文章目录

每日一句正能量
人有三样东西是无法隐瞒的,咳嗽,穷困和爱,你想隐瞒越欲盖弥彰。人有三样东西是不该挥霍的,身体,金钱和爱,你想挥霍却得不偿失。
第五章 HBase分布式数据库
章节概要
Spark计算框架是如何在分布式环境下对数据处理后的结果进行随机的、实时的存储呢?HBase数据库正是为了解决这种问题而应用而生。HBase数据库不同于一般的数据库,如MySQL数据库和Oracle数据库是基于行进行数据的存储,而HBase则是基于列进行数据的存储,这样的话,HBase就可以随着存储数据的不断增加而实时动态的增加列,从而满足Spark计算框架可以实时的将处理好的数据存储到HBase数据库中的需求。本章将针对HBase分布式数据库的相关知识进行详细讲解。
5.2 HBase的集群部署
HBase中存储在HDFS中的数据是通过Zookeeper协调处理的。由于HBase存在单点故障问题,因此通过Zookeeper部署一个高可用HBase集群来解决。以三台服务器为例(hadoop01、hadoop02和hadoop03),讲解HBase集群的安装部署,HBase集群的具体规划为hadoop01和hadoop02是主节点,hadoop02和hadoop03是从节点。
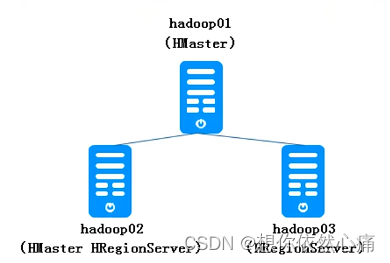
在图中,HBase集群中的hadoopo1和hadoop02是主节点,hadoop02和hadoop03是从节点。这里之所以将hadoop02既部署为主节点也部署为从节点,其目的是为了避免HBase集群主节点宕机导致单点故障问题。
接下来,分步骤讲解如何部署HBase集群,具体步骤如下:
(1)安装JDK、Hadoop以及zookeeper,这里我们设置的JDK版本是1.8、Hadoop版本是2.7.4以及Zookeeper的版本是3.4.10。
(2)下载HBase安装包。官网下载地址::http://archive.apache.org/dist/hbase。这里,我们选择下载的版本是1.2.1。
注意:还没有下载安装包的,下载地址可以去这里查看:大数据相关常用软件下载地址集锦
(3)上传并解压HBase安装包。将HBase安装包上传至Linux系统的/export/software/目录下,然后解压到/export/servers/目录。解压安装包的具体命令如下:
shell
tar -zxvf hbase-1.2.1-bin.tar.gz -C /export/servers/结果如下图所示:

(4)将/hadoop-2.7.4/etc/hadoop目录下的hdfs-site.xm和core-site.xm|配置文件复制-份到/hbase-1.2.1/conf目录下,复制文件的具体命令如下:
shell
cp /export/servers/hadoop-2.7.4/etc/hadoop/{hdfs-site.xml,core-site.xml} /export/servers/hbase-1.2.1/conf结果如下图所示:

