一、编码
当我们用数字来让电脑"认识"字符或单词时,最简单的方法是为每个字符或单词分配一个唯一的编号,然后用一个长长的向量来表示它。比如,假设"我"这个字在字典中的编号是第10个,那么它的表示就是一个很多0组成的向量,除了第10个位置是1,其余都是0。这种表示叫做one-hot编码,中文常用字就有大约五千个,所以每个字的向量长度也就大约是五千维。
不过,这样的表示有两个问题。第一,向量很长,存储和计算都很浪费空间,因为大部分位置都是0,没有任何信息。第二,虽然这种编码能让每个字唯一标识,但是它完全没有体现字与字之间的关系。
one-hot编码方式存在一个问题,one-hot矩阵相当于简单的给每个单词编了 个号,但是单词和单词之间的关系则完全体现不出来,比如说"cat"和"dog"经过onehot编码后可能是'1,0,0,0,0,0'和'0,1,0,0,0,0'我们可以求他们的余弦相似度:
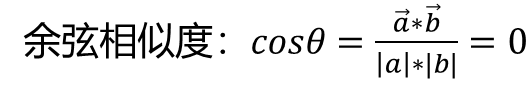
余弦相似度为0,他们毫不相关,但实际上"cat"和"dog"应该是有关系的,至少他们都 是动物,可以发现one-hot编码并不能表示单词之间的关系。 综上所述,one-hot编码存在两个问题(维度灾难和语义鸿沟):
编码后形成高维稀疏矩阵占用大量空间
编码后不能表示单词之间的关系
二、词嵌入(Word Embedding)
词嵌入是一种将词转换为低维稠密向量的技术,旨在用连续的向量表示单词的语义和语法信息。不同于传统的独热编码(One-Hot Encoding),词嵌入能够捕捉单词之间的语义关系,比如相似词的距离更近。
主要特点:
稠密向量:每个单词由一个实数向量表示,通常维度较低(如100、300维),节省存储空间。
语义捕捉:通过训练,词向量中相似或相关的词在空间中的距距离更近,包括词义相似、上下文关系等。
可迁移性:预训练的词嵌入(如Word2Vec、GloVe)可以迁移到不同的任务上,提升模型效果。
主要方法:
Word2Vec:利用Skip-Gram或CBOW模型,通过预测邻近词或目标词学习词向量。
GloVe:结合全局统计信息,优化词与词之间的共现概率,得到词向量。
FastText:考虑到词内部的子词(字符n-gram),更善于处理未登录词(OOV)。
应用场景:
词义相似性计算
词性标注
文本分类
机器翻译
其他多种NLP任务
三、Embedding降维
WordEmbedding解决了这个问题,WordEmbedding的核心就是给每个单词赋予一 个固定长度的词嵌入向量。
这个向量可以自己调整,可以是64维,也可以是128,512、1024,等等。而这个向 量的维度远远小于字典的长度。为了得到这个向量我们可以用一个可训练参数矩阵与 原来的one-hot编码矩阵相乘,比如说one-hot编码的矩阵大小是 100*100,可训 练参数矩阵的大小是100*100 ,那得到的词嵌入矩阵就为100*64 的矩阵,可以看 到我们将100维的特征维度降低为64维。
四、 Embedding映射
比如说"cat"的词嵌入向量为-0.95 0.44,"dog"的词嵌入向量为-2.15 0.11。此时我 们再计算"cat"和"dog"的余弦相似度:
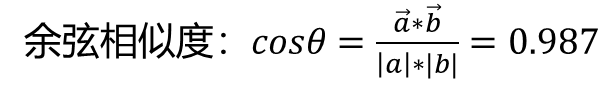
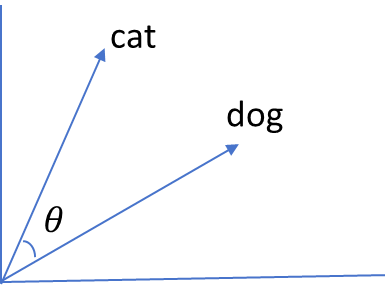
可以看到,现在可以体现出两个单词之间的关系。从坐标系上看他们也靠的很近。当 然这只是一种简单的词嵌入方式,即通过一个可训练矩阵将高维稀疏的矩阵映射为低 维稠密的矩阵。
五、设计思路
python
import torch
import torch.nn as nn
# 定义一个简单的词嵌入层
embedding_dim = 64
vocab_size = 10000 # 假设词典大小为10000
embedding_layer = nn.Embedding(vocab_size, embedding_dim)
# 输入一个单词的索引
word_index = torch.tensor([567]) # 假设单词"cat"在词典中的索引是567
# 通过词嵌入层获取词嵌入向量a
word_embedding = embedding_layer(word_index)
# 打印词嵌入向量
print("Word Embedding for 'cat':")
print(word_embedding)