全部内容梳理
目标检测的两个任务:
预测标签 边界框
语义分割 实力分割
一个是类别 一个是实例级别
分类任务把每个图像当作一张图片看待 所有解决方法是先生成候选区域 再进行分类
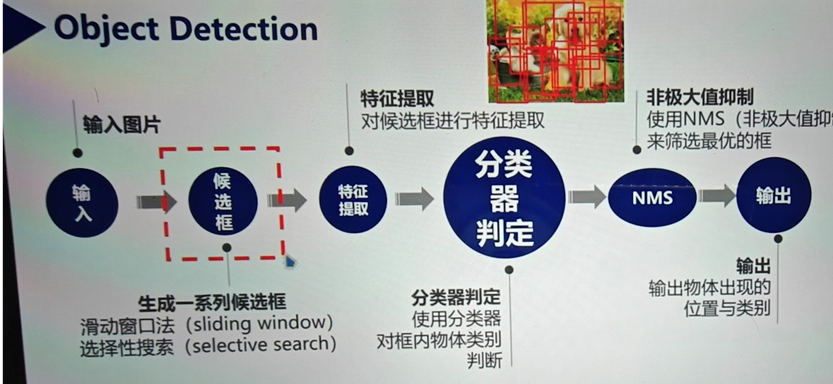
置信度:
包括对类别和边界框预测的自信程度
输出分类和IOU分数的乘积
双阶段代表R-CNN FAST R-CNN
分类 阈值判断
回归 拟合最优
锚定框是可能的候选区域
具体的
是否包含物体
判断类别
微调边界框
coco格式 json文件

YOLO格式 类别 x,y,w,h
验证集:用于验证模型效果的数据,评价模型学的好不好,选择超参数。
直接通过测试集进行检测,那么模型是以测试集为目标去优化,相当于作弊
交叉验证---为了规避掉验证集选择的bias(如验证集上的都是同一类别)
mAP:对每个类别计算AP,取所有类别AP计算平均mAP
对于每个类别,基于预测结果和真实标签,计算出一个precision-recall曲线
对于每个类别的precision-recall曲线,计算出该曲线下的面积,即AP。
计算所有类别的AP的平均值。
正样本
类别 边界框损失
负样本
类别
softmax单一预测
sigmoid多预测
检测任务是遍历的分类任务
常见的优化器
Loss(w,b)容易陷入局部最优
SGD也叫mini-batch,之后的优化算法,一定是建立在SGD之上,容易震荡
模拟退火,通过随机扰动避免了局部最优
AdaGrad自适应调整学习率,缺点:学习率会一直减小,最终可能变得过小,导致训练提前停止
RMSProp是对AdaGrad改进,通过指数加权平均来调整历史梯度的影响,使学习率减小的更加平滑。
Momentum参数更新不仅取决于当前梯度,还取决于之前的更新的累计动量。
Adam结合了Momentum和RMSProp的优点,通过自适应学习率和动量加速收敛
主干网络
颈部:对于主干网络提取的特征信息做进一步融合,增加了鲁棒性和特征的表达能力,对多尺度目标检测和小目标检测有着重要作用
头部:卷积层或FC层进行分类和定位
anchor free
对每个像素点预测类别和边界框
每个位置预测一个框 重叠位置可能无法检测
anchor box
复杂度高
不灵活
正样本
正样本指预测框和真实框IOU大于设定阈值
负样本指预测框和真实框IOU小于设定阈值
失衡的后果:
负样本过多会淹没正样本 关注负样本
模型倾向于负样本预测 漏检正样本
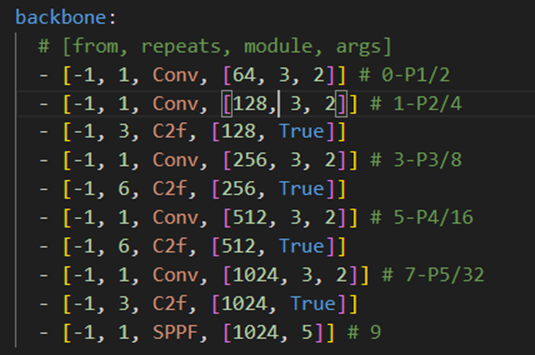
最后一层换成了SPPF