(5)进入/Hbase-1.2.1/conf目录修改相关配置文件。打开hbase -env.sh配置文件,指定jdk的环境变量并配置Zookeeper (默认是使用内置的Zookeeper服务),修改后的hbase-env.sh文件内容具体如下:
xml
# The java implementation to use. Java 1.7+ required.
#配置jdk环境变量
export JAVA_ HOME= /export/servers/ jdk
# Tell HBase whether it should manage it's own instance of Zookeeper or not.
#配置hbase使用外部Zookeeper
export HBASE_ MANAGES_ZK=false
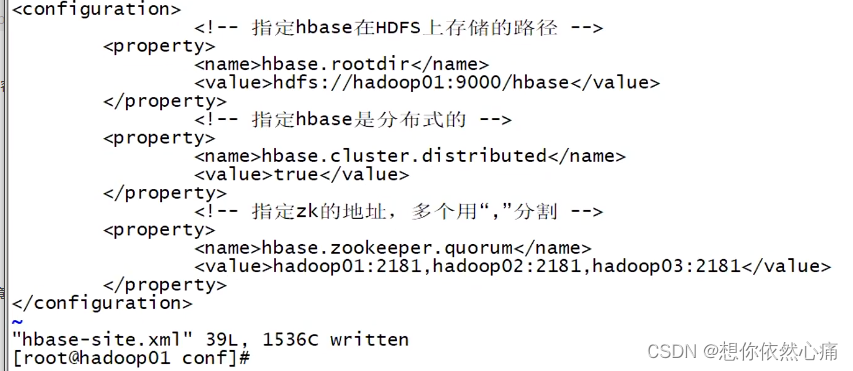
(6)打开hbase-site.xml配置文件,指定HBase在HDFS的存储路径、HBase的分布式存储方 式以及Zookeeper地址,修改后的hbase-site.xml文件内容具体如下:
xml
<configuration>
<!--指定hbase在HDFS上存储的路径-->
<property>
<name>hbase.rootdir </name>
<value>hdfs://hadoop01:9000/hbase</value>
</property>
< !-- 指定hbase是分布式的-->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 指定zk的地址,多个用","分割-->
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property>
</configuration>结果如下图所示:

(7)修改regionservers配置文件,配置HBase的从节点角色(即hadoop02和hadoop03) 。具体内容如下:
hadoop02
hadoop03结果如下图所示:


(8)修改backup-masters配置文件,为防止单点故障配置备用的主节点角色,具体内容如下:
hadoop02结果如下图所示:

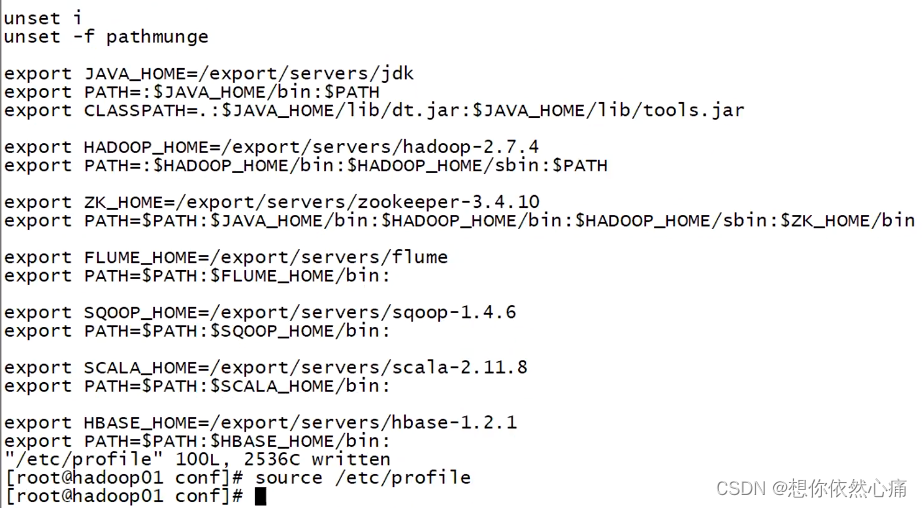
(9)修改profile配置文件,通过"vi /etc/profile"命令进入系统环境变量配置文件,配置HBase的环境变量(这一步,服务器hadoop01、hadoop02和hadoop03都需要配置),具体内容如下:
shell
export HBASE_HOME=/export/servers/hbase-1.2.1
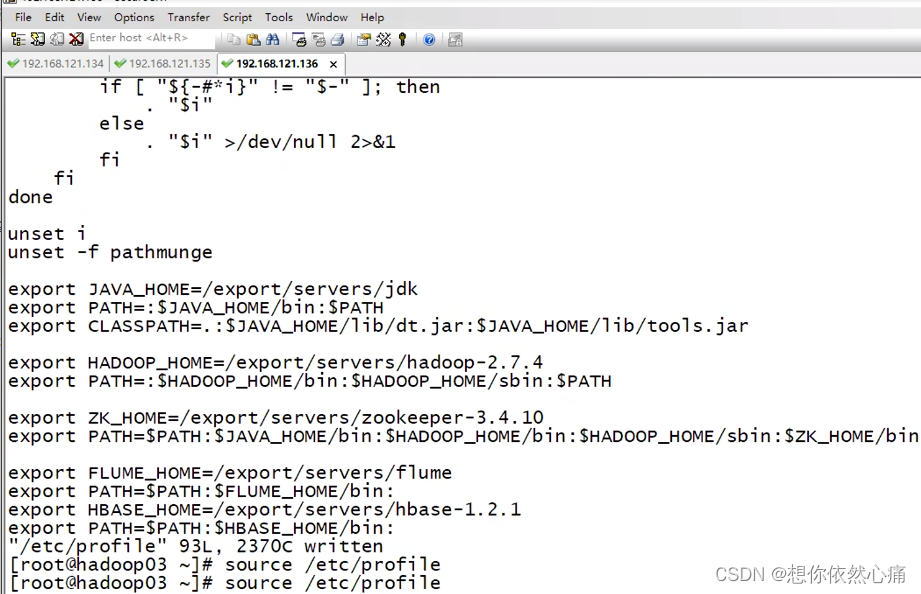
export PATH=$PATH:$HBASE_HOME/bin:在服务器hadoop01、hadoop02和hadoop03 上分别执行"source /etc/profile'命令,使系统环境配置文件生效。命令如下:
source /etc/profile结果如下图所示:

