1. 神经网络-非线性激活
1.1 relu与sigmoid
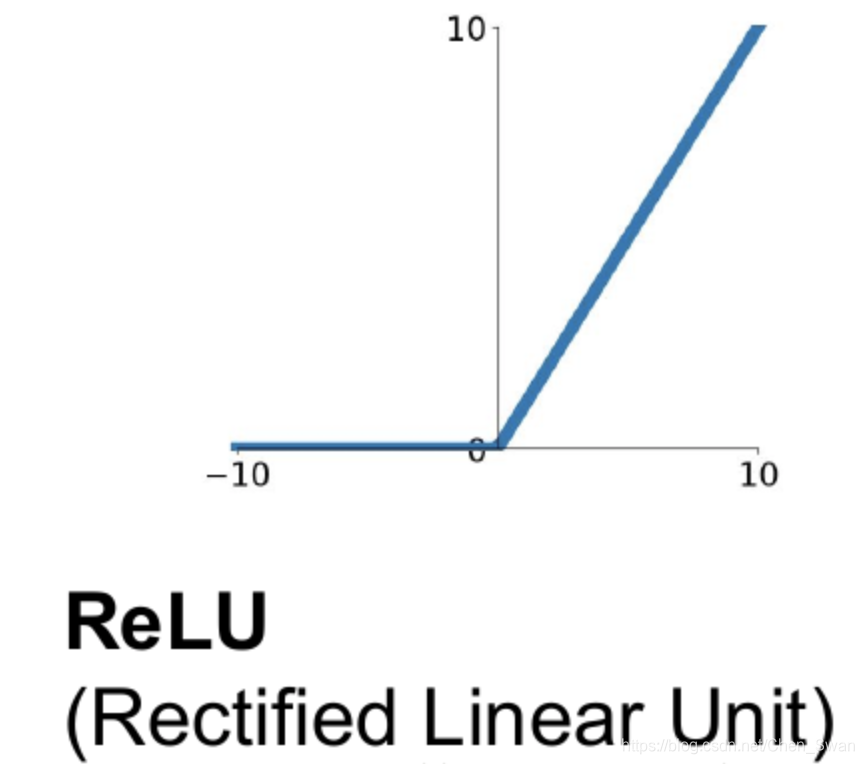
1.1.1 ReLU(Rectified Linear Unit,修正线性单元 )
- 定义与数学表达 :数学定义为 f ( x ) = max ( 0 , x ) f(x) = \max(0, x) f(x)=max(0,x) ,即当输入 x > 0 x > 0 x>0 时,输出为 x x x;当 x ≤ 0 x \leq 0 x≤0 时,输出为 0 0 0 。函数图像在正区间为线性,负区间为 0 0 0 ,整体呈现非线性。
- 核心优势
- 计算高效 :只需比较输入值与 0 0 0 的大小,无需像Sigmoid函数那样进行复杂的指数运算 ,能显著提升神经网络训练速度。
- 缓解梯度消失问题 :在正区间内,ReLU的导数为 1 1 1 。传统激活函数(如Sigmoid、Tanh )在反向传播时,因梯度趋近于 0 0 0 会导致训练停滞,ReLU在这方面有优势,尤其适用于深层网络。
- 稀疏激活特性 :负输入时输出为 0 0 0 ,使神经元激活呈现稀疏性,类似生物神经元工作方式,可减少计算量,提升模型泛化能力。
- 避免饱和问题 :在正区间无饱和现象,输出随输入线性增长,而Sigmoid/Tanh在极端输入时梯度趋近于 0 0 0 。
- 局限性及改进方案
- 死神经元问题(Dying ReLU) :当输入持续为负时,神经元输出恒为 0 0 0 且梯度无法更新,导致永久性失效。改进方法如Leaky ReLU,在负区间引入小斜率(如 0.01 0.01 0.01 ),保留微弱激活 ;Parametric ReLU (PReLU) ,将负区间的斜率设为可学习参数,自适应调整;Exponential Linear Unit (ELU) ,负区间使用指数函数,平滑过渡且保持梯度非零。
- 非零中心性:输出均为非负数,可能导致梯度更新方向单一,影响收敛效率。
- 应用领域
- 卷积神经网络(CNN):是CNN中的标准激活函数,如ResNet、YOLO等网络结构,能加速特征提取 ,在图像分类、目标检测等任务中提升模型性能。
- 自然语言处理:在Transformer架构中结合注意力机制,处理长序列依赖;BERT、GPT等模型通过ReLU增强非线性表达能力。
- 语音识别 :在深度神经网络(DNN)和LSTM中减少梯度消失,提升语音特征学习效率。
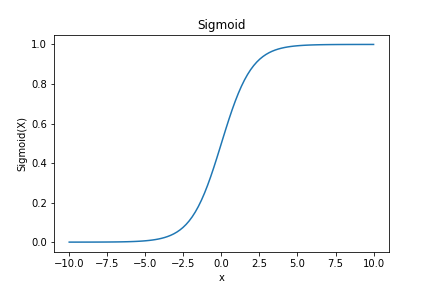
1.1.2 Sigmoid函数
- 定义与数学表达 :也称为Logistic函数,数学表达式为 σ ( x ) = 1 1 + e − x \sigma(x)=\frac{1}{1 + e^{-x}} σ(x)=1+e−x1 ,它将任意实数映射到 0 0 0 到 1 1 1 之间的值 。
- 核心优势
- 输出范围合适 :输出范围在 0 0 0 到 1 1 1 之间,适合用于二分类问题,可将输出解释为样本属于某个类别的概率。
- 平滑性:函数光滑且连续,在整个定义域上都具有可导性,对于基于梯度的优化方法(如梯度下降 )很重要。