|-----------------------|--------------------------------|-------------------------|------------------------------------|------------------------------|-------------------------|
| 模型版本 | 准确率 (Accuracy) | 召回率(Recall) | F1****值 (F1 Score) | 每秒浮点运算次数(GFLOPs) | 平均精度均值(mAP) |
| 未改进版本 | 82.3% | 78.5% | 80.1% | 5.6 | 0.468 |
| 改进点一 | 83.6% | 82.5% | 82.8% | 5.7 | 0.479 |
| 改进点二 | 83.4% | 81.7% | 80.3% | 5.6 | 0.468 |
| 改进点一**+**改进点二 | 85.1% | 83.7% | 84.1% | 5.7 | 0.481 |
对于小波卷积的替换 只需要对写好小波卷积部分 然后在各个结构中进行替换
同理
标注使用LABELME YOLO格式
使用的主干网络RESNET101 使用了预训练权重
批次大小设置为24 训练轮次100 优化器为 Adam 优化器,初始学习率为0.01

召回率关注的是在所有实际为正的样本中,模型能够正确预测出多少,即模型预测正类的完整性
精确率关注的是模型预测为正的样本中有多少是 真正的正样本,即模型预测正类的准确性
map是0.5--0.95的平均map
0.75更能反映小目标
小波变换 正交基 没有冗余信息
小波变换用于替代短时傅里叶变换 把无限长的基替换为有限长的衰减小波基
短时傅里叶处理不平稳的信号 小波变换克服了短时傅里叶的窗口不变性

小波变换卷积通过小波变换分解为不同的频率分量 关注不同的频率
进行小核卷积 进行上采样 小波基函数类似卷积核
低频对应全局 高频对应局部 通过对低频高频分别处理 更好的进行多尺度表达
小波变换卷积通过低频逐渐向高频过渡 从而实现大尺度物体向小尺度的转变 低频的信息具有全局特征 弥补了CNN局部提取的缺陷 高频特征更好的捕捉了边缘纹理等 强化了形状的识别
绝大部分噪音都是图像的高频分量 ,通过低通滤波器来滤除高频 ; 边缘也是图像的高频分量,可以通过添加高频分量来增强原始图像的边缘;
学生网络接收到的标签
一种是教师网络的输出, 一种是真实的标签。
硬标签 独热编码 软标签 概率分布
蒸馏温度 温度越高越平滑 越可以容忍学生的过失
concat 维度增加 自适应学习
add 信息量增加 残差连接
卷积如何在计算机中并行计算 转化为特征向量