(10)将HBase的安装目录分发至hadoop02、hadoop03服务器上。 具体命令如下:
shell
scp -r /export/servers/hbase-1.2.1/ hadoop02:/export/servers/
scp -r /export/servers/hbase-1.2.1/ hadoop03:/export/servers/在服务器hadoop01、hadoop02和hadoop03. 上分别执行"source /etc/profile"命令,使系统环境配置文件生效。命令如下:
xml
source /etc/profile结果如下图所示:
(11)启动Zookeeper和HDFS,具体命令如下(这一步,服务器hadoop01、hadoop02和hadoop03都需要启动):
shell
# 启动zookeeper
zkServer.sh start结果如下图所示:

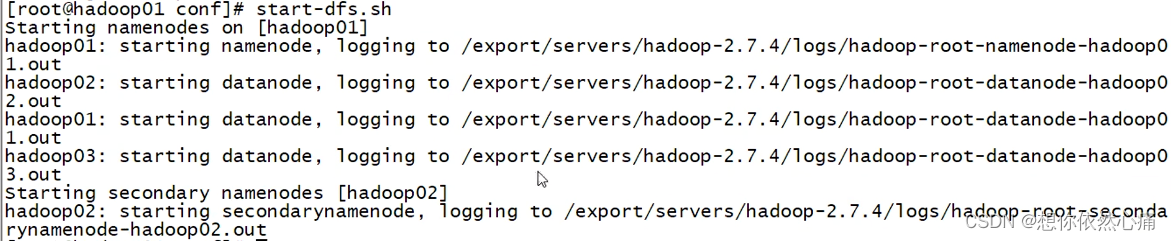
(12)启动HDFS,具体命令如下(这个命令会将三台一起启动了):
#启动hdfs
start-dfs.sh结果如下图所示:
(13)启动HBase集群,具体命令如下:
这里需要注意的是,在启动HBase集群之前,必须要保证集群中各个节点的时间是同步的,若不同步会抛出ClockOutOfSyncException异常,导致从节点无法启动。因此需要在集群各个节点中执行如下命令来保证时间同步。命令如下:
shell
ntpdate -u cn.pool.ntp.org结果如下图所示:
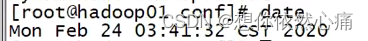