- 非线性特性:引入非线性变换,让神经网络能够学习和表示复杂的非线性函数关系。
- 局限性
- 梯度饱和:当输入很大或很小时,Sigmoid函数的梯度会接近于零,导致梯度消失问题,使训练过程变得缓慢或停滞。
- 输出不是零中心 :输出范围是 ( 0 , 1 ) (0, 1) (0,1) ,不是零中心,可能会引发一些训练问题。
- 指数运算开销大:计算需要进行指数运算,计算量较大,在大规模数据集和深层网络中更为明显。
- 应用领域
- 二分类问题 :作为输出层的激活函数,将网络的输出映射到 ( 0 , 1 ) (0, 1) (0,1) 的概率范围内 。
- 逻辑回归:用作逻辑函数,将线性模型的输出转换为概率值。
- 异常检测 :将数据映射到 0 0 0 到 1 1 1 的范围内,评估数据点是否属于正常状态。
- 概率建模:用于概率模型中的激活函数,确保输出在概率范围内。
1.2 相关代码
bash
import torch
import torchvision.datasets
from torch import nn
from torch.nn import ReLU, Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
input = torch.tensor([[1,-0.5],
[-1,3]])
input = torch.reshape(input,(-1,1,2,2))
print(input.shape)
dataset = torchvision.datasets.CIFAR10("data", train=False, download=True,
transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset,batch_size=64)
class Test(nn.Module):
def __init__(self):
super(Test,self).__init__()
self.relu1 = ReLU()
self.sigmoid1 = Sigmoid()
def forward(self, input):
output = self.sigmoid1(input)
return output
test = Test()
output = test(input)
print(output)
step = 0
writer = SummaryWriter("logs")
for data in dataloader:
imgs, targets = data
writer.add_images("input", imgs, global_step=step)
output = test(imgs)
writer.add_images("output",output, global_step=step)
step = step + 1
writer.close()打开tensorboard展示运行结果

2. 线性层及其他层介绍
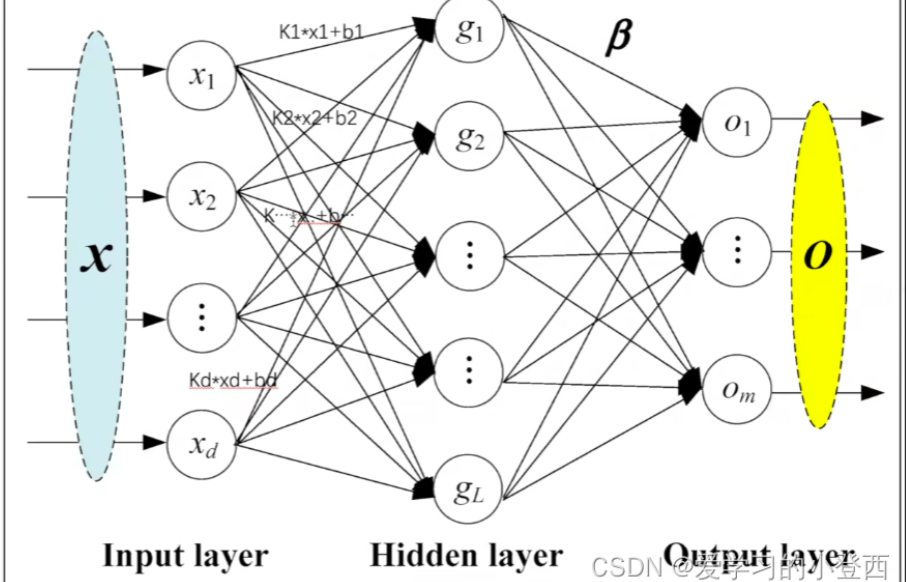
这是一张神经网络结构示意图