深度可分离卷积 空洞卷积 扩大感受野
车道线检测
线提议单元 为了学习全局特征 类似于猫框
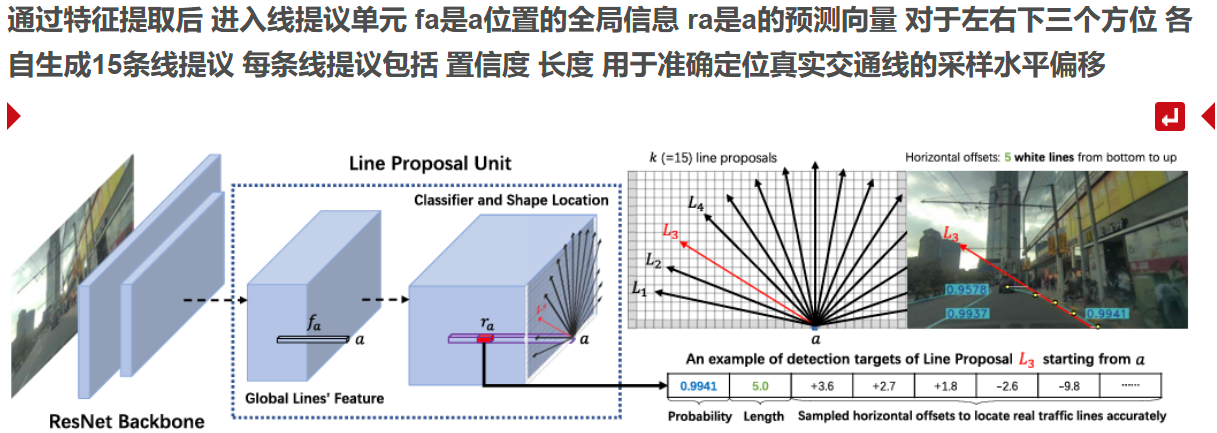
正标签选择 小于一个阈值 但一个车道线可以有多个提议
负标签选择 与所有车道线都大于阈值
首先是距离判断正负标签 其次看分类的分数
像目标检测一样 只有正标签 才有回归损失
回归损失 平滑L1损失 避免了过度惩罚小误差
车道线具有高级语义 也需要低级语义进行定位
高级语义检测车道线 低级语义定位
RIO聚合上下文
车到先验
背景前景概率 长度 角度和起点 N个偏移量
线IOU把车道线作为一个
在检测过程中
计算焦点损失 类别
相似度损失 距离远近
训练时
类别损失 回归损失 LIOU损失
Lseg辅助分割损失 更好的定位
Laneiou考虑了车道角度
CLRKDNE对检测头和FPN进行简化 推理速度上升60% 保持了和CLRNET相当的精度
利用教师模型 CLRNet 的中间特征层、先验嵌入和最终检测头 logits 来提升其车道检测能力
logits是一个向量 类似软标签
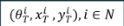
起点和角度
CLRKDNET单个检测头 固定先验参数(教师传递,不可迭代)
知识蒸馏分为三个部分
注意力图蒸馏
让学生网络也能关注关键特征
先验知识嵌入和logits蒸馏
学生网络直接使用起点和角度(RIO精炼后的)L2范数进行损失比较
Logit 蒸馏:Logit 蒸馏关注检测头的最终输出
确保学生有老师的输出逻辑 参数包括长度 类别 偏移量等
目标检测
DETR对于真实值 预测值 摒弃了NMS 使用匈牙利算法进行二分图匹配 并行预测
二分图匹配考虑 匹配损失 包括类别和回归
GIOU广义交并比 考虑了重叠区域 考虑了位置信息
D-fine
对于回归任务 概率分布 细粒度分布优化
深层向浅层的知识传递
传统的logits模仿和特征模仿在检测任务下精度低下
从固定的坐标预测变成建模概率分布(残差方式)
把四个边分为了n个bin预测每个bin的概率 取最大
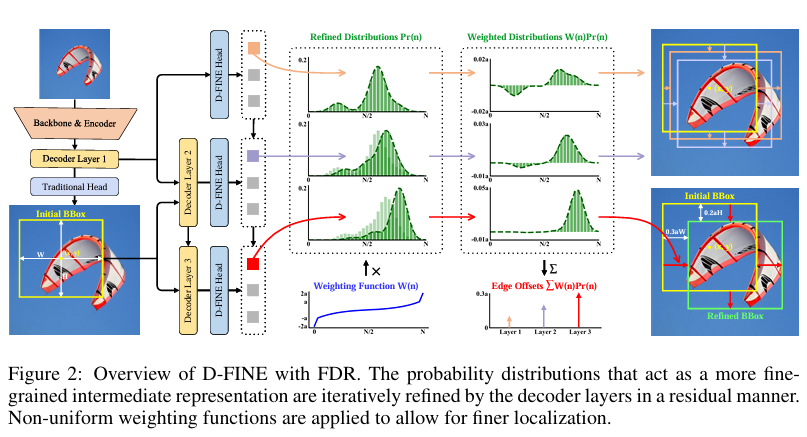
首先第一层预测初步边界框 初步概率分布
边界框作为参考框 后续层对概率分布进行优化
wn通过分段可以对小的偏差更精细调整
DEIM
解决DETR中稀疏监督的问题
增加额外的目标 提高每个图像中的正样本数量
YOLO的每个目标和多个猫框相关联 提供了密集监督
对小目标 密集监督更加重要
增加每张训练样本中的额外目标数量
提供监督
保留了020的匹配机制 避免了NMS 防止推理速度变慢