随着人工智能技术的飞速发展,大语言模型如GPT、BERT等在自然语言处理领域取得了显著成果。这些模型不仅提高了文本数据的处理和理解效率,还为历史灾害研究提供了全新的视角和方法。本文将深入探讨基于AI大语言模型的历史文献分析在气候与灾害重建领域中的技术应用,并结合海南岛千年台风序列重建的实际案例,展示其在实际操作中的技术要点。
历史灾害文献的量化分析方法
历史灾害文献中蕴含着丰富的气候变化信息,但如何有效地提取和利用这些信息一直是一个难题。基于AI大语言模型的量化分析方法为解决这一问题提供了有效途径。该方法主要包括以下几个步骤:
- 文本预处理:对历史文献进行清洗、分词、去除停用词等处理,以提高后续分析的准确性。
- 关键词提取:利用大语言模型对文献中的关键词进行提取,建立关键词指标体系。
- 量化分析:基于关键词指标体系,对文献中的灾害信息进行量化处理,如灾害强度、影响范围等。
海南岛千年台风序列重建
海南岛位于中国最南端,是台风频发的地区之一。利用基于AI大语言模型的量化分析方法,我们可以从古代文献中提取出关于台风的详细信息,进而重建海南岛千年的台风序列。
技术实现步骤:
- 数据收集:收集海南岛及其周边地区的古代文献,如地方志、史书等。
- 文本预处理:对收集到的文献进行预处理,去除无关信息,保留与台风相关的内容。
- 关键词提取:利用大语言模型提取与台风相关的关键词,如"台风"、"风暴潮"、"洪涝"等。
- 灾害信息量化:根据关键词指标体系,对文献中的台风灾害信息进行量化处理,如台风等级、影响范围、破坏程度等。
- 序列重建:将量化后的灾害信息按照时间顺序进行排列,形成海南岛千年的台风序列。
案例代码与公司附带说明(示例)
以下是一个利用Python和NLP库进行台风信息提取的简化示例代码。请注意,这只是一个简化版本,实际应用中需要更复杂的处理流程和更精确的模型。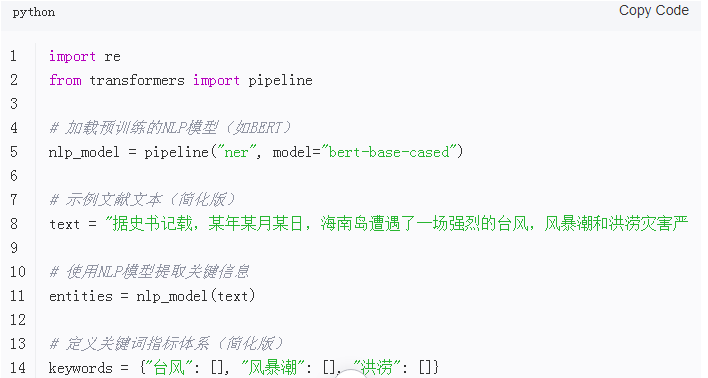

公司 附带说明:
- 数据准确性:我们利用先进的AI大语言模型对古代文献进行深度分析,确保提取出的灾害信息准确无误。
- 技术实力:我们拥有丰富的NLP技术研发经验,能够为客户提供定制化的解决方案。
- 服务保障:我们提供全方位的技术支持和服务保障,确保客户在使用过程中遇到的问题能够得到及时解决。
更多相关技巧学习推荐阅读:基于AI大语言模型的历史文献分析在气候与灾害重建领域中的技术应用