输入层(Input layer)
- 左侧浅蓝色椭圆标记为 X X X ,代表输入向量 ,包含 d d d 个输入特征,分别为 x 1 , x 2 , ⋯ , x d x_1, x_2, \cdots, x_d x1,x2,⋯,xd 。这些特征是神经网络接收的原始数据,是后续计算的基础。
隐藏层(Hidden layer)
- 中间层由多个神经元(圆圈表示)组成,分别为 g 1 , g 2 , ⋯ , g L g_1, g_2, \cdots, g_L g1,g2,⋯,gL 。
- 从输入层到隐藏层的连接线上标有计算式,如 k 1 × x 1 + b 1 k_1 \times x_1 + b_1 k1×x1+b1 ,表示输入特征 x 1 x_1 x1 与权重 k 1 k_1 k1 相乘后加上偏置 b 1 b_1 b1 ,这是神经元进行线性变换的过程。每个隐藏层神经元都对输入特征进行这样的线性组合操作,然后通常会经过一个激活函数(图中未明确画出激活函数,但实际应用中存在)进行非线性变换,得到隐藏层神经元的输出。
输出层(Output layer)
- 右侧黄色椭圆标记为 O O O ,包含 m m m 个输出神经元,分别为 o 1 , o 2 , ⋯ , o m o_1, o_2, \cdots, o_m o1,o2,⋯,om 。
- 隐藏层与输出层之间的连接线上标有 β \beta β ,表示隐藏层到输出层的权重 。隐藏层神经元的输出与这些权重进行加权求和,得到输出层神经元的最终输出,用于完成预测任务,如回归或分类任务。
bash
import torch
import torchvision
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("das", train=False, transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset, batch_size=64,drop_last=True)
class Test(nn.Module):
def __init__(self):
super(Test, self).__init__()
self.linear1 = Linear(196608,10)
def forward(self, input):
output = self.linear1(input)
return output
test = Test()
for data in dataloader:
imgs,targets = data
print(imgs.shape)
output = torch.flatten(imgs)
print(output.shape)
output = test(output)
print(output.shape)结果为:

...
输入层:接收展平后的图像张量,大小为 196608(即 643 32*32,对应一个批次 64 张 3 通道 32×32 的图像)。
输出层:直接通过一个线性层输出 10 个类别得分(对应 CIFAR10 的 10 个类别)。
隐藏层:代码中未定义任何隐藏层,因此隐藏层特征数为 0。