层的三种结构,以及封装通用的数据访问层代码
希望能够帮助到大家😊