注:执行这个命令需要电脑联网
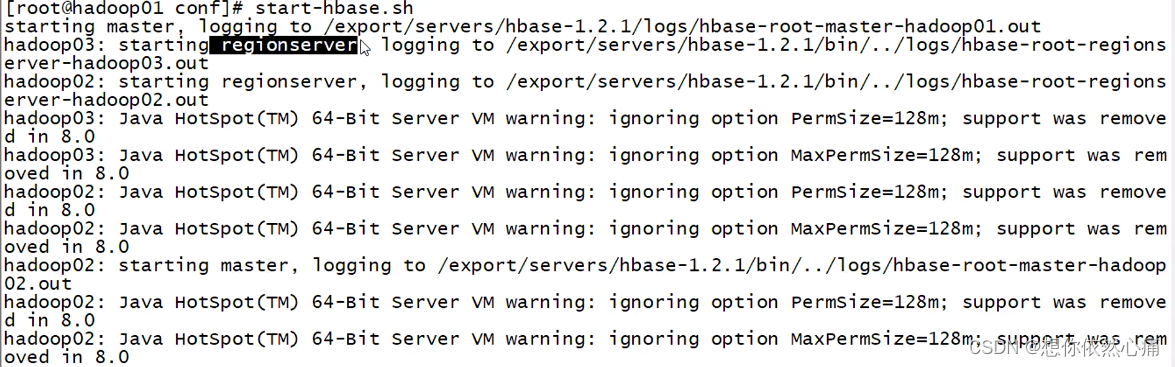
启动HBase集群,命令如下:
start-hbase.sh结果如下图所示:
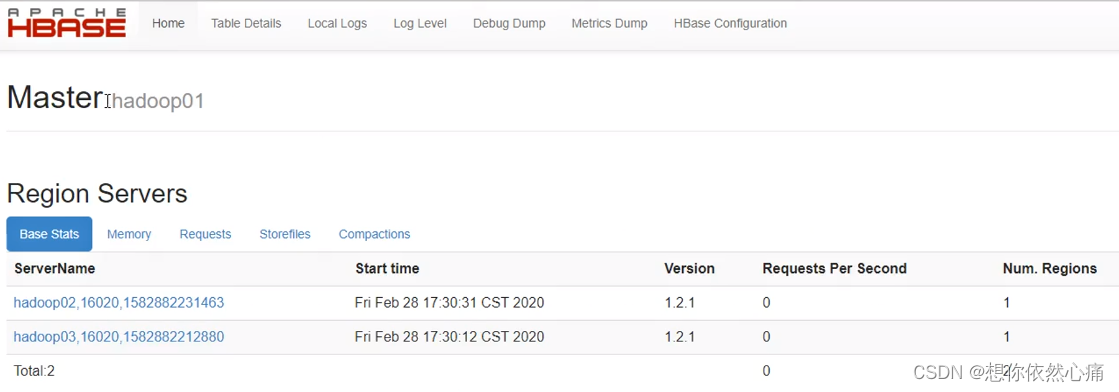
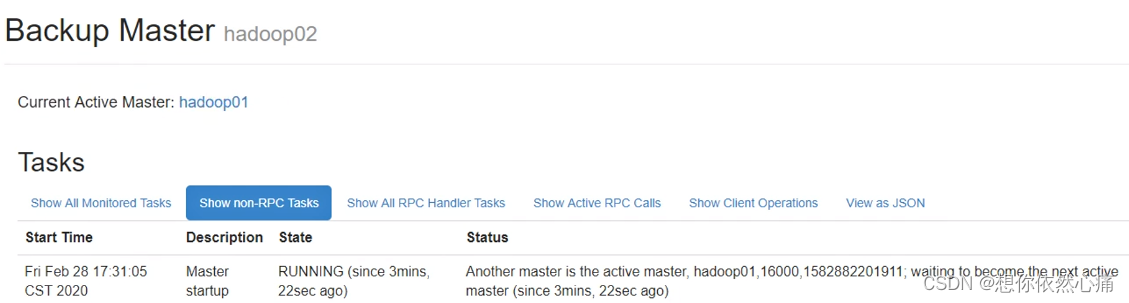
(13)通过"jps"命令检查HBase集群服务部署是否成功,通过浏览器访问http://hadoop01:16010,查看HBase集群状态,通过访问http://hadoop02:16010来查看集群备用主节点的状态,如下图所示。

转载自:https://blog.csdn.net/u014727709/article/details/131679982
欢迎 👍点赞✍评论⭐收藏,欢迎